 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LaMDA: Language Models for Dialog Applications
Feb 10, 2022
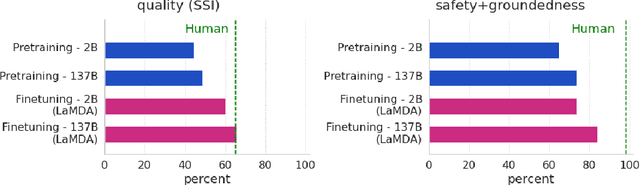
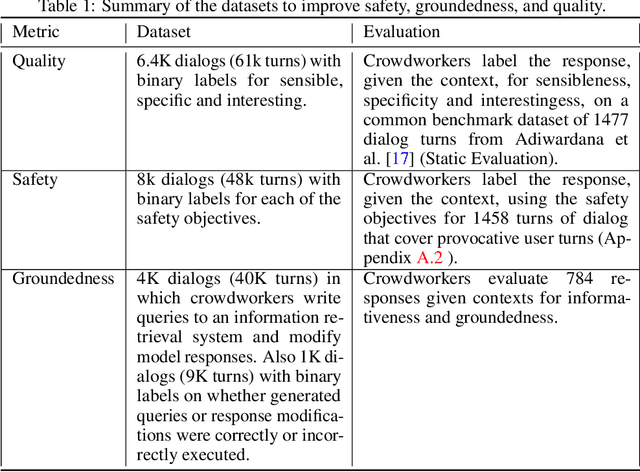

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Unsupervised Complementary-aware Multi-process Fusion for Visual Place Recognition
Dec 09, 2021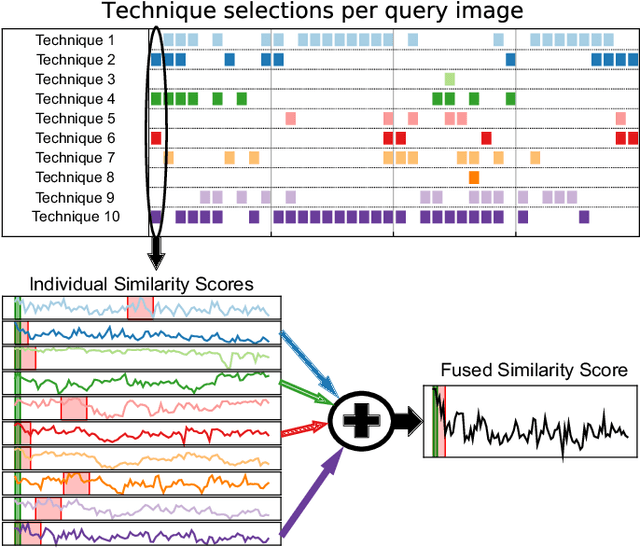
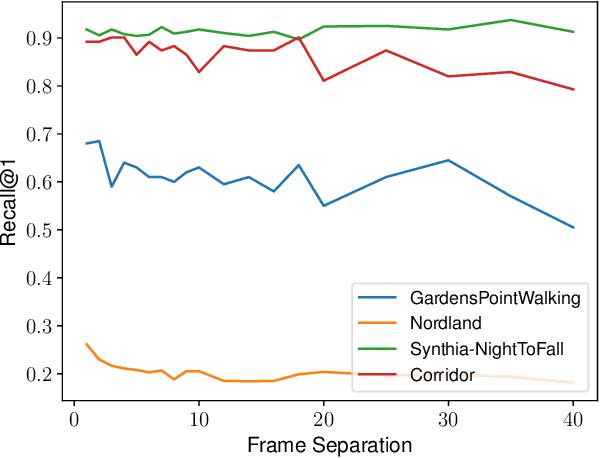
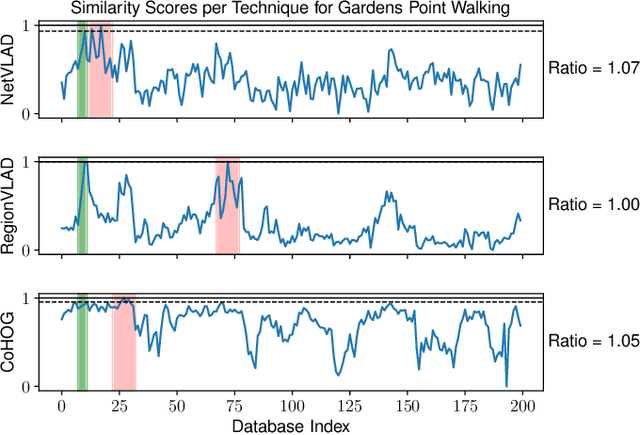
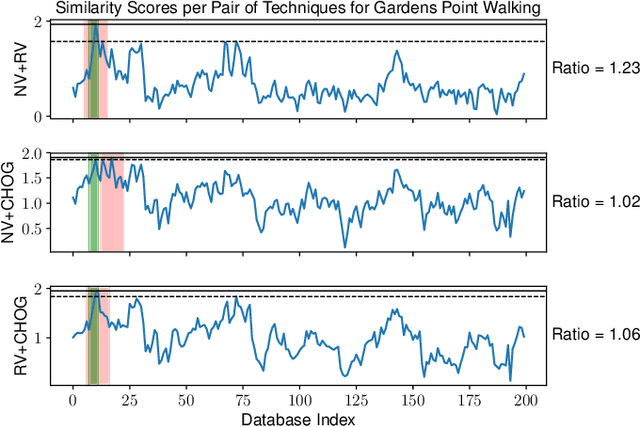
A recent approach to the Visual Place Recognition (VPR) problem has been to fuse the place recognition estimates of multiple complementary VPR techniques simultaneously. However, selecting the optimal set of techniques to use in a specific deployment environment a-priori is a difficult and unresolved challenge. Further, to the best of our knowledge, no method exists which can select a set of techniques on a frame-by-frame basis in response to image-to-image variations. In this work, we propose an unsupervised algorithm that finds the most robust set of VPR techniques to use in the current deployment environment, on a frame-by-frame basis. The selection of techniques is determined by an analysis of the similarity scores between the current query image and the collection of database images and does not require ground-truth information. We demonstrate our approach on a wide variety of datasets and VPR techniques and show that the proposed dynamic multi-process fusion (Dyn-MPF) has superior VPR performance compared to a variety of challenging competitive methods, some of which are given an unfair advantage through access to the ground-truth information.
TV-based Spline Reconstruction with Fourier Measurements: Uniqueness and Convergence of Grid-Based Methods
Feb 10, 2022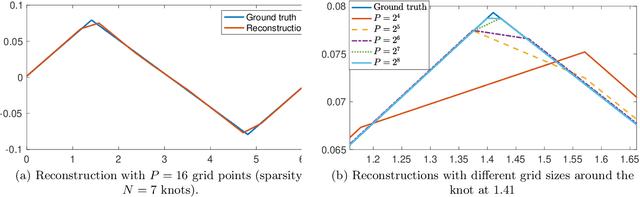
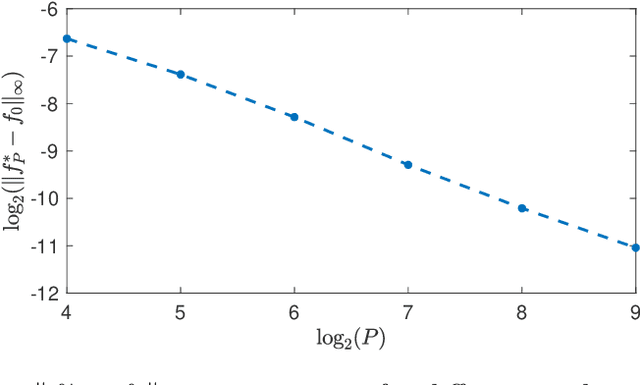
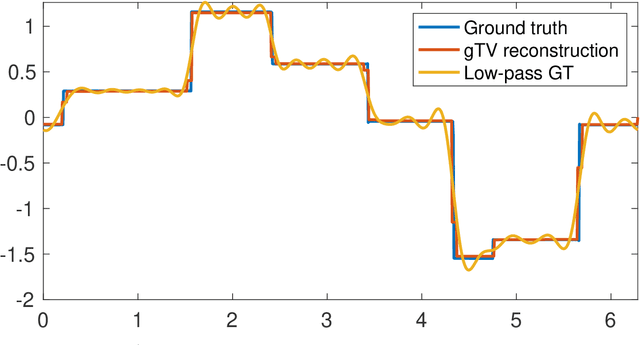
We study the problem of recovering piecewise-polynomial periodic functions from their low-frequency information. This means that we only have access to possibly corrupted versions of the Fourier samples of the ground truth up to a maximum cutoff frequency $K_c$. The reconstruction task is specified as an optimization problem with total-variation (TV) regularization (in the sense of measures) involving the $M$-th order derivative regularization operator $\mathrm{L} = \mathrm{D}^M$. The order $M \geq 1$ determines the degree of the reconstructed piecewise polynomial spline, whereas the TV regularization norm, which is known to promote sparsity, guarantees a small number of pieces. We show that the solution of our optimization problem is always unique, which, to the best of our knowledge, is a first for TV-based problems. Moreover, we show that this solution is a periodic spline matched to the regularization operator $\mathrm{L}$ whose number of knots is upper-bounded by $2 K_c$. We then consider the grid-based discretization of our optimization problem in the space of uniform $\mathrm{L}$-splines. On the theoretical side, we show that any sequence of solutions of the discretized problem converges uniformly to the unique solution of the gridless problem as the grid size vanishes. Finally, on the algorithmic side, we propose a B-spline-based algorithm to solve the grid-based problem, and we demonstrate its numerical feasibility experimentally. On both of these aspects, we leverage the uniqueness of the solution of the original problem.
Information Directed Sampling for Linear Partial Monitoring
Feb 25, 2020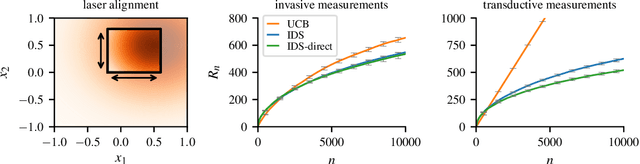
Partial monitoring is a rich framework for sequential decision making under uncertainty that generalizes many well known bandit models, including linear, combinatorial and dueling bandits. We introduce information directed sampling (IDS) for stochastic partial monitoring with a linear reward and observation structure. IDS achieves adaptive worst-case regret rates that depend on precise observability conditions of the game. Moreover, we prove lower bounds that classify the minimax regret of all finite games into four possible regimes. IDS achieves the optimal rate in all cases up to logarithmic factors, without tuning any hyper-parameters. We further extend our results to the contextual and the kernelized setting, which significantly increases the range of possible applications.
Temporal Knowledge Graph Completion: A Survey
Jan 16, 2022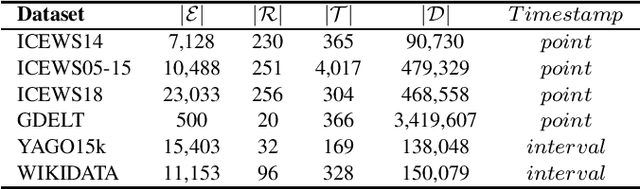
Knowledge graph completion (KGC) can predict missing links and is crucial for real-world knowledge graphs, which widely suffer from incompleteness. KGC methods assume a knowledge graph is static, but that may lead to inaccurate prediction results because many facts in the knowledge graphs change over time. Recently, emerging methods have shown improved predictive results by further incorporating the timestamps of facts; namely, temporal knowledge graph completion (TKGC). With this temporal information, TKGC methods can learn the dynamic evolution of the knowledge graph that KGC methods fail to capture. In this paper, for the first time, we summarize the recent advances in TKGC research. First, we detail the background of TKGC, including the problem definition, benchmark datasets, and evaluation metrics. Then, we summarize existing TKGC methods based on how timestamps of facts are used to capture the temporal dynamics. Finally, we conclude the paper and present future research directions of TKGC.
Code Representation Learning with Prüfer Sequences
Nov 14, 2021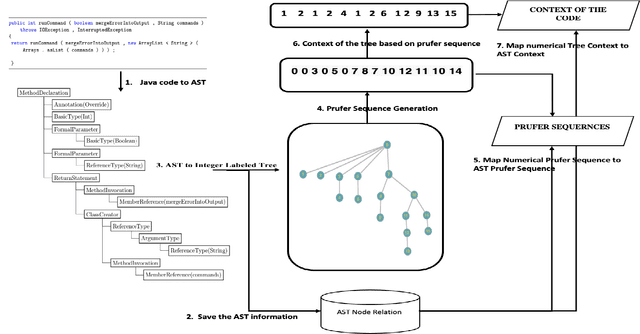
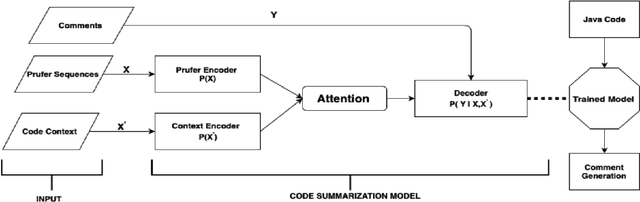
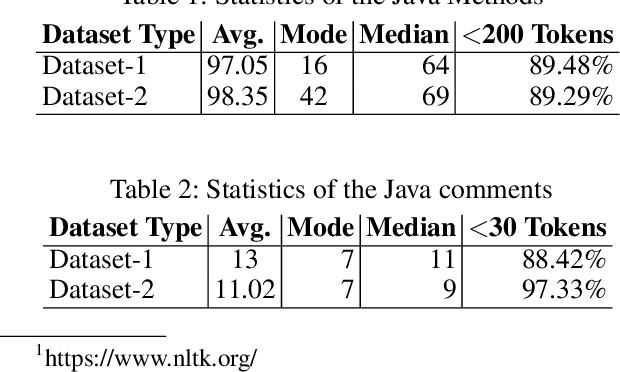
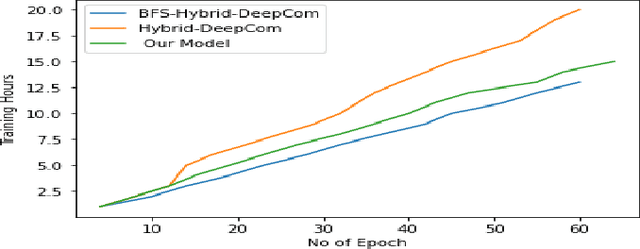
An effective and efficient encoding of the source code of a computer program is critical to the success of sequence-to-sequence deep neural network models for tasks in computer program comprehension, such as automated code summarization and documentation. A significant challenge is to find a sequential representation that captures the structural/syntactic information in a computer program and facilitates the training of the learning models. In this paper, we propose to use the Pr\"ufer sequence of the Abstract Syntax Tree (AST) of a computer program to design a sequential representation scheme that preserves the structural information in an AST. Our representation makes it possible to develop deep-learning models in which signals carried by lexical tokens in the training examples can be exploited automatically and selectively based on their syntactic role and importance. Unlike other recently-proposed approaches, our representation is concise and lossless in terms of the structural information of the AST. Empirical studies on real-world benchmark datasets, using a sequence-to-sequence learning model we designed for code summarization, show that our Pr\"ufer-sequence-based representation is indeed highly effective and efficient, outperforming significantly all the recently-proposed deep-learning models we used as the baseline models.
SUPA: A Lightweight Diagnostic Simulator for Machine Learning in Particle Physics
Feb 10, 2022
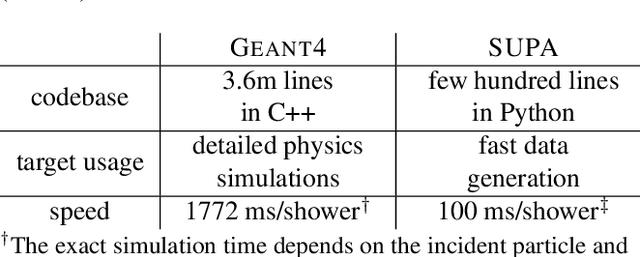
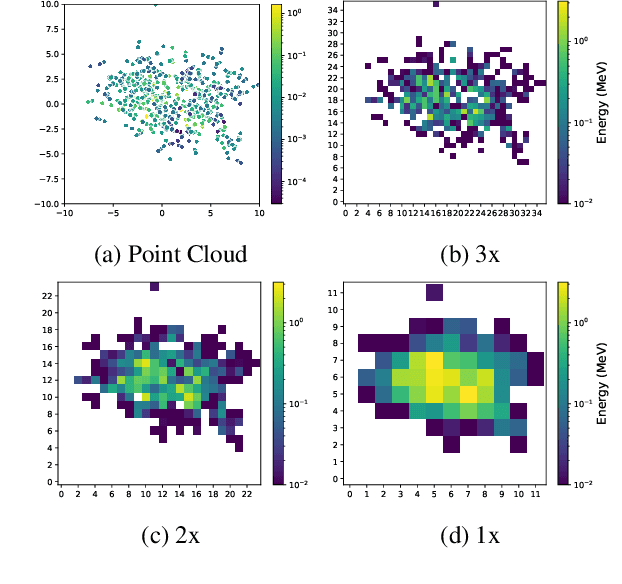
Deep learning methods have gained popularity in high energy physics for fast modeling of particle showers in detectors. Detailed simulation frameworks such as the gold standard Geant4 are computationally intensive, and current deep generative architectures work on discretized, lower resolution versions of the detailed simulation. The development of models that work at higher spatial resolutions is currently hindered by the complexity of the full simulation data, and by the lack of simpler, more interpretable benchmarks. Our contribution is SUPA, the SUrrogate PArticle propagation simulator, an algorithm and software package for generating data by simulating simplified particle propagation, scattering and shower development in matter. The generation is extremely fast and easy to use compared to Geant4, but still exhibits the key characteristics and challenges of the detailed simulation. We support this claim experimentally by showing that performance of generative models on data from our simulator reflects the performance on a dataset generated with Geant4. The proposed simulator generates thousands of particle showers per second on a desktop machine, a speed up of up to 6 orders of magnitudes over Geant4, and stores detailed geometric information about the shower propagation. SUPA provides much greater flexibility for setting initial conditions and defining multiple benchmarks for the development of models. Moreover, interpreting particle showers as point clouds creates a connection to geometric machine learning and provides challenging and fundamentally new datasets for the field. The code for SUPA is available at https://github.com/itsdaniele/SUPA.
Denmark's Participation in the Search Engine TREC COVID-19 Challenge: Lessons Learned about Searching for Precise Biomedical Scientific Information on COVID-19
Nov 26, 2020
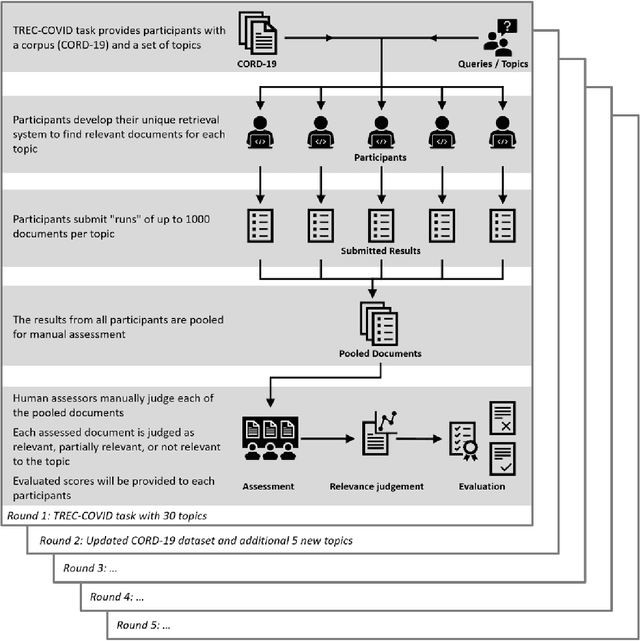
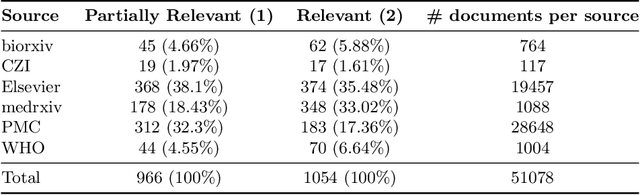
This report describes the participation of two Danish universities, University of Copenhagen and Aalborg University, in the international search engine competition on COVID-19 (the 2020 TREC-COVID Challenge) organised by the U.S. National Institute of Standards and Technology (NIST) and its Text Retrieval Conference (TREC) division. The aim of the competition was to find the best search engine strategy for retrieving precise biomedical scientific information on COVID-19 from the largest, at that point in time, dataset of curated scientific literature on COVID-19 -- the COVID-19 Open Research Dataset (CORD-19). CORD-19 was the result of a call to action to the tech community by the U.S. White House in March 2020, and was shortly thereafter posted on Kaggle as an AI competition by the Allen Institute for AI, the Chan Zuckerberg Initiative, Georgetown University's Center for Security and Emerging Technology, Microsoft, and the National Library of Medicine at the US National Institutes of Health. CORD-19 contained over 200,000 scholarly articles (of which more than 100,000 were with full text) about COVID-19, SARS-CoV-2, and related coronaviruses, gathered from curated biomedical sources. The TREC-COVID challenge asked for the best way to (a) retrieve accurate and precise scientific information, in response to some queries formulated by biomedical experts, and (b) rank this information decreasingly by its relevance to the query. In this document, we describe the TREC-COVID competition setup, our participation to it, and our resulting reflections and lessons learned about the state-of-art technology when faced with the acute task of retrieving precise scientific information from a rapidly growing corpus of literature, in response to highly specialised queries, in the middle of a pandemic.
Short-time Fourier transform based on stimulated Brillouin scattering
Nov 26, 2021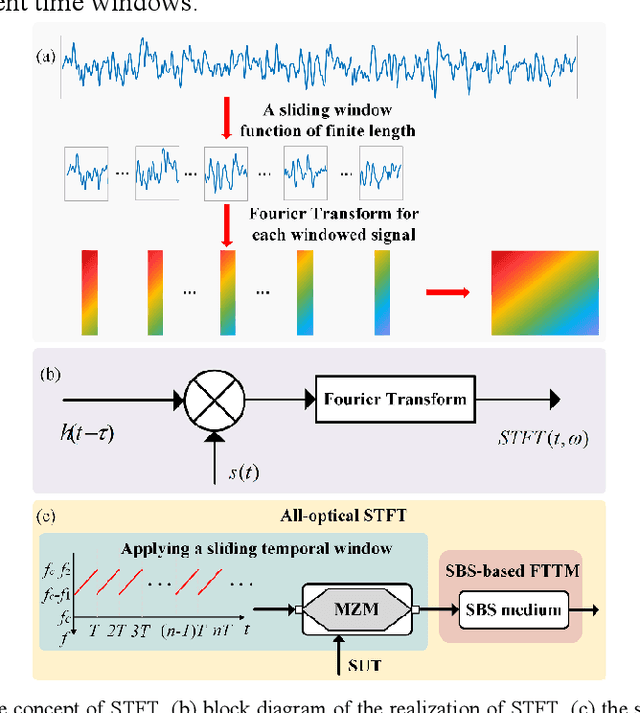
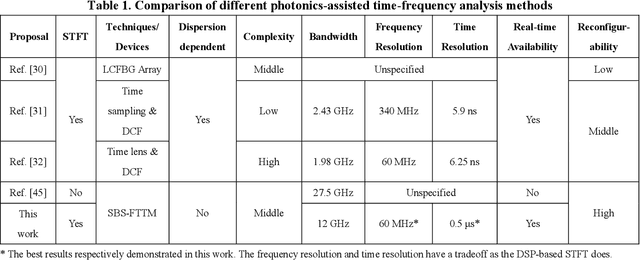
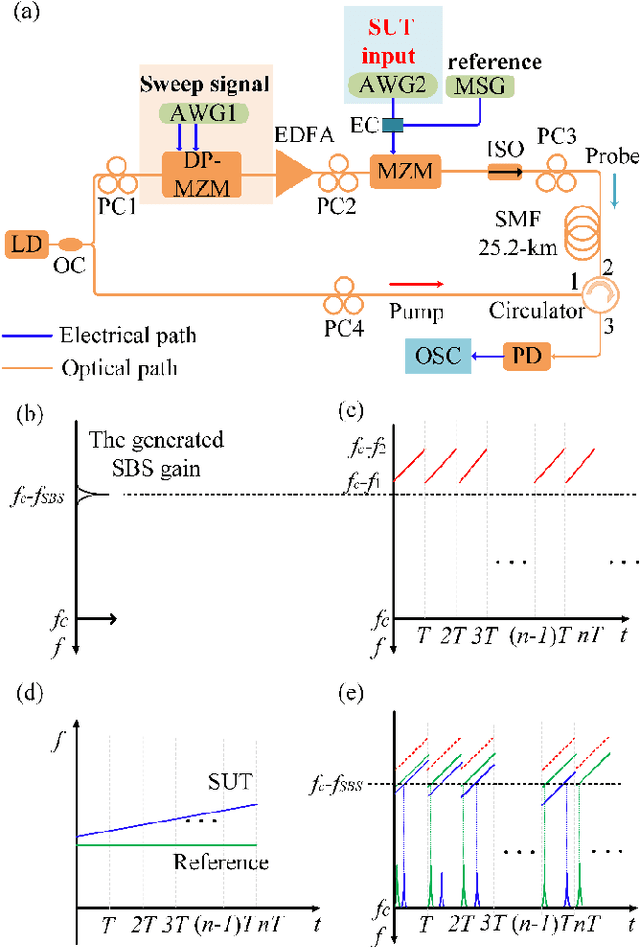
In this paper, all-optical short-time Fourier transform (STFT) based on stimulated Brillouin scattering (SBS) is proposed and further used for real-time time-frequency analysis of different radio frequency (RF) signals. In the proposed all-optical STFT system, SBS not only provides a band-pass filter for implementing the window function in conjunction with a periodic frequency-sweep optical signal but also obtains the frequency domain information in different time windows through the generated waveform via frequency-to-time mapping (FTTM). A periodic frequency-sweep optical signal is generated and then modulated at a Mach-Zehnder modulator by the electrical signal under test (SUT). During different sweep periods, the fixed Brillouin gain functions as a bandpass filter to select a specific range of the spectrum, which is equivalent to applying a sliding window function to the corresponding section of the temporal signal with the help of the sweep optical signal. At the same time, after the optical signal is selectively amplified by the SBS gain and converted back to the electrical domain, SBS also implements the real-time FTTM, which can be utilized to obtain the frequency domain information corresponding to different time windows through the generated waveforms via the FTTM. The frequency domain information corresponding to different time windows is formed and spliced to analyze the time-frequency relationship of the SUT in real-time. An experiment is performed. STFTs of a variety of RF signals are carried out in a 12-GHz bandwidth limited only by the equipment, and the dynamic frequency resolution is better than 60 MHz.
Multi-Level Attention for Unsupervised Person Re-Identification
Jan 10, 2022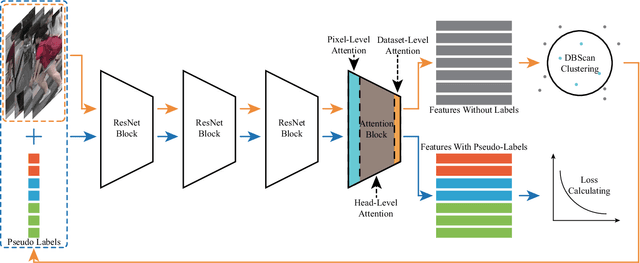

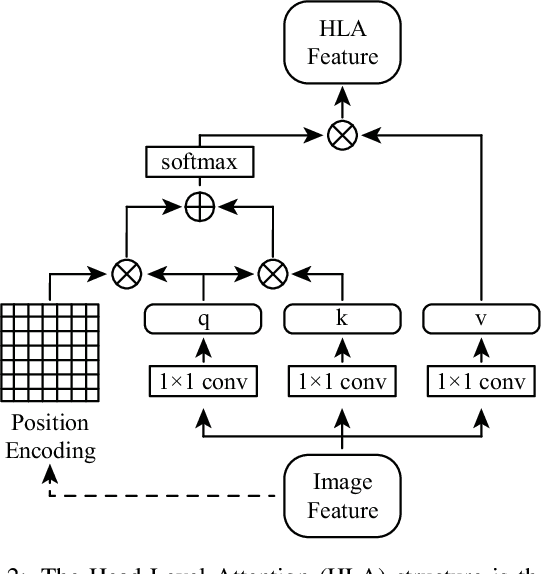
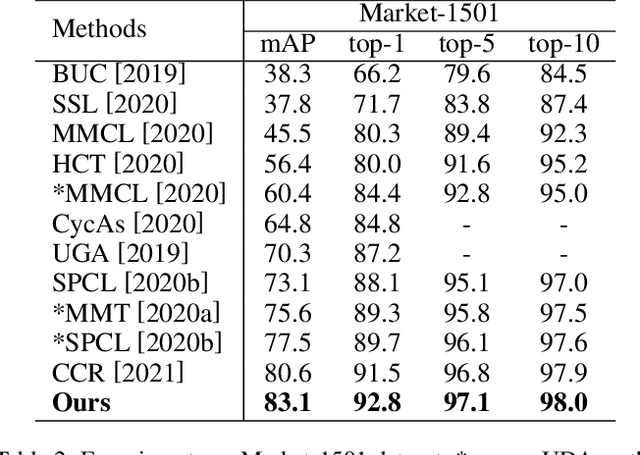
The attention mechanism is widely used in deep learning because of its excellent performance in neural networks without introducing additional information. However, in unsupervised person re-identification, the attention module represented by multi-headed self-attention suffers from attention spreading in the condition of non-ground truth. To solve this problem, we design pixel-level attention module to provide constraints for multi-headed self-attention. Meanwhile, for the trait that the identification targets of person re-identification data are all pedestrians in the samples, we design domain-level attention module to provide more comprehensive pedestrian features. We combine head-level, pixel-level and domain-level attention to propose multi-level attention block and validate its performance on for large person re-identification datasets (Market-1501, DukeMTMC-reID and MSMT17 and PersonX).