 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Automated Analysis Framework for Trajectory Datasets
Feb 12, 2022
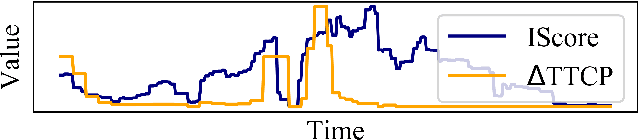
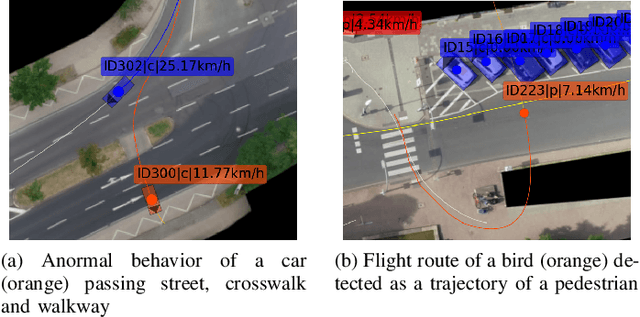

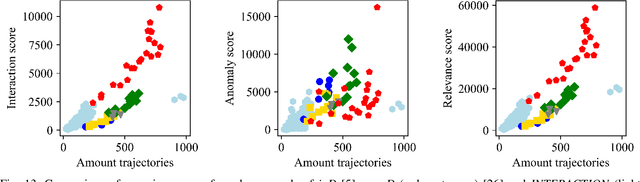
Trajectory datasets of road users have become more important in the last years for safety validation of highly automated vehicles. Several naturalistic trajectory datasets with each more than 10.000 tracks were released and others will follow. Considering this amount of data, it is necessary to be able to compare these datasets in-depth with ease to get an overview. By now, the datasets' own provided information is mainly limited to meta-data and qualitative descriptions which are mostly not consistent with other datasets. This is insufficient for users to differentiate the emerging datasets for application-specific selection. Therefore, an automated analysis framework is proposed in this work. Starting with analyzing individual tracks, fourteen elementary characteristics, so-called detection types, are derived and used as the base of this framework. To describe each traffic scenario precisely, the detections are subdivided into common metrics, clustering methods and anomaly detection. Those are combined using a modular approach. The detections are composed into new scores to describe three defined attributes of each track data quantitatively: interaction, anomaly and relevance. These three scores are calculated hierarchically for different abstract layers to provide an overview not just between datasets but also for tracks, spatial regions and individual situations. So, an objective comparison between datasets can be realized. Furthermore, it can help to get a deeper understanding of the recorded infrastructure and its effect on road user behavior. To test the validity of the framework, a study is conducted to compare the scores with human perception. Additionally, several datasets are compared.
Neural Network based on Automatic Differentiation Transformation of Numeric Iterate-to-Fixedpoint
Oct 30, 2021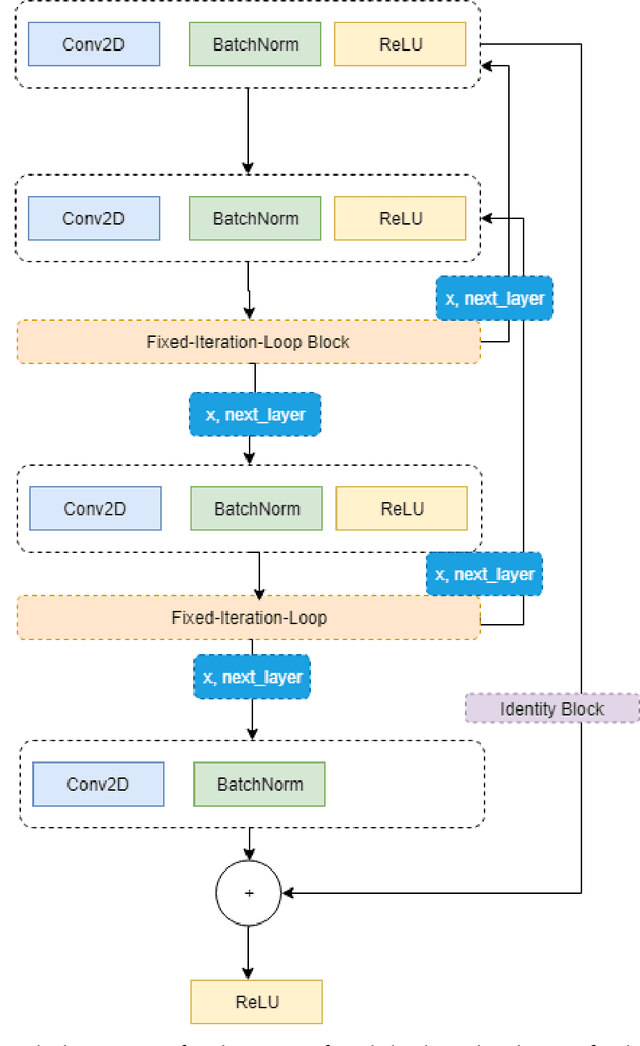


This work proposes a Neural Network model that can control its depth using an iterate-to-fixed-point operator. The architecture starts with a standard layered Network but with added connections from current later to earlier layers, along with a gate to make them inactive under most circumstances. These ``temporal wormhole'' connections create a shortcut that allows the Neural Network to use the information available at deeper layers and re-do earlier computations with modulated inputs. End-to-end training is accomplished by using appropriate calculations for a numeric iterate-to-fixed-point operator. In a typical case, where the ``wormhole'' connections are inactive, this is inexpensive; but when they are active, the network takes a longer time to settle down, and the gradient calculation is also more laborious, with an effect similar to making the network deeper. In contrast to the existing skip-connection concept, this proposed technique enables information to flow up and down in the network. Furthermore, the flow of information follows a fashion that seems analogous to the afferent and efferent flow of information through layers of processing in the brain. We evaluate models that use this novel mechanism on different long-term dependency tasks. The results are competitive with other studies, showing that the proposed model contributes significantly to overcoming traditional deep learning models' vanishing gradient descent problem. At the same time, the training time is significantly reduced, as the ``easy'' input cases are processed more quickly than ``difficult'' ones.
HampDTI: a heterogeneous graph automatic meta-path learning method for drug-target interaction prediction
Dec 16, 2021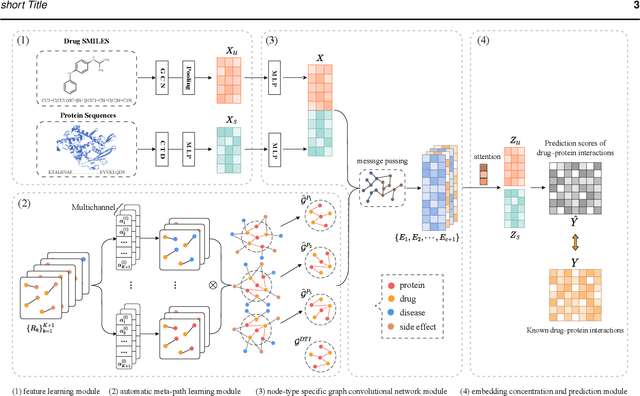

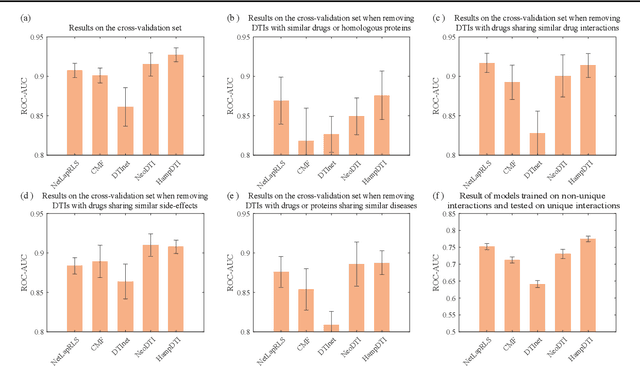
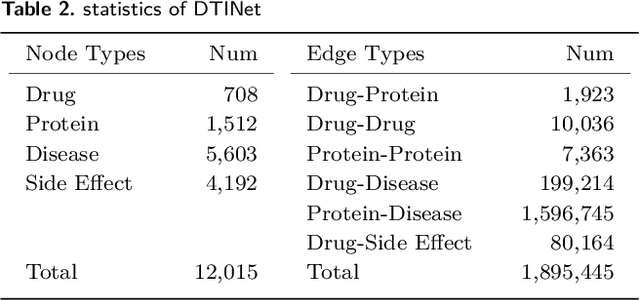
Motivation: Identifying drug-target interactions (DTIs) is a key step in drug repositioning. In recent years, the accumulation of a large number of genomics and pharmacology data has formed mass drug and target related heterogeneous networks (HNs), which provides new opportunities of developing HN-based computational models to accurately predict DTIs. The HN implies lots of useful information about DTIs but also contains irrelevant data, and how to make the best of heterogeneous networks remains a challenge. Results: In this paper, we propose a heterogeneous graph automatic meta-path learning based DTI prediction method (HampDTI). HampDTI automatically learns the important meta-paths between drugs and targets from the HN, and generates meta-path graphs. For each meta-path graph, the features learned from drug molecule graphs and target protein sequences serve as the node attributes, and then a node-type specific graph convolutional network (NSGCN) which efficiently considers node type information (drugs or targets) is designed to learn embeddings of drugs and targets. Finally, the embeddings from multiple meta-path graphs are combined to predict novel DTIs. The experiments on benchmark datasets show that our proposed HampDTI achieves superior performance compared with state-of-the-art DTI prediction methods. More importantly, HampDTI identifies the important meta-paths for DTI prediction, which could explain how drugs connect with targets in HNs.
Disentangle Saliency Detection into Cascaded Detail Modeling and Body Filling
Feb 08, 2022
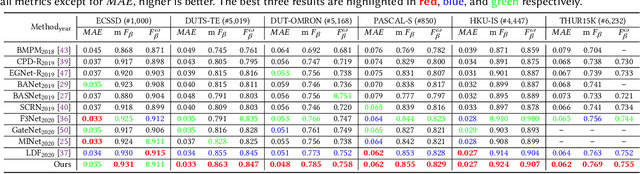
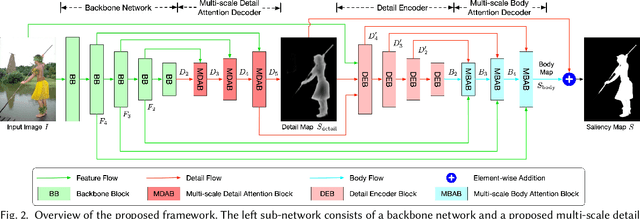
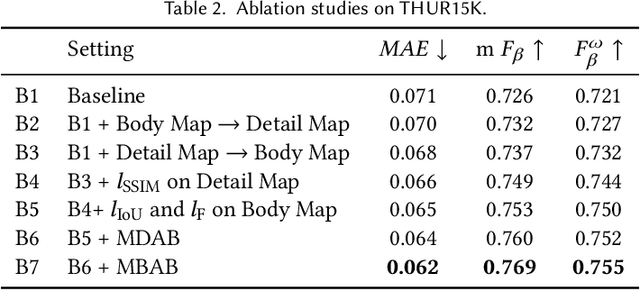
Salient object detection has been long studied to identify the most visually attractive objects in images/videos. Recently, a growing amount of approaches have been proposed all of which rely on the contour/edge information to improve detection performance. The edge labels are either put into the loss directly or used as extra supervision. The edge and body can also be learned separately and then fused afterward. Both methods either lead to high prediction errors near the edge or cannot be trained in an end-to-end manner. Another problem is that existing methods may fail to detect objects of various sizes due to the lack of efficient and effective feature fusion mechanisms. In this work, we propose to decompose the saliency detection task into two cascaded sub-tasks, \emph{i.e.}, detail modeling and body filling. Specifically, the detail modeling focuses on capturing the object edges by supervision of explicitly decomposed detail label that consists of the pixels that are nested on the edge and near the edge. Then the body filling learns the body part which will be filled into the detail map to generate more accurate saliency map. To effectively fuse the features and handle objects at different scales, we have also proposed two novel multi-scale detail attention and body attention blocks for precise detail and body modeling. Experimental results show that our method achieves state-of-the-art performances on six public datasets.
Label fusion and training methods for reliable representation of inter-rater uncertainty
Feb 15, 2022
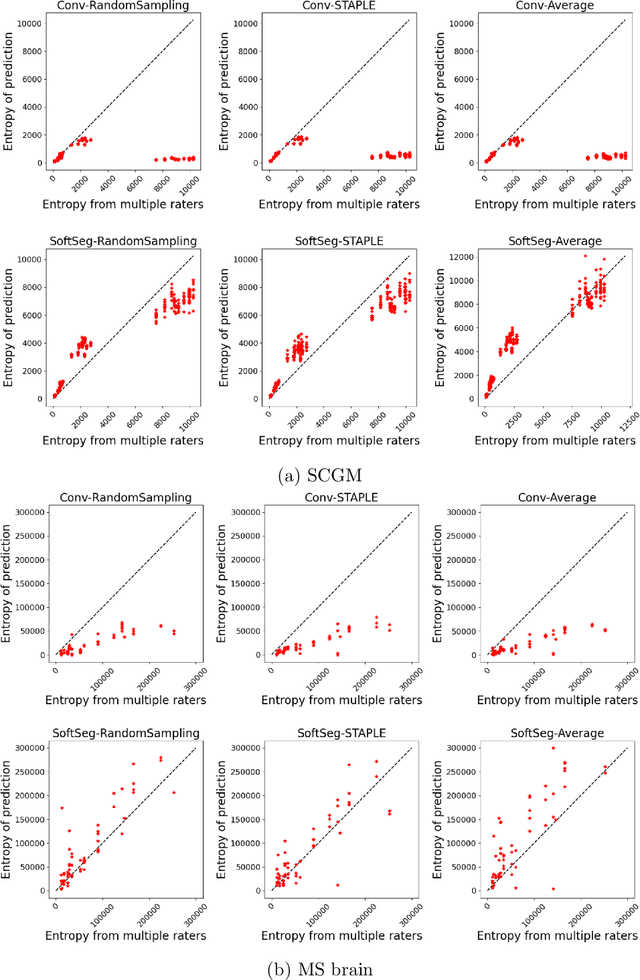
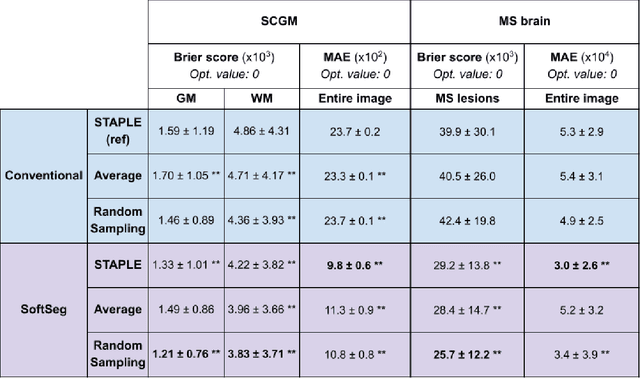
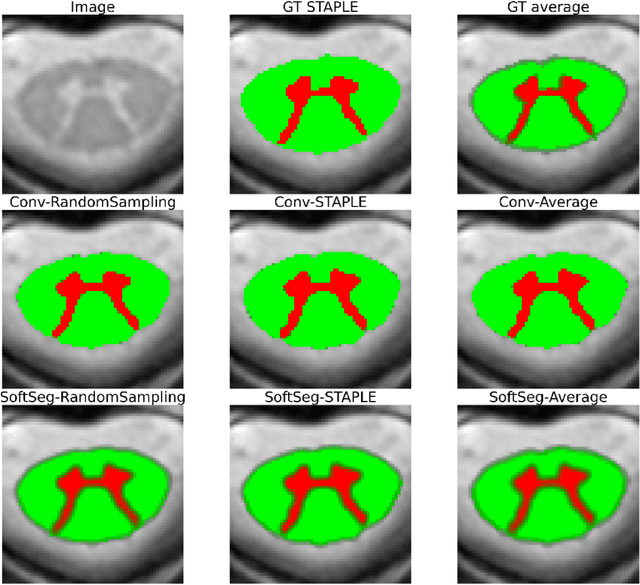
Medical tasks are prone to inter-rater variability due to multiple factors such as image quality, professional experience and training, or guideline clarity. Training deep learning networks with annotations from multiple raters is a common practice that mitigates the model's bias towards a single expert. Reliable models generating calibrated outputs and reflecting the inter-rater disagreement are key to the integration of artificial intelligence in clinical practice. Various methods exist to take into account different expert labels. We focus on comparing three label fusion methods: STAPLE, average of the rater's segmentation, and random sampling each rater's segmentation during training. Each label fusion method is studied using the conventional training framework or the recently published SoftSeg framework that limits information loss by treating the segmentation task as a regression. Our results, across 10 data splittings on two public datasets, indicate that SoftSeg models, regardless of the ground truth fusion method, had better calibration and preservation of the inter-rater rater variability compared with their conventional counterparts without impacting the segmentation performance. Conventional models, i.e., trained with a Dice loss, with binary inputs, and sigmoid/softmax final activate, were overconfident and underestimated the uncertainty associated with inter-rater variability. Conversely, fusing labels by averaging with the SoftSeg framework led to underconfident outputs and overestimation of the rater disagreement. In terms of segmentation performance, the best label fusion method was different for the two datasets studied, indicating this parameter might be task-dependent. However, SoftSeg had segmentation performance systematically superior or equal to the conventionally trained models and had the best calibration and preservation of the inter-rater variability.
The Efficiency of Human Cognition Reflects Planned Information Processing
Feb 13, 2020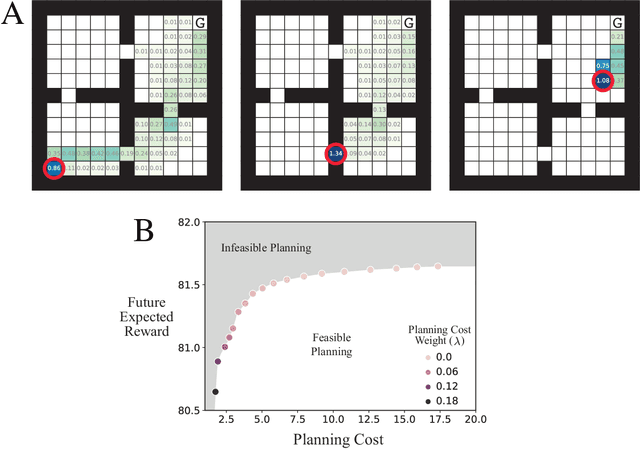
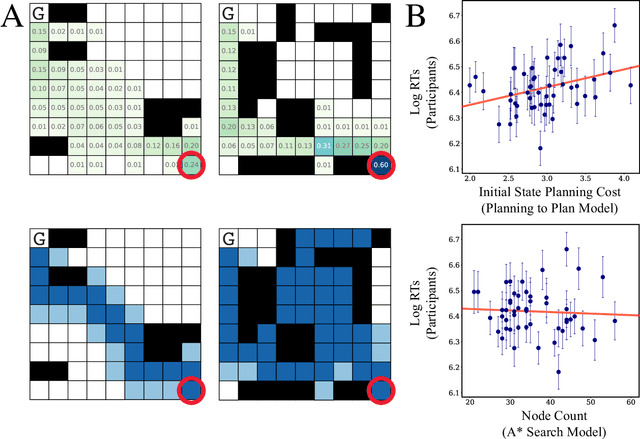

Planning is useful. It lets people take actions that have desirable long-term consequences. But, planning is hard. It requires thinking about consequences, which consumes limited computational and cognitive resources. Thus, people should plan their actions, but they should also be smart about how they deploy resources used for planning their actions. Put another way, people should also "plan their plans". Here, we formulate this aspect of planning as a meta-reasoning problem and formalize it in terms of a recursive Bellman objective that incorporates both task rewards and information-theoretic planning costs. Our account makes quantitative predictions about how people should plan and meta-plan as a function of the overall structure of a task, which we test in two experiments with human participants. We find that people's reaction times reflect a planned use of information processing, consistent with our account. This formulation of planning to plan provides new insight into the function of hierarchical planning, state abstraction, and cognitive control in both humans and machines.
Algorithmic audits of algorithms, and the law
Feb 15, 2022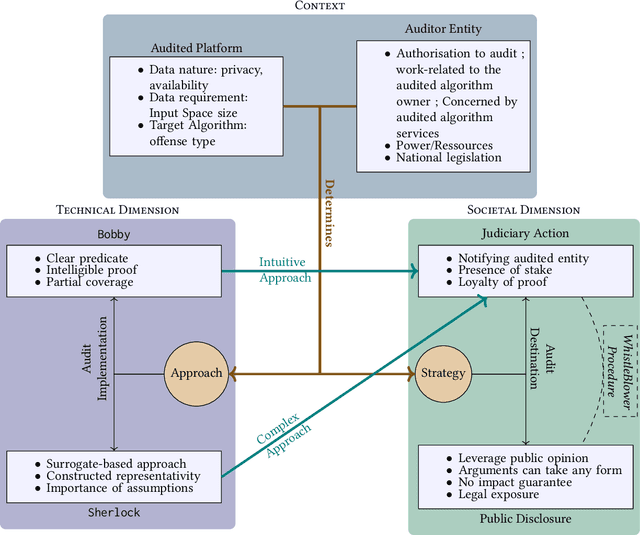
Algorithmic decision making is now widespread, ranging from health care allocation to more common actions such as recommendation or information ranking. The aim to audit these algorithms has grown alongside. In this paper, we focus on external audits that are conducted by interacting with the user side of the target algorithm, hence considered as a black box. Yet, the legal framework in which these audits take place is mostly ambiguous to researchers developing them: on the one hand, the legal value of the audit outcome is uncertain; on the other hand the auditors' rights and obligations are unclear. The contribution of this paper is to articulate two canonical audit forms to law, to shed light on these aspects: 1) the first audit form (we coin the Bobby audit form) checks a predicate against the algorithm, while the second (Sherlock) is more loose and opens up to multiple investigations. We find that: Bobby audits are more amenable to prosecution, yet are delicate as operating on real user data. This can lead to reject by a court (notion of admissibility). Sherlock audits craft data for their operation, most notably to build surrogates of the audited algorithm. It is mostly used for acts for whistleblowing, as even if accepted as a proof, the evidential value will be low in practice. 2) these two forms require the prior respect of a proper right to audit, granted by law or by the platform being audited; otherwise the auditor will be also prone to prosecutions regardless of the audit outcome. This article thus highlights the relation of current audits with law, in order to structure the growing field of algorithm auditing.
Score Transformer: Generating Musical Score from Note-level Representation
Dec 01, 2021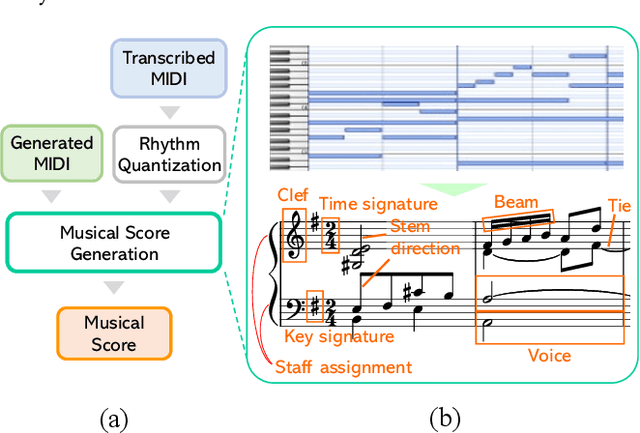
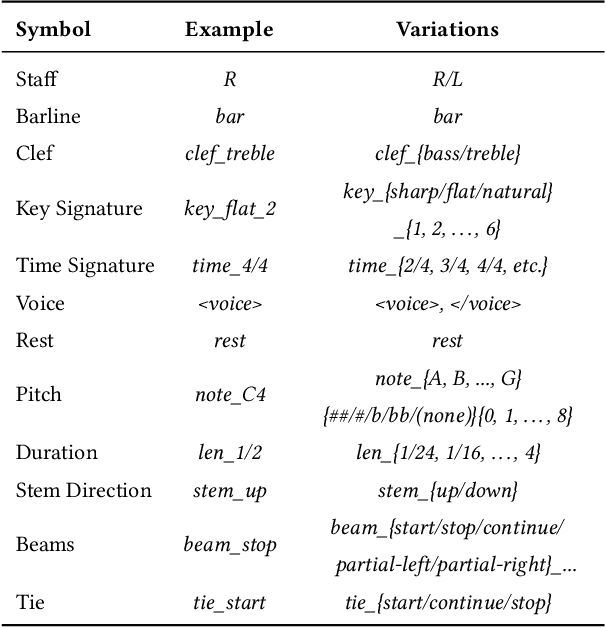

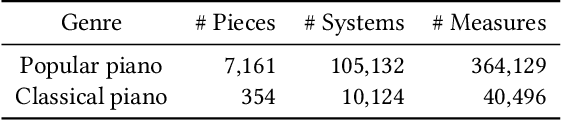
In this paper, we explore the tokenized representation of musical scores using the Transformer model to automatically generate musical scores. Thus far, sequence models have yielded fruitful results with note-level (MIDI-equivalent) symbolic representations of music. Although the note-level representations can comprise sufficient information to reproduce music aurally, they cannot contain adequate information to represent music visually in terms of notation. Musical scores contain various musical symbols (e.g., clef, key signature, and notes) and attributes (e.g., stem direction, beam, and tie) that enable us to visually comprehend musical content. However, automated estimation of these elements has yet to be comprehensively addressed. In this paper, we first design score token representation corresponding to the various musical elements. We then train the Transformer model to transcribe note-level representation into appropriate music notation. Evaluations of popular piano scores show that the proposed method significantly outperforms existing methods on all 12 musical aspects that were investigated. We also explore an effective notation-level token representation to work with the model and determine that our proposed representation produces the steadiest results.
(2.5+1)D Spatio-Temporal Scene Graphs for Video Question Answering
Feb 18, 2022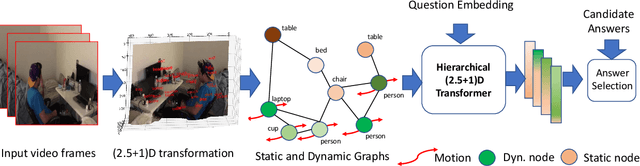
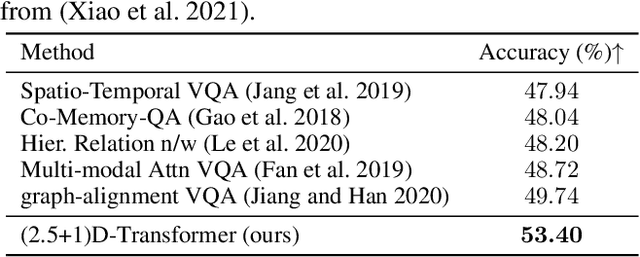
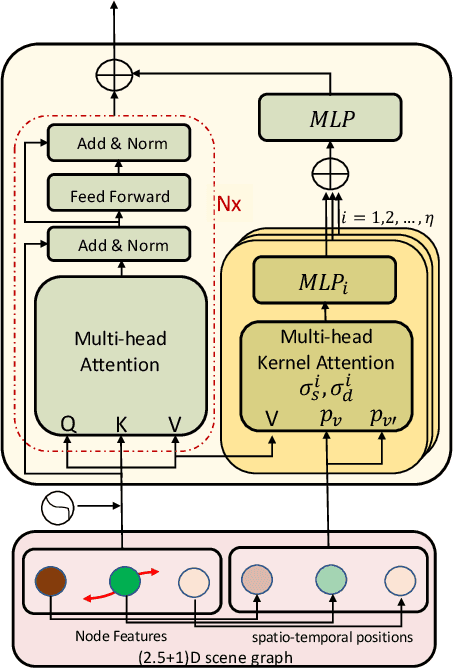
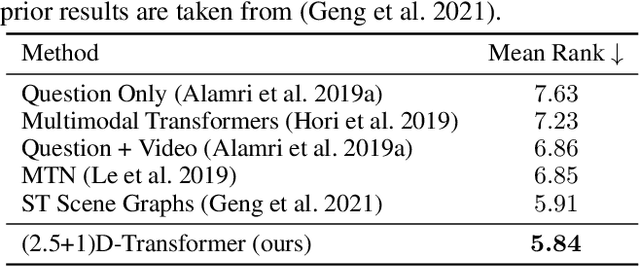
Spatio-temporal scene-graph approaches to video-based reasoning tasks such as video question-answering (QA) typically construct such graphs for every video frame. Such approaches often ignore the fact that videos are essentially sequences of 2D "views" of events happening in a 3D space, and that the semantics of the 3D scene can thus be carried over from frame to frame. Leveraging this insight, we propose a (2.5+1)D scene graph representation to better capture the spatio-temporal information flows inside the videos. Specifically, we first create a 2.5D (pseudo-3D) scene graph by transforming every 2D frame to have an inferred 3D structure using an off-the-shelf 2D-to-3D transformation module, following which we register the video frames into a shared (2.5+1)D spatio-temporal space and ground each 2D scene graph within it. Such a (2.5+1)D graph is then segregated into a static sub-graph and a dynamic sub-graph, corresponding to whether the objects within them usually move in the world. The nodes in the dynamic graph are enriched with motion features capturing their interactions with other graph nodes. Next, for the video QA task, we present a novel transformer-based reasoning pipeline that embeds the (2.5+1)D graph into a spatio-temporal hierarchical latent space, where the sub-graphs and their interactions are captured at varied granularity. To demonstrate the effectiveness of our approach, we present experiments on the NExT-QA and AVSD-QA datasets. Our results show that our proposed (2.5+1)D representation leads to faster training and inference, while our hierarchical model showcases superior performance on the video QA task versus the state of the art.
Zero-shot Singing Technique Conversion
Nov 16, 2021
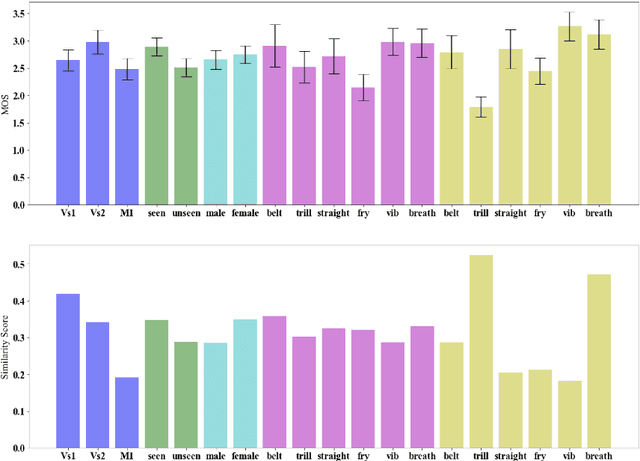
In this paper we propose modifications to the neural network framework, AutoVC for the task of singing technique conversion. This includes utilising a pretrained singing technique encoder which extracts technique information, upon which a decoder is conditioned during training. By swapping out a source singer's technique information for that of the target's during conversion, the input spectrogram is reconstructed with the target's technique. We document the beneficial effects of omitting the latent loss, the importance of sequential training, and our process for fine-tuning the bottleneck. We also conducted a listening study where participants rate the specificity of technique-converted voices as well as their naturalness. From this we are able to conclude how effective the technique conversions are and how different conditions affect them, while assessing the model's ability to reconstruct its input data.