 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Motion-Plane-Adaptive Inter Prediction in 360-Degree Video Coding
Feb 07, 2022



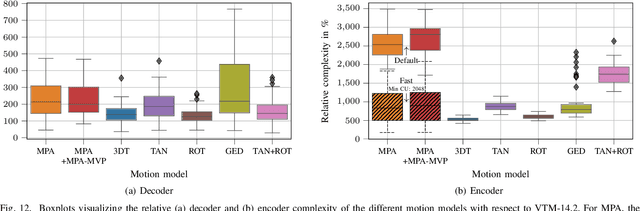
Inter prediction is one of the key technologies enabling the high compression efficiency of modern video coding standards. 360-degree video needs to be mapped to the 2D image plane prior to coding in order to allow compression using existing video coding standards. The distortions that inevitably occur when mapping spherical data onto the 2D image plane, however, impair the performance of classical inter prediction techniques. In this paper, we propose a motion-plane-adaptive inter prediction technique (MPA) for 360-degree video that takes the spherical characteristics of 360-degree video into account. Based on the known projection format of the video, MPA allows to perform inter prediction on different motion planes in 3D space instead of having to work on the - in theory arbitrarily mapped - 2D image representation directly. We furthermore derive a motion-plane-adaptive motion vector prediction technique (MPA-MVP) that allows to translate motion information between different motion planes and motion models. Our proposed integration of MPA together with MPA-MVP into the state-of-the-art H.266/VVC video coding standard shows significant Bjontegaard Delta rate savings of 1.72% with a peak of 3.97% based on PSNR and 1.56% with a peak of 3.40% based on WS-PSNR compared to the VTM-14.2 baseline on average.
Crafting Better Contrastive Views for Siamese Representation Learning
Feb 07, 2022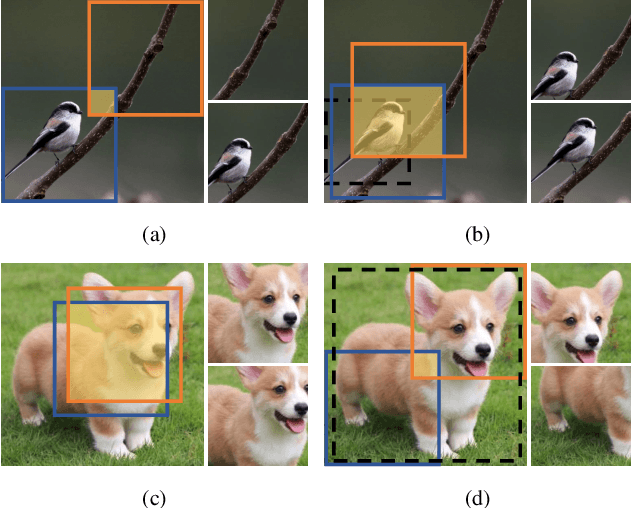
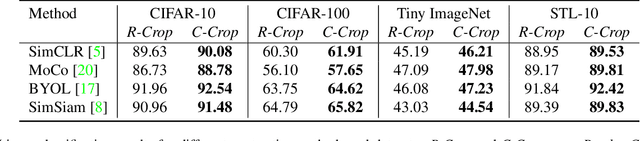

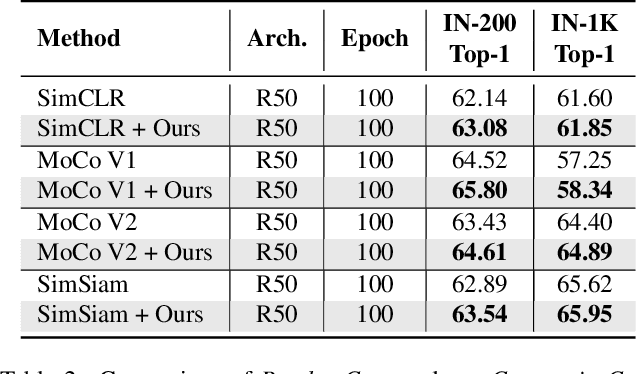
Recent self-supervised contrastive learning methods greatly benefit from the Siamese structure that aims at minimizing distances between positive pairs. For high performance Siamese representation learning, one of the keys is to design good contrastive pairs. Most previous works simply apply random sampling to make different crops of the same image, which overlooks the semantic information that may degrade the quality of views. In this work, we propose ContrastiveCrop, which could effectively generate better crops for Siamese representation learning. Firstly, a semantic-aware object localization strategy is proposed within the training process in a fully unsupervised manner. This guides us to generate contrastive views which could avoid most false positives (i.e., object vs. background). Moreover, we empirically find that views with similar appearances are trivial for the Siamese model training. Thus, a center-suppressed sampling is further designed to enlarge the variance of crops. Remarkably, our method takes a careful consideration of positive pairs for contrastive learning with negligible extra training overhead. As a plug-and-play and framework-agnostic module, ContrastiveCrop consistently improves SimCLR, MoCo, BYOL, SimSiam by 0.4% ~ 2.0% classification accuracy on CIFAR-10, CIFAR-100, Tiny ImageNet and STL-10. Superior results are also achieved on downstream detection and segmentation tasks when pre-trained on ImageNet-1K.
Knowledge Sharing via Domain Adaptation in Customs Fraud Detection
Jan 18, 2022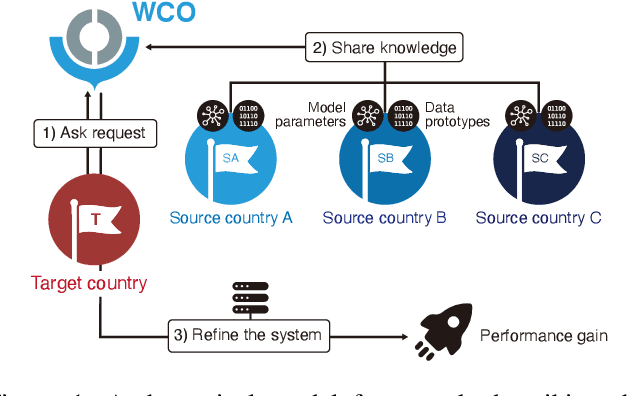
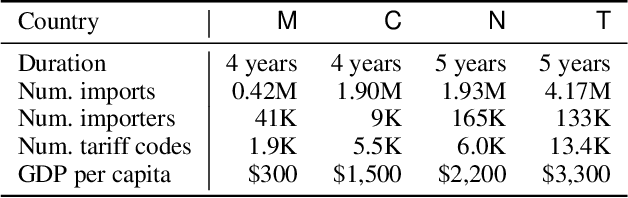
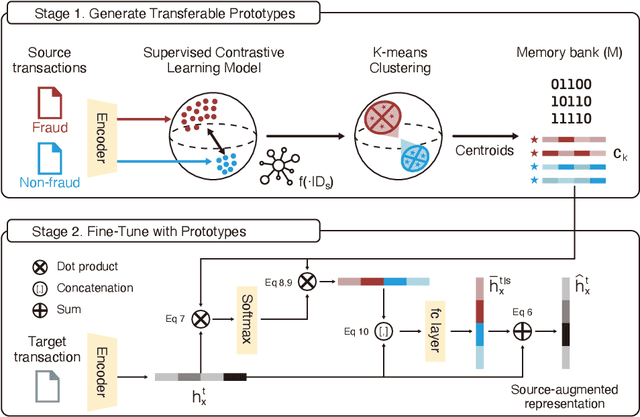
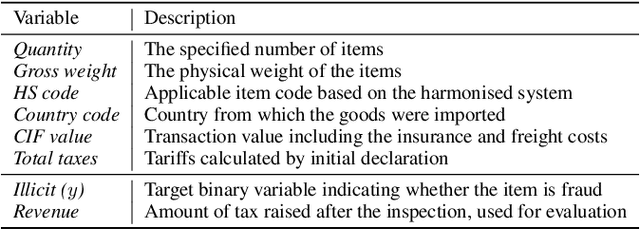
Knowledge of the changing traffic is critical in risk management. Customs offices worldwide have traditionally relied on local resources to accumulate knowledge and detect tax fraud. This naturally poses countries with weak infrastructure to become tax havens of potentially illicit trades. The current paper proposes DAS, a memory bank platform to facilitate knowledge sharing across multi-national customs administrations to support each other. We propose a domain adaptation method to share transferable knowledge of frauds as prototypes while safeguarding the local trade information. Data encompassing over 8 million import declarations have been used to test the feasibility of this new system, which shows that participating countries may benefit up to 2-11 times in fraud detection with the help of shared knowledge. We discuss implications for substantial tax revenue potential and strengthened policy against illicit trades.
Learning from scarce information: using synthetic data to classify Roman fine ware pottery
Jul 03, 2021
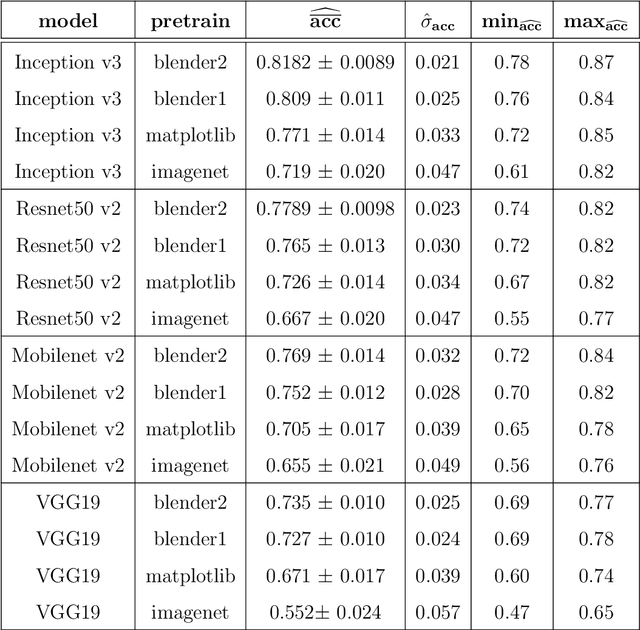
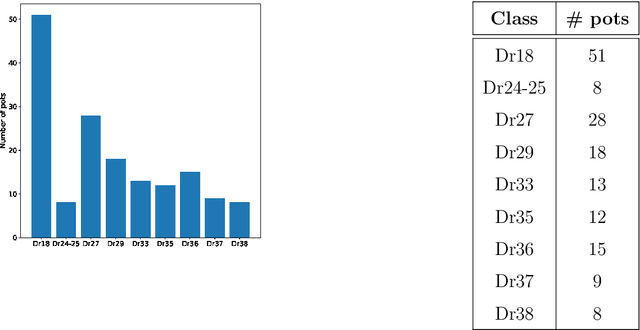
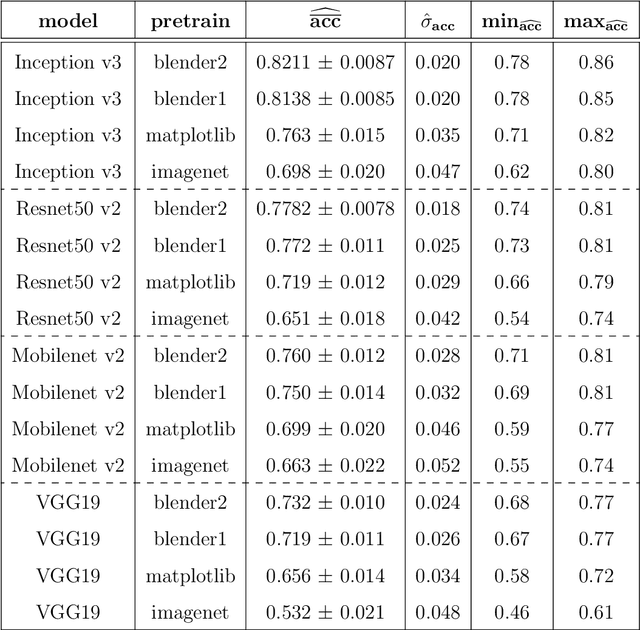
In this article we consider a version of the challenging problem of learning from datasets whose size is too limited to allow generalisation beyond the training set. To address the challenge we propose to use a transfer learning approach whereby the model is first trained on a synthetic dataset replicating features of the original objects. In this study the objects were smartphone photographs of near-complete Roman terra sigillata pottery vessels from the collection of the Museum of London. Taking the replicated features from published profile drawings of pottery forms allowed the integration of expert knowledge into the process through our synthetic data generator. After this first initial training the model was fine-tuned with data from photographs of real vessels. We show, through exhaustive experiments across several popular deep learning architectures, different test priors, and considering the impact of the photograph viewpoint and excessive damage to the vessels, that the proposed hybrid approach enables the creation of classifiers with appropriate generalisation performance. This performance is significantly better than that of classifiers trained exclusively on the original data which shows the promise of the approach to alleviate the fundamental issue of learning from small datasets.
Privacy-Preserving In-Bed Pose Monitoring: A Fusion and Reconstruction Study
Feb 22, 2022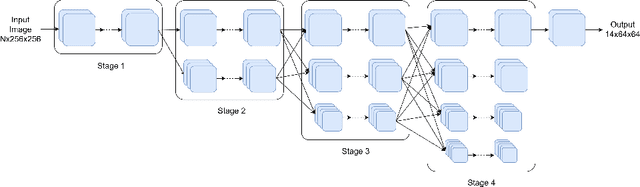

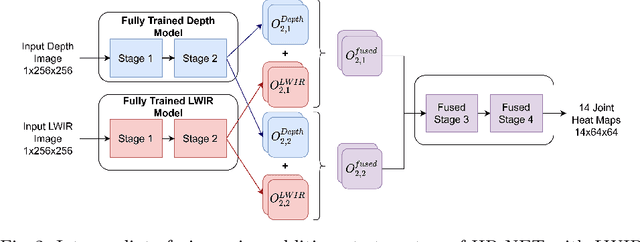
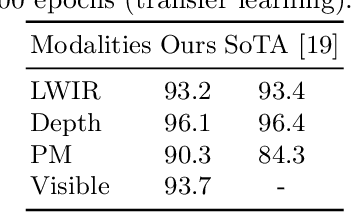
Recently, in-bed human pose estimation has attracted the interest of researchers due to its relevance to a wide range of healthcare applications. Compared to the general problem of human pose estimation, in-bed pose estimation has several inherent challenges, the most prominent being frequent and severe occlusions caused by bedding. In this paper we explore the effective use of images from multiple non-visual and privacy-preserving modalities such as depth, long-wave infrared (LWIR) and pressure maps for the task of in-bed pose estimation in two settings. First, we explore the effective fusion of information from different imaging modalities for better pose estimation. Secondly, we propose a framework that can estimate in-bed pose estimation when visible images are unavailable, and demonstrate the applicability of fusion methods to scenarios where only LWIR images are available. We analyze and demonstrate the effect of fusing features from multiple modalities. For this purpose, we consider four different techniques: 1) Addition, 2) Concatenation, 3) Fusion via learned modal weights, and 4) End-to-end fully trainable approach; with a state-of-the-art pose estimation model. We also evaluate the effect of reconstructing a data-rich modality (i.e., visible modality) from a privacy-preserving modality with data scarcity (i.e., long-wavelength infrared) for in-bed human pose estimation. For reconstruction, we use a conditional generative adversarial network. We conduct ablative studies across different design decisions of our framework. This includes selecting features with different levels of granularity, using different fusion techniques, and varying model parameters. Through extensive evaluations, we demonstrate that our method produces on par or better results compared to the state-of-the-art.
Dialog Intent Induction via Density-based Deep Clustering Ensemble
Jan 18, 2022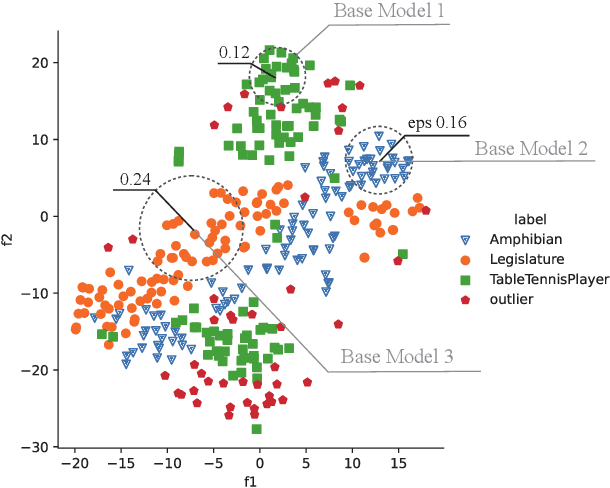

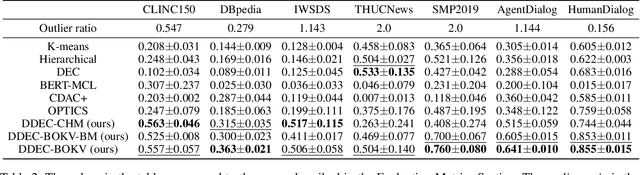
Existing task-oriented chatbots heavily rely on spoken language understanding (SLU) systems to determine a user's utterance's intent and other key information for fulfilling specific tasks. In real-life applications, it is crucial to occasionally induce novel dialog intents from the conversation logs to improve the user experience. In this paper, we propose the Density-based Deep Clustering Ensemble (DDCE) method for dialog intent induction. Compared to existing K-means based methods, our proposed method is more effective in dealing with real-life scenarios where a large number of outliers exist. To maximize data utilization, we jointly optimize texts' representations and the hyperparameters of the clustering algorithm. In addition, we design an outlier-aware clustering ensemble framework to handle the overfitting issue. Experimental results over seven datasets show that our proposed method significantly outperforms other state-of-the-art baselines.
Poisoning Attacks and Defenses on Artificial Intelligence: A Survey
Feb 22, 2022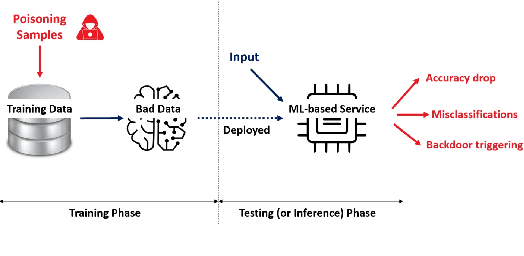
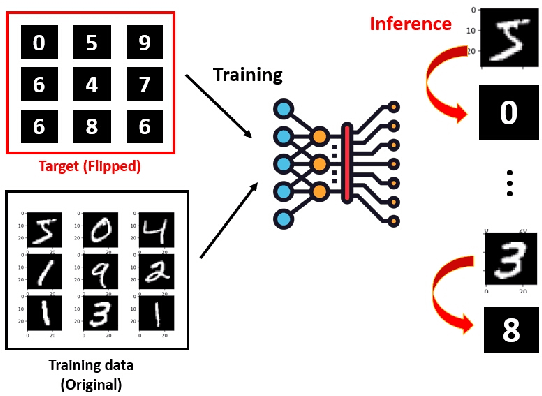
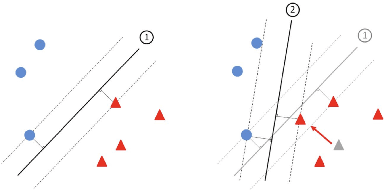
Machine learning models have been widely adopted in several fields. However, most recent studies have shown several vulnerabilities from attacks with a potential to jeopardize the integrity of the model, presenting a new window of research opportunity in terms of cyber-security. This survey is conducted with a main intention of highlighting the most relevant information related to security vulnerabilities in the context of machine learning (ML) classifiers; more specifically, directed towards training procedures against data poisoning attacks, representing a type of attack that consists of tampering the data samples fed to the model during the training phase, leading to a degradation in the models accuracy during the inference phase. This work compiles the most relevant insights and findings found in the latest existing literatures addressing this type of attacks. Moreover, this paper also covers several defense techniques that promise feasible detection and mitigation mechanisms, capable of conferring a certain level of robustness to a target model against an attacker. A thorough assessment is performed on the reviewed works, comparing the effects of data poisoning on a wide range of ML models in real-world conditions, performing quantitative and qualitative analyses. This paper analyzes the main characteristics for each approach including performance success metrics, required hyperparameters, and deployment complexity. Moreover, this paper emphasizes the underlying assumptions and limitations considered by both attackers and defenders along with their intrinsic properties such as: availability, reliability, privacy, accountability, interpretability, etc. Finally, this paper concludes by making references of some of main existing research trends that provide pathways towards future research directions in the field of cyber-security.
Regularized directional representations for medical image registration
Nov 30, 2021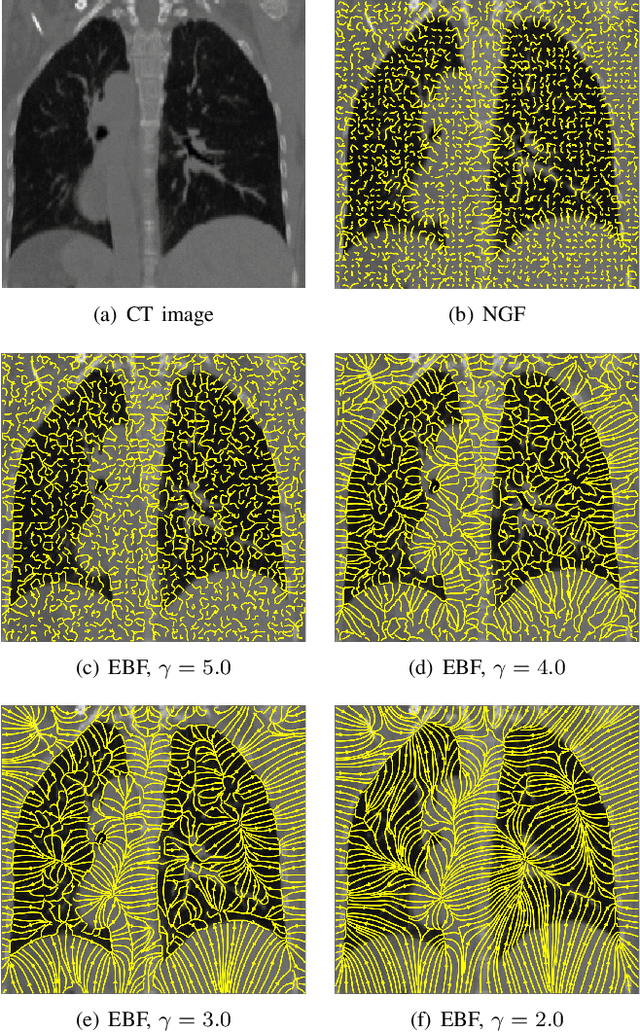
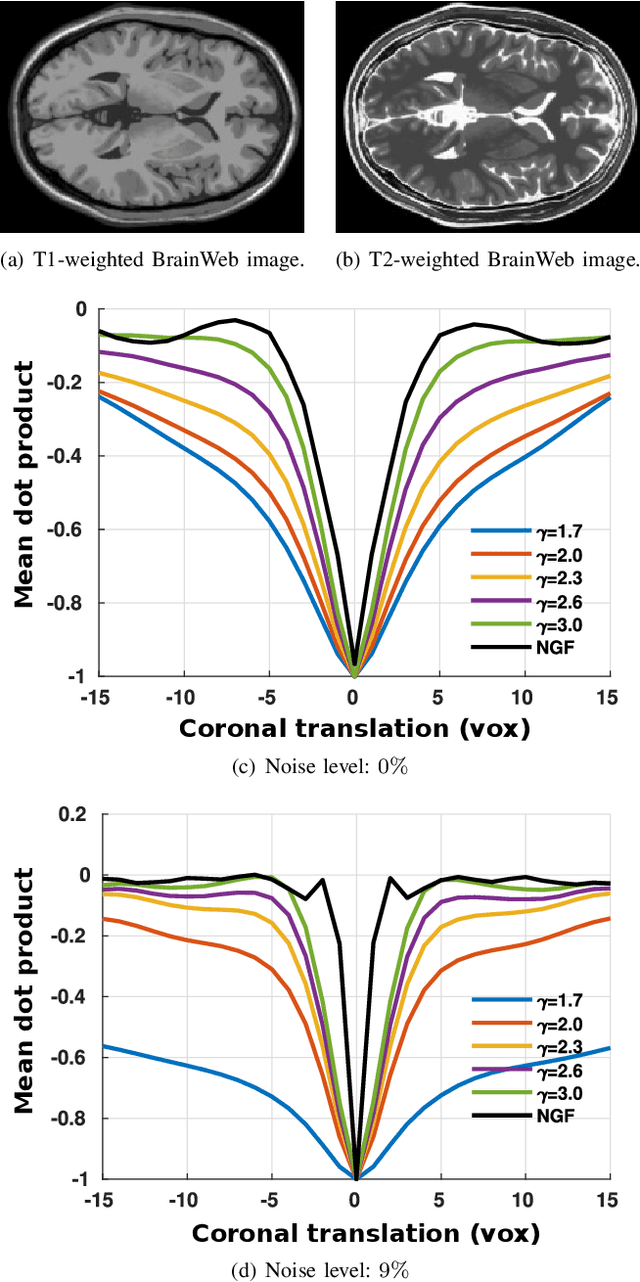
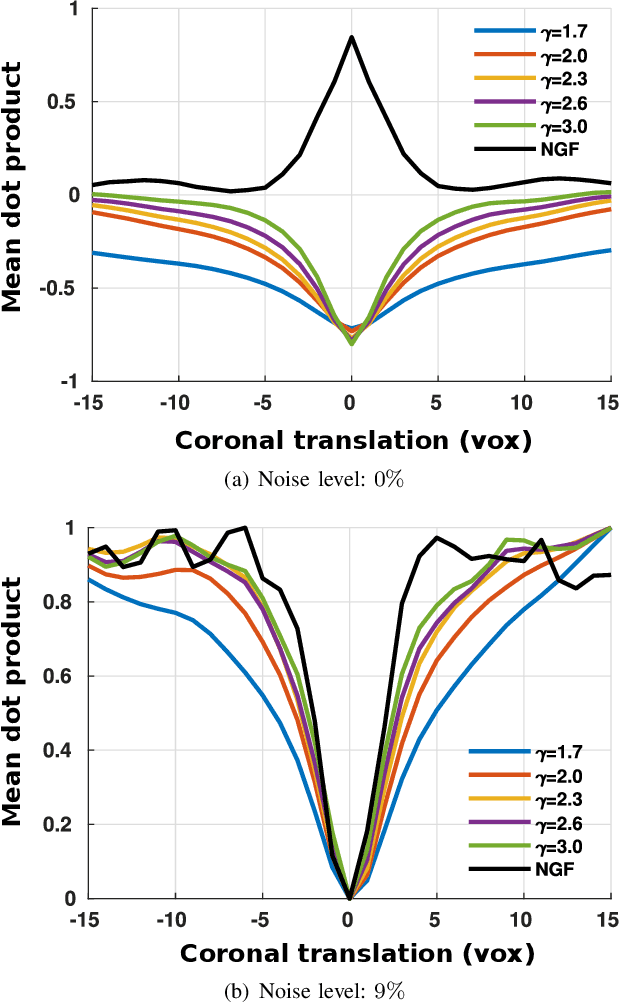
In image registration, many efforts have been devoted to the development of alternatives to the popular normalized mutual information criterion. Concurrently to these efforts, an increasing number of works have demonstrated that substantial gains in registration accuracy can also be achieved by aligning structural representations of images rather than images themselves. Following this research path, we propose a new method for mono- and multimodal image registration based on the alignment of regularized vector fields derived from structural information such as gradient vector flow fields, a technique we call \textit{vector field similarity}. Our approach can be combined in a straightforward fashion with any existing registration framework by substituting vector field similarity to intensity-based registration. In our experiments, we show that the proposed approach compares favourably with conventional image alignment on several public image datasets using a diversity of imaging modalities and anatomical locations.
Using Social Media Images for Building Function Classification
Feb 15, 2022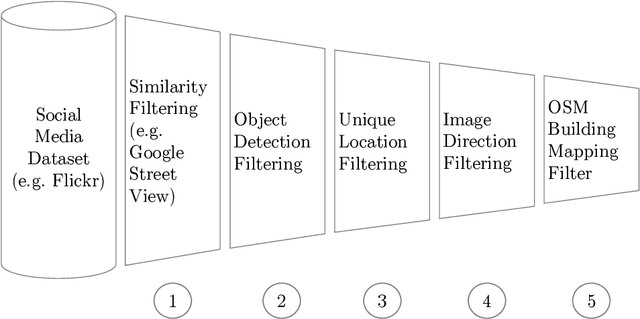
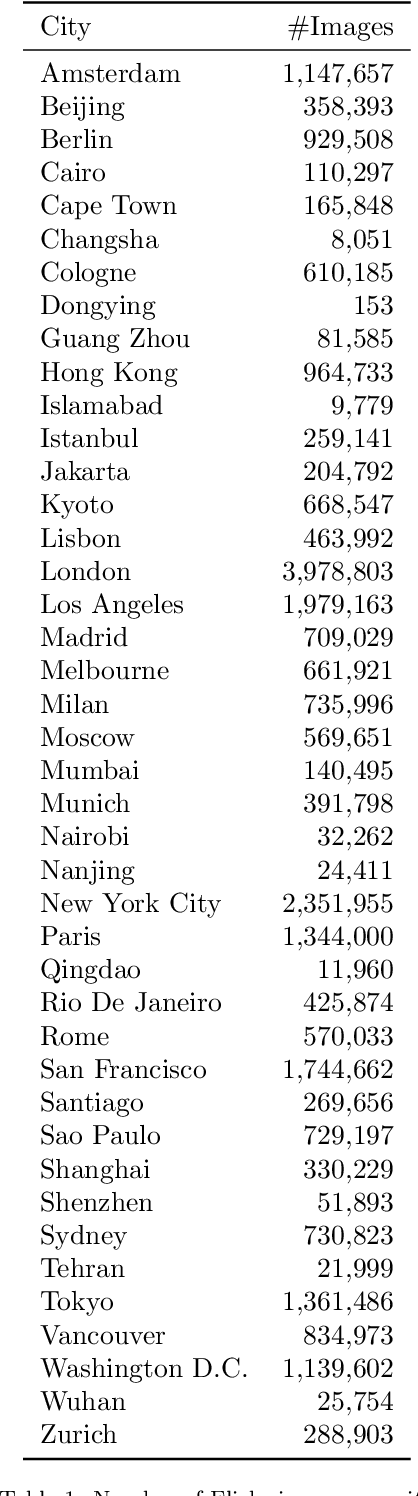
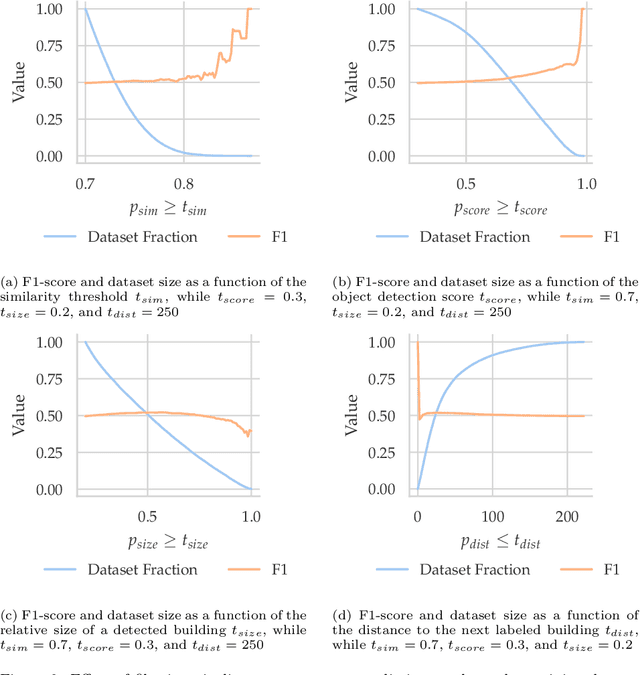
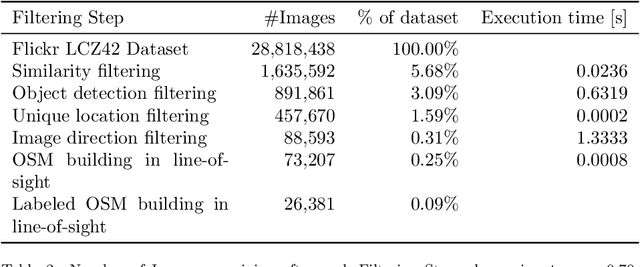
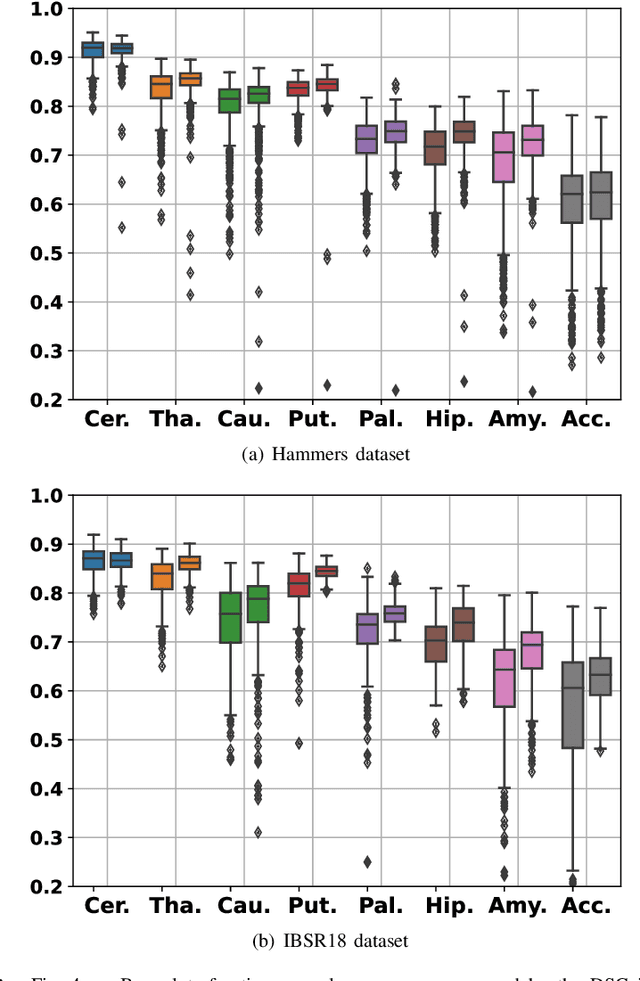
Urban land use on a building instance level is crucial geo-information for many applications, yet difficult to obtain. An intuitive approach to close this gap is predicting building functions from ground level imagery. Social media image platforms contain billions of images, with a large variety of motifs including but not limited to street perspectives. To cope with this issue this study proposes a filtering pipeline to yield high quality, ground level imagery from large social media image datasets. The pipeline ensures that all resulting images have full and valid geotags with a compass direction to relate image content and spatial objects from maps. We analyze our method on a culturally diverse social media dataset from Flickr with more than 28 million images from 42 cities around the world. The obtained dataset is then evaluated in a context of 3-classes building function classification task. The three building classes that are considered in this study are: commercial, residential, and other. Fine-tuned state-of-the-art architectures yield F1-scores of up to 0.51 on the filtered images. Our analysis shows that the performance is highly limited by the quality of the labels obtained from OpenStreetMap, as the metrics increase by 0.2 if only human validated labels are considered. Therefore, we consider these labels to be weak and publish the resulting images from our pipeline together with the buildings they are showing as a weakly labeled dataset.
A Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022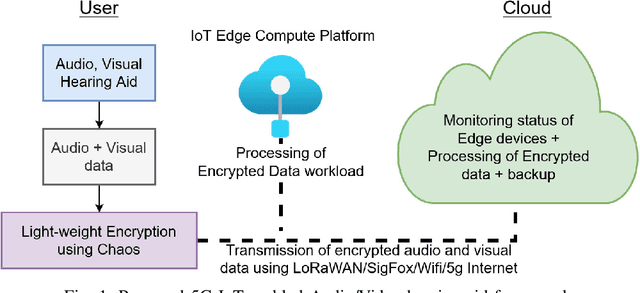

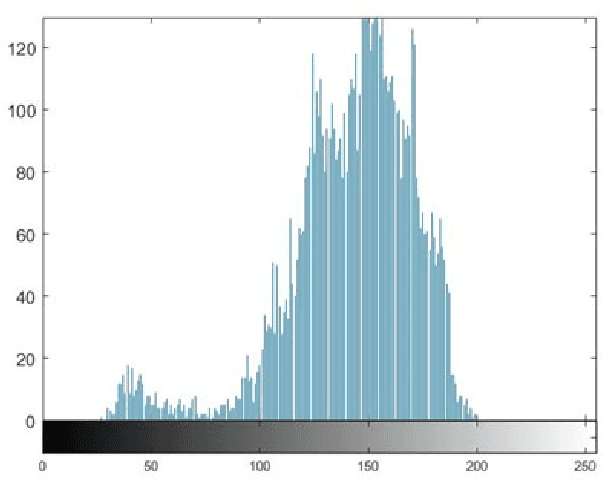
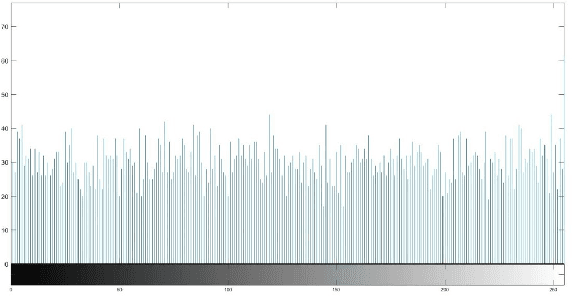
Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.