 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Infusing Sequential Information into Conditional Masked Translation Model with Self-Review Mechanism
Oct 26, 2020
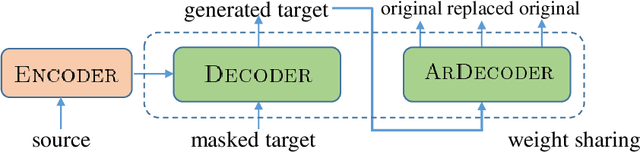
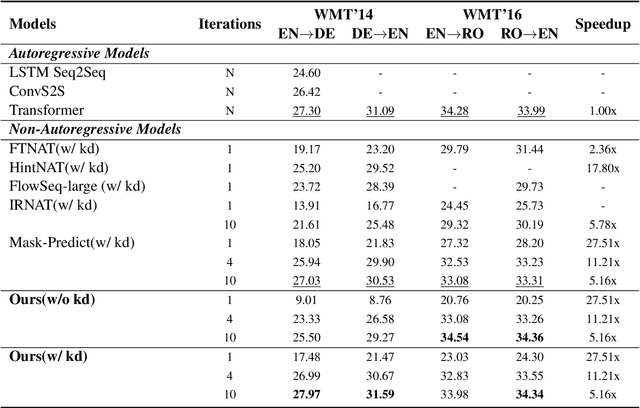
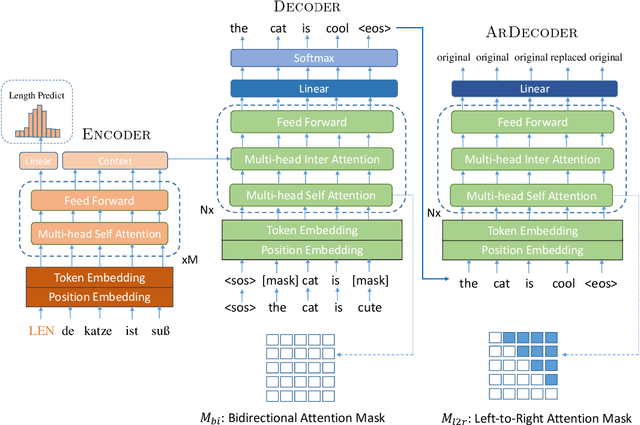
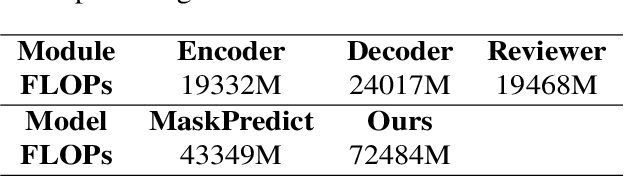
Non-autoregressive models generate target words in a parallel way, which achieve a faster decoding speed but at the sacrifice of translation accuracy. To remedy a flawed translation by non-autoregressive models, a promising approach is to train a conditional masked translation model (CMTM), and refine the generated results within several iterations. Unfortunately, such approach hardly considers the \textit{sequential dependency} among target words, which inevitably results in a translation degradation. Hence, instead of solely training a Transformer-based CMTM, we propose a Self-Review Mechanism to infuse sequential information into it. Concretely, we insert a left-to-right mask to the same decoder of CMTM, and then induce it to autoregressively review whether each generated word from CMTM is supposed to be replaced or kept. The experimental results (WMT14 En$\leftrightarrow$De and WMT16 En$\leftrightarrow$Ro) demonstrate that our model uses dramatically less training computations than the typical CMTM, as well as outperforms several state-of-the-art non-autoregressive models by over 1 BLEU. Through knowledge distillation, our model even surpasses a typical left-to-right Transformer model, while significantly speeding up decoding.
Deep Capsule Encoder-Decoder Network for Surrogate Modeling and Uncertainty Quantification
Jan 19, 2022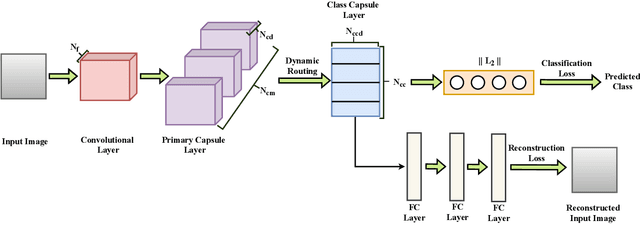
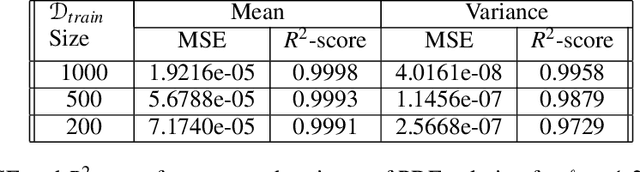
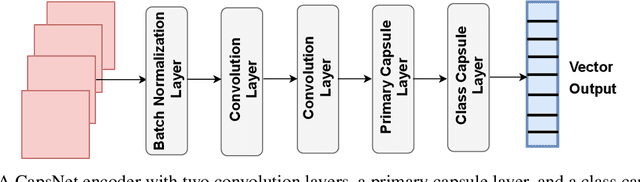
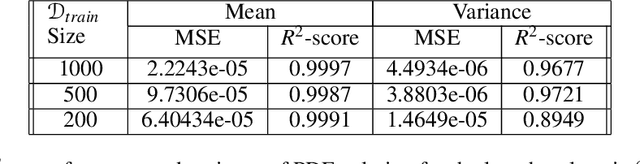
We propose a novel \textit{capsule} based deep encoder-decoder model for surrogate modeling and uncertainty quantification of systems in mechanics from sparse data. The proposed framework is developed by adapting Capsule Network (CapsNet) architecture into image-to-image regression encoder-decoder network. Specifically, the aim is to exploit the benefits of CapsNet over convolution neural network (CNN) $-$ retaining pose and position information related to an entity to name a few. The performance of proposed approach is illustrated by solving an elliptic stochastic partial differential equation (SPDE), which also governs systems in mechanics such as steady heat conduction, ground water flow or other diffusion processes, based uncertainty quantification problem with an input dimensionality of $1024$. However, the problem definition does not the restrict the random diffusion field to a particular covariance structure, and the more strenuous task of response prediction for an arbitrary diffusion field is solved. The obtained results from performance evaluation indicate that the proposed approach is accurate, efficient, and robust.
Energy-efficient Dynamic-subarray with Fixed True-time-delay Design for Terahertz Wideband Hybrid Beamforming
Feb 07, 2022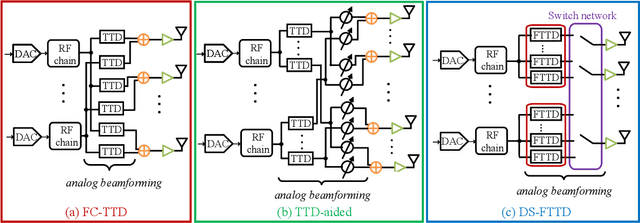
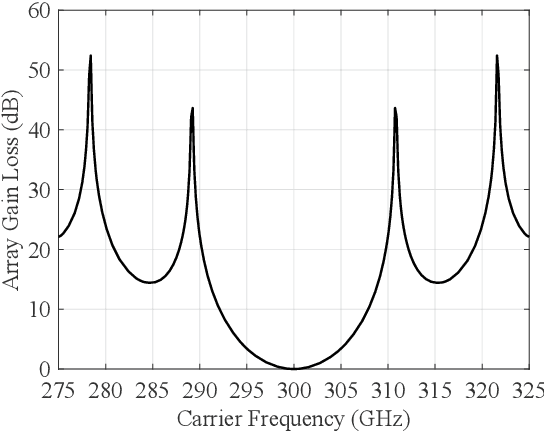
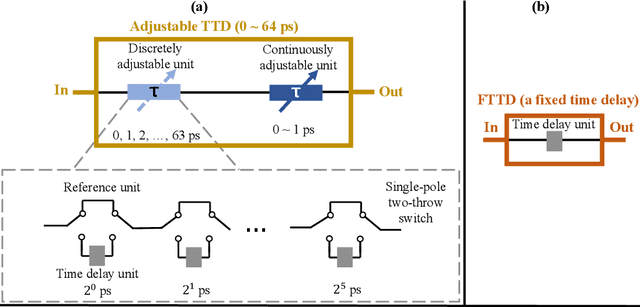
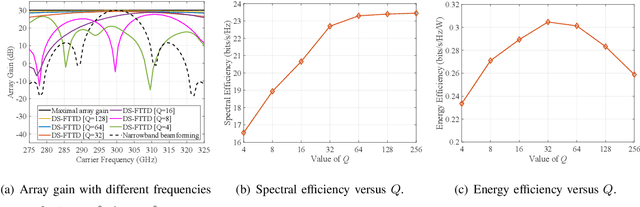
Hybrid beamforming for Terahertz (THz) ultra-massive multiple-input multiple-output (UM-MIMO) systems is a promising technology for 6G space-air-ground integrated networks, which can overcome huge propagation loss and offer unprecedented data rates. With ultra-wide bandwidth and ultra-large-scale antennas array in THz band, the beam squint becomes one of the critical problems which could reduce the array gain and degrade the data rate substantially. However, the traditional phase-shifters-based hybrid beamforming architectures cannot tackle this issue due to the frequency-flat property of the phase shifters. In this paper, to combat the beam squint while keeping high energy efficiency, a novel dynamic-subarray with fixed true-time-delay (DS-FTTD) architecture is proposed. Compared to the existing studies which use the complicated adjustable TTDs, the DS-FTTD architecture has lower power consumption and hardware complexity, thanks to the low-cost FTTDs. Furthermore, a low-complexity row-decomposition (RD) algorithm is proposed to design hybrid beamforming matrices for the DS-FTTD architecture. Extensive simulation results show that, by using the RD algorithm, the DS-FTTD architecture achieves near-optimal array gain and significantly higher energy efficiency than the existing architectures. Moreover, the spectral efficiency of DS-FTTD architecture with the RD algorithm is robust to the imperfect channel state information.
Improving Location Recommendation with Urban Knowledge Graph
Nov 01, 2021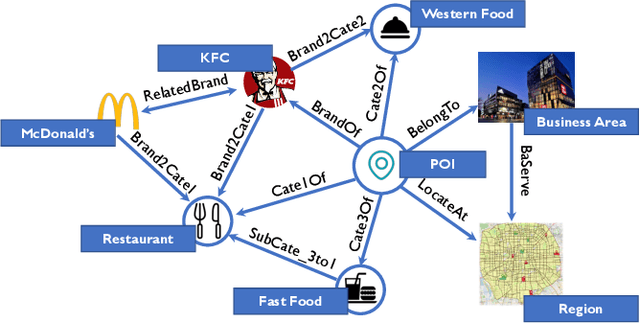
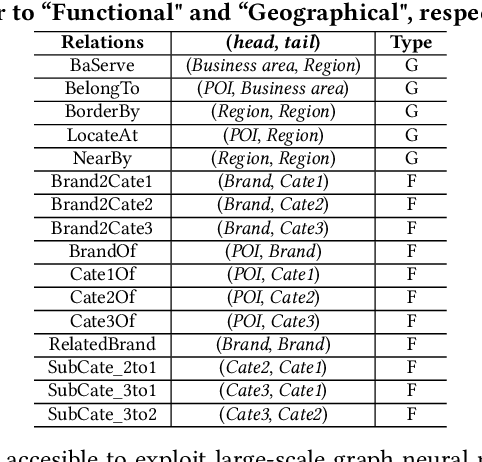
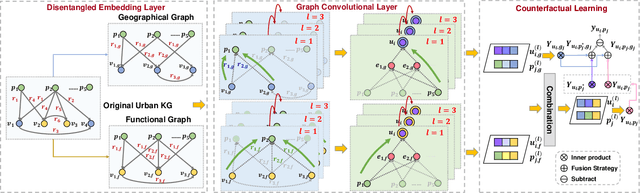
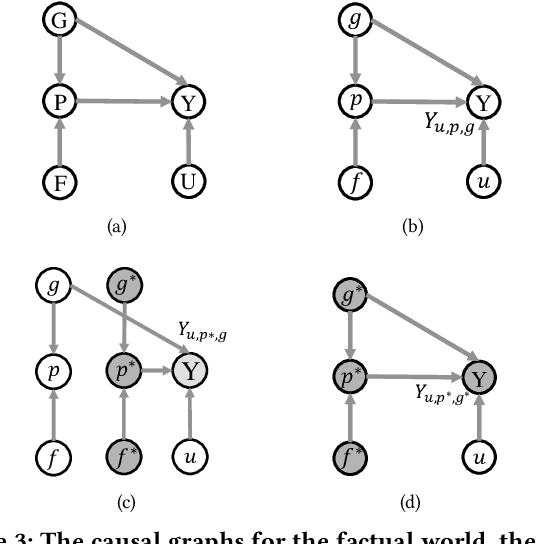
Location recommendation is defined as to recommend locations (POIs) to users in location-based services. The existing data-driving approaches of location recommendation suffer from the limitation of the implicit modeling of the geographical factor, which may lead to sub-optimal recommendation results. In this work, we address this problem by introducing knowledge-driven solutions. Specifically, we first construct the Urban Knowledge Graph (UrbanKG) with geographical information and functional information of POIs. On the other side, there exist a fact that the geographical factor not only characterizes POIs but also affects user-POI interactions. To address it, we propose a novel method named UKGC. We first conduct information propagation on two sub-graphs to learn the representations of POIs and users. We then fuse two parts of representations by counterfactual learning for the final prediction. Extensive experiments on two real-world datasets verify that our method can outperform the state-of-the-art methods.
Uformer: A Unet based dilated complex & real dual-path conformer network for simultaneous speech enhancement and dereverberation
Nov 11, 2021
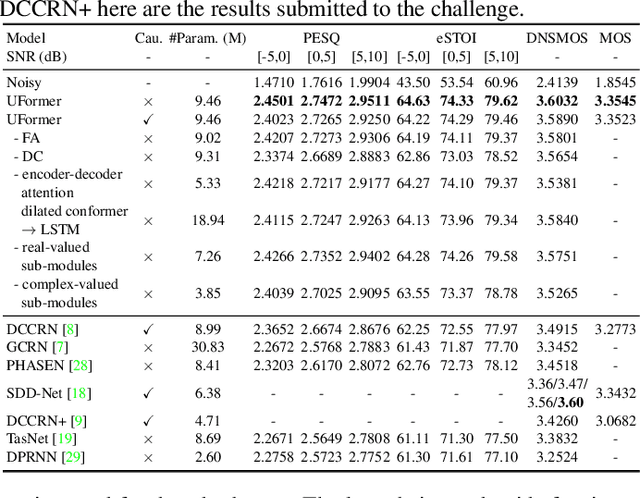
Complex spectrum and magnitude are considered as two major features of speech enhancement and dereverberation. Traditional approaches always treat these two features separately, ignoring their underlying relationship. In this paper, we proposem Uformer, a Unet based dilated complex & real dual-path conformer network in both complex and magnitude domain for simultaneous speech enhancement and dereverberation. We exploit time attention (TA) and dilated convolution (DC) to leverage local and global contextual information and frequency attention (FA) to model dimensional information. These three sub-modules contained in the proposed dilated complex & real dual-path conformer module effectively improve the speech enhancement and dereverberation performance. Furthermore, hybrid encoder and decoder are adopted to simultaneously model the complex spectrum and magnitude and promote the information interaction between two domains. Encoder decoder attention is also applied to enhance the interaction between encoder and decoder. Our experimental results outperform all SOTA time and complex domain models objectively and subjectively. Specifically, Uformer reaches 3.6032 DNSMOS on the blind test set of Interspeech 2021 DNS Challenge, which outperforms all top-performed models. We also carry out ablation experiments to tease apart all proposed sub-modules that are most important.
GRAPHSHAP: Motif-based Explanations for Black-box Graph Classifiers
Feb 17, 2022
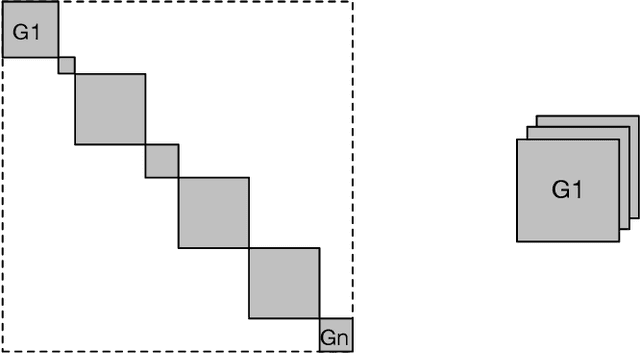
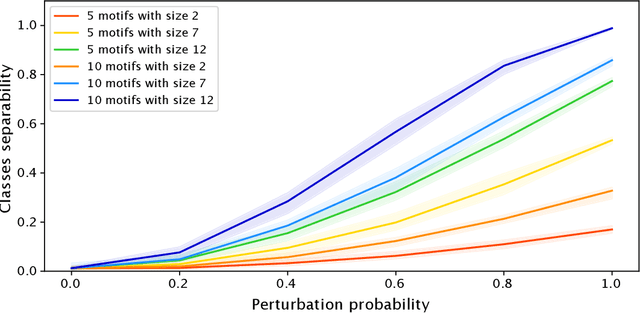
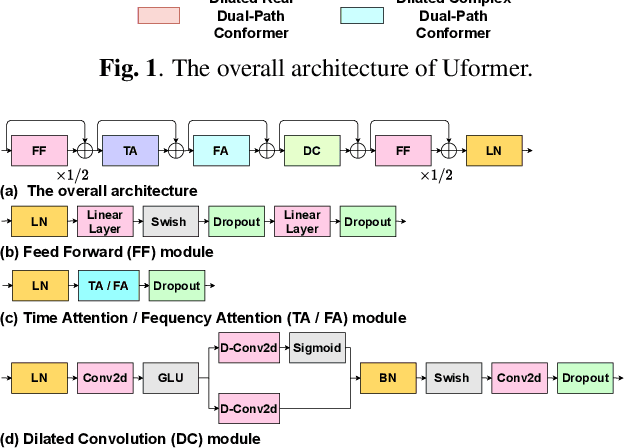
Most methods for explaining black-box classifiers (e.g., on tabular data, images, or time series) rely on measuring the impact that the removal/perturbation of features has on the model output. This forces the explanation language to match the classifier features space. However, when dealing with graph data, in which the basic features correspond essentially to the adjacency information describing the graph structure (i.e., the edges), this matching between features space and explanation language might not be appropriate. In this regard, we argue that (i) a good explanation method for graph classification should be fully agnostic with respect to the internal representation used by the black-box; and (ii) a good explanation language for graph classification tasks should be represented by higher-order structures, such as motifs. The need to decouple the feature space (edges) from the explanation space (motifs) is thus a major challenge towards developing actionable explanations for graph classification tasks. In this paper we introduce GRAPHSHAP, a Shapley-based approach able to provide motif-based explanations for black-box graph classifiers, assuming no knowledge whatsoever about the model or its training data: the only requirement is that the black-box can be queried at will. Furthermore, we introduce additional auxiliary components such as a synthetic graph dataset generator, algorithms for subgraph mining and ranking, a custom graph convolutional layer, and a kernel to approximate the explanation scores while maintaining linear time complexity. Finally, we test GRAPHSHAP on a real-world brain-network dataset consisting of patients affected by Autism Spectrum Disorder and a control group. Our experiments highlight how the classification provided by a black-box model can be effectively explained by few connectomics patterns.
Learning Stochastic Graph Neural Networks with Constrained Variance
Jan 29, 2022
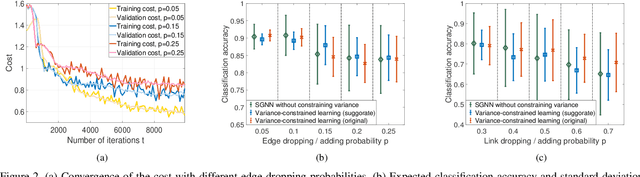
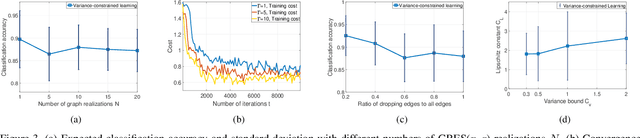
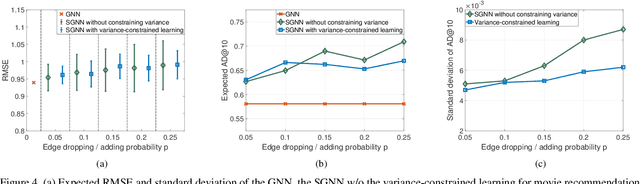
Stochastic graph neural networks (SGNNs) are information processing architectures that learn representations from data over random graphs. SGNNs are trained with respect to the expected performance, which comes with no guarantee about deviations of particular output realizations around the optimal expectation. To overcome this issue, we propose a variance-constrained optimization problem for SGNNs, balancing the expected performance and the stochastic deviation. An alternating primal-dual learning procedure is undertaken that solves the problem by updating the SGNN parameters with gradient descent and the dual variable with gradient ascent. To characterize the explicit effect of the variance-constrained learning, we conduct a theoretical analysis on the variance of the SGNN output and identify a trade-off between the stochastic robustness and the discrimination power. We further analyze the duality gap of the variance-constrained optimization problem and the converging behavior of the primal-dual learning procedure. The former indicates the optimality loss induced by the dual transformation and the latter characterizes the limiting error of the iterative algorithm, both of which guarantee the performance of the variance-constrained learning. Through numerical simulations, we corroborate our theoretical findings and observe a strong expected performance with a controllable standard deviation.
Powerful Graph Convolutioal Networks with Adaptive Propagation Mechanism for Homophily and Heterophily
Dec 27, 2021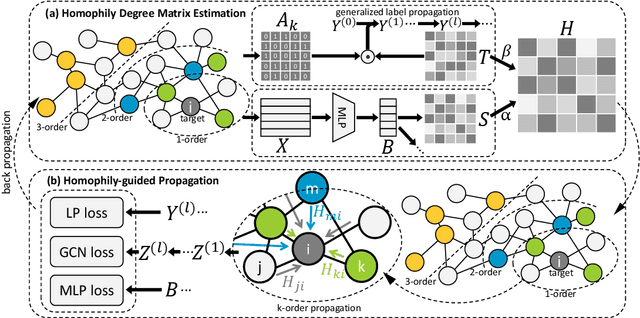
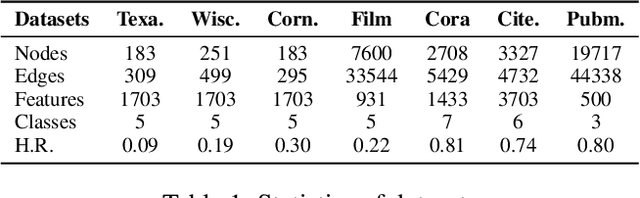
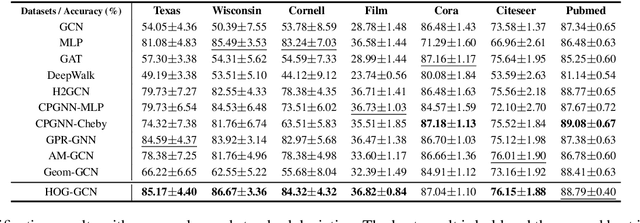

Graph Convolutional Networks (GCNs) have been widely applied in various fields due to their significant power on processing graph-structured data. Typical GCN and its variants work under a homophily assumption (i.e., nodes with same class are prone to connect to each other), while ignoring the heterophily which exists in many real-world networks (i.e., nodes with different classes tend to form edges). Existing methods deal with heterophily by mainly aggregating higher-order neighborhoods or combing the immediate representations, which leads to noise and irrelevant information in the result. But these methods did not change the propagation mechanism which works under homophily assumption (that is a fundamental part of GCNs). This makes it difficult to distinguish the representation of nodes from different classes. To address this problem, in this paper we design a novel propagation mechanism, which can automatically change the propagation and aggregation process according to homophily or heterophily between node pairs. To adaptively learn the propagation process, we introduce two measurements of homophily degree between node pairs, which is learned based on topological and attribute information, respectively. Then we incorporate the learnable homophily degree into the graph convolution framework, which is trained in an end-to-end schema, enabling it to go beyond the assumption of homophily. More importantly, we theoretically prove that our model can constrain the similarity of representations between nodes according to their homophily degree. Experiments on seven real-world datasets demonstrate that this new approach outperforms the state-of-the-art methods under heterophily or low homophily, and gains competitive performance under homophily.
Mitigating Leakage from Data Dependent Communications in Decentralized Computing using Differential Privacy
Dec 23, 2021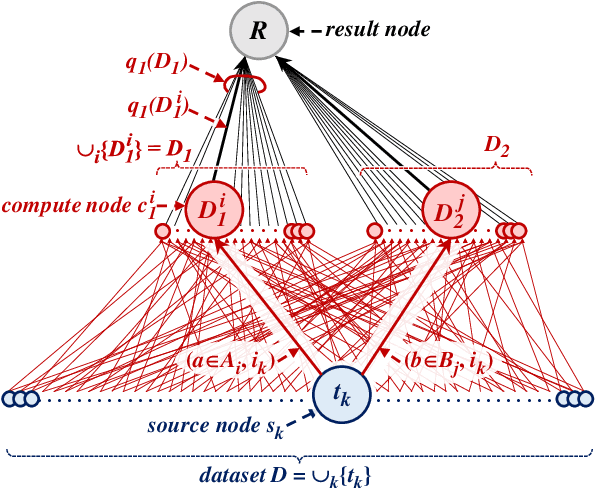
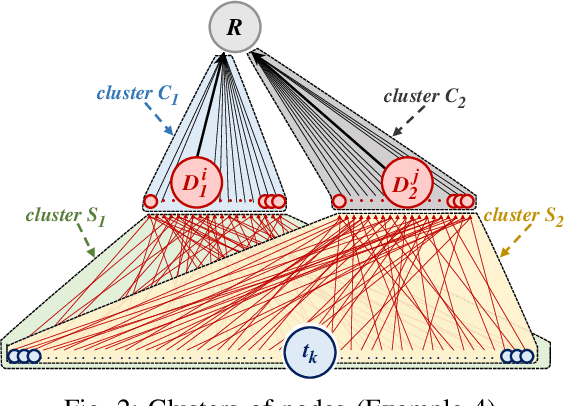
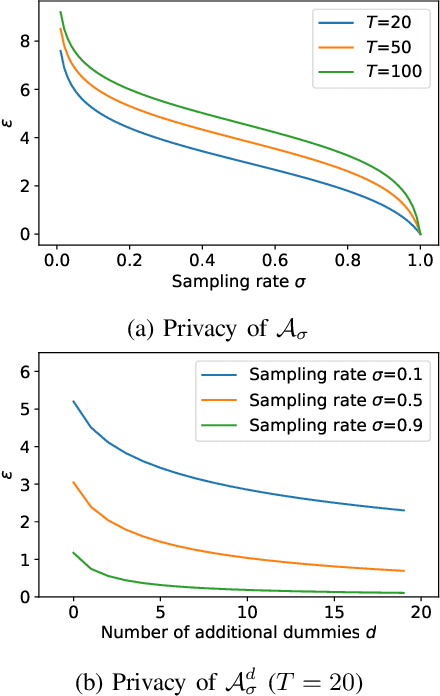
Imagine a group of citizens willing to collectively contribute their personal data for the common good to produce socially useful information, resulting from data analytics or machine learning computations. Sharing raw personal data with a centralized server performing the computation could raise concerns about privacy and a perceived risk of mass surveillance. Instead, citizens may trust each other and their own devices to engage into a decentralized computation to collaboratively produce an aggregate data release to be shared. In the context of secure computing nodes exchanging messages over secure channels at runtime, a key security issue is to protect against external attackers observing the traffic, whose dependence on data may reveal personal information. Existing solutions are designed for the cloud setting, with the goal of hiding all properties of the underlying dataset, and do not address the specific privacy and efficiency challenges that arise in the above context. In this paper, we define a general execution model to control the data-dependence of communications in user-side decentralized computations, in which differential privacy guarantees for communication patterns in global execution plans can be analyzed by combining guarantees obtained on local clusters of nodes. We propose a set of algorithms which allow to trade-off between privacy, utility and efficiency. Our formal privacy guarantees leverage and extend recent results on privacy amplification by shuffling. We illustrate the usefulness of our proposal on two representative examples of decentralized execution plans with data-dependent communications.
User Satisfaction Estimation with Sequential Dialogue Act Modeling in Goal-oriented Conversational Systems
Feb 07, 2022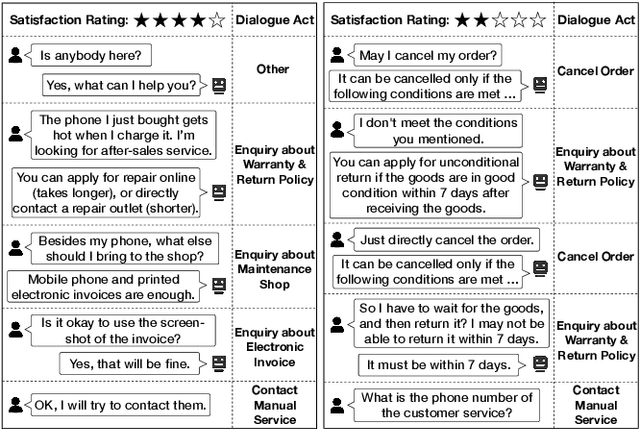
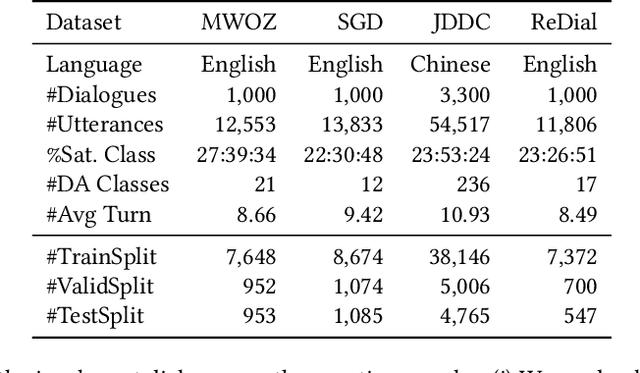
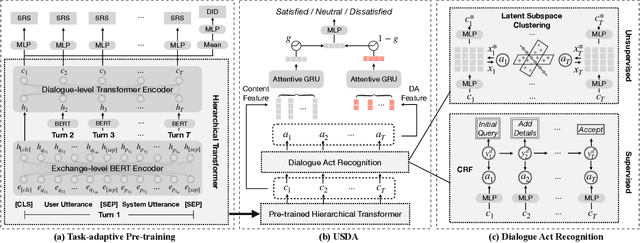
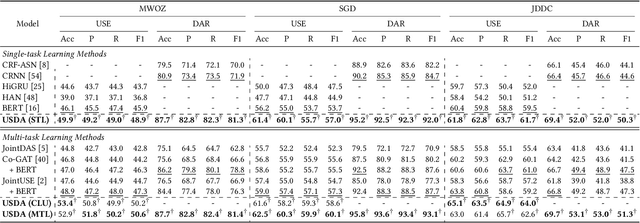
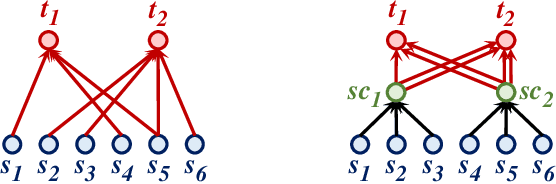
User Satisfaction Estimation (USE) is an important yet challenging task in goal-oriented conversational systems. Whether the user is satisfied with the system largely depends on the fulfillment of the user's needs, which can be implicitly reflected by users' dialogue acts. However, existing studies often neglect the sequential transitions of dialogue act or rely heavily on annotated dialogue act labels when utilizing dialogue acts to facilitate USE. In this paper, we propose a novel framework, namely USDA, to incorporate the sequential dynamics of dialogue acts for predicting user satisfaction, by jointly learning User Satisfaction Estimation and Dialogue Act Recognition tasks. In specific, we first employ a Hierarchical Transformer to encode the whole dialogue context, with two task-adaptive pre-training strategies to be a second-phase in-domain pre-training for enhancing the dialogue modeling ability. In terms of the availability of dialogue act labels, we further develop two variants of USDA to capture the dialogue act information in either supervised or unsupervised manners. Finally, USDA leverages the sequential transitions of both content and act features in the dialogue to predict the user satisfaction. Experimental results on four benchmark goal-oriented dialogue datasets across different applications show that the proposed method substantially and consistently outperforms existing methods on USE, and validate the important role of dialogue act sequences in USE.