 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploring Versatile Prior for Human Motion via Motion Frequency Guidance
Nov 25, 2021
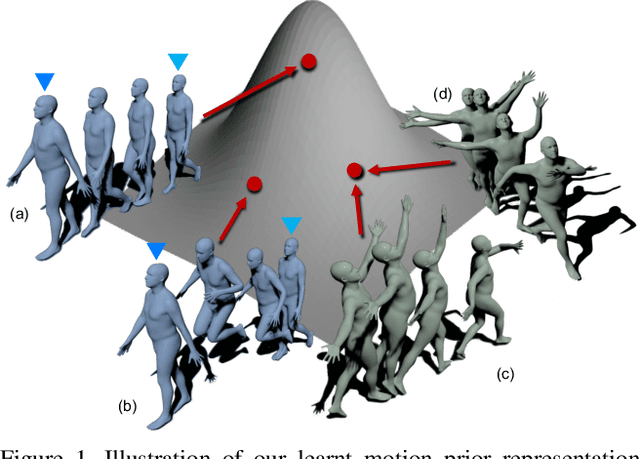
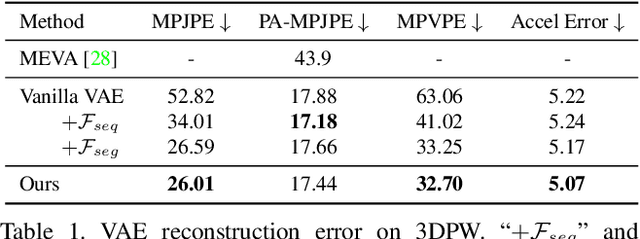
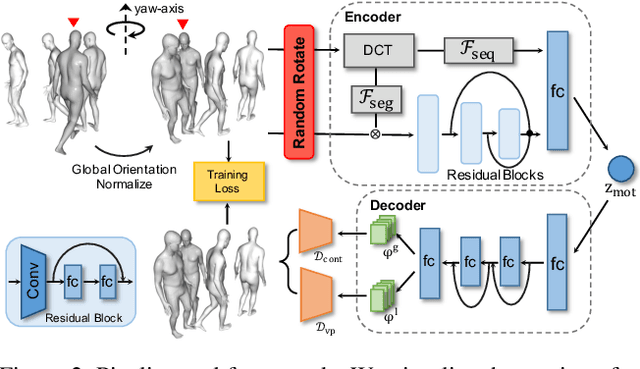
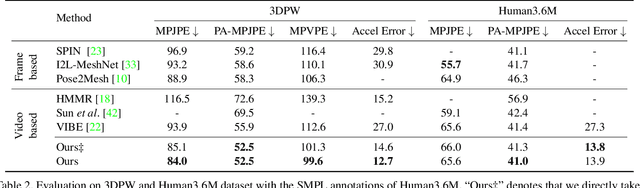
Prior plays an important role in providing the plausible constraint on human motion. Previous works design motion priors following a variety of paradigms under different circumstances, leading to the lack of versatility. In this paper, we first summarize the indispensable properties of the motion prior, and accordingly, design a framework to learn the versatile motion prior, which models the inherent probability distribution of human motions. Specifically, for efficient prior representation learning, we propose a global orientation normalization to remove redundant environment information in the original motion data space. Also, a two-level, sequence-based and segment-based, frequency guidance is introduced into the encoding stage. Then, we adopt a denoising training scheme to disentangle the environment information from input motion data in a learnable way, so as to generate consistent and distinguishable representation. Embedding our motion prior into prevailing backbones on three different tasks, we conduct extensive experiments, and both quantitative and qualitative results demonstrate the versatility and effectiveness of our motion prior. Our model and code are available at https://github.com/JchenXu/human-motion-prior.
Discrete Representations Strengthen Vision Transformer Robustness
Nov 20, 2021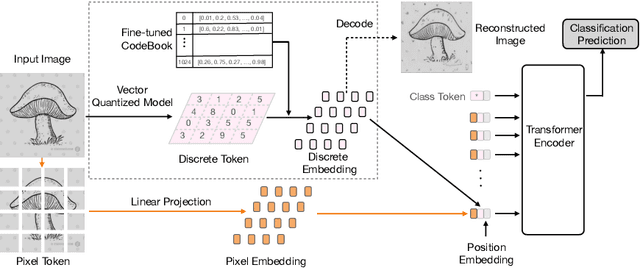
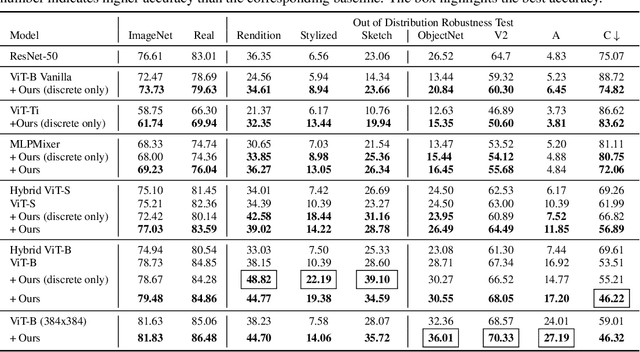


Vision Transformer (ViT) is emerging as the state-of-the-art architecture for image recognition. While recent studies suggest that ViTs are more robust than their convolutional counterparts, our experiments find that ViTs are overly reliant on local features (e.g., nuisances and texture) and fail to make adequate use of global context (e.g., shape and structure). As a result, ViTs fail to generalize to out-of-distribution, real-world data. To address this deficiency, we present a simple and effective architecture modification to ViT's input layer by adding discrete tokens produced by a vector-quantized encoder. Different from the standard continuous pixel tokens, discrete tokens are invariant under small perturbations and contain less information individually, which promote ViTs to learn global information that is invariant. Experimental results demonstrate that adding discrete representation on four architecture variants strengthens ViT robustness by up to 12% across seven ImageNet robustness benchmarks while maintaining the performance on ImageNet.
Enhancing Hyperbolic Graph Embeddings via Contrastive Learning
Jan 21, 2022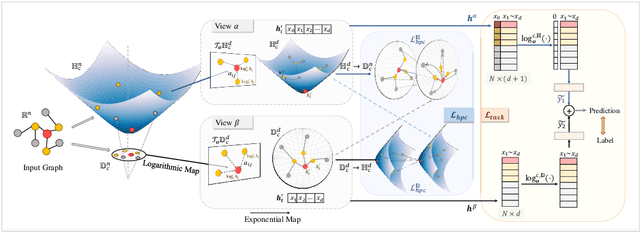
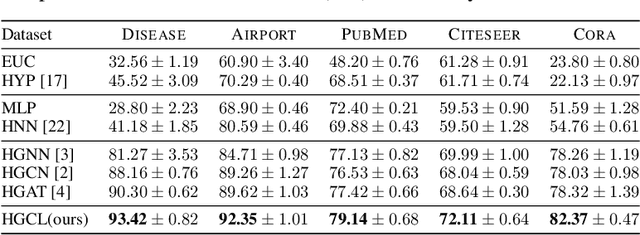
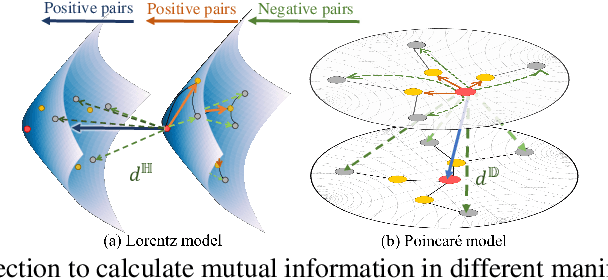

Recently, hyperbolic space has risen as a promising alternative for semi-supervised graph representation learning. Many efforts have been made to design hyperbolic versions of neural network operations. However, the inspiring geometric properties of this unique geometry have not been fully explored yet. The potency of graph models powered by the hyperbolic space is still largely underestimated. Besides, the rich information carried by abundant unlabelled samples is also not well utilized. Inspired by the recently active and emerging self-supervised learning, in this study, we attempt to enhance the representation power of hyperbolic graph models by drawing upon the advantages of contrastive learning. More specifically, we put forward a novel Hyperbolic Graph Contrastive Learning (HGCL) framework which learns node representations through multiple hyperbolic spaces to implicitly capture the hierarchical structure shared between different views. Then, we design a hyperbolic position consistency (HPC) constraint based on hyperbolic distance and the homophily assumption to make contrastive learning fit into hyperbolic space. Experimental results on multiple real-world datasets demonstrate the superiority of the proposed HGCL as it consistently outperforms competing methods by considerable margins for the node classification task.
KARL-Trans-NER: Knowledge Aware Representation Learning for Named Entity Recognition using Transformers
Nov 30, 2021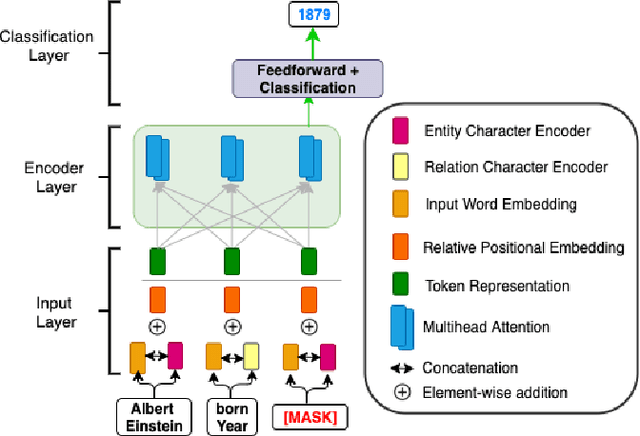
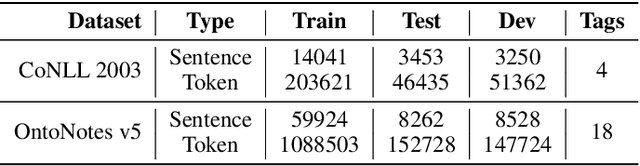
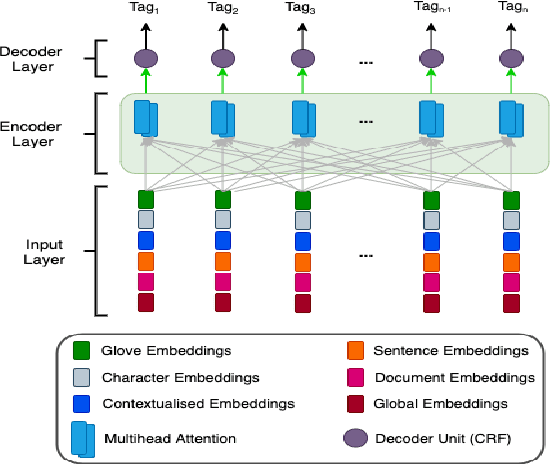
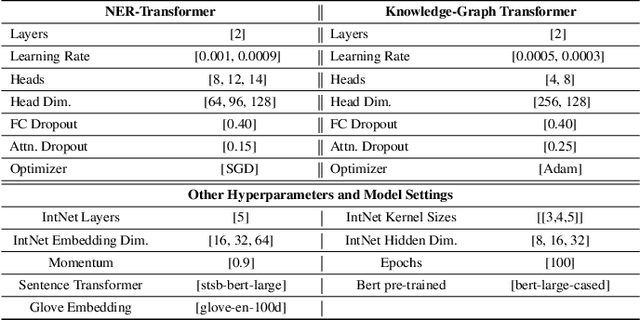
The inception of modeling contextual information using models such as BERT, ELMo, and Flair has significantly improved representation learning for words. It has also given SOTA results in almost every NLP task - Machine Translation, Text Summarization and Named Entity Recognition, to name a few. In this work, in addition to using these dominant context-aware representations, we propose a Knowledge Aware Representation Learning (KARL) Network for Named Entity Recognition (NER). We discuss the challenges of using existing methods in incorporating world knowledge for NER and show how our proposed methods could be leveraged to overcome those challenges. KARL is based on a Transformer Encoder that utilizes large knowledge bases represented as fact triplets, converts them to a graph context, and extracts essential entity information residing inside to generate contextualized triplet representation for feature augmentation. Experimental results show that the augmentation done using KARL can considerably boost the performance of our NER system and achieve significantly better results than existing approaches in the literature on three publicly available NER datasets, namely CoNLL 2003, CoNLL++, and OntoNotes v5. We also observe better generalization and application to a real-world setting from KARL on unseen entities.
Processing of large sets of stochastic signals: filtering based on piecewise interpolation technique
Nov 11, 2021

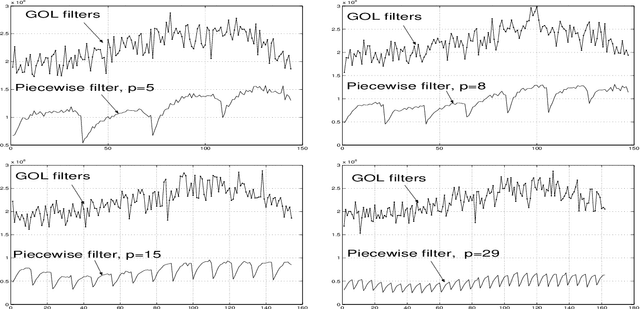

Suppose $K_{_Y}$ and $K_{_X}$ are large sets of observed and reference signals, respectively, each containing $N$ signals. Is it possible to construct a filter $F$ that requires a priori information only on few signals, $p\ll N$, from $K_{_X}$ but performs better than the known filters based on a priori information on every reference signal from $K_{_X}$? It is shown that the positive answer is achievable under quite unrestrictive assumptions. The device behind the proposed method is based on a special extension of the piecewise linear interpolation technique to the case of random signal sets. The proposed technique provides a single filter to process any signal from the arbitrarily large signal set. The filter is determined in terms of pseudo-inverse matrices so that it always exists.
Information Mandala: Statistical Distance Matrix with Its Clustering
Jun 07, 2020

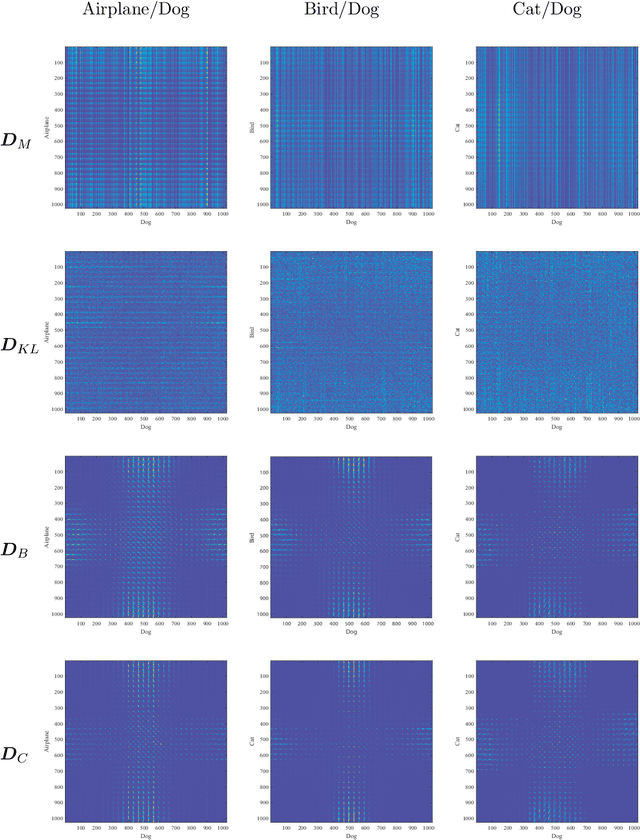
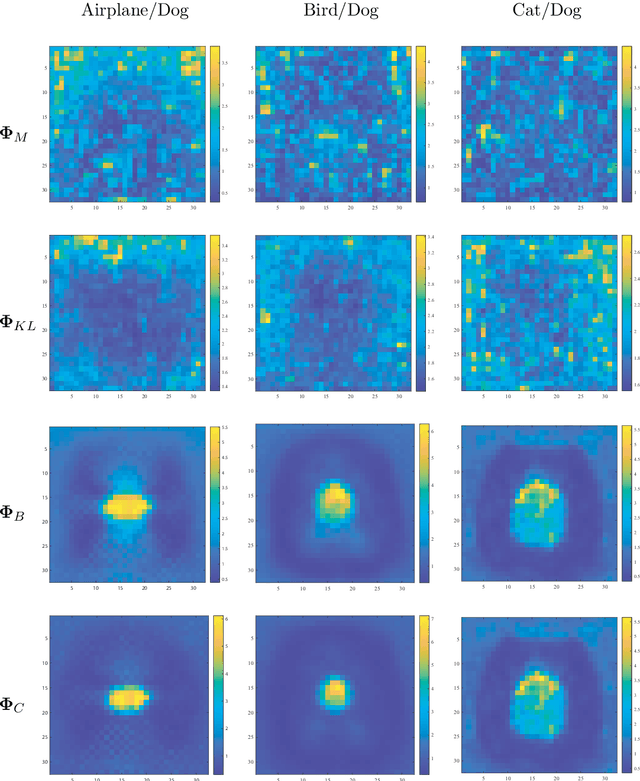
In machine learning, observation features are measured in a metric space to get their distance function for optimization. Given the similar features are many enough as a population in statistics, a statistical distance between two probability distributions can be calculated for more precise learning than before. Moreover, the statistical distance is still efficient enough, provided the observed features are multi-valued, but due to its scalar output it cannot be applied to represent detailed distances between feature elements. To resolve this problem, this paper extends the traditional statistical distance to a matrix form, referred as to statistical distance matrix, to achieve distance refinement. In experiments, the proposed statistical distance matrix performs so well in object recognition as to clearly and intuitively represent the differences between cat and dog images in the CIFAR dataset, even if it is directly calculated using the image pixels. By using the hierarchical clustering of the statistical distance matrix, the image pixels can be separated into several classes that are geometrically arranged around a center, like a Mandala pattern. The statistical distance matrix with its clustering called Information Mandala is beyond ordinary saliency map and helps to understand the basic principles of the convolution neural network.
Quantifying Layerwise Information Discarding of Neural Networks
Jun 10, 2019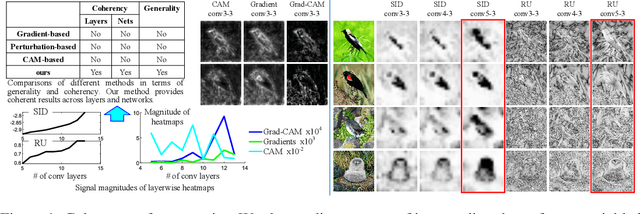
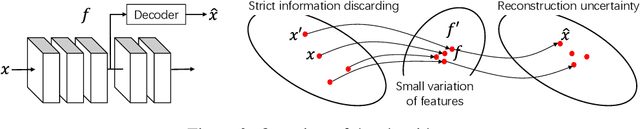

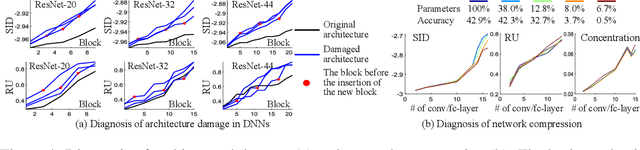
This paper presents a method to explain how input information is discarded through intermediate layers of a neural network during the forward propagation, in order to quantify and diagnose knowledge representations of pre-trained deep neural networks. We define two types of entropy-based metrics, i.e., the strict information discarding and the reconstruction uncertainty, which measure input information of a specific layer from two perspectives. We develop a method to enable efficient computation of such entropy-based metrics. Our method can be broadly applied to various neural networks and enable comprehensive comparisons between different layers of different networks. Preliminary experiments have shown the effectiveness of our metrics in analyzing benchmark networks and explaining existing deep-learning techniques.
Information State Embedding in Partially Observable Cooperative Multi-Agent Reinforcement Learning
Apr 18, 2020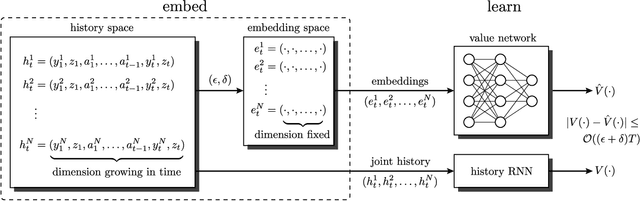
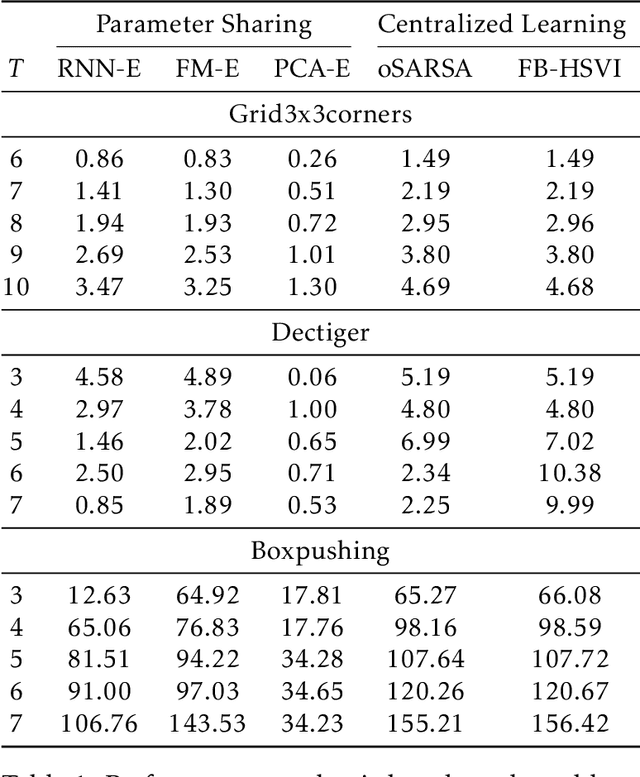
Multi-agent reinforcement learning (MARL) under partial observability has long been considered challenging, primarily due to the requirement for each agent to maintain a belief over all other agents' local histories -- a domain that generally grows exponentially over time. In this work, we investigate a partially observable MARL problem in which agents are cooperative. To enable the development of tractable algorithms, we introduce the concept of an information state embedding that serves to compress agents' histories. We quantify how the compression error influences the resulting value functions for decentralized control. Furthermore, we propose three natural embeddings, based on finite-memory truncation, principal component analysis, and recurrent neural networks. The output of these embeddings are then used as the information state, and can be fed into any MARL algorithm. The proposed embed-then-learn pipeline opens the black-box of existing MARL algorithms, allowing us to establish some theoretical guarantees (error bounds of value functions) while still achieving competitive performance with many end-to-end approaches.
Interactive Feature Fusion for End-to-End Noise-Robust Speech Recognition
Oct 11, 2021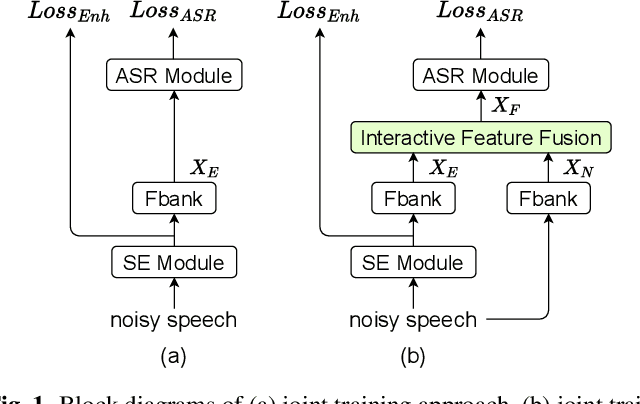
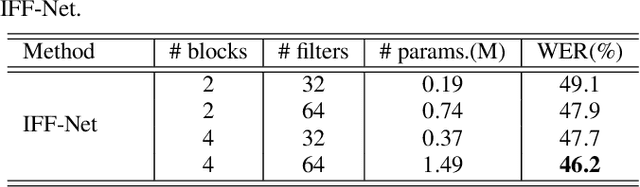
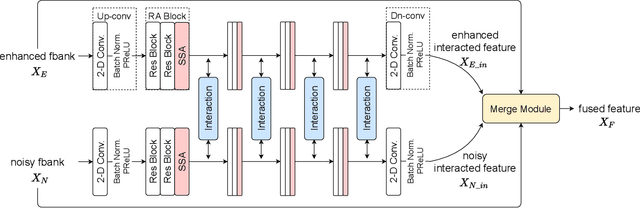
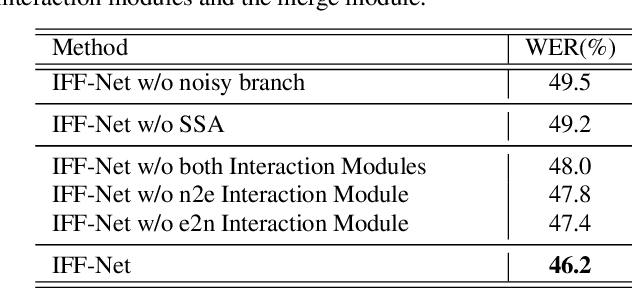
Speech enhancement (SE) aims to suppress the additive noise from a noisy speech signal to improve the speech's perceptual quality and intelligibility. However, the over-suppression phenomenon in the enhanced speech might degrade the performance of downstream automatic speech recognition (ASR) task due to the missing latent information. To alleviate such problem, we propose an interactive feature fusion network (IFF-Net) for noise-robust speech recognition to learn complementary information from the enhanced feature and original noisy feature. Experimental results show that the proposed method achieves absolute word error rate (WER) reduction of 4.1% over the best baseline on RATS Channel-A corpus. Our further analysis indicates that the proposed IFF-Net can complement some missing information in the over-suppressed enhanced feature.
Using Ballistocardiography for Sleep Stage Classification
Feb 02, 2022A practical way of detecting sleep stages has become more necessary as we begin to learn about the vast effects that sleep has on people's lives. The current methods of sleep stage detection are expensive, invasive to a person's sleep, and not practical in a modern home setting. While the method of detecting sleep stages via the monitoring of brain activity, muscle activity, and eye movement, through electroencephalogram in a lab setting, provide the gold standard for detection, this paper aims to investigate a new method that will allow a person to gain similar insight and results with no obtrusion to their normal sleeping habits. Ballistocardiography (BCG) is a non-invasive sensing technology that collects information by measuring the ballistic forces generated by the heart. Using features extracted from BCG such as time of usage, heart rate, respiration rate, relative stroke volume, and heart rate variability, we propose to implement a sleep stage detection algorithm and compare it against sleep stages extracted from a Fitbit Sense Smart Watch. The accessibility, ease of use, and relatively-low cost of the BCG offers many applications and advantages for using this device. By standardizing this device, people will be able to benefit from the BCG in analyzing their own sleep patterns and draw conclusions on their sleep efficiency. This work demonstrates the feasibility of using BCG for an accurate and non-invasive sleep monitoring method that can be set up in the comfort of a one's personal sleep environment.