 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Identity Conversion for Emotional Speakers: A Study for Disentanglement of Emotion Style and Speaker Identity
Oct 20, 2021
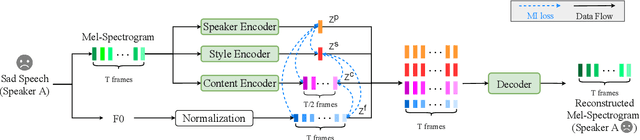
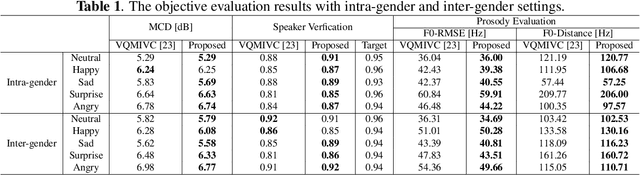

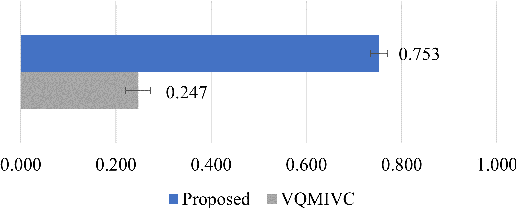
Expressive voice conversion performs identity conversion for emotional speakers by jointly converting speaker identity and speaker-dependent emotion style. Due to the hierarchical structure of speech emotion, it is challenging to disentangle the speaker-dependent emotional style for expressive voice conversion. Motivated by the recent success on speaker disentanglement with variational autoencoder (VAE), we propose an expressive voice conversion framework which can effectively disentangle linguistic content, speaker identity, pitch, and emotional style information. We study the use of emotion encoder to model emotional style explicitly, and introduce mutual information (MI) losses to reduce the irrelevant information from the disentangled emotion representations. At run-time, our proposed framework can convert both speaker identity and speaker-dependent emotional style without the need for parallel data. Experimental results validate the effectiveness of our proposed framework in both objective and subjective evaluations.
A Mutual Information Maximization Perspective of Language Representation Learning
Nov 26, 2019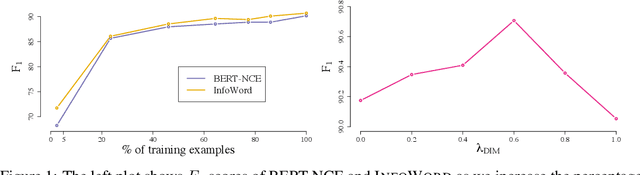
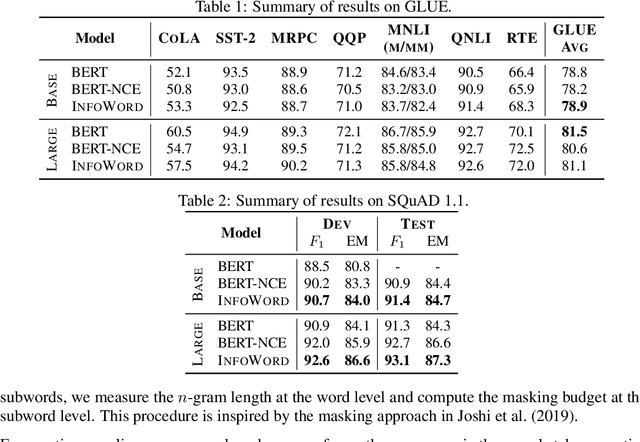
We show state-of-the-art word representation learning methods maximize an objective function that is a lower bound on the mutual information between different parts of a word sequence (i.e., a sentence). Our formulation provides an alternative perspective that unifies classical word embedding models (e.g., Skip-gram) and modern contextual embeddings (e.g., BERT, XLNet). In addition to enhancing our theoretical understanding of these methods, our derivation leads to a principled framework that can be used to construct new self-supervised tasks. We provide an example by drawing inspirations from related methods based on mutual information maximization that have been successful in computer vision, and introduce a simple self-supervised objective that maximizes the mutual information between a global sentence representation and n-grams in the sentence. Our analysis offers a holistic view of representation learning methods to transfer knowledge and translate progress across multiple domains (e.g., natural language processing, computer vision, audio processing).
Assemble Foundation Models for Automatic Code Summarization
Jan 13, 2022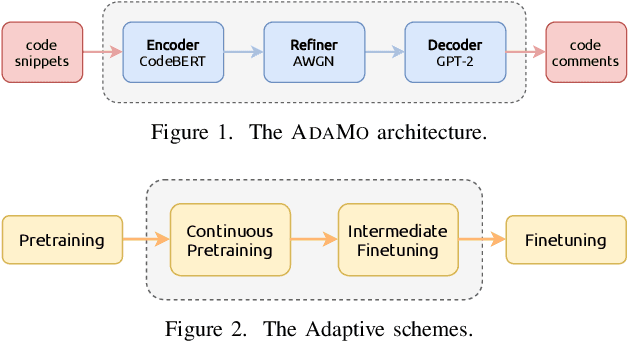
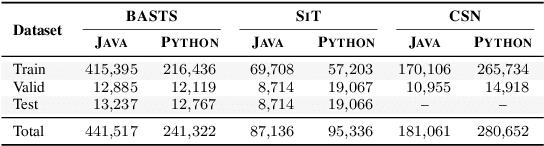
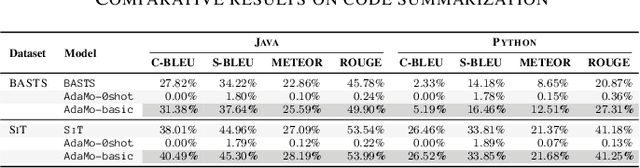
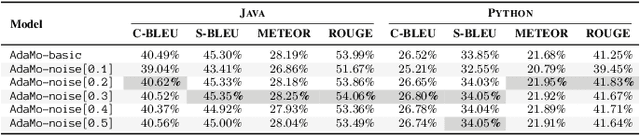
Automatic code summarization is beneficial to software development and maintenance since it reduces the burden of manual tasks. Currently, artificial intelligence is undergoing a paradigm shift. The foundation models pretrained on massive data and finetuned to downstream tasks surpass specially customized models. This trend inspired us to consider reusing foundation models instead of learning from scratch. Based on this, we propose a flexible and robust approach for automatic code summarization based on neural networks. We assemble available foundation models, such as CodeBERT and GPT-2, into a single model named AdaMo. Moreover, we utilize Gaussian noise as the simulation of contextual information to optimize the latent representation. Furthermore, we introduce two adaptive schemes from the perspective of knowledge transfer, namely continuous pretraining and intermediate finetuning, and design intermediate stage tasks for general sequence-to-sequence learning. Finally, we evaluate AdaMo against a benchmark dataset for code summarization, by comparing it with state-of-the-art models.
Robotic Tissue Sampling for Safe Post-mortem Biopsy in Infectious Corpses
Jan 28, 2022
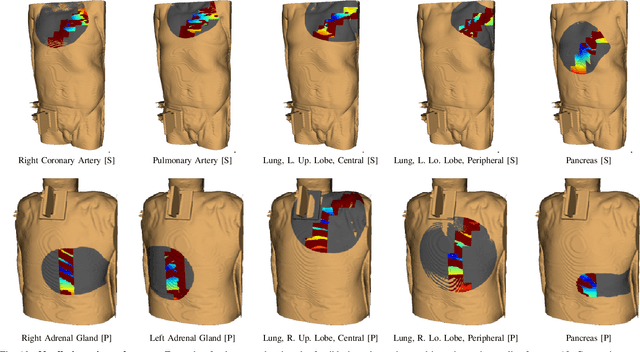
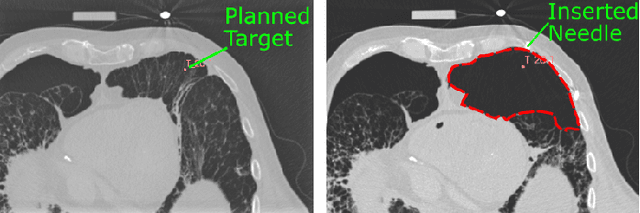
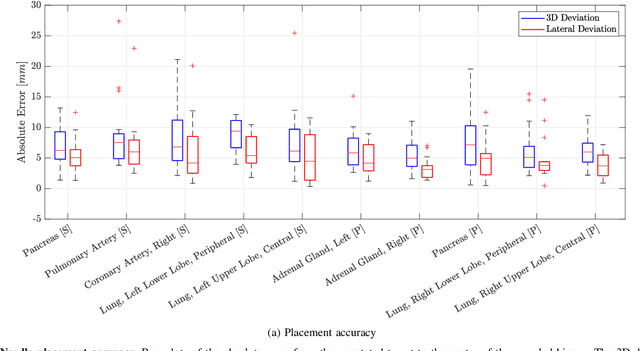
In pathology and legal medicine, the histopathological and microbiological analysis of tissue samples from infected deceased is a valuable information for developing treatment strategies during a pandemic such as COVID-19. However, a conventional autopsy carries the risk of disease transmission and may be rejected by relatives. We propose minimally invasive biopsy with robot assistance under CT guidance to minimize the risk of disease transmission during tissue sampling and to improve accuracy. A flexible robotic system for biopsy sampling is presented, which is applied to human corpses placed inside protective body bags. An automatic planning and decision system estimates optimal insertion point. Heat maps projected onto the segmented skin visualize the distance and angle of insertions and estimate the minimum cost of a puncture while avoiding bone collisions. Further, we test multiple insertion paths concerning feasibility and collisions. A custom end effector is designed for inserting needles and extracting tissue samples under robotic guidance. Our robotic post-mortem biopsy (RPMB) system is evaluated in a study during the COVID-19 pandemic on 20 corpses and 10 tissue targets, 5 of them being infected with SARS-CoV-2. The mean planning time including robot path planning is (5.72+-1.67) s. Mean needle placement accuracy is (7.19+-4.22) mm.
Variational Auto-Encoder Based Variability Encoding for Dysarthric Speech Recognition
Jan 24, 2022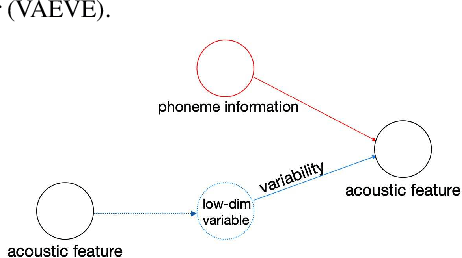
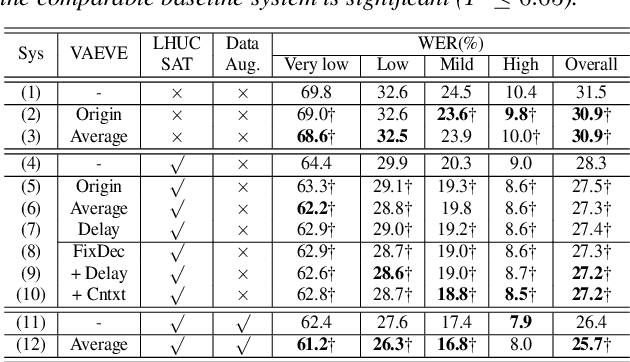
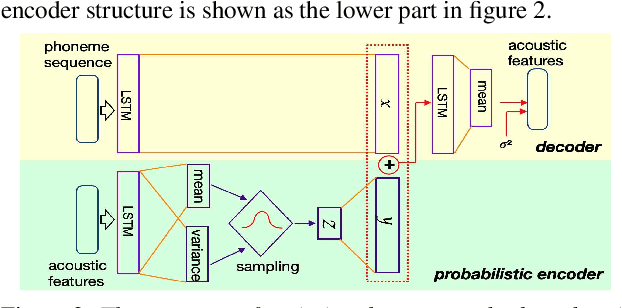
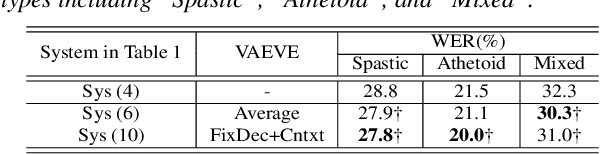
Dysarthric speech recognition is a challenging task due to acoustic variability and limited amount of available data. Diverse conditions of dysarthric speakers account for the acoustic variability, which make the variability difficult to be modeled precisely. This paper presents a variational auto-encoder based variability encoder (VAEVE) to explicitly encode such variability for dysarthric speech. The VAEVE makes use of both phoneme information and low-dimensional latent variable to reconstruct the input acoustic features, thereby the latent variable is forced to encode the phoneme-independent variability. Stochastic gradient variational Bayes algorithm is applied to model the distribution for generating variability encodings, which are further used as auxiliary features for DNN acoustic modeling. Experiment results conducted on the UASpeech corpus show that the VAEVE based variability encodings have complementary effect to the learning hidden unit contributions (LHUC) speaker adaptation. The systems using variability encodings consistently outperform the comparable baseline systems without using them, and" obtain absolute word error rate (WER) reduction by up to 2.2% on dysarthric speech with "Very lowintelligibility level, and up to 2% on the "Mixed" type of dysarthric speech with diverse or uncertain conditions.
Explainable Decision Making with Lean and Argumentative Explanations
Jan 24, 2022

It is widely acknowledged that transparency of automated decision making is crucial for deployability of intelligent systems, and explaining the reasons why some decisions are "good" and some are not is a way to achieving this transparency. We consider two variants of decision making, where "good" decisions amount to alternatives (i) meeting "most" goals, and (ii) meeting "most preferred" goals. We then define, for each variant and notion of "goodness" (corresponding to a number of existing notions in the literature), explanations in two formats, for justifying the selection of an alternative to audiences with differing needs and competences: lean explanations, in terms of goals satisfied and, for some notions of "goodness", alternative decisions, and argumentative explanations, reflecting the decision process leading to the selection, while corresponding to the lean explanations. To define argumentative explanations, we use assumption-based argumentation (ABA), a well-known form of structured argumentation. Specifically, we define ABA frameworks such that "good" decisions are admissible ABA arguments and draw argumentative explanations from dispute trees sanctioning this admissibility. Finally, we instantiate our overall framework for explainable decision-making to accommodate connections between goals and decisions in terms of decision graphs incorporating defeasible and non-defeasible information.
FairEdit: Preserving Fairness in Graph Neural Networks through Greedy Graph Editing
Jan 10, 2022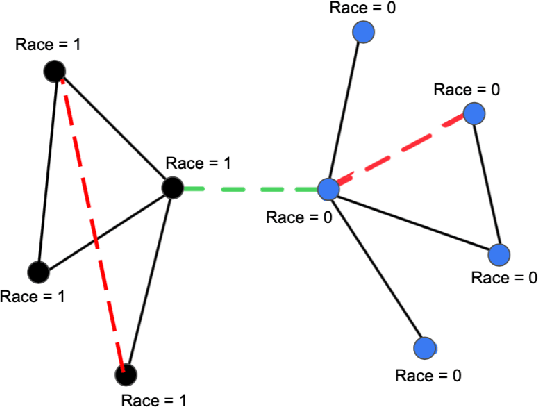
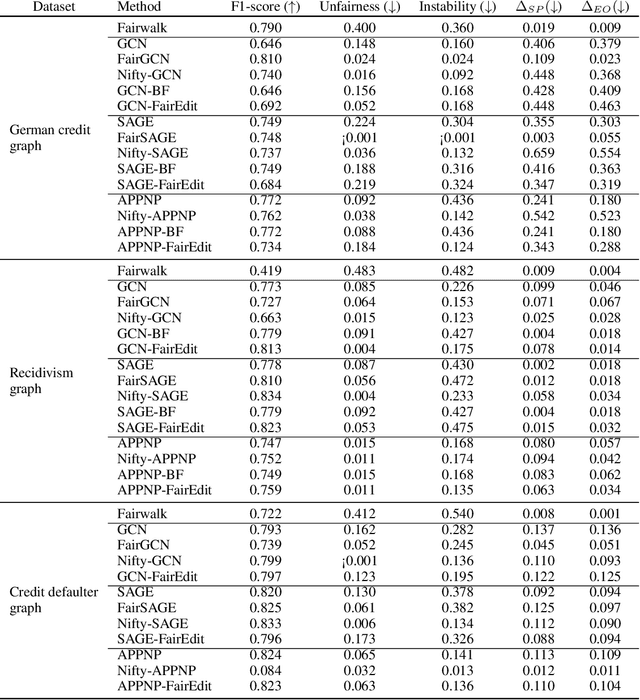
Graph Neural Networks (GNNs) have proven to excel in predictive modeling tasks where the underlying data is a graph. However, as GNNs are extensively used in human-centered applications, the issue of fairness has arisen. While edge deletion is a common method used to promote fairness in GNNs, it fails to consider when data is inherently missing fair connections. In this work we consider the unexplored method of edge addition, accompanied by deletion, to promote fairness. We propose two model-agnostic algorithms to perform edge editing: a brute force approach and a continuous approximation approach, FairEdit. FairEdit performs efficient edge editing by leveraging gradient information of a fairness loss to find edges that improve fairness. We find that FairEdit outperforms standard training for many data sets and GNN methods, while performing comparably to many state-of-the-art methods, demonstrating FairEdit's ability to improve fairness across many domains and models.
Pythia: A Customizable Hardware Prefetching Framework Using Online Reinforcement Learning
Oct 19, 2021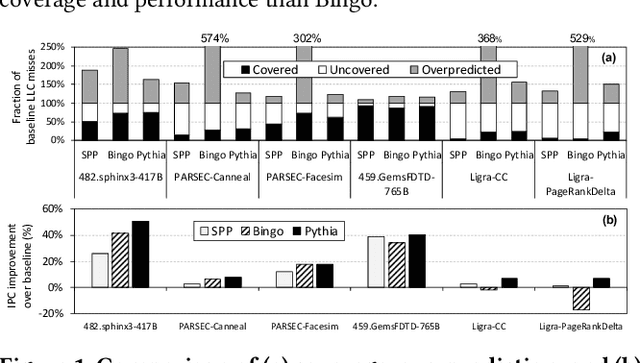
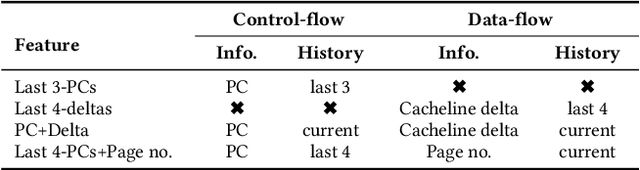

Past research has proposed numerous hardware prefetching techniques, most of which rely on exploiting one specific type of program context information (e.g., program counter, cacheline address) to predict future memory accesses. These techniques either completely neglect a prefetcher's undesirable effects (e.g., memory bandwidth usage) on the overall system, or incorporate system-level feedback as an afterthought to a system-unaware prefetch algorithm. We show that prior prefetchers often lose their performance benefit over a wide range of workloads and system configurations due to their inherent inability to take multiple different types of program context and system-level feedback information into account while prefetching. In this paper, we make a case for designing a holistic prefetch algorithm that learns to prefetch using multiple different types of program context and system-level feedback information inherent to its design. To this end, we propose Pythia, which formulates the prefetcher as a reinforcement learning agent. For every demand request, Pythia observes multiple different types of program context information to make a prefetch decision. For every prefetch decision, Pythia receives a numerical reward that evaluates prefetch quality under the current memory bandwidth usage. Pythia uses this reward to reinforce the correlation between program context information and prefetch decision to generate highly accurate, timely, and system-aware prefetch requests in the future. Our extensive evaluations using simulation and hardware synthesis show that Pythia outperforms multiple state-of-the-art prefetchers over a wide range of workloads and system configurations, while incurring only 1.03% area overhead over a desktop-class processor and no software changes in workloads. The source code of Pythia can be freely downloaded from https://github.com/CMU-SAFARI/Pythia.
Dynamic Graph Representation Learning via Graph Transformer Networks
Nov 19, 2021
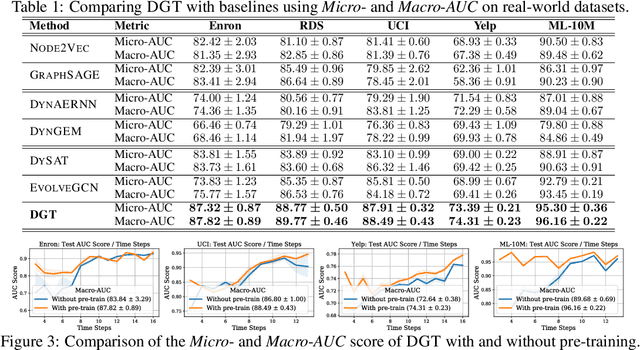
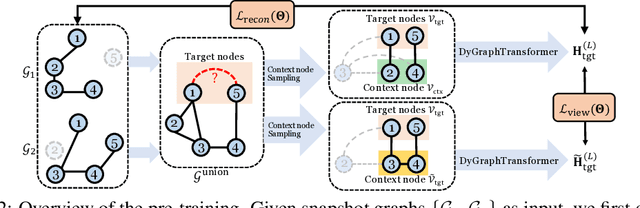
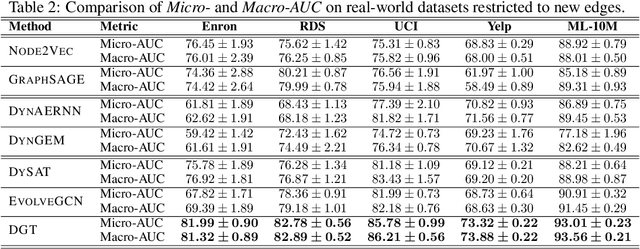
Dynamic graph representation learning is an important task with widespread applications. Previous methods on dynamic graph learning are usually sensitive to noisy graph information such as missing or spurious connections, which can yield degenerated performance and generalization. To overcome this challenge, we propose a Transformer-based dynamic graph learning method named Dynamic Graph Transformer (DGT) with spatial-temporal encoding to effectively learn graph topology and capture implicit links. To improve the generalization ability, we introduce two complementary self-supervised pre-training tasks and show that jointly optimizing the two pre-training tasks results in a smaller Bayesian error rate via an information-theoretic analysis. We also propose a temporal-union graph structure and a target-context node sampling strategy for efficient and scalable training. Extensive experiments on real-world datasets illustrate that DGT presents superior performance compared with several state-of-the-art baselines.
Reasoning for Complex Data through Ensemble-based Self-Supervised Learning
Feb 09, 2022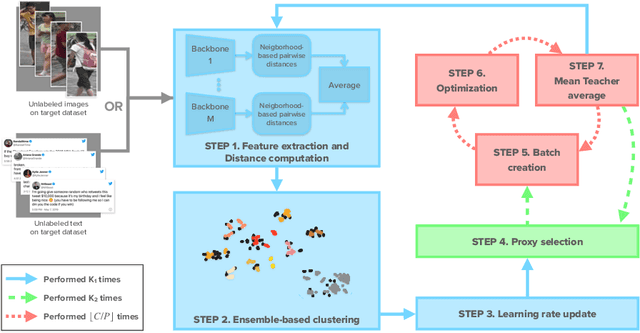
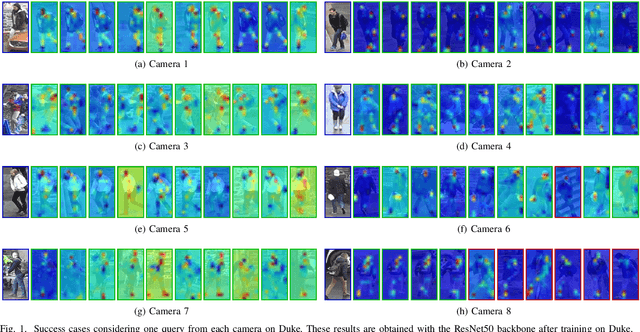
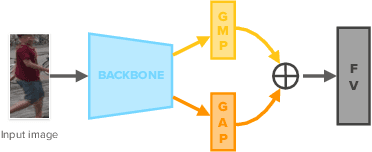
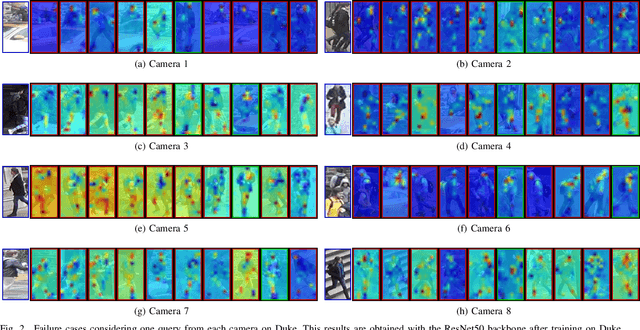
Self-supervised learning deals with problems that have little or no available labeled data. Recent work has shown impressive results when underlying classes have significant semantic differences. One important dataset in which this technique thrives is ImageNet, as intra-class distances are substantially lower than inter-class distances. However, this is not the case for several critical tasks, and general self-supervised learning methods fail to learn discriminative features when classes have closer semantics, thus requiring more robust strategies. We propose a strategy to tackle this problem, and to enable learning from unlabeled data even when samples from different classes are not prominently diverse. We approach the problem by leveraging a novel ensemble-based clustering strategy where clusters derived from different configurations are combined to generate a better grouping for the data samples in a fully-unsupervised way. This strategy allows clusters with different densities and higher variability to emerge, which in turn reduces intra-class discrepancies, without requiring the burden of finding an optimal configuration per dataset. We also consider different Convolutional Neural Networks to compute distances between samples. We refine these distances by performing context analysis and group them to capture complementary information. We consider two applications to validate our pipeline: Person Re-Identification and Text Authorship Verification. These are challenging applications considering that classes are semantically close to each other and that training and test sets have disjoint identities. Our method is robust across different modalities and outperforms state-of-the-art results with a fully-unsupervised solution without any labeling or human intervention.