 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Developing Smart Web-Search Using RegEx
Oct 10, 2021
Due to the increasing storage data on Web Applications, it becomes very difficult to use only keyword-based searches to provide comprehensive search results, thus increasing the difficulty for web users to search information on the web. In this paper, we proposed using a combined method of keyword-based and Regular expressions (regEx) searches to perform a search using strings of targeted items for optimal results even as the volume of data around the world on the Internet continues to explode. The idea is to embed regEx patterns as part of the search engine's algorithm in a web application project to provide strings related to the targeted items for more comprehensive coverage of search results. The user's search query is a string of characters guided by search boundaries selected from the entry point. The results returned from the search operation are different results within a category determined by the search boundaries. This is designed to be beneficial to a user who has an obscure idea about the information he/she wanted to search but knows the boundaries within which to get the information. This technique can be applied to data processing tasks such as information extraction and search refinement.
Enhancing the Security & Privacy of Wearable Brain-Computer Interfaces
Jan 19, 2022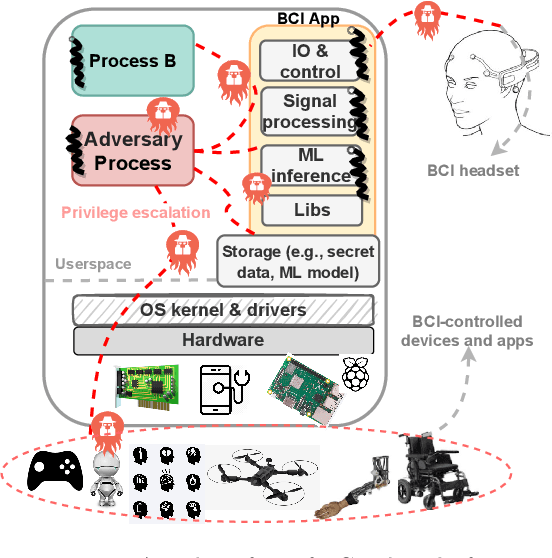

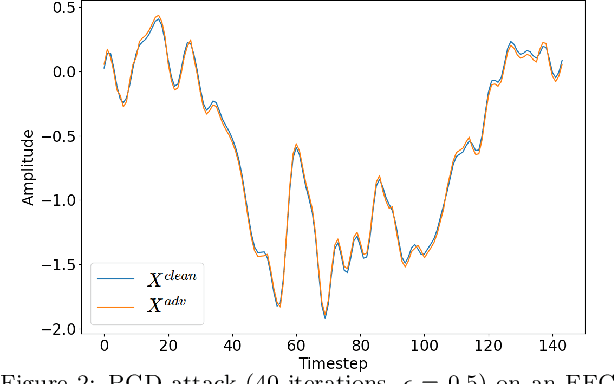
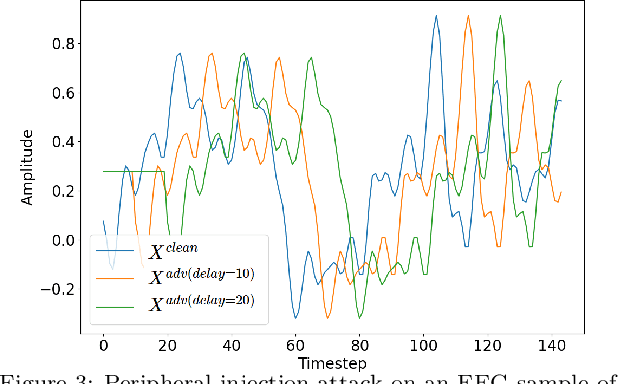
Brain computing interfaces (BCI) are used in a plethora of safety/privacy-critical applications, ranging from healthcare to smart communication and control. Wearable BCI setups typically involve a head-mounted sensor connected to a mobile device, combined with ML-based data processing. Consequently, they are susceptible to a multiplicity of attacks across the hardware, software, and networking stacks used that can leak users' brainwave data or at worst relinquish control of BCI-assisted devices to remote attackers. In this paper, we: (i) analyse the whole-system security and privacy threats to existing wearable BCI products from an operating system and adversarial machine learning perspective; and (ii) introduce Argus, the first information flow control system for wearable BCI applications that mitigates these attacks. Argus' domain-specific design leads to a lightweight implementation on Linux ARM platforms suitable for existing BCI use-cases. Our proof of concept attacks on real-world BCI devices (Muse, NeuroSky, and OpenBCI) led us to discover more than 300 vulnerabilities across the stacks of six major attack vectors. Our evaluation shows Argus is highly effective in tracking sensitive dataflows and restricting these attacks with an acceptable memory and performance overhead (<15%).
Active Sensing for Communications by Learning
Dec 08, 2021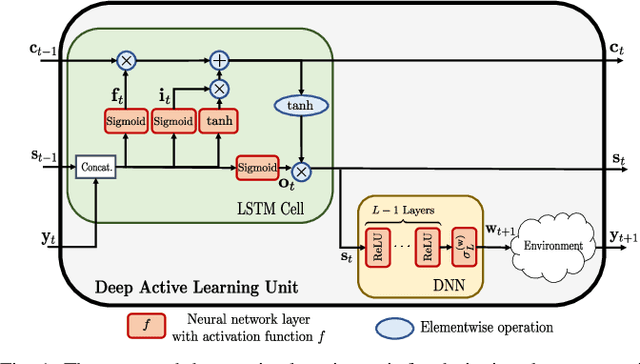
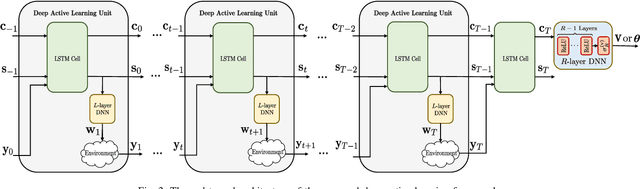
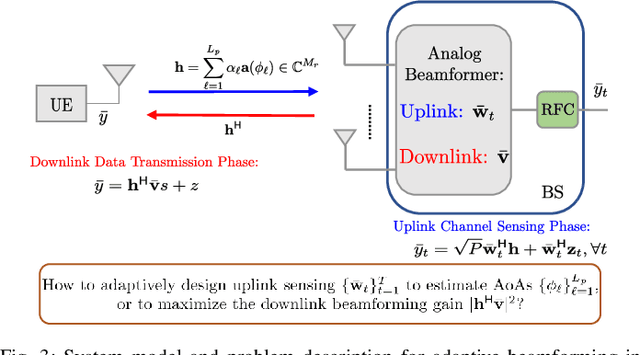
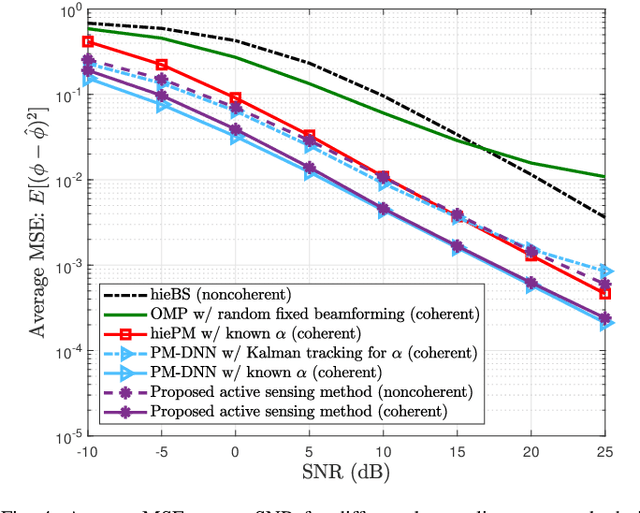
This paper proposes a deep learning approach to a class of active sensing problems in wireless communications in which an agent sequentially interacts with an environment over a predetermined number of time frames to gather information in order to perform a sensing or actuation task for maximizing some utility function. In such an active learning setting, the agent needs to design an adaptive sensing strategy sequentially based on the observations made so far. To tackle such a challenging problem in which the dimension of historical observations increases over time, we propose to use a long short-term memory (LSTM) network to exploit the temporal correlations in the sequence of observations and to map each observation to a fixed-size state information vector. We then use a deep neural network (DNN) to map the LSTM state at each time frame to the design of the next measurement step. Finally, we employ another DNN to map the final LSTM state to the desired solution. We investigate the performance of the proposed framework for adaptive channel sensing problems in wireless communications. In particular, we consider the adaptive beamforming problem for mmWave beam alignment and the adaptive reconfigurable intelligent surface sensing problem for reflection alignment. Numerical results demonstrate that the proposed deep active sensing strategy outperforms the existing adaptive or nonadaptive sensing schemes.
Multi$^2$OIE: Multilingual Open Information Extraction Based on Multi-Head Attention with BERT
Oct 07, 2020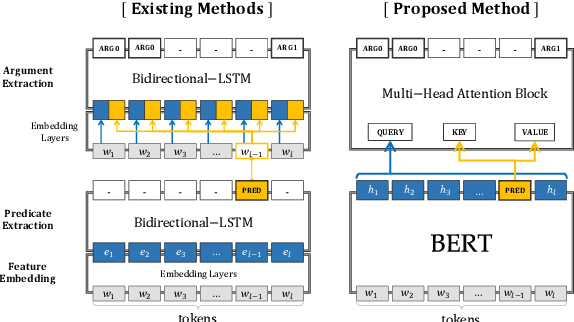
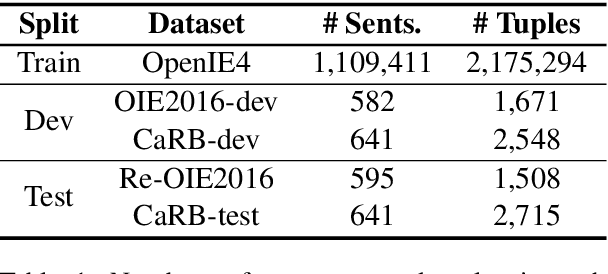
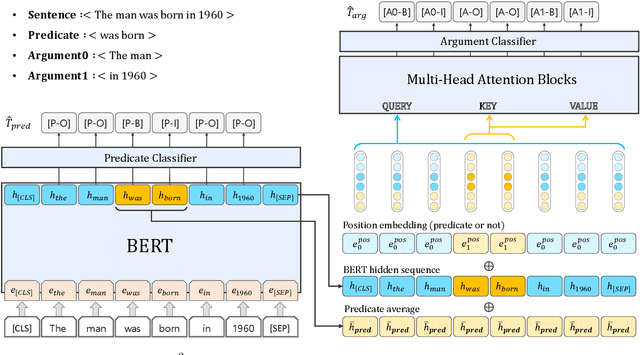

In this paper, we propose Multi$^2$OIE, which performs open information extraction (open IE) by combining BERT with multi-head attention. Our model is a sequence-labeling system with an efficient and effective argument extraction method. We use a query, key, and value setting inspired by the Multimodal Transformer to replace the previously used bidirectional long short-term memory architecture with multi-head attention. Multi$^2$OIE outperforms existing sequence-labeling systems with high computational efficiency on two benchmark evaluation datasets, Re-OIE2016 and CaRB. Additionally, we apply the proposed method to multilingual open IE using multilingual BERT. Experimental results on new benchmark datasets introduced for two languages (Spanish and Portuguese) demonstrate that our model outperforms other multilingual systems without training data for the target languages.
Improving short-term bike sharing demand forecast through an irregular convolutional neural network
Feb 11, 2022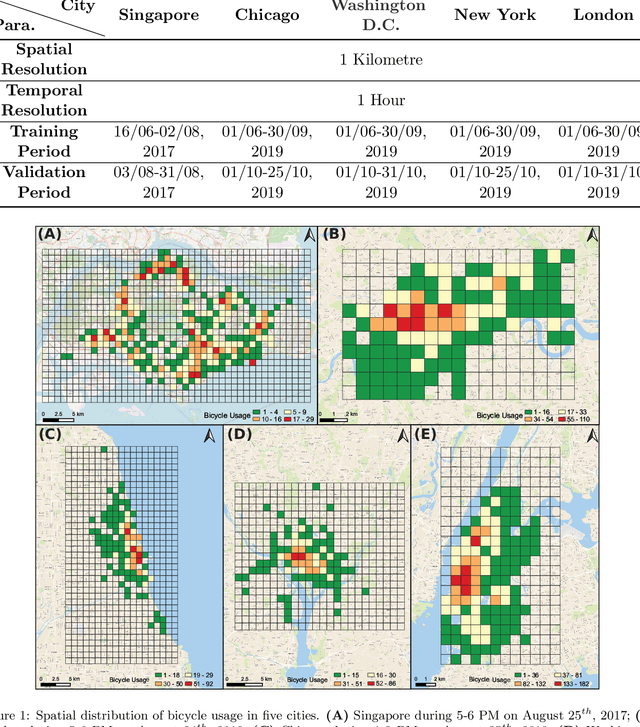
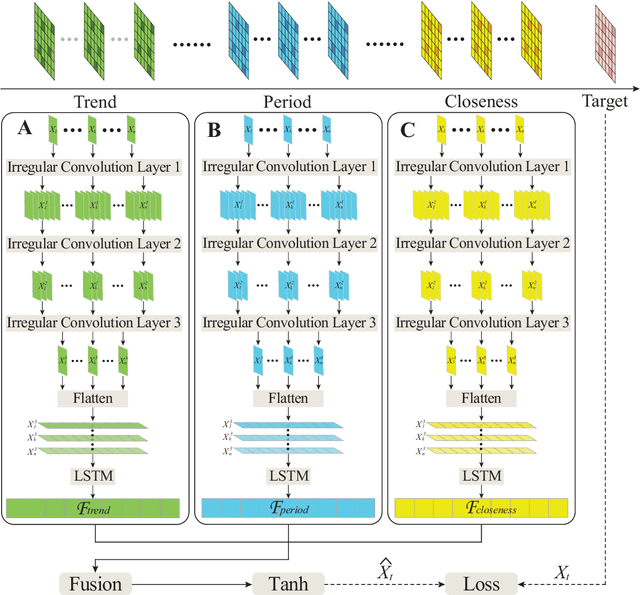
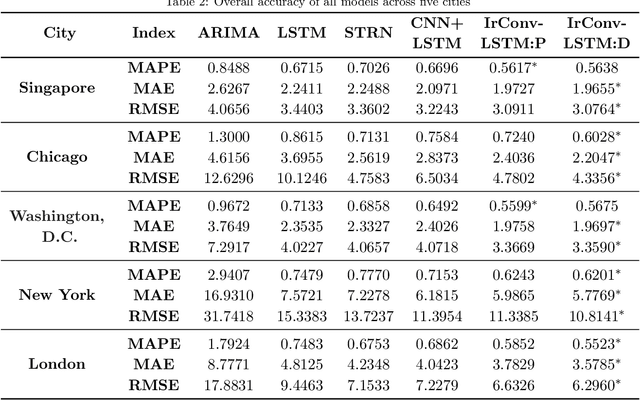
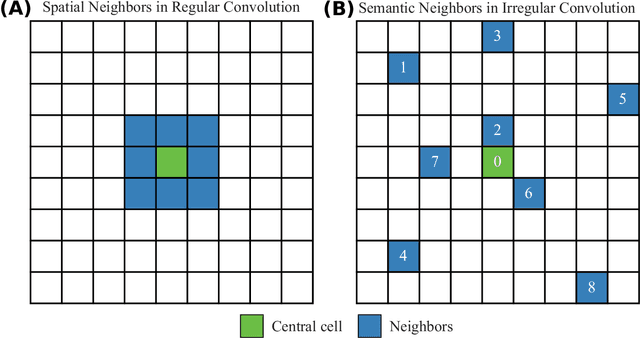
As an important task for the management of bike sharing systems, accurate forecast of travel demand could facilitate dispatch and relocation of bicycles to improve user satisfaction. In recent years, many deep learning algorithms have been introduced to improve bicycle usage forecast. A typical practice is to integrate convolutional (CNN) and recurrent neural network (RNN) to capture spatial-temporal dependency in historical travel demand. For typical CNN, the convolution operation is conducted through a kernel that moves across a "matrix-format" city to extract features over spatially adjacent urban areas. This practice assumes that areas close to each other could provide useful information that improves prediction accuracy. However, bicycle usage in neighboring areas might not always be similar, given spatial variations in built environment characteristics and travel behavior that affect cycling activities. Yet, areas that are far apart can be relatively more similar in temporal usage patterns. To utilize the hidden linkage among these distant urban areas, the study proposes an irregular convolutional Long-Short Term Memory model (IrConv+LSTM) to improve short-term bike sharing demand forecast. The model modifies traditional CNN with irregular convolutional architecture to extract dependency among "semantic neighbors". The proposed model is evaluated with a set of benchmark models in five study sites, which include one dockless bike sharing system in Singapore, and four station-based systems in Chicago, Washington, D.C., New York, and London. We find that IrConv+LSTM outperforms other benchmark models in the five cities. The model also achieves superior performance in areas with varying levels of bicycle usage and during peak periods. The findings suggest that "thinking beyond spatial neighbors" can further improve short-term travel demand prediction of urban bike sharing systems.
Generalized Spatially-Coupled Parallel Concatenated Codes With Partial Repetition
Jan 24, 2022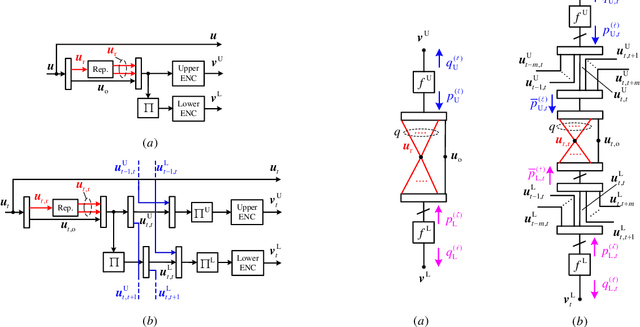
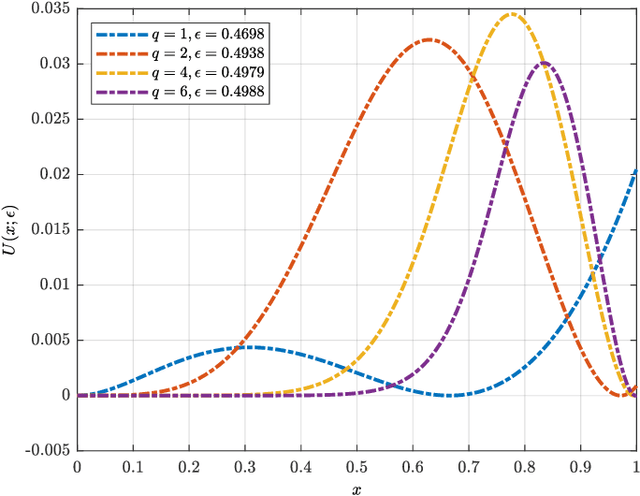
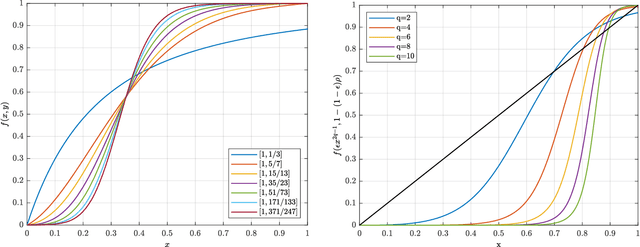
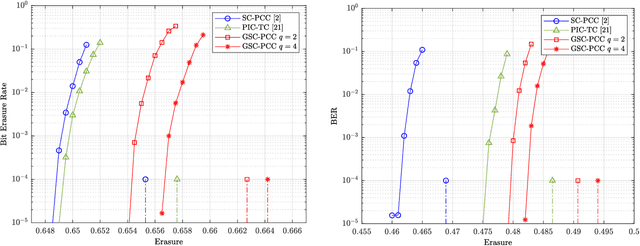
A new class of spatially-coupled turbo-like codes (SC-TCs), dubbed generalized spatially coupled parallel concatenated codes (GSC-PCCs), is introduced. These codes are constructed by applying spatial coupling on parallel concatenated codes (PCCs) with a fraction of information bits repeated $q$ times. GSC-PCCs can be seen as a generalization of the original spatially-coupled parallel concatenated codes proposed by Moloudi et al. [2]. To characterize the asymptotic performance of GSC-PCCs, we derive the corresponding density evolution equations and compute their decoding thresholds. The threshold saturation effect is observed and proven. Most importantly, we rigorously prove that any rate-$R$ GSC-PCC ensemble with 2-state convolutional component codes achieves at least a fraction $1-\frac{R}{R+q}$ of the capacity of the binary erasure channel (BEC) for repetition factor $q\geq2$ and this multiplicative gap vanishes as $q$ tends to infinity. To the best of our knowledge, this is the first class of SC-TCs that are proven to be capacity-achieving. Further, the connection between the strength of the component codes, the decoding thresholds of GSC-PCCs, and the repetition factor are established. The superiority of the proposed codes with finite blocklength is exemplified by comparing their error performance with that of existing SC-TCs via computer simulations.
When less is more: Simplifying inputs aids neural network understanding
Jan 19, 2022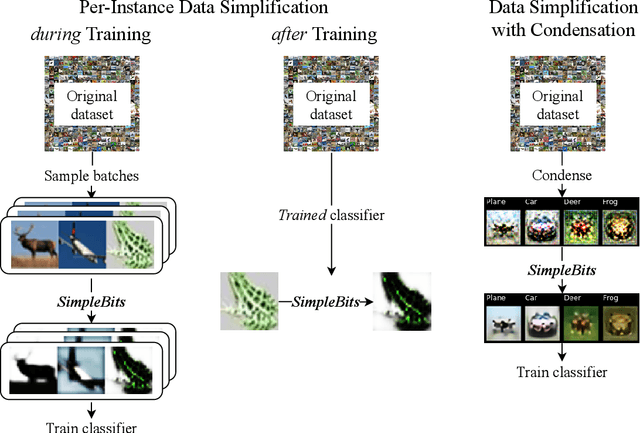

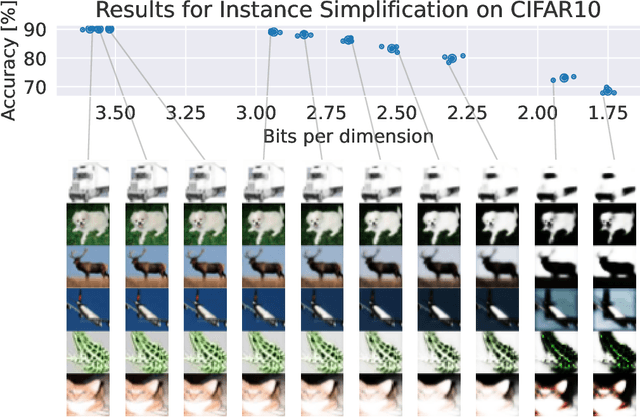
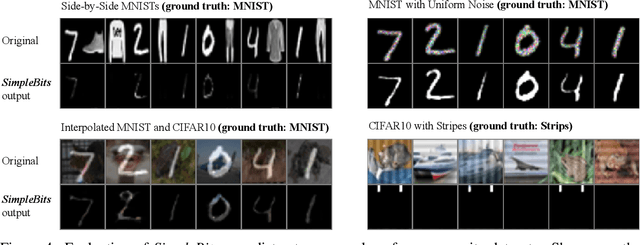
How do neural network image classifiers respond to simpler and simpler inputs? And what do such responses reveal about the learning process? To answer these questions, we need a clear measure of input simplicity (or inversely, complexity), an optimization objective that correlates with simplification, and a framework to incorporate such objective into training and inference. Lastly we need a variety of testbeds to experiment and evaluate the impact of such simplification on learning. In this work, we measure simplicity with the encoding bit size given by a pretrained generative model, and minimize the bit size to simplify inputs in training and inference. We investigate the effect of such simplification in several scenarios: conventional training, dataset condensation and post-hoc explanations. In all settings, inputs are simplified along with the original classification task, and we investigate the trade-off between input simplicity and task performance. For images with injected distractors, such simplification naturally removes superfluous information. For dataset condensation, we find that inputs can be simplified with almost no accuracy degradation. When used in post-hoc explanation, our learning-based simplification approach offers a valuable new tool to explore the basis of network decisions.
Privacy-Aware Human Mobility Prediction via Adversarial Networks
Jan 19, 2022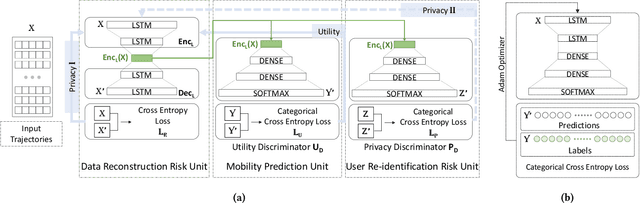

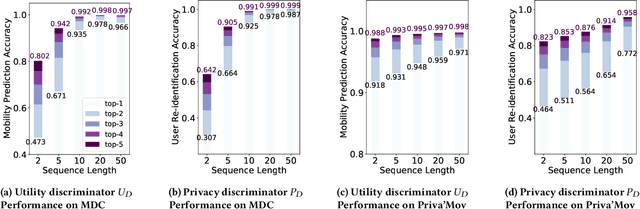
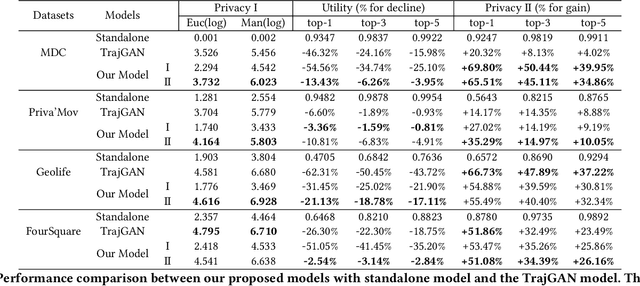
As various mobile devices and location-based services are increasingly developed in different smart city scenarios and applications, many unexpected privacy leakages have arisen due to geolocated data collection and sharing. While these geolocated data could provide a rich understanding of human mobility patterns and address various societal research questions, privacy concerns for users' sensitive information have limited their utilization. In this paper, we design and implement a novel LSTM-based adversarial mechanism with representation learning to attain a privacy-preserving feature representation of the original geolocated data (mobility data) for a sharing purpose. We quantify the utility-privacy trade-off of mobility datasets in terms of trajectory reconstruction risk, user re-identification risk, and mobility predictability. Our proposed architecture reports a Pareto Frontier analysis that enables the user to assess this trade-off as a function of Lagrangian loss weight parameters. The extensive comparison results on four representative mobility datasets demonstrate the superiority of our proposed architecture and the efficiency of the proposed privacy-preserving features extractor. Our results show that by exploring Pareto optimal setting, we can simultaneously increase both privacy (45%) and utility (32%).
Nonnegative Tensor Completion via Integer Optimization
Nov 08, 2021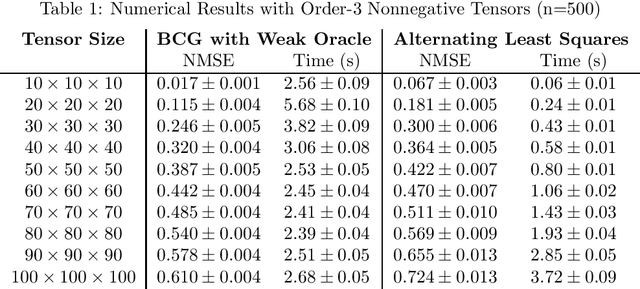

Unlike matrix completion, no algorithm for the tensor completion problem has so far been shown to achieve the information-theoretic sample complexity rate. This paper develops a new algorithm for the special case of completion for nonnegative tensors. We prove that our algorithm converges in a linear (in numerical tolerance) number of oracle steps, while achieving the information-theoretic rate. Our approach is to define a new norm for nonnegative tensors using the gauge of a specific 0-1 polytope that we construct. Because the norm is defined using a 0-1 polytope, this means we can use integer linear programming to solve linear separation problems over the polytope. We combine this insight with a variant of the Frank-Wolfe algorithm to construct our numerical algorithm, and we demonstrate its effectiveness and scalability through experiments.
Towards Private Learning on Decentralized Graphs with Local Differential Privacy
Jan 23, 2022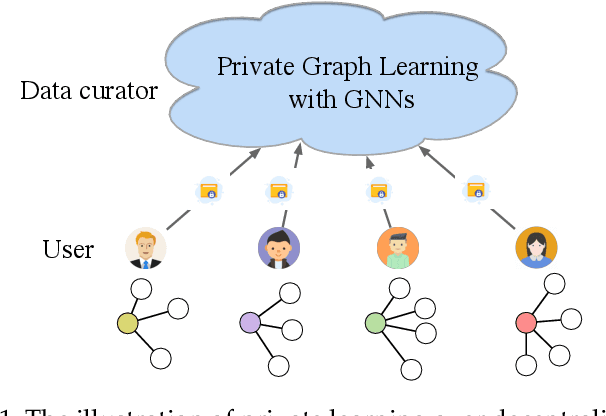
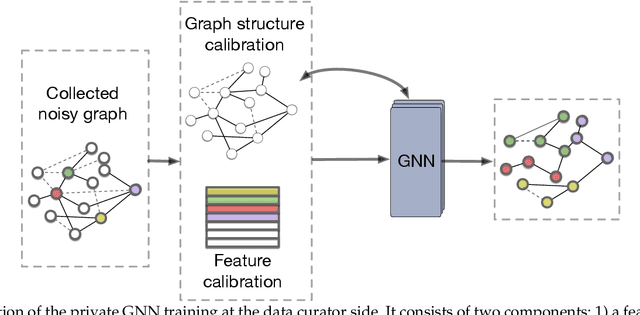

Many real-world networks are inherently decentralized. For example, in social networks, each user maintains a local view of a social graph, such as a list of friends and her profile. It is typical to collect these local views of social graphs and conduct graph learning tasks. However, learning over graphs can raise privacy concerns as these local views often contain sensitive information. In this paper, we seek to ensure private graph learning on a decentralized network graph. Towards this objective, we propose {\em Solitude}, a new privacy-preserving learning framework based on graph neural networks (GNNs), with formal privacy guarantees based on edge local differential privacy. The crux of {\em Solitude} is a set of new delicate mechanisms that can calibrate the introduced noise in the decentralized graph collected from the users. The principle behind the calibration is the intrinsic properties shared by many real-world graphs, such as sparsity. Unlike existing work on locally private GNNs, our new framework can simultaneously protect node feature privacy and edge privacy, and can seamlessly incorporate with any GNN with privacy-utility guarantees. Extensive experiments on benchmarking datasets show that {\em Solitude} can retain the generalization capability of the learned GNN while preserving the users' data privacy under given privacy budgets.