 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Causal Disentanglement for Semantics-Aware Intent Learning in Recommendation
Feb 05, 2022


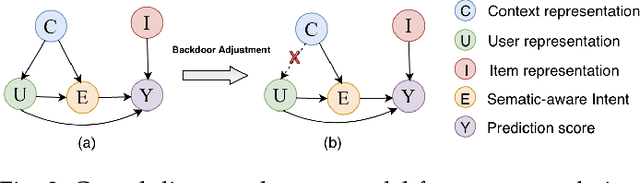
Traditional recommendation models trained on observational interaction data have generated large impacts in a wide range of applications, it faces bias problems that cover users' true intent and thus deteriorate the recommendation effectiveness. Existing methods tracks this problem as eliminating bias for the robust recommendation, e.g., by re-weighting training samples or learning disentangled representation. The disentangled representation methods as the state-of-the-art eliminate bias through revealing cause-effect of the bias generation. However, how to design the semantics-aware and unbiased representation for users true intents is largely unexplored. To bridge the gap, we are the first to propose an unbiased and semantics-aware disentanglement learning called CaDSI (Causal Disentanglement for Semantics-Aware Intent Learning) from a causal perspective. Particularly, CaDSI explicitly models the causal relations underlying recommendation task, and thus produces semantics-aware representations via disentangling users true intents aware of specific item context. Moreover, the causal intervention mechanism is designed to eliminate confounding bias stemmed from context information, which further to align the semantics-aware representation with users true intent. Extensive experiments and case studies both validate the robustness and interpretability of our proposed model.
Self-Supervised Learning based Monaural Speech Enhancement with Complex-Cycle-Consistent
Dec 21, 2021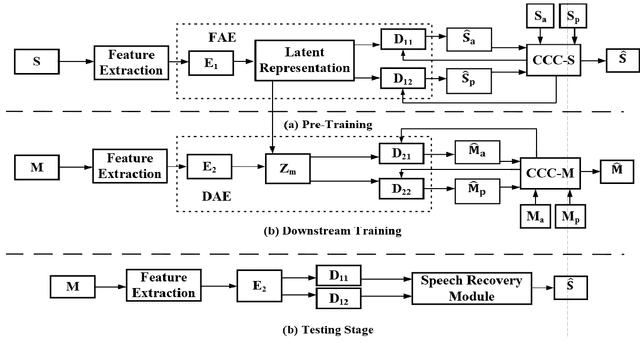
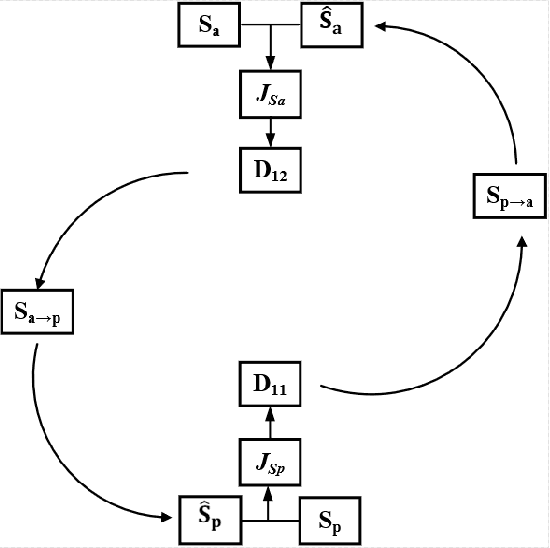
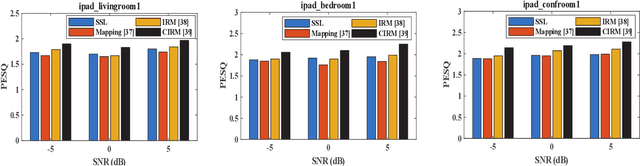

Recently, self-supervised learning (SSL) techniques have been introduced to solve the monaural speech enhancement problem. Due to the lack of using clean phase information, the enhancement performance is limited in most SSL methods. Therefore, in this paper, we propose a phase-aware self-supervised learning based monaural speech enhancement method. The latent representations of both amplitude and phase are studied in two decoders of the foundation autoencoder (FAE) with only a limited set of clean speech signals independently. Then, the downstream autoencoder (DAE) learns a shared latent space between the clean speech and mixture representations with a large number of unseen mixtures. A complex-cycle-consistent (CCC) mechanism is proposed to minimize the reconstruction loss between the amplitude and phase domains. Besides, it is noticed that if the speech features are extracted as the multi-resolution spectra, the desired information distributed in spectra of different scales can be studied to further boost the performance. The NOISEX and DAPS corpora are used to generate mixtures with different interferences to evaluate the efficacy of the proposed method. It is highlighted that the clean speech and mixtures fed in FAE and DAE are not paired. Both ablation and comparison experimental results show that the proposed method clearly outperforms the state-of-the-art approaches.
Learning Online for Unified Segmentation and Tracking Models
Nov 12, 2021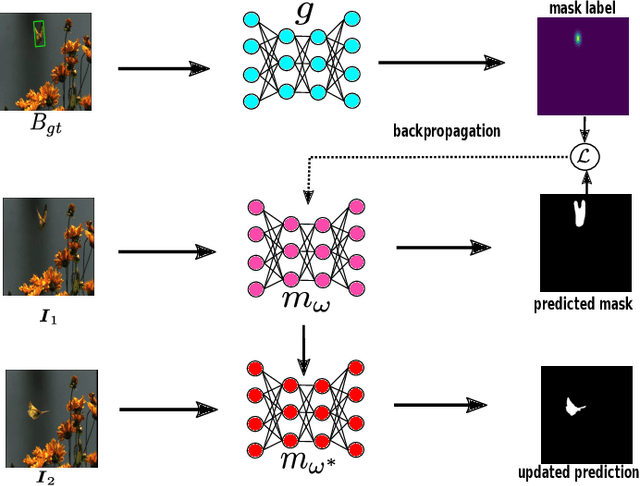
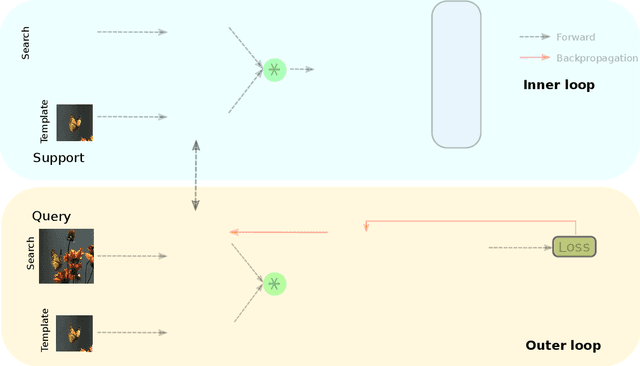
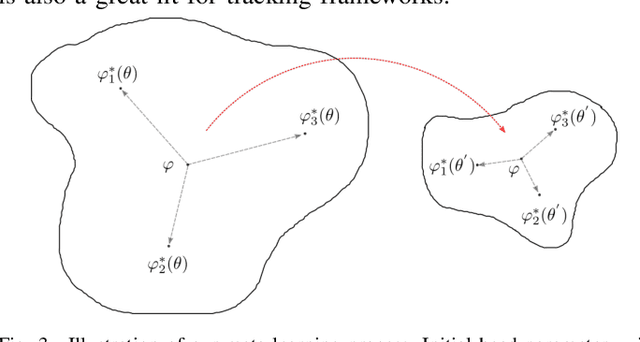

Tracking requires building a discriminative model for the target in the inference stage. An effective way to achieve this is online learning, which can comfortably outperform models that are only trained offline. Recent research shows that visual tracking benefits significantly from the unification of visual tracking and segmentation due to its pixel-level discrimination. However, it imposes a great challenge to perform online learning for such a unified model. A segmentation model cannot easily learn from prior information given in the visual tracking scenario. In this paper, we propose TrackMLP: a novel meta-learning method optimized to learn from only partial information to resolve the imposed challenge. Our model is capable of extensively exploiting limited prior information hence possesses much stronger target-background discriminability than other online learning methods. Empirically, we show that our model achieves state-of-the-art performance and tangible improvement over competing models. Our model achieves improved average overlaps of66.0%,67.1%, and68.5% in VOT2019, VOT2018, and VOT2016 datasets, which are 6.4%,7.3%, and6.4% higher than our baseline. Code will be made publicly available.
Extreme precipitation forecasting using attention augmented convolutions
Jan 31, 2022
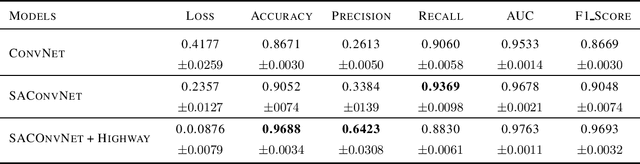
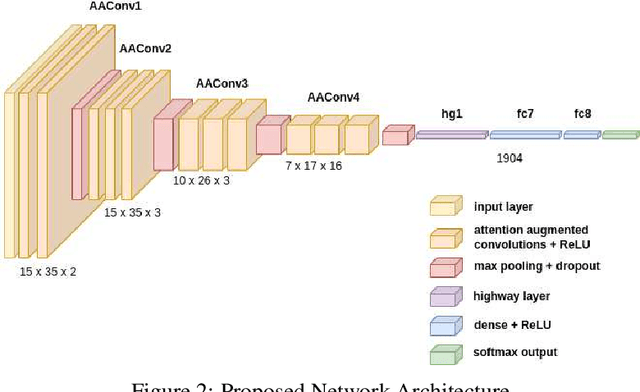
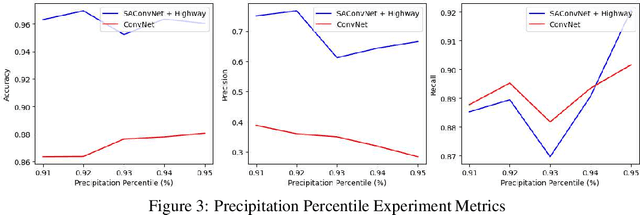
Extreme precipitation wreaks havoc throughout the world, causing billions of dollars in damage and uprooting communities, ecosystems, and economies. Accurate extreme precipitation prediction allows more time for preparation and disaster risk management for such extreme events. In this paper, we focus on short-term extreme precipitation forecasting (up to a 12-hour ahead-of-time prediction) from a sequence of sea level pressure and zonal wind anomalies. Although existing machine learning approaches have shown promising results, the associated model and climate uncertainties may reduce their reliability. To address this issue, we propose a self-attention augmented convolution mechanism for extreme precipitation forecasting, systematically combining attention scores with traditional convolutions to enrich feature data and reduce the expected errors of the results. The proposed network architecture is further fused with a highway neural network layer to gain the benefits of unimpeded information flow across several layers. Our experimental results show that the framework outperforms classical convolutional models by 12%. The proposed method increases machine learning as a tool for gaining insights into the physical causes of changing extremes, lowering uncertainty in future forecasts.
Word Embeddings for Automatic Equalization in Audio Mixing
Feb 17, 2022
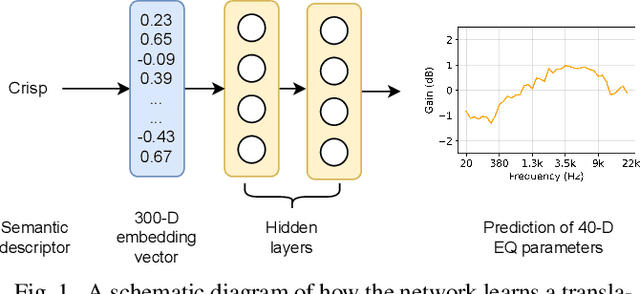
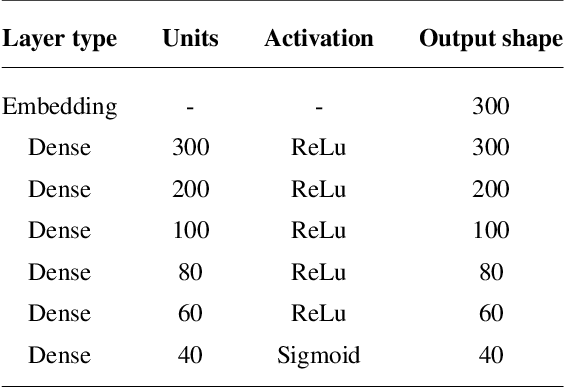

In recent years, machine learning has been widely adopted to automate the audio mixing process. Automatic mixing systems have been applied to various audio effects such as gain-adjustment, stereo panning, equalization, and reverberation. These systems can be controlled through visual interfaces, providing audio examples, using knobs, and semantic descriptors. Using semantic descriptors or textual information to control these systems is an effective way for artists to communicate their creative goals. Furthermore, sometimes artists use non-technical words that may not be understood by the mixing system, or even a mixing engineer. In this paper, we explore the novel idea of using word embeddings to represent semantic descriptors. Word embeddings are generally obtained by training neural networks on large corpora of written text. These embeddings serve as the input layer of the neural network to create a translation from words to EQ settings. Using this technique, the machine learning model can also generate EQ settings for semantic descriptors that it has not seen before. We perform experiments to demonstrate the feasibility of this idea. In addition, we compare the EQ settings of humans with the predictions of the neural network to evaluate the quality of predictions. The results showed that the embedding layer enables the neural network to understand semantic descriptors. We observed that the models with embedding layers perform better those without embedding layers, but not as good as human labels.
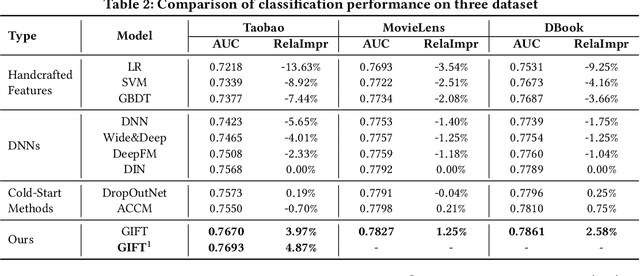
GIFT: Graph-guIded Feature Transfer for Cold-Start Video Click-Through Rate Prediction
Feb 21, 2022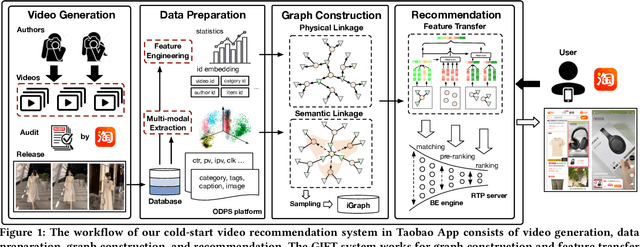
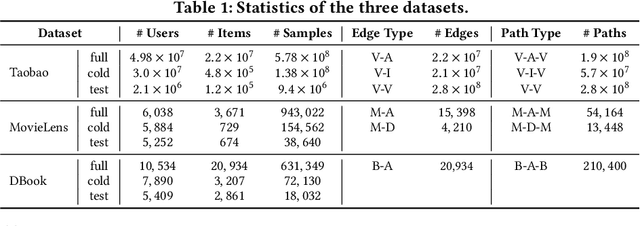
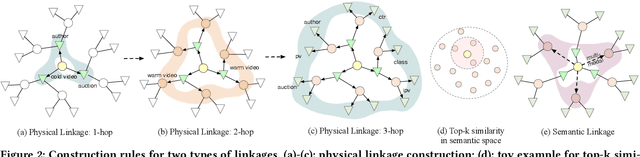
Short video has witnessed rapid growth in China and shows a promising market for promoting the sales of products in e-commerce platforms like Taobao. To ensure the freshness of the content, the platform needs to release a large number of new videos every day, which makes the conventional click-through rate (CTR) prediction model suffer from the severe item cold-start problem. In this paper, we propose GIFT, an efficient Graph-guIded Feature Transfer system, to fully take advantages of the rich information of warmed-up videos that related to the cold-start video. More specifically, we conduct feature transfer from warmed-up videos to those cold-start ones by involving the physical and semantic linkages into a heterogeneous graph. The former linkages consist of those explicit relationships (e.g., sharing the same category, under the same authorship etc.), while the latter measure the proximity of multimodal representations of two videos. In practice, the style, content, and even the recommendation pattern are pretty similar among those physically or semantically related videos. Besides, in order to provide the robust id representations and historical statistics obtained from warmed-up neighbors that cold-start videos covet most, we elaborately design the transfer function to make aware of different transferred features from different types of nodes and edges along the metapath on the graph. Extensive experiments on a large real-world dataset show that our GIFT system outperforms SOTA methods significantly and brings a 6.82% lift on click-through rate (CTR) in the homepage of Taobao App.
Science Facing Interoperability as a Necessary Condition of Success and Evil
Feb 05, 2022Artificial intelligence (AI) systems, such as machine learning algorithms, have allowed scientists, marketers and governments to shed light on correlations that remained invisible until now. Beforehand, the dots that we had to connect in order to imagine a new knowledge were either too numerous, too sparse or not even detected. Sometimes, the information was not stored in the same data lake or format and was not able to communicate. But in creating new bridges with AI, many problems appeared such as bias reproduction, unfair inferences or mass surveillance. Our aim is to show that, on one hand, the AI's deep ethical problem lays essentially in these new connections made possible by systems interoperability. In connecting the spheres of our life, these systems undermine the notion of justice particular to each of them, because the new interactions create dominances of social goods from a sphere to another. These systems make therefore spheres permeable to one another and, in doing so, they open to progress as well as to tyranny. On another hand, however, we would like to emphasize that the act to connect what used to seem a priori disjoint is a necessary move of knowledge and scientific progress.
BEER: Fast $O(1/T)$ Rate for Decentralized Nonconvex Optimization with Communication Compression
Jan 31, 2022
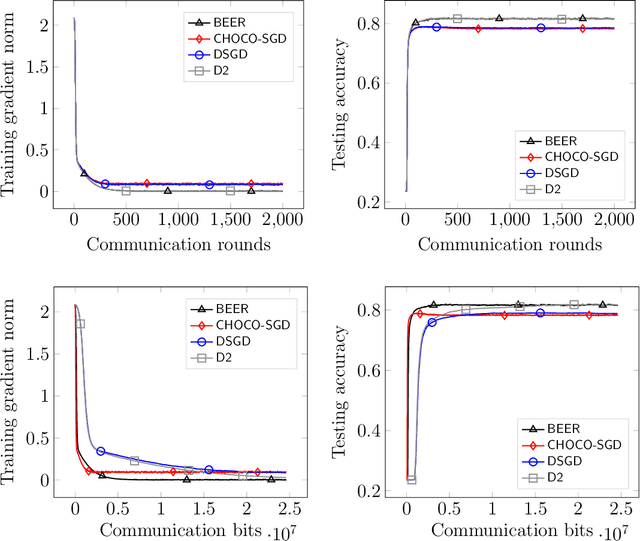
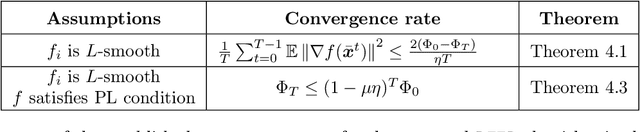
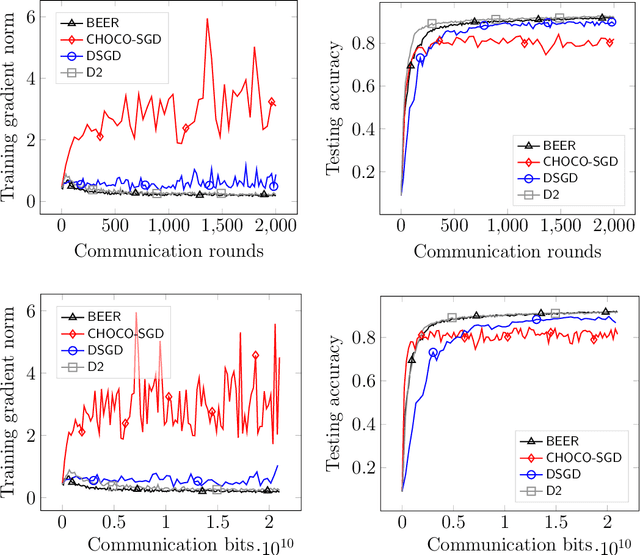
Communication efficiency has been widely recognized as the bottleneck for large-scale decentralized machine learning applications in multi-agent or federated environments. To tackle the communication bottleneck, there have been many efforts to design communication-compressed algorithms for decentralized nonconvex optimization, where the clients are only allowed to communicate a small amount of quantized information (aka bits) with their neighbors over a predefined graph topology. Despite significant efforts, the state-of-the-art algorithm in the nonconvex setting still suffers from a slower rate of convergence $O((G/T)^{2/3})$ compared with their uncompressed counterpart, where $G$ measures the data heterogeneity across different clients, and $T$ is the number of communication rounds. This paper proposes BEER, which adopts communication compression with gradient tracking, and shows it converges at a faster rate of $O(1/T)$. This significantly improves over the state-of-the-art rate, by matching the rate without compression even under arbitrary data heterogeneity. Numerical experiments are also provided to corroborate our theory and confirm the practical superiority of BEER in the data heterogeneous regime.
The Lokahi Prototype: Toward the automatic Extraction of Entity Relationship Models from Text
Jan 14, 2022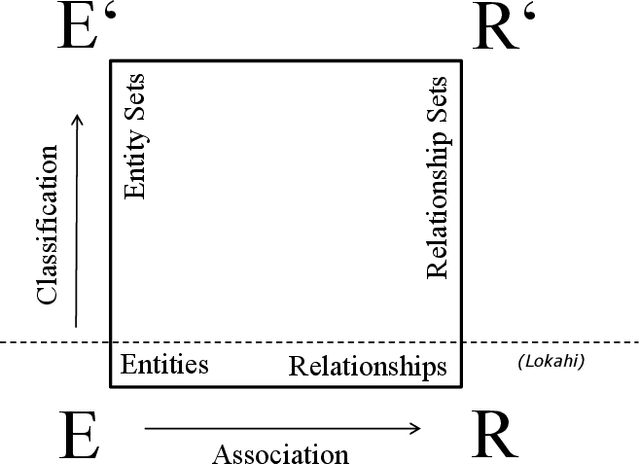
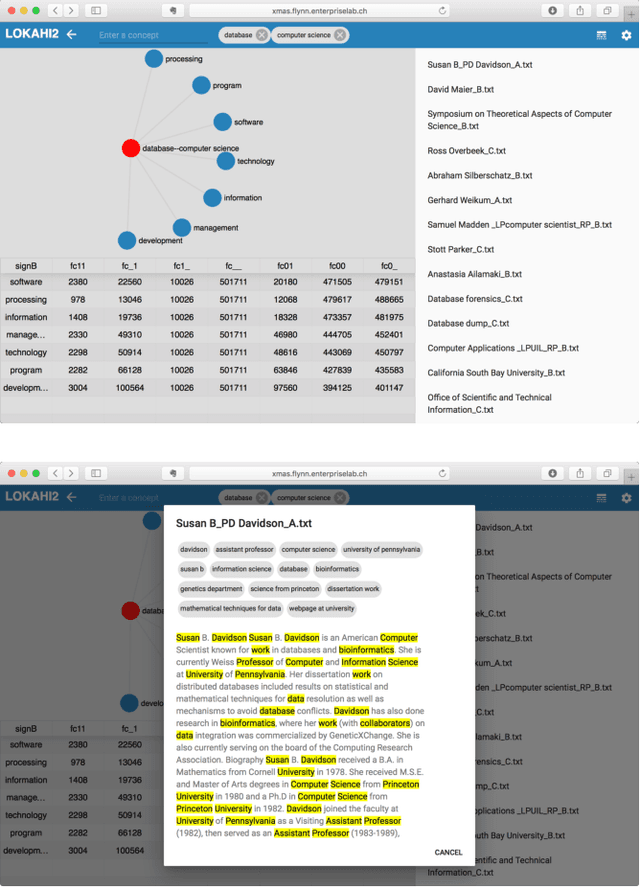
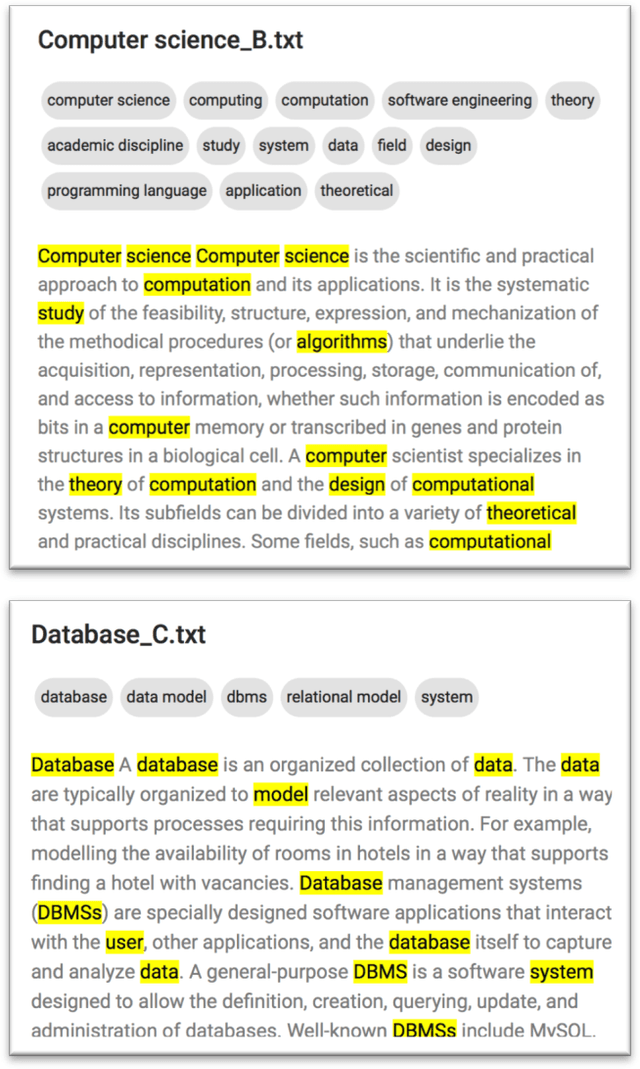
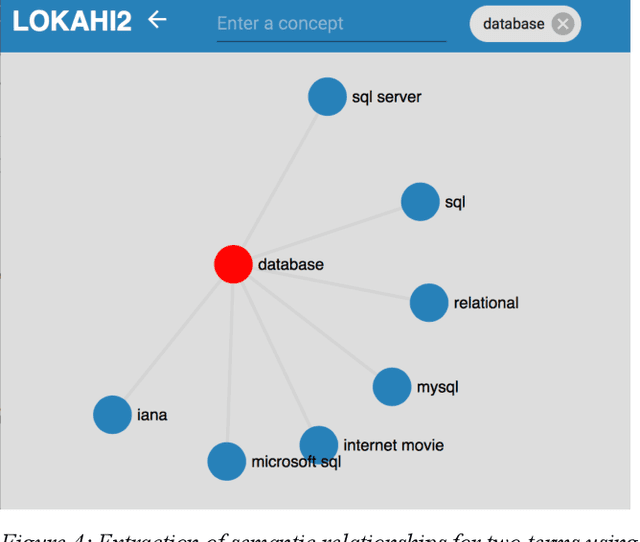
Entity relationship extraction envisions the automatic generation of semantic data models from collections of text, by automatic recognition of entities, by association of entities to form relationships, and by classifying these instances to assign them to entity sets (or classes) and relationship sets (or associations). As a first step in this direction, the Lokahi prototype can extract entities based on the TF*IDF measure, and generate semantic relationships based on document-level co-occurrence statistics, for example with likelihood ratios and pointwise mutual information. This paper presents results of an explorative, prototypical, qualitative and synthetic research, summarizes insights from two research projects and, based on this, indicates an outline for further research in the field of entity relationship extraction from text.
A Saliency based Feature Fusion Model for EEG Emotion Estimation
Jan 26, 2022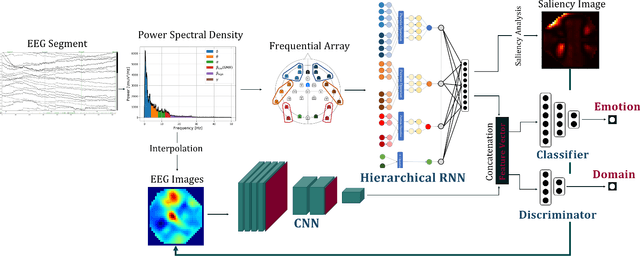

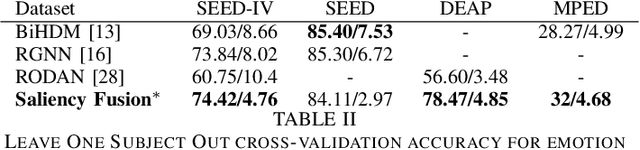
Among the different modalities to assess emotion, electroencephalogram (EEG), representing the electrical brain activity, achieved motivating results over the last decade. Emotion estimation from EEG could help in the diagnosis or rehabilitation of certain diseases. In this paper, we propose a dual model considering two different representations of EEG feature maps: 1) a sequential based representation of EEG band power, 2) an image-based representation of the feature vectors. We also propose an innovative method to combine the information based on a saliency analysis of the image-based model to promote joint learning of both model parts. The model has been evaluated on four publicly available datasets and achieves similar results to the state-of-the-art approaches. It outperforms results for two of the proposed datasets with a lower standard deviation that reflects higher stability. For sake of reproducibility, the codes and models proposed in this paper are available at https://github.com/VDelv/Emotion-EEG.