 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Saliency based Feature Fusion Model for EEG Emotion Estimation
Jan 26, 2022
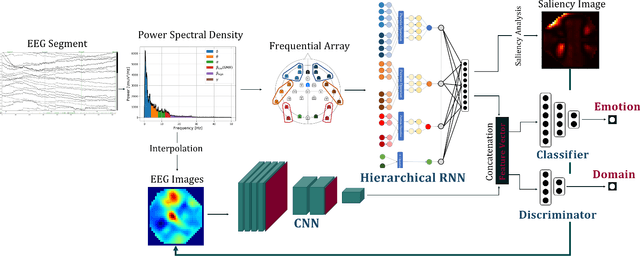

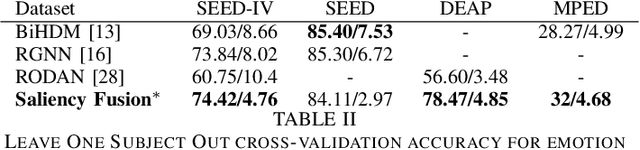
Among the different modalities to assess emotion, electroencephalogram (EEG), representing the electrical brain activity, achieved motivating results over the last decade. Emotion estimation from EEG could help in the diagnosis or rehabilitation of certain diseases. In this paper, we propose a dual model considering two different representations of EEG feature maps: 1) a sequential based representation of EEG band power, 2) an image-based representation of the feature vectors. We also propose an innovative method to combine the information based on a saliency analysis of the image-based model to promote joint learning of both model parts. The model has been evaluated on four publicly available datasets and achieves similar results to the state-of-the-art approaches. It outperforms results for two of the proposed datasets with a lower standard deviation that reflects higher stability. For sake of reproducibility, the codes and models proposed in this paper are available at https://github.com/VDelv/Emotion-EEG.
Variational Model Inversion Attacks
Jan 26, 2022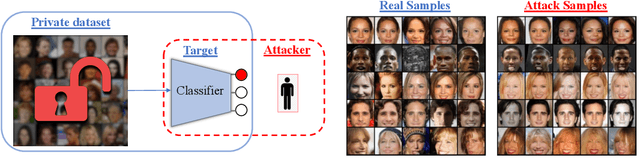
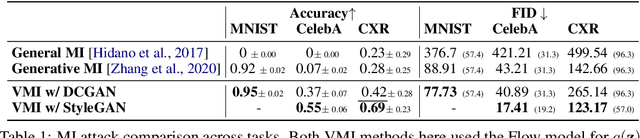

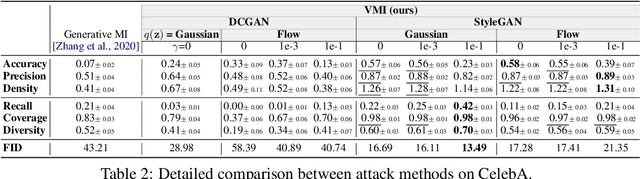
Given the ubiquity of deep neural networks, it is important that these models do not reveal information about sensitive data that they have been trained on. In model inversion attacks, a malicious user attempts to recover the private dataset used to train a supervised neural network. A successful model inversion attack should generate realistic and diverse samples that accurately describe each of the classes in the private dataset. In this work, we provide a probabilistic interpretation of model inversion attacks, and formulate a variational objective that accounts for both diversity and accuracy. In order to optimize this variational objective, we choose a variational family defined in the code space of a deep generative model, trained on a public auxiliary dataset that shares some structural similarity with the target dataset. Empirically, our method substantially improves performance in terms of target attack accuracy, sample realism, and diversity on datasets of faces and chest X-ray images.
Less is More: Reversible Steganography with Uncertainty-Aware Predictive Analytics
Feb 05, 2022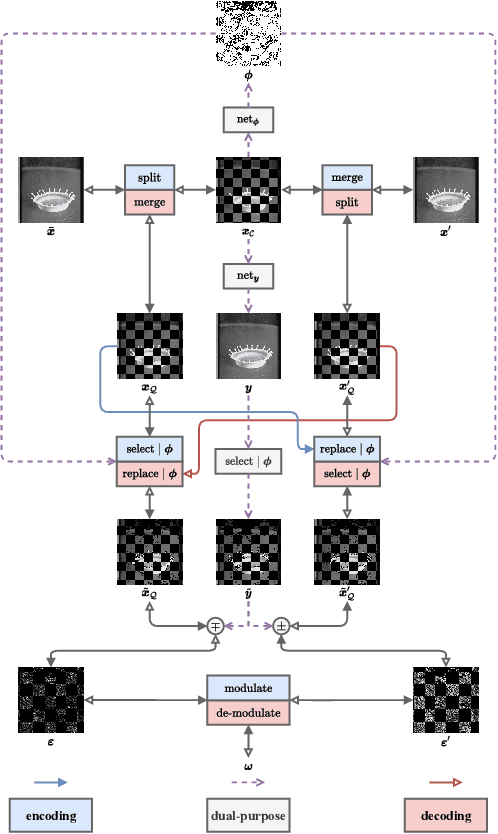



Artificial neural networks have advanced the frontiers of reversible steganography. The core strength of neural networks is the ability to render accurate predictions for a bewildering variety of data. Residual modulation is recognised as the most advanced reversible steganographic algorithm for digital images and the pivot of which is the predictive module. The function of this module is to predict pixel intensity given some pixel-wise contextual information. This task can be perceived as a low-level vision problem and hence neural networks for addressing a similar class of problems can be deployed. On top of the prior art, this paper analyses the predictive uncertainty and endows the predictive module with the option to abstain when encountering a high level of uncertainty. Uncertainty analysis can be formulated as a pixel-level binary classification problem and tackled by both supervised and unsupervised learning. In contrast to handcrafted statistical analytics, learning-based analytics can learn to follow some general statistical principles and simultaneously adapt to a specific predictor. Experimental results show that steganographic performance can be remarkably improved by adaptively filtering out the unpredictable regions with the learning-based uncertainty analysers.
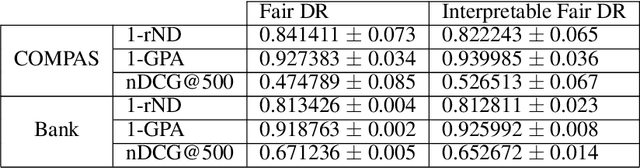
Fair Interpretable Learning via Correction Vectors
Jan 17, 2022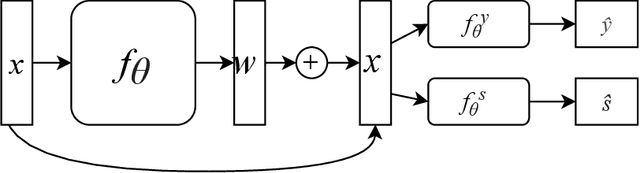

Neural network architectures have been extensively employed in the fair representation learning setting, where the objective is to learn a new representation for a given vector which is independent of sensitive information. Various "representation debiasing" techniques have been proposed in the literature. However, as neural networks are inherently opaque, these methods are hard to comprehend, which limits their usefulness. We propose a new framework for fair representation learning which is centered around the learning of "correction vectors", which have the same dimensionality as the given data vectors. The corrections are then simply summed up to the original features, and can therefore be analyzed as an explicit penalty or bonus to each feature. We show experimentally that a fair representation learning problem constrained in such a way does not impact performance.
FairGNN: Eliminating the Discrimination in Graph Neural Networks with Limited Sensitive Attribute Information
Sep 03, 2020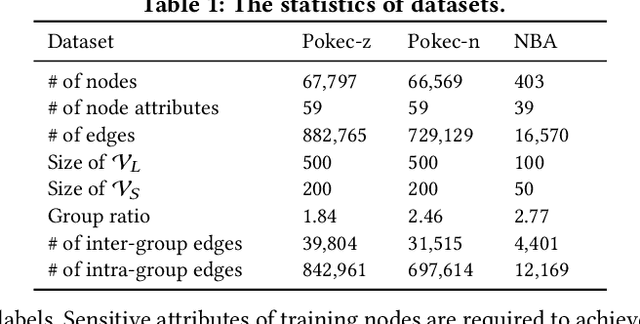
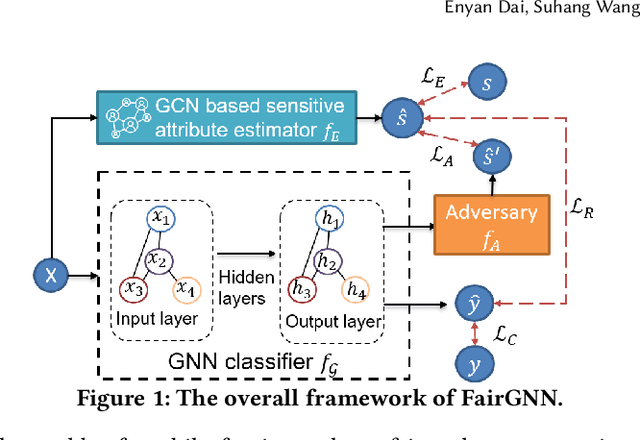
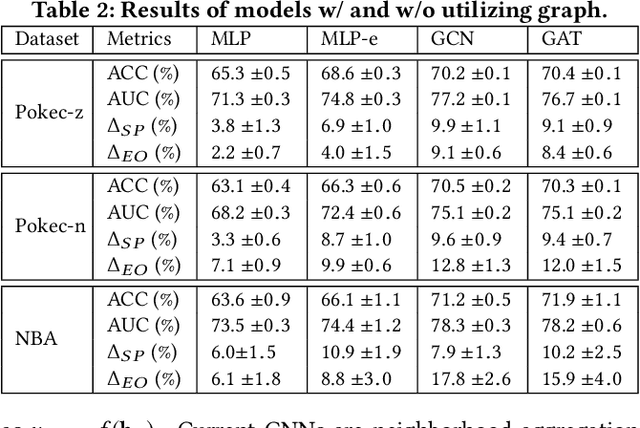
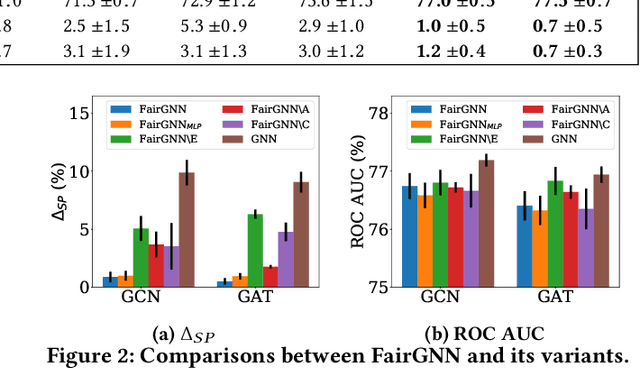
Graph neural networks (GNNs) have shown great power in modeling graph structured data. However, similar to other machine learning models, GNNs may make predictions biased on protected sensitive attributes, e.g., skin color, gender, and nationality. Because machine learning algorithms including GNNs are trained to faithfully reflect the distribution of the training data which often contains historical bias towards sensitive attributes. In addition, the discrimination in GNNs can be magnified by graph structures and the message-passing mechanism. As a result, the applications of GNNs in sensitive domains such as crime rate prediction would be largely limited. Though extensive studies of fair classification have been conducted on i.i.d data, methods to address the problem of discrimination on non-i.i.d data are rather limited. Furthermore, the practical scenario of sparse annotations in sensitive attributes is rarely considered in existing works. Therefore, we study the novel and important problem of learning fair GNNs with limited sensitive attribute information. FairGNN is proposed to eliminate the bias of GNNs whilst maintaining high node classification accuracy by leveraging graph structures and limited sensitive information. Our theoretical analysis shows that FairGNN can ensure the fairness of GNNs under mild conditions given limited nodes with known sensitive attributes. Extensive experiments on real-world datasets also demonstrate the effectiveness of FairGNN in debiasing and keeping high accuracy.
Game of Privacy: Towards Better Federated Platform Collaboration under Privacy Restriction
Feb 24, 2022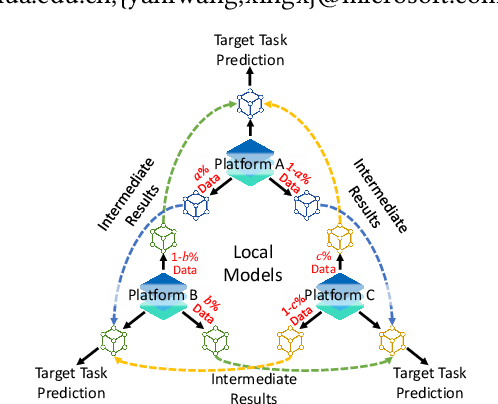
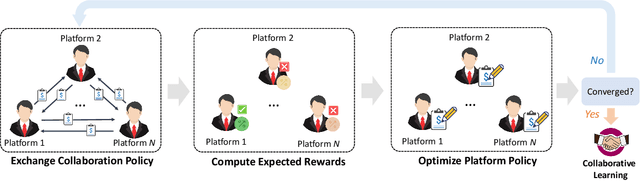
Vertical federated learning (VFL) aims to train models from cross-silo data with different feature spaces stored on different platforms. Existing VFL methods usually assume all data on each platform can be used for model training. However, due to the intrinsic privacy risks of federated learning, the total amount of involved data may be constrained. In addition, existing VFL studies usually assume only one platform has task labels and can benefit from the collaboration, making it difficult to attract other platforms to join in the collaborative learning. In this paper, we study the platform collaboration problem in VFL under privacy constraint. We propose to incent different platforms through a reciprocal collaboration, where all platforms can exploit multi-platform information in the VFL framework to benefit their own tasks. With limited privacy budgets, each platform needs to wisely allocate its data quotas for collaboration with other platforms. Thereby, they naturally form a multi-party game. There are two core problems in this game, i.e., how to appraise other platforms' data value to compute game rewards and how to optimize policies to solve the game. To evaluate the contributions of other platforms' data, each platform offers a small amount of "deposit" data to participate in the VFL. We propose a performance estimation method to predict the expected model performance when involving different amount combinations of inter-platform data. To solve the game, we propose a platform negotiation method that simulates the bargaining among platforms and locally optimizes their policies via gradient descent. Extensive experiments on two real-world datasets show that our approach can effectively facilitate the collaborative exploitation of multi-platform data in VFL under privacy restrictions.
Belief Revision in Sentential Decision Diagrams
Jan 20, 2022Belief revision is the task of modifying a knowledge base when new information becomes available, while also respecting a number of desirable properties. Classical belief revision schemes have been already specialised to \emph{binary decision diagrams} (BDDs), the classical formalism to compactly represent propositional knowledge. These results also apply to \emph{ordered} BDDs (OBDDs), a special class of BDDs, designed to guarantee canonicity. Yet, those revisions cannot be applied to \emph{sentential decision diagrams} (SDDs), a typically more compact but still canonical class of Boolean circuits, which generalizes OBDDs, while not being a subclass of BDDs. Here we fill this gap by deriving a general revision algorithm for SDDs based on a syntactic characterisation of Dalal revision. A specialised procedure for DNFs is also presented. Preliminary experiments performed with randomly generated knowledge bases show the advantages of directly perform revision within SDD formalism.
Lessons from the AdKDD'21 Privacy-Preserving ML Challenge
Jan 31, 2022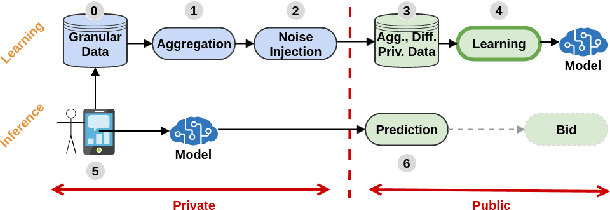
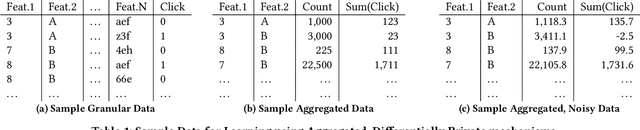
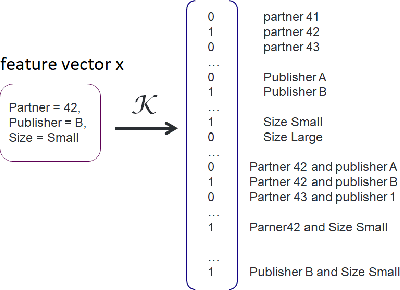
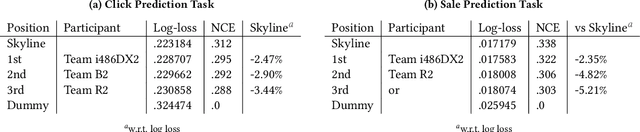
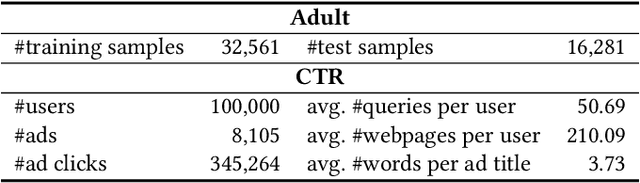
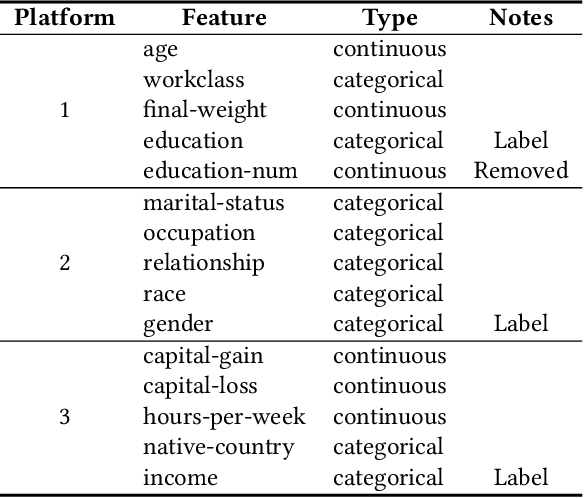
Designing data sharing mechanisms providing performance and strong privacy guarantees is a hot topic for the Online Advertising industry. Namely, a prominent proposal discussed under the Improving Web Advertising Business Group at W3C only allows sharing advertising signals through aggregated, differentially private reports of past displays. To study this proposal extensively, an open Privacy-Preserving Machine Learning Challenge took place at AdKDD'21, a premier workshop on Advertising Science with data provided by advertising company Criteo. In this paper, we describe the challenge tasks, the structure of the available datasets, report the challenge results, and enable its full reproducibility. A key finding is that learning models on large, aggregated data in the presence of a small set of unaggregated data points can be surprisingly efficient and cheap. We also run additional experiments to observe the sensitivity of winning methods to different parameters such as privacy budget or quantity of available privileged side information. We conclude that the industry needs either alternate designs for private data sharing or a breakthrough in learning with aggregated data only to keep ad relevance at a reasonable level.
Joint 3D Human Shape Recovery from A Single Imag with Bilayer-Graph
Oct 16, 2021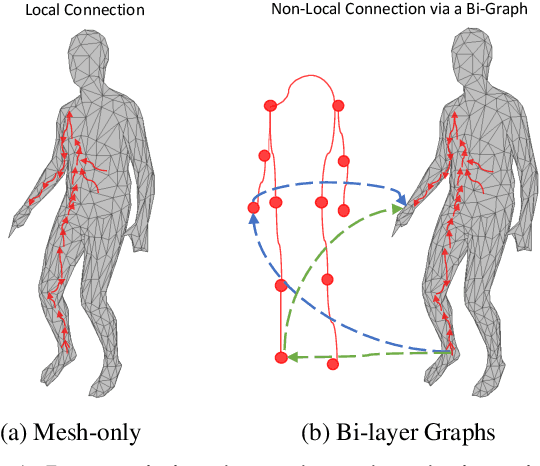
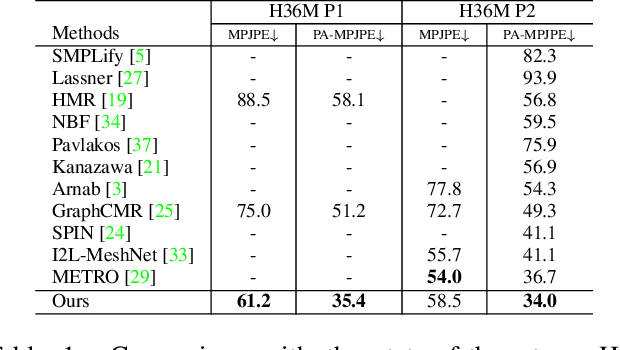
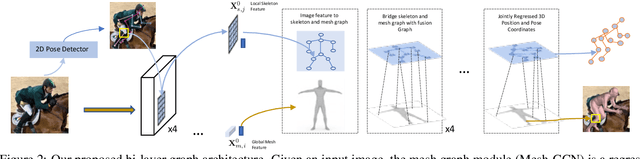
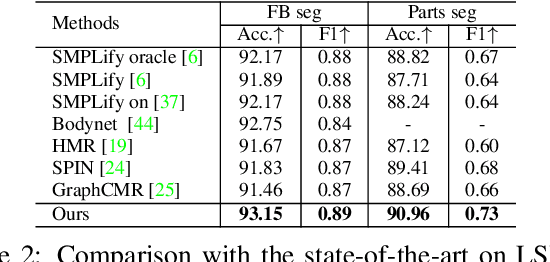
The ability to estimate the 3D human shape and pose from images can be useful in many contexts. Recent approaches have explored using graph convolutional networks and achieved promising results. The fact that the 3D shape is represented by a mesh, an undirected graph, makes graph convolutional networks a natural fit for this problem. However, graph convolutional networks have limited representation power. Information from nodes in the graph is passed to connected neighbors, and propagation of information requires successive graph convolutions. To overcome this limitation, we propose a dual-scale graph approach. We use a coarse graph, derived from a dense graph, to estimate the human's 3D pose, and the dense graph to estimate the 3D shape. Information in coarse graphs can be propagated over longer distances compared to dense graphs. In addition, information about pose can guide to recover local shape detail and vice versa. We recognize that the connection between coarse and dense is itself a graph, and introduce graph fusion blocks to exchange information between graphs with different scales. We train our model end-to-end and show that we can achieve state-of-the-art results for several evaluation datasets.
Server-Side Local Gradient Averaging and Learning Rate Acceleration for Scalable Split Learning
Dec 11, 2021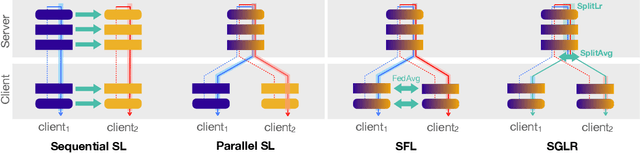
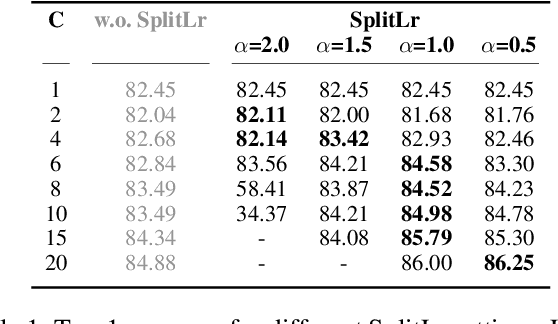
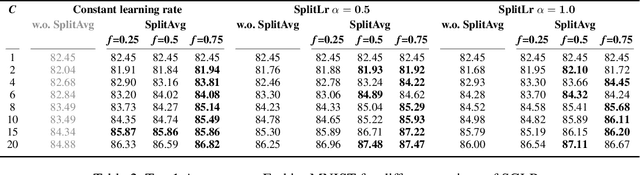

In recent years, there have been great advances in the field of decentralized learning with private data. Federated learning (FL) and split learning (SL) are two spearheads possessing their pros and cons, and are suited for many user clients and large models, respectively. To enjoy both benefits, hybrid approaches such as SplitFed have emerged of late, yet their fundamentals have still been illusive. In this work, we first identify the fundamental bottlenecks of SL, and thereby propose a scalable SL framework, coined SGLR. The server under SGLR broadcasts a common gradient averaged at the split-layer, emulating FL without any additional communication across clients as opposed to SplitFed. Meanwhile, SGLR splits the learning rate into its server-side and client-side rates, and separately adjusts them to support many clients in parallel. Simulation results corroborate that SGLR achieves higher accuracy than other baseline SL methods including SplitFed, which is even on par with FL consuming higher energy and communication costs. As a secondary result, we observe greater reduction in leakage of sensitive information via mutual information using SLGR over the baselines.