 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Structure-aware Image Inpainting with Two Parallel Streams
Nov 05, 2021

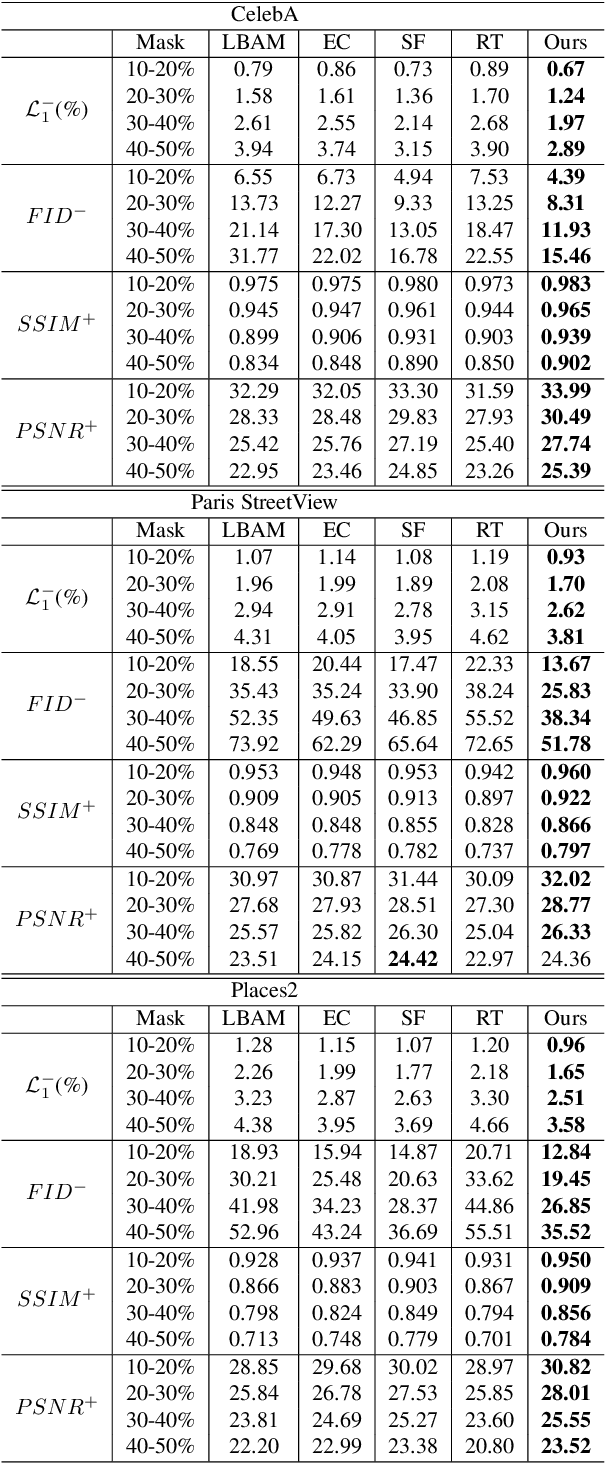
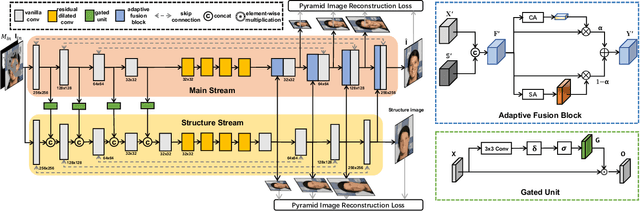
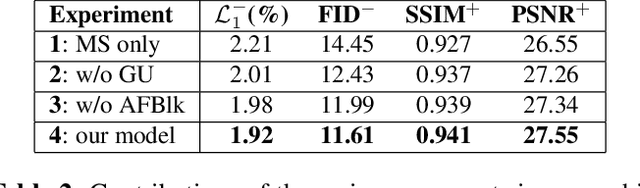
Recent works in image inpainting have shown that structural information plays an important role in recovering visually pleasing results. In this paper, we propose an end-to-end architecture composed of two parallel UNet-based streams: a main stream (MS) and a structure stream (SS). With the assistance of SS, MS can produce plausible results with reasonable structures and realistic details. Specifically, MS reconstructs detailed images by inferring missing structures and textures simultaneously, and SS restores only missing structures by processing the hierarchical information from the encoder of MS. By interacting with SS in the training process, MS can be implicitly encouraged to exploit structural cues. In order to help SS focus on structures and prevent textures in MS from being affected, a gated unit is proposed to depress structure-irrelevant activations in the information flow between MS and SS. Furthermore, the multi-scale structure feature maps in SS are utilized to explicitly guide the structure-reasonable image reconstruction in the decoder of MS through the fusion block. Extensive experiments on CelebA, Paris StreetView and Places2 datasets demonstrate that our proposed method outperforms state-of-the-art methods.
Exploring Event-driven Dynamic Context for Accident Scene Segmentation
Dec 09, 2021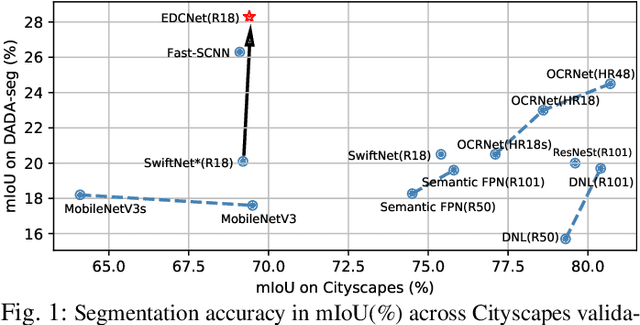


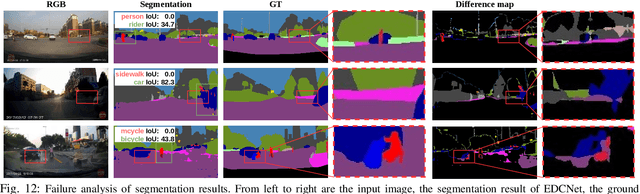
The robustness of semantic segmentation on edge cases of traffic scene is a vital factor for the safety of intelligent transportation. However, most of the critical scenes of traffic accidents are extremely dynamic and previously unseen, which seriously harm the performance of semantic segmentation methods. In addition, the delay of the traditional camera during high-speed driving will further reduce the contextual information in the time dimension. Therefore, we propose to extract dynamic context from event-based data with a higher temporal resolution to enhance static RGB images, even for those from traffic accidents with motion blur, collisions, deformations, overturns, etc. Moreover, in order to evaluate the segmentation performance in traffic accidents, we provide a pixel-wise annotated accident dataset, namely DADA-seg, which contains a variety of critical scenarios from traffic accidents. Our experiments indicate that event-based data can provide complementary information to stabilize semantic segmentation under adverse conditions by preserving fine-grained motion of fast-moving foreground (crash objects) in accidents. Our approach achieves +8.2% performance gain on the proposed accident dataset, exceeding more than 20 state-of-the-art semantic segmentation methods. The proposal has been demonstrated to be consistently effective for models learned on multiple source databases including Cityscapes, KITTI-360, BDD, and ApolloScape.
Learning to Model the Relationship Between Brain Structural and Functional Connectomes
Dec 18, 2021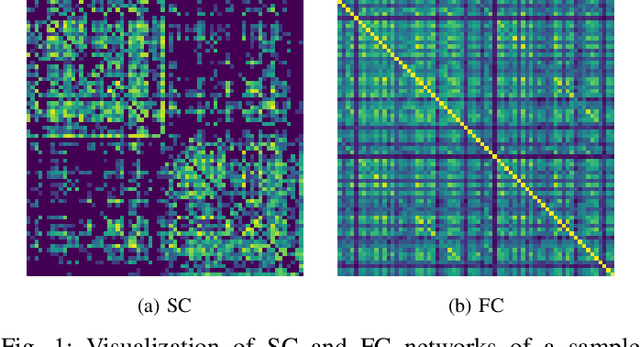
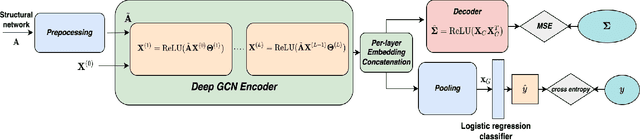
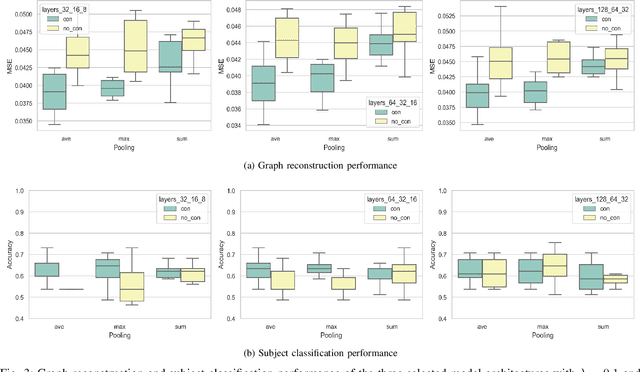
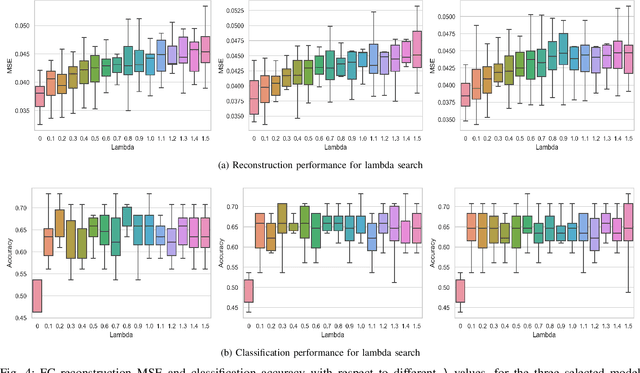
Recent advances in neuroimaging along with algorithmic innovations in statistical learning from network data offer a unique pathway to integrate brain structure and function, and thus facilitate revealing some of the brain's organizing principles at the system level. In this direction, we develop a supervised graph representation learning framework to model the relationship between brain structural connectivity (SC) and functional connectivity (FC) via a graph encoder-decoder system, where the SC is used as input to predict empirical FC. A trainable graph convolutional encoder captures direct and indirect interactions between brain regions-of-interest that mimic actual neural communications, as well as to integrate information from both the structural network topology and nodal (i.e., region-specific) attributes. The encoder learns node-level SC embeddings which are combined to generate (whole brain) graph-level representations for reconstructing empirical FC networks. The proposed end-to-end model utilizes a multi-objective loss function to jointly reconstruct FC networks and learn discriminative graph representations of the SC-to-FC mapping for downstream subject (i.e., graph-level) classification. Comprehensive experiments demonstrate that the learnt representations of said relationship capture valuable information from the intrinsic properties of the subject's brain networks and lead to improved accuracy in classifying a large population of heavy drinkers and non-drinkers from the Human Connectome Project. Our work offers new insights on the relationship between brain networks that support the promising prospect of using graph representation learning to discover more about human brain activity and function.
HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning
Jan 15, 2022
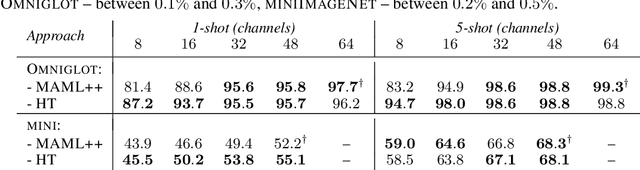
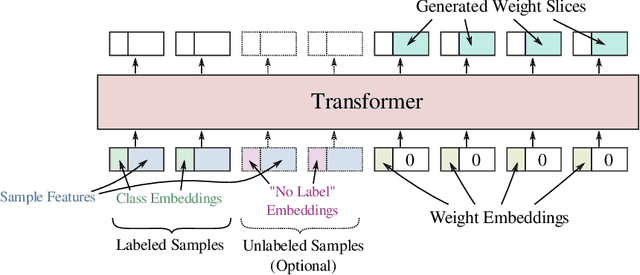
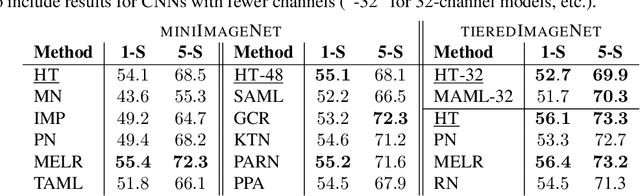
In this work we propose a HyperTransformer, a transformer-based model for few-shot learning that generates weights of a convolutional neural network (CNN) directly from support samples. Since the dependence of a small generated CNN model on a specific task is encoded by a high-capacity transformer model, we effectively decouple the complexity of the large task space from the complexity of individual tasks. Our method is particularly effective for small target CNN architectures where learning a fixed universal task-independent embedding is not optimal and better performance is attained when the information about the task can modulate all model parameters. For larger models we discover that generating the last layer alone allows us to produce competitive or better results than those obtained with state-of-the-art methods while being end-to-end differentiable. Finally, we extend our approach to a semi-supervised regime utilizing unlabeled samples in the support set and further improving few-shot performance.
Learning Debiased and Disentangled Representations for Semantic Segmentation
Oct 31, 2021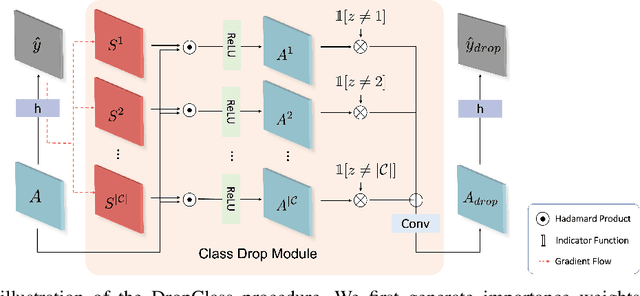
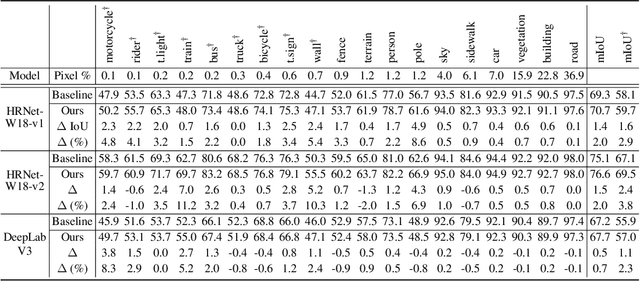
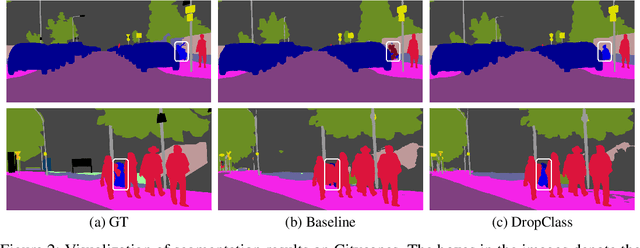

Deep neural networks are susceptible to learn biased models with entangled feature representations, which may lead to subpar performances on various downstream tasks. This is particularly true for under-represented classes, where a lack of diversity in the data exacerbates the tendency. This limitation has been addressed mostly in classification tasks, but there is little study on additional challenges that may appear in more complex dense prediction problems including semantic segmentation. To this end, we propose a model-agnostic and stochastic training scheme for semantic segmentation, which facilitates the learning of debiased and disentangled representations. For each class, we first extract class-specific information from the highly entangled feature map. Then, information related to a randomly sampled class is suppressed by a feature selection process in the feature space. By randomly eliminating certain class information in each training iteration, we effectively reduce feature dependencies among classes, and the model is able to learn more debiased and disentangled feature representations. Models trained with our approach demonstrate strong results on multiple semantic segmentation benchmarks, with especially notable performance gains on under-represented classes.
BI-GCN: Boundary-Aware Input-Dependent Graph Convolution Network for Biomedical Image Segmentation
Oct 31, 2021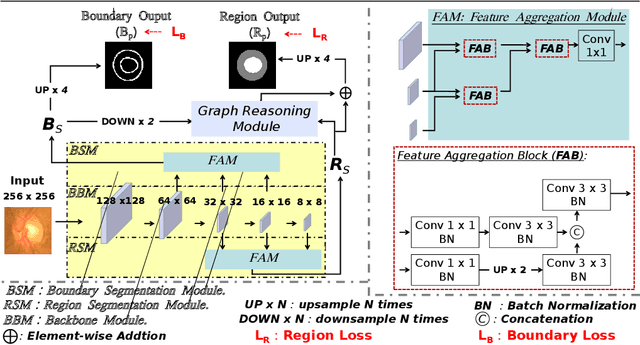



Segmentation is an essential operation of image processing. The convolution operation suffers from a limited receptive field, while global modelling is fundamental to segmentation tasks. In this paper, we apply graph convolution into the segmentation task and propose an improved \textit{Laplacian}. Different from existing methods, our \textit{Laplacian} is data-dependent, and we introduce two attention diagonal matrices to learn a better vertex relationship. In addition, it takes advantage of both region and boundary information when performing graph-based information propagation. Specifically, we model and reason about the boundary-aware region-wise correlations of different classes through learning graph representations, which is capable of manipulating long range semantic reasoning across various regions with the spatial enhancement along the object's boundary. Our model is well-suited to obtain global semantic region information while also accommodates local spatial boundary characteristics simultaneously. Experiments on two types of challenging datasets demonstrate that our method outperforms the state-of-the-art approaches on the segmentation of polyps in colonoscopy images and of the optic disc and optic cup in colour fundus images.
Catch Me If You Hear Me: Audio-Visual Navigation in Complex Unmapped Environments with Moving Sounds
Nov 29, 2021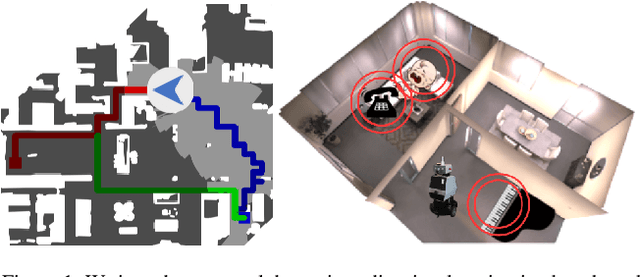
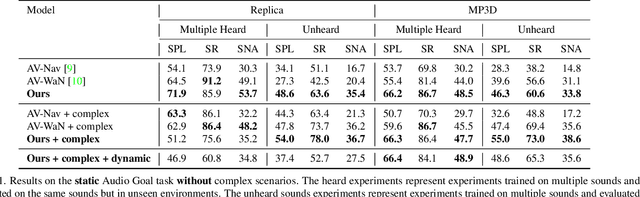
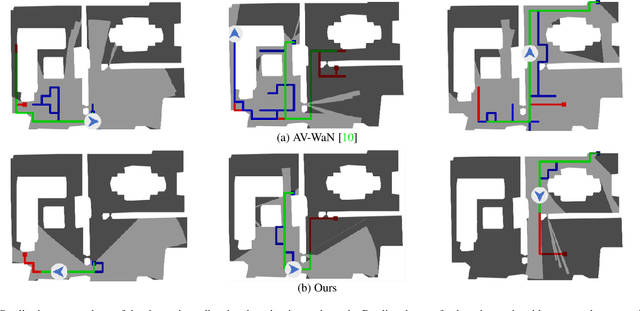
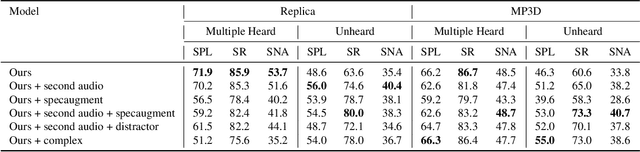
Audio-visual navigation combines sight and hearing to navigate to a sound-emitting source in an unmapped environment. While recent approaches have demonstrated the benefits of audio input to detect and find the goal, they focus on clean and static sound sources and struggle to generalize to unheard sounds. In this work, we propose the novel dynamic audio-visual navigation benchmark which requires to catch a moving sound source in an environment with noisy and distracting sounds. We introduce a reinforcement learning approach that learns a robust navigation policy for these complex settings. To achieve this, we propose an architecture that fuses audio-visual information in the spatial feature space to learn correlations of geometric information inherent in both local maps and audio signals. We demonstrate that our approach consistently outperforms the current state-of-the-art by a large margin across all tasks of moving sounds, unheard sounds, and noisy environments, on two challenging 3D scanned real-world environments, namely Matterport3D and Replica. The benchmark is available at http://dav-nav.cs.uni-freiburg.de.
FairEdit: Preserving Fairness in Graph Neural Networks through Greedy Graph Editing
Jan 12, 2022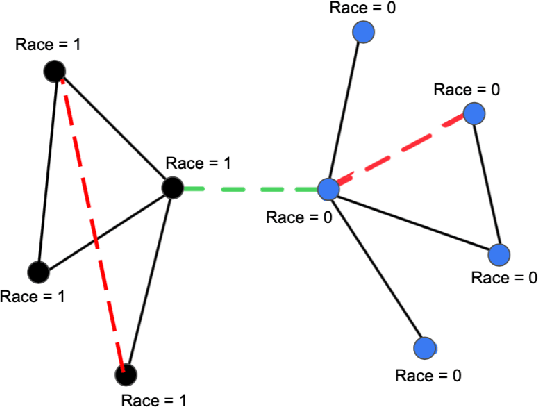
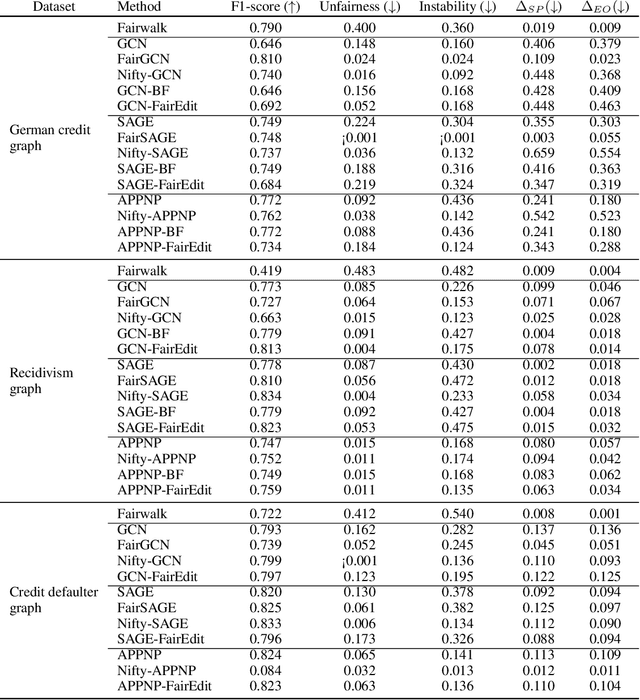
Graph Neural Networks (GNNs) have proven to excel in predictive modeling tasks where the underlying data is a graph. However, as GNNs are extensively used in human-centered applications, the issue of fairness has arisen. While edge deletion is a common method used to promote fairness in GNNs, it fails to consider when data is inherently missing fair connections. In this work we consider the unexplored method of edge addition, accompanied by deletion, to promote fairness. We propose two model-agnostic algorithms to perform edge editing: a brute force approach and a continuous approximation approach, FairEdit. FairEdit performs efficient edge editing by leveraging gradient information of a fairness loss to find edges that improve fairness. We find that FairEdit outperforms standard training for many data sets and GNN methods, while performing comparably to many state-of-the-art methods, demonstrating FairEdit's ability to improve fairness across many domains and models.
3D Infomax improves GNNs for Molecular Property Prediction
Oct 08, 2021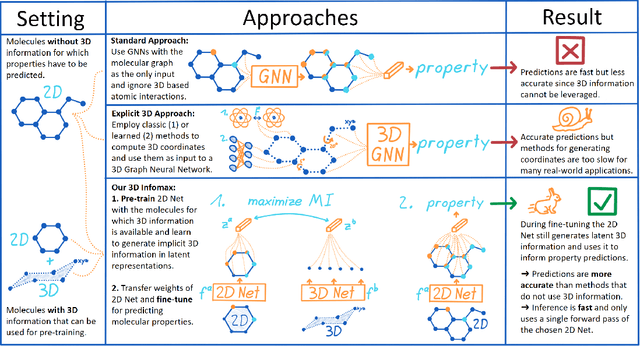
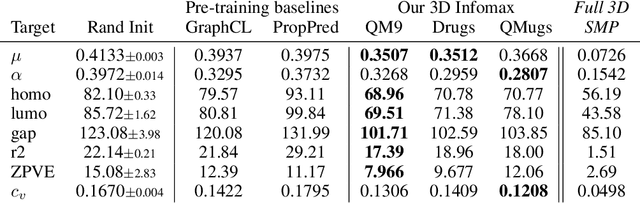
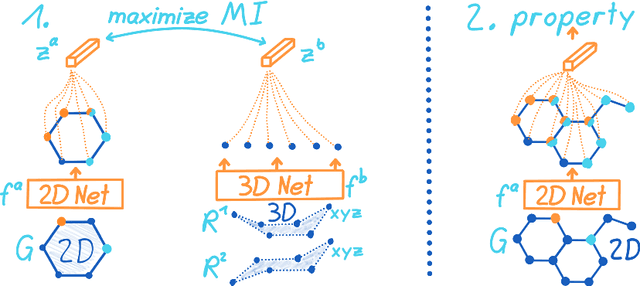

Molecular property prediction is one of the fastest-growing applications of deep learning with critical real-world impacts. Including 3D molecular structure as input to learned models their performance for many molecular tasks. However, this information is infeasible to compute at the scale required by several real-world applications. We propose pre-training a model to reason about the geometry of molecules given only their 2D molecular graphs. Using methods from self-supervised learning, we maximize the mutual information between 3D summary vectors and the representations of a Graph Neural Network (GNN) such that they contain latent 3D information. During fine-tuning on molecules with unknown geometry, the GNN still generates implicit 3D information and can use it to improve downstream tasks. We show that 3D pre-training provides significant improvements for a wide range of properties, such as a 22% average MAE reduction on eight quantum mechanical properties. Moreover, the learned representations can be effectively transferred between datasets in different molecular spaces.
My(o) Armband Leaks Passwords: An EMG and IMU Based Keylogging Side-Channel Attack
Dec 04, 2021
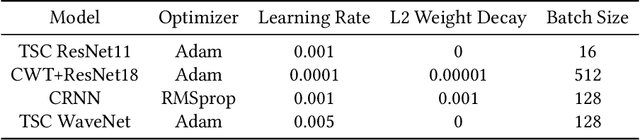

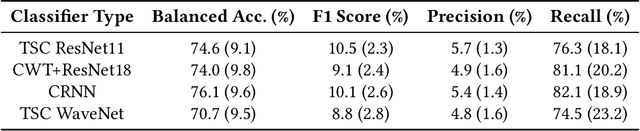
Wearables that constantly collect various sensor data of their users increase the chances for inferences of unintentional and sensitive information such as passwords typed on a physical keyboard. We take a thorough look at the potential of using electromyographic (EMG) data, a sensor modality which is new to the market but has lately gained attention in the context of wearables for augmented reality (AR), for a keylogging side-channel attack. Our approach is based on neural networks for a between-subject attack in a realistic scenario using the Myo Armband to collect the sensor data. In our approach, the EMG data has proven to be the most prominent source of information compared to the accelerometer and gyroscope, increasing the keystroke detection performance. For our end-to-end approach on raw data, we report a mean balanced accuracy of about 76 % for the keystroke detection and a mean top-3 key accuracy of about 32 % on 52 classes for the key identification on passwords of varying strengths. We have created an extensive dataset including more than 310 000 keystrokes recorded from 37 volunteers, which is available as open access along with the source code used to create the given results.
* 24 pages, 10 figures, the source code is available at https://github.com/seemoo-lab/myo-keylogging and the dataset is available at https://doi.org/10.5281/zenodo.5594651