 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Zero-Shot and Few-Shot Classification of Biomedical Articles in Context of the COVID-19 Pandemic
Jan 11, 2022
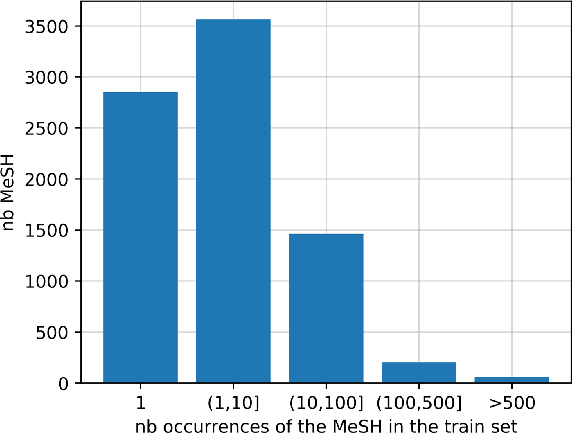
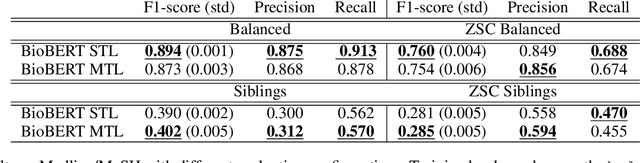
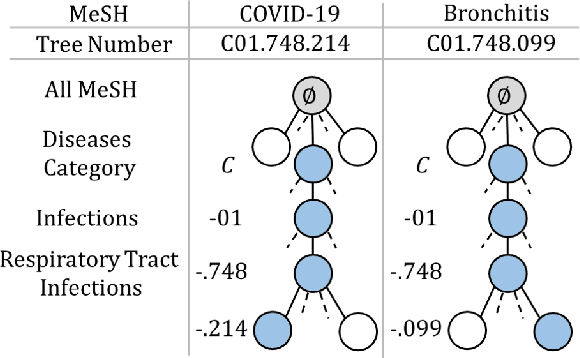
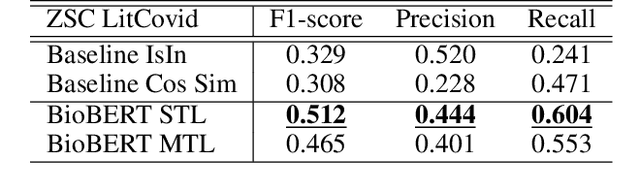
MeSH (Medical Subject Headings) is a large thesaurus created by the National Library of Medicine and used for fine-grained indexing of publications in the biomedical domain. In the context of the COVID-19 pandemic, MeSH descriptors have emerged in relation to articles published on the corresponding topic. Zero-shot classification is an adequate response for timely labeling of the stream of papers with MeSH categories. In this work, we hypothesise that rich semantic information available in MeSH has potential to improve BioBERT representations and make them more suitable for zero-shot/few-shot tasks. We frame the problem as determining if MeSH term definitions, concatenated with paper abstracts are valid instances or not, and leverage multi-task learning to induce the MeSH hierarchy in the representations thanks to a seq2seq task. Results establish a baseline on the MedLine and LitCovid datasets, and probing shows that the resulting representations convey the hierarchical relations present in MeSH.
S2MS: Self-Supervised Learning Driven Multi-Spectral CT Image Enhancement
Jan 26, 2022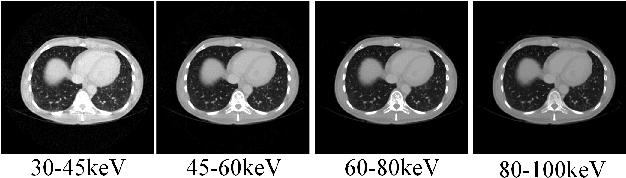
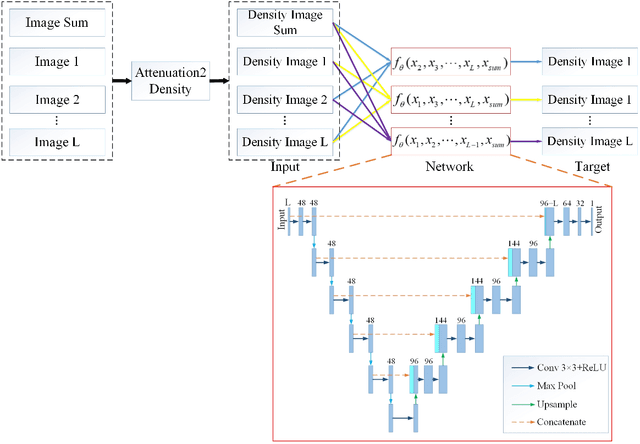
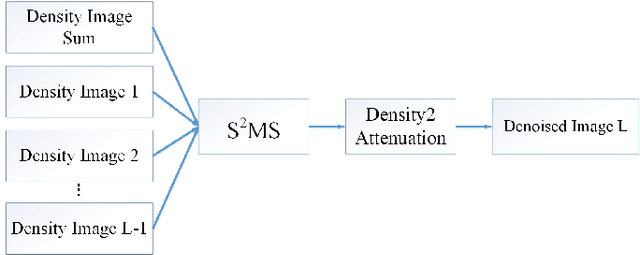
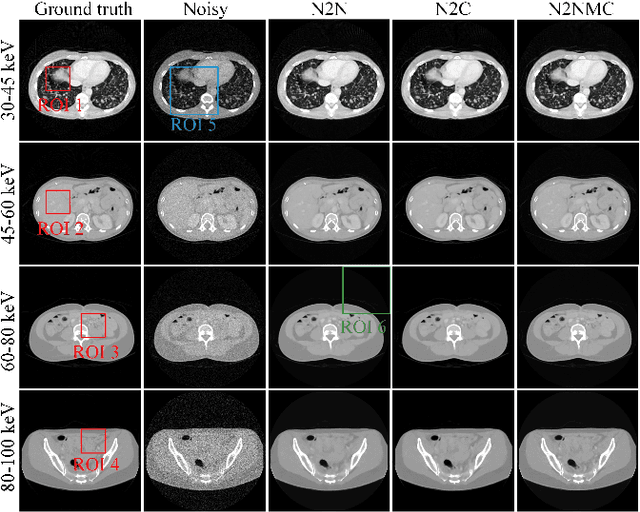
Photon counting spectral CT (PCCT) can produce reconstructed attenuation maps in different energy channels, reflecting energy properties of the scanned object. Due to the limited photon numbers and the non-ideal detector response of each energy channel, the reconstructed images usually contain much noise. With the development of Deep Learning (DL) technique, different kinds of DL-based models have been proposed for noise reduction. However, most of the models require clean data set as the training labels, which are not always available in medical imaging field. Inspiring by the similarities of each channel's reconstructed image, we proposed a self-supervised learning based PCCT image enhancement framework via multi-spectral channels (S2MS). In S2MS framework, both the input and output labels are noisy images. Specifically, one single channel image was used as output while images of other single channels and channel-sum image were used as input to train the network, which can fully use the spectral data information without extra cost. The simulation results based on the AAPM Low-dose CT Challenge database showed that the proposed S2MS model can suppress the noise and preserve details more effectively in comparison with the traditional DL models, which has potential to improve the image quality of PCCT in clinical applications.
Memory-Augmented Deep Unfolding Network for Compressive Sensing
Oct 25, 2021
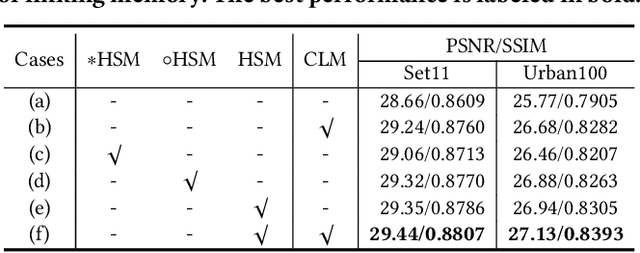
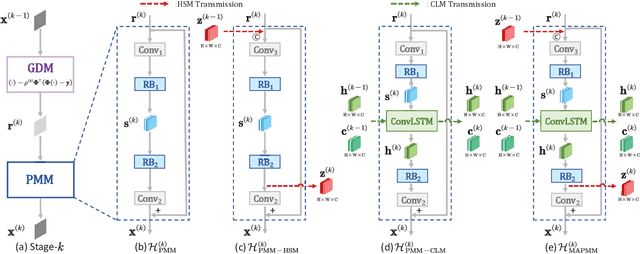
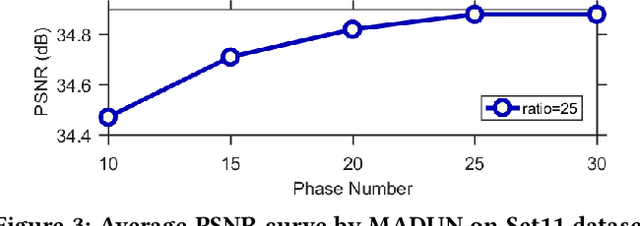
Mapping a truncated optimization method into a deep neural network, deep unfolding network (DUN) has attracted growing attention in compressive sensing (CS) due to its good interpretability and high performance. Each stage in DUNs corresponds to one iteration in optimization. By understanding DUNs from the perspective of the human brain's memory processing, we find there exists two issues in existing DUNs. One is the information between every two adjacent stages, which can be regarded as short-term memory, is usually lost seriously. The other is no explicit mechanism to ensure that the previous stages affect the current stage, which means memory is easily forgotten. To solve these issues, in this paper, a novel DUN with persistent memory for CS is proposed, dubbed Memory-Augmented Deep Unfolding Network (MADUN). We design a memory-augmented proximal mapping module (MAPMM) by combining two types of memory augmentation mechanisms, namely High-throughput Short-term Memory (HSM) and Cross-stage Long-term Memory (CLM). HSM is exploited to allow DUNs to transmit multi-channel short-term memory, which greatly reduces information loss between adjacent stages. CLM is utilized to develop the dependency of deep information across cascading stages, which greatly enhances network representation capability. Extensive CS experiments on natural and MR images show that with the strong ability to maintain and balance information our MADUN outperforms existing state-of-the-art methods by a large margin. The source code is available at https://github.com/jianzhangcs/MADUN/.
Low-confidence Samples Matter for Domain Adaptation
Feb 06, 2022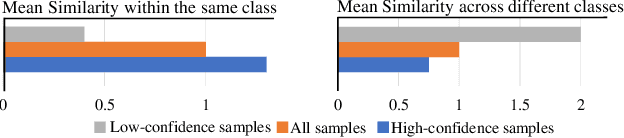
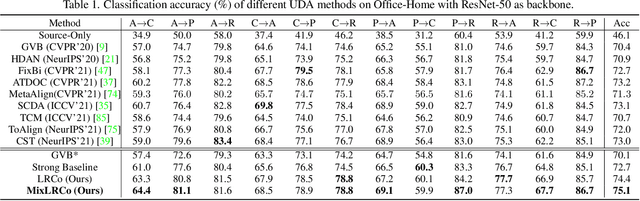
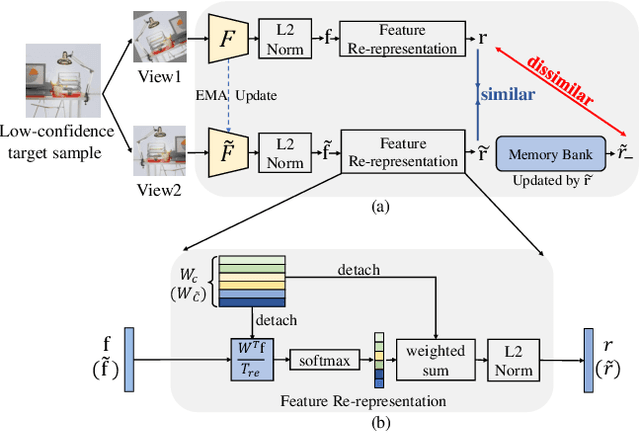
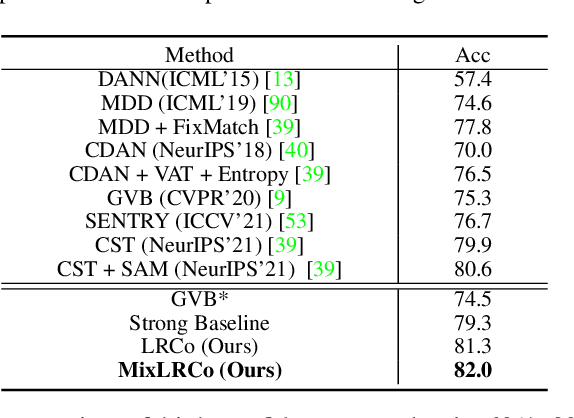
Domain adaptation (DA) aims to transfer knowledge from a label-rich source domain to a related but label-scarce target domain. The conventional DA strategy is to align the feature distributions of the two domains. Recently, increasing researches have focused on self-training or other semi-supervised algorithms to explore the data structure of the target domain. However, the bulk of them depend largely on confident samples in order to build reliable pseudo labels, prototypes or cluster centers. Representing the target data structure in such a way would overlook the huge low-confidence samples, resulting in sub-optimal transferability that is biased towards the samples similar to the source domain. To overcome this issue, we propose a novel contrastive learning method by processing low-confidence samples, which encourages the model to make use of the target data structure through the instance discrimination process. To be specific, we create positive and negative pairs only using low-confidence samples, and then re-represent the original features with the classifier weights rather than directly utilizing them, which can better encode the task-specific semantic information. Furthermore, we combine cross-domain mixup to augment the proposed contrastive loss. Consequently, the domain gap can be well bridged through contrastive learning of intermediate representations across domains. We evaluate the proposed method in both unsupervised and semi-supervised DA settings, and extensive experimental results on benchmarks reveal that our method is effective and achieves state-of-the-art performance. The code can be found in https://github.com/zhyx12/MixLRCo.
Stock Movement Prediction Based on Bi-typed and Hybrid-relational Market Knowledge Graph via Dual Attention Networks
Jan 11, 2022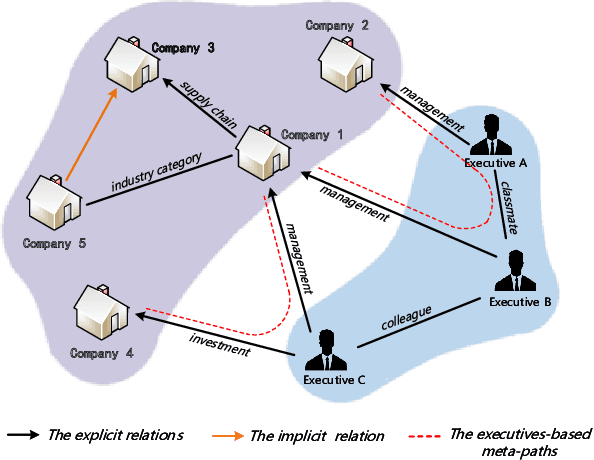
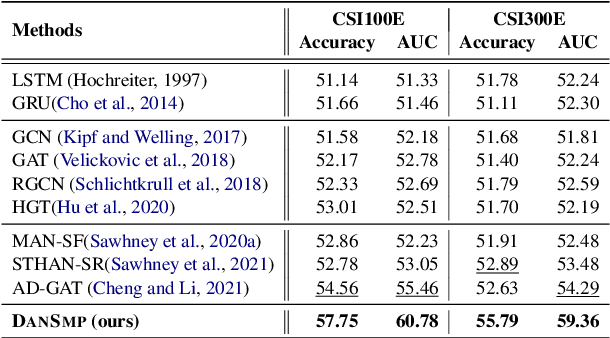
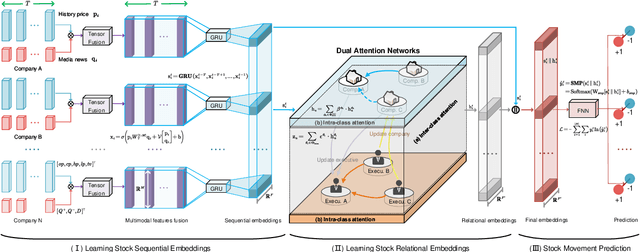
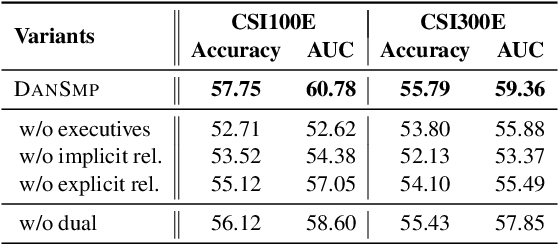
Stock Movement Prediction (SMP) aims at predicting listed companies' stock future price trend, which is a challenging task due to the volatile nature of financial markets. Recent financial studies show that the momentum spillover effect plays a significant role in stock fluctuation. However, previous studies typically only learn the simple connection information among related companies, which inevitably fail to model complex relations of listed companies in the real financial market. To address this issue, we first construct a more comprehensive Market Knowledge Graph (MKG) which contains bi-typed entities including listed companies and their associated executives, and hybrid-relations including the explicit relations and implicit relations. Afterward, we propose DanSmp, a novel Dual Attention Networks to learn the momentum spillover signals based upon the constructed MKG for stock prediction. The empirical experiments on our constructed datasets against nine SOTA baselines demonstrate that the proposed DanSmp is capable of improving stock prediction with the constructed MKG.
A novel audio representation using space filling curves
Jan 08, 2022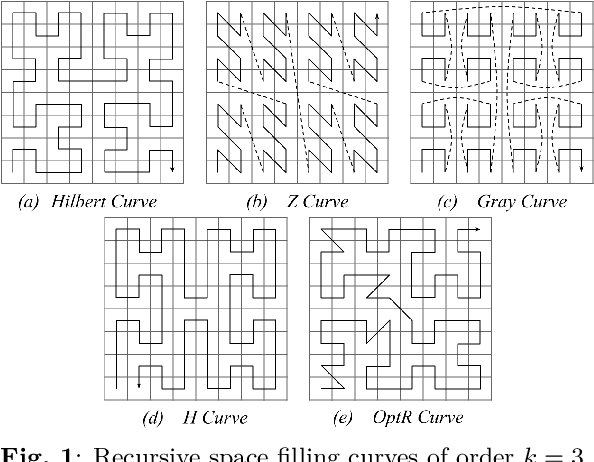
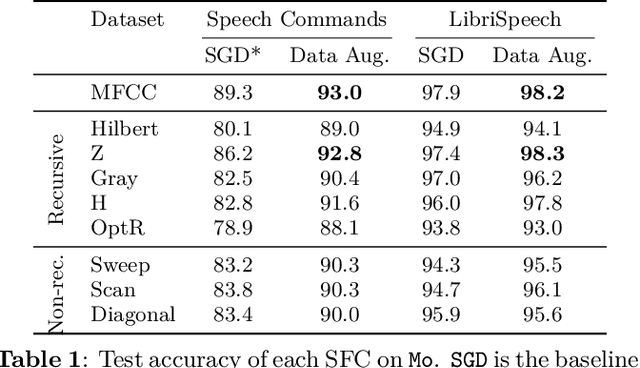
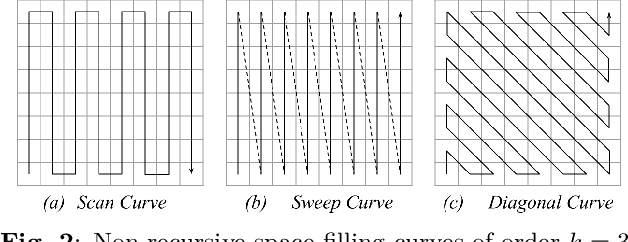
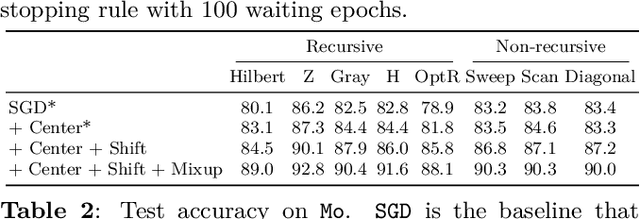
Since convolutional neural networks (CNNs) have revolutionized the image processing field, they have been widely applied in the audio context. A common approach is to convert the one-dimensional audio signal time series to two-dimensional images using a time-frequency decomposition method. Also it is common to discard the phase information. In this paper, we propose to map one-dimensional audio waveforms to two-dimensional images using space filling curves (SFCs). These mappings do not compress the input signal, while preserving its local structure. Moreover, the mappings benefit from progress made in deep learning and the large collection of existing computer vision networks. We test eight SFCs on two keyword spotting problems. We show that the Z curve yields the best results due to its shift equivariance under convolution operations. Additionally, the Z curve produces comparable results to the widely used mel frequency cepstral coefficients across multiple CNNs.
When to Call Your Neighbor? Strategic Communication in Cooperative Stochastic Bandits
Oct 08, 2021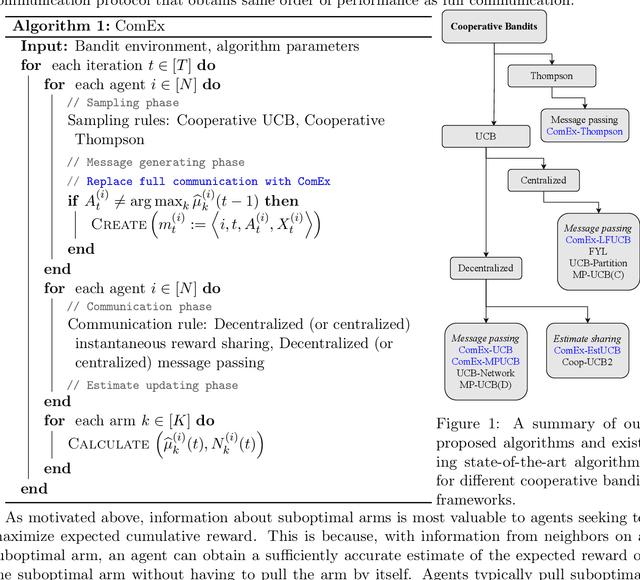
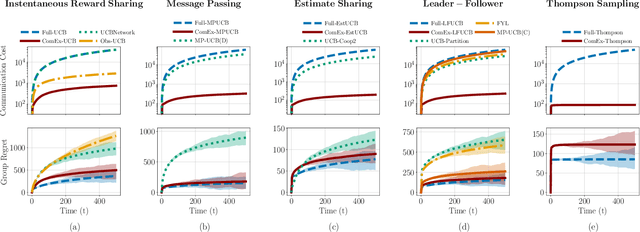
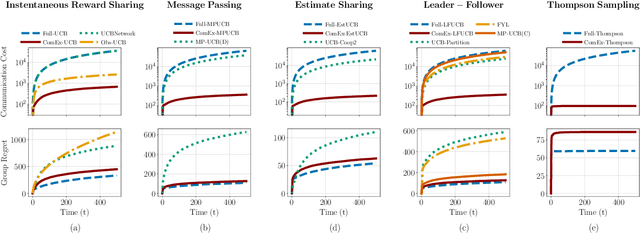
In cooperative bandits, a framework that captures essential features of collective sequential decision making, agents can minimize group regret, and thereby improve performance, by leveraging shared information. However, sharing information can be costly, which motivates developing policies that minimize group regret while also reducing the number of messages communicated by agents. Existing cooperative bandit algorithms obtain optimal performance when agents share information with their neighbors at \textit{every time step}, i.e., full communication. This requires $\Theta(T)$ number of messages, where $T$ is the time horizon of the decision making process. We propose \textit{ComEx}, a novel cost-effective communication protocol in which the group achieves the same order of performance as full communication while communicating only $O(\log T)$ number of messages. Our key step is developing a method to identify and only communicate the information crucial to achieving optimal performance. Further we propose novel algorithms for several benchmark cooperative bandit frameworks and show that our algorithms obtain \textit{state-of-the-art} performance while consistently incurring a significantly smaller communication cost than existing algorithms.
Quantifying Layerwise Information Discarding of Neural Networks
Jun 10, 2019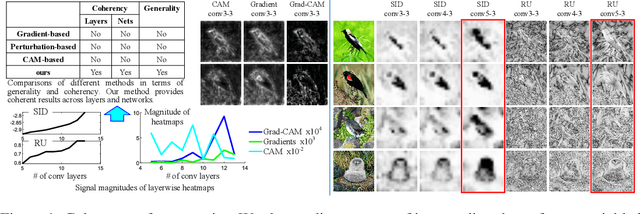
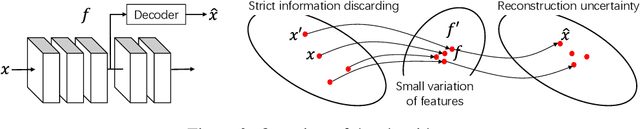

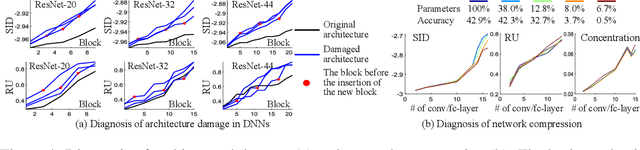
This paper presents a method to explain how input information is discarded through intermediate layers of a neural network during the forward propagation, in order to quantify and diagnose knowledge representations of pre-trained deep neural networks. We define two types of entropy-based metrics, i.e., the strict information discarding and the reconstruction uncertainty, which measure input information of a specific layer from two perspectives. We develop a method to enable efficient computation of such entropy-based metrics. Our method can be broadly applied to various neural networks and enable comprehensive comparisons between different layers of different networks. Preliminary experiments have shown the effectiveness of our metrics in analyzing benchmark networks and explaining existing deep-learning techniques.
An AI-based Domain-Decomposition Non-Intrusive Reduced-Order Model for Extended Domains applied to Multiphase Flow in Pipes
Feb 13, 2022

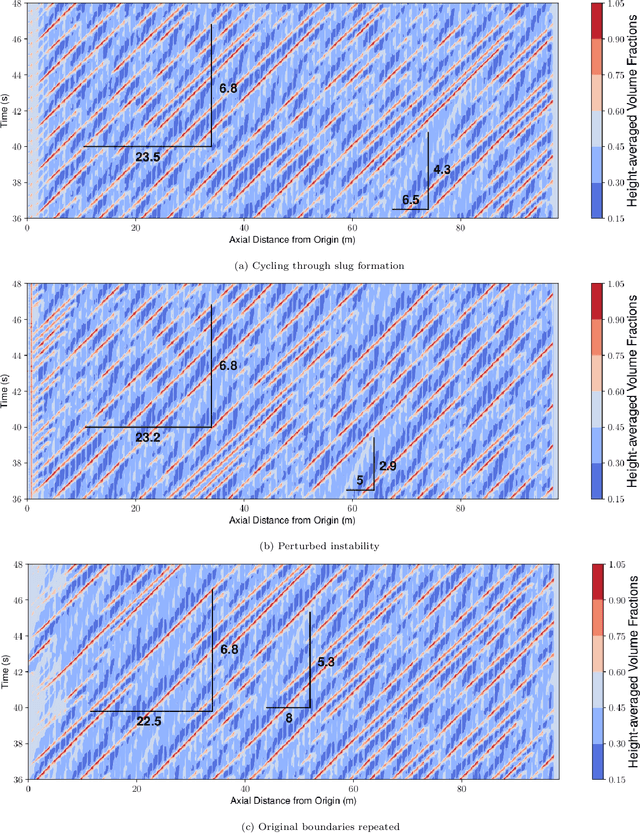
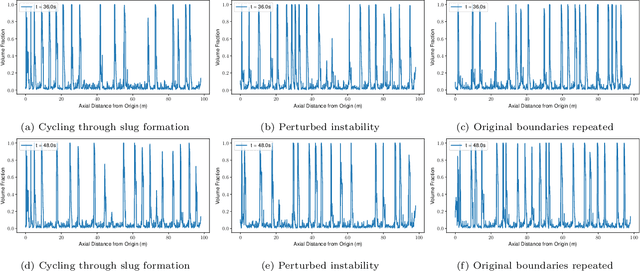
The modelling of multiphase flow in a pipe presents a significant challenge for high-resolution computational fluid dynamics (CFD) models due to the high aspect ratio (length over diameter) of the domain. In subsea applications, the pipe length can be several hundreds of kilometres versus a pipe diameter of just a few inches. In this paper, we present a new AI-based non-intrusive reduced-order model within a domain decomposition framework (AI-DDNIROM) which is capable of making predictions for domains significantly larger than the domain used in training. This is achieved by using domain decomposition; dimensionality reduction; training a neural network to make predictions for a single subdomain; and by using an iteration-by-subdomain technique to converge the solution over the whole domain. To find the low-dimensional space, we explore several types of autoencoder networks, known for their ability to compress information accurately and compactly. The performance of the autoencoders is assessed on two advection-dominated problems: flow past a cylinder and slug flow in a pipe. To make predictions in time, we exploit an adversarial network which aims to learn the distribution of the training data, in addition to learning the mapping between particular inputs and outputs. This type of network has shown the potential to produce realistic outputs. The whole framework is applied to multiphase slug flow in a horizontal pipe for which an AI-DDNIROM is trained on high-fidelity CFD simulations of a pipe of length 10 m with an aspect ratio of 13:1, and tested by simulating the flow for a pipe of length 98 m with an aspect ratio of almost 130:1. Statistics of the flows obtained from the CFD simulations are compared to those of the AI-DDNIROM predictions to demonstrate the success of our approach.
Real-World Semantic Grasping Detection
Nov 20, 2021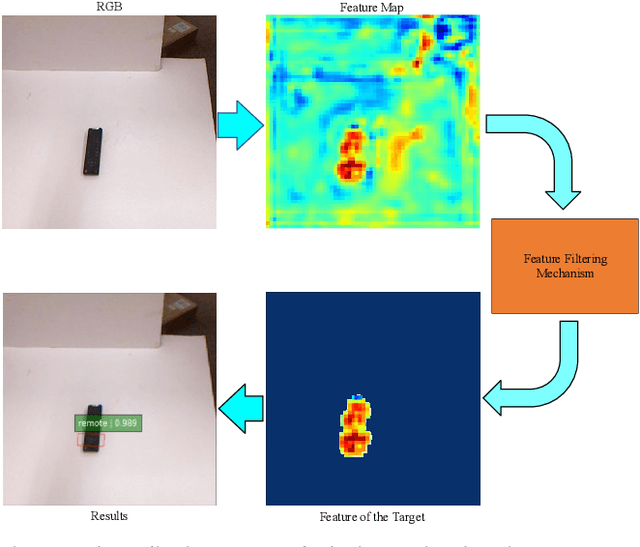
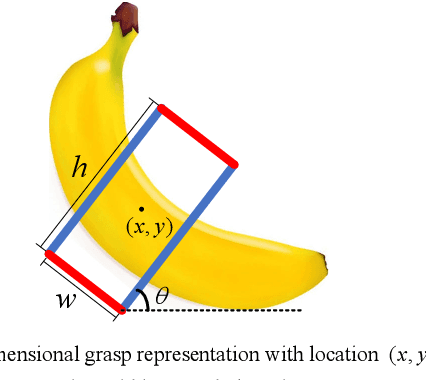
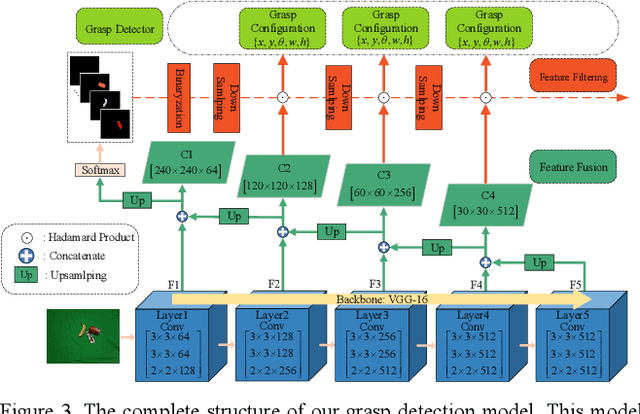

Reducing the scope of grasping detection according to the semantic information of the target is significant to improve the accuracy of the grasping detection model and expand its application. Researchers have been trying to combine these capabilities in an end-to-end network to grasp specific objects in a cluttered scene efficiently. In this paper, we propose an end-to-end semantic grasping detection model, which can accomplish both semantic recognition and grasping detection. And we also design a target feature filtering mechanism, which only maintains the features of a single object according to the semantic information for grasping detection. This method effectively reduces the background features that are weakly correlated to the target object, thus making the features more unique and guaranteeing the accuracy and efficiency of grasping detection. Experimental results show that the proposed method can achieve 98.38% accuracy in Cornell grasping dataset Furthermore, our results on different datasets or evaluation metrics show the domain adaptability of our method over the state-of-the-art.