 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multiple Time Series Fusion Based on LSTM An Application to CAP A Phase Classification Using EEG
Dec 18, 2021
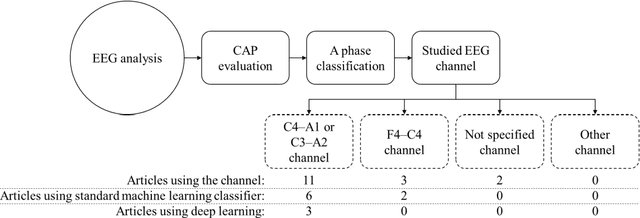

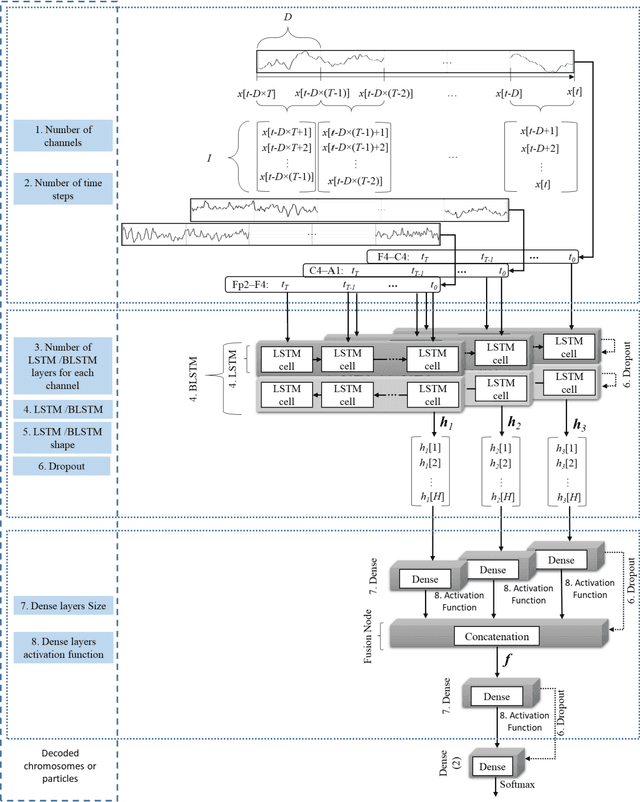

Biomedical decision making involves multiple signal processing, either from different sensors or from different channels. In both cases, information fusion plays a significant role. A deep learning based electroencephalogram channels' feature level fusion is carried out in this work for the electroencephalogram cyclic alternating pattern A phase classification. Channel selection, fusion, and classification procedures were optimized by two optimization algorithms, namely, Genetic Algorithm and Particle Swarm Optimization. The developed methodologies were evaluated by fusing the information from multiple electroencephalogram channels for patients with nocturnal frontal lobe epilepsy and patients without any neurological disorder, which was significantly more challenging when compared to other state of the art works. Results showed that both optimization algorithms selected a comparable structure with similar feature level fusion, consisting of three electroencephalogram channels, which is in line with the CAP protocol to ensure multiple channels' arousals for CAP detection. Moreover, the two optimized models reached an area under the receiver operating characteristic curve of 0.82, with average accuracy ranging from 77% to 79%, a result which is in the upper range of the specialist agreement. The proposed approach is still in the upper range of the best state of the art works despite a difficult dataset, and has the advantage of providing a fully automatic analysis without requiring any manual procedure. Ultimately, the models revealed to be noise resistant and resilient to multiple channel loss.
Cooperative Localization in Massive Networks
Oct 15, 2021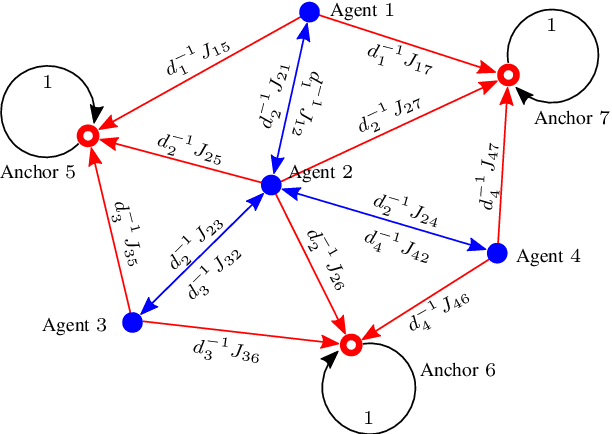
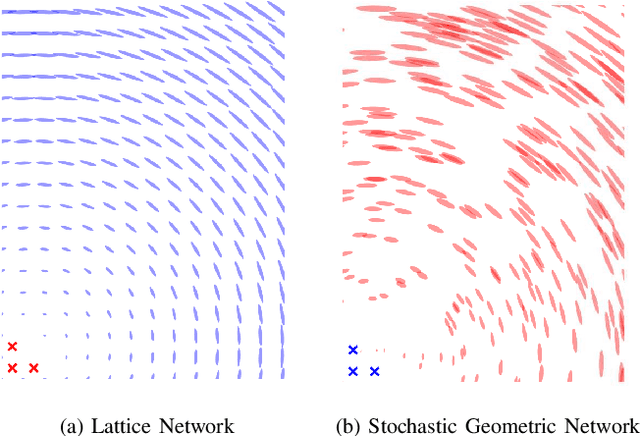
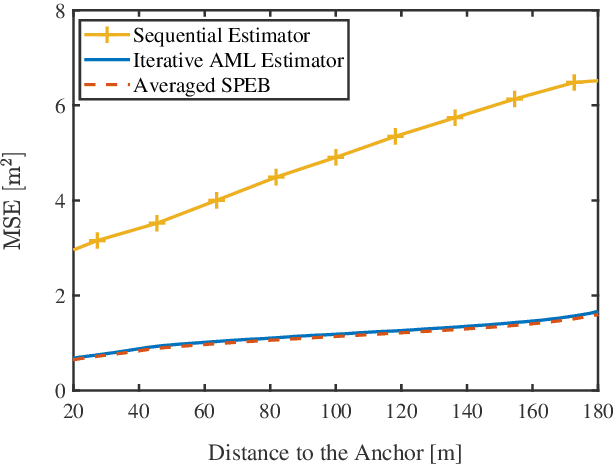
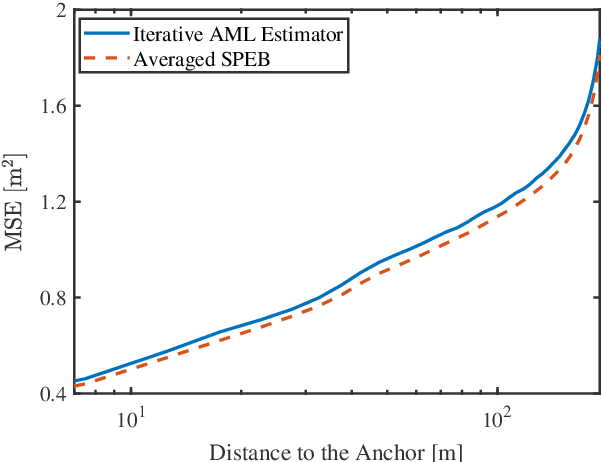
Network localization is capable of providing accurate and ubiquitous position information for numerous wireless applications. This paper studies the accuracy of cooperative network localization in large-scale wireless networks. Based on a decomposition of the equivalent Fisher information matrix (EFIM), we develop a random-walk-inspired approach for the analysis of EFIM, and propose a position information routing interpretation of cooperative network localization. Using this approach, we show that in large lattice and stochastic geometric networks, when anchors are uniformly distributed, the average localization error of agents grows logarithmically with the reciprocal of anchor density in an asymptotic regime. The results are further illustrated using numerical examples.
Temporal Knowledge Graph Completion: A Survey
Jan 16, 2022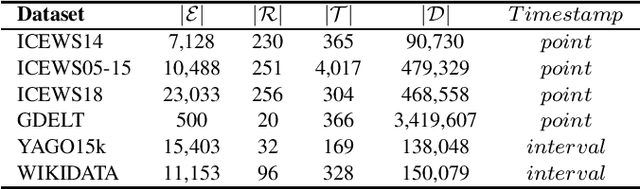
Knowledge graph completion (KGC) can predict missing links and is crucial for real-world knowledge graphs, which widely suffer from incompleteness. KGC methods assume a knowledge graph is static, but that may lead to inaccurate prediction results because many facts in the knowledge graphs change over time. Recently, emerging methods have shown improved predictive results by further incorporating the timestamps of facts; namely, temporal knowledge graph completion (TKGC). With this temporal information, TKGC methods can learn the dynamic evolution of the knowledge graph that KGC methods fail to capture. In this paper, for the first time, we summarize the recent advances in TKGC research. First, we detail the background of TKGC, including the problem definition, benchmark datasets, and evaluation metrics. Then, we summarize existing TKGC methods based on how timestamps of facts are used to capture the temporal dynamics. Finally, we conclude the paper and present future research directions of TKGC.
Information Robust Dirichlet Networks for Predictive Uncertainty Estimation
Oct 10, 2019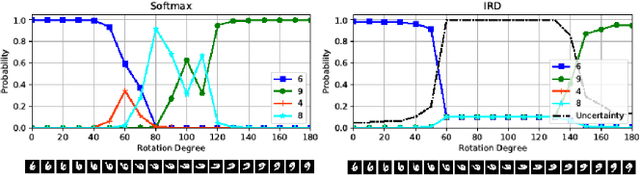
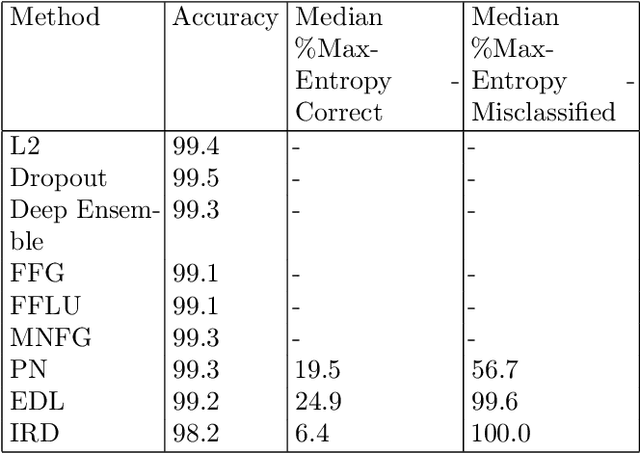
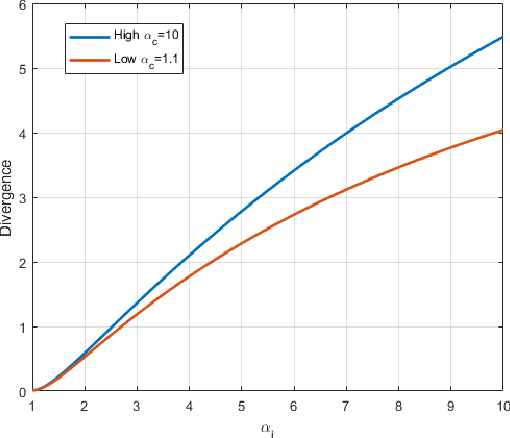
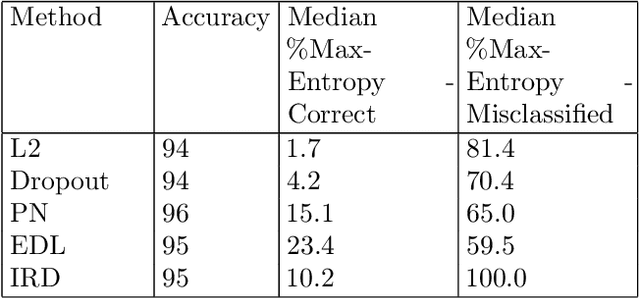
Precise estimation of uncertainty in predictions for AI systems is a critical factor in ensuring trust and safety. Conventional neural networks tend to be overconfident as they do not account for uncertainty during training. In contrast to Bayesian neural networks that learn approximate distributions on weights to infer prediction confidence, we propose a novel method, Information Robust Dirichlet networks, that learns the Dirichlet distribution on prediction probabilities by minimizing the expected $L_p$ norm of the prediction error and an information divergence loss that penalizes information flow towards incorrect classes, while simultaneously maximizing differential entropy of small adversarial perturbations to provide accurate uncertainty estimates. Properties of the new cost function are derived to indicate how improved uncertainty estimation is achieved. Experiments using real datasets show that our technique outperforms state-of-the-art neural networks, by a large margin, for estimating in-distribution and out-of-distribution uncertainty, and detecting adversarial examples.
Unsupervised Complementary-aware Multi-process Fusion for Visual Place Recognition
Dec 09, 2021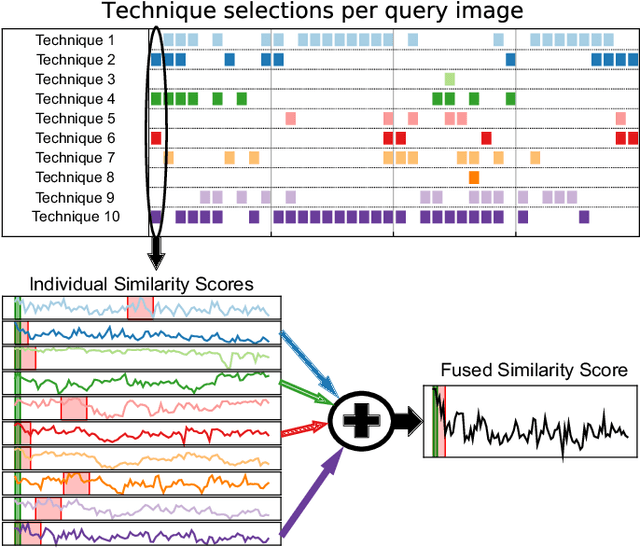
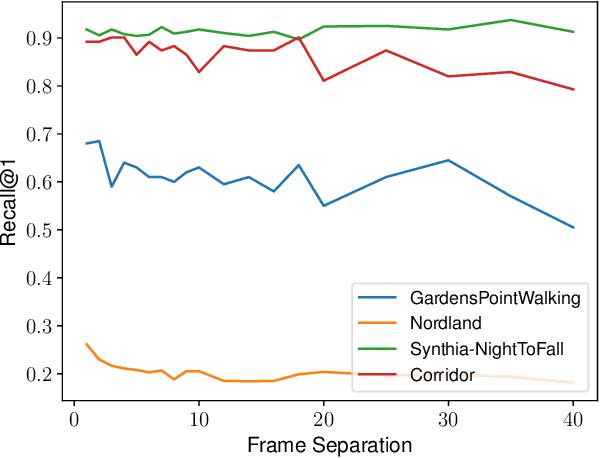
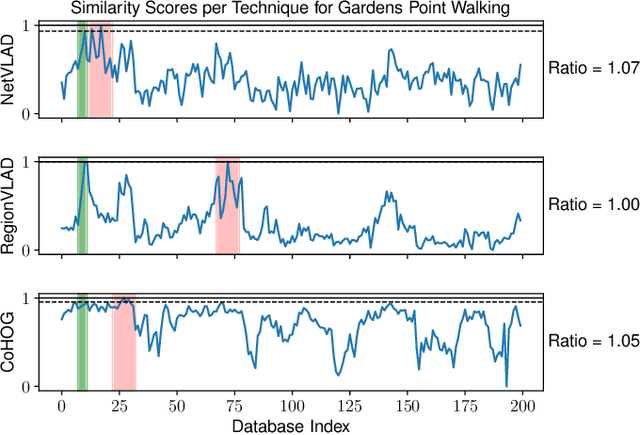
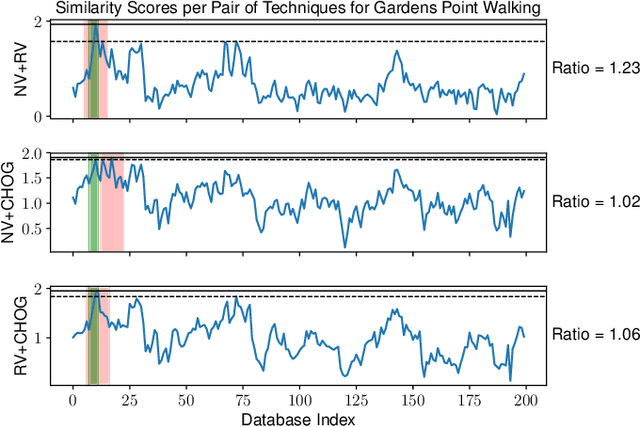
A recent approach to the Visual Place Recognition (VPR) problem has been to fuse the place recognition estimates of multiple complementary VPR techniques simultaneously. However, selecting the optimal set of techniques to use in a specific deployment environment a-priori is a difficult and unresolved challenge. Further, to the best of our knowledge, no method exists which can select a set of techniques on a frame-by-frame basis in response to image-to-image variations. In this work, we propose an unsupervised algorithm that finds the most robust set of VPR techniques to use in the current deployment environment, on a frame-by-frame basis. The selection of techniques is determined by an analysis of the similarity scores between the current query image and the collection of database images and does not require ground-truth information. We demonstrate our approach on a wide variety of datasets and VPR techniques and show that the proposed dynamic multi-process fusion (Dyn-MPF) has superior VPR performance compared to a variety of challenging competitive methods, some of which are given an unfair advantage through access to the ground-truth information.
Multi-Level Attention for Unsupervised Person Re-Identification
Jan 10, 2022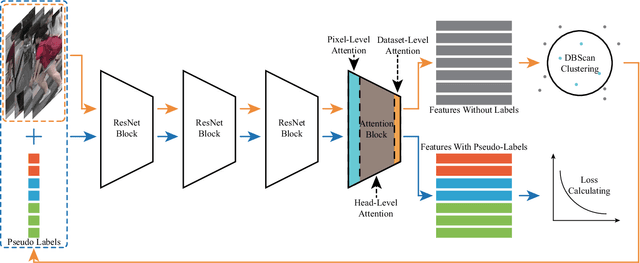

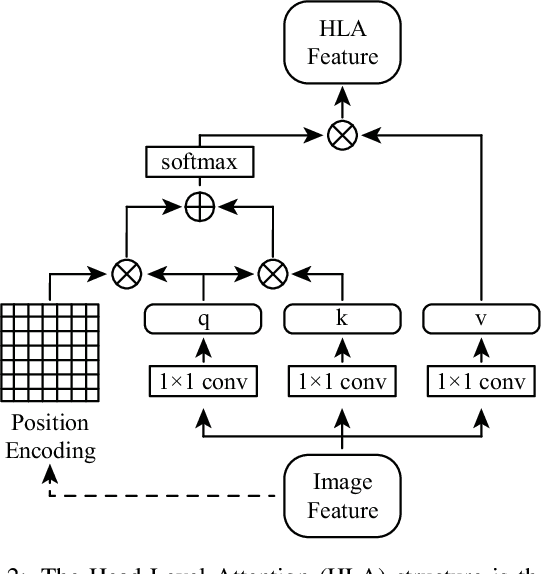
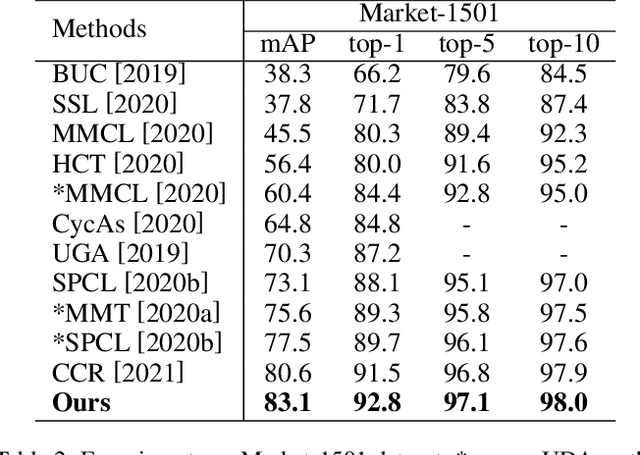
The attention mechanism is widely used in deep learning because of its excellent performance in neural networks without introducing additional information. However, in unsupervised person re-identification, the attention module represented by multi-headed self-attention suffers from attention spreading in the condition of non-ground truth. To solve this problem, we design pixel-level attention module to provide constraints for multi-headed self-attention. Meanwhile, for the trait that the identification targets of person re-identification data are all pedestrians in the samples, we design domain-level attention module to provide more comprehensive pedestrian features. We combine head-level, pixel-level and domain-level attention to propose multi-level attention block and validate its performance on for large person re-identification datasets (Market-1501, DukeMTMC-reID and MSMT17 and PersonX).
Data-Efficient Mutual Information Neural Estimator
May 08, 2019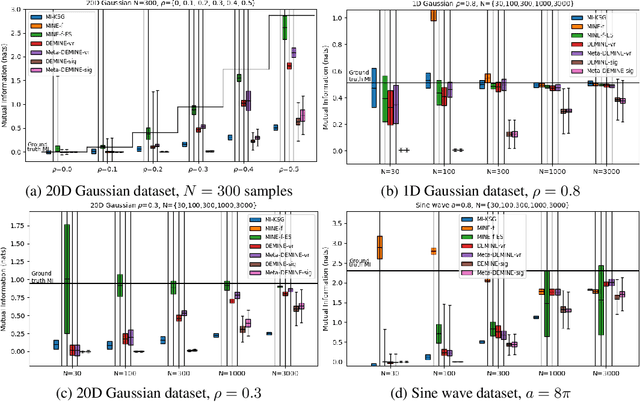
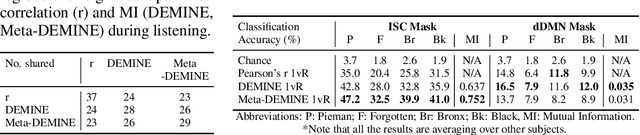
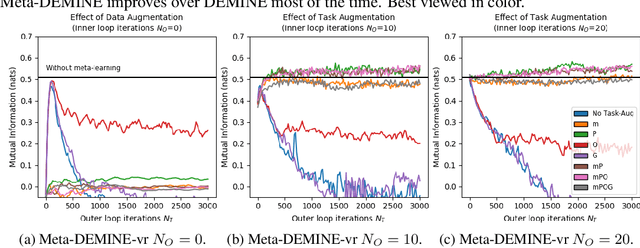
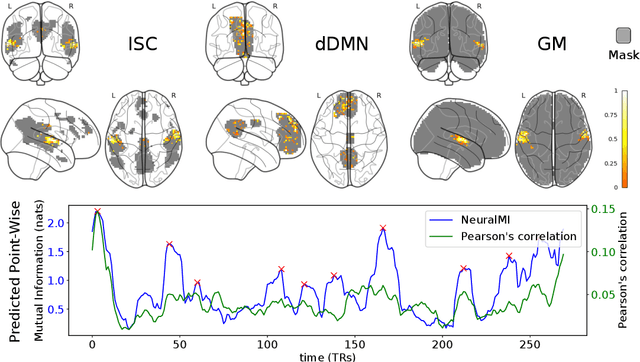
Measuring Mutual Information (MI) between high-dimensional, continuous, random variables from observed samples has wide theoretical and practical applications. While traditional MI methods, such as (Kraskov et al. 2004), capable of capturing MI between low-dimensional signals, they fall short when dimensionality increases and are not scalable. Existing neural approaches, such as MINE (Belghazi et al. 2018), searches for a d-dimensional neural network that maximizes a variational lower bound for mutual information estimation; however, this requires O(d log d) observed samples to prevent the neural network from overfitting. For practical mutual information estimation in real world applications, data is not always available at a surplus, especially in cases where acquisition of the data is prohibitively expensive, for example in fMRI analysis. We introduce a scalable, data-efficient mutual information estimator. By coupling a learning-based view of the MI lower bound with meta-learning, DEMINE achieves high-confidence estimations irrespective of network size and with improved accuracy at practical dataset sizes. We demonstrate the effectiveness of DEMINE on synthetic benchmarks as well as a real world application of fMRI inter-subject correlation analysis.
Short-time Fourier transform based on stimulated Brillouin scattering
Nov 26, 2021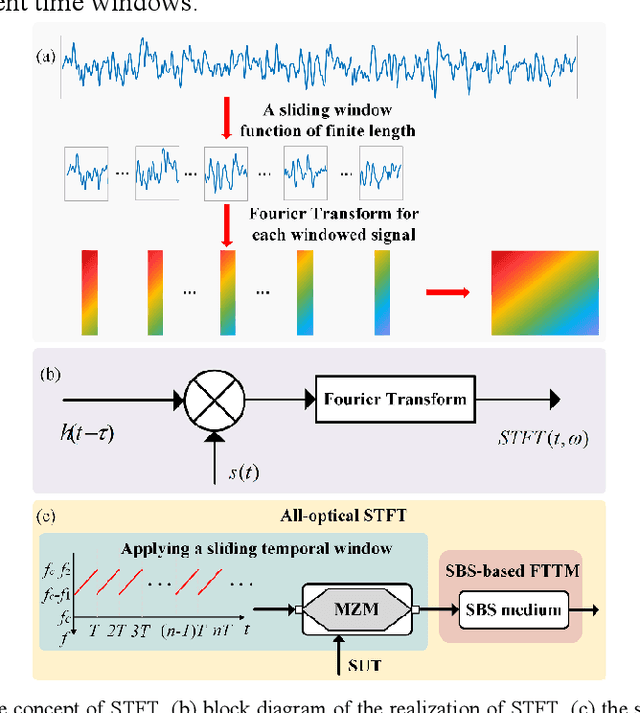
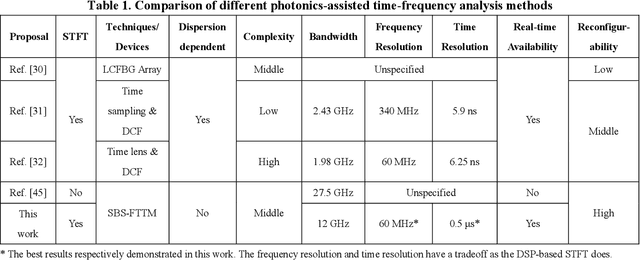
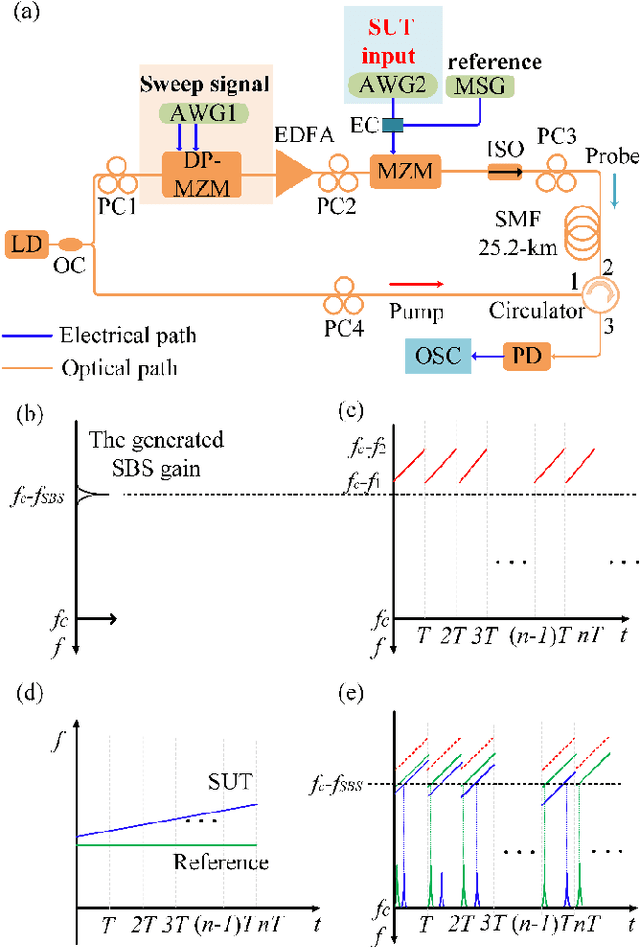
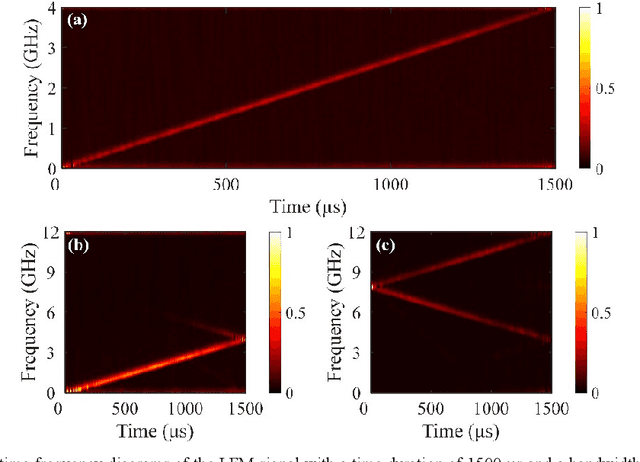
In this paper, all-optical short-time Fourier transform (STFT) based on stimulated Brillouin scattering (SBS) is proposed and further used for real-time time-frequency analysis of different radio frequency (RF) signals. In the proposed all-optical STFT system, SBS not only provides a band-pass filter for implementing the window function in conjunction with a periodic frequency-sweep optical signal but also obtains the frequency domain information in different time windows through the generated waveform via frequency-to-time mapping (FTTM). A periodic frequency-sweep optical signal is generated and then modulated at a Mach-Zehnder modulator by the electrical signal under test (SUT). During different sweep periods, the fixed Brillouin gain functions as a bandpass filter to select a specific range of the spectrum, which is equivalent to applying a sliding window function to the corresponding section of the temporal signal with the help of the sweep optical signal. At the same time, after the optical signal is selectively amplified by the SBS gain and converted back to the electrical domain, SBS also implements the real-time FTTM, which can be utilized to obtain the frequency domain information corresponding to different time windows through the generated waveforms via the FTTM. The frequency domain information corresponding to different time windows is formed and spliced to analyze the time-frequency relationship of the SUT in real-time. An experiment is performed. STFTs of a variety of RF signals are carried out in a 12-GHz bandwidth limited only by the equipment, and the dynamic frequency resolution is better than 60 MHz.
Code Representation Learning with Prüfer Sequences
Nov 14, 2021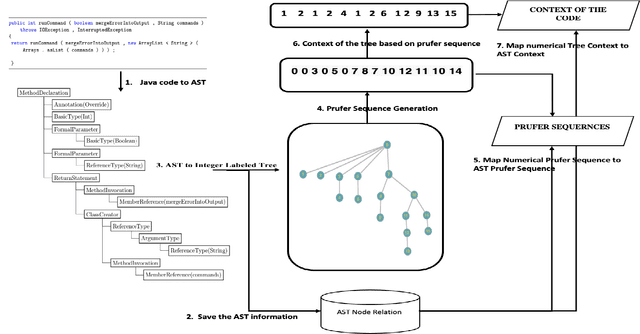
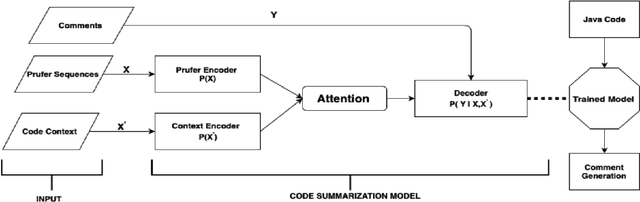
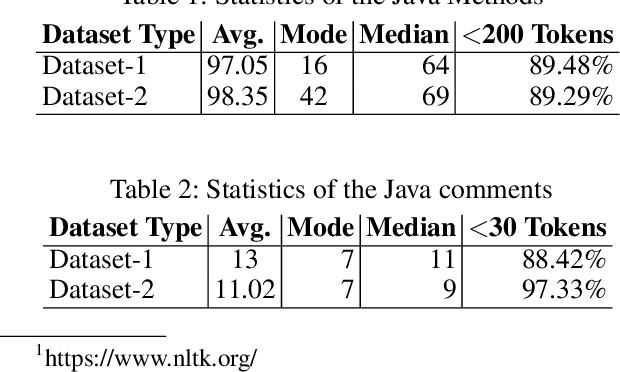
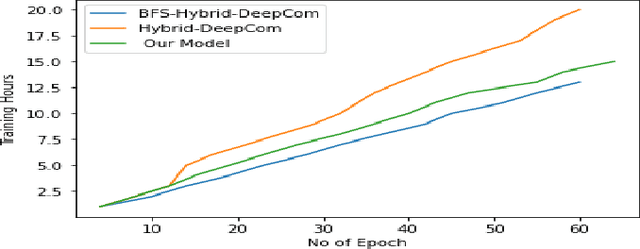
An effective and efficient encoding of the source code of a computer program is critical to the success of sequence-to-sequence deep neural network models for tasks in computer program comprehension, such as automated code summarization and documentation. A significant challenge is to find a sequential representation that captures the structural/syntactic information in a computer program and facilitates the training of the learning models. In this paper, we propose to use the Pr\"ufer sequence of the Abstract Syntax Tree (AST) of a computer program to design a sequential representation scheme that preserves the structural information in an AST. Our representation makes it possible to develop deep-learning models in which signals carried by lexical tokens in the training examples can be exploited automatically and selectively based on their syntactic role and importance. Unlike other recently-proposed approaches, our representation is concise and lossless in terms of the structural information of the AST. Empirical studies on real-world benchmark datasets, using a sequence-to-sequence learning model we designed for code summarization, show that our Pr\"ufer-sequence-based representation is indeed highly effective and efficient, outperforming significantly all the recently-proposed deep-learning models we used as the baseline models.
Fast MRI Reconstruction: How Powerful Transformers Are?
Jan 23, 2022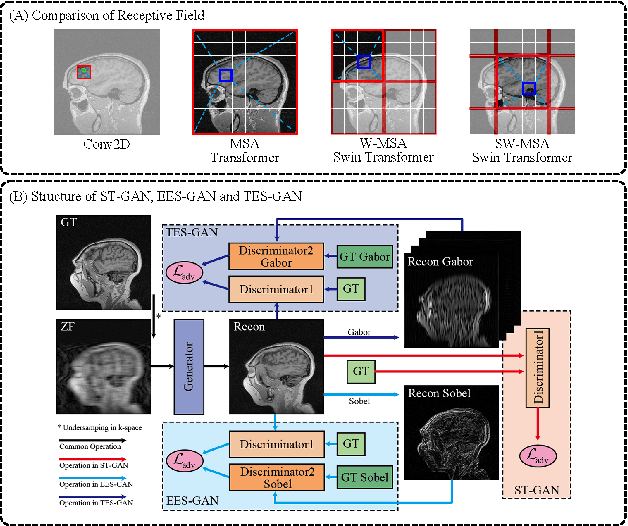
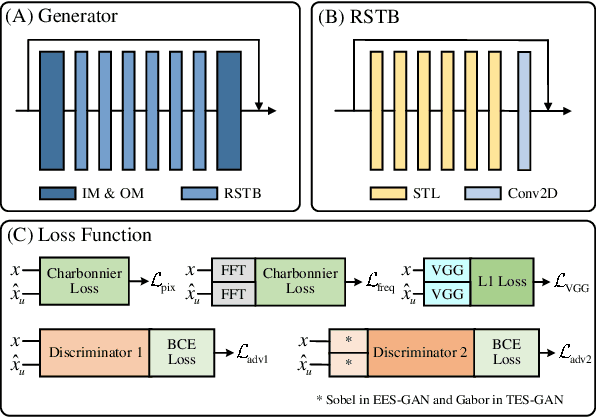
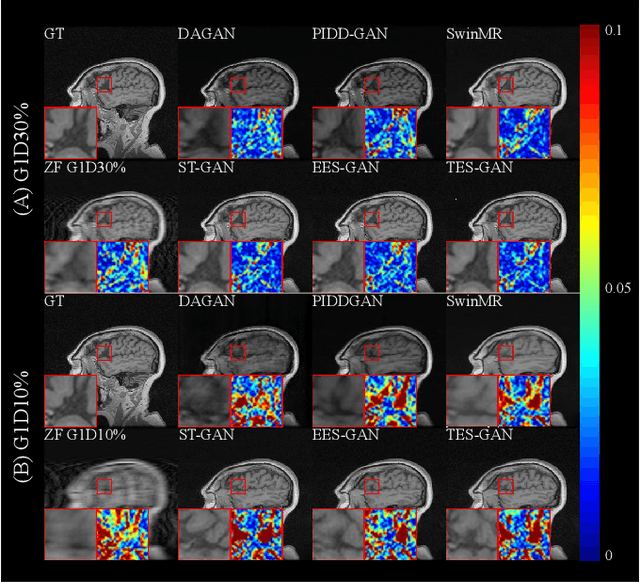
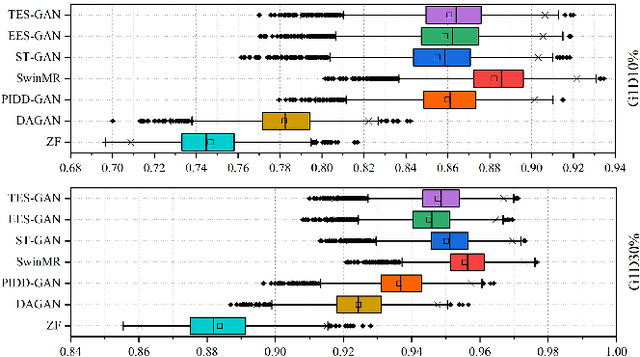
Magnetic resonance imaging (MRI) is a widely used non-radiative and non-invasive method for clinical interrogation of organ structures and metabolism, with an inherently long scanning time. Methods by k-space undersampling and deep learning based reconstruction have been popularised to accelerate the scanning process. This work focuses on investigating how powerful transformers are for fast MRI by exploiting and comparing different novel network architectures. In particular, a generative adversarial network (GAN) based Swin transformer (ST-GAN) was introduced for the fast MRI reconstruction. To further preserve the edge and texture information, edge enhanced GAN based Swin transformer (EESGAN) and texture enhanced GAN based Swin transformer (TES-GAN) were also developed, where a dual-discriminator GAN structure was applied. We compared our proposed GAN based transformers, standalone Swin transformer and other convolutional neural networks based based GAN model in terms of the evaluation metrics PSNR, SSIM and FID. We showed that transformers work well for the MRI reconstruction from different undersampling conditions. The utilisation of GAN's adversarial structure improves the quality of images reconstructed when undersampled for 30% or higher.