 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Recurrent Reinforcement Learning Crypto Agent
Jan 12, 2022
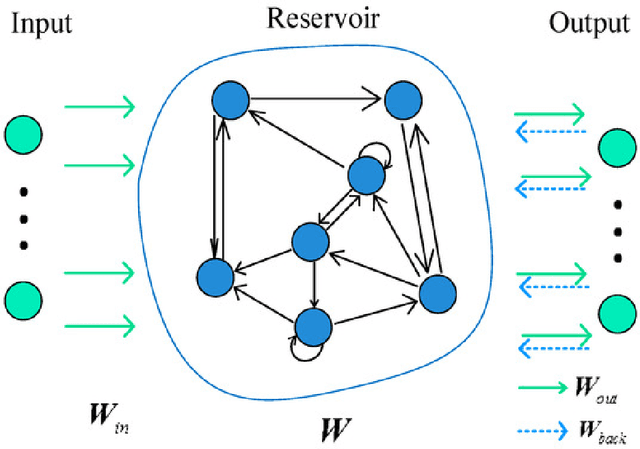
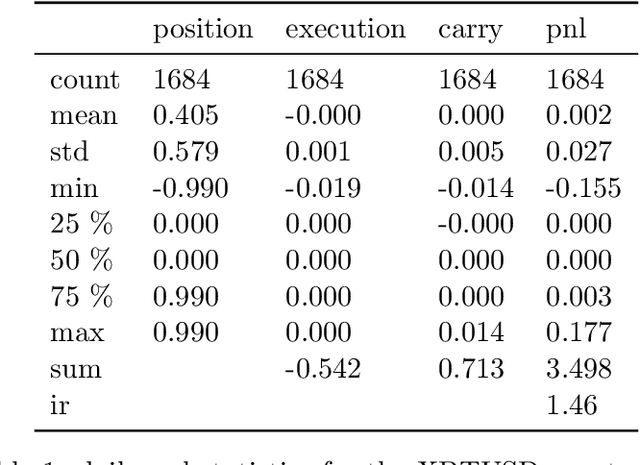
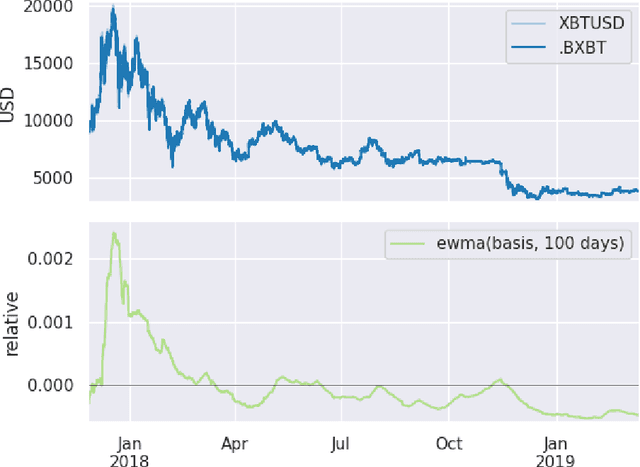
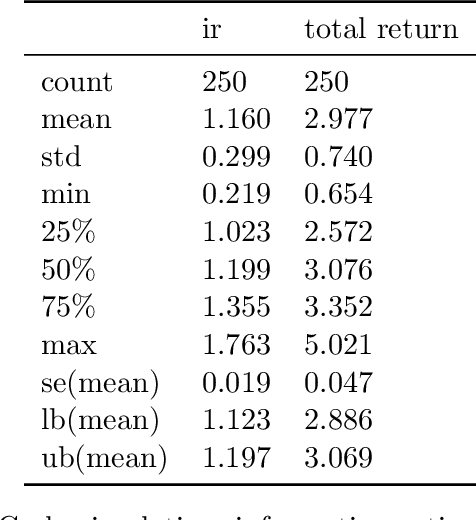
We demonstrate an application of online transfer learning as a digital assets trading agent. This agent makes use of a powerful feature space representation in the form of an echo state network, the output of which is made available to a direct, recurrent reinforcement learning agent. The agent learns to trade the XBTUSD (Bitcoin versus US dollars) perpetual swap derivatives contract on BitMEX. It learns to trade intraday on five minutely sampled data, avoids excessive over-trading, captures a funding profit and is also able to predict the direction of the market. Overall, our crypto agent realises a total return of 350%, net of transaction costs, over roughly five years, 71% of which is down to funding profit. The annualised information ratio that it achieves is 1.46.
CentSmoothie: Central-Smoothing Hypergraph Neural Networks for Predicting Drug-Drug Interactions
Dec 15, 2021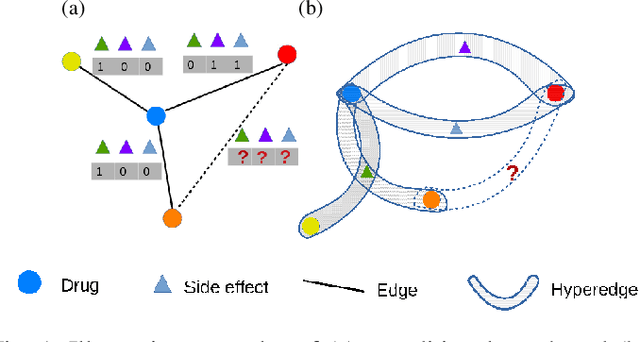
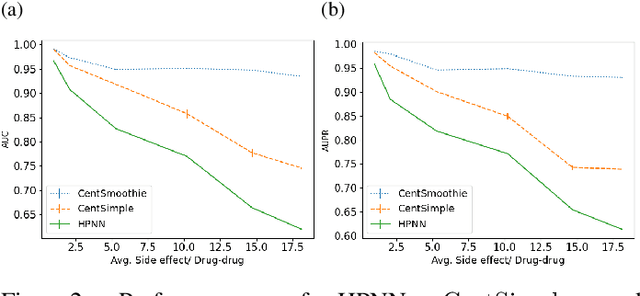
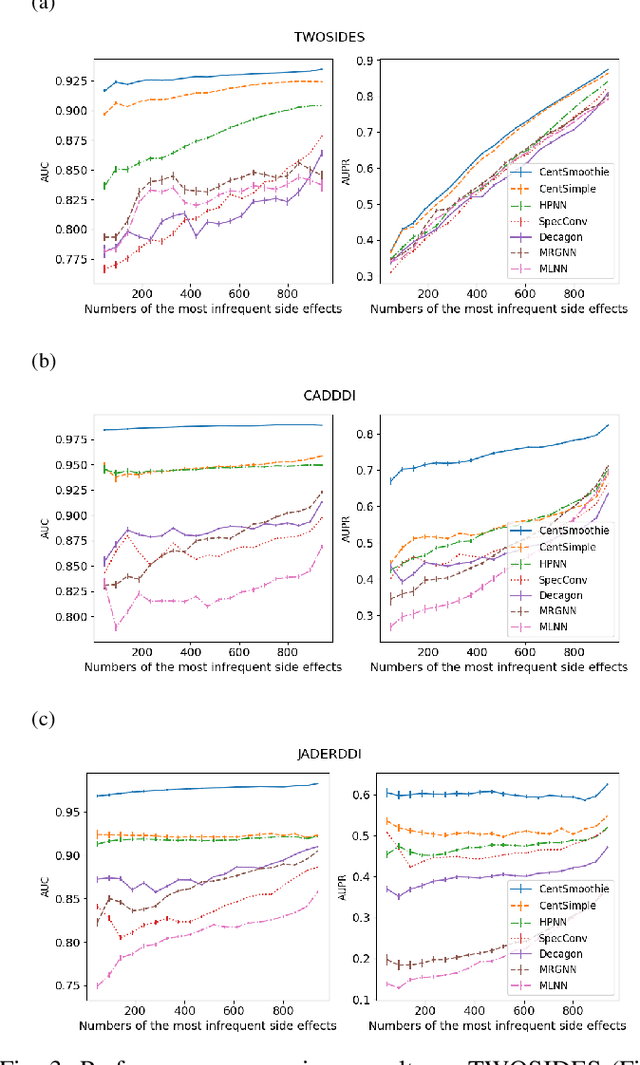
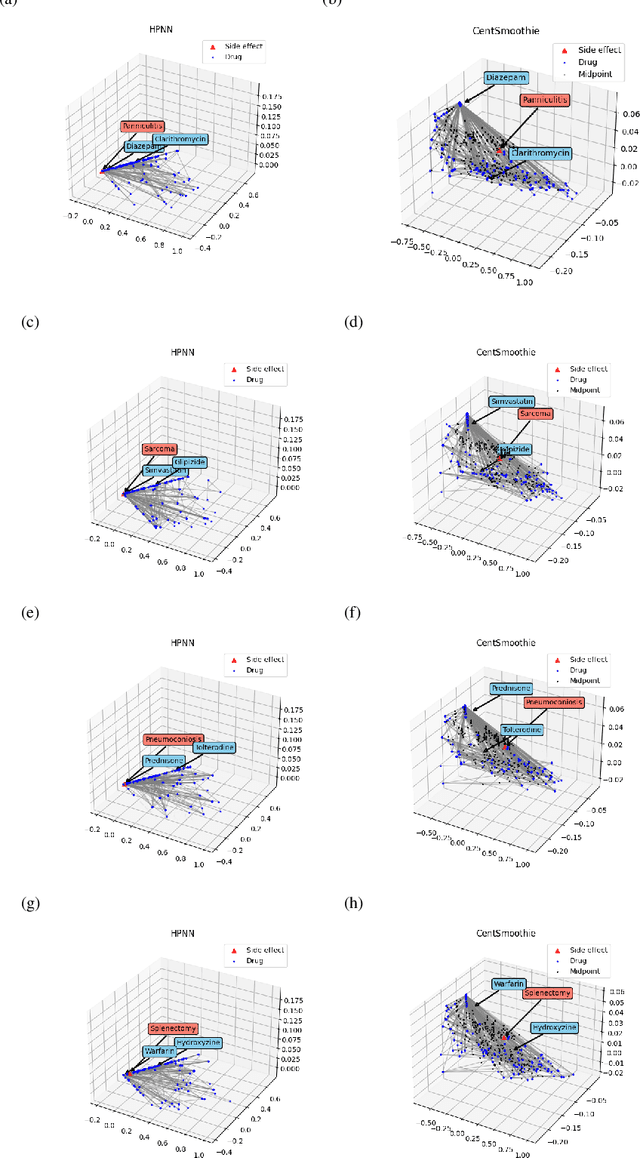
Predicting drug-drug interactions (DDI) is the problem of predicting side effects (unwanted outcomes) of a pair of drugs using drug information and known side effects of many pairs. This problem can be formulated as predicting labels (i.e. side effects) for each pair of nodes in a DDI graph, of which nodes are drugs and edges are interacting drugs with known labels. State-of-the-art methods for this problem are graph neural networks (GNNs), which leverage neighborhood information in the graph to learn node representations. For DDI, however, there are many labels with complicated relationships due to the nature of side effects. Usual GNNs often fix labels as one-hot vectors that do not reflect label relationships and potentially do not obtain the highest performance in the difficult cases of infrequent labels. In this paper, we formulate DDI as a hypergraph where each hyperedge is a triple: two nodes for drugs and one node for a label. We then present CentSmoothie, a hypergraph neural network that learns representations of nodes and labels altogether with a novel central-smoothing formulation. We empirically demonstrate the performance advantages of CentSmoothie in simulations as well as real datasets.
Unsupervised Hierarchical Graph Representation Learning by Mutual Information Maximization
Mar 18, 2020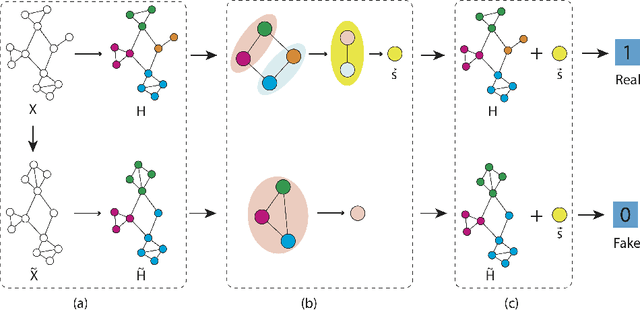
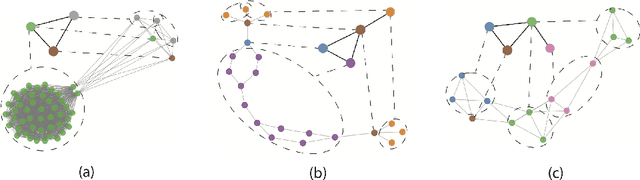
Graph representation learning based on graph neural networks (GNNs) can greatly improve the performance of downstream tasks, such as node and graph classification. However, the general GNN models cannot aggregate node information in a hierarchical manner, and thus cannot effectively capture the structural features of graphs. In addition, most of the existing hierarchical graph representation learning are supervised, which are limited by the extreme cost of acquiring labeled data. To address these issues, we present an unsupervised graph representation learning method, Unsupervised Hierarchical Graph Representation UHGR, which can generate hierarchical representations of graphs. This contrastive learning technique focuses on maximizing mutual information between "local" and high-level "global" representations, which enables us to learn the node embeddings and graph embeddings without any labeled data. To demonstrate the effectiveness of the proposed method, we perform the node and graph classification using the learned node and graph embeddings. The results show that the proposed method achieves comparable results to state-of-the-art supervised methods on several benchmarks. In addition, our visualization of hierarchical representations indicates that our method can capture meaningful and interpretable clusters.
Augmenting Neural Differential Equations to Model Unknown Dynamical Systems with Incomplete State Information
Aug 22, 2020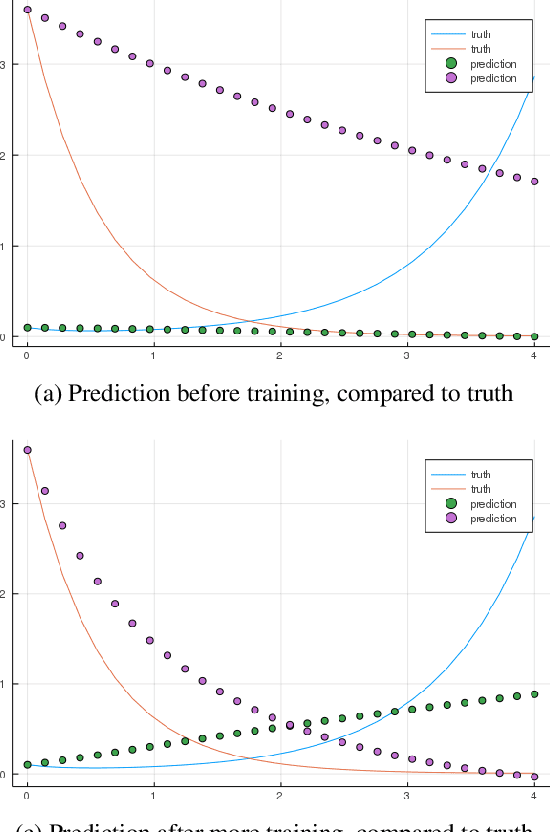
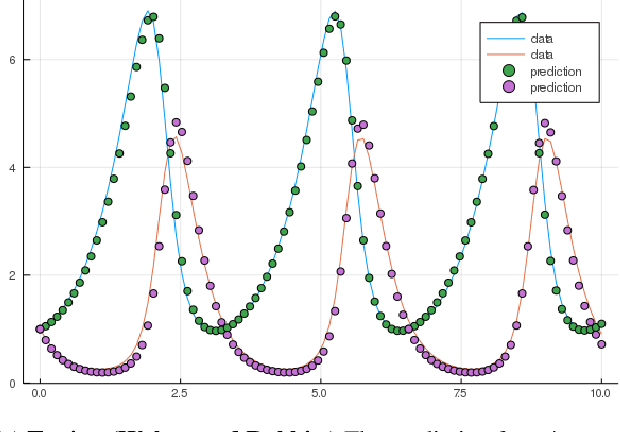
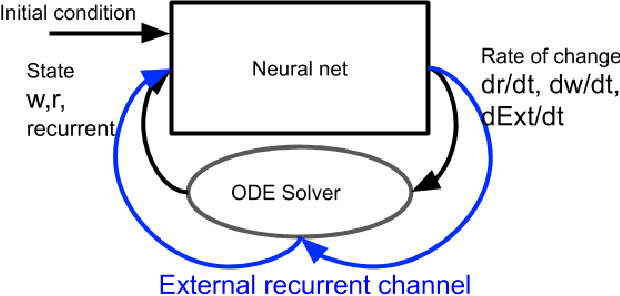
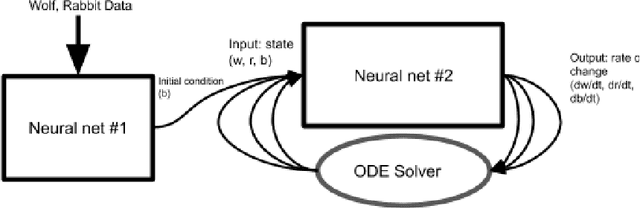
Neural Ordinary Differential Equations replace the right-hand side of a conventional ODE with a neural net, which by virtue of the universal approximation theorem, can be trained to the representation of any function. When we do not know the function itself, but have state trajectories (time evolution) of the ODE system we can still train the neural net to learn the representation of the underlying but unknown ODE. However if the state of the system is incompletely known then the right-hand side of the ODE cannot be calculated. The derivatives to propagate the system are unavailable. We show that a specially augmented Neural ODE can learn the system when given incomplete state information. As a worked example we apply neural ODEs to the Lotka-Voltera problem of 3 species, rabbits, wolves, and bears. We show that even when the data for the bear time series is removed the remaining time series of the rabbits and wolves is sufficient to learn the dynamical system despite the missing the incomplete state information. This is surprising since a conventional ODE system cannot output the correct derivatives without the full state as the input. We implement augmented neural ODEs and differential equation solvers in the julia programming language.
FINO: Flow-based Joint Image and Noise Model
Nov 11, 2021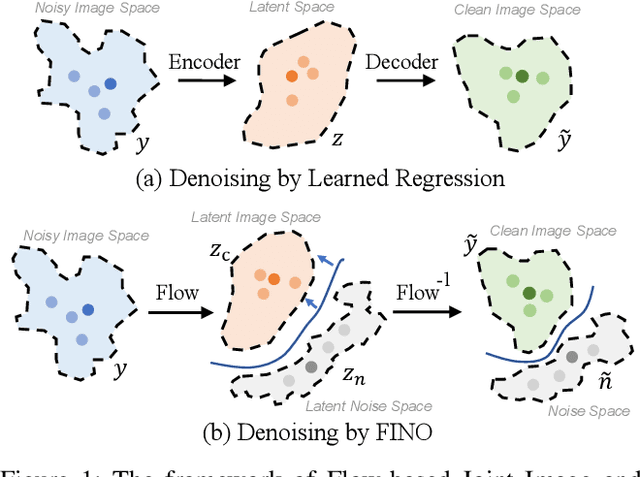
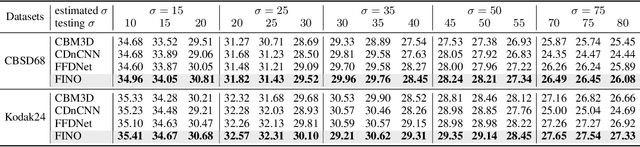
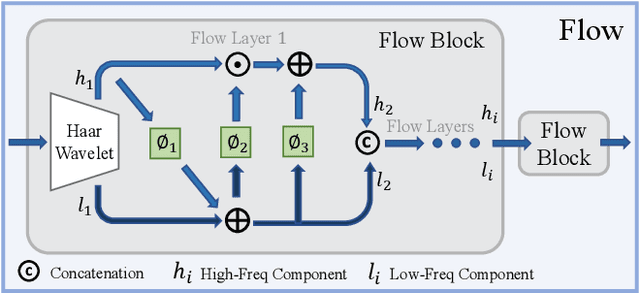
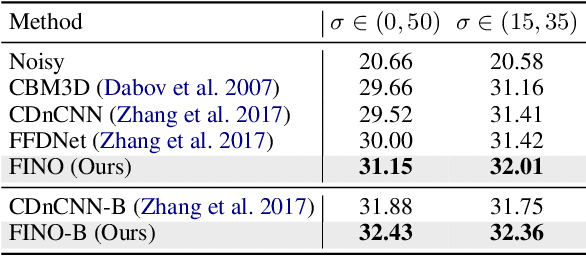
One of the fundamental challenges in image restoration is denoising, where the objective is to estimate the clean image from its noisy measurements. To tackle such an ill-posed inverse problem, the existing denoising approaches generally focus on exploiting effective natural image priors. The utilization and analysis of the noise model are often ignored, although the noise model can provide complementary information to the denoising algorithms. In this paper, we propose a novel Flow-based joint Image and NOise model (FINO) that distinctly decouples the image and noise in the latent space and losslessly reconstructs them via a series of invertible transformations. We further present a variable swapping strategy to align structural information in images and a noise correlation matrix to constrain the noise based on spatially minimized correlation information. Experimental results demonstrate FINO's capacity to remove both synthetic additive white Gaussian noise (AWGN) and real noise. Furthermore, the generalization of FINO to the removal of spatially variant noise and noise with inaccurate estimation surpasses that of the popular and state-of-the-art methods by large margins.
COVID-19 Hospitalizations Forecasts Using Internet Search Data
Feb 03, 2022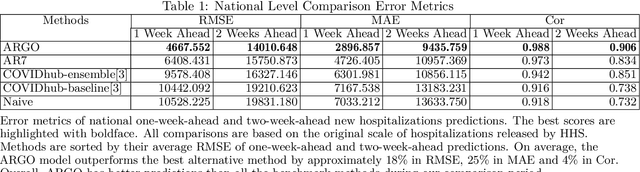
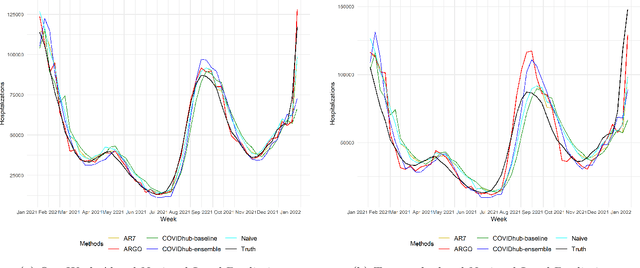
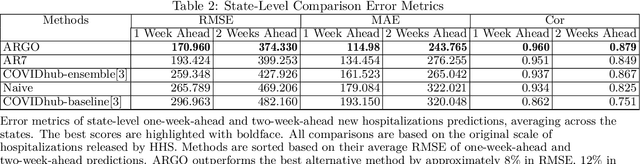
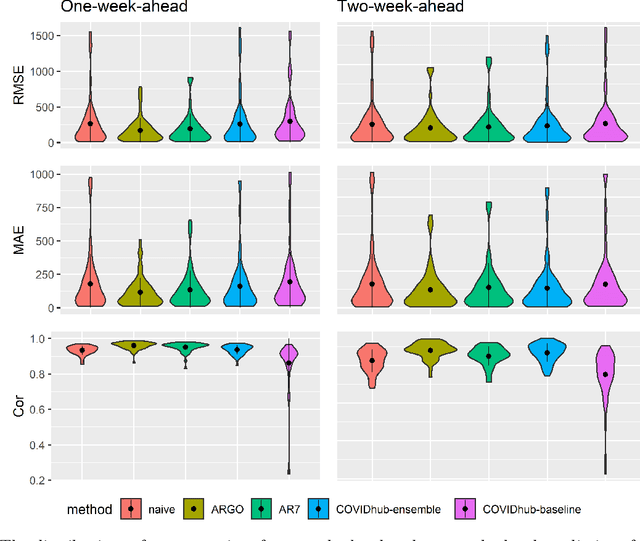
As the COVID-19 spread over the globe and new variants of COVID-19 keep occurring, reliable real-time forecasts of COVID-19 hospitalizations are critical for public health decision on medical resources allocations such as ICU beds, ventilators, and personnel to prepare for the surge of COVID-19 pandemics. Inspired by the strong association between public search behavior and hospitalization admission, we extended previously-proposed influenza tracking model, ARGO (AutoRegression with GOogle search data), to predict future 2-week national and state-level COVID-19 new hospital admissions. Leveraging the COVID-19 related time series information and Google search data, our method is able to robustly capture new COVID-19 variants' surges, and self-correct at both national and state level. Based on our retrospective out-of-sample evaluation over 12-month comparison period, our method achieves on average 15\% error reduction over the best alternative models collected from COVID-19 forecast hub. Overall, we showed that our method is flexible, self-correcting, robust, accurate, and interpretable, making it a potentially powerful tool to assist health-care officials and decision making for the current and future infectious disease outbreak.
Boosting Graph Neural Networks by Injecting Pooling in Message Passing
Feb 08, 2022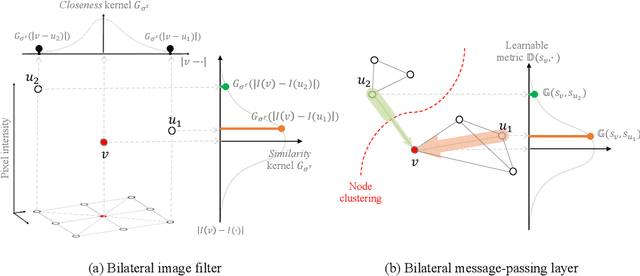

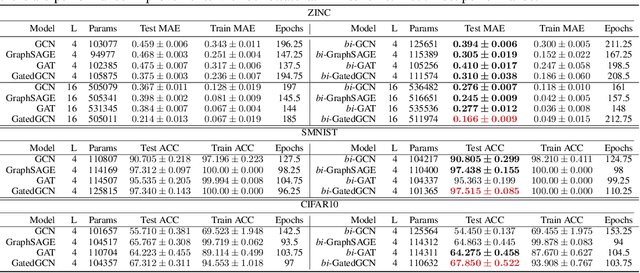
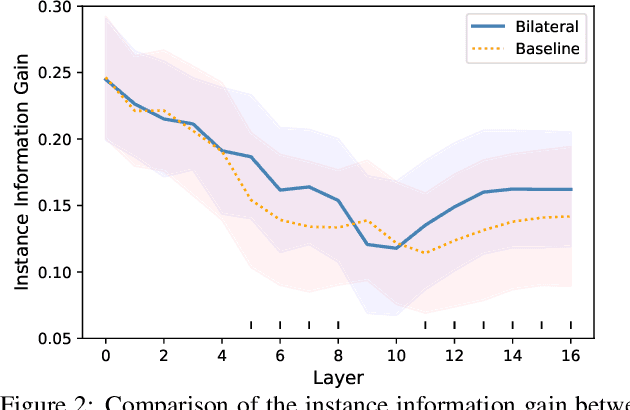
There has been tremendous success in the field of graph neural networks (GNNs) as a result of the development of the message-passing (MP) layer, which updates the representation of a node by combining it with its neighbors to address variable-size and unordered graphs. Despite the fruitful progress of MP GNNs, their performance can suffer from over-smoothing, when node representations become too similar and even indistinguishable from one another. Furthermore, it has been reported that intrinsic graph structures are smoothed out as the GNN layer increases. Inspired by the edge-preserving bilateral filters used in image processing, we propose a new, adaptable, and powerful MP framework to prevent over-smoothing. Our bilateral-MP estimates a pairwise modular gradient by utilizing the class information of nodes, and further preserves the global graph structure by using the gradient when the aggregating function is applied. Our proposed scheme can be generalized to all ordinary MP GNNs. Experiments on five medium-size benchmark datasets using four state-of-the-art MP GNNs indicate that the bilateral-MP improves performance by alleviating over-smoothing. By inspecting quantitative measurements, we additionally validate the effectiveness of the proposed mechanism in preventing the over-smoothing issue.
Input correlations impede suppression of chaos and learning in balanced rate networks
Jan 24, 2022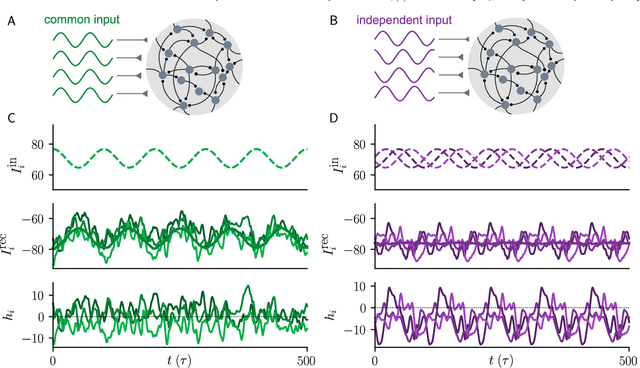
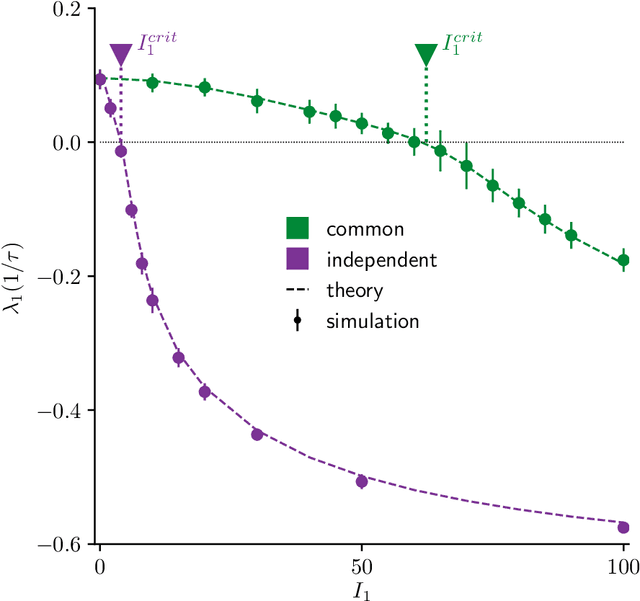
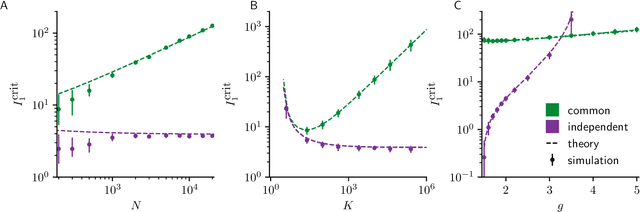
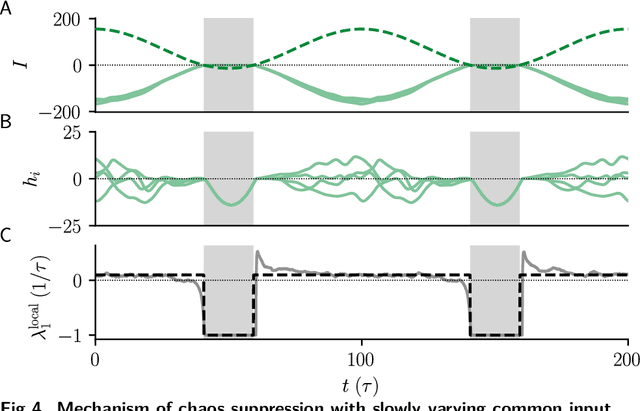
Neural circuits exhibit complex activity patterns, both spontaneously and evoked by external stimuli. Information encoding and learning in neural circuits depend on how well time-varying stimuli can control spontaneous network activity. We show that in firing-rate networks in the balanced state, external control of recurrent dynamics, i.e., the suppression of internally-generated chaotic variability, strongly depends on correlations in the input. A unique feature of balanced networks is that, because common external input is dynamically canceled by recurrent feedback, it is far easier to suppress chaos with independent inputs into each neuron than through common input. To study this phenomenon we develop a non-stationary dynamic mean-field theory that determines how the activity statistics and largest Lyapunov exponent depend on frequency and amplitude of the input, recurrent coupling strength, and network size, for both common and independent input. We also show that uncorrelated inputs facilitate learning in balanced networks.
A Robust Phased Elimination Algorithm for Corruption-Tolerant Gaussian Process Bandits
Feb 03, 2022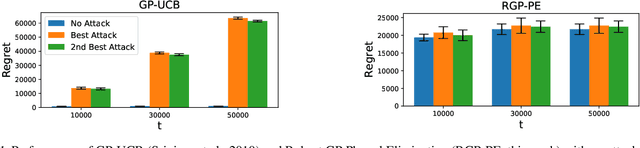

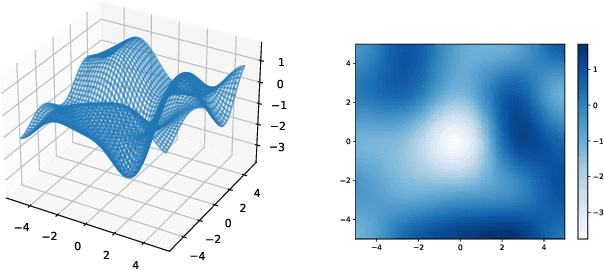
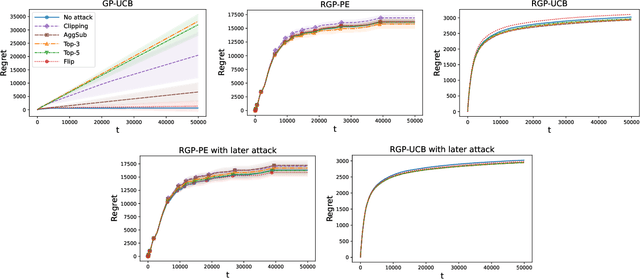
We consider the sequential optimization of an unknown, continuous, and expensive to evaluate reward function, from noisy and adversarially corrupted observed rewards. When the corruption attacks are subject to a suitable budget $C$ and the function lives in a Reproducing Kernel Hilbert Space (RKHS), the problem can be posed as corrupted Gaussian process (GP) bandit optimization. We propose a novel robust elimination-type algorithm that runs in epochs, combines exploration with infrequent switching to select a small subset of actions, and plays each action for multiple time instants. Our algorithm, Robust GP Phased Elimination (RGP-PE), successfully balances robustness to corruptions with exploration and exploitation such that its performance degrades minimally in the presence (or absence) of adversarial corruptions. When $T$ is the number of samples and $\gamma_T$ is the maximal information gain, the corruption-dependent term in our regret bound is $O(C \gamma_T^{3/2})$, which is significantly tighter than the existing $O(C \sqrt{T \gamma_T})$ for several commonly-considered kernels. We perform the first empirical study of robustness in the corrupted GP bandit setting, and show that our algorithm is robust against a variety of adversarial attacks.
Deep Decoding of $\ell_\infty$-coded Light Field Images
Jan 24, 2022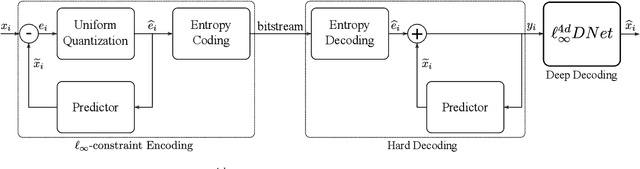
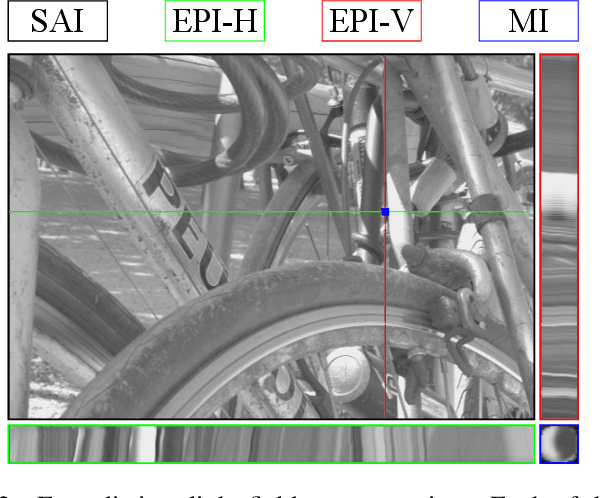
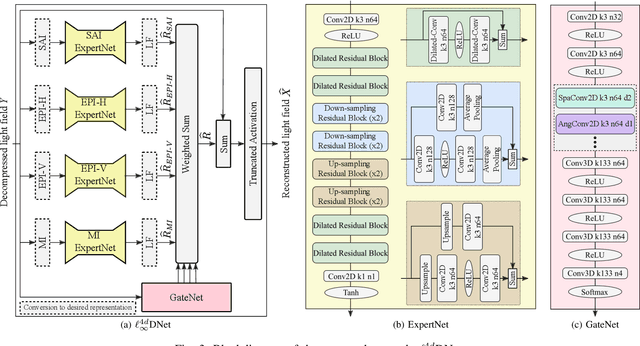
To enrich the functionalities of traditional cameras, light field cameras record both the intensity and direction of light rays, so that images can be rendered with user-defined camera parameters via computations. The added capability and flexibility are gained at the cost of gathering typically more than $100\times$ greater amount of information than conventional images. To cope with this issue, several light field compression schemes have been introduced. However, their ways of exploiting correlations of multidimensional light field data are complex and are hence not suited for inexpensive light field cameras. In this work, we propose a novel $\ell_\infty$-constrained light-field image compression system that has a very low-complexity DPCM encoder and a CNN-based deep decoder. Targeting high-fidelity reconstruction, the CNN decoder capitalizes on the $\ell_\infty$-constraint and light field properties to remove the compression artifacts and achieves significantly better performance than existing state-of-the-art $\ell_2$-based light field compression methods.