 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Impact of Using Regression Models to Build Defect Classifiers
Feb 12, 2022
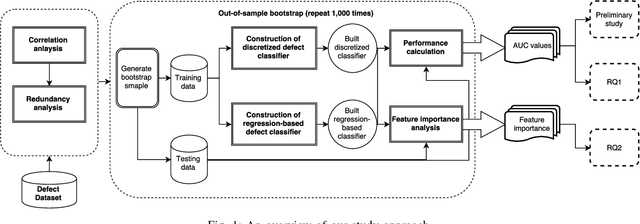
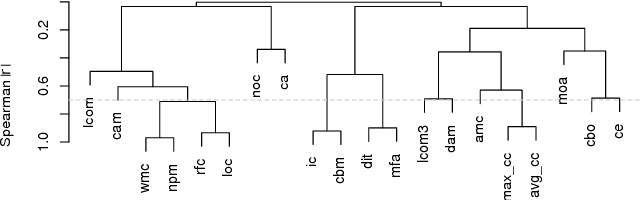
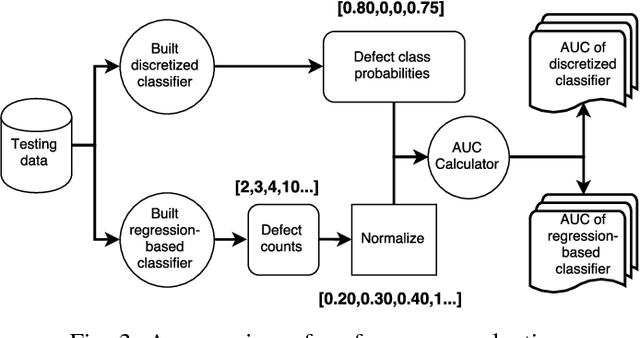
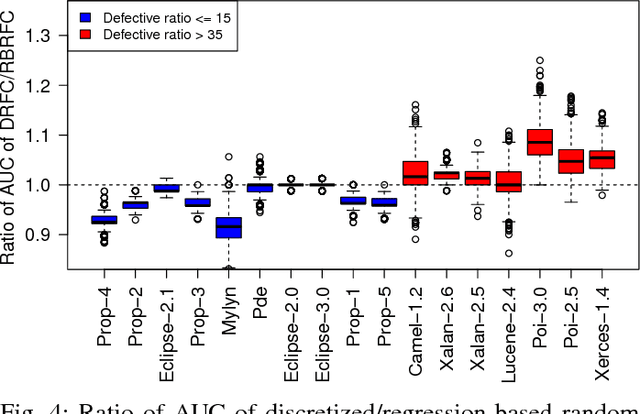
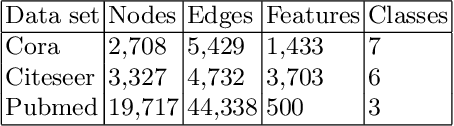
It is common practice to discretize continuous defect counts into defective and non-defective classes and use them as a target variable when building defect classifiers (discretized classifiers). However, this discretization of continuous defect counts leads to information loss that might affect the performance and interpretation of defect classifiers. Another possible approach to build defect classifiers is through the use of regression models then discretizing the predicted defect counts into defective and non-defective classes (regression-based classifiers). In this paper, we compare the performance and interpretation of defect classifiers that are built using both approaches (i.e., discretized classifiers and regression-based classifiers) across six commonly used machine learning classifiers (i.e., linear/logistic regression, random forest, KNN, SVM, CART, and neural networks) and 17 datasets. We find that: i) Random forest based classifiers outperform other classifiers (best AUC) for both classifier building approaches; ii) In contrast to common practice, building a defect classifier using discretized defect counts (i.e., discretized classifiers) does not always lead to better performance. Hence we suggest that future defect classification studies should consider building regression-based classifiers (in particular when the defective ratio of the modeled dataset is low). Moreover, we suggest that both approaches for building defect classifiers should be explored, so the best-performing classifier can be used when determining the most influential features.
SelfRecon: Self Reconstruction Your Digital Avatar from Monocular Video
Jan 30, 2022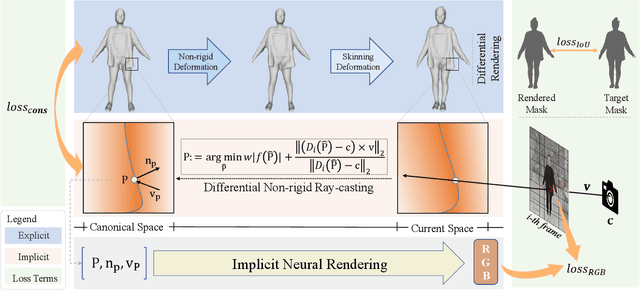
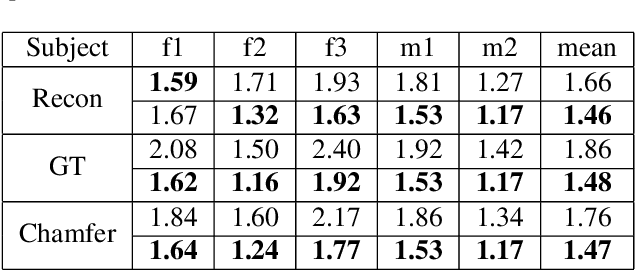
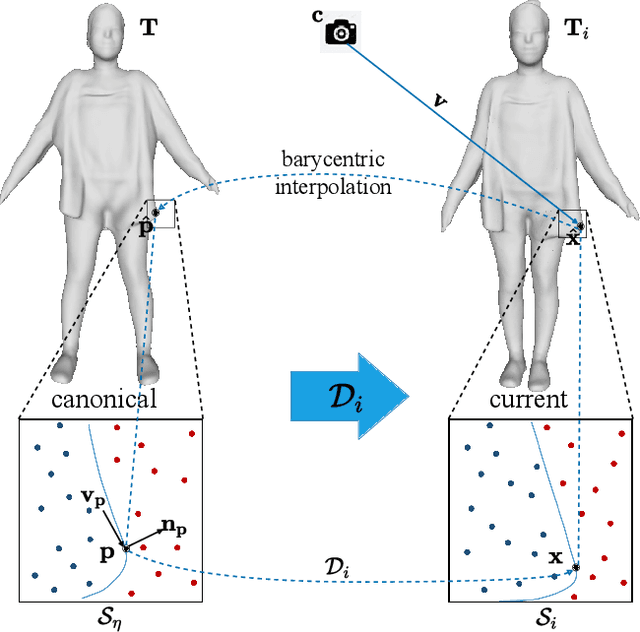

We propose SelfRecon, a clothed human body reconstruction method that combines implicit and explicit representations to recover space-time coherent geometries from a monocular self-rotating human video. Explicit methods require a predefined template mesh for a given sequence, while the template is hard to acquire for a specific subject. Meanwhile, the fixed topology limits the reconstruction accuracy and clothing types. Implicit methods support arbitrary topology and have high quality due to continuous geometric representation. However, it is difficult to integrate multi-frame information to produce a consistent registration sequence for downstream applications. We propose to combine the advantages of both representations. We utilize differential mask loss of the explicit mesh to obtain the coherent overall shape, while the details on the implicit surface are refined with the differentiable neural rendering. Meanwhile, the explicit mesh is updated periodically to adjust its topology changes, and a consistency loss is designed to match both representations closely. Compared with existing methods, SelfRecon can produce high-fidelity surfaces for arbitrary clothed humans with self-supervised optimization. Extensive experimental results demonstrate its effectiveness on real captured monocular videos.
A Central Difference Graph Convolutional Operator for Skeleton-Based Action Recognition
Nov 13, 2021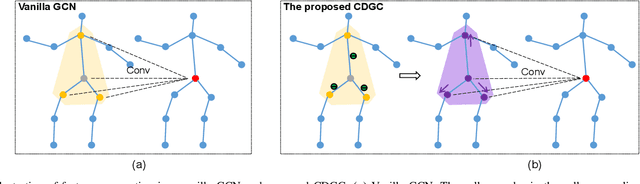
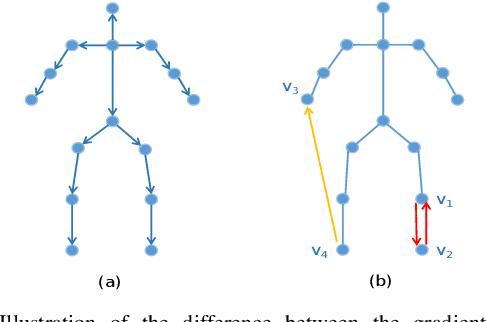
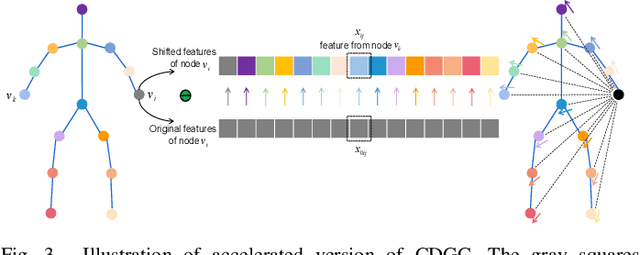
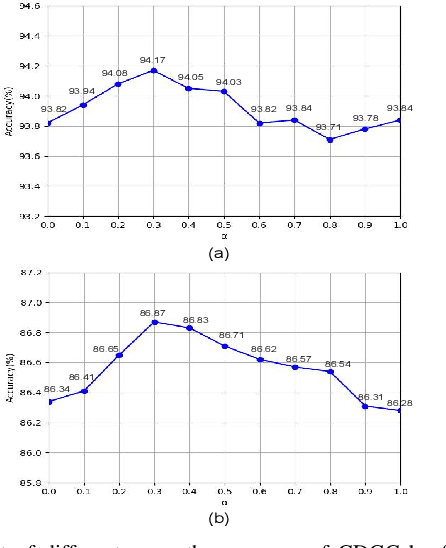
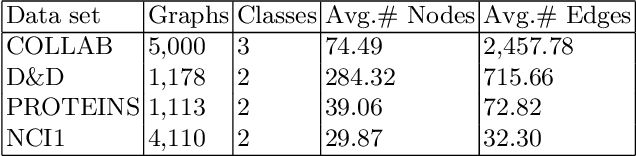
This paper proposes a new graph convolutional operator called central difference graph convolution (CDGC) for skeleton based action recognition. It is not only able to aggregate node information like a vanilla graph convolutional operation but also gradient information. Without introducing any additional parameters, CDGC can replace vanilla graph convolution in any existing Graph Convolutional Networks (GCNs). In addition, an accelerated version of the CDGC is developed which greatly improves the speed of training. Experiments on two popular large-scale datasets NTU RGB+D 60 & 120 have demonstrated the efficacy of the proposed CDGC. Code is available at https://github.com/iesymiao/CD-GCN.
Motion Sickness Modeling with Visual Vertical Estimation and Its Application to Autonomous Personal Mobility Vehicles
Feb 20, 2022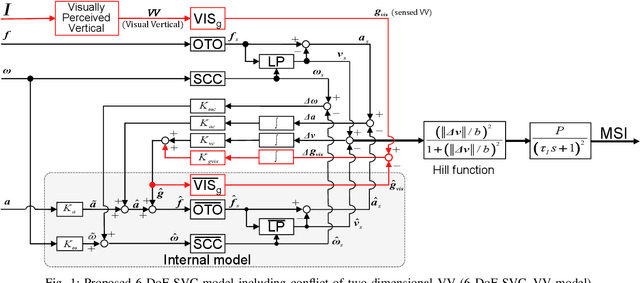


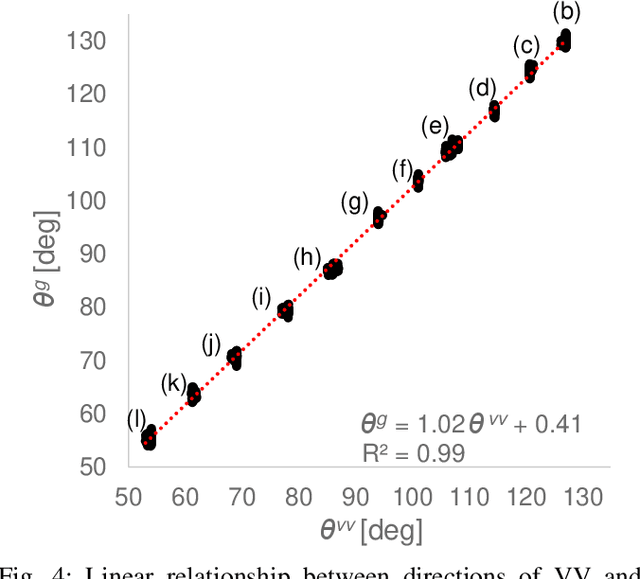
Passengers (drivers) of level 3-5 autonomous personal mobility vehicles (APMV) and cars can perform non-driving tasks, such as reading books and smartphones, while driving. It has been pointed out that such activities may increase motion sickness. Many studies have been conducted to build countermeasures, of which various computational motion sickness models have been developed. Many of these are based on subjective vertical conflict (SVC) theory, which describes vertical changes in direction sensed by human sensory organs vs. those expected by the central nervous system. Such models are expected to be applied to autonomous driving scenarios. However, no current computational model can integrate visual vertical information with vestibular sensations. We proposed a 6 DoF SVC-VV model which add a visually perceived vertical block into a conventional six-degrees-of-freedom SVC model to predict VV directions from image data simulating the visual input of a human. Hence, a simple image-based VV estimation method is proposed. As the validation of the proposed model, this paper focuses on describing the fact that the motion sickness increases as a passenger reads a book while using an AMPV, assuming that visual vertical (VV) plays an important role. In the static experiment, it is demonstrated that the estimated VV by the proposed method accurately described the gravitational acceleration direction with a low mean absolute deviation. In addition, the results of the driving experiment using an APMV demonstrated that the proposed 6 DoF SVC-VV model could describe that the increased motion sickness experienced when the VV and gravitational acceleration directions were different.
Online Bayesian Recommendation with No Regret
Feb 12, 2022We introduce and study the online Bayesian recommendation problem for a platform, who can observe a utility-relevant state of a product, repeatedly interacting with a population of myopic users through an online recommendation mechanism. This paradigm is common in a wide range of scenarios in the current Internet economy. For each user with her own private preference and belief, the platform commits to a recommendation strategy to utilize his information advantage on the product state to persuade the self-interested user to follow the recommendation. The platform does not know user's preferences and beliefs, and has to use an adaptive recommendation strategy to persuade with gradually learning user's preferences and beliefs in the process. We aim to design online learning policies with no Stackelberg regret for the platform, i.e., against the optimum policy in hindsight under the assumption that users will correspondingly adapt their behaviors to the benchmark policy. Our first result is an online policy that achieves double logarithm regret dependence on the number of rounds. We then present a hardness result showing that no adaptive online policy can achieve regret with better dependency on the number of rounds. Finally, by formulating the platform's problem as optimizing a linear program with membership oracle access, we present our second online policy that achieves regret with polynomial dependence on the number of states but logarithm dependence on the number of rounds.
Deep Cellular Recurrent Network for Efficient Analysis of Time-Series Data with Spatial Information
Jan 12, 2021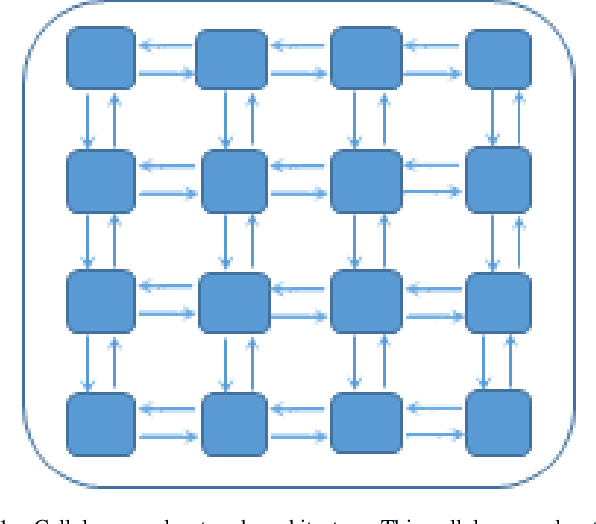
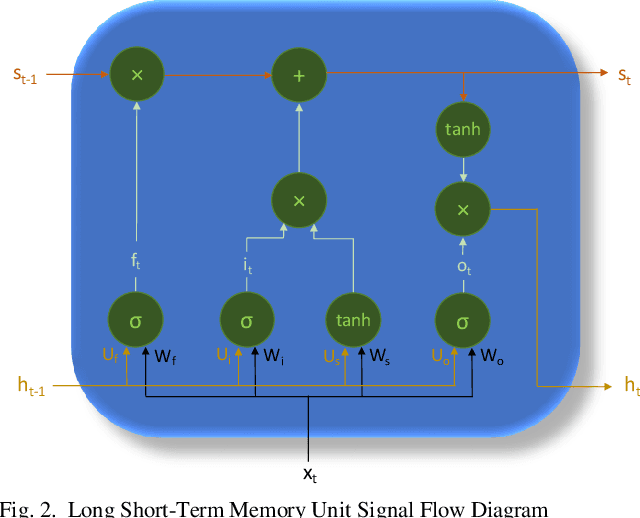
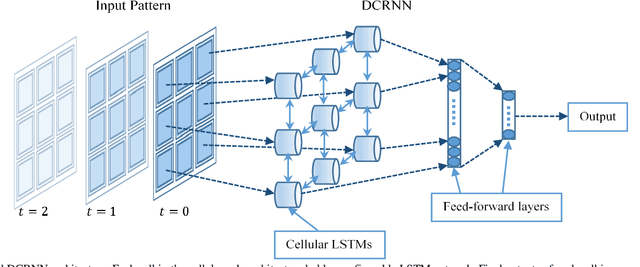
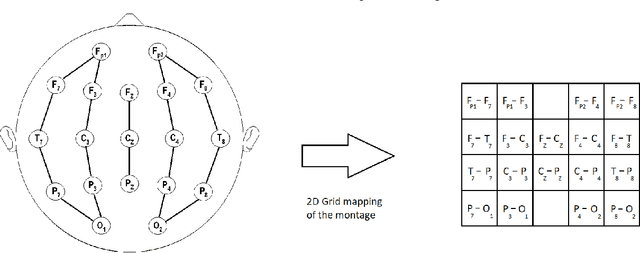
Efficient processing of large-scale time series data is an intricate problem in machine learning. Conventional sensor signal processing pipelines with hand engineered feature extraction often involve huge computational cost with high dimensional data. Deep recurrent neural networks have shown promise in automated feature learning for improved time-series processing. However, generic deep recurrent models grow in scale and depth with increased complexity of the data. This is particularly challenging in presence of high dimensional data with temporal and spatial characteristics. Consequently, this work proposes a novel deep cellular recurrent neural network (DCRNN) architecture to efficiently process complex multi-dimensional time series data with spatial information. The cellular recurrent architecture in the proposed model allows for location-aware synchronous processing of time series data from spatially distributed sensor signal sources. Extensive trainable parameter sharing due to cellularity in the proposed architecture ensures efficiency in the use of recurrent processing units with high-dimensional inputs. This study also investigates the versatility of the proposed DCRNN model for classification of multi-class time series data from different application domains. Consequently, the proposed DCRNN architecture is evaluated using two time-series datasets: a multichannel scalp EEG dataset for seizure detection, and a machine fault detection dataset obtained in-house. The results suggest that the proposed architecture achieves state-of-the-art performance while utilizing substantially less trainable parameters when compared to comparable methods in the literature.
Vision at A Glance: Interplay between Fine and Coarse Information Processing Pathways
Aug 23, 2020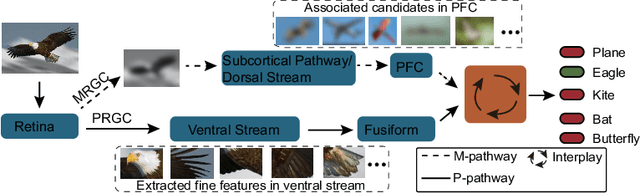
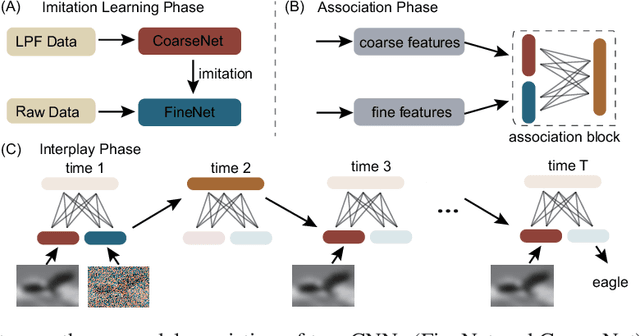

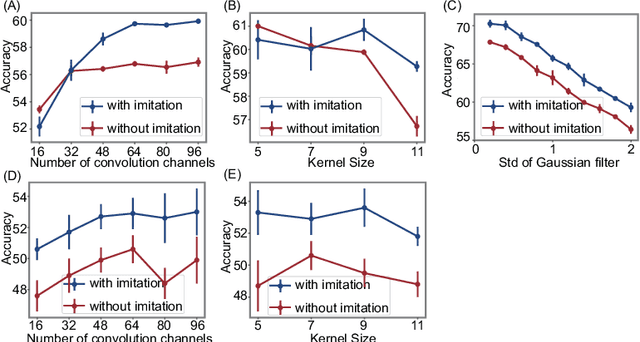
Object recognition is often viewed as a feedforward, bottom-up process in machine learning, but in real neural systems, object recognition is a complicated process which involves the interplay between two signal pathways. One is the parvocellular pathway (P-pathway), which is slow and extracts fine features of objects; the other is the magnocellular pathway (M-pathway), which is fast and extracts coarse features of objects. It has been suggested that the interplay between the two pathways endows the neural system with the capacity of processing visual information rapidly, adaptively, and robustly. However, the underlying computational mechanisms remain largely unknown. In this study, we build a computational model to elucidate the computational advantages associated with the interactions between two pathways. Our model consists of two convolution neural networks: one mimics the P-pathway, referred to as FineNet, which is deep, has small-size kernels, and receives detailed visual inputs; the other mimics the M-pathway, referred to as CoarseNet, which is shallow, has large-size kernels, and receives low-pass filtered or binarized visual inputs. The two pathways interact with each other via a Restricted Boltzmann Machine. We find that: 1) FineNet can teach CoarseNet through imitation and improve its performance considerably; 2) CoarseNet can improve the noise robustness of FineNet through association; 3) the output of CoarseNet can serve as a cognitive bias to improve the performance of FineNet. We hope that this study will provide insight into understanding visual information processing and inspire the development of new object recognition architectures.
Explainability of Predictive Process Monitoring Results: Can You See My Data Issues?
Feb 16, 2022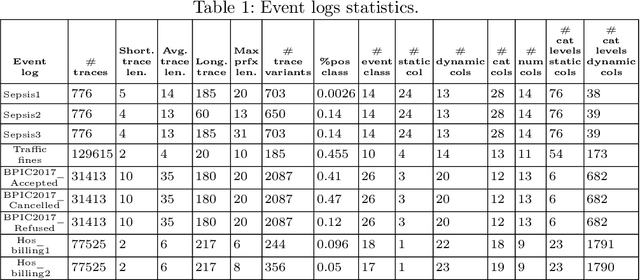

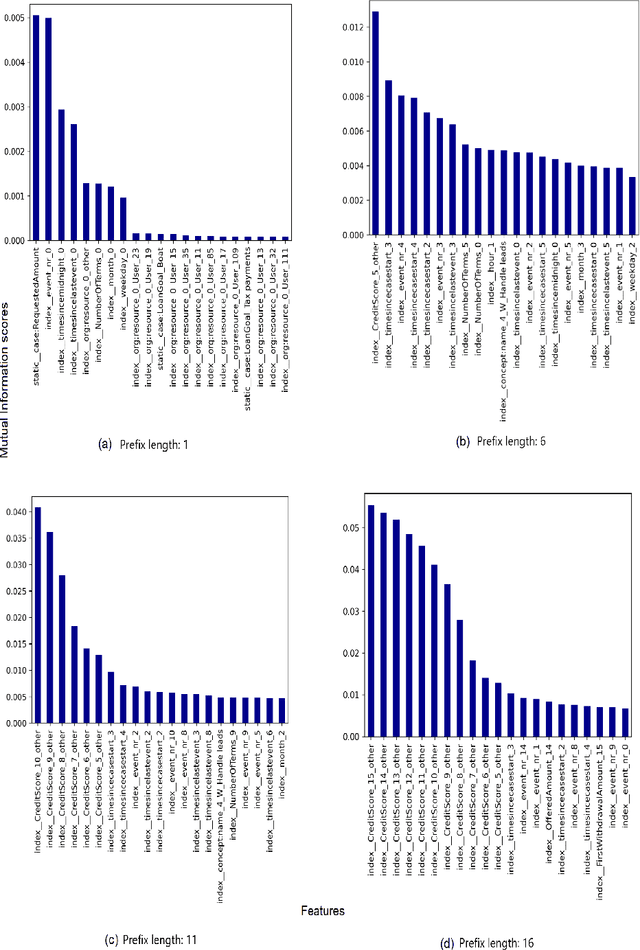
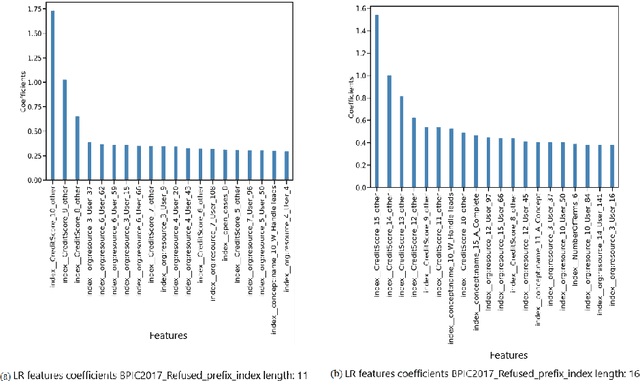
Predictive business process monitoring (PPM) has been around for several years as a use case of process mining. PPM enables foreseeing the future of a business process through predicting relevant information about how a running process instance might end, related performance indicators, and other predictable aspects. A big share of PPM approaches adopts a Machine Learning (ML) technique to address a prediction task, especially non-process-aware PPM approaches. Consequently, PPM inherits the challenges faced by ML approaches. One of these challenges concerns the need to gain user trust in the predictions generated. The field of explainable artificial intelligence (XAI) addresses this issue. However, the choices made, and the techniques employed in a PPM task, in addition to ML model characteristics, influence resulting explanations. A comparison of the influence of different settings on the generated explanations is missing. To address this gap, we investigate the effect of different PPM settings on resulting data fed into an ML model and consequently to a XAI method. We study how differences in resulting explanations may indicate several issues in underlying data. We construct a framework for our experiments including different settings at each stage of PPM with XAI integrated as a fundamental part. Our experiments reveal several inconsistencies, as well as agreements, between data characteristics (and hence expectations about these data), important data used by the ML model as a result of querying it, and explanations of predictions of the investigated ML model.
Unsupervised Hierarchical Graph Representation Learning by Mutual Information Maximization
Mar 18, 2020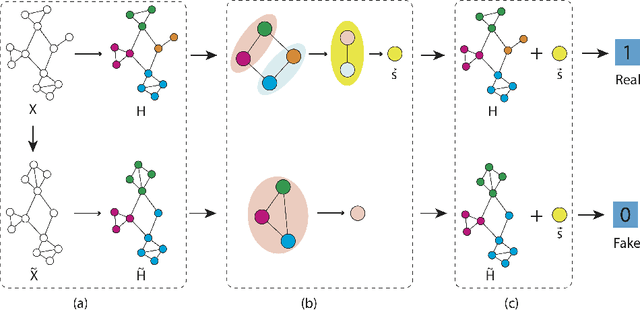
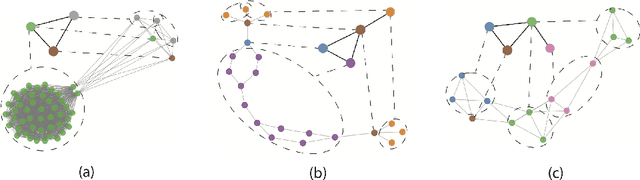
Graph representation learning based on graph neural networks (GNNs) can greatly improve the performance of downstream tasks, such as node and graph classification. However, the general GNN models cannot aggregate node information in a hierarchical manner, and thus cannot effectively capture the structural features of graphs. In addition, most of the existing hierarchical graph representation learning are supervised, which are limited by the extreme cost of acquiring labeled data. To address these issues, we present an unsupervised graph representation learning method, Unsupervised Hierarchical Graph Representation UHGR, which can generate hierarchical representations of graphs. This contrastive learning technique focuses on maximizing mutual information between "local" and high-level "global" representations, which enables us to learn the node embeddings and graph embeddings without any labeled data. To demonstrate the effectiveness of the proposed method, we perform the node and graph classification using the learned node and graph embeddings. The results show that the proposed method achieves comparable results to state-of-the-art supervised methods on several benchmarks. In addition, our visualization of hierarchical representations indicates that our method can capture meaningful and interpretable clusters.
Spectral Propagation Graph Network for Few-shot Time Series Classification
Feb 08, 2022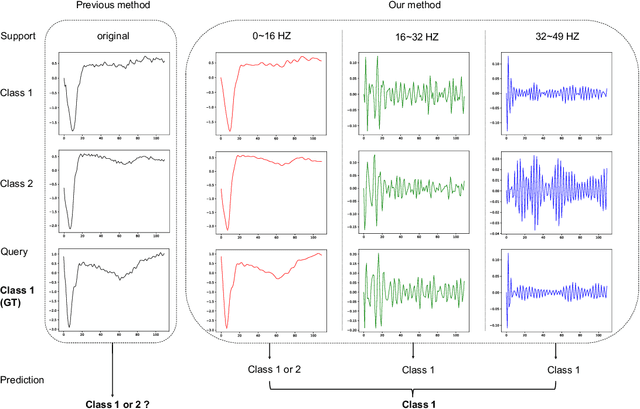
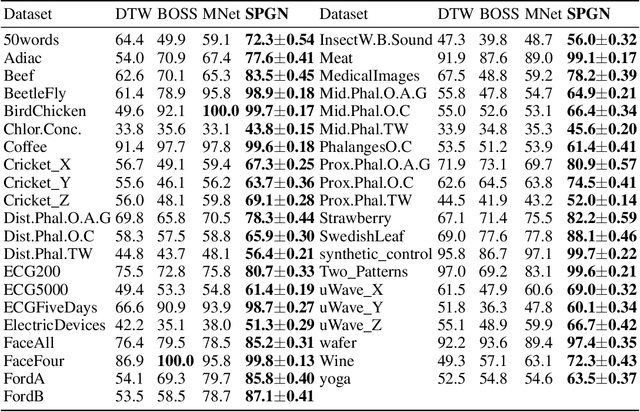
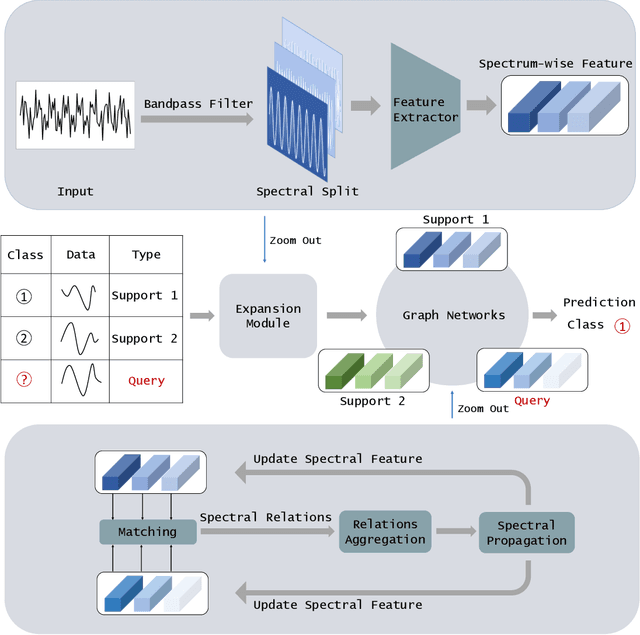
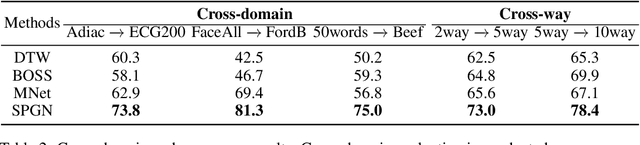
Few-shot Time Series Classification (few-shot TSC) is a challenging problem in time series analysis. It is more difficult to classify when time series of the same class are not completely consistent in spectral domain or time series of different classes are partly consistent in spectral domain. To address this problem, we propose a novel method named Spectral Propagation Graph Network (SPGN) to explicitly model and propagate the spectrum-wise relations between different time series with graph network. To the best of our knowledge, SPGN is the first to utilize spectral comparisons in different intervals and involve spectral propagation across all time series with graph networks for few-shot TSC. SPGN first uses bandpass filter to expand time series in spectral domain for calculating spectrum-wise relations between time series. Equipped with graph networks, SPGN then integrates spectral relations with label information to make spectral propagation. The further study conveys the bi-directional effect between spectral relations acquisition and spectral propagation. We conduct extensive experiments on few-shot TSC benchmarks. SPGN outperforms state-of-the-art results by a large margin in $4\% \sim 13\%$. Moreover, SPGN surpasses them by around $12\%$ and $9\%$ under cross-domain and cross-way settings respectively.