 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Quantifying Layerwise Information Discarding of Neural Networks
Jun 10, 2019
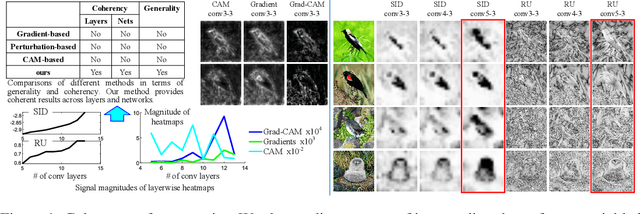
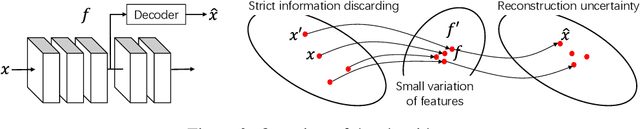

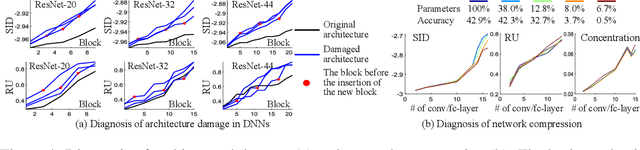
This paper presents a method to explain how input information is discarded through intermediate layers of a neural network during the forward propagation, in order to quantify and diagnose knowledge representations of pre-trained deep neural networks. We define two types of entropy-based metrics, i.e., the strict information discarding and the reconstruction uncertainty, which measure input information of a specific layer from two perspectives. We develop a method to enable efficient computation of such entropy-based metrics. Our method can be broadly applied to various neural networks and enable comprehensive comparisons between different layers of different networks. Preliminary experiments have shown the effectiveness of our metrics in analyzing benchmark networks and explaining existing deep-learning techniques.
Relevance Vector Machine with Weakly Informative Hyperprior and Extended Predictive Information Criterion
May 07, 2020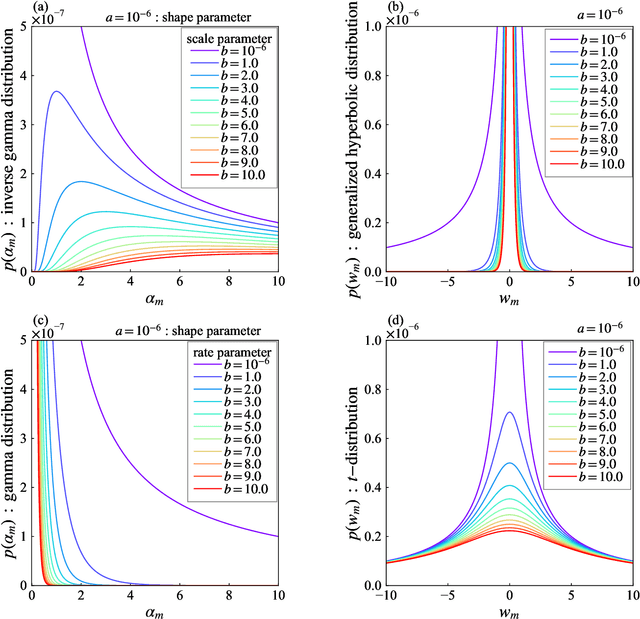
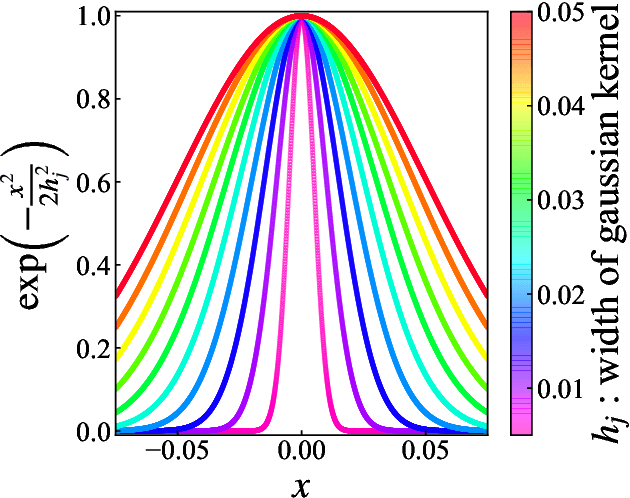
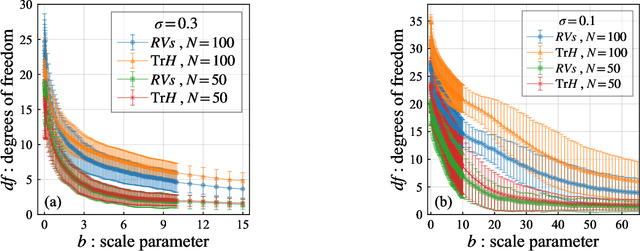
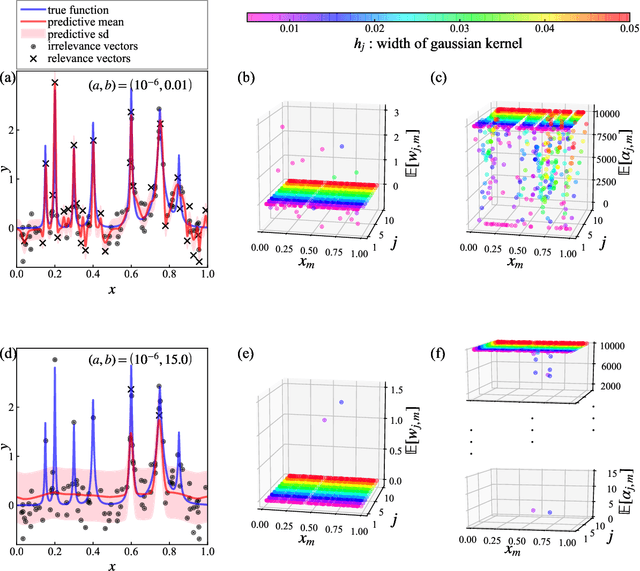
In the variational relevance vector machine, the gamma distribution is representative as a hyperprior over the noise precision of automatic relevance determination prior. Instead of the gamma hyperprior, we propose to use the inverse gamma hyperprior with a shape parameter close to zero and a scale parameter not necessary close to zero. This hyperprior is associated with the concept of a weakly informative prior. The effect of this hyperprior is investigated through regression to non-homogeneous data. Because it is difficult to capture the structure of such data with a single kernel function, we apply the multiple kernel method, in which multiple kernel functions with different widths are arranged for input data. We confirm that the degrees of freedom in a model is controlled by adjusting the scale parameter and keeping the shape parameter close to zero. A candidate for selecting the scale parameter is the predictive information criterion. However the estimated model using this criterion seems to cause over-fitting. This is because the multiple kernel method makes the model a situation where the dimension of the model is larger than the data size. To select an appropriate scale parameter even in such a situation, we also propose an extended prediction information criterion. It is confirmed that a multiple kernel relevance vector regression model with good predictive accuracy can be obtained by selecting the scale parameter minimizing extended prediction information criterion.
Decoupling Visual-Semantic Feature Learning for Robust Scene Text Recognition
Nov 24, 2021
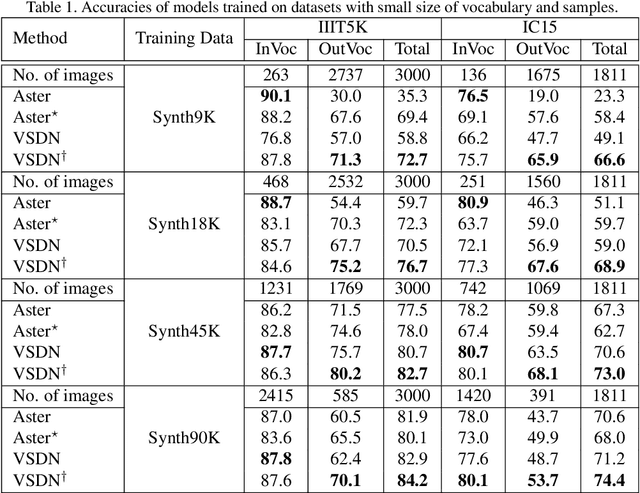
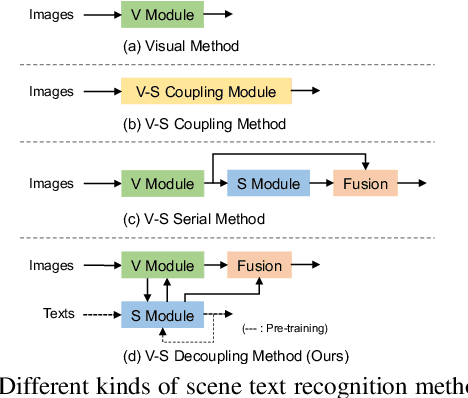
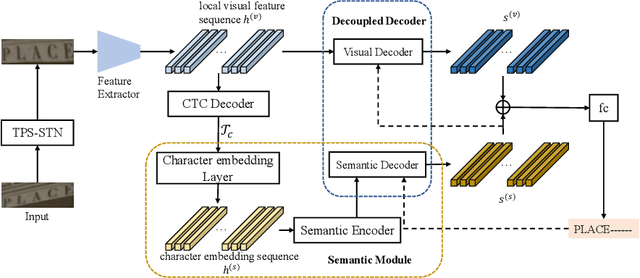
Semantic information has been proved effective in scene text recognition. Most existing methods tend to couple both visual and semantic information in an attention-based decoder. As a result, the learning of semantic features is prone to have a bias on the limited vocabulary of the training set, which is called vocabulary reliance. In this paper, we propose a novel Visual-Semantic Decoupling Network (VSDN) to address the problem. Our VSDN contains a Visual Decoder (VD) and a Semantic Decoder (SD) to learn purer visual and semantic feature representation respectively. Besides, a Semantic Encoder (SE) is designed to match SD, which can be pre-trained together by additional inexpensive large vocabulary via a simple word correction task. Thus the semantic feature is more unbiased and precise to guide the visual feature alignment and enrich the final character representation. Experiments show that our method achieves state-of-the-art or competitive results on the standard benchmarks, and outperforms the popular baseline by a large margin under circumstances where the training set has a small size of vocabulary.
Big Data Application for Network Level Travel Time Prediction
Jan 15, 2022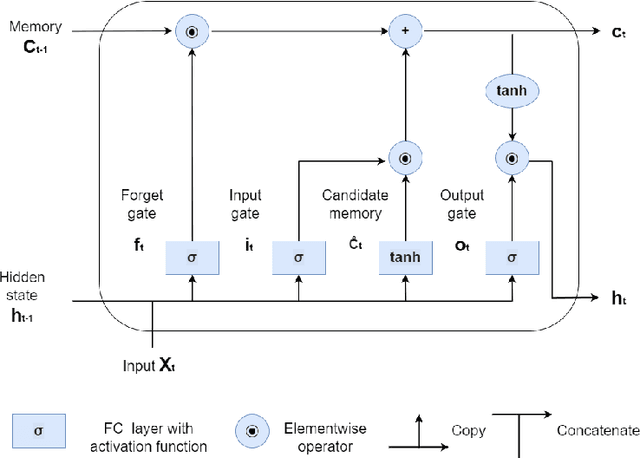
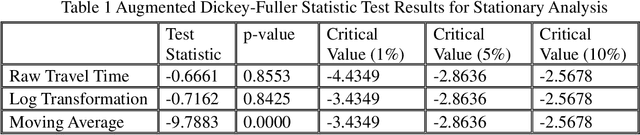
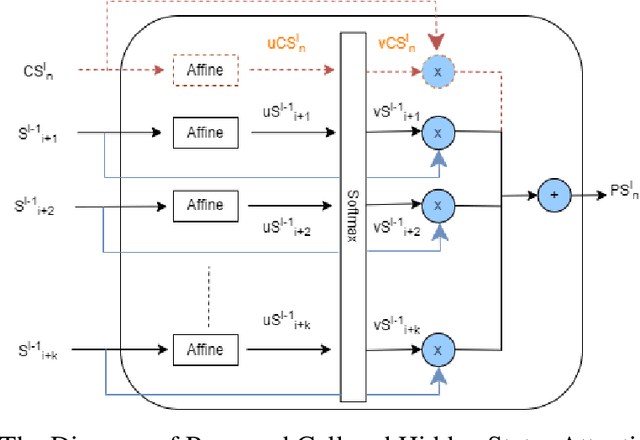
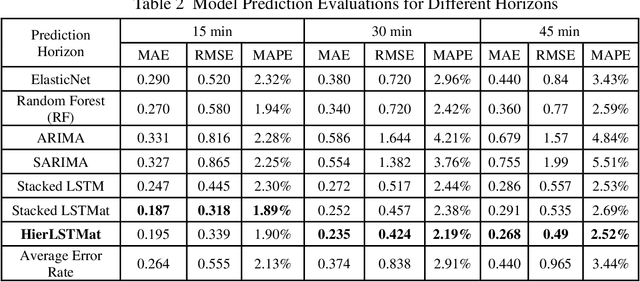
Travel time is essential in advanced traveler information systems (ATIS). This paper used the big data analytics engines Apache Spark and Apache MXNet for data processing and modeling. The efficiency gain was evaluated by comparing it with popular data science and deep learning frameworks. The hierarchical feature pooling is explored for both between layer and the output layer LSTM (Long-Short-Term-Memory). The designed hierarchical LSTM (hiLSTM) model can consider the dependencies at a different time scale to capture the spatial-temporal correlations from network-level corridor travel time. A self-attention module is then used to connect temporal and spatial features to the fully connected layers, predicting travel time for all corridors instead of a single link/route. Seasonality and autocorrelation were performed to explore the trend of time-varying data. The case study shows that the Hierarchical LSTM with Attention (hiLSTMat) model gives the best result and outperforms baseline models. The California Bay Area corridor travel time dataset covering four-year periods was published from Caltrans Performance Measurement System (PeMS) system.
Order Matters: Matching Multiple Knowledge Graphs
Nov 03, 2021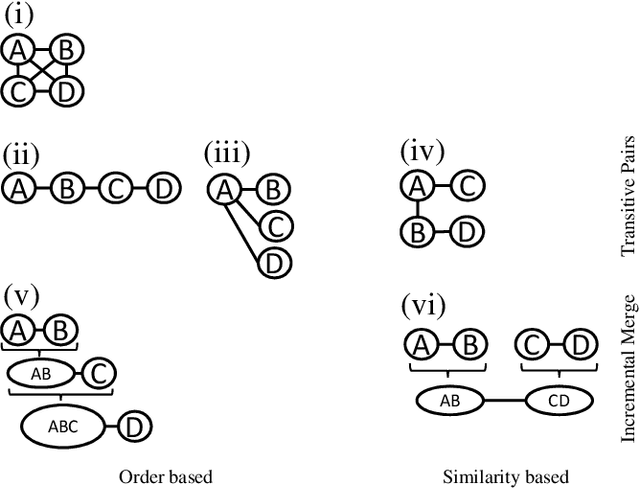
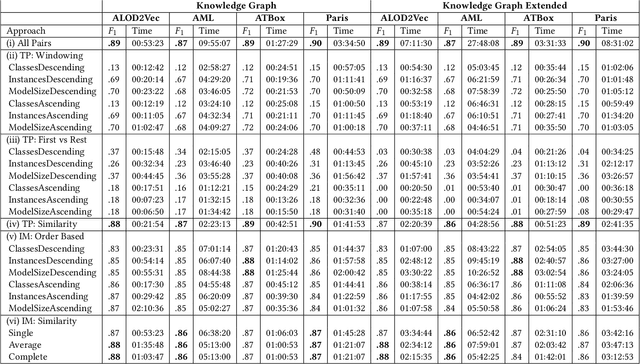
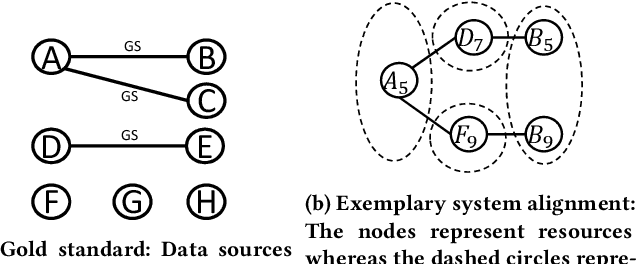
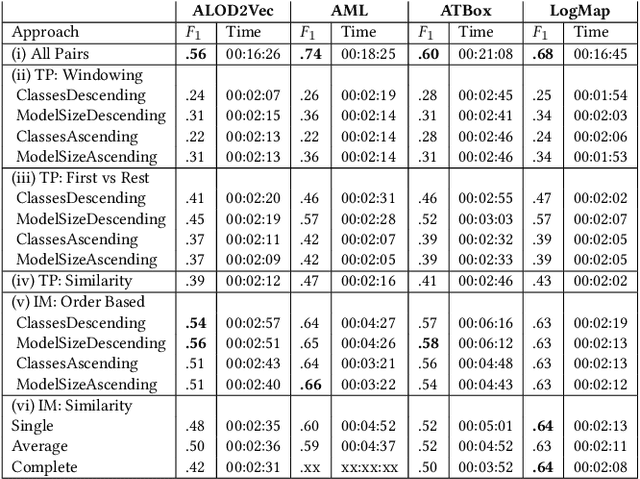
Knowledge graphs (KGs) provide information in machine interpretable form. In cases where multiple KGs are used in the same system, that information needs to be integrated. This is usually done by automated matching systems. Most of those systems consider only 1:1 (binary) matching tasks. Thus, matching a larger number of knowledge graphs with such systems would lead to quadratic efforts. In this paper, we empirically analyze different approaches to reduce the task of multi-source matching to a linear number of executions of binary matching systems. We show that the matching order of KGs and the multi-source strategy actually matter and that near-optimal results can be achieved with linear efforts.
Communication-Efficient Device Scheduling for Federated Learning Using Stochastic Optimization
Jan 19, 2022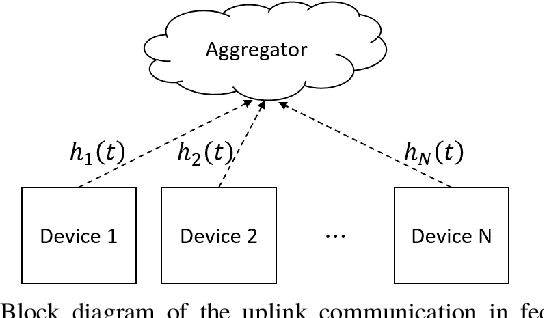
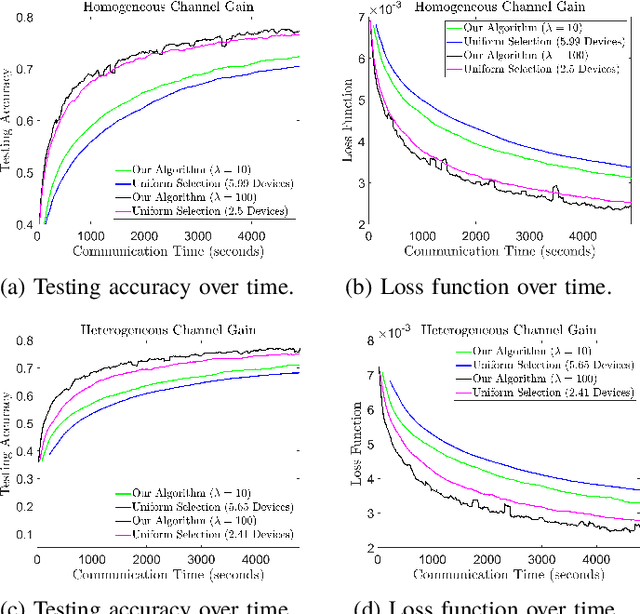
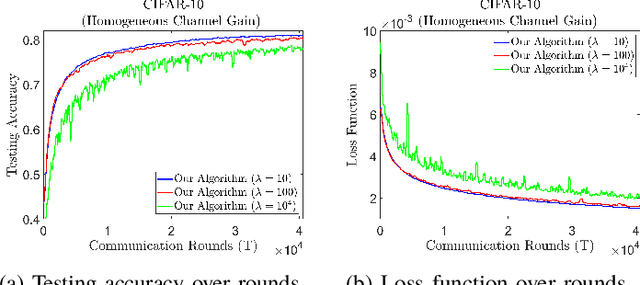
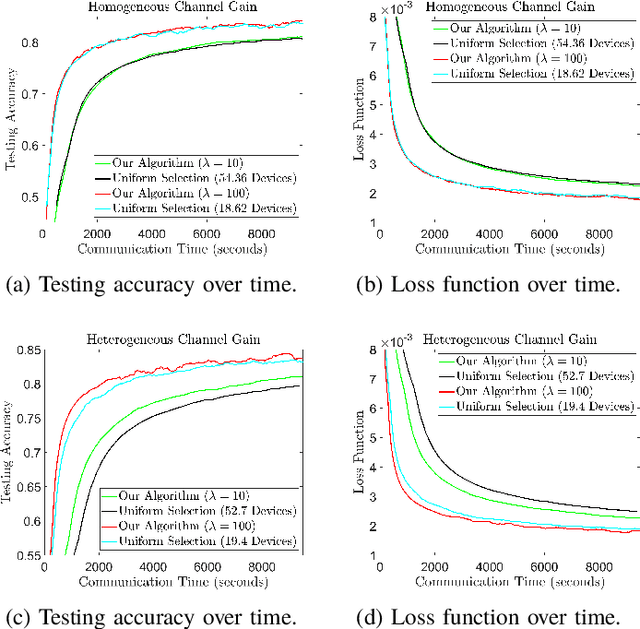
Federated learning (FL) is a useful tool in distributed machine learning that utilizes users' local datasets in a privacy-preserving manner. When deploying FL in a constrained wireless environment; however, training models in a time-efficient manner can be a challenging task due to intermittent connectivity of devices, heterogeneous connection quality, and non-i.i.d. data. In this paper, we provide a novel convergence analysis of non-convex loss functions using FL on both i.i.d. and non-i.i.d. datasets with arbitrary device selection probabilities for each round. Then, using the derived convergence bound, we use stochastic optimization to develop a new client selection and power allocation algorithm that minimizes a function of the convergence bound and the average communication time under a transmit power constraint. We find an analytical solution to the minimization problem. One key feature of the algorithm is that knowledge of the channel statistics is not required and only the instantaneous channel state information needs to be known. Using the FEMNIST and CIFAR-10 datasets, we show through simulations that the communication time can be significantly decreased using our algorithm, compared to uniformly random participation.
Shuffle Private Linear Contextual Bandits
Feb 11, 2022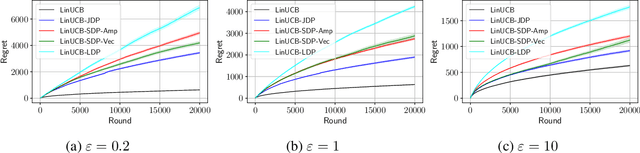
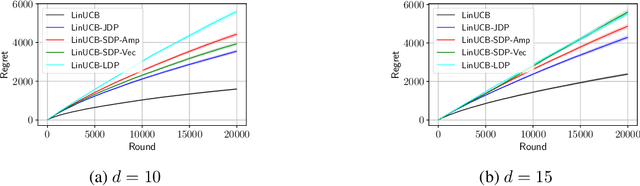
Differential privacy (DP) has been recently introduced to linear contextual bandits to formally address the privacy concerns in its associated personalized services to participating users (e.g., recommendations). Prior work largely focus on two trust models of DP: the central model, where a central server is responsible for protecting users sensitive data, and the (stronger) local model, where information needs to be protected directly on user side. However, there remains a fundamental gap in the utility achieved by learning algorithms under these two privacy models, e.g., $\tilde{O}(\sqrt{T})$ regret in the central model as compared to $\tilde{O}(T^{3/4})$ regret in the local model, if all users are unique within a learning horizon $T$. In this work, we aim to achieve a stronger model of trust than the central model, while suffering a smaller regret than the local model by considering recently popular shuffle model of privacy. We propose a general algorithmic framework for linear contextual bandits under the shuffle trust model, where there exists a trusted shuffler in between users and the central server, that randomly permutes a batch of users data before sending those to the server. We then instantiate this framework with two specific shuffle protocols: one relying on privacy amplification of local mechanisms, and another incorporating a protocol for summing vectors and matrices of bounded norms. We prove that both these instantiations lead to regret guarantees that significantly improve on that of the local model, and can potentially be of the order $\tilde{O}(T^{3/5})$ if all users are unique. We also verify this regret behavior with simulations on synthetic data. Finally, under the practical scenario of non-unique users, we show that the regret of our shuffle private algorithm scale as $\tilde{O}(T^{2/3})$, which matches that the central model could achieve in this case.
SequentialPointNet: A strong parallelized point cloud sequence network for 3D action recognition
Nov 16, 2021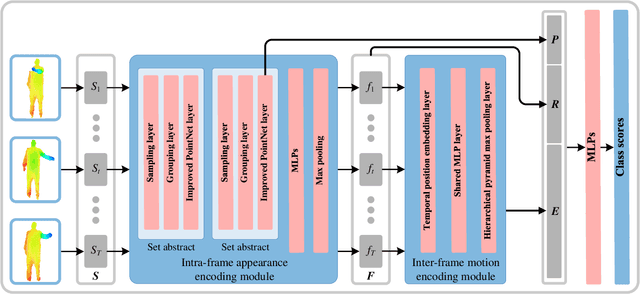
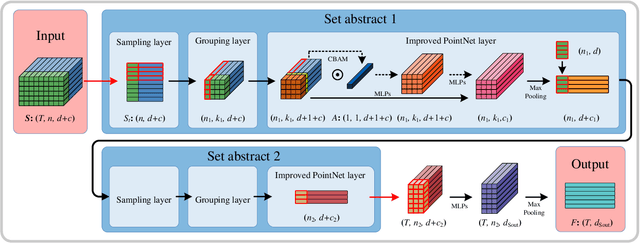
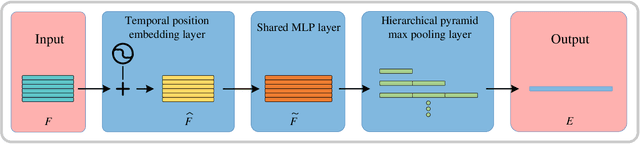
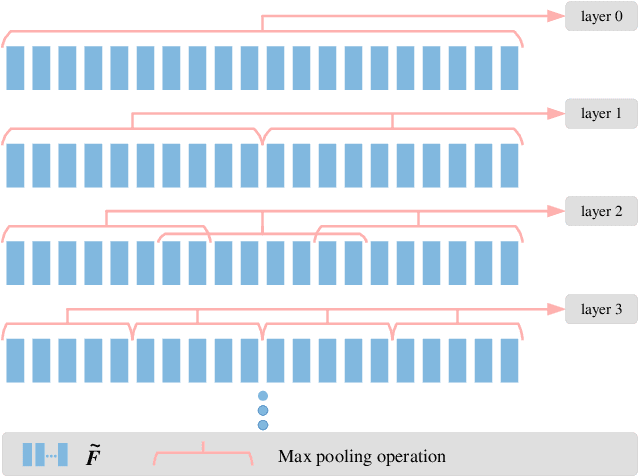
Point cloud sequences of 3D human actions exhibit unordered intra-frame spatial information and ordered interframe temporal information. In order to capture the spatiotemporal structures of the point cloud sequences, cross-frame spatio-temporal local neighborhoods around the centroids are usually constructed. However, the computationally expensive construction procedure of spatio-temporal local neighborhoods severely limits the parallelism of models. Moreover, it is unreasonable to treat spatial and temporal information equally in spatio-temporal local learning, because human actions are complicated along the spatial dimensions and simple along the temporal dimension. In this paper, to avoid spatio-temporal local encoding, we propose a strong parallelized point cloud sequence network referred to as SequentialPointNet for 3D action recognition. SequentialPointNet is composed of two serial modules, i.e., an intra-frame appearance encoding module and an inter-frame motion encoding module. For modeling the strong spatial structures of human actions, each point cloud frame is processed in parallel in the intra-frame appearance encoding module and the feature vector of each frame is output to form a feature vector sequence that characterizes static appearance changes along the temporal dimension. For modeling the weak temporal changes of human actions, in the inter-frame motion encoding module, the temporal position encoding and the hierarchical pyramid pooling strategy are implemented on the feature vector sequence. In addition, in order to better explore spatio-temporal content, multiple level features of human movements are aggregated before performing the end-to-end 3D action recognition. Extensive experiments conducted on three public datasets show that SequentialPointNet outperforms stateof-the-art approaches.
Machine Learning using the Variational Predictive Information Bottleneck with a Validation Set
Nov 06, 2019Zellner (1988) modeled statistical inference in terms of information processing and postulated the Information Conservation Principle (ICP) between the input and output of the information processing block, showing that this yielded Bayesian inference as the optimum information processing rule. Recently, Alemi (2019) reviewed Zellner's work in the context of machine learning and showed that the ICP could be seen as a special case of a more general optimum information processing criterion, namely the Predictive Information Bottleneck Objective. However, Alemi modeled the model training step in machine learning as using training and test data sets only, and did not account for the use of a validation data set during training. The present note is an attempt to extend Alemi's information processing formulation of machine learning, and the predictive information bottleneck objective for model training, to the widely-used scenario where training utilizes not only a training but also a validation data set.
Multi$^2$OIE: Multilingual Open Information Extraction Based on Multi-Head Attention with BERT
Oct 07, 2020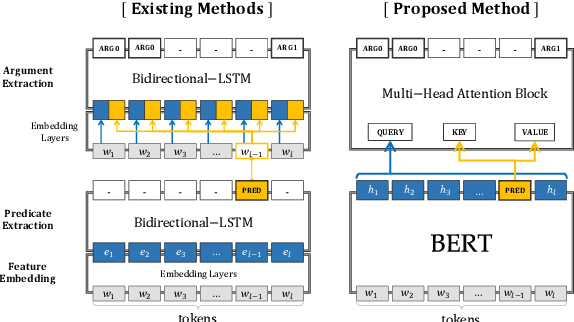
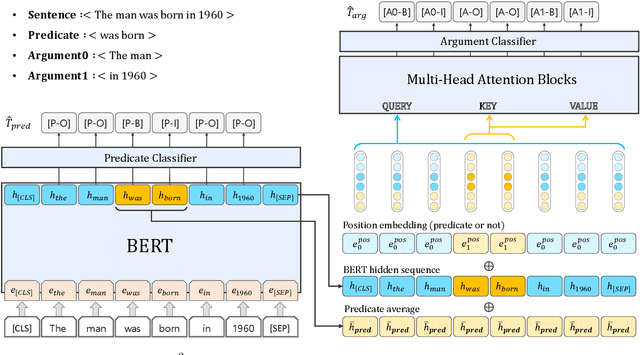

In this paper, we propose Multi$^2$OIE, which performs open information extraction (open IE) by combining BERT with multi-head attention. Our model is a sequence-labeling system with an efficient and effective argument extraction method. We use a query, key, and value setting inspired by the Multimodal Transformer to replace the previously used bidirectional long short-term memory architecture with multi-head attention. Multi$^2$OIE outperforms existing sequence-labeling systems with high computational efficiency on two benchmark evaluation datasets, Re-OIE2016 and CaRB. Additionally, we apply the proposed method to multilingual open IE using multilingual BERT. Experimental results on new benchmark datasets introduced for two languages (Spanish and Portuguese) demonstrate that our model outperforms other multilingual systems without training data for the target languages.