 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DeepScalper: A Risk-Aware Deep Reinforcement Learning Framework for Intraday Trading with Micro-level Market Embedding
Dec 15, 2021
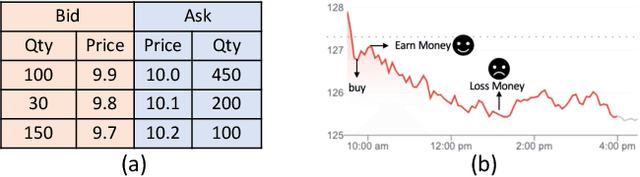
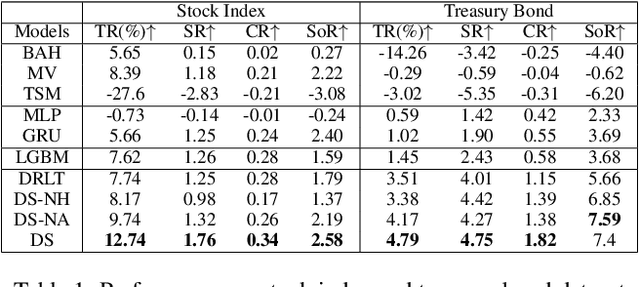
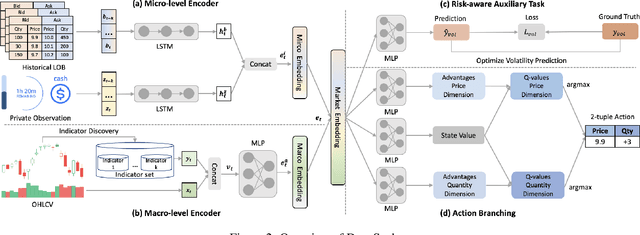
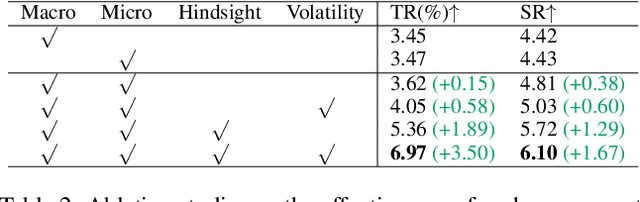
Reinforcement learning (RL) techniques have shown great success in quantitative investment tasks, such as portfolio management and algorithmic trading. Especially, intraday trading is one of the most profitable and risky tasks because of the intraday behaviors of the financial market that reflect billions of rapidly fluctuating values. However, it is hard to apply existing RL methods to intraday trading due to the following three limitations: 1) overlooking micro-level market information (e.g., limit order book); 2) only focusing on local price fluctuation and failing to capture the overall trend of the whole trading day; 3) neglecting the impact of market risk. To tackle these limitations, we propose DeepScalper, a deep reinforcement learning framework for intraday trading. Specifically, we adopt an encoder-decoder architecture to learn robust market embedding incorporating both macro-level and micro-level market information. Moreover, a novel hindsight reward function is designed to provide the agent a long-term horizon for capturing the overall price trend. In addition, we propose a risk-aware auxiliary task by predicting future volatility, which helps the agent take market risk into consideration while maximizing profit. Finally, extensive experiments on two stock index futures and four treasury bond futures demonstrate that DeepScalper achieves significant improvement against many state-of-the-art approaches.
Phishing Attacks Detection -- A Machine Learning-Based Approach
Jan 26, 2022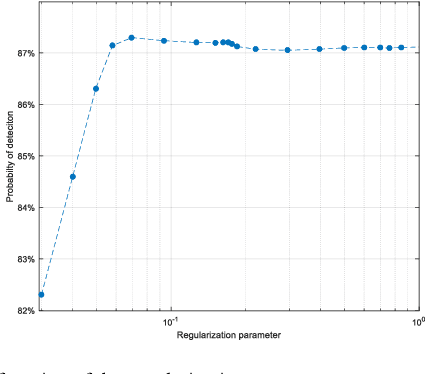
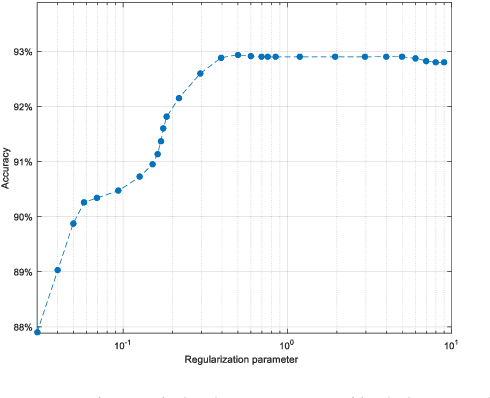

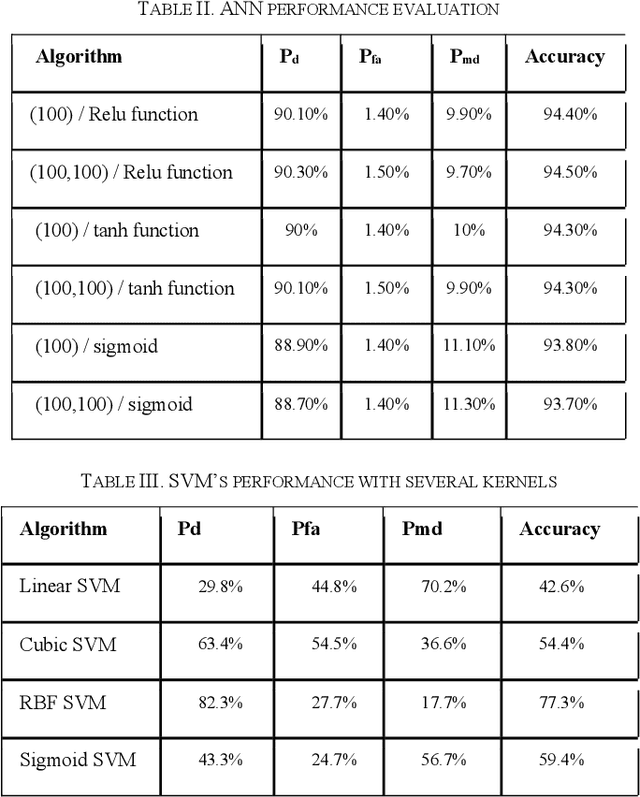
Phishing attacks are one of the most common social engineering attacks targeting users emails to fraudulently steal confidential and sensitive information. They can be used as a part of more massive attacks launched to gain a foothold in corporate or government networks. Over the last decade, a number of anti-phishing techniques have been proposed to detect and mitigate these attacks. However, they are still inefficient and inaccurate. Thus, there is a great need for efficient and accurate detection techniques to cope with these attacks. In this paper, we proposed a phishing attack detection technique based on machine learning. We collected and analyzed more than 4000 phishing emails targeting the email service of the University of North Dakota. We modeled these attacks by selecting 10 relevant features and building a large dataset. This dataset was used to train, validate, and test the machine learning algorithms. For performance evaluation, four metrics have been used, namely probability of detection, probability of miss-detection, probability of false alarm, and accuracy. The experimental results show that better detection can be achieved using an artificial neural network.
Graph Neural Networks with Dynamic and Static Representations for Social Recommendation
Jan 26, 2022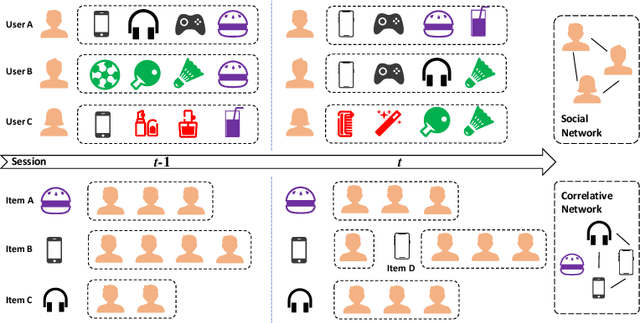
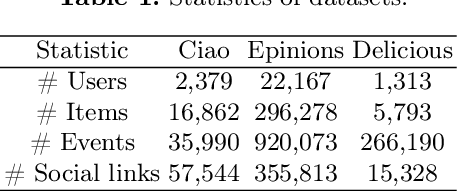
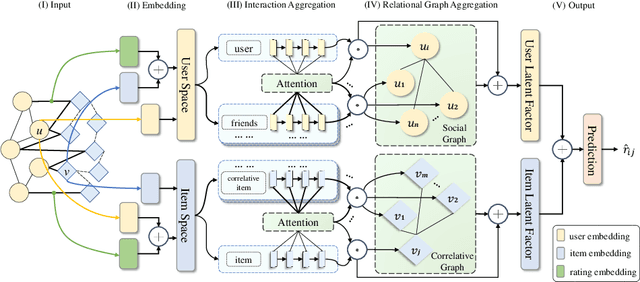
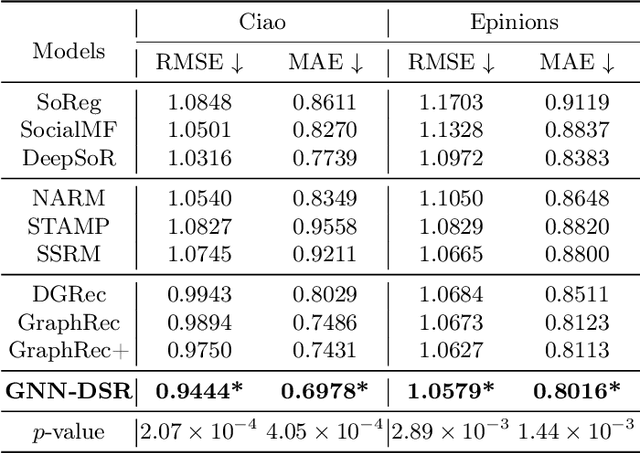
Recommender systems based on graph neural networks receive increasing research interest due to their excellent ability to learn a variety of side information including social networks. However, previous works usually focus on modeling users, not much attention is paid to items. Moreover, the possible changes in the attraction of items over time, which is like the dynamic interest of users are rarely considered, and neither do the correlations among items. To overcome these limitations, this paper proposes graph neural networks with dynamic and static representations for social recommendation (GNN-DSR), which considers both dynamic and static representations of users and items and incorporates their relational influence. GNN-DSR models the short-term dynamic and long-term static interactional representations of the user's interest and the item's attraction, respectively. Furthermore, the attention mechanism is used to aggregate the social influence of users on the target user and the correlative items' influence on a given item. The final latent factors of user and item are combined to make a prediction. Experiments on three real-world recommender system datasets validate the effectiveness of GNN-DSR.
Joint-bone Fusion Graph Convolutional Network for Semi-supervised Skeleton Action Recognition
Feb 08, 2022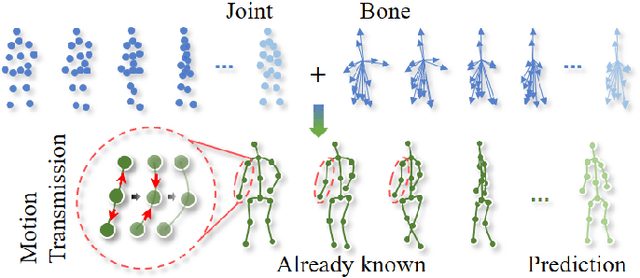
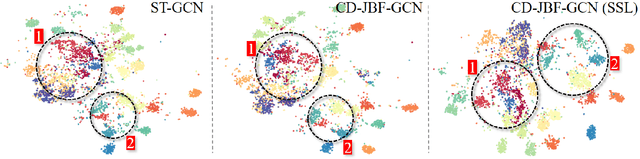
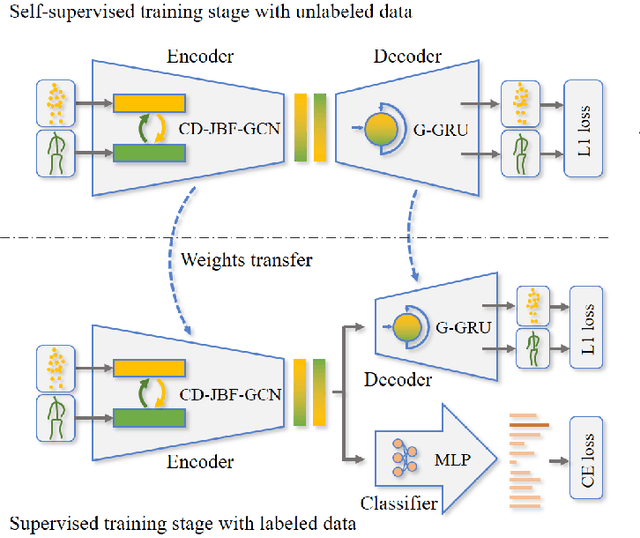
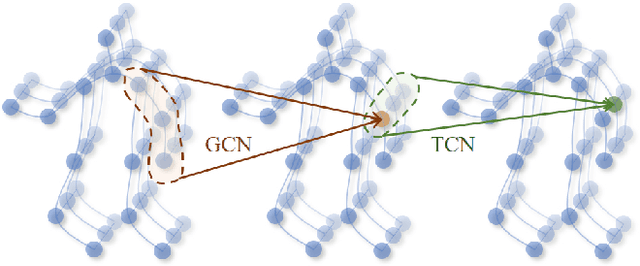
In recent years, graph convolutional networks (GCNs) play an increasingly critical role in skeleton-based human action recognition. However, most GCN-based methods still have two main limitations: 1) They only consider the motion information of the joints or process the joints and bones separately, which are unable to fully explore the latent functional correlation between joints and bones for action recognition. 2) Most of these works are performed in the supervised learning way, which heavily relies on massive labeled training data. To address these issues, we propose a semi-supervised skeleton-based action recognition method which has been rarely exploited before. We design a novel correlation-driven joint-bone fusion graph convolutional network (CD-JBF-GCN) as an encoder and use a pose prediction head as a decoder to achieve semi-supervised learning. Specifically, the CD-JBF-GC can explore the motion transmission between the joint stream and the bone stream, so that promoting both streams to learn more discriminative feature representations. The pose prediction based auto-encoder in the self-supervised training stage allows the network to learn motion representation from unlabeled data, which is essential for action recognition. Extensive experiments on two popular datasets, i.e. NTU-RGB+D and Kinetics-Skeleton, demonstrate that our model achieves the state-of-the-art performance for semi-supervised skeleton-based action recognition and is also useful for fully-supervised methods.
Structural Information Learning Machinery: Learning from Observing, Associating, Optimizing, Decoding, and Abstracting
Jan 27, 2020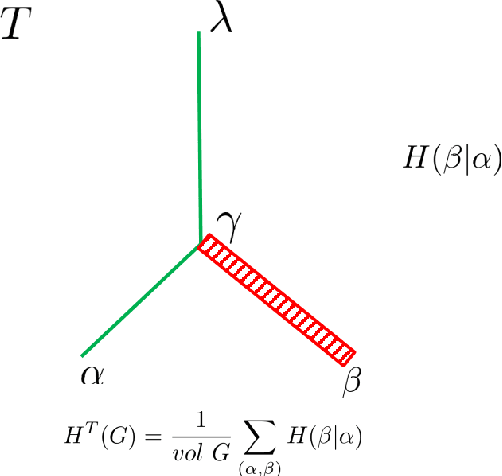
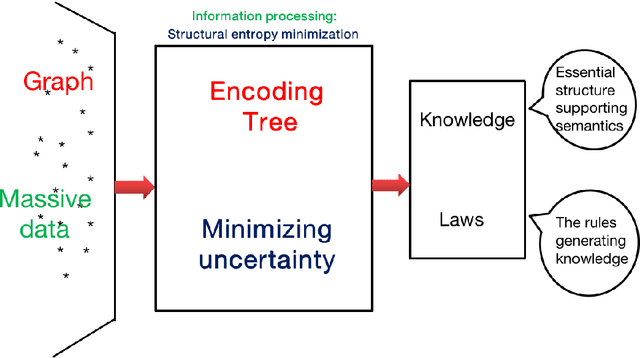
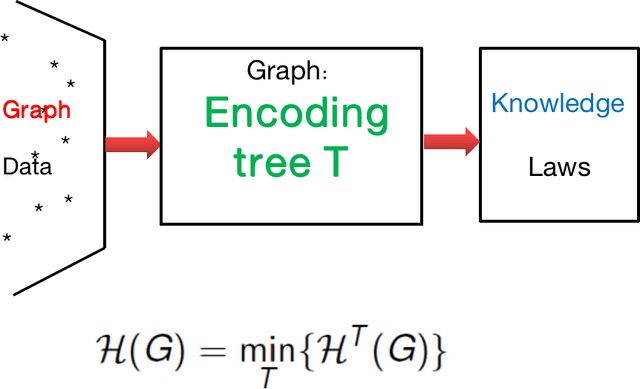
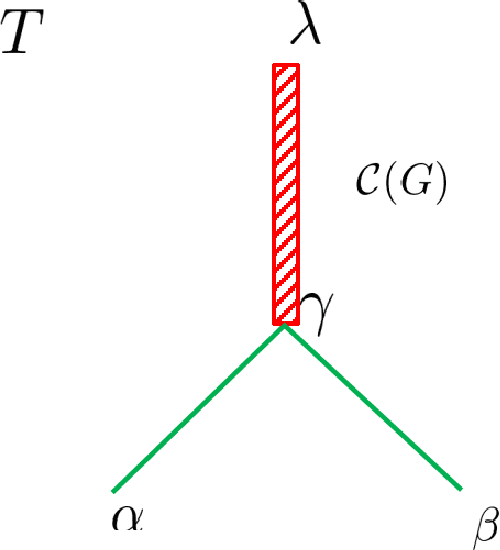
In the present paper, we propose the model of {\it structural information learning machines} (SiLeM for short), leading to a mathematical definition of learning by merging the theories of computation and information. Our model shows that the essence of learning is {\it to gain information}, that to gain information is {\it to eliminate uncertainty} embedded in a data space, and that to eliminate uncertainty of a data space can be reduced to an optimization problem, that is, an {\it information optimization problem}, which can be realized by a general {\it encoding tree method}. The principle and criterion of the structural information learning machines are maximization of {\it decoding information} from the data points observed together with the relationships among the data points, and semantical {\it interpretation} of syntactical {\it essential structure}, respectively. A SiLeM machine learns the laws or rules of nature. It observes the data points of real world, builds the {\it connections} among the observed data and constructs a {\it data space}, for which the principle is to choose the way of connections of data points so that the {\it decoding information} of the data space is maximized, finds the {\it encoding tree} of the data space that minimizes the dynamical uncertainty of the data space, in which the encoding tree is hence referred to as a {\it decoder}, due to the fact that it has already eliminated the maximum amount of uncertainty embedded in the data space, interprets the {\it semantics} of the decoder, an encoding tree, to form a {\it knowledge tree}, extracts the {\it remarkable common features} for both semantical and syntactical features of the modules decoded by a decoder to construct {\it trees of abstractions}, providing the foundations for {\it intuitive reasoning} in the learning when new data are observed.
Infusing Sequential Information into Conditional Masked Translation Model with Self-Review Mechanism
Oct 26, 2020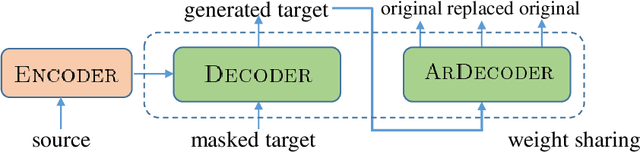
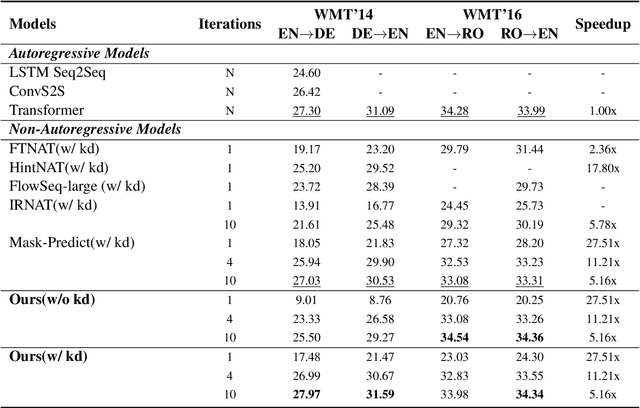
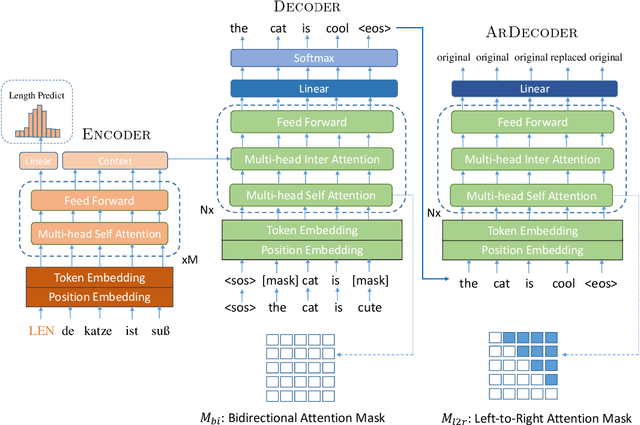
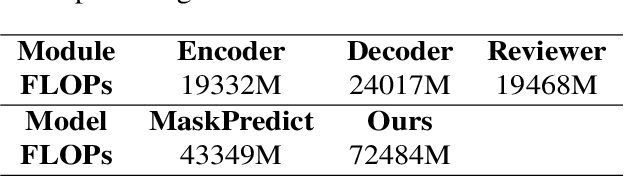
Non-autoregressive models generate target words in a parallel way, which achieve a faster decoding speed but at the sacrifice of translation accuracy. To remedy a flawed translation by non-autoregressive models, a promising approach is to train a conditional masked translation model (CMTM), and refine the generated results within several iterations. Unfortunately, such approach hardly considers the \textit{sequential dependency} among target words, which inevitably results in a translation degradation. Hence, instead of solely training a Transformer-based CMTM, we propose a Self-Review Mechanism to infuse sequential information into it. Concretely, we insert a left-to-right mask to the same decoder of CMTM, and then induce it to autoregressively review whether each generated word from CMTM is supposed to be replaced or kept. The experimental results (WMT14 En$\leftrightarrow$De and WMT16 En$\leftrightarrow$Ro) demonstrate that our model uses dramatically less training computations than the typical CMTM, as well as outperforms several state-of-the-art non-autoregressive models by over 1 BLEU. Through knowledge distillation, our model even surpasses a typical left-to-right Transformer model, while significantly speeding up decoding.
To Impute or not to Impute? -- Missing Data in Treatment Effect Estimation
Feb 04, 2022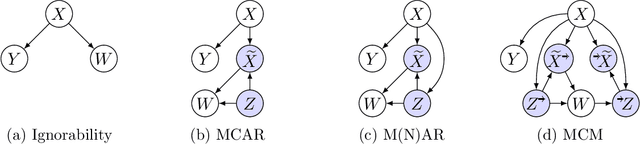
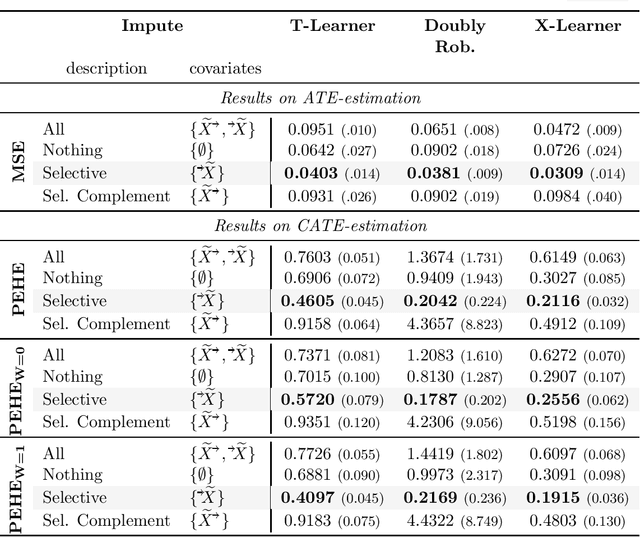
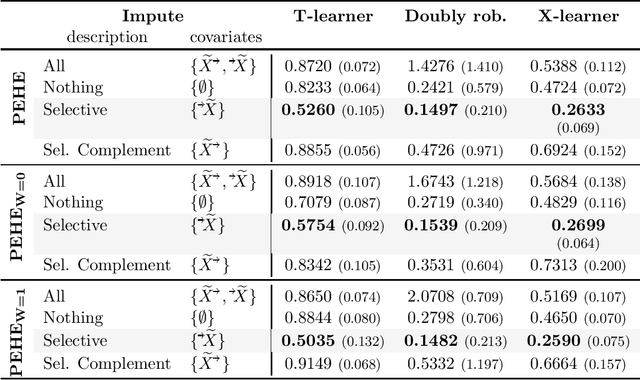
Missing data is a systemic problem in practical scenarios that causes noise and bias when estimating treatment effects. This makes treatment effect estimation from data with missingness a particularly tricky endeavour. A key reason for this is that standard assumptions on missingness are rendered insufficient due to the presence of an additional variable, treatment, besides the individual and the outcome. Having a treatment variable introduces additional complexity with respect to why some variables are missing that is not fully explored by previous work. In our work we identify a new missingness mechanism, which we term mixed confounded missingness (MCM), where some missingness determines treatment selection and other missingness is determined by treatment selection. Given MCM, we show that naively imputing all data leads to poor performing treatment effects models, as the act of imputation effectively removes information necessary to provide unbiased estimates. However, no imputation at all also leads to biased estimates, as missingness determined by treatment divides the population in distinct subpopulations, where estimates across these populations will be biased. Our solution is selective imputation, where we use insights from MCM to inform precisely which variables should be imputed and which should not. We empirically demonstrate how various learners benefit from selective imputation compared to other solutions for missing data.
Improving Location Recommendation with Urban Knowledge Graph
Nov 01, 2021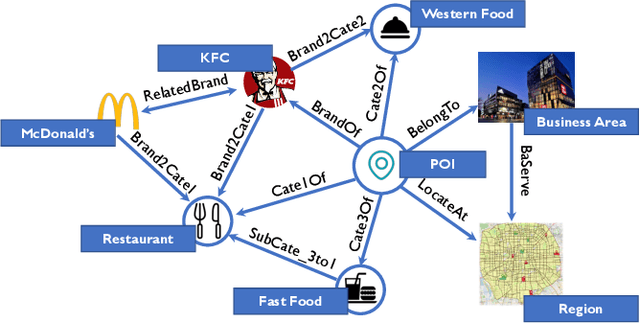
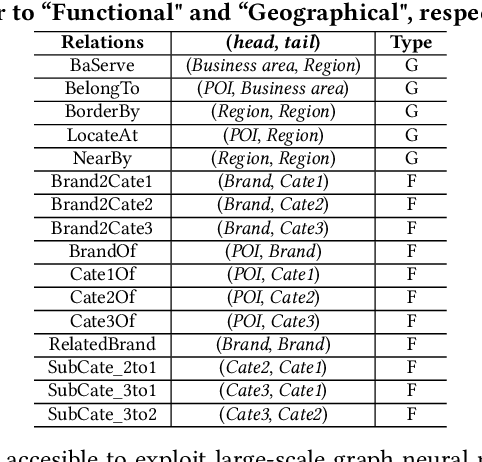
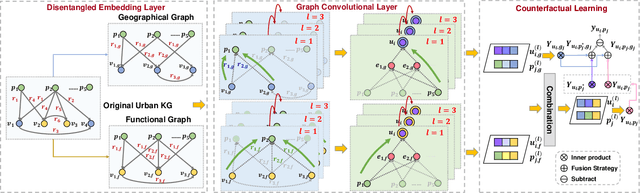
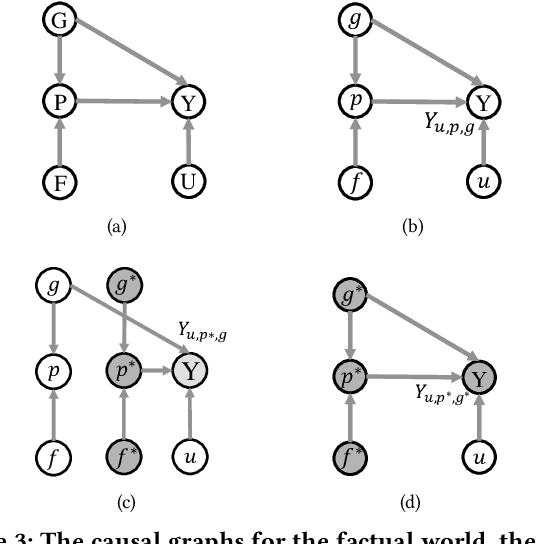
Location recommendation is defined as to recommend locations (POIs) to users in location-based services. The existing data-driving approaches of location recommendation suffer from the limitation of the implicit modeling of the geographical factor, which may lead to sub-optimal recommendation results. In this work, we address this problem by introducing knowledge-driven solutions. Specifically, we first construct the Urban Knowledge Graph (UrbanKG) with geographical information and functional information of POIs. On the other side, there exist a fact that the geographical factor not only characterizes POIs but also affects user-POI interactions. To address it, we propose a novel method named UKGC. We first conduct information propagation on two sub-graphs to learn the representations of POIs and users. We then fuse two parts of representations by counterfactual learning for the final prediction. Extensive experiments on two real-world datasets verify that our method can outperform the state-of-the-art methods.
Exploring the multimodal information from video content using deep learning features of appearance, audio and action for video recommendation
Nov 21, 2020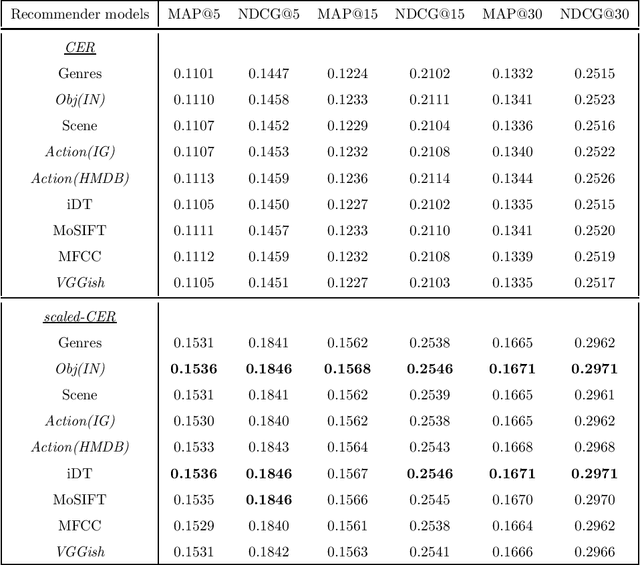
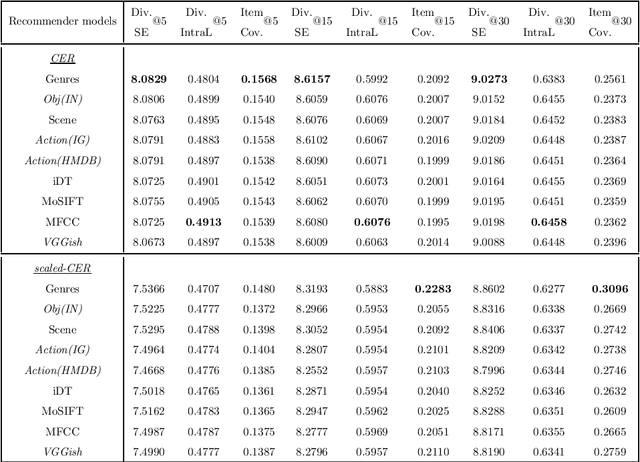
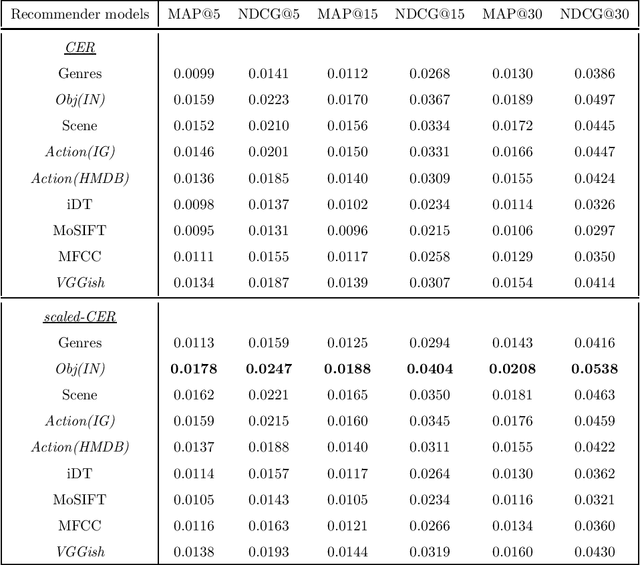
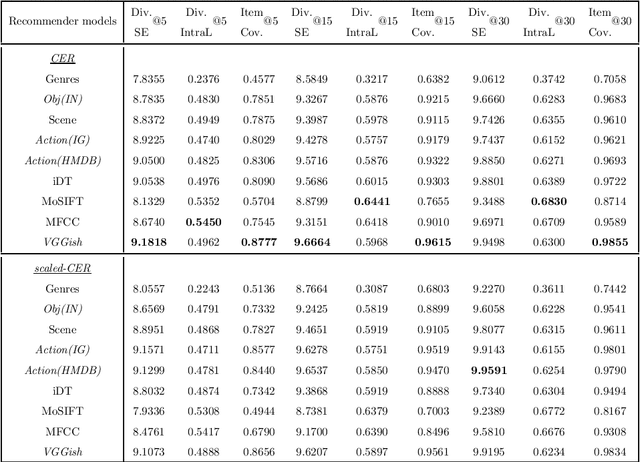
Following the popularisation of media streaming, a number of video streaming services are continuously buying new video content to mine the potential profit from them. As such, the newly added content has to be handled well to be recommended to suitable users. In this paper, we address the new item cold-start problem by exploring the potential of various deep learning features to provide video recommendations. The deep learning features investigated include features that capture the visual-appearance, audio and motion information from video content. We also explore different fusion methods to evaluate how well these feature modalities can be combined to fully exploit the complementary information captured by them. Experiments on a real-world video dataset for movie recommendations show that deep learning features outperform hand-crafted features. In particular, recommendations generated with deep learning audio features and action-centric deep learning features are superior to MFCC and state-of-the-art iDT features. In addition, the combination of various deep learning features with hand-crafted features and textual metadata yields significant improvement in recommendations compared to combining only the former.
Unsupervised Anomaly Detection in MR Images using Multi-Contrast Information
May 02, 2021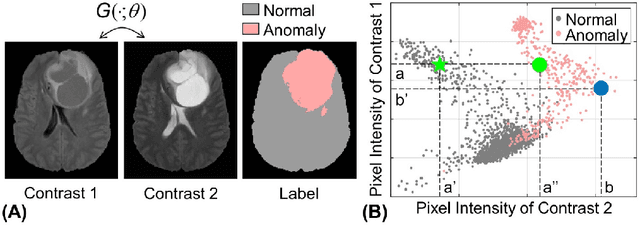
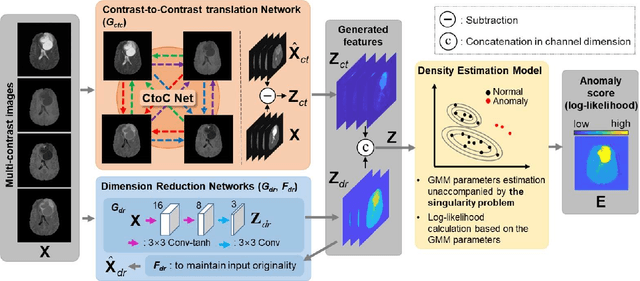
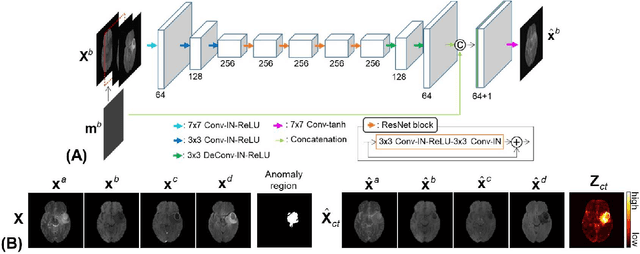
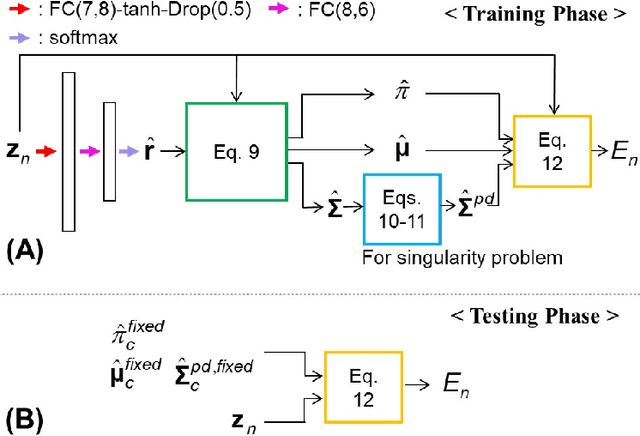
Anomaly detection in medical imaging is to distinguish the relevant biomarkers of diseases from those of normal tissues. Deep supervised learning methods have shown potentials in various detection tasks, but its performances would be limited in medical imaging fields where collecting annotated anomaly data is limited and labor-intensive. Therefore, unsupervised anomaly detection can be an effective tool for clinical practices, which uses only unlabeled normal images as training data. In this paper, we developed an unsupervised learning framework for pixel-wise anomaly detection in multi-contrast magnetic resonance imaging (MRI). The framework has two steps of feature generation and density estimation with Gaussian mixture model (GMM). A feature is derived through the learning of contrast-to-contrast translation that effectively captures the normal tissue characteristics in multi-contrast MRI. The feature is collaboratively used with another feature that is the low-dimensional representation of multi-contrast images. In density estimation using GMM, a simple but efficient way is introduced to handle the singularity problem which interrupts the joint learning process. The proposed method outperforms previous anomaly detection approaches. Quantitative and qualitative analyses demonstrate the effectiveness of the proposed method in anomaly detection for multi-contrast MRI.