 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Interactive Feature Fusion for End-to-End Noise-Robust Speech Recognition
Oct 11, 2021
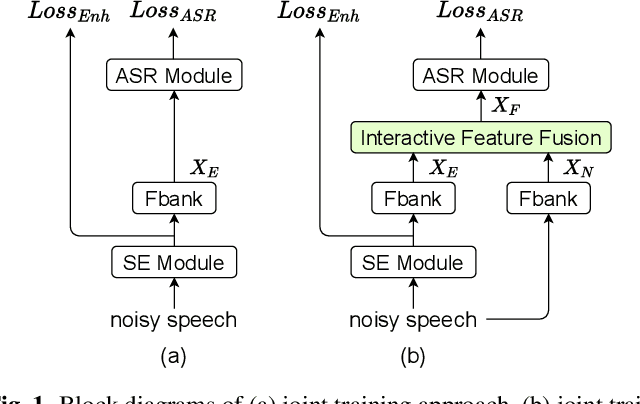
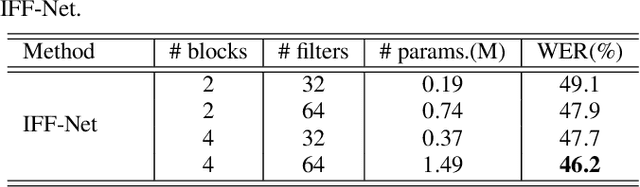
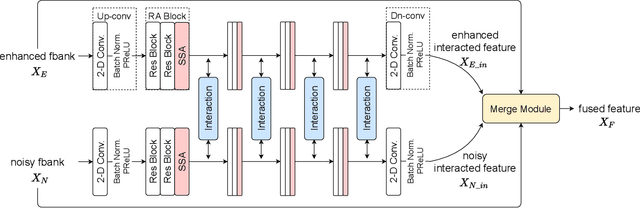
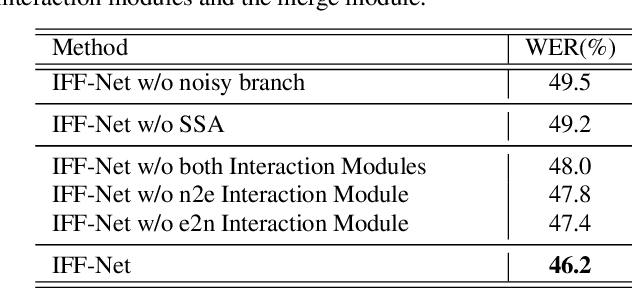
Speech enhancement (SE) aims to suppress the additive noise from a noisy speech signal to improve the speech's perceptual quality and intelligibility. However, the over-suppression phenomenon in the enhanced speech might degrade the performance of downstream automatic speech recognition (ASR) task due to the missing latent information. To alleviate such problem, we propose an interactive feature fusion network (IFF-Net) for noise-robust speech recognition to learn complementary information from the enhanced feature and original noisy feature. Experimental results show that the proposed method achieves absolute word error rate (WER) reduction of 4.1% over the best baseline on RATS Channel-A corpus. Our further analysis indicates that the proposed IFF-Net can complement some missing information in the over-suppressed enhanced feature.
Multi-Pair Two-Way Massive MIMO DF Relaying Over Rician Fading Channels Under Imperfect CSI
Oct 28, 2021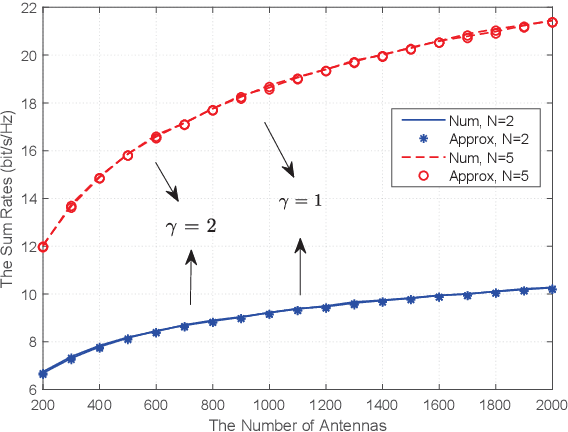
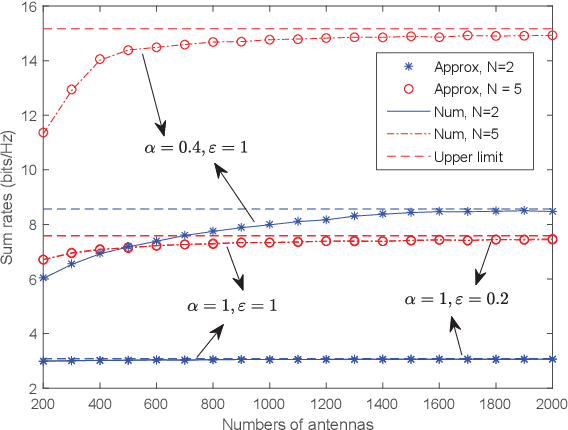

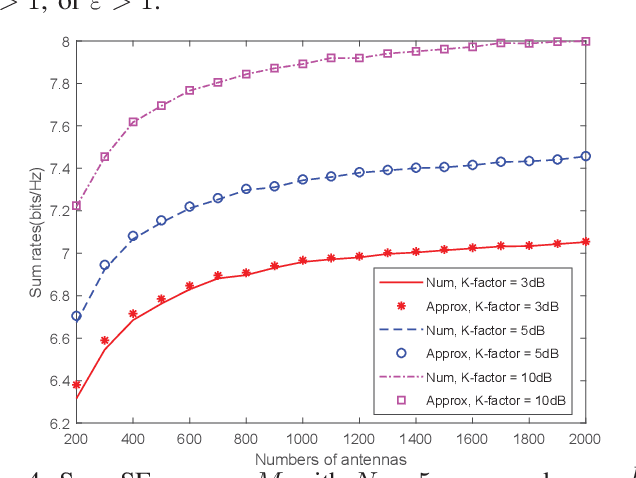
We investigate a multi-pair two-way decode-andforward relaying aided massive multiple-input multiple-output antenna system under Rician fading channels, in which multiple pairs of users exchange information through a relay station having multiple antennas. Imperfect channel state information is considered in the context of maximum-ratio processing. Closedform expressions are derived for approximating the sum spectral efficiency (SE) of the system. Moreover, we obtain the powerscaling laws at the users and the relay station to satisfy a certain SE requirement in three typical scenarios. Finally, simulations validate the accuracy of the derived results.
Learning Population-level Shape Statistics and Anatomy Segmentation From Images: A Joint Deep Learning Model
Jan 10, 2022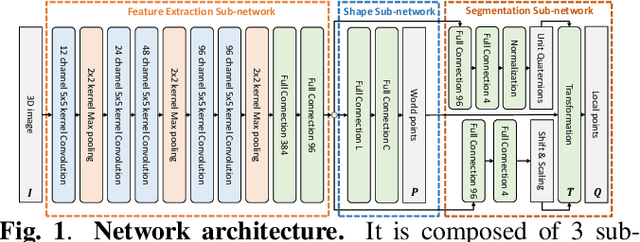
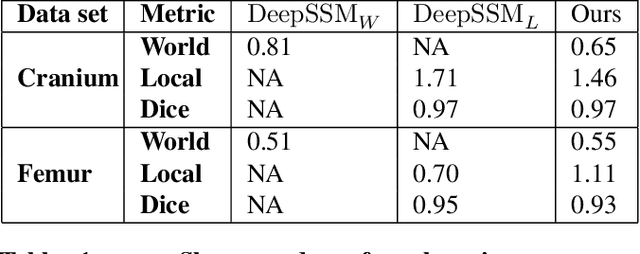
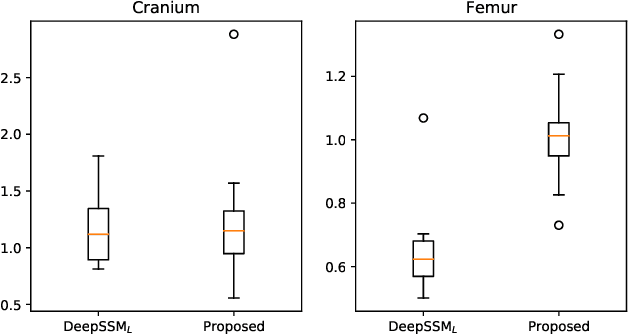
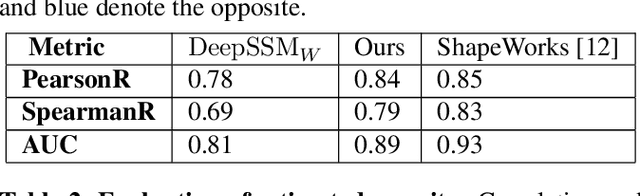
Statistical shape modeling is an essential tool for the quantitative analysis of anatomical populations. Point distribution models (PDMs) represent the anatomical surface via a dense set of correspondences, an intuitive and easy-to-use shape representation for subsequent applications. These correspondences are exhibited in two coordinate spaces: the local coordinates describing the geometrical features of each individual anatomical surface and the world coordinates representing the population-level statistical shape information after removing global alignment differences across samples in the given cohort. We propose a deep-learning-based framework that simultaneously learns these two coordinate spaces directly from the volumetric images. The proposed joint model serves a dual purpose; the world correspondences can directly be used for shape analysis applications, circumventing the heavy pre-processing and segmentation involved in traditional PDM models. Additionally, the local correspondences can be used for anatomy segmentation. We demonstrate the efficacy of this joint model for both shape modeling applications on two datasets and its utility in inferring the anatomical surface.
TASSY -- A Text Annotation Survey System
Dec 14, 2021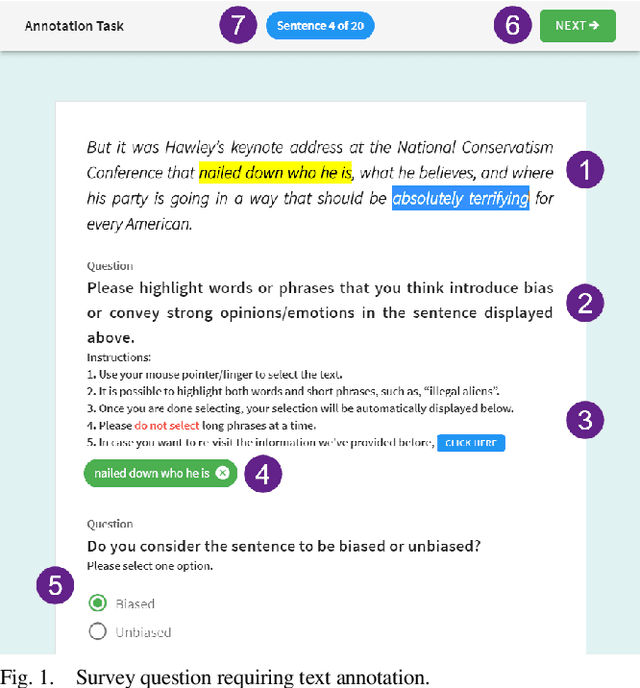
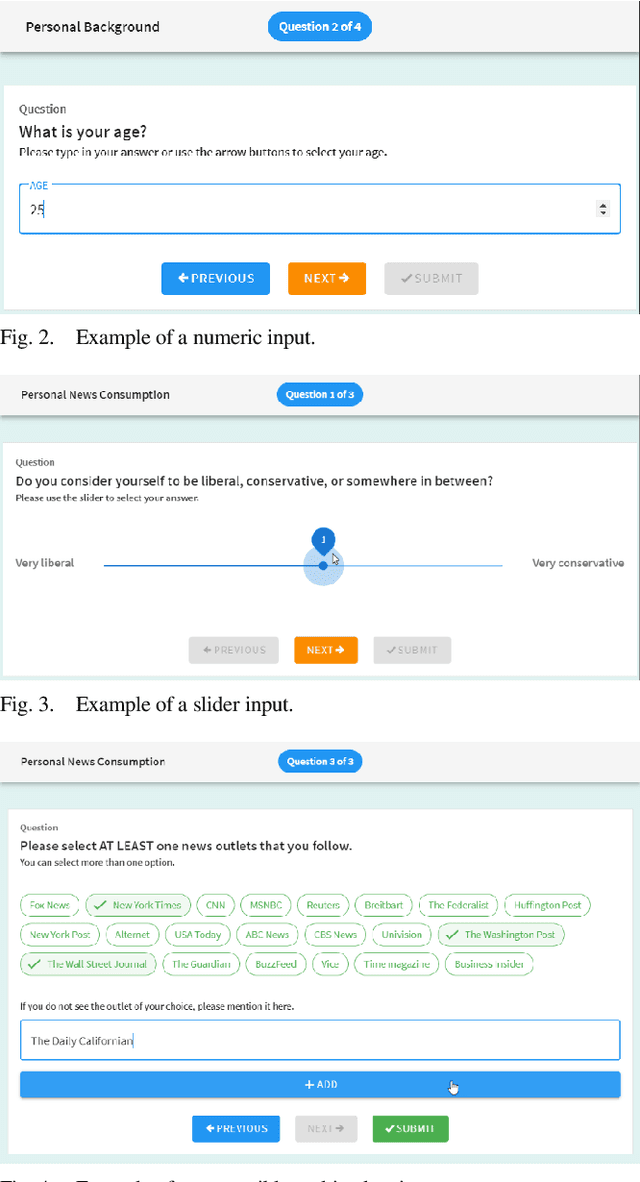
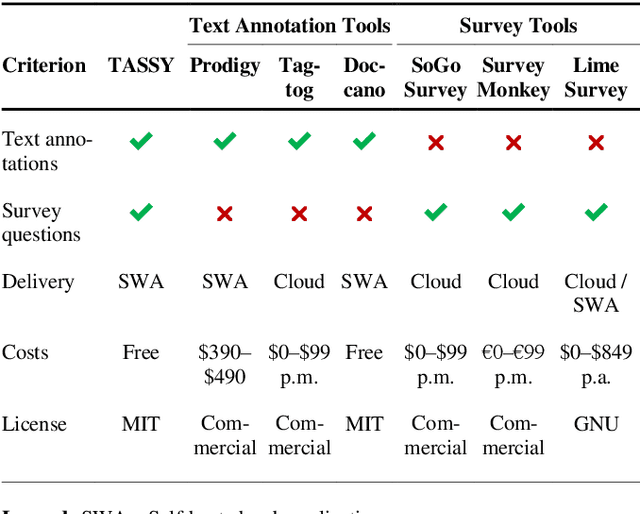
We present a free and open-source tool for creating web-based surveys that include text annotation tasks. Existing tools offer either text annotation or survey functionality but not both. Combining the two input types is particularly relevant for investigating a reader's perception of a text which also depends on the reader's background, such as age, gender, and education. Our tool caters primarily to the needs of researchers in the Library and Information Sciences, the Social Sciences, and the Humanities who apply Content Analysis to investigate, e.g., media bias, political communication, or fake news.
Leveraging Social Influence based on Users Activity Centers for Point-of-Interest Recommendation
Jan 10, 2022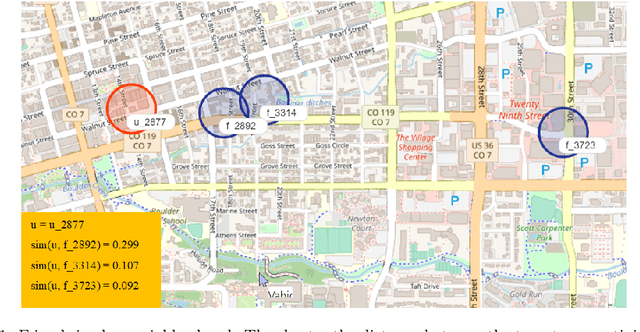
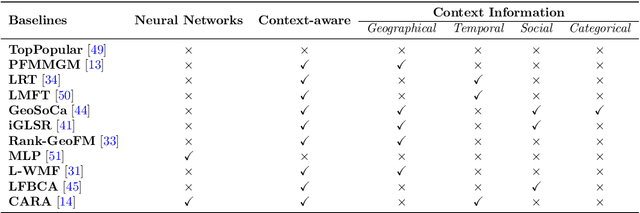
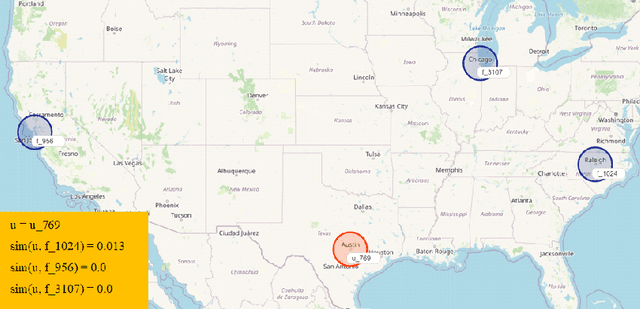
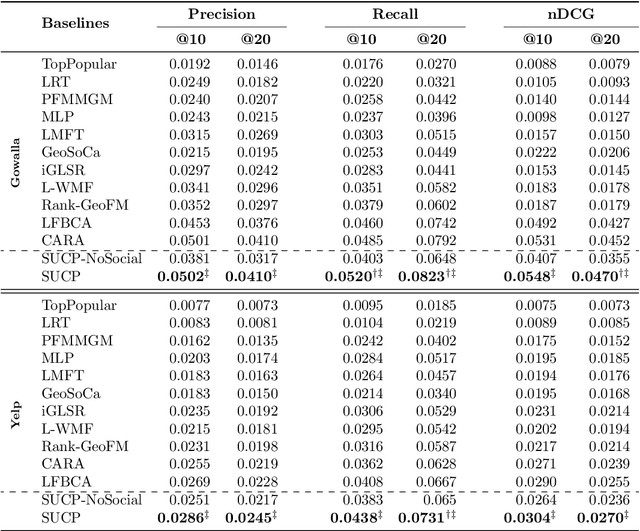
Recommender Systems (RSs) aim to model and predict the user preference while interacting with items, such as Points of Interest (POIs). These systems face several challenges, such as data sparsity, limiting their effectiveness. In this paper, we address this problem by incorporating social, geographical, and temporal information into the Matrix Factorization (MF) technique. To this end, we model social influence based on two factors: similarities between users in terms of common check-ins and the friendships between them. We introduce two levels of friendship based on explicit friendship networks and high check-in overlap between users. We base our friendship algorithm on users' geographical activity centers. The results show that our proposed model outperforms the state-of-the-art on two real-world datasets. More specifically, our ablation study shows that the social model improves the performance of our proposed POI recommendation system by 31% and 14% on the Gowalla and Yelp datasets in terms of Precision@10, respectively.
CRIS: CLIP-Driven Referring Image Segmentation
Nov 30, 2021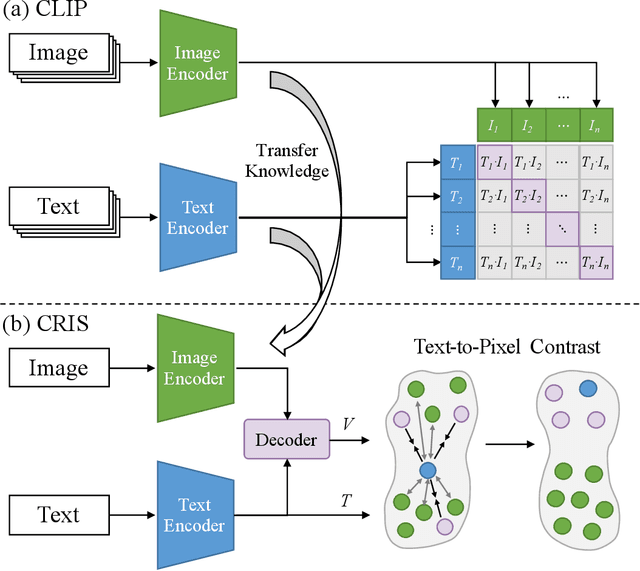
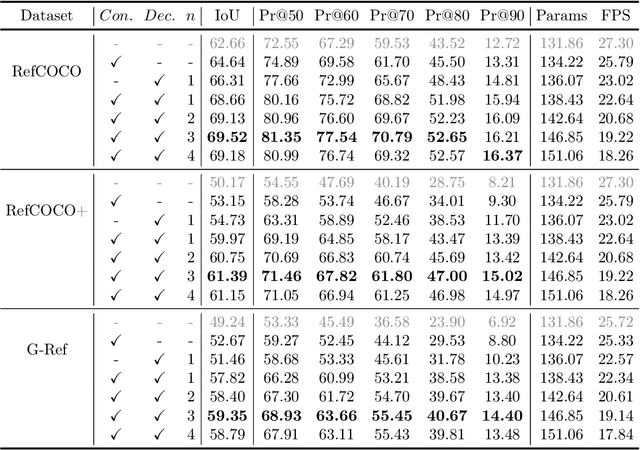

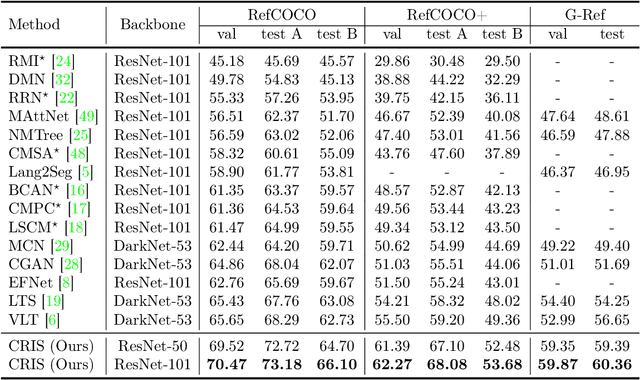
Referring image segmentation aims to segment a referent via a natural linguistic expression.Due to the distinct data properties between text and image, it is challenging for a network to well align text and pixel-level features. Existing approaches use pretrained models to facilitate learning, yet separately transfer the language/vision knowledge from pretrained models, ignoring the multi-modal corresponding information. Inspired by the recent advance in Contrastive Language-Image Pretraining (CLIP), in this paper, we propose an end-to-end CLIP-Driven Referring Image Segmentation framework (CRIS). To transfer the multi-modal knowledge effectively, CRIS resorts to vision-language decoding and contrastive learning for achieving the text-to-pixel alignment. More specifically, we design a vision-language decoder to propagate fine-grained semantic information from textual representations to each pixel-level activation, which promotes consistency between the two modalities. In addition, we present text-to-pixel contrastive learning to explicitly enforce the text feature similar to the related pixel-level features and dissimilar to the irrelevances. The experimental results on three benchmark datasets demonstrate that our proposed framework significantly outperforms the state-of-the-art performance without any post-processing. The code will be released.
MHAttnSurv: Multi-Head Attention for Survival Prediction Using Whole-Slide Pathology Images
Oct 22, 2021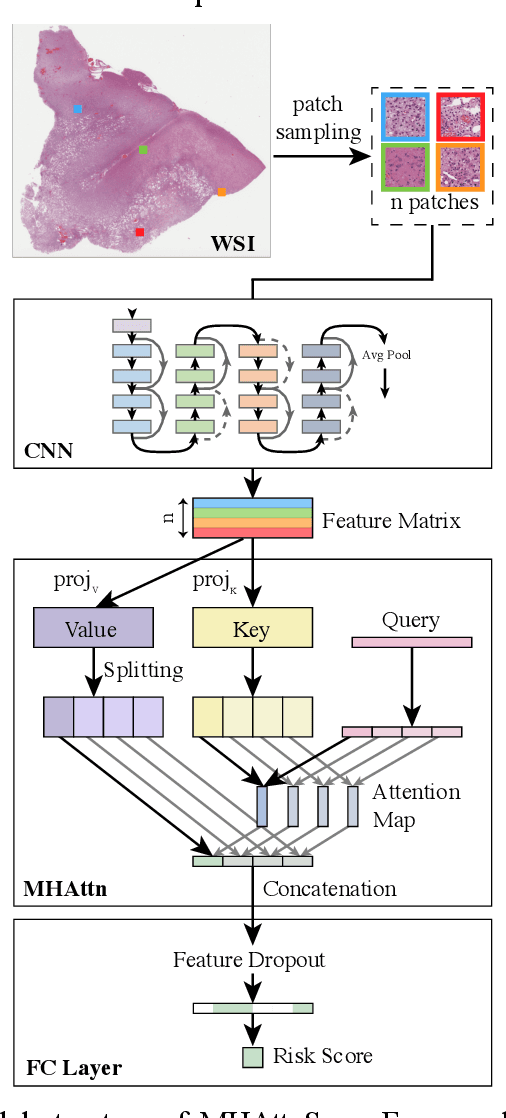
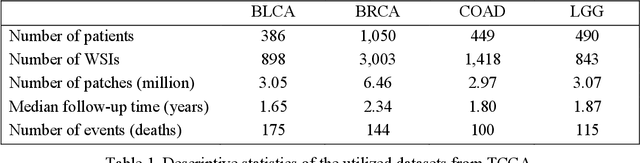
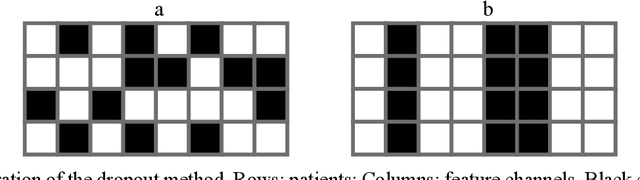
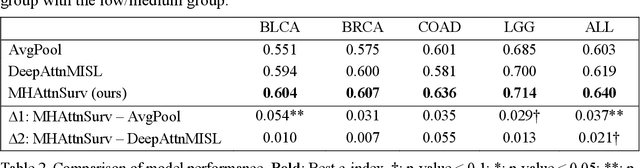
In pathology, whole-slide images (WSI) based survival prediction has attracted increasing interest. However, given the large size of WSIs and the lack of pathologist annotations, extracting the prognostic information from WSIs remains a challenging task. Previous studies have used multiple instance learning approaches to combine the information from multiple randomly sampled patches, but different visual patterns may contribute differently to prognosis prediction. In this study, we developed a multi-head attention approach to focus on various parts of a tumor slide, for more comprehensive information extraction from WSIs. We evaluated our approach on four cancer types from The Cancer Genome Atlas database. Our model achieved an average c-index of 0.640, outperforming two existing state-of-the-art approaches for WSI-based survival prediction, which have an average c-index of 0.603 and 0.619 on these datasets. Visualization of our attention maps reveals each attention head focuses synergistically on different morphological patterns.
Learning with less labels in Digital Pathology via Scribble Supervision from natural images
Jan 07, 2022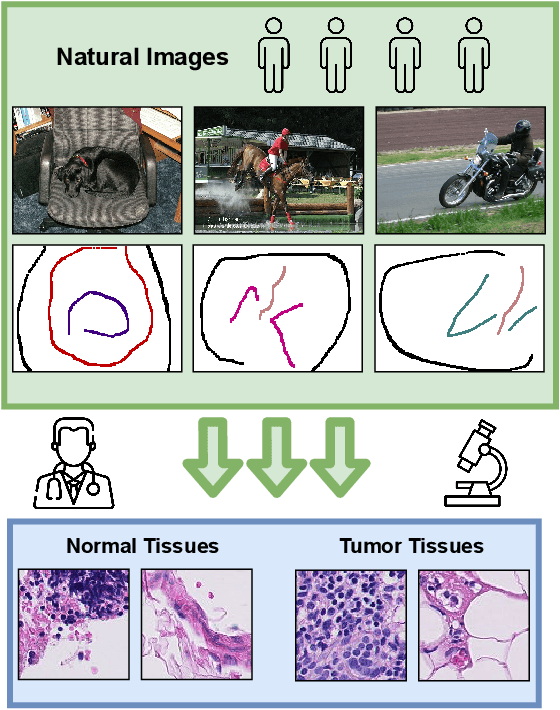
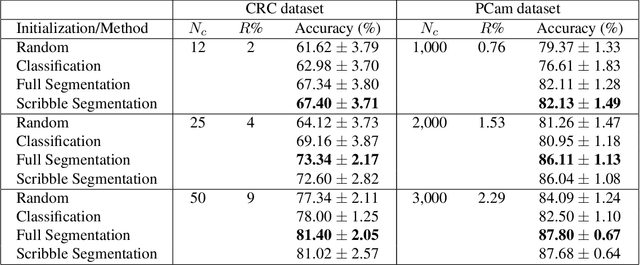
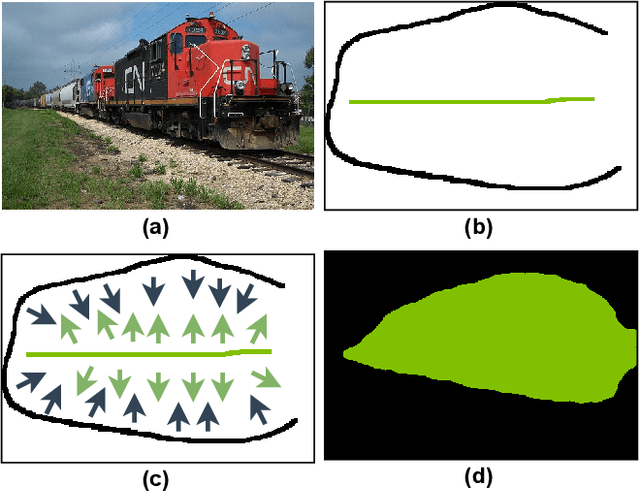

A critical challenge of training deep learning models in the Digital Pathology (DP) domain is the high annotation cost by medical experts. One way to tackle this issue is via transfer learning from the natural image domain (NI), where the annotation cost is considerably cheaper. Cross-domain transfer learning from NI to DP is shown to be successful via class labels~\cite{teh2020learning}. One potential weakness of relying on class labels is the lack of spatial information, which can be obtained from spatial labels such as full pixel-wise segmentation labels and scribble labels. We demonstrate that scribble labels from NI domain can boost the performance of DP models on two cancer classification datasets (Patch Camelyon Breast Cancer and Colorectal Cancer dataset). Furthermore, we show that models trained with scribble labels yield the same performance boost as full pixel-wise segmentation labels despite being significantly easier and faster to collect.
Structure from Silence: Learning Scene Structure from Ambient Sound
Nov 10, 2021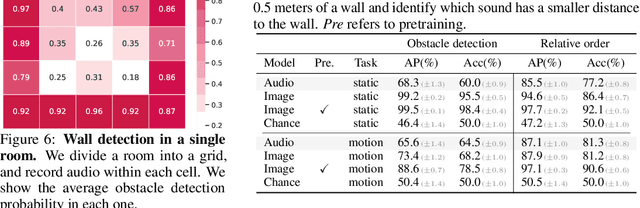

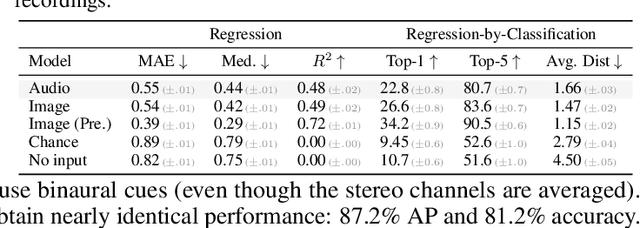
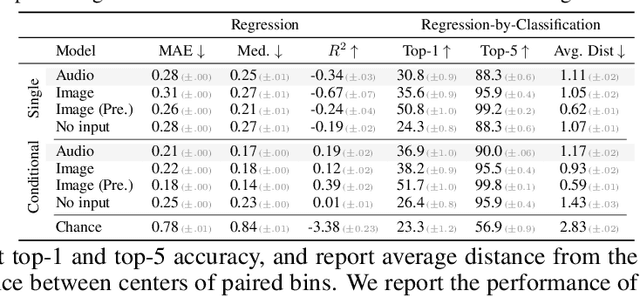
From whirling ceiling fans to ticking clocks, the sounds that we hear subtly vary as we move through a scene. We ask whether these ambient sounds convey information about 3D scene structure and, if so, whether they provide a useful learning signal for multimodal models. To study this, we collect a dataset of paired audio and RGB-D recordings from a variety of quiet indoor scenes. We then train models that estimate the distance to nearby walls, given only audio as input. We also use these recordings to learn multimodal representations through self-supervision, by training a network to associate images with their corresponding sounds. These results suggest that ambient sound conveys a surprising amount of information about scene structure, and that it is a useful signal for learning multimodal features.
Differentially-Private Clustering of Easy Instances
Dec 29, 2021

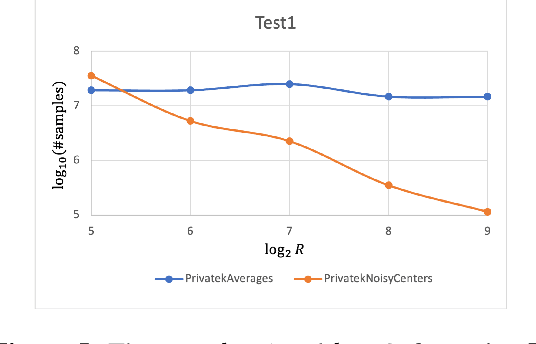
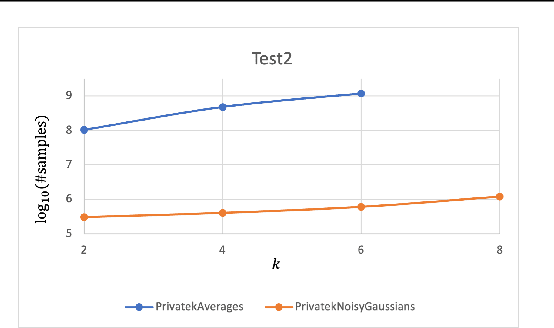
Clustering is a fundamental problem in data analysis. In differentially private clustering, the goal is to identify $k$ cluster centers without disclosing information on individual data points. Despite significant research progress, the problem had so far resisted practical solutions. In this work we aim at providing simple implementable differentially private clustering algorithms that provide utility when the data is "easy," e.g., when there exists a significant separation between the clusters. We propose a framework that allows us to apply non-private clustering algorithms to the easy instances and privately combine the results. We are able to get improved sample complexity bounds in some cases of Gaussian mixtures and $k$-means. We complement our theoretical analysis with an empirical evaluation on synthetic data.