 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fast Fair Regression via Efficient Approximations of Mutual Information
Feb 14, 2020
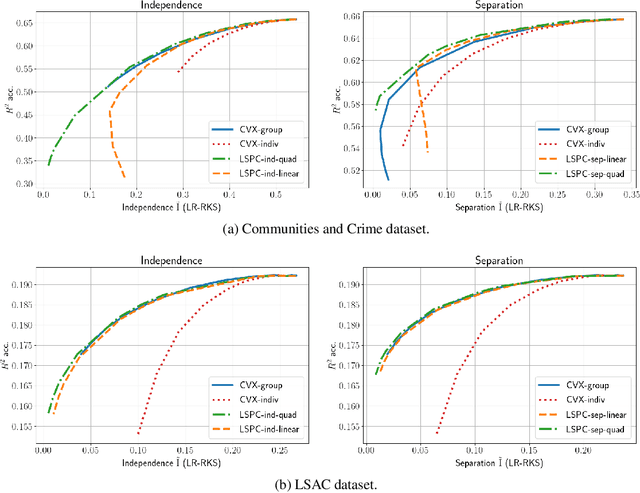
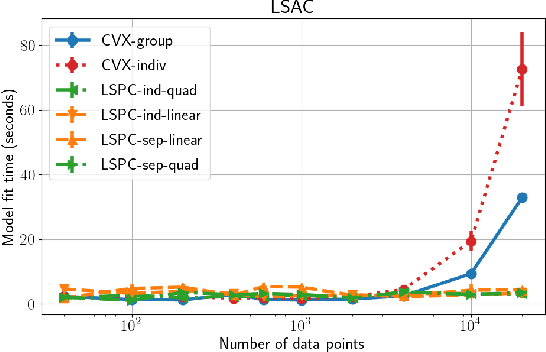
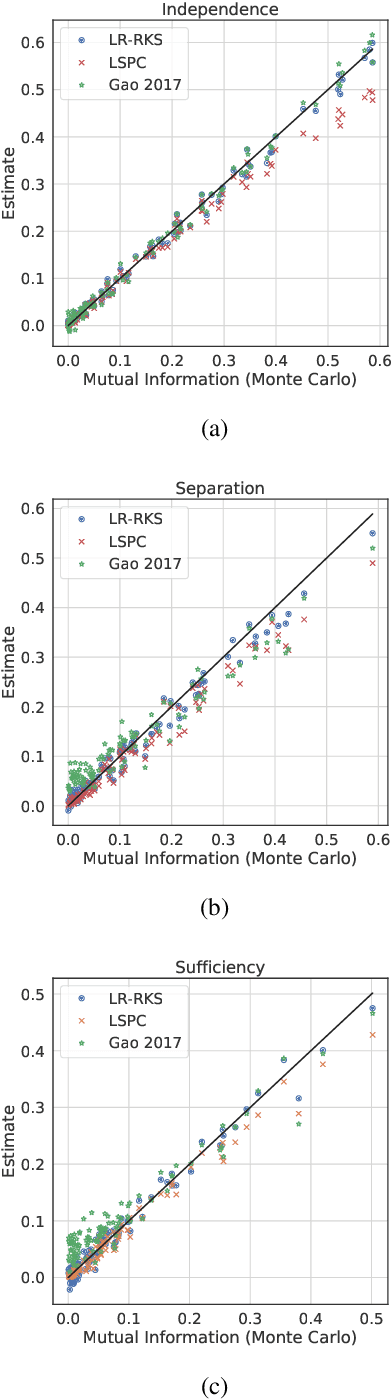
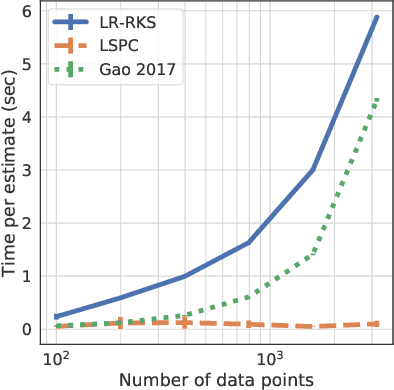
Most work in algorithmic fairness to date has focused on discrete outcomes, such as deciding whether to grant someone a loan or not. In these classification settings, group fairness criteria such as independence, separation and sufficiency can be measured directly by comparing rates of outcomes between subpopulations. Many important problems however require the prediction of a real-valued outcome, such as a risk score or insurance premium. In such regression settings, measuring group fairness criteria is computationally challenging, as it requires estimating information-theoretic divergences between conditional probability density functions. This paper introduces fast approximations of the independence, separation and sufficiency group fairness criteria for regression models from their (conditional) mutual information definitions, and uses such approximations as regularisers to enforce fairness within a regularised risk minimisation framework. Experiments in real-world datasets indicate that in spite of its superior computational efficiency our algorithm still displays state-of-the-art accuracy/fairness tradeoffs.
CO2Sum:Contrastive Learning for Factual-Consistent Abstractive Summarization
Dec 02, 2021
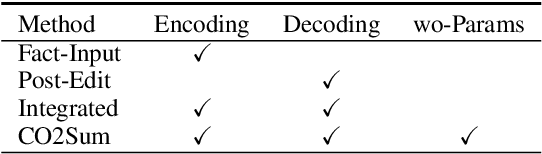
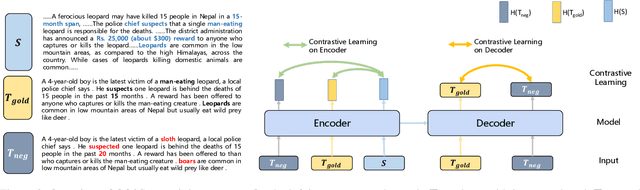
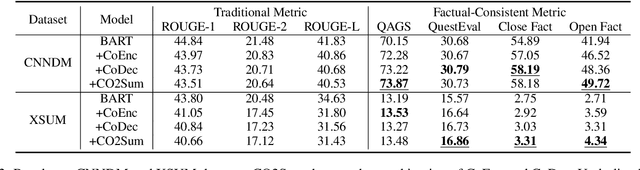
Generating factual-consistent summaries is a challenging task for abstractive summarization. Previous works mainly encode factual information or perform post-correct/rank after decoding. In this paper, we provide a factual-consistent solution from the perspective of contrastive learning, which is a natural extension of previous works. We propose CO2Sum (Contrastive for Consistency), a contrastive learning scheme that can be easily applied on sequence-to-sequence models for factual-consistent abstractive summarization, proving that the model can be fact-aware without modifying the architecture. CO2Sum applies contrastive learning on the encoder, which can help the model be aware of the factual information contained in the input article, or performs contrastive learning on the decoder, which makes the model to generate factual-correct output summary. What's more, these two schemes are orthogonal and can be combined to further improve faithfulness. Comprehensive experiments on public benchmarks demonstrate that CO2Sum improves the faithfulness on large pre-trained language models and reaches competitive results compared to other strong factual-consistent summarization baselines.
FUN-SIS: a Fully UNsupervised approach for Surgical Instrument Segmentation
Feb 16, 2022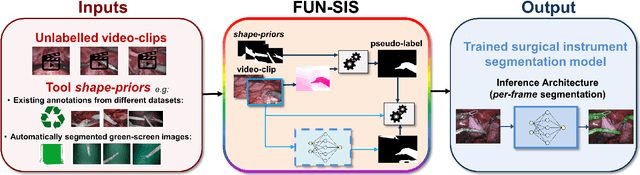
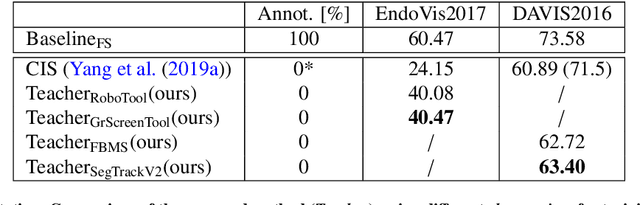
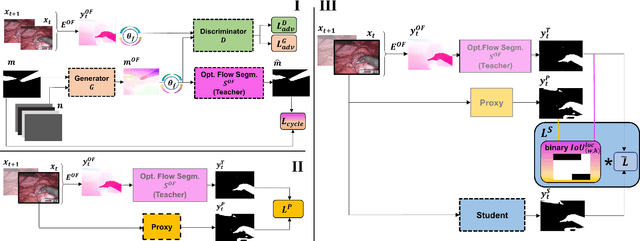
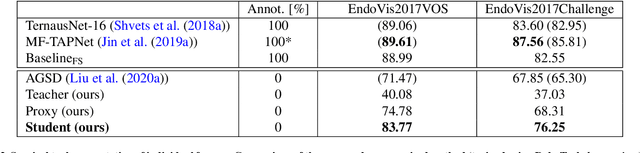
Automatic surgical instrument segmentation of endoscopic images is a crucial building block of many computer-assistance applications for minimally invasive surgery. So far, state-of-the-art approaches completely rely on the availability of a ground-truth supervision signal, obtained via manual annotation, thus expensive to collect at large scale. In this paper, we present FUN-SIS, a Fully-UNsupervised approach for binary Surgical Instrument Segmentation. FUN-SIS trains a per-frame segmentation model on completely unlabelled endoscopic videos, by solely relying on implicit motion information and instrument shape-priors. We define shape-priors as realistic segmentation masks of the instruments, not necessarily coming from the same dataset/domain as the videos. The shape-priors can be collected in various and convenient ways, such as recycling existing annotations from other datasets. We leverage them as part of a novel generative-adversarial approach, allowing to perform unsupervised instrument segmentation of optical-flow images during training. We then use the obtained instrument masks as pseudo-labels in order to train a per-frame segmentation model; to this aim, we develop a learning-from-noisy-labels architecture, designed to extract a clean supervision signal from these pseudo-labels, leveraging their peculiar noise properties. We validate the proposed contributions on three surgical datasets, including the MICCAI 2017 EndoVis Robotic Instrument Segmentation Challenge dataset. The obtained fully-unsupervised results for surgical instrument segmentation are almost on par with the ones of fully-supervised state-of-the-art approaches. This suggests the tremendous potential of the proposed method to leverage the great amount of unlabelled data produced in the context of minimally invasive surgery.
Modeling Multi-granularity User Intent Evolving via Heterogeneous Graph Neural Networks for Session-based Recommendation
Dec 25, 2021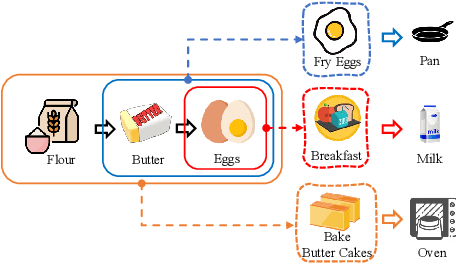
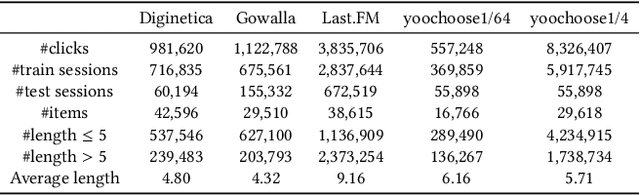
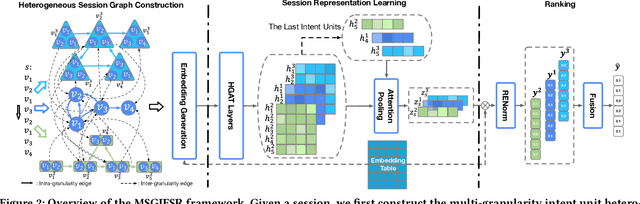
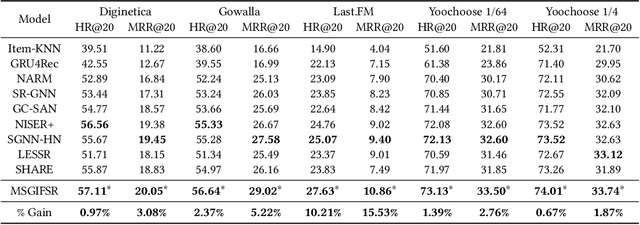
Session-based recommendation aims to predict a user's next action based on previous actions in the current session. The major challenge is to capture authentic and complete user preferences in the entire session. Recent work utilizes graph structure to represent the entire session and adopts Graph Neural Network to encode session information. This modeling choice has been proved to be effective and achieved remarkable results. However, most of the existing studies only consider each item within the session independently and do not capture session semantics from a high-level perspective. Such limitation often leads to severe information loss and increases the difficulty of capturing long-range dependencies within a session. Intuitively, compared with individual items, a session snippet, i.e., a group of locally consecutive items, is able to provide supplemental user intents which are hardly captured by existing methods. In this work, we propose to learn multi-granularity consecutive user intent unit to improve the recommendation performance. Specifically, we creatively propose Multi-granularity Intent Heterogeneous Session Graph which captures the interactions between different granularity intent units and relieves the burden of long-dependency. Moreover, we propose the Intent Fusion Ranking module to compose the recommendation results from various granularity user intents. Compared with current methods that only leverage intents from individual items, IFR benefits from different granularity user intents to generate more accurate and comprehensive session representation, thus eventually boosting recommendation performance. We conduct extensive experiments on five session-based recommendation datasets and the results demonstrate the effectiveness of our method.
A survey of unsupervised learning methods for high-dimensional uncertainty quantification in black-box-type problems
Feb 09, 2022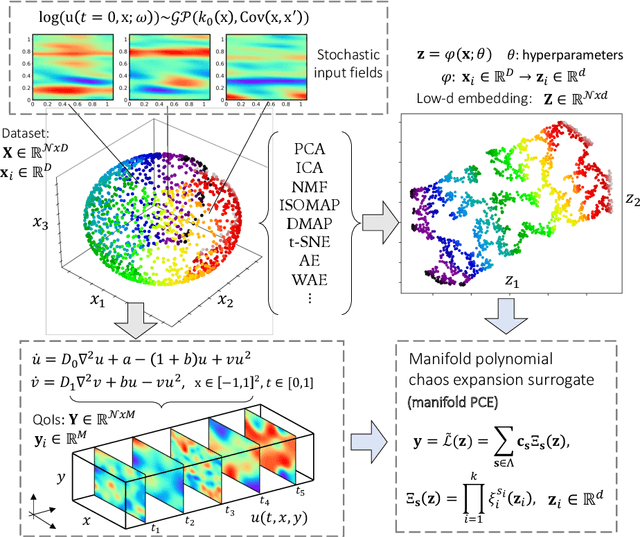
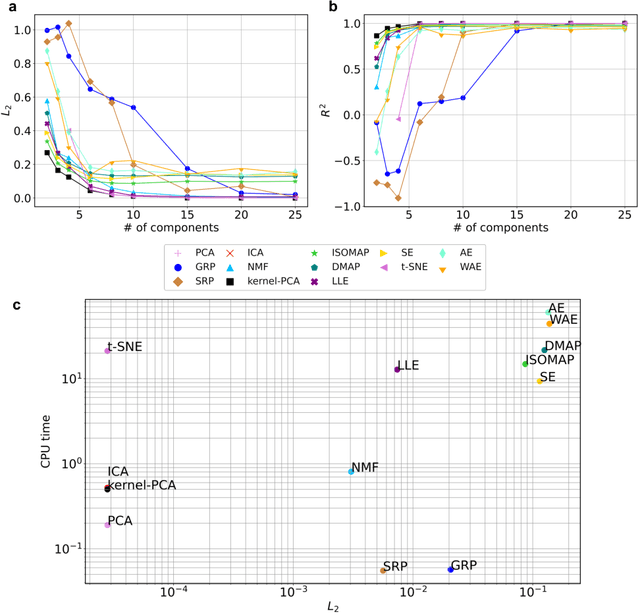
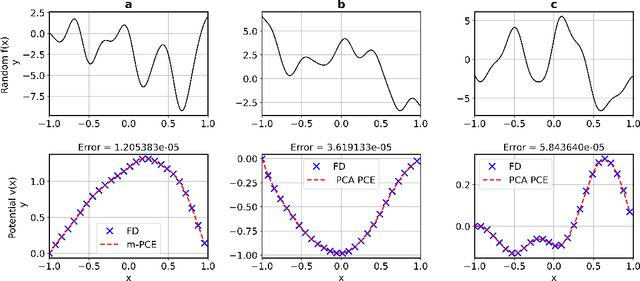
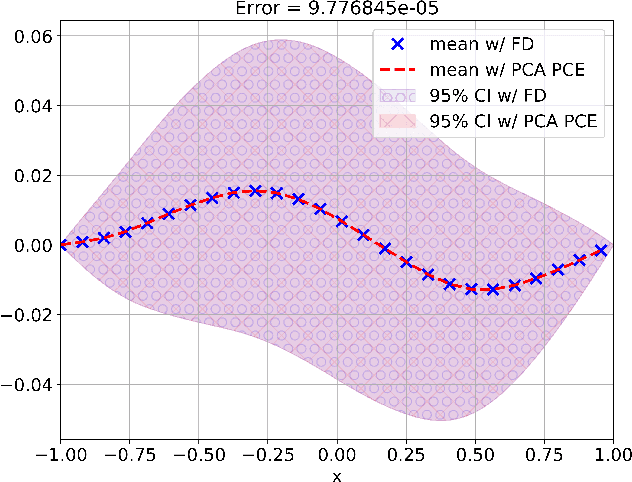
Constructing surrogate models for uncertainty quantification (UQ) on complex partial differential equations (PDEs) having inherently high-dimensional $\mathcal{O}(10^{\ge 2})$ stochastic inputs (e.g., forcing terms, boundary conditions, initial conditions) poses tremendous challenges. The curse of dimensionality can be addressed with suitable unsupervised learning techniques used as a pre-processing tool to encode inputs onto lower-dimensional subspaces while retaining its structural information and meaningful properties. In this work, we review and investigate thirteen dimension reduction methods including linear and nonlinear, spectral, blind source separation, convex and non-convex methods and utilize the resulting embeddings to construct a mapping to quantities of interest via polynomial chaos expansions (PCE). We refer to the general proposed approach as manifold PCE (m-PCE), where manifold corresponds to the latent space resulting from any of the studied dimension reduction methods. To investigate the capabilities and limitations of these methods we conduct numerical tests for three physics-based systems (treated as black-boxes) having high-dimensional stochastic inputs of varying complexity modeled as both Gaussian and non-Gaussian random fields to investigate the effect of the intrinsic dimensionality of input data. We demonstrate both the advantages and limitations of the unsupervised learning methods and we conclude that a suitable m-PCE model provides a cost-effective approach compared to alternative algorithms proposed in the literature, including recently proposed expensive deep neural network-based surrogates and can be readily applied for high-dimensional UQ in stochastic PDEs.
Spectrally Adaptive Common Spatial Patterns
Feb 09, 2022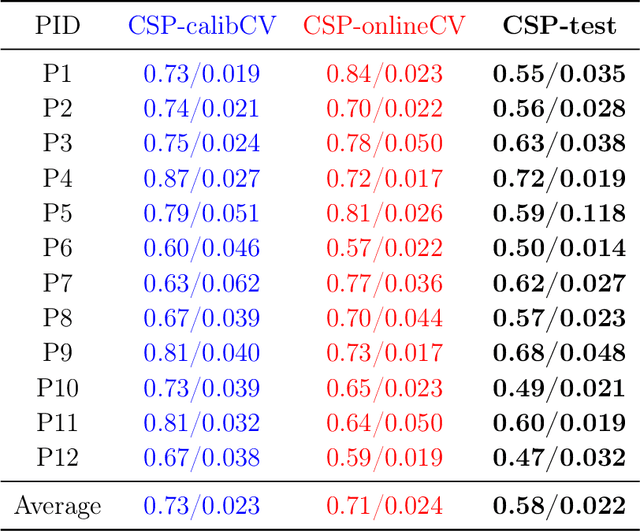
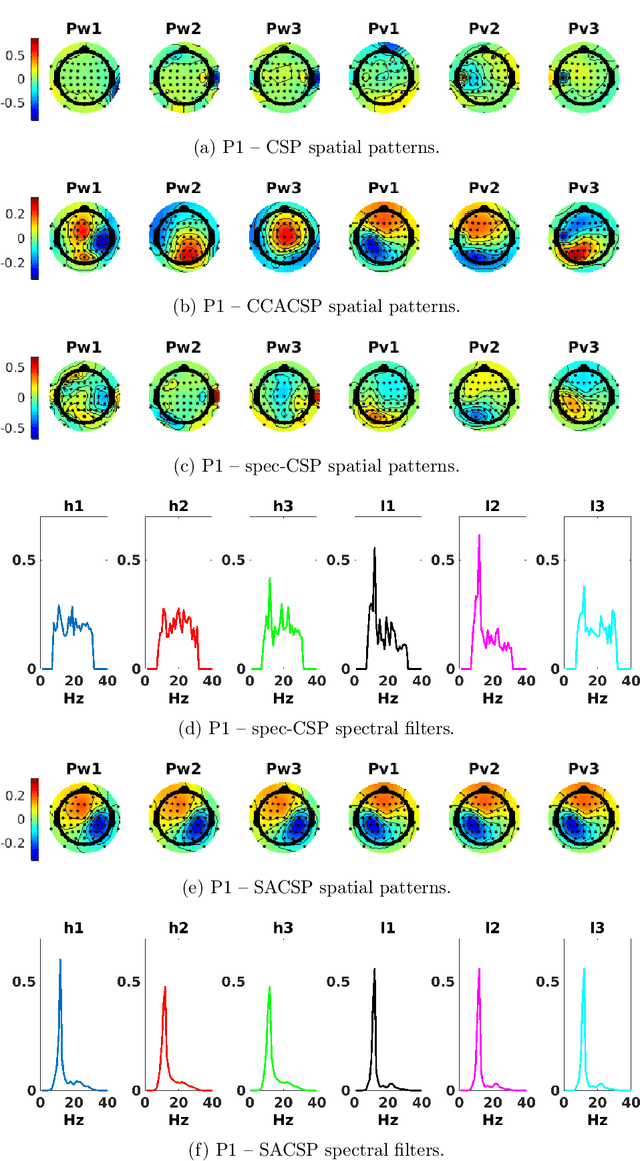
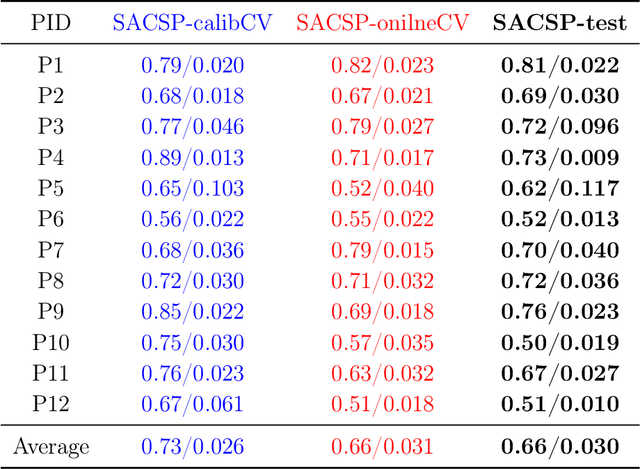
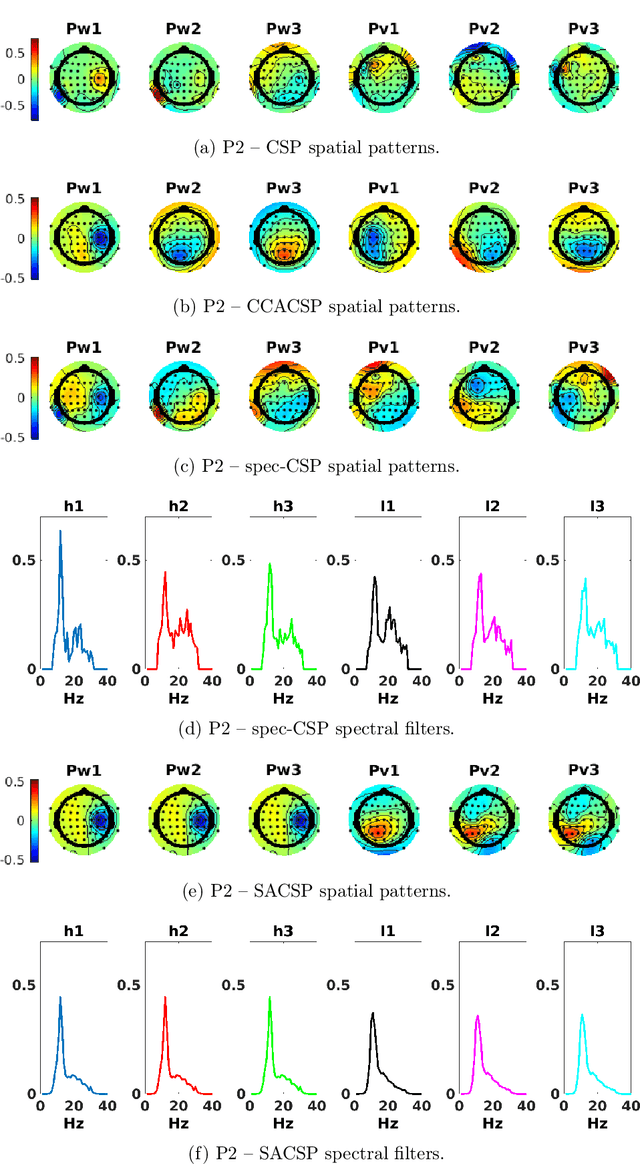
The method of Common Spatial Patterns (CSP) is widely used for feature extraction of electroencephalography (EEG) data, such as in motor imagery brain-computer interface (BCI) systems. It is a data-driven method estimating a set of spatial filters so that the power of the filtered EEG signal is maximized for one motor imagery class and minimized for the other. This method, however, is prone to overfitting and is known to suffer from poor generalization especially with limited calibration data. Additionally, due to the high heterogeneity in brain data and the non-stationarity of brain activity, CSP is usually trained for each user separately resulting in long calibration sessions or frequent re-calibrations that are tiring for the user. In this work, we propose a novel algorithm called Spectrally Adaptive Common Spatial Patterns (SACSP) that improves CSP by learning a temporal/spectral filter for each spatial filter so that the spatial filters are concentrated on the most relevant temporal frequencies for each user. We show the efficacy of SACSP in providing better generalizability and higher classification accuracy from calibration to online control compared to existing methods. Furthermore, we show that SACSP provides neurophysiologically relevant information about the temporal frequencies of the filtered signals. Our results highlight the differences in the motor imagery signal among BCI users as well as spectral differences in the signals generated for each class, and show the importance of learning robust user-specific features in a data-driven manner.
The Efficiency of Human Cognition Reflects Planned Information Processing
Feb 13, 2020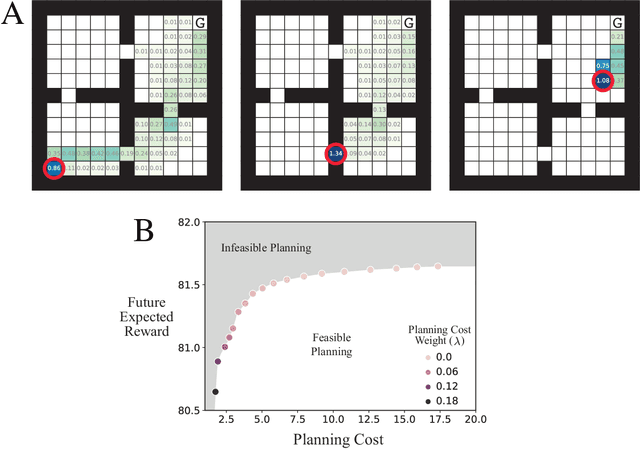
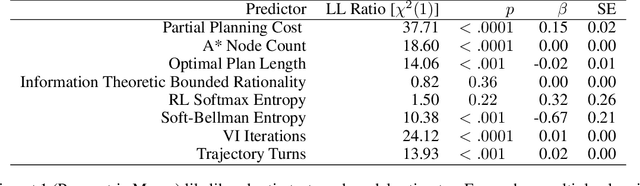
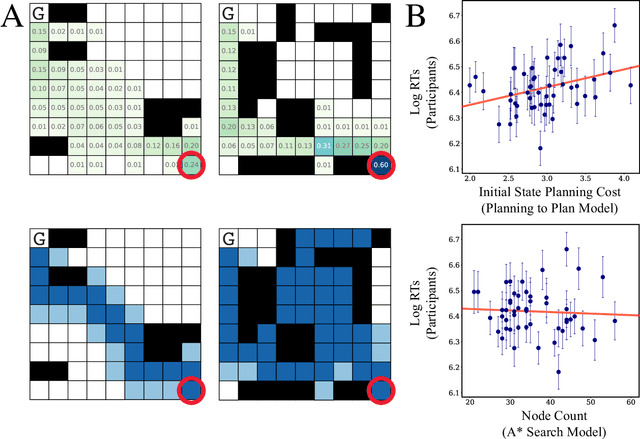

Planning is useful. It lets people take actions that have desirable long-term consequences. But, planning is hard. It requires thinking about consequences, which consumes limited computational and cognitive resources. Thus, people should plan their actions, but they should also be smart about how they deploy resources used for planning their actions. Put another way, people should also "plan their plans". Here, we formulate this aspect of planning as a meta-reasoning problem and formalize it in terms of a recursive Bellman objective that incorporates both task rewards and information-theoretic planning costs. Our account makes quantitative predictions about how people should plan and meta-plan as a function of the overall structure of a task, which we test in two experiments with human participants. We find that people's reaction times reflect a planned use of information processing, consistent with our account. This formulation of planning to plan provides new insight into the function of hierarchical planning, state abstraction, and cognitive control in both humans and machines.
FacTeR-Check: Semi-automated fact-checking through Semantic Similarity and Natural Language Inference
Oct 27, 2021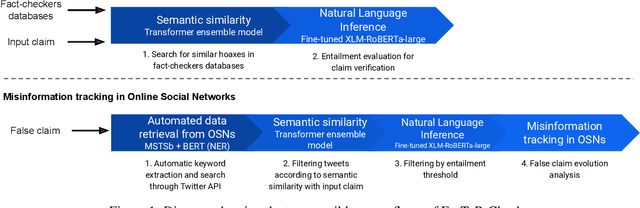
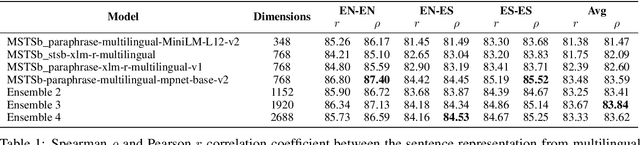

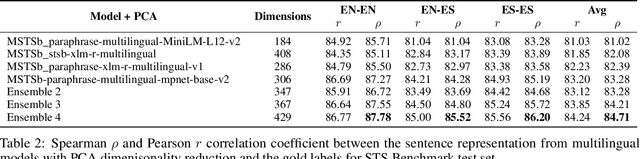
Our society produces and shares overwhelming amounts of information through the Online Social Networks (OSNs). Within this environment, misinformation and disinformation have proliferated, becoming a public safety concern on every country. Allowing the public and professionals to efficiently find reliable evidence about the factual veracity of a claim is crucial to mitigate this harmful spread. To this end, we propose FacTeR-Check, a multilingual architecture for semi-automated fact-checking that can be used for either the general public but also useful for fact-checking organisations. FacTeR-Check enables retrieving fact-checked information, unchecked claims verification and tracking dangerous information over social media. This architectures involves several modules developed to evaluate semantic similarity, to calculate natural language inference and to retrieve information from Online Social Networks. The union of all these modules builds a semi-automated fact-checking tool able of verifying new claims, to extract related evidence, and to track the evolution of a hoax on a OSN. While individual modules are validated on related benchmarks (mainly MSTS and SICK), the complete architecture is validated using a new dataset called NLI19-SP that is publicly released with COVID-19 related hoaxes and tweets from Spanish social media. Our results show state-of-the-art performance on the individual benchmarks, as well as producing useful analysis of the evolution over time of 61 different hoaxes.
Graph Tree Neural Networks
Oct 31, 2021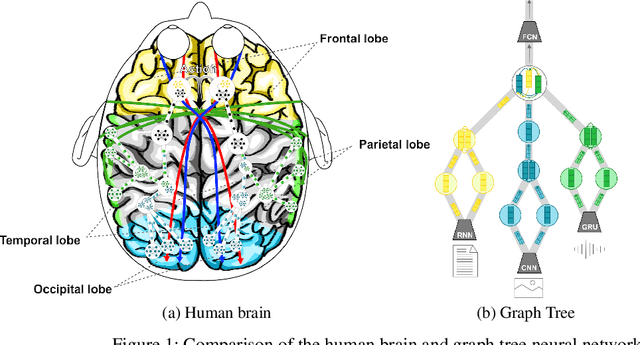
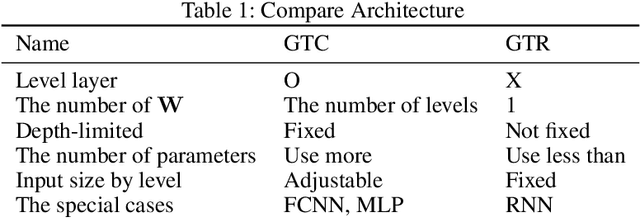
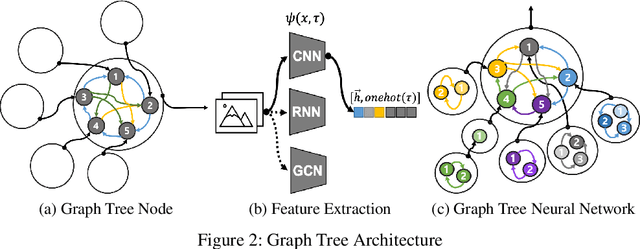
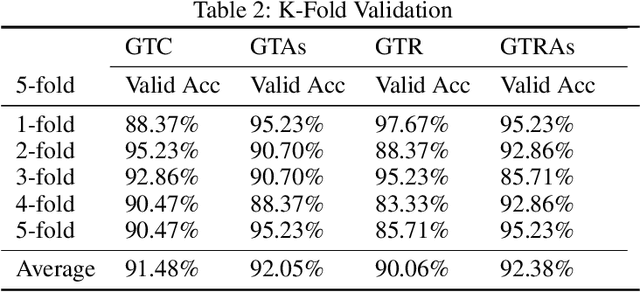
Graph neural networks (GNNs) have recently shown good performance in various fields. In this paper, we propose graph tree neural networks (GTNNs) designed to solve the problems of existing networks by analyzing the structure of human neural networks. In GTNNs, information units are related to the form of a graph and then they become a bigger unit of information again and have a relationship with other information units. At this point, the unit of information is a set of neurons, and we can express it as a vector with GTNN. Defining the starting and ending points in a single graph is difficult, and a tree cannot express the relationship among sibling nodes. However, a graph tree can be expressed using leaf and root nodes as its starting and ending points and the relationship among sibling nodes. Depth-first convolution (DFC) encodes the interaction result from leaf nodes to the root node in a bottom-up approach, and depth-first deconvolution (DFD) decodes the interaction result from the root node to the leaf nodes in a top-down approach. GTNN is data-driven learning in which the number of convolutions varies according to the depth of the tree. Moreover, learning features of different types together is possible. Supervised, unsupervised, and semi-supervised learning using graph tree recursive neural network (GTR) , graph tree recursive attention networks (GTRAs), and graph tree recursive autoencoders (GTRAEs) are introduced in this paper. We experimented with a simple toy test with source code dataset.
A Heterogeneous Graph Learning Model for Cyber-Attack Detection
Dec 16, 2021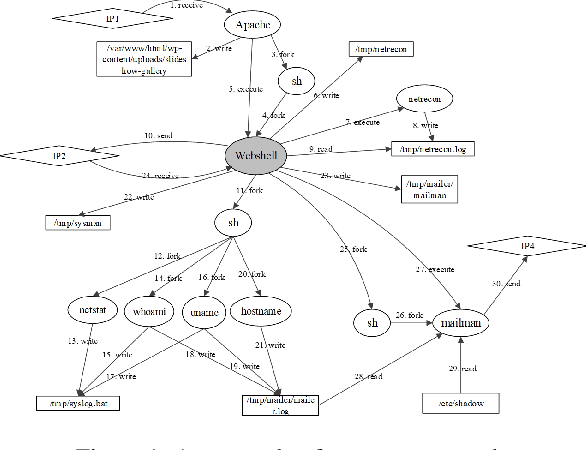

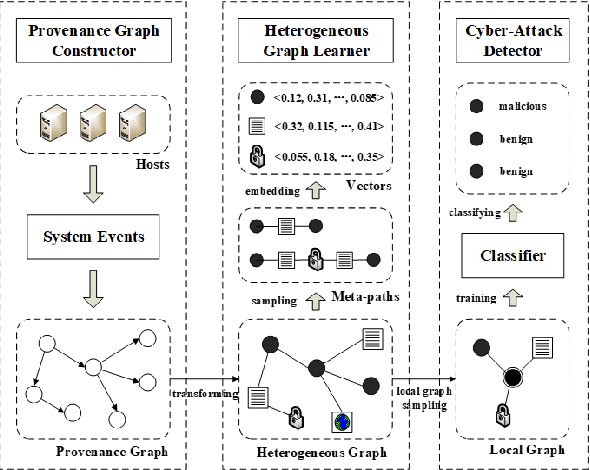

A cyber-attack is a malicious attempt by experienced hackers to breach the target information system. Usually, the cyber-attacks are characterized as hybrid TTPs (Tactics, Techniques, and Procedures) and long-term adversarial behaviors, making the traditional intrusion detection methods ineffective. Most existing cyber-attack detection systems are implemented based on manually designed rules by referring to domain knowledge (e.g., threat models, threat intelligences). However, this process is lack of intelligence and generalization ability. Aiming at this limitation, this paper proposes an intelligent cyber-attack detection method based on provenance data. To effective and efficient detect cyber-attacks from a huge number of system events in the provenance data, we firstly model the provenance data by a heterogeneous graph to capture the rich context information of each system entities (e.g., process, file, socket, etc.), and learns a semantic vector representation for each system entity. Then, we perform online cyber-attack detection by sampling a small and compact local graph from the heterogeneous graph, and classifying the key system entities as malicious or benign. We conducted a series of experiments on two provenance datasets with real cyber-attacks. The experiment results show that the proposed method outperforms other learning based detection models, and has competitive performance against state-of-the-art rule based cyber-attack detection systems.