 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FedGCN: Convergence and Communication Tradeoffs in Federated Training of Graph Convolutional Networks
Jan 28, 2022
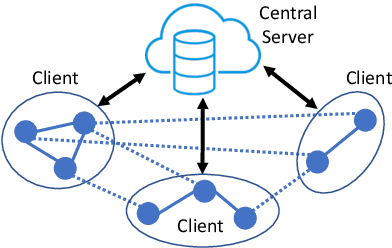

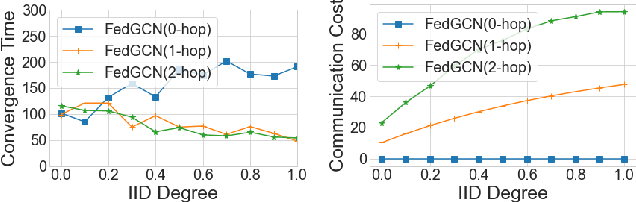
Distributed methods for training models on graph datasets have recently grown in popularity, due to the size of graph datasets as well as the private nature of graphical data like social networks. However, the graphical structure of this data means that it cannot be disjointly partitioned between different learning clients, leading to either significant communication overhead between clients or a loss of information available to the training method. We introduce Federated Graph Convolutional Network (FedGCN), which uses federated learning to train GCN models with optimized convergence rate and communication cost. Compared to prior methods that require communication among clients at each iteration, FedGCN preserves the privacy of client data and only needs communication at the initial step, which greatly reduces communication cost and speeds up the convergence rate. We theoretically analyze the tradeoff between FedGCN's convergence rate and communication cost under different data distributions, introducing a general framework can be generally used for the analysis of all edge-completion-based GCN training algorithms. Experimental results demonstrate the effectiveness of our algorithm and validate our theoretical analysis.
Multi-AAV Cooperative Path Planning using Nonlinear Model Predictive Control with Localization Constraints
Jan 23, 2022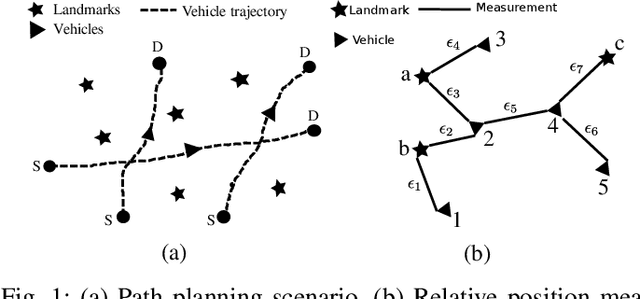
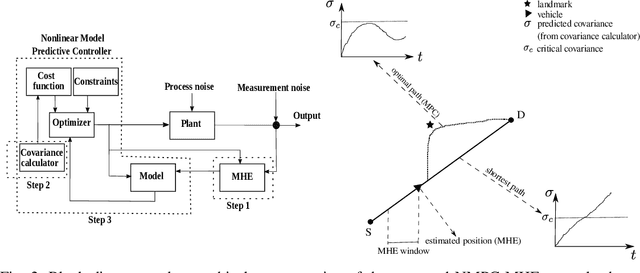
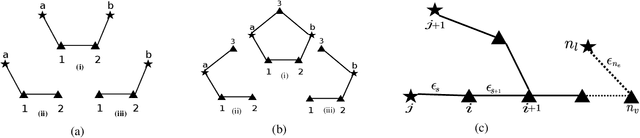
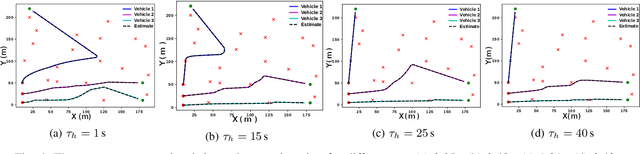
In this paper, we solve a joint cooperative localization and path planning problem for a group of Autonomous Aerial Vehicles (AAVs) in GPS-denied areas using nonlinear model predictive control (NMPC). A moving horizon estimator (MHE) is used to estimate the vehicle states with the help of relative bearing information to known landmarks and other vehicles. The goal of the NMPC is to devise optimal paths for each vehicle between a given source and destination while maintaining desired localization accuracy. Estimating localization covariance in the NMPC is computationally intensive, hence we develop an approximate analytical closed form expression based on the relationship between covariance and path lengths to landmarks. Using this expression while computing NMPC commands reduces the computational complexity significantly. We present numerical simulations to validate the proposed approach for different numbers of vehicles and landmark configurations. We also compare the results with EKF-based estimation to show the superiority of the proposed closed form approach.
Multimodal Maximum Entropy Dynamic Games
Feb 02, 2022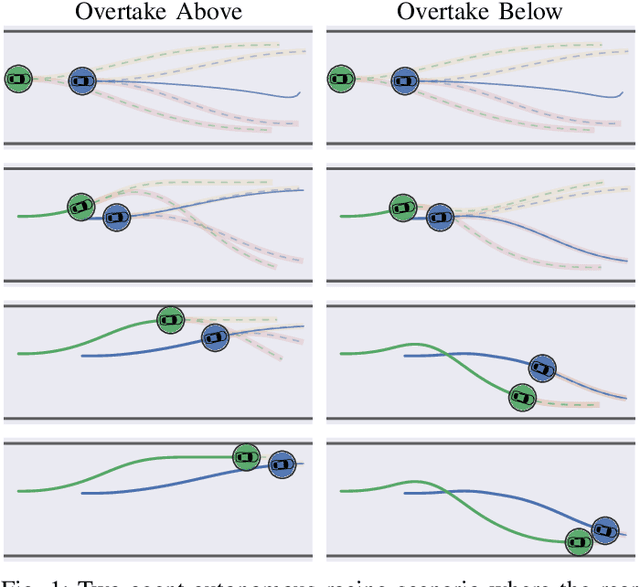
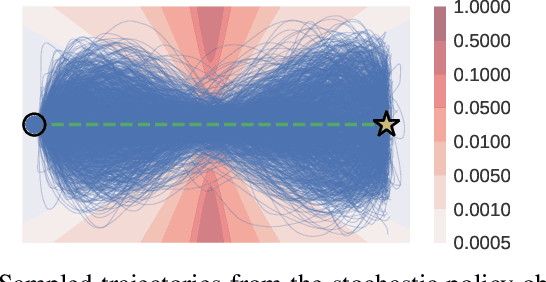
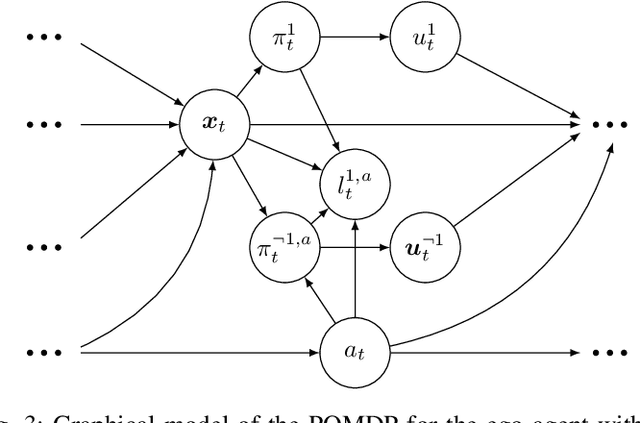

Environments with multi-agent interactions often result a rich set of modalities of behavior between agents due to the inherent suboptimality of decision making processes when agents settle for satisfactory decisions. However, existing algorithms for solving these dynamic games are strictly unimodal and fail to capture the intricate multimodal behaviors of the agents. In this paper, we propose MMELQGames (Multimodal Maximum-Entropy Linear Quadratic Games), a novel constrained multimodal maximum entropy formulation of the Differential Dynamic Programming algorithm for solving generalized Nash equilibria. By formulating the problem as a certain dynamic game with incomplete and asymmetric information where agents are uncertain about the cost and dynamics of the game itself, the proposed method is able to reason about multiple local generalized Nash equilibria, enforce constraints with the Augmented Lagrangian framework and also perform Bayesian inference on the latent mode from past observations. We assess the efficacy of the proposed algorithm on two illustrative examples: multi-agent collision avoidance and autonomous racing. In particular, we show that only MMELQGames is able to effectively block a rear vehicle when given a speed disadvantage and the rear vehicle can overtake from multiple positions.
Dataset Condensation with Contrastive Signals
Feb 07, 2022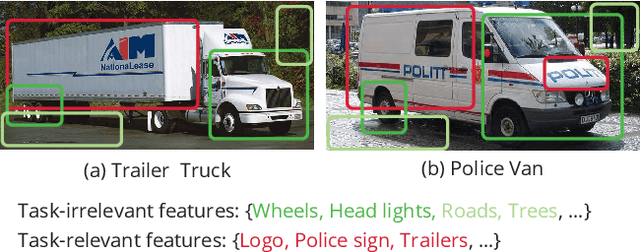
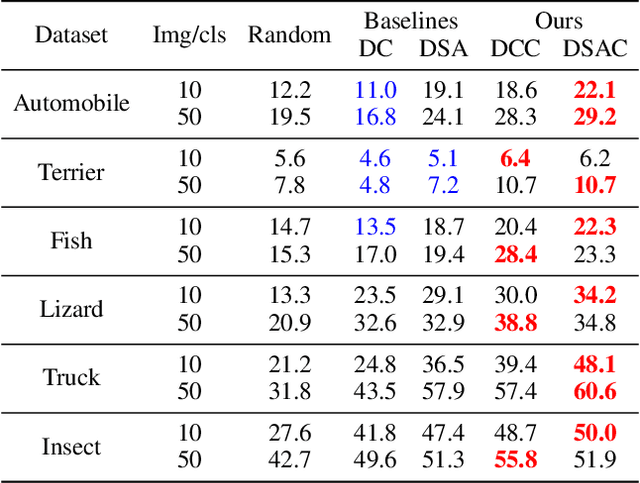
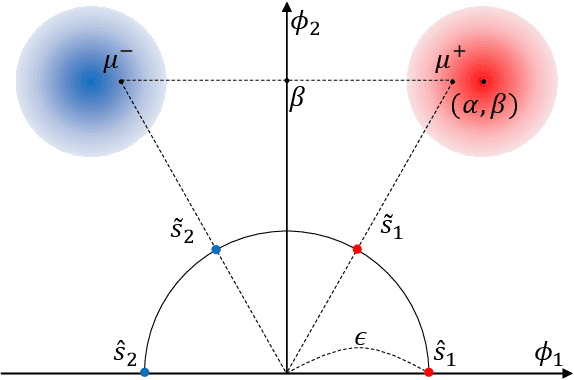
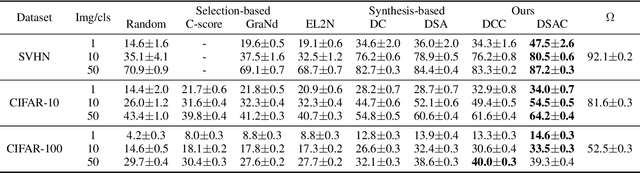
Recent studies have demonstrated that gradient matching-based dataset synthesis, or dataset condensation (DC), methods can achieve state-of-the-art performance when applied to data-efficient learning tasks. However, in this study, we prove that the existing DC methods can perform worse than the random selection method when task-irrelevant information forms a significant part of the training dataset. We attribute this to the lack of participation of the contrastive signals between the classes resulting from the class-wise gradient matching strategy. To address this problem, we propose Dataset Condensation with Contrastive signals (DCC) by modifying the loss function to enable the DC methods to effectively capture the differences between classes. In addition, we analyze the new loss function in terms of training dynamics by tracking the kernel velocity. Furthermore, we introduce a bi-level warm-up strategy to stabilize the optimization. Our experimental results indicate that while the existing methods are ineffective for fine-grained image classification tasks, the proposed method can successfully generate informative synthetic datasets for the same tasks. Moreover, we demonstrate that the proposed method outperforms the baselines even on benchmark datasets such as SVHN, CIFAR-10, and CIFAR-100. Finally, we demonstrate the high applicability of the proposed method by applying it to continual learning tasks.
Graph Neural Network-Based Scheduling for Multi-UAV-Enabled Communications in D2D Networks
Feb 15, 2022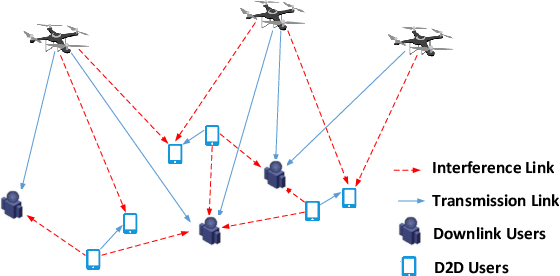
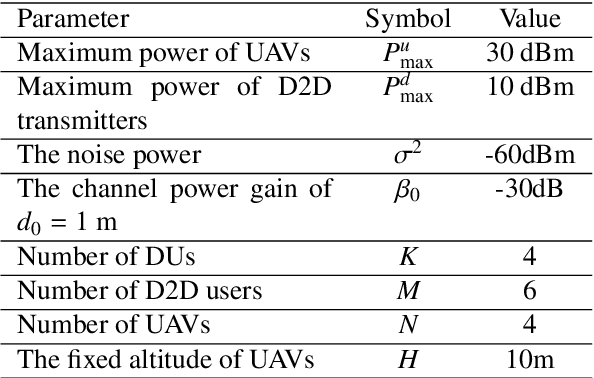
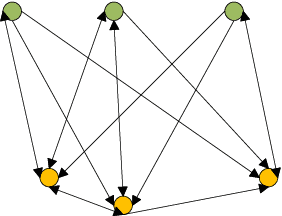
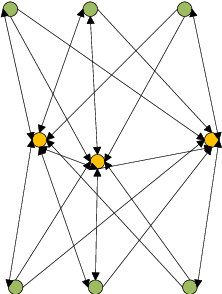
In this paper, we jointly design the power control and position dispatch for Multi-unmanned aerial vehicle (UAV)-enabled communication in device-to-device (D2D) networks. Our objective is to maximize the total transmission rate of downlink users (DUs). Meanwhile, the quality of service (QoS) of all D2D users must be satisfied. We comprehensively considered the interference among D2D communications and downlink transmissions. The original problem is strongly non-convex, which requires high computational complexity for traditional optimization methods. And to make matters worse, the results are not necessarily globally optimal. In this paper, we propose a novel graph neural networks (GNN) based approach that can map the considered system into a specific graph structure and achieve the optimal solution in a low complexity manner. Particularly, we first construct a GNN-based model for the proposed network, in which the transmission links and interference links are formulated as vertexes and edges, respectively. Then, by taking the channel state information and the coordinates of ground users as the inputs, as well as the location of UAVs and the transmission power of all transmitters as outputs, we obtain the mapping from inputs to outputs through training the parameters of GNN. Simulation results verified that the way to maximize the total transmission rate of DUs can be extracted effectively via the training on samples. Moreover, it also shows that the performance of proposed GNN-based method is better than that of traditional means.
Bayesian Deep Learning for Graphs
Feb 24, 2022
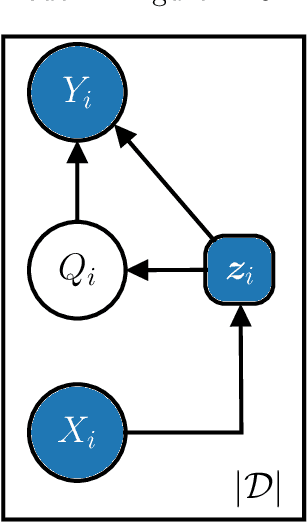
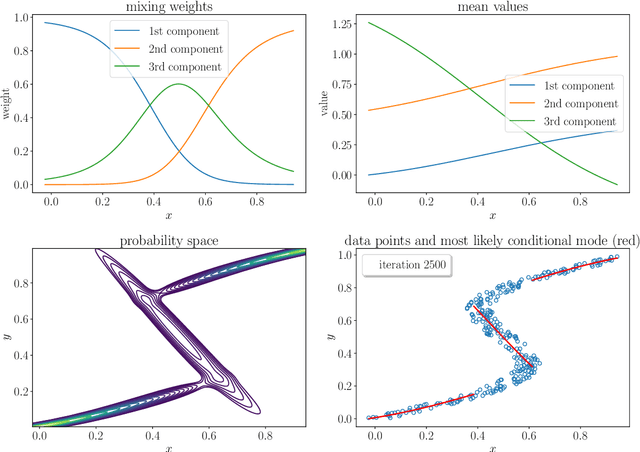
The adaptive processing of structured data is a long-standing research topic in machine learning that investigates how to automatically learn a mapping from a structured input to outputs of various nature. Recently, there has been an increasing interest in the adaptive processing of graphs, which led to the development of different neural network-based methodologies. In this thesis, we take a different route and develop a Bayesian Deep Learning framework for graph learning. The dissertation begins with a review of the principles over which most of the methods in the field are built, followed by a study on graph classification reproducibility issues. We then proceed to bridge the basic ideas of deep learning for graphs with the Bayesian world, by building our deep architectures in an incremental fashion. This framework allows us to consider graphs with discrete and continuous edge features, producing unsupervised embeddings rich enough to reach the state of the art on several classification tasks. Our approach is also amenable to a Bayesian nonparametric extension that automatizes the choice of almost all model's hyper-parameters. Two real-world applications demonstrate the efficacy of deep learning for graphs. The first concerns the prediction of information-theoretic quantities for molecular simulations with supervised neural models. After that, we exploit our Bayesian models to solve a malware-classification task while being robust to intra-procedural code obfuscation techniques. We conclude the dissertation with an attempt to blend the best of the neural and Bayesian worlds together. The resulting hybrid model is able to predict multimodal distributions conditioned on input graphs, with the consequent ability to model stochasticity and uncertainty better than most works. Overall, we aim to provide a Bayesian perspective into the articulated research field of deep learning for graphs.
First Arrival Position in Molecular Communication Via Generator of Diffusion Semigroup
Jan 14, 2022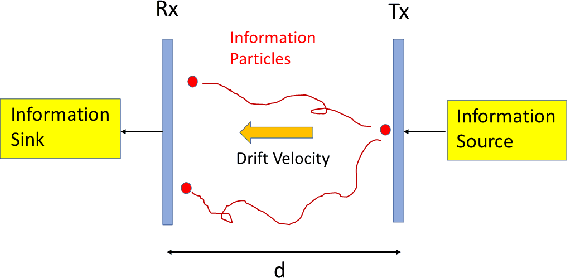
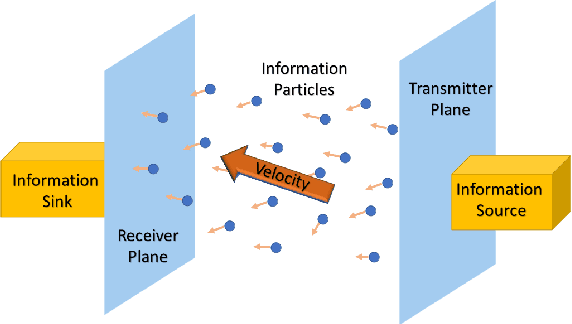
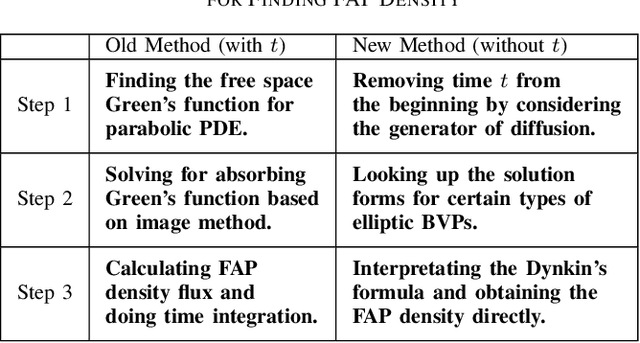
We consider the problem of characterizing the first arrival position (FAP) density in molecular communication (MC) with a diffusion-advection channel that permits a constant drift velocity pointed to arbitrary direction. The advantage of FAP modulation lies in the fact that it could encode more information into higher dimensional spatial variables, compared to other modulation techniques using time or molecule numbers. However, effective methods to characterize the FAP density in a general framework do not exist. In this paper, we devise a methodology that fully resolves the FAP density with planar absorbing receivers in arbitrary dimensions. Our work recovers existing results of FAP in 2D and 3D as special cases. The key insight of our approach is to remove the time dependence of the MC system evolution based on the generator of diffusion semigroups.
An Empirical Analysis of AI Contributions to Sustainable Cities (SDG11)
Feb 06, 2022
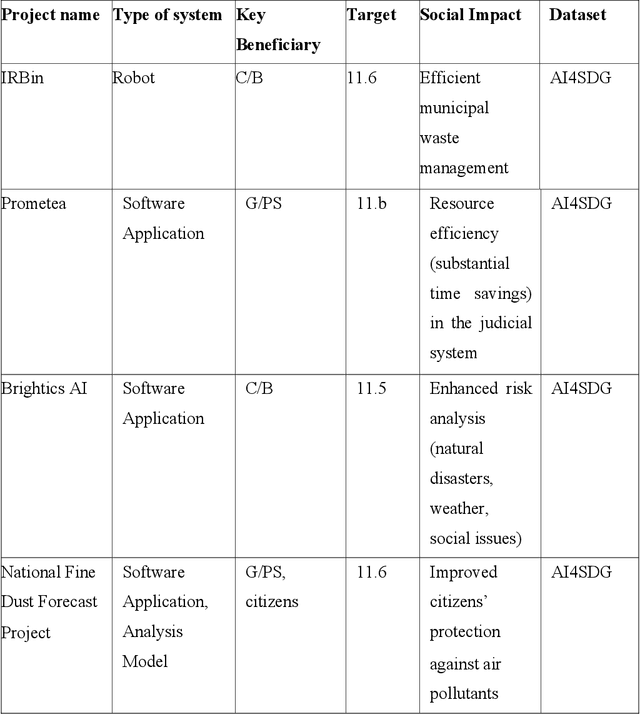
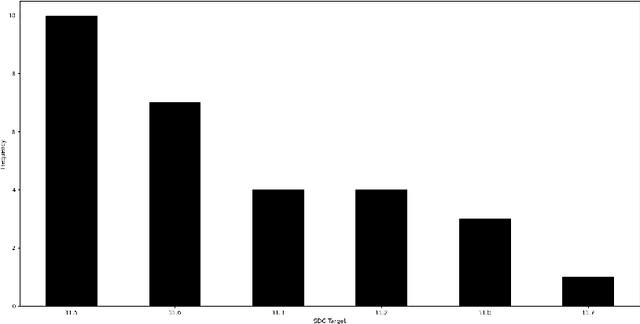
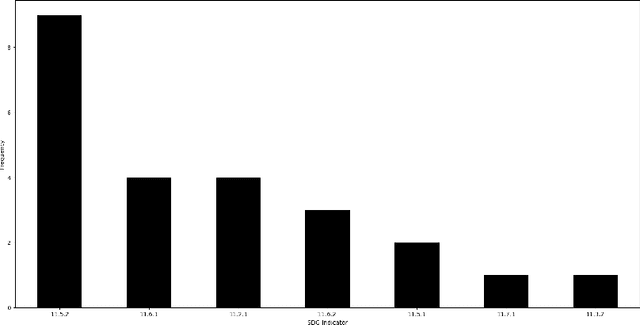
Artificial Intelligence (AI) presents opportunities to develop tools and techniques for addressing some of the major global challenges and deliver solutions with significant social and economic impacts. The application of AI has far-reaching implications for the 17 Sustainable Development Goals (SDGs) in general, and sustainable urban development in particular. However, existing attempts to understand and use the opportunities offered by AI for SDG 11 have been explored sparsely, and the shortage of empirical evidence about the practical application of AI remains. In this chapter, we analyze the contribution of AI to support the progress of SDG 11 (Sustainable Cities and Communities). We address the knowledge gap by empirically analyzing the AI systems (N = 29) from the AIxSDG database and the Community Research and Development Information Service (CORDIS) database. Our analysis revealed that AI systems have indeed contributed to advancing sustainable cities in several ways (e.g., waste management, air quality monitoring, disaster response management, transportation management), but many projects are still working for citizens and not with them. This snapshot of AI's impact on SDG11 is inherently partial, yet useful to advance our understanding as we move towards more mature systems and research on the impact of AI systems for social good.
Augmenting Neural Differential Equations to Model Unknown Dynamical Systems with Incomplete State Information
Aug 19, 2020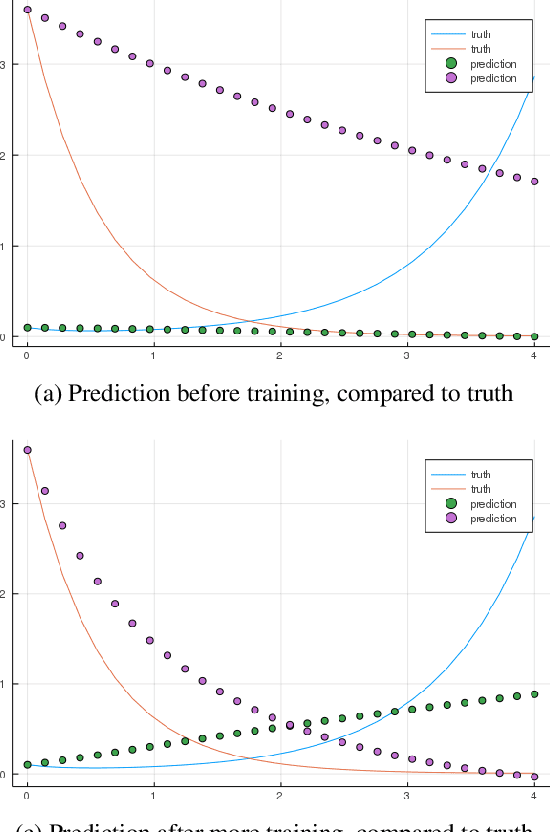
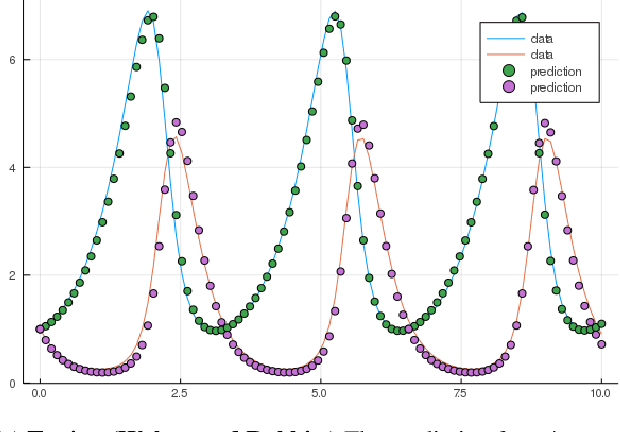
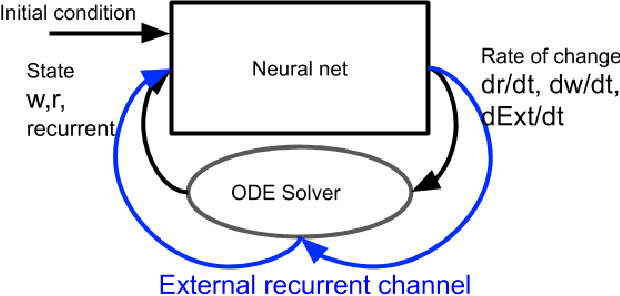
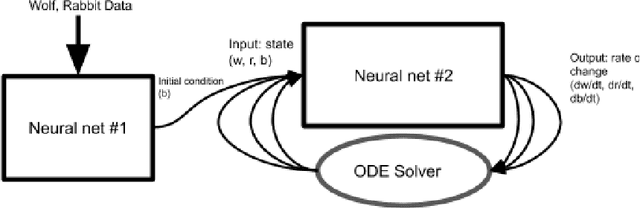
Neural Ordinary Differential Equations replace the right-hand side of a conventional ODE with a neural net, which by virtue of the universal approximation theorem, can be trained to the representation of any function. When we do not know the function itself, but have state trajectories (time evolution) of the ODE system we can still train the neural net to learn the representation of the underlying but unknown ODE. However if the state of the system is incompletely known then the right-hand side of the ODE cannot be calculated. The derivatives to propagate the system are unavailable. We show that a specially augmented Neural ODE can learn the system when given incomplete state information. As a worked example we apply neural ODEs to the Lotka-Voltera problem of 3 species, rabbits, wolves, and bears. We show that even when the data for the bear time series is removed the remaining time series of the rabbits and wolves is sufficient to learn the dynamical system despite the missing the incomplete state information. This is surprising since a conventional ODE system cannot output the correct derivatives without the full state as the input. We implement augmented neural ODEs and differential equation solvers in the julia programming language.
Face Deblurring Based on Separable Normalization and Adaptive Denormalization
Dec 18, 2021



Face deblurring aims to restore a clear face image from a blurred input image with more explicit structure and facial details. However, most conventional image and face deblurring methods focus on the whole generated image resolution without consideration of special face part texture and generally produce unsufficient details. Considering that faces and backgrounds have different distribution information, in this study, we designed an effective face deblurring network based on separable normalization and adaptive denormalization (SNADNet). First, We fine-tuned the face parsing network to obtain an accurate face structure. Then, we divided the face parsing feature into face foreground and background. Moreover, we constructed a new feature adaptive denormalization to regularize fafcial structures as a condition of the auxiliary to generate more harmonious and undistorted face structure. In addition, we proposed a texture extractor and multi-patch discriminator to enhance the generated facial texture information. Experimental results on both CelebA and CelebA-HQ datasets demonstrate that the proposed face deblurring network restores face structure with more facial details and performs favorably against state-of-the-art methods in terms of structured similarity indexing method (SSIM), peak signal-to-noise ratio (PSNR), Frechet inception distance (FID) and L1, and qualitative comparisons.