 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On-Demand AoI Minimization in Resource-Constrained Cache-Enabled IoT Networks with Energy Harvesting Sensors
Jan 28, 2022
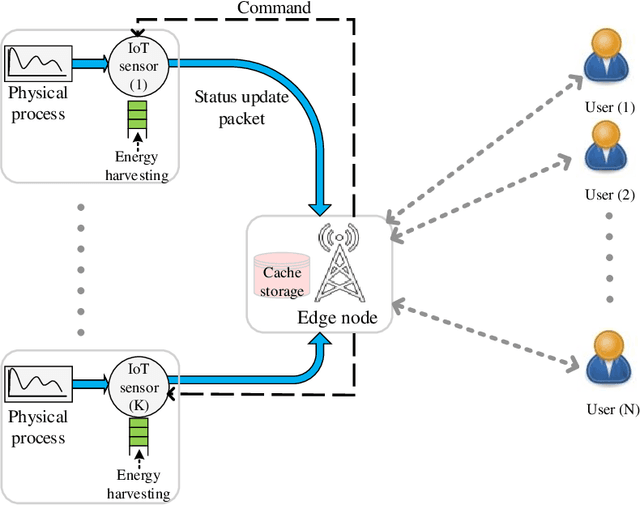
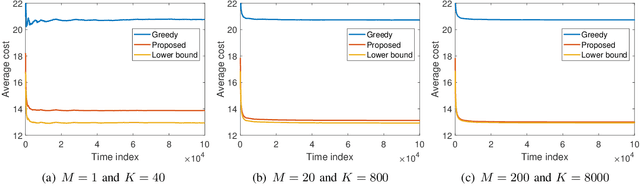
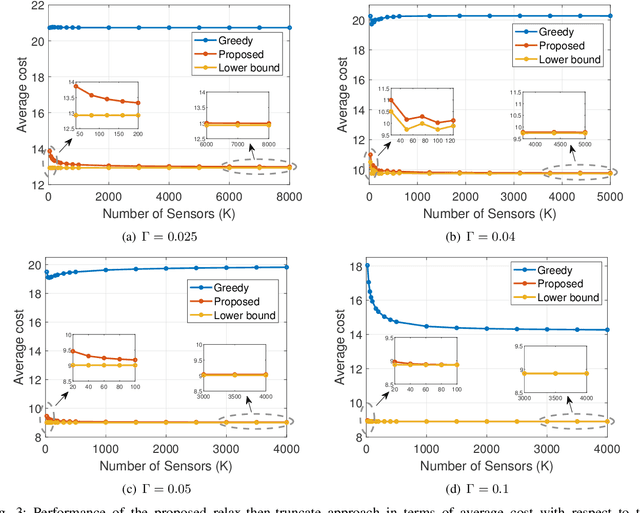
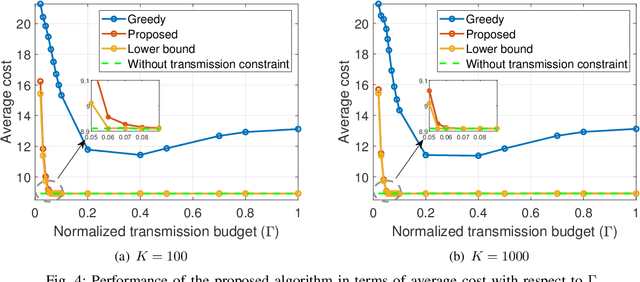
We consider a resource-constrained IoT network, where multiple users make on-demand requests to a cache-enabled edge node to send status updates about various random processes, each monitored by an energy harvesting sensor. The edge node serves users' requests by deciding whether to command the corresponding sensor to send a fresh status update or retrieve the most recently received measurement from the cache. Our objective is to find the best actions of the edge node to minimize the average age of information (AoI) of the received measurements upon request, i.e., average on-demand AoI, subject to per-slot transmission and energy constraints. First, we derive a Markov decision process model and propose an iterative algorithm that obtains an optimal policy. Then, we develop an asymptotically optimal low-complexity algorithm -- termed relax-then-truncate -- and prove that it is optimal as the number of sensors goes to infinity. Simulation results illustrate that the proposed relax-then-truncate approach significantly reduces the average on-demand AoI compared to a request-aware greedy (myopic) policy and also depict that it performs close to the optimal solution even for moderate numbers of sensors.
High-Accuracy RGB-D Face Recognition via Segmentation-Aware Face Depth Estimation and Mask-Guided Attention Network
Dec 22, 2021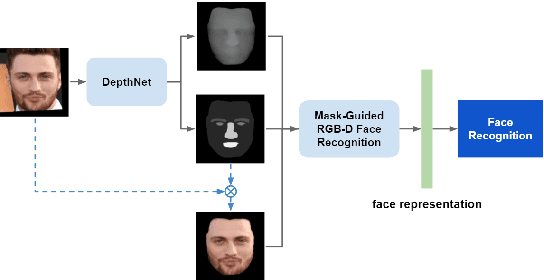
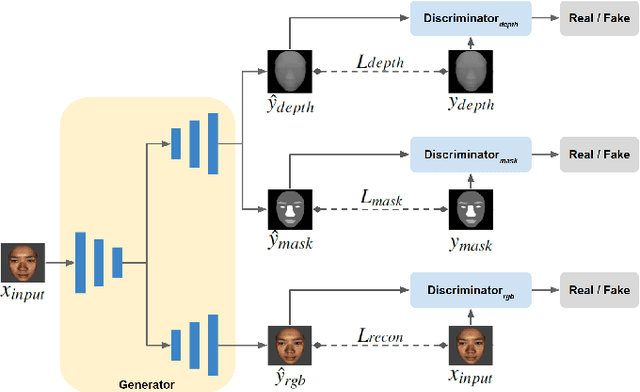
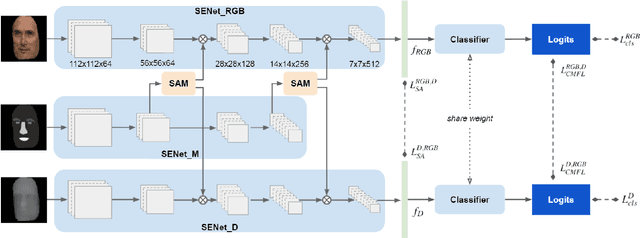

Deep learning approaches have achieved highly accurate face recognition by training the models with very large face image datasets. Unlike the availability of large 2D face image datasets, there is a lack of large 3D face datasets available to the public. Existing public 3D face datasets were usually collected with few subjects, leading to the over-fitting problem. This paper proposes two CNN models to improve the RGB-D face recognition task. The first is a segmentation-aware depth estimation network, called DepthNet, which estimates depth maps from RGB face images by including semantic segmentation information for more accurate face region localization. The other is a novel mask-guided RGB-D face recognition model that contains an RGB recognition branch, a depth map recognition branch, and an auxiliary segmentation mask branch with a spatial attention module. Our DepthNet is used to augment a large 2D face image dataset to a large RGB-D face dataset, which is used for training an accurate RGB-D face recognition model. Furthermore, the proposed mask-guided RGB-D face recognition model can fully exploit the depth map and segmentation mask information and is more robust against pose variation than previous methods. Our experimental results show that DepthNet can produce more reliable depth maps from face images with the segmentation mask. Our mask-guided face recognition model outperforms state-of-the-art methods on several public 3D face datasets.
Hybrid Contrastive Quantization for Efficient Cross-View Video Retrieval
Feb 10, 2022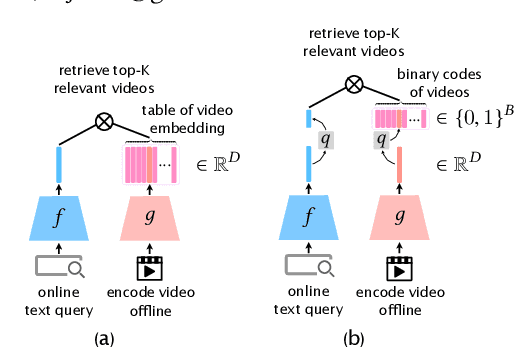
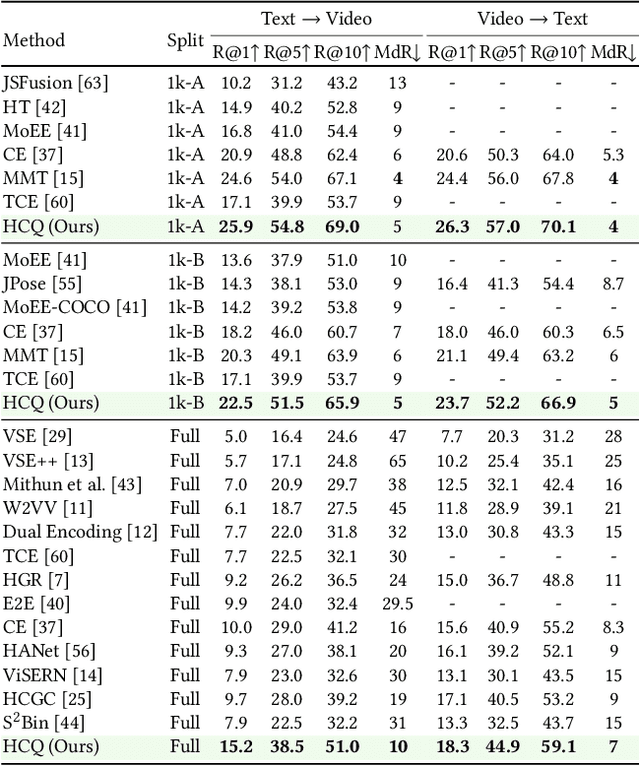
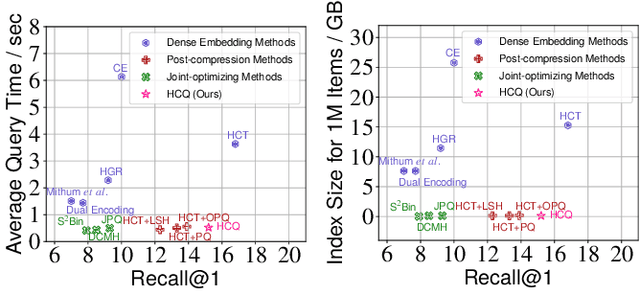
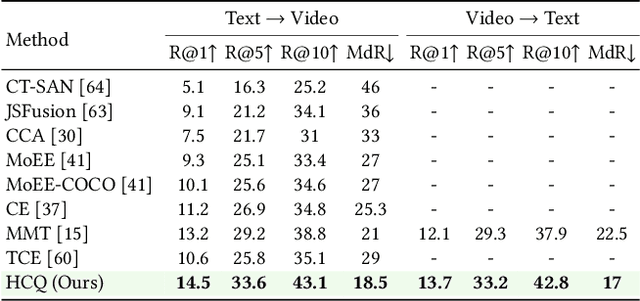
With the recent boom of video-based social platforms (e.g., YouTube and TikTok), video retrieval using sentence queries has become an important demand and attracts increasing research attention. Despite the decent performance, existing text-video retrieval models in vision and language communities are impractical for large-scale Web search because they adopt brute-force search based on high-dimensional embeddings. To improve efficiency, Web search engines widely apply vector compression libraries (e.g., FAISS) to post-process the learned embeddings. Unfortunately, separate compression from feature encoding degrades the robustness of representations and incurs performance decay. To pursue a better balance between performance and efficiency, we propose the first quantized representation learning method for cross-view video retrieval, namely Hybrid Contrastive Quantization (HCQ). Specifically, HCQ learns both coarse-grained and fine-grained quantizations with transformers, which provide complementary understandings for texts and videos and preserve comprehensive semantic information. By performing Asymmetric-Quantized Contrastive Learning (AQ-CL) across views, HCQ aligns texts and videos at coarse-grained and multiple fine-grained levels. This hybrid-grained learning strategy serves as strong supervision on the cross-view video quantization model, where contrastive learning at different levels can be mutually promoted. Extensive experiments on three Web video benchmark datasets demonstrate that HCQ achieves competitive performance with state-of-the-art non-compressed retrieval methods while showing high efficiency in storage and computation. Code and configurations are available at https://github.com/gimpong/WWW22-HCQ.
Data-Efficient Mutual Information Neural Estimator
May 08, 2019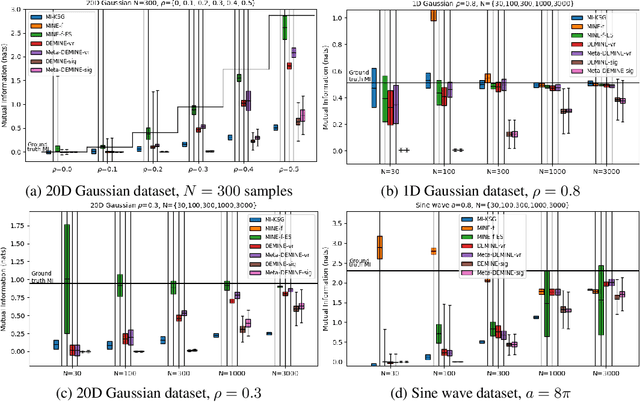
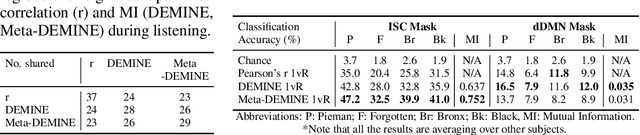
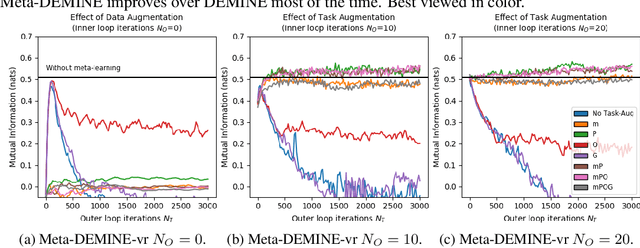
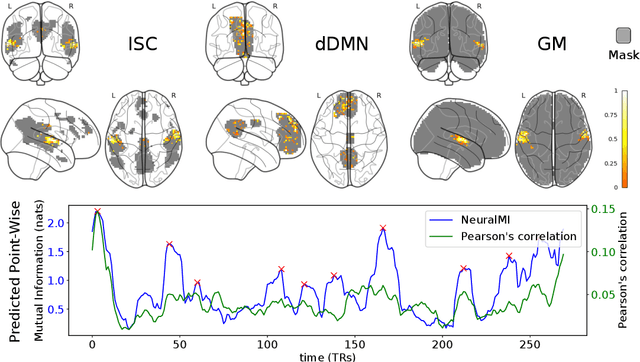
Measuring Mutual Information (MI) between high-dimensional, continuous, random variables from observed samples has wide theoretical and practical applications. While traditional MI methods, such as (Kraskov et al. 2004), capable of capturing MI between low-dimensional signals, they fall short when dimensionality increases and are not scalable. Existing neural approaches, such as MINE (Belghazi et al. 2018), searches for a d-dimensional neural network that maximizes a variational lower bound for mutual information estimation; however, this requires O(d log d) observed samples to prevent the neural network from overfitting. For practical mutual information estimation in real world applications, data is not always available at a surplus, especially in cases where acquisition of the data is prohibitively expensive, for example in fMRI analysis. We introduce a scalable, data-efficient mutual information estimator. By coupling a learning-based view of the MI lower bound with meta-learning, DEMINE achieves high-confidence estimations irrespective of network size and with improved accuracy at practical dataset sizes. We demonstrate the effectiveness of DEMINE on synthetic benchmarks as well as a real world application of fMRI inter-subject correlation analysis.
No-Regret Learning in Dynamic Stackelberg Games
Feb 10, 2022In a Stackelberg game, a leader commits to a randomized strategy, and a follower chooses their best strategy in response. We consider an extension of a standard Stackelberg game, called a discrete-time dynamic Stackelberg game, that has an underlying state space that affects the leader's rewards and available strategies and evolves in a Markovian manner depending on both the leader and follower's selected strategies. Although standard Stackelberg games have been utilized to improve scheduling in security domains, their deployment is often limited by requiring complete information of the follower's utility function. In contrast, we consider scenarios where the follower's utility function is unknown to the leader; however, it can be linearly parameterized. Our objective then is to provide an algorithm that prescribes a randomized strategy to the leader at each step of the game based on observations of how the follower responded in previous steps. We design a no-regret learning algorithm that, with high probability, achieves a regret bound (when compared to the best policy in hindsight) which is sublinear in the number of time steps; the degree of sublinearity depends on the number of features representing the follower's utility function. The regret of the proposed learning algorithm is independent of the size of the state space and polynomial in the rest of the parameters of the game. We show that the proposed learning algorithm outperforms existing model-free reinforcement learning approaches.
Semantic Labeling of Human Action For Visually Impaired And Blind People Scene Interaction
Jan 12, 2022
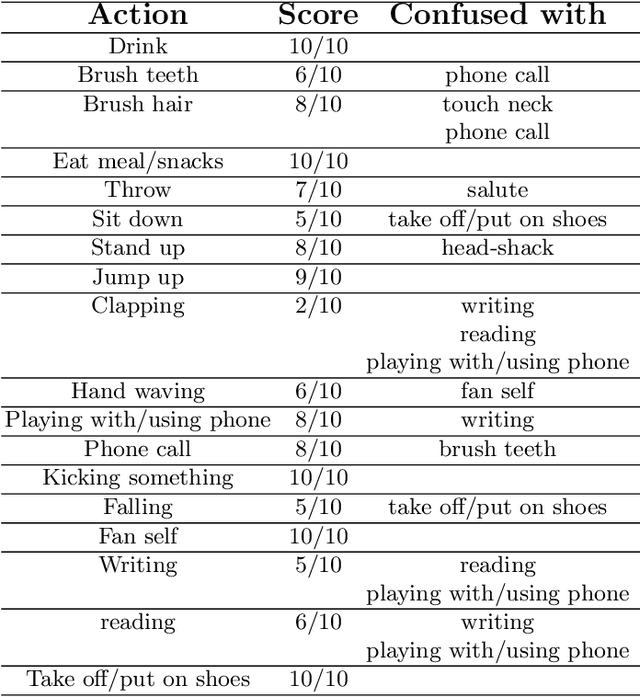
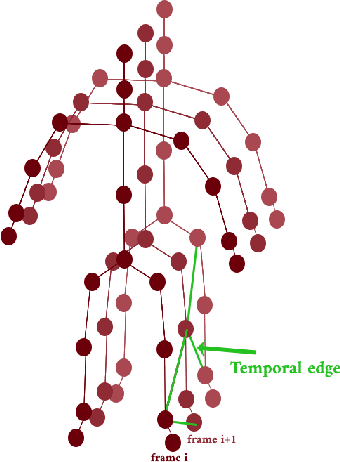
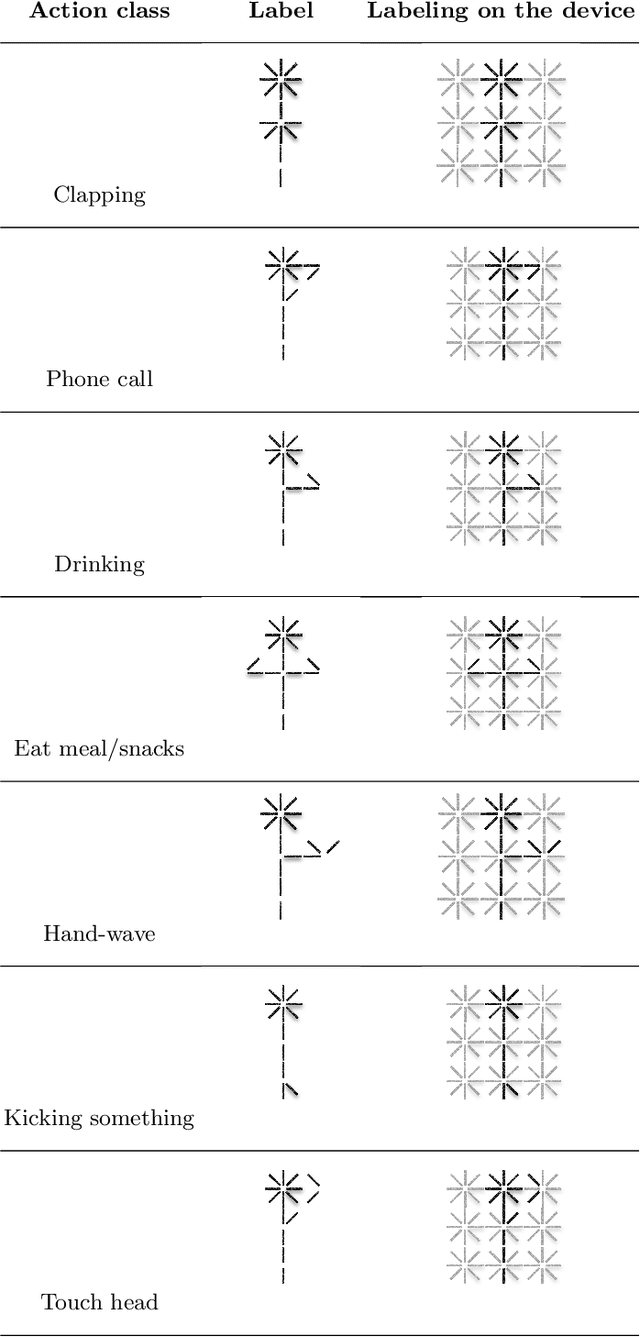
The aim of this work is to contribute to the development of a tactile device for visually impaired and blind persons in order to let them to understand actions of the surrounding people and to interact with them. First, based on the state-of-the-art methods of human action recognition from RGB-D sequences, we use the skeleton information provided by Kinect, with the disentangled and unified multi-scale Graph Convolutional (MS-G3D) model to recognize the performed actions. We tested this model on real scenes and found some of constraints and limitations. Next, we apply a fusion between skeleton modality with MS-G3D and depth modality with CNN in order to bypass the discussed limitations. Third, the recognized actions are labeled semantically and will be mapped into an output device perceivable by the touch sense.
Motion Sickness Modeling with Visual Vertical Estimation and Its Application to Autonomous Personal Mobility Vehicles
Feb 13, 2022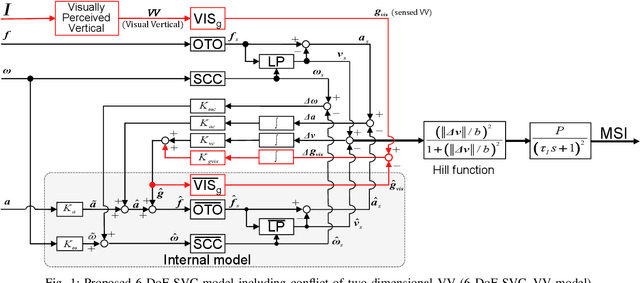


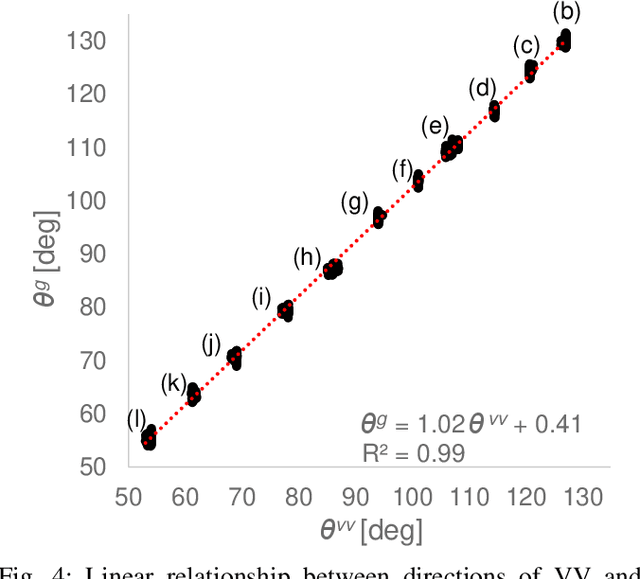
Passengers (drivers) of level 3-5 autonomous personal mobility vehicles (APMV) and cars can perform non-driving tasks, such as reading books and smartphones, while driving. It has been pointed out that such activities may increase motion sickness. Many studies have been conducted to build countermeasures, of which various computational motion sickness models have been developed. Many of these are based on subjective vertical conflict (SVC) theory, which describes vertical changes in direction sensed by human sensory organs vs. those expected by the central nervous system. Such models are expected to be applied to autonomous driving scenarios. However, no current computational model can integrate visual vertical information with vestibular sensations. We proposed a 6 DoF SVC-VV model which add a visually perceived vertical block into a conventional six-degrees-of-freedom SVC model to predict VV directions from image data simulating the visual input of a human. Hence, a simple image-based VV estimation method is proposed. As the validation of the proposed model, this paper focuses on describing the fact that the motion sickness increases as a passenger reads a book while using an AMPV, assuming that visual vertical (VV) plays an important role. In the static experiment, it is demonstrated that the estimated VV by the proposed method accurately described the gravitational acceleration direction with a low mean absolute deviation. In addition, the results of the driving experiment using an APMV demonstrated that the proposed 6 DoF SVC-VV model could describe that the increased motion sickness experienced when the VV and gravitational acceleration directions were different.
Contextualize differential privacy in image database: a lightweight image differential privacy approach based on principle component analysis inverse
Feb 16, 2022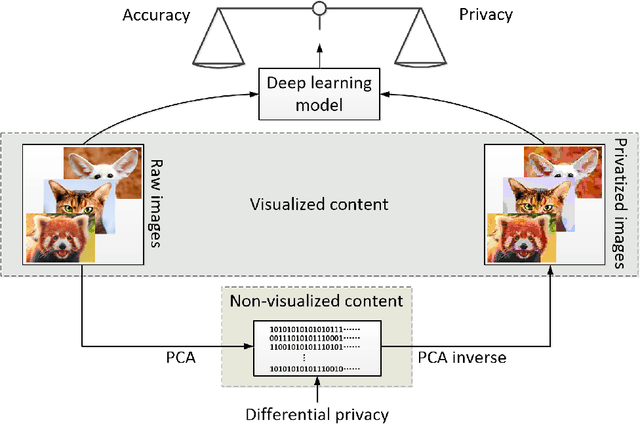


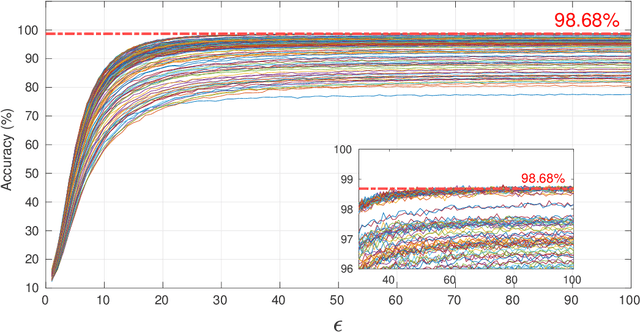
Differential privacy (DP) has been the de-facto standard to preserve privacy-sensitive information in database. Nevertheless, there lacks a clear and convincing contextualization of DP in image database, where individual images' indistinguishable contribution to a certain analysis can be achieved and observed when DP is exerted. As a result, the privacy-accuracy trade-off due to integrating DP is insufficiently demonstrated in the context of differentially-private image database. This work aims at contextualizing DP in image database by an explicit and intuitive demonstration of integrating conceptional differential privacy with images. To this end, we design a lightweight approach dedicating to privatizing image database as a whole and preserving the statistical semantics of the image database to an adjustable level, while making individual images' contribution to such statistics indistinguishable. The designed approach leverages principle component analysis (PCA) to reduce the raw image with large amount of attributes to a lower dimensional space whereby DP is performed, so as to decrease the DP load of calculating sensitivity attribute-by-attribute. The DP-exerted image data, which is not visible in its privatized format, is visualized through PCA inverse such that both a human and machine inspector can evaluate the privatization and quantify the privacy-accuracy trade-off in an analysis on the privatized image database. Using the devised approach, we demonstrate the contextualization of DP in images by two use cases based on deep learning models, where we show the indistinguishability of individual images induced by DP and the privatized images' retention of statistical semantics in deep learning tasks, which is elaborated by quantitative analyses on the privacy-accuracy trade-off under different privatization settings.
Adversarial Concept Erasure in Kernel Space
Jan 28, 2022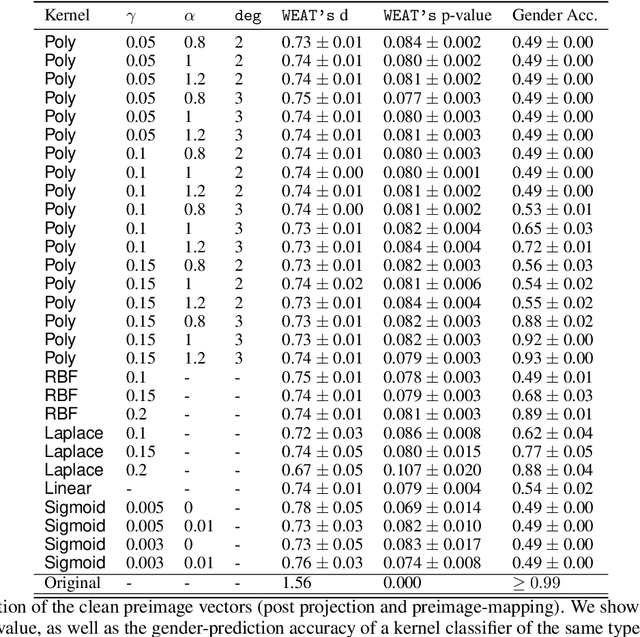
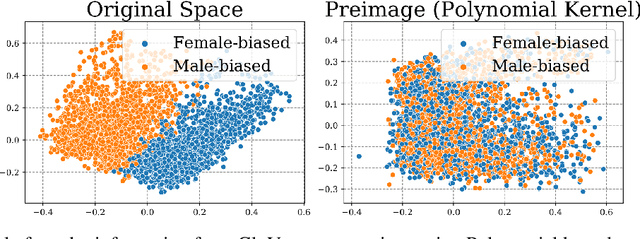

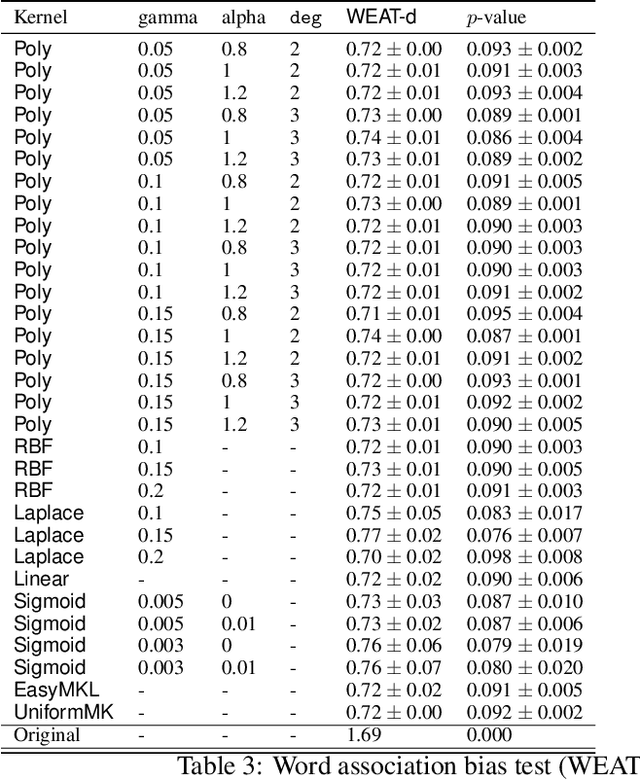
The representation space of neural models for textual data emerges in an unsupervised manner during training. Understanding how human-interpretable concepts, such as gender, are encoded in these representations would improve the ability of users to \emph{control} the content of these representations and analyze the working of the models that rely on them. One prominent approach to the control problem is the identification and removal of linear concept subspaces -- subspaces in the representation space that correspond to a given concept. While those are tractable and interpretable, neural network do not necessarily represent concepts in linear subspaces. We propose a kernalization of the linear concept-removal objective of [Ravfogel et al. 2022], and show that it is effective in guarding against the ability of certain nonlinear adversaries to recover the concept. Interestingly, our findings suggest that the division between linear and nonlinear models is overly simplistic: when considering the concept of binary gender and its neutralization, we do not find a single kernel space that exclusively contains all the concept-related information. It is therefore challenging to protect against \emph{all} nonlinear adversaries at once.
Directed Weight Neural Networks for Protein Structure Representation Learning
Jan 28, 2022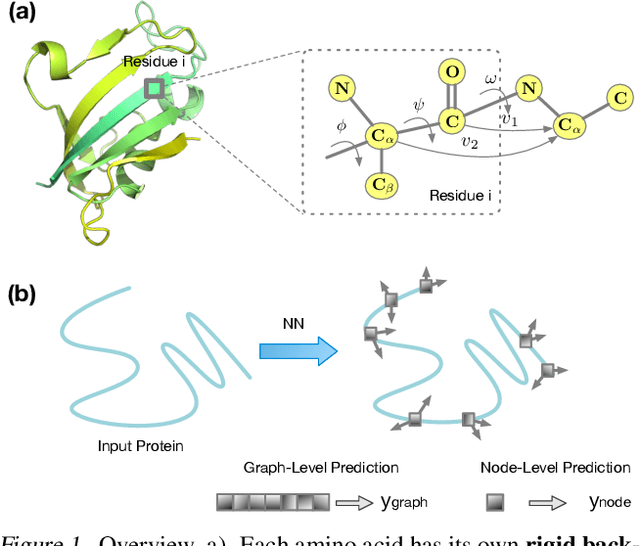
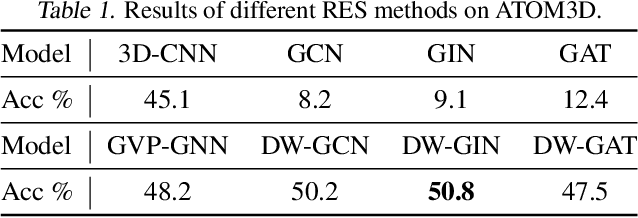
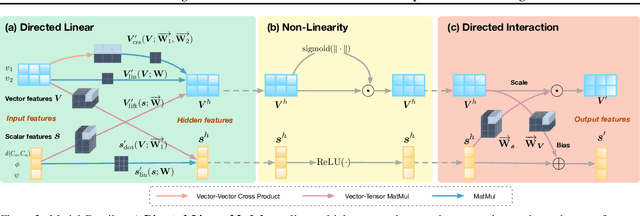
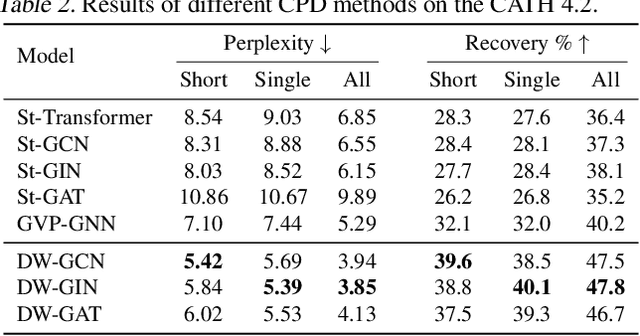
A protein performs biological functions by folding to a particular 3D structure. To accurately model the protein structures, both the overall geometric topology and local fine-grained relations between amino acids (e.g. side-chain torsion angles and inter-amino-acid orientations) should be carefully considered. In this work, we propose the Directed Weight Neural Network for better capturing geometric relations among different amino acids. Extending a single weight from a scalar to a 3D directed vector, our new framework supports a rich set of geometric operations on both classical and SO(3)--representation features, on top of which we construct a perceptron unit for processing amino-acid information. In addition, we introduce an equivariant message passing paradigm on proteins for plugging the directed weight perceptrons into existing Graph Neural Networks, showing superior versatility in maintaining SO(3)-equivariance at the global scale. Experiments show that our network has remarkably better expressiveness in representing geometric relations in comparison to classical neural networks and the (globally) equivariant networks. It also achieves state-of-the-art performance on various computational biology applications related to protein 3D structures.