 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enabling Reproducibility and Meta-learning Through a Lifelong Database of Experiments (LDE)
Feb 23, 2022
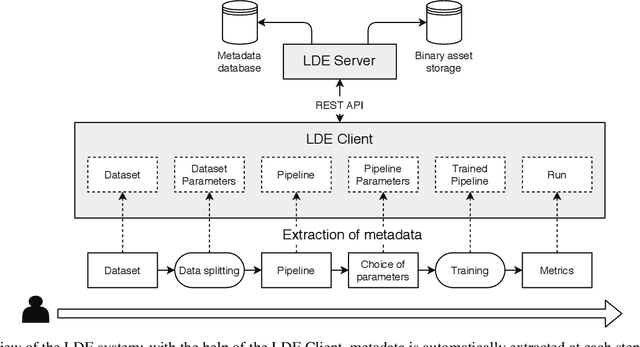
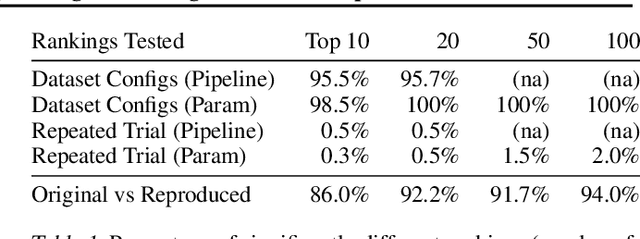
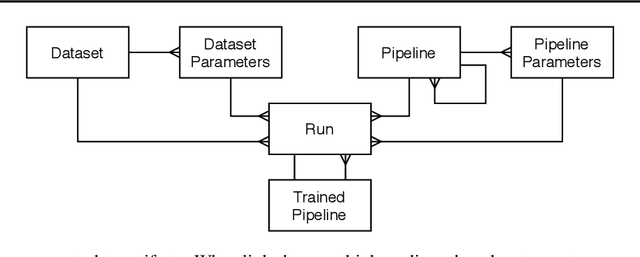

Artificial Intelligence (AI) development is inherently iterative and experimental. Over the course of normal development, especially with the advent of automated AI, hundreds or thousands of experiments are generated and are often lost or never examined again. There is a lost opportunity to document these experiments and learn from them at scale, but the complexity of tracking and reproducing these experiments is often prohibitive to data scientists. We present the Lifelong Database of Experiments (LDE) that automatically extracts and stores linked metadata from experiment artifacts and provides features to reproduce these artifacts and perform meta-learning across them. We store context from multiple stages of the AI development lifecycle including datasets, pipelines, how each is configured, and training runs with information about their runtime environment. The standardized nature of the stored metadata allows for querying and aggregation, especially in terms of ranking artifacts by performance metrics. We exhibit the capabilities of the LDE by reproducing an existing meta-learning study and storing the reproduced metadata in our system. Then, we perform two experiments on this metadata: 1) examining the reproducibility and variability of the performance metrics and 2) implementing a number of meta-learning algorithms on top of the data and examining how variability in experimental results impacts recommendation performance. The experimental results suggest significant variation in performance, especially depending on dataset configurations; this variation carries over when meta-learning is built on top of the results, with performance improving when using aggregated results. This suggests that a system that automatically collects and aggregates results such as the LDE not only assists in implementing meta-learning but may also improve its performance.
Expert Human-Level Driving in Gran Turismo Sport Using Deep Reinforcement Learning with Image-based Representation
Nov 11, 2021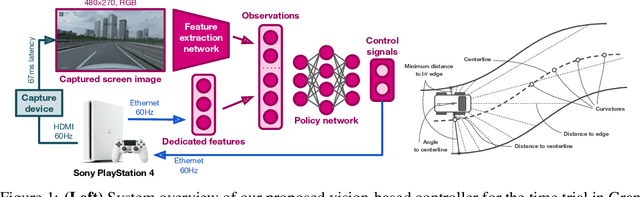

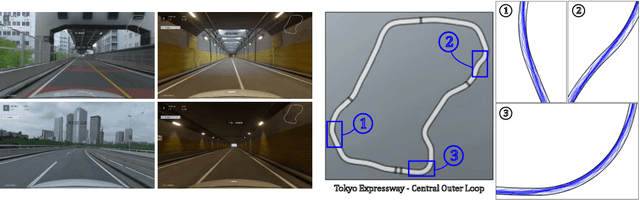
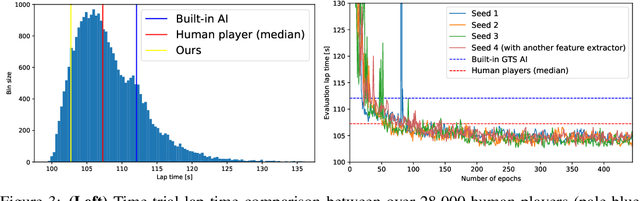
When humans play virtual racing games, they use visual environmental information on the game screen to understand the rules within the environments. In contrast, a state-of-the-art realistic racing game AI agent that outperforms human players does not use image-based environmental information but the compact and precise measurements provided by the environment. In this paper, a vision-based control algorithm is proposed and compared with human player performances under the same conditions in realistic racing scenarios using Gran Turismo Sport (GTS), which is known as a high-fidelity realistic racing simulator. In the proposed method, the environmental information that constitutes part of the observations in conventional state-of-the-art methods is replaced with feature representations extracted from game screen images. We demonstrate that the proposed method performs expert human-level vehicle control under high-speed driving scenarios even with game screen images as high-dimensional inputs. Additionally, it outperforms the built-in AI in GTS in a time trial task, and its score places it among the top 10% approximately 28,000 human players.
GearNet: Stepwise Dual Learning for Weakly Supervised Domain Adaptation
Jan 25, 2022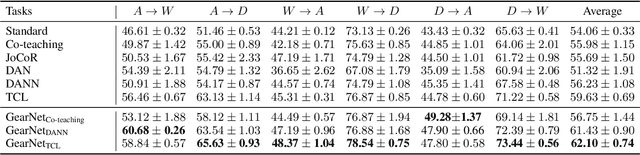
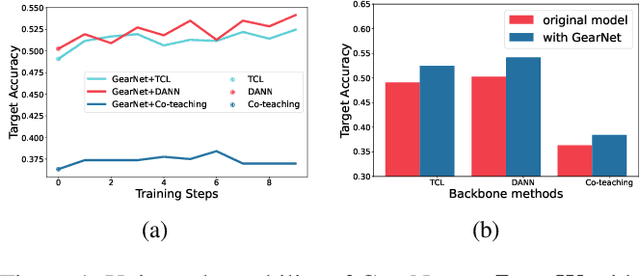
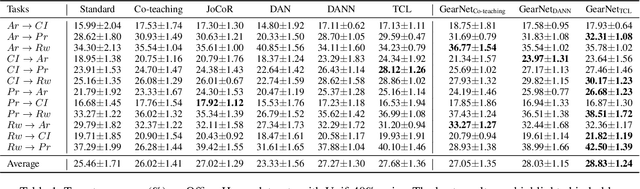
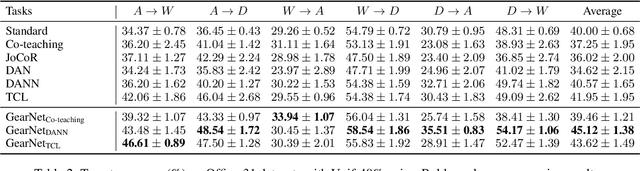
This paper studies weakly supervised domain adaptation(WSDA) problem, where we only have access to the source domain with noisy labels, from which we need to transfer useful information to the unlabeled target domain. Although there have been a few studies on this problem, most of them only exploit unidirectional relationships from the source domain to the target domain. In this paper, we propose a universal paradigm called GearNet to exploit bilateral relationships between the two domains. Specifically, we take the two domains as different inputs to train two models alternately, and asymmetrical Kullback-Leibler loss is used for selectively matching the predictions of the two models in the same domain. This interactive learning schema enables implicit label noise canceling and exploits correlations between the source and target domains. Therefore, our GearNet has the great potential to boost the performance of a wide range of existing WSDL methods. Comprehensive experimental results show that the performance of existing methods can be significantly improved by equipping with our GearNet.
Deep Learning Aided Packet Routing in Aeronautical Ad-Hoc Networks Relying on Real Flight Data: From Single-Objective to Near-Pareto Multi-Objective Optimization
Oct 28, 2021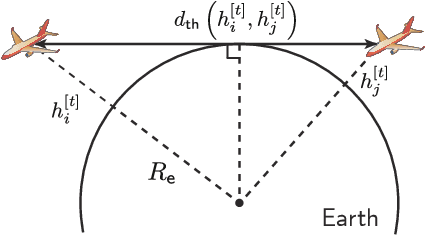
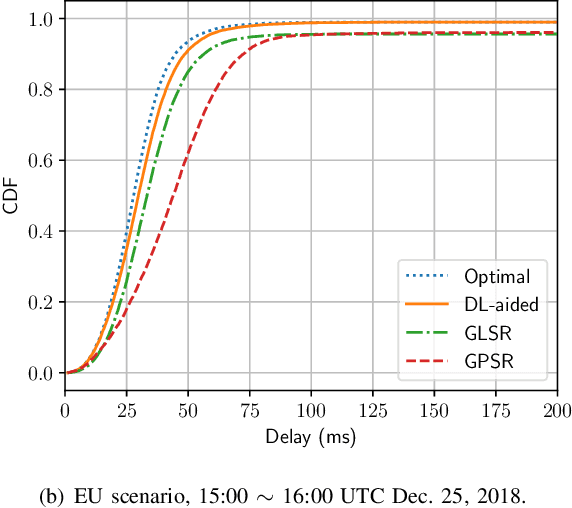
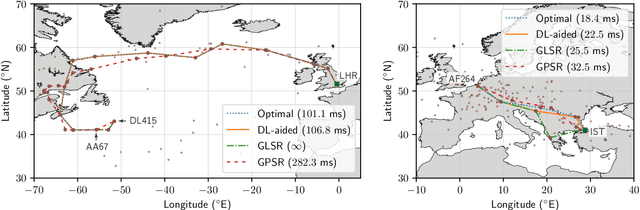
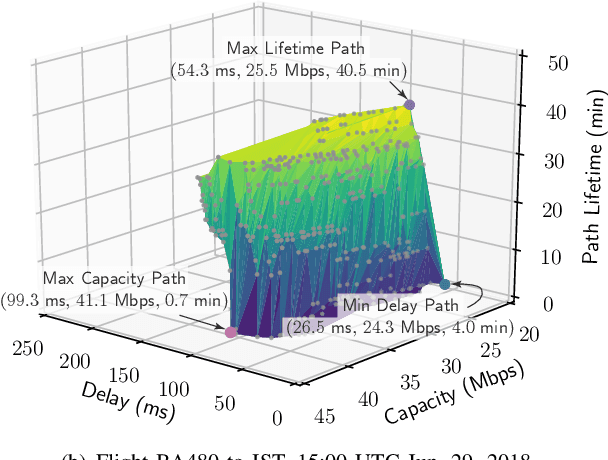
Data packet routing in aeronautical ad-hoc networks (AANETs) is challenging due to their high-dynamic topology. In this paper, we invoke deep learning (DL) to assist routing in AANETs. We set out from the single objective of minimizing the end-to-end (E2E) delay. Specifically, a deep neural network (DNN) is conceived for mapping the local geographic information observed by the forwarding node into the information required for determining the optimal next hop. The DNN is trained by exploiting the regular mobility pattern of commercial passenger airplanes from historical flight data. After training, the DNN is stored by each airplane for assisting their routing decisions during flight relying solely on local geographic information. Furthermore, we extend the DL-aided routing algorithm to a multi-objective scenario, where we aim for simultaneously minimizing the delay, maximizing the path capacity, and maximizing the path lifetime. Our simulation results based on real flight data show that the proposed DL-aided routing outperforms existing position-based routing protocols in terms of its E2E delay, path capacity as well as path lifetime, and it is capable of approaching the Pareto front that is obtained using global link information.
Clustering by the Probability Distributions from Extreme Value Theory
Feb 20, 2022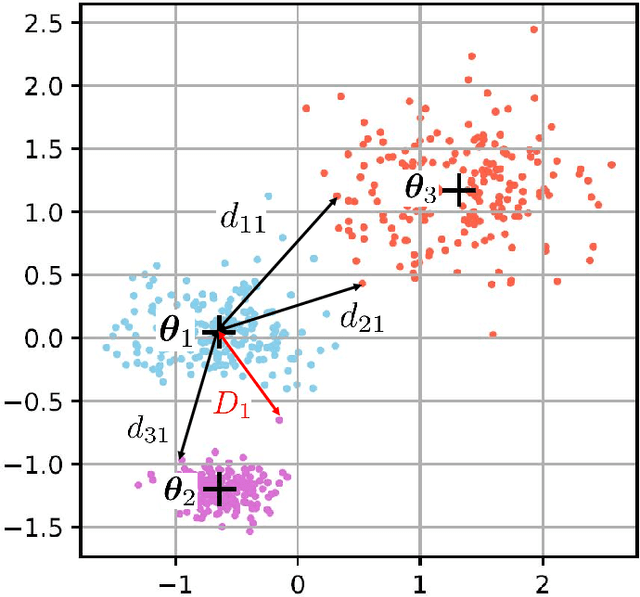
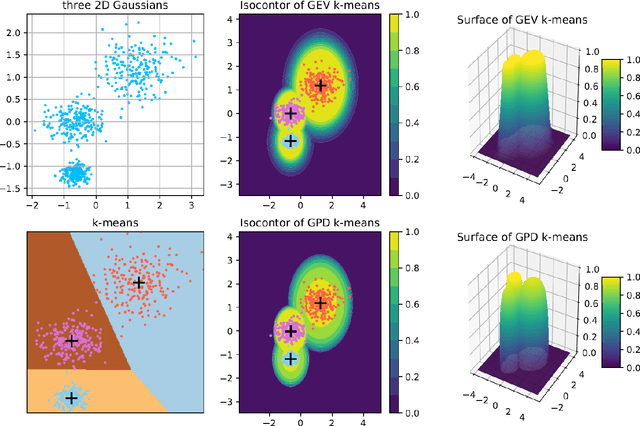
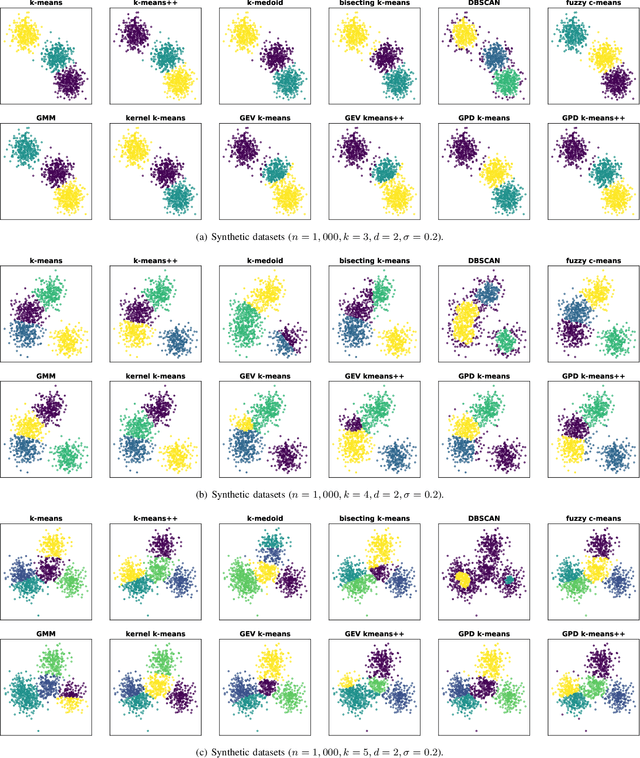
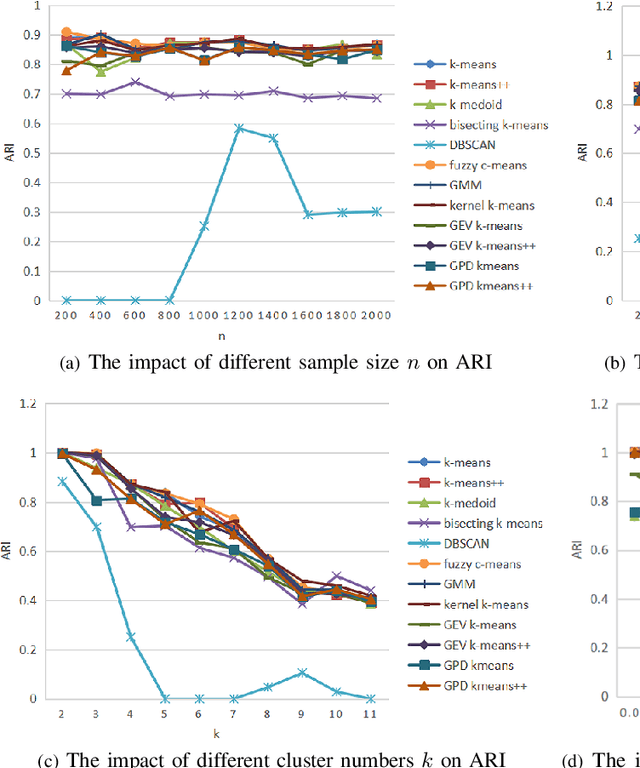
Clustering is an essential task to unsupervised learning. It tries to automatically separate instances into coherent subsets. As one of the most well-known clustering algorithms, k-means assigns sample points at the boundary to a unique cluster, while it does not utilize the information of sample distribution or density. Comparably, it would potentially be more beneficial to consider the probability of each sample in a possible cluster. To this end, this paper generalizes k-means to model the distribution of clusters. Our novel clustering algorithm thus models the distributions of distances to centroids over a threshold by Generalized Pareto Distribution (GPD) in Extreme Value Theory (EVT). Notably, we propose the concept of centroid margin distance, use GPD to establish a probability model for each cluster, and perform a clustering algorithm based on the covering probability function derived from GPD. Such a GPD k-means thus enables the clustering algorithm from the probabilistic perspective. Correspondingly, we also introduce a naive baseline, dubbed as Generalized Extreme Value (GEV) k-means. GEV fits the distribution of the block maxima. In contrast, the GPD fits the distribution of distance to the centroid exceeding a sufficiently large threshold, leading to a more stable performance of GPD k-means. Notably, GEV k-means can also estimate cluster structure and thus perform reasonably well over classical k-means. Thus, extensive experiments on synthetic datasets and real datasets demonstrate that GPD k-means outperforms competitors. The github codes are released in https://github.com/sixiaozheng/EVT-K-means.
Temporal-Spatial Feature Extraction Based on Convolutional Neural Networks for Travel Time Prediction
Oct 30, 2021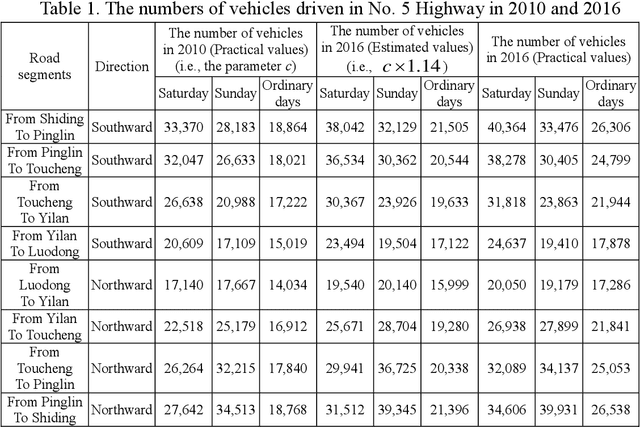
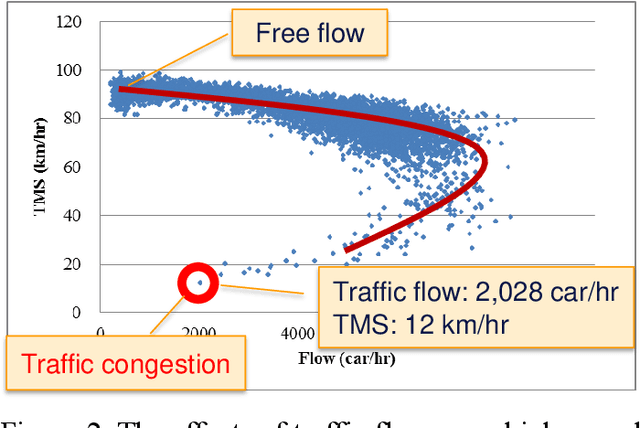
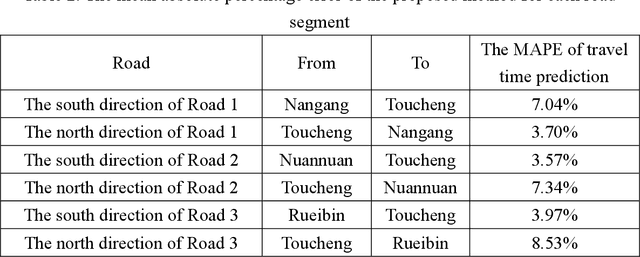
In recent years, some traffic information prediction methods have been proposed to provide the precise information of travel time, vehicle speed, and traffic flow for highways. However, big errors may be obtained by these methods for urban roads or the alternative roads of highways. Therefore, this study proposes a travel time prediction method based on convolutional neural networks to extract important factors for the improvement of traffic information prediction. In practical experimental environments, the travel time records of No. 5 Highway and the alternative roads of its were collected and used to evaluate the proposed method. The results showed that the mean absolute percentage error of the proposed method was about 5.69%. Therefore, the proposed method based on deep learning techniques can improve the accuracy of travel time prediction.
Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
Oct 28, 2021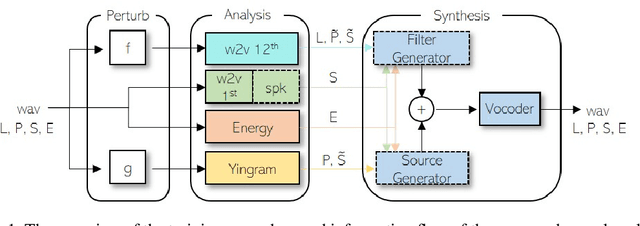

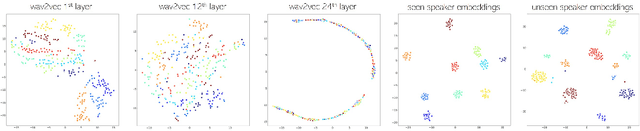
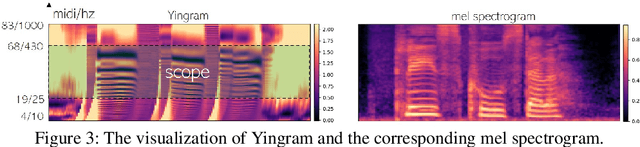
We present a neural analysis and synthesis (NANSY) framework that can manipulate voice, pitch, and speed of an arbitrary speech signal. Most of the previous works have focused on using information bottleneck to disentangle analysis features for controllable synthesis, which usually results in poor reconstruction quality. We address this issue by proposing a novel training strategy based on information perturbation. The idea is to perturb information in the original input signal (e.g., formant, pitch, and frequency response), thereby letting synthesis networks selectively take essential attributes to reconstruct the input signal. Because NANSY does not need any bottleneck structures, it enjoys both high reconstruction quality and controllability. Furthermore, NANSY does not require any labels associated with speech data such as text and speaker information, but rather uses a new set of analysis features, i.e., wav2vec feature and newly proposed pitch feature, Yingram, which allows for fully self-supervised training. Taking advantage of fully self-supervised training, NANSY can be easily extended to a multilingual setting by simply training it with a multilingual dataset. The experiments show that NANSY can achieve significant improvement in performance in several applications such as zero-shot voice conversion, pitch shift, and time-scale modification.
Modeling Multi-granularity User Intent Evolving via Heterogeneous Graph Neural Networks for Session-based Recommendation
Jan 02, 2022
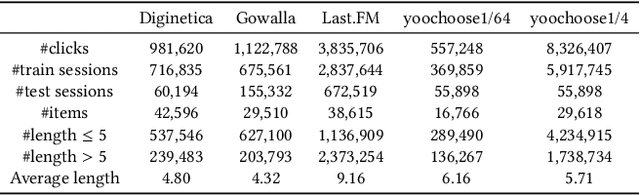
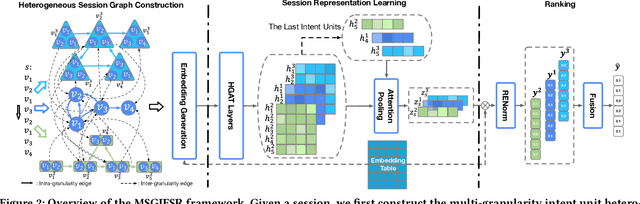
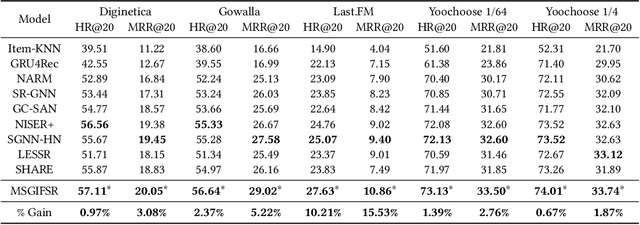
Session-based recommendation aims to predict a user's next action based on previous actions in the current session. The major challenge is to capture authentic and complete user preferences in the entire session. Recent work utilizes graph structure to represent the entire session and adopts Graph Neural Network to encode session information. This modeling choice has been proved to be effective and achieved remarkable results. However, most of the existing studies only consider each item within the session independently and do not capture session semantics from a high-level perspective. Such limitation often leads to severe information loss and increases the difficulty of capturing long-range dependencies within a session. Intuitively, compared with individual items, a session snippet, i.e., a group of locally consecutive items, is able to provide supplemental user intents which are hardly captured by existing methods. In this work, we propose to learn multi-granularity consecutive user intent unit to improve the recommendation performance. Specifically, we creatively propose Multi-granularity Intent Heterogeneous Session Graph which captures the interactions between different granularity intent units and relieves the burden of long-dependency. Moreover, we propose the Intent Fusion Ranking module to compose the recommendation results from various granularity user intents. Compared with current methods that only leverage intents from individual items, IFR benefits from different granularity user intents to generate more accurate and comprehensive session representation, thus eventually boosting recommendation performance. We conduct extensive experiments on five session-based recommendation datasets and the results demonstrate the effectiveness of our method.
KORSAL: Key-point Detection based Online Real-Time Spatio-Temporal Action Localization
Nov 05, 2021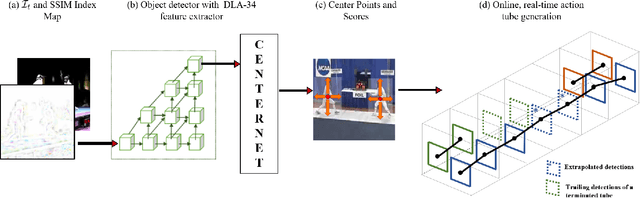
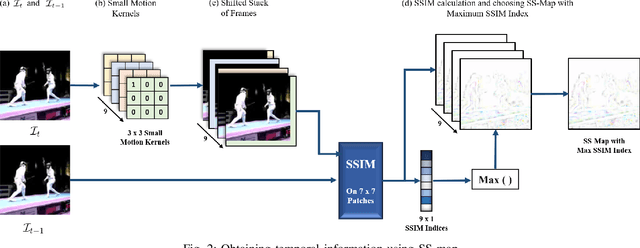

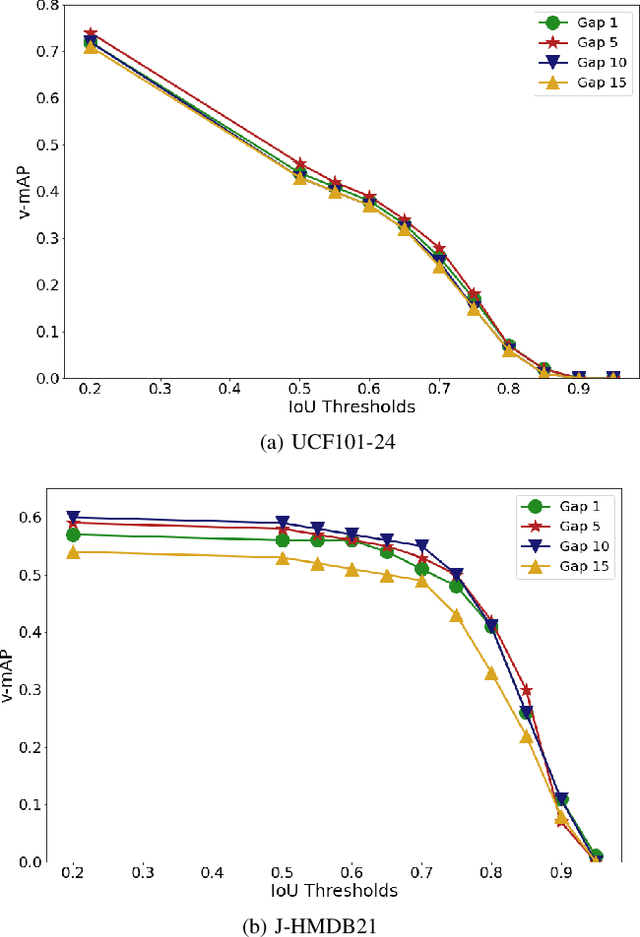
Real-time and online action localization in a video is a critical yet highly challenging problem. Accurate action localization requires the utilization of both temporal and spatial information. Recent attempts achieve this by using computationally intensive 3D CNN architectures or highly redundant two-stream architectures with optical flow, making them both unsuitable for real-time, online applications. To accomplish activity localization under highly challenging real-time constraints, we propose utilizing fast and efficient key-point based bounding box prediction to spatially localize actions. We then introduce a tube-linking algorithm that maintains the continuity of action tubes temporally in the presence of occlusions. Further, we eliminate the need for a two-stream architecture by combining temporal and spatial information into a cascaded input to a single network, allowing the network to learn from both types of information. Temporal information is efficiently extracted using a structural similarity index map as opposed to computationally intensive optical flow. Despite the simplicity of our approach, our lightweight end-to-end architecture achieves state-of-the-art frame-mAP of 74.7% on the challenging UCF101-24 dataset, demonstrating a performance gain of 6.4% over the previous best online methods. We also achieve state-of-the-art video-mAP results compared to both online and offline methods. Moreover, our model achieves a frame rate of 41.8 FPS, which is a 10.7% improvement over contemporary real-time methods.
TLogic: Temporal Logical Rules for Explainable Link Forecasting on Temporal Knowledge Graphs
Dec 15, 2021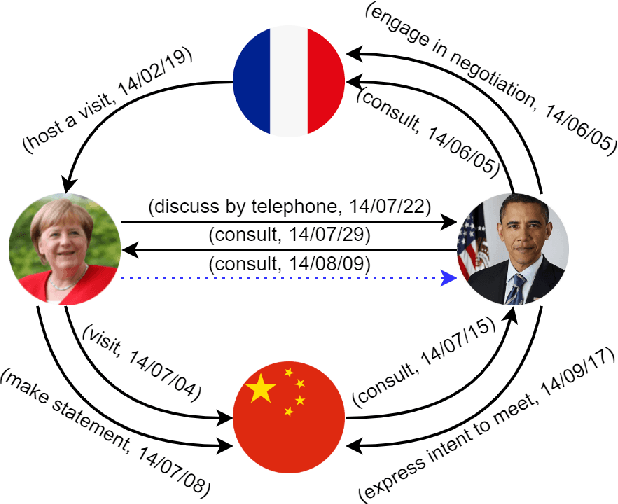
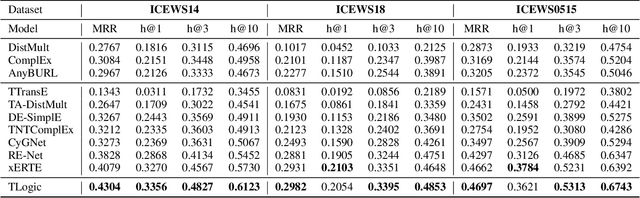

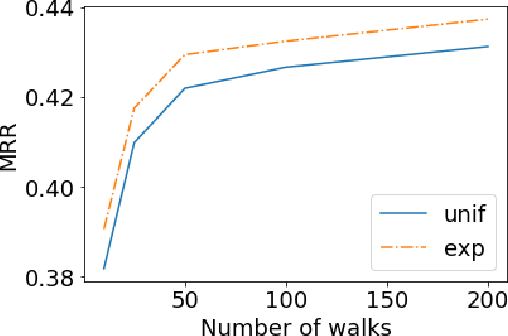
Conventional static knowledge graphs model entities in relational data as nodes, connected by edges of specific relation types. However, information and knowledge evolve continuously, and temporal dynamics emerge, which are expected to influence future situations. In temporal knowledge graphs, time information is integrated into the graph by equipping each edge with a timestamp or a time range. Embedding-based methods have been introduced for link prediction on temporal knowledge graphs, but they mostly lack explainability and comprehensible reasoning chains. Particularly, they are usually not designed to deal with link forecasting -- event prediction involving future timestamps. We address the task of link forecasting on temporal knowledge graphs and introduce TLogic, an explainable framework that is based on temporal logical rules extracted via temporal random walks. We compare TLogic with state-of-the-art baselines on three benchmark datasets and show better overall performance while our method also provides explanations that preserve time consistency. Furthermore, in contrast to most state-of-the-art embedding-based methods, TLogic works well in the inductive setting where already learned rules are transferred to related datasets with a common vocabulary.