 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LaMDA: Language Models for Dialog Applications
Feb 10, 2022
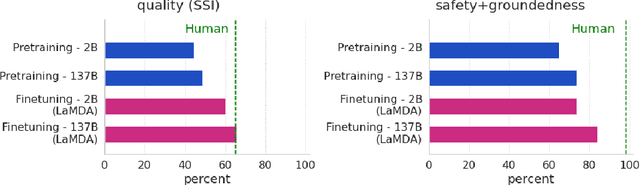
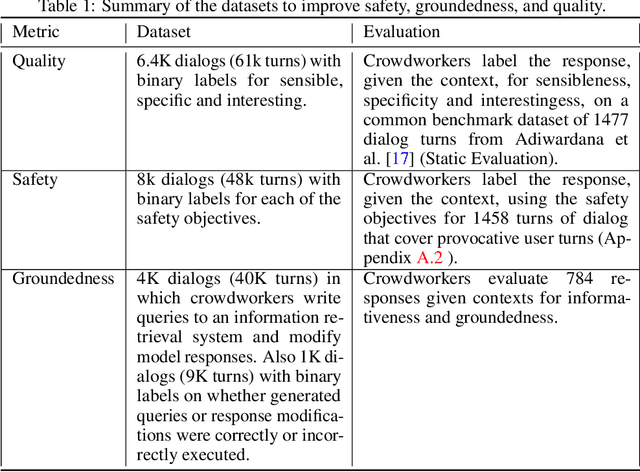
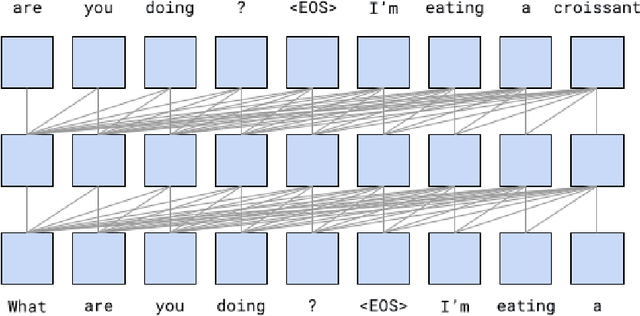

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Multi-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information
Nov 02, 2020
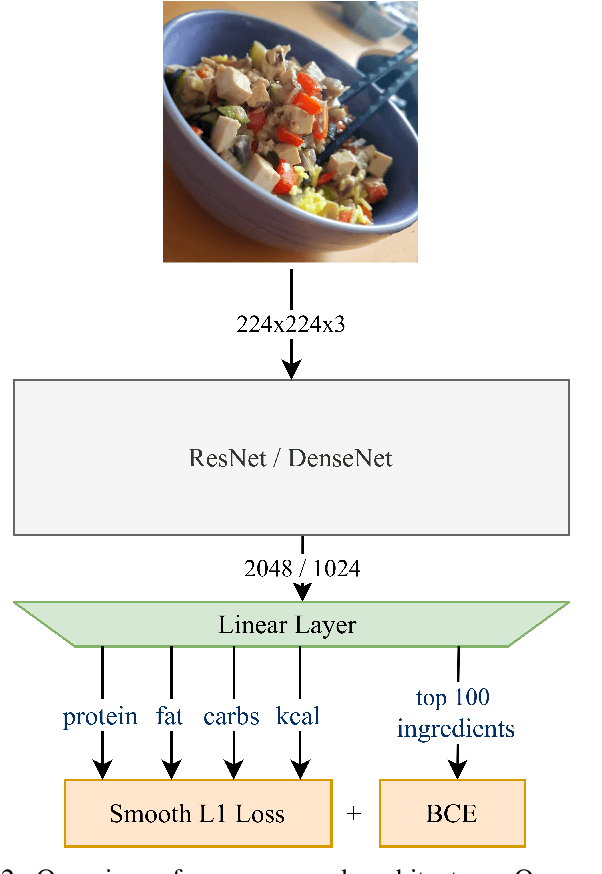
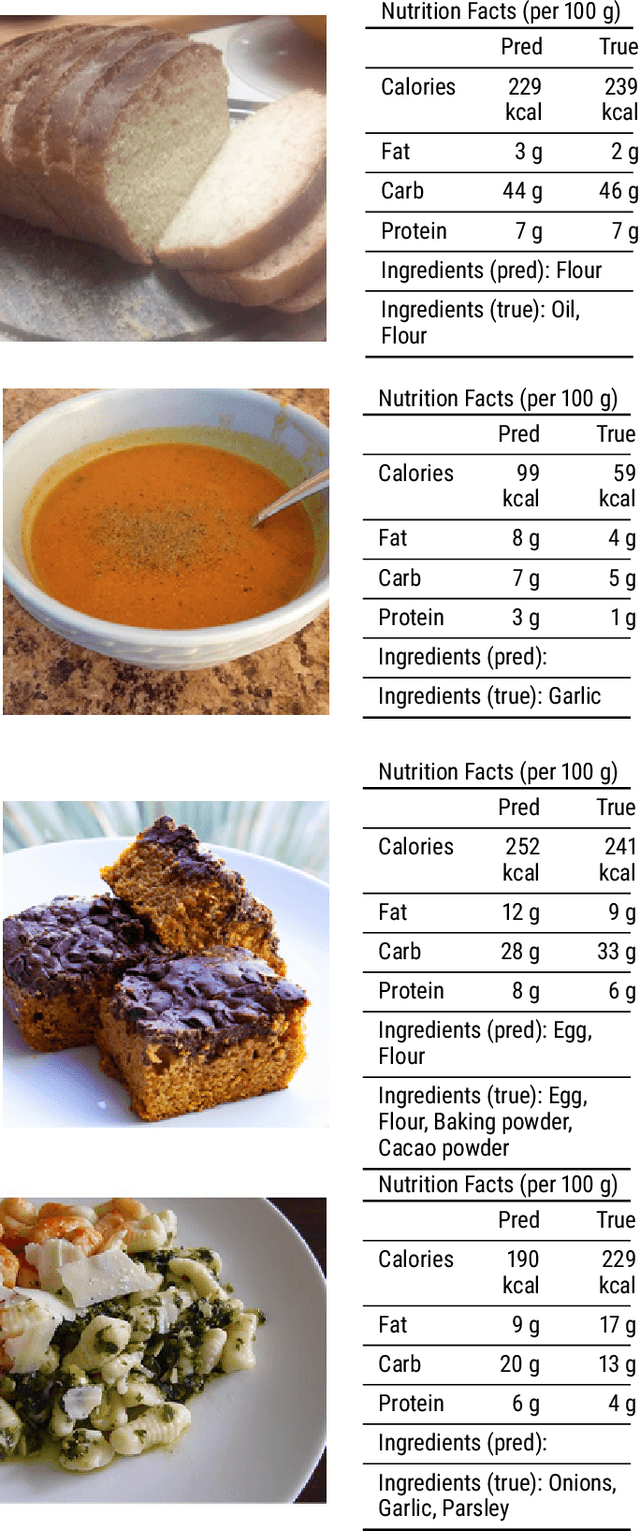
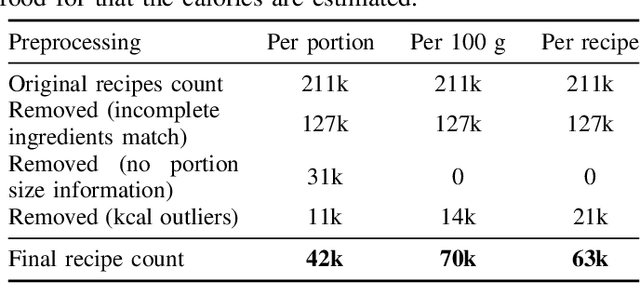
A rapidly growing amount of content posted online, such as food recipes, opens doors to new exciting applications at the intersection of vision and language. In this work, we aim to estimate the calorie amount of a meal directly from an image by learning from recipes people have published on the Internet, thus skipping time-consuming manual data annotation. Since there are few large-scale publicly available datasets captured in unconstrained environments, we propose the pic2kcal benchmark comprising 308,000 images from over 70,000 recipes including photographs, ingredients and instructions. To obtain nutritional information of the ingredients and automatically determine the ground-truth calorie value, we match the items in the recipes with structured information from a food item database. We evaluate various neural networks for regression of the calorie quantity and extend them with the multi-task paradigm. Our learning procedure combines the calorie estimation with prediction of proteins, carbohydrates, and fat amounts as well as a multi-label ingredient classification. Our experiments demonstrate clear benefits of multi-task learning for calorie estimation, surpassing the single-task calorie regression by 9.9%. To encourage further research on this task, we make the code for generating the dataset and the models publicly available.
TV-based Spline Reconstruction with Fourier Measurements: Uniqueness and Convergence of Grid-Based Methods
Feb 10, 2022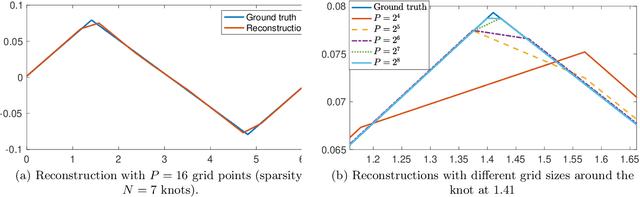
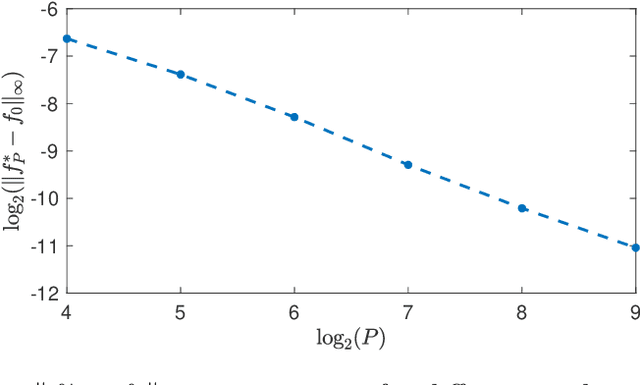
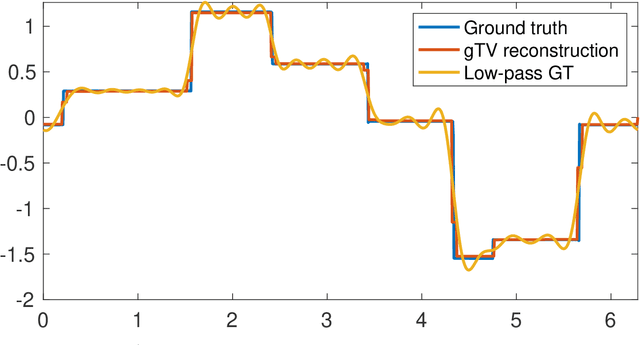
We study the problem of recovering piecewise-polynomial periodic functions from their low-frequency information. This means that we only have access to possibly corrupted versions of the Fourier samples of the ground truth up to a maximum cutoff frequency $K_c$. The reconstruction task is specified as an optimization problem with total-variation (TV) regularization (in the sense of measures) involving the $M$-th order derivative regularization operator $\mathrm{L} = \mathrm{D}^M$. The order $M \geq 1$ determines the degree of the reconstructed piecewise polynomial spline, whereas the TV regularization norm, which is known to promote sparsity, guarantees a small number of pieces. We show that the solution of our optimization problem is always unique, which, to the best of our knowledge, is a first for TV-based problems. Moreover, we show that this solution is a periodic spline matched to the regularization operator $\mathrm{L}$ whose number of knots is upper-bounded by $2 K_c$. We then consider the grid-based discretization of our optimization problem in the space of uniform $\mathrm{L}$-splines. On the theoretical side, we show that any sequence of solutions of the discretized problem converges uniformly to the unique solution of the gridless problem as the grid size vanishes. Finally, on the algorithmic side, we propose a B-spline-based algorithm to solve the grid-based problem, and we demonstrate its numerical feasibility experimentally. On both of these aspects, we leverage the uniqueness of the solution of the original problem.
SUPA: A Lightweight Diagnostic Simulator for Machine Learning in Particle Physics
Feb 10, 2022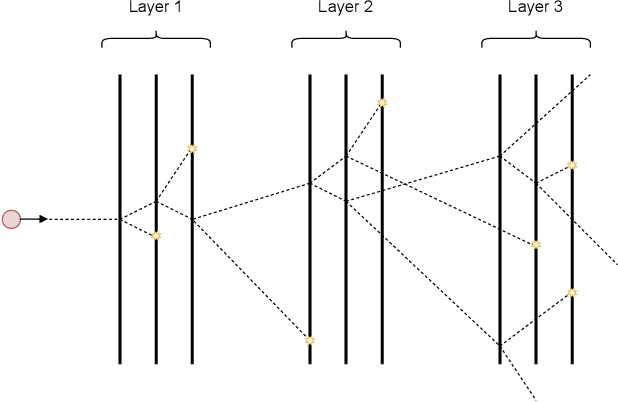
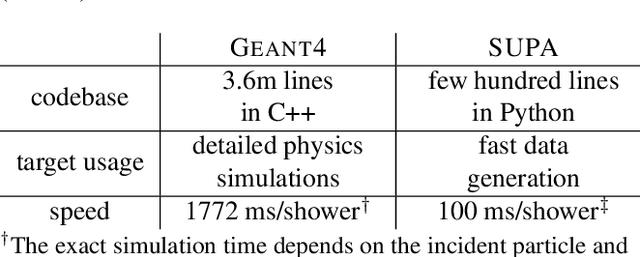
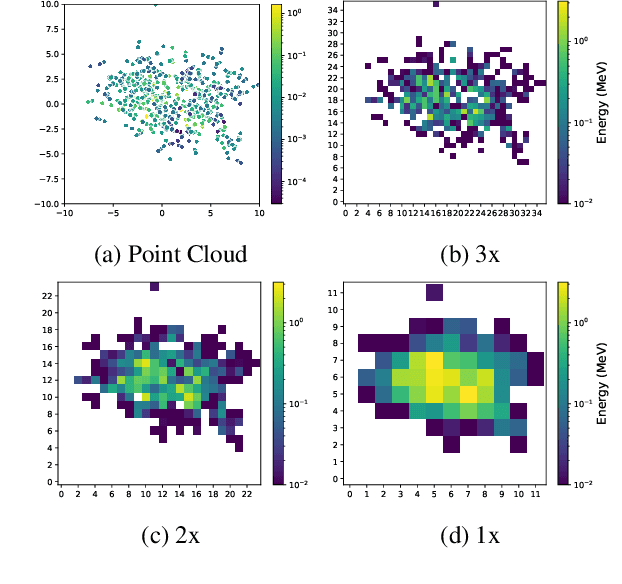
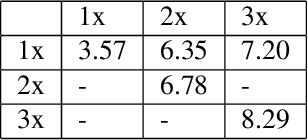
Deep learning methods have gained popularity in high energy physics for fast modeling of particle showers in detectors. Detailed simulation frameworks such as the gold standard Geant4 are computationally intensive, and current deep generative architectures work on discretized, lower resolution versions of the detailed simulation. The development of models that work at higher spatial resolutions is currently hindered by the complexity of the full simulation data, and by the lack of simpler, more interpretable benchmarks. Our contribution is SUPA, the SUrrogate PArticle propagation simulator, an algorithm and software package for generating data by simulating simplified particle propagation, scattering and shower development in matter. The generation is extremely fast and easy to use compared to Geant4, but still exhibits the key characteristics and challenges of the detailed simulation. We support this claim experimentally by showing that performance of generative models on data from our simulator reflects the performance on a dataset generated with Geant4. The proposed simulator generates thousands of particle showers per second on a desktop machine, a speed up of up to 6 orders of magnitudes over Geant4, and stores detailed geometric information about the shower propagation. SUPA provides much greater flexibility for setting initial conditions and defining multiple benchmarks for the development of models. Moreover, interpreting particle showers as point clouds creates a connection to geometric machine learning and provides challenging and fundamentally new datasets for the field. The code for SUPA is available at https://github.com/itsdaniele/SUPA.
DeepSteal: Advanced Model Extractions Leveraging Efficient Weight Stealing in Memories
Nov 08, 2021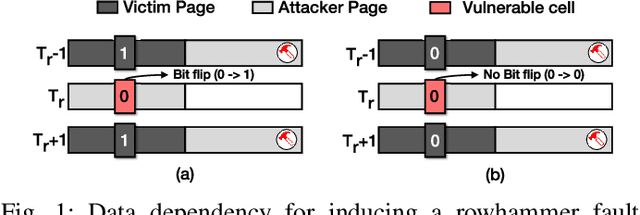
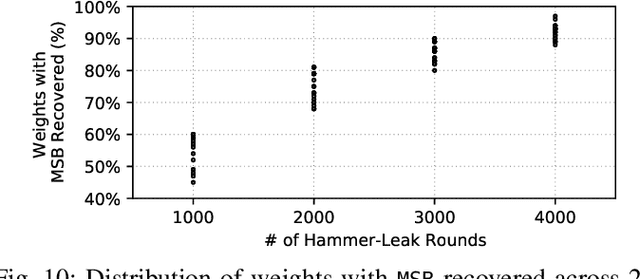
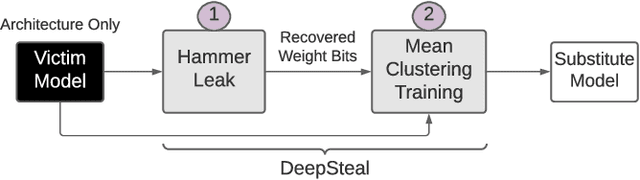
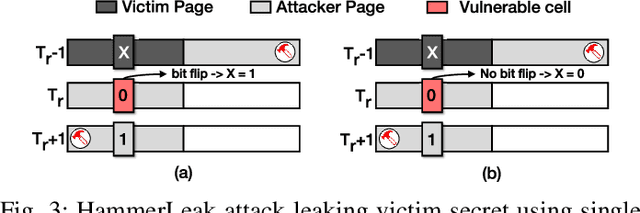
Recent advancements of Deep Neural Networks (DNNs) have seen widespread deployment in multiple security-sensitive domains. The need of resource-intensive training and use of valuable domain-specific training data have made these models a top intellectual property (IP) for model owners. One of the major threats to the DNN privacy is model extraction attacks where adversaries attempt to steal sensitive information in DNN models. Recent studies show hardware-based side channel attacks can reveal internal knowledge about DNN models (e.g., model architectures) However, to date, existing attacks cannot extract detailed model parameters (e.g., weights/biases). In this work, for the first time, we propose an advanced model extraction attack framework DeepSteal that effectively steals DNN weights with the aid of memory side-channel attack. Our proposed DeepSteal comprises two key stages. Firstly, we develop a new weight bit information extraction method, called HammerLeak, through adopting the rowhammer based hardware fault technique as the information leakage vector. HammerLeak leverages several novel system-level techniques tailed for DNN applications to enable fast and efficient weight stealing. Secondly, we propose a novel substitute model training algorithm with Mean Clustering weight penalty, which leverages the partial leaked bit information effectively and generates a substitute prototype of the target victim model. We evaluate this substitute model extraction method on three popular image datasets (e.g., CIFAR-10/100/GTSRB) and four DNN architectures (e.g., ResNet-18/34/Wide-ResNet/VGG-11). The extracted substitute model has successfully achieved more than 90 % test accuracy on deep residual networks for the CIFAR-10 dataset. Moreover, our extracted substitute model could also generate effective adversarial input samples to fool the victim model.
Semantically enriched spatial modelling of industrial indoor environments enabling location-based services
Dec 22, 2021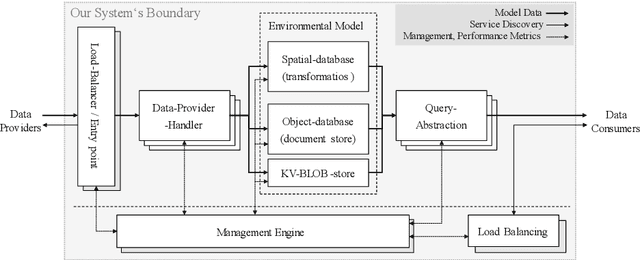
This paper presents a concept for a software system called RAIL representing industrial indoor environments in a dynamic spatial model, aimed at easing development and provision of location-based services. RAIL integrates data from different sensor modalities and additional contextual information through a unified interface. Approaches to environmental modelling from other domains are reviewed and analyzed for their suitability regarding the requirements for our target domains; intralogistics and production. Subsequently a novel way of modelling data representing indoor space, and an architecture for the software system are proposed.
* 3. Kongresses Montage Handhabung Industrieroboter MHI
Semantic Labeling of Human Action For Visually Impaired And Blind People Scene Interaction
Jan 12, 2022
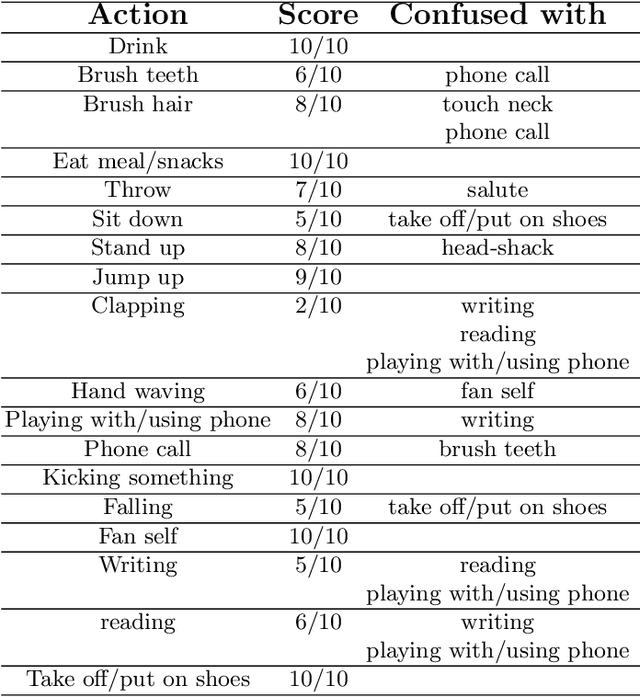
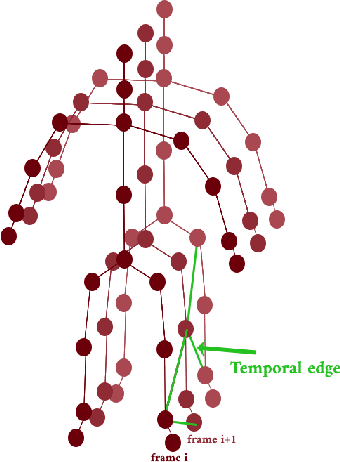
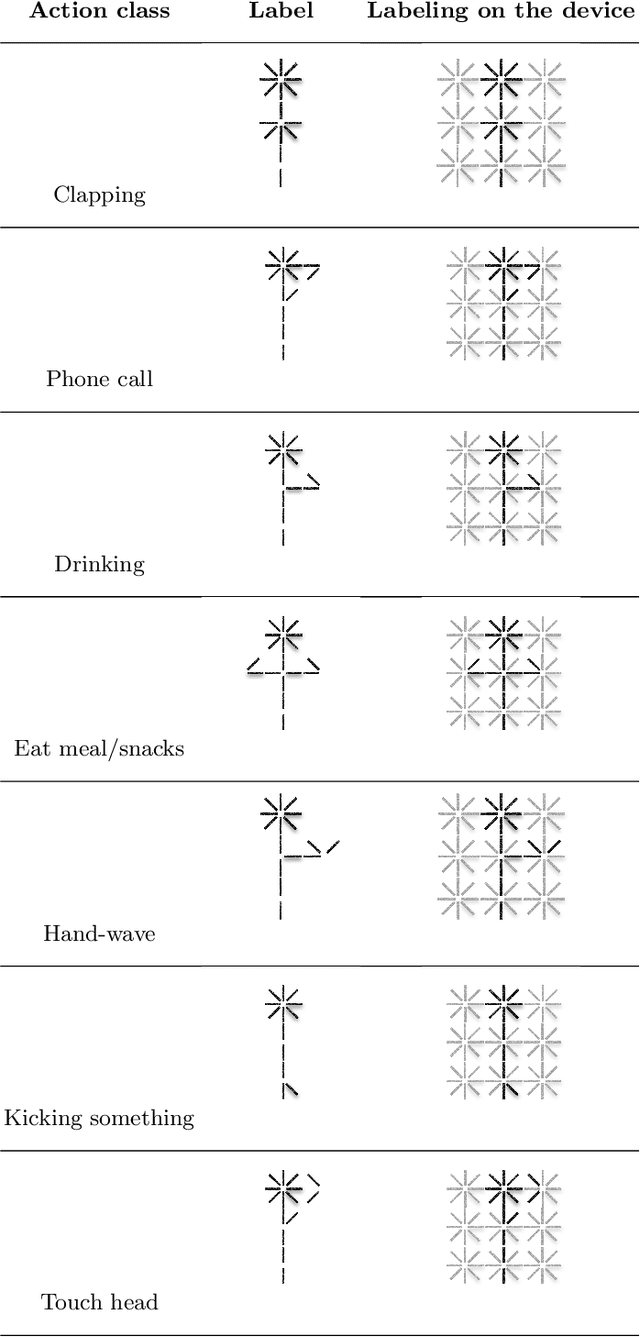
The aim of this work is to contribute to the development of a tactile device for visually impaired and blind persons in order to let them to understand actions of the surrounding people and to interact with them. First, based on the state-of-the-art methods of human action recognition from RGB-D sequences, we use the skeleton information provided by Kinect, with the disentangled and unified multi-scale Graph Convolutional (MS-G3D) model to recognize the performed actions. We tested this model on real scenes and found some of constraints and limitations. Next, we apply a fusion between skeleton modality with MS-G3D and depth modality with CNN in order to bypass the discussed limitations. Third, the recognized actions are labeled semantically and will be mapped into an output device perceivable by the touch sense.
Deep Asymmetric Hashing with Dual Semantic Regression and Class Structure Quantization
Oct 24, 2021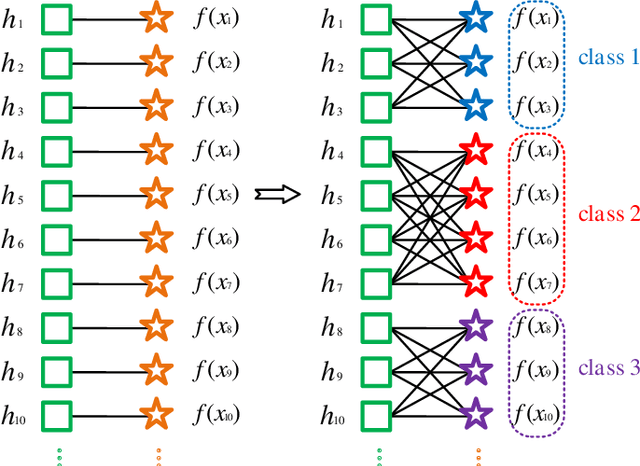
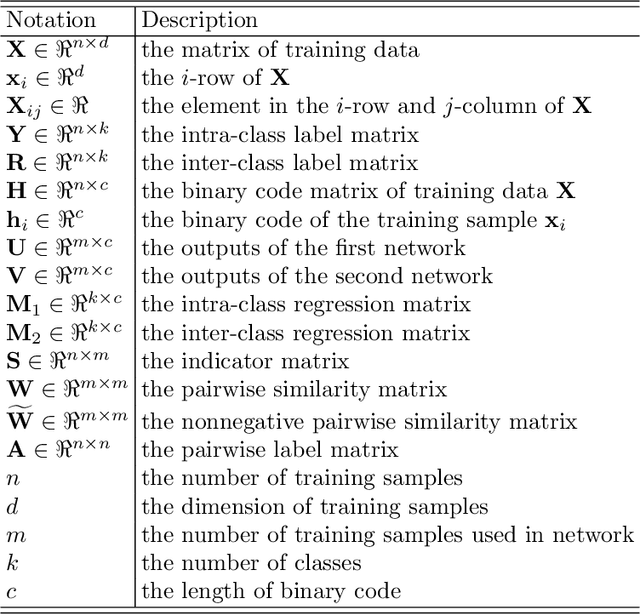
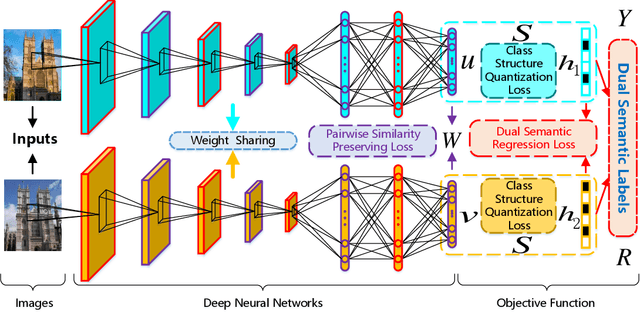
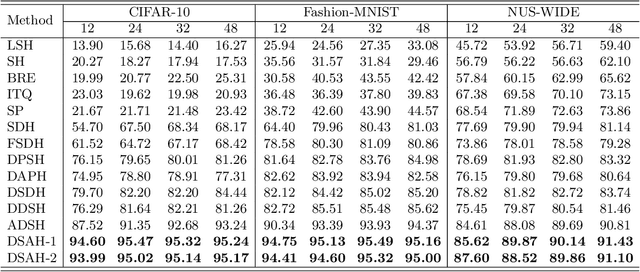
Recently, deep hashing methods have been widely used in image retrieval task. Most existing deep hashing approaches adopt one-to-one quantization to reduce information loss. However, such class-unrelated quantization cannot give discriminative feedback for network training. In addition, these methods only utilize single label to integrate supervision information of data for hashing function learning, which may result in inferior network generalization performance and relatively low-quality hash codes since the inter-class information of data is totally ignored. In this paper, we propose a dual semantic asymmetric hashing (DSAH) method, which generates discriminative hash codes under three-fold constrains. Firstly, DSAH utilizes class prior to conduct class structure quantization so as to transmit class information during the quantization process. Secondly, a simple yet effective label mechanism is designed to characterize both the intra-class compactness and inter-class separability of data, thereby achieving semantic-sensitive binary code learning. Finally, a meaningful pairwise similarity preserving loss is devised to minimize the distances between class-related network outputs based on an affinity graph. With these three main components, high-quality hash codes can be generated through network. Extensive experiments conducted on various datasets demonstrate the superiority of DSAH in comparison with state-of-the-art deep hashing methods.
FreeDOM: A Transferable Neural Architecture for Structured Information Extraction on Web Documents
Oct 21, 2020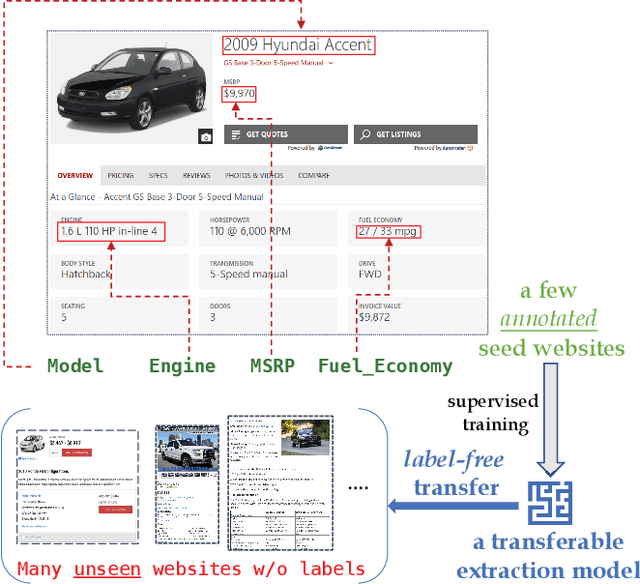
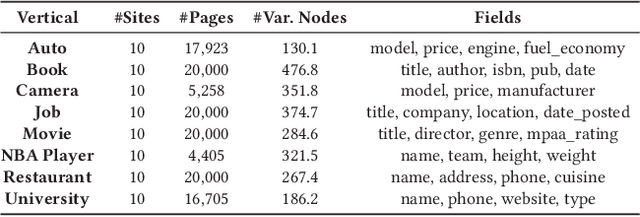

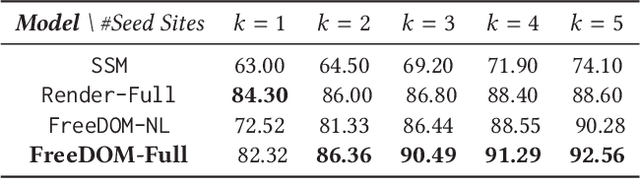
Extracting structured data from HTML documents is a long-studied problem with a broad range of applications like augmenting knowledge bases, supporting faceted search, and providing domain-specific experiences for key verticals like shopping and movies. Previous approaches have either required a small number of examples for each target site or relied on carefully handcrafted heuristics built over visual renderings of websites. In this paper, we present a novel two-stage neural approach, named FreeDOM, which overcomes both these limitations. The first stage learns a representation for each DOM node in the page by combining both the text and markup information. The second stage captures longer range distance and semantic relatedness using a relational neural network. By combining these stages, FreeDOM is able to generalize to unseen sites after training on a small number of seed sites from that vertical without requiring expensive hand-crafted features over visual renderings of the page. Through experiments on a public dataset with 8 different verticals, we show that FreeDOM beats the previous state of the art by nearly 3.7 F1 points on average without requiring features over rendered pages or expensive hand-crafted features.
Fast MRI Reconstruction: How Powerful Transformers Are?
Jan 23, 2022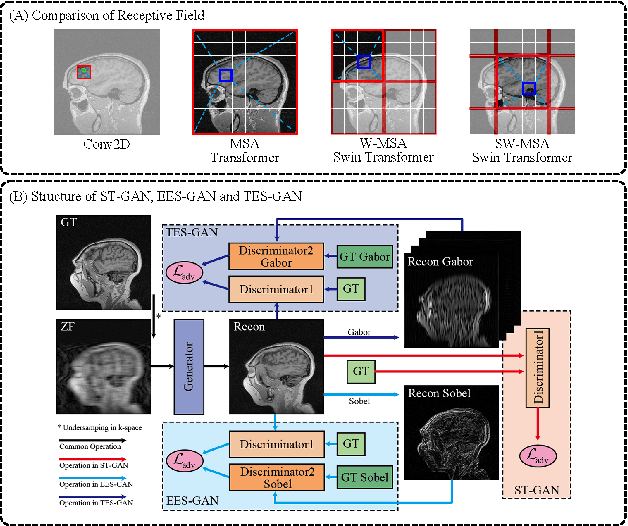
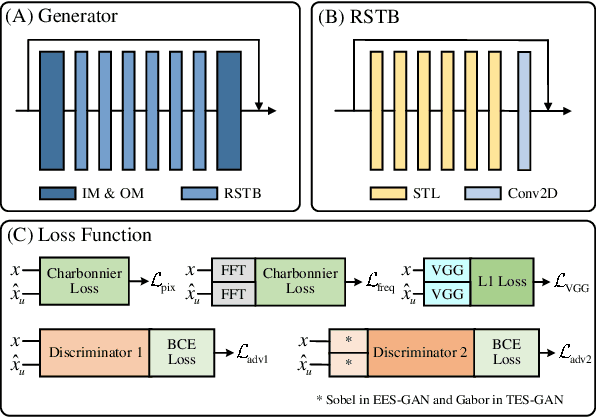
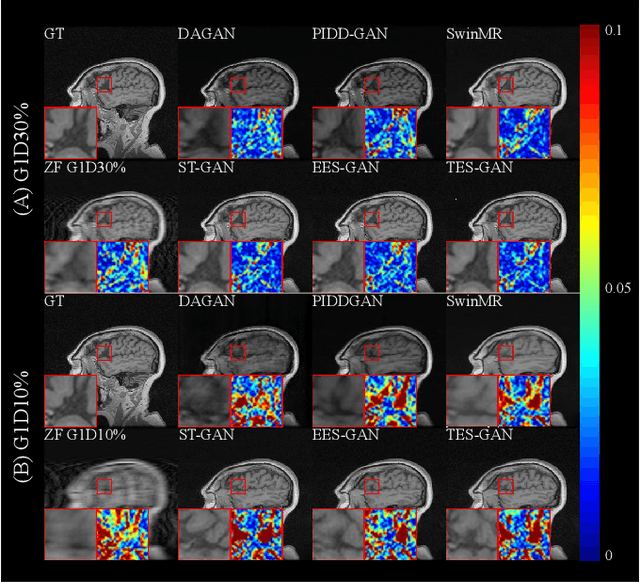
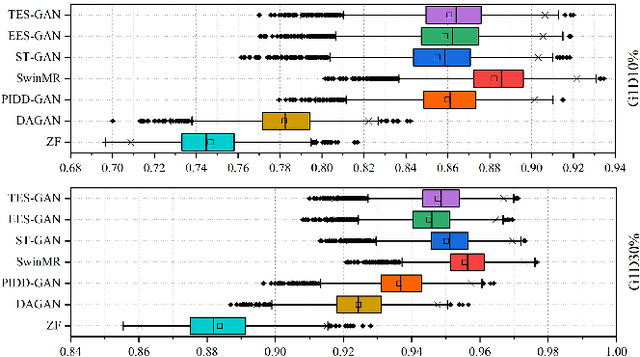
Magnetic resonance imaging (MRI) is a widely used non-radiative and non-invasive method for clinical interrogation of organ structures and metabolism, with an inherently long scanning time. Methods by k-space undersampling and deep learning based reconstruction have been popularised to accelerate the scanning process. This work focuses on investigating how powerful transformers are for fast MRI by exploiting and comparing different novel network architectures. In particular, a generative adversarial network (GAN) based Swin transformer (ST-GAN) was introduced for the fast MRI reconstruction. To further preserve the edge and texture information, edge enhanced GAN based Swin transformer (EESGAN) and texture enhanced GAN based Swin transformer (TES-GAN) were also developed, where a dual-discriminator GAN structure was applied. We compared our proposed GAN based transformers, standalone Swin transformer and other convolutional neural networks based based GAN model in terms of the evaluation metrics PSNR, SSIM and FID. We showed that transformers work well for the MRI reconstruction from different undersampling conditions. The utilisation of GAN's adversarial structure improves the quality of images reconstructed when undersampled for 30% or higher.