 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neural Network Compression of ACAS Xu is Unsafe: Closed-Loop Verification through Quantized State Backreachability
Jan 26, 2022
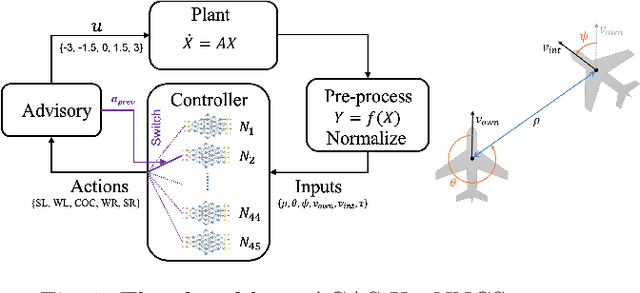
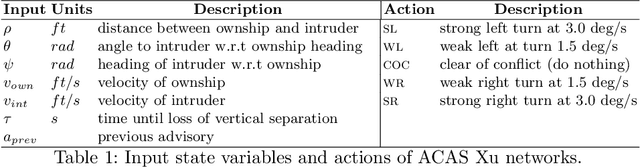
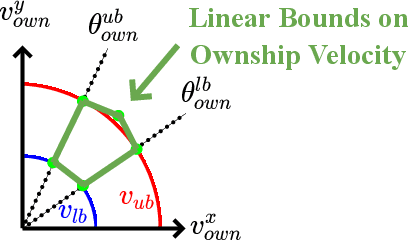
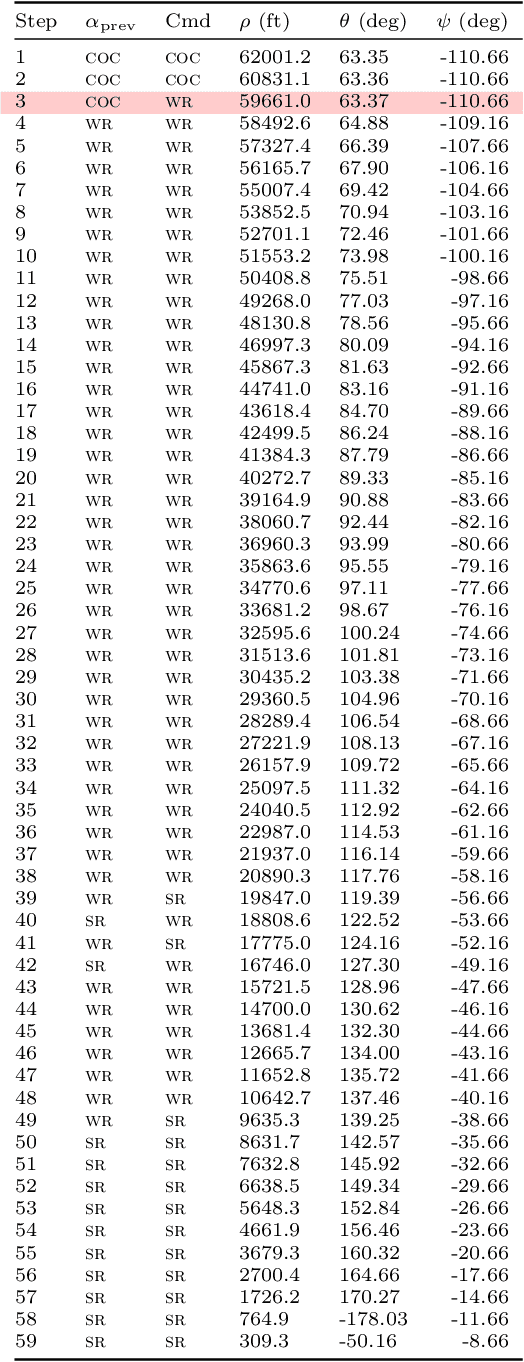
ACAS Xu is an air-to-air collision avoidance system designed for unmanned aircraft that issues horizontal turn advisories to avoid an intruder aircraft. Due the use of a large lookup table in the design, a neural network compression of the policy was proposed. Analysis of this system has spurred a significant body of research in the formal methods community on neural network verification. While many powerful methods have been developed, most work focuses on open-loop properties of the networks, rather than the main point of the system -- collision avoidance -- which requires closed-loop analysis. In this work, we develop a technique to verify a closed-loop approximation of ACAS Xu using state quantization and backreachability. We use favorable assumptions for the analysis -- perfect sensor information, instant following of advisories, ideal aircraft maneuvers and an intruder that only flies straight. When the method fails to prove the system is safe, we refine the quantization parameters until generating counterexamples where the original (non-quantized) system also has collisions.
Statistical and Spatio-temporal Hand Gesture Features for Sign Language Recognition using the Leap Motion Sensor
Feb 22, 2022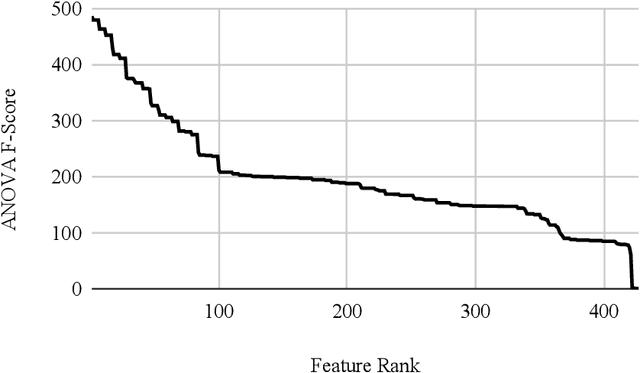
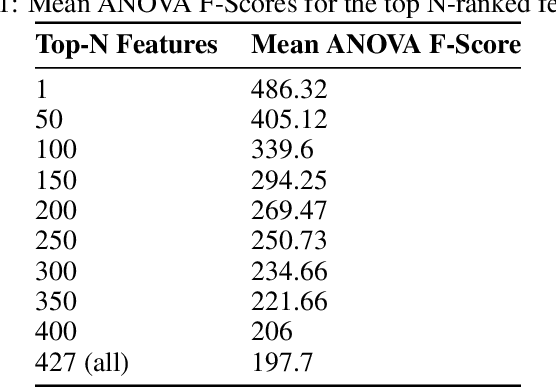
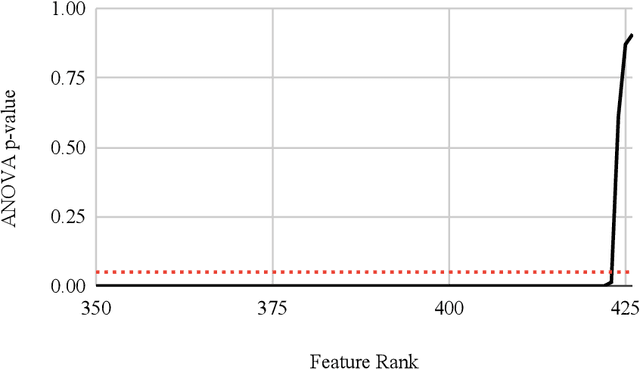
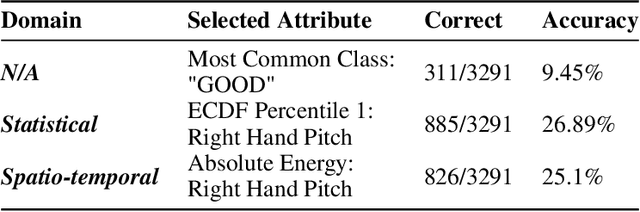
In modern society, people should not be identified based on their disability, rather, it is environments that can disable people with impairments. Improvements to automatic Sign Language Recognition (SLR) will lead to more enabling environments via digital technology. Many state-of-the-art approaches to SLR focus on the classification of static hand gestures, but communication is a temporal activity, which is reflected by many of the dynamic gestures present. Given this, temporal information during the delivery of a gesture is not often considered within SLR. The experiments in this work consider the problem of SL gesture recognition regarding how dynamic gestures change during their delivery, and this study aims to explore how single types of features as well as mixed features affect the classification ability of a machine learning model. 18 common gestures recorded via a Leap Motion Controller sensor provide a complex classification problem. Two sets of features are extracted from a 0.6 second time window, statistical descriptors and spatio-temporal attributes. Features from each set are compared by their ANOVA F-Scores and p-values, arranged into bins grown by 10 features per step to a limit of the 250 highest-ranked features. Results show that the best statistical model selected 240 features and scored 85.96% accuracy, the best spatio-temporal model selected 230 features and scored 80.98%, and the best mixed-feature model selected 240 features from each set leading to a classification accuracy of 86.75%. When all three sets of results are compared (146 individual machine learning models), the overall distribution shows that the minimum results are increased when inputs are any number of mixed features compared to any number of either of the two single sets of features.
Augmenting Neural Differential Equations to Model Unknown Dynamical Systems with Incomplete State Information
Aug 20, 2020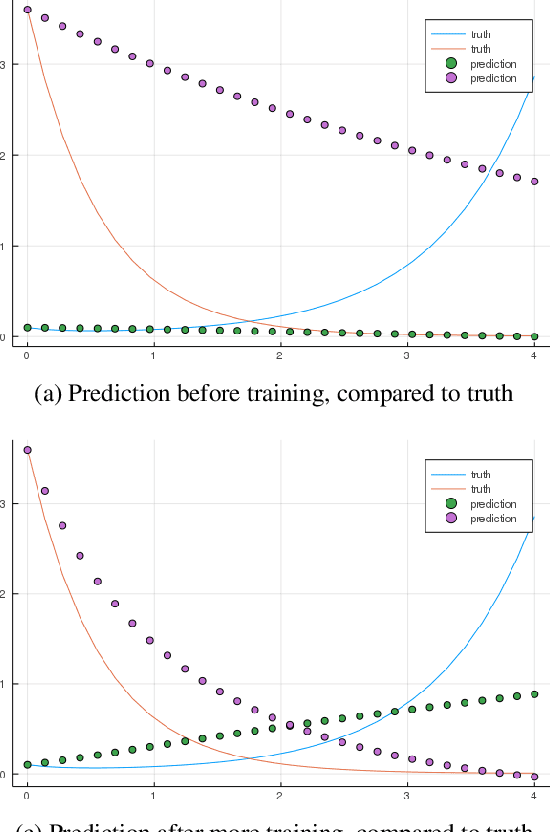
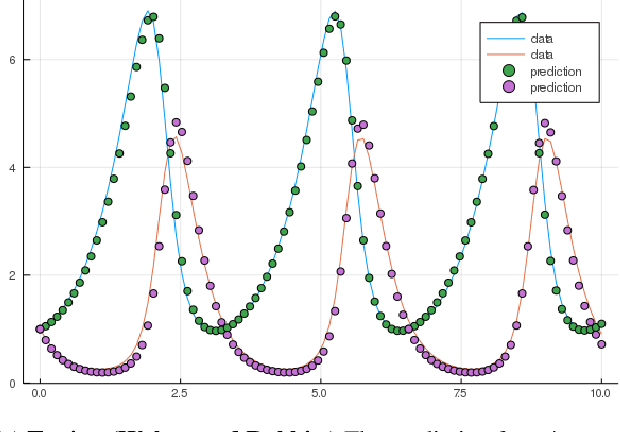
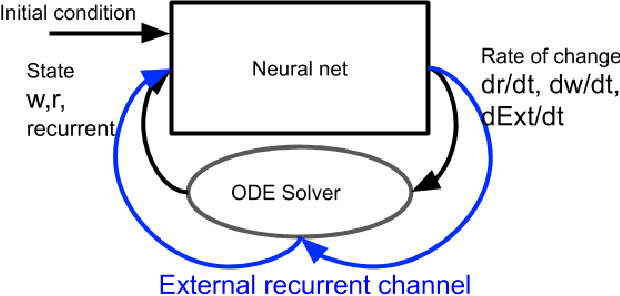
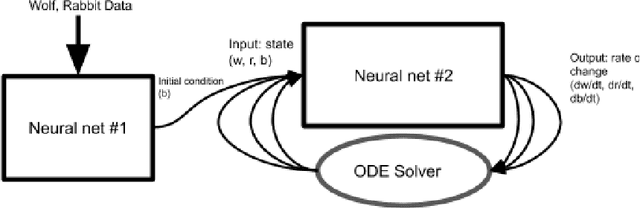
Neural Ordinary Differential Equations replace the right-hand side of a conventional ODE with a neural net, which by virtue of the universal approximation theorem, can be trained to the representation of any function. When we do not know the function itself, but have state trajectories (time evolution) of the ODE system we can still train the neural net to learn the representation of the underlying but unknown ODE. However if the state of the system is incompletely known then the right-hand side of the ODE cannot be calculated. The derivatives to propagate the system are unavailable. We show that a specially augmented Neural ODE can learn the system when given incomplete state information. As a worked example we apply neural ODEs to the Lotka-Voltera problem of 3 species, rabbits, wolves, and bears. We show that even when the data for the bear time series is removed the remaining time series of the rabbits and wolves is sufficient to learn the dynamical system despite the missing the incomplete state information. This is surprising since a conventional ODE system cannot output the correct derivatives without the full state as the input. We implement augmented neural ODEs and differential equation solvers in the julia programming language.
Rank-based loss for learning hierarchical representations
Oct 11, 2021
Hierarchical taxonomies are common in many contexts, and they are a very natural structure humans use to organise information. In machine learning, the family of methods that use the 'extra' information is called hierarchical classification. However, applied to audio classification, this remains relatively unexplored. Here we focus on how to integrate the hierarchical information of a problem to learn embeddings representative of the hierarchical relationships. Previously, triplet loss has been proposed to address this problem, however it presents some issues like requiring the careful construction of the triplets, and being limited in the extent of hierarchical information it uses at each iteration. In this work we propose a rank based loss function that uses hierarchical information and translates this into a rank ordering of target distances between the examples. We show that rank based loss is suitable to learn hierarchical representations of the data. By testing on unseen fine level classes we show that this method is also capable of learning hierarchically correct representations of the new classes. Rank based loss has two promising aspects, it is generalisable to hierarchies with any number of levels, and is capable of dealing with data with incomplete hierarchical labels.
GLocal: Global Graph Reasoning and Local Structure Transfer for Person Image Generation
Dec 01, 2021
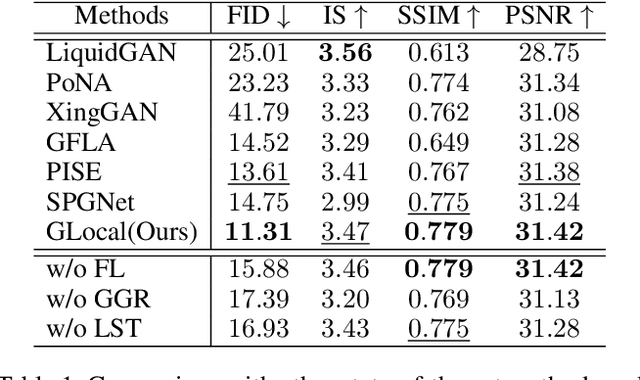
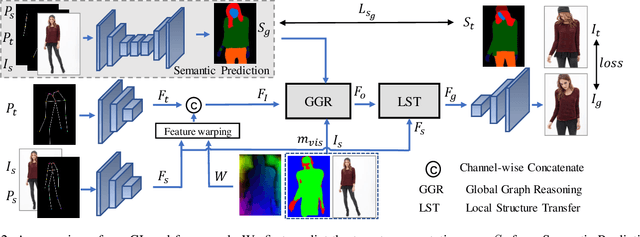
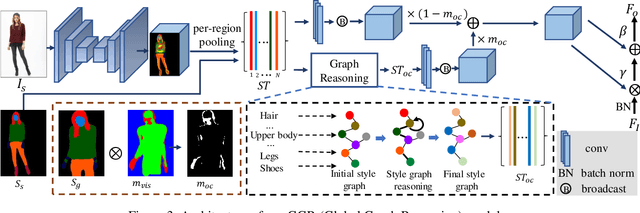
In this paper, we focus on person image generation, namely, generating person image under various conditions, e.g., corrupted texture or different pose. To address texture occlusion and large pose misalignment in this task, previous works just use the corresponding region's style to infer the occluded area and rely on point-wise alignment to reorganize the context texture information, lacking the ability to globally correlate the region-wise style codes and preserve the local structure of the source. To tackle these problems, we present a GLocal framework to improve the occlusion-aware texture estimation by globally reasoning the style inter-correlations among different semantic regions, which can also be employed to recover the corrupted images in texture inpainting. For local structural information preservation, we further extract the local structure of the source image and regain it in the generated image via local structure transfer. We benchmark our method to fully characterize its performance on DeepFashion dataset and present extensive ablation studies that highlight the novelty of our method.
Two Wrongs Don't Make a Right: Combating Confirmation Bias in Learning with Label Noise
Dec 06, 2021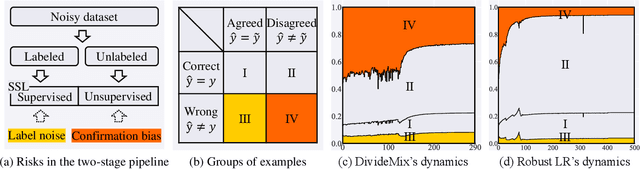
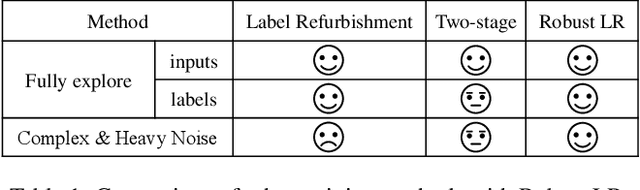
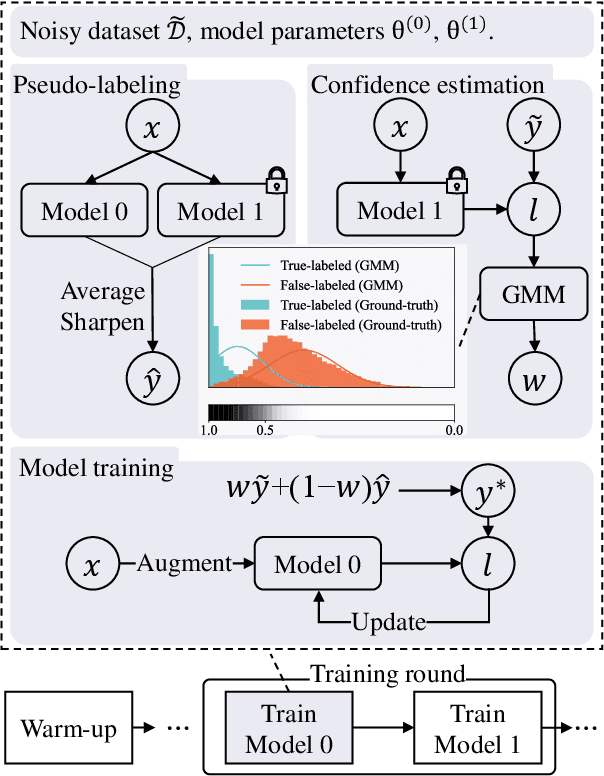
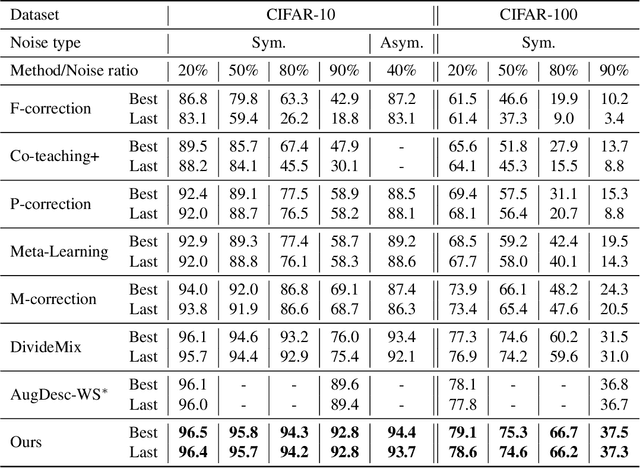
Noisy labels damage the performance of deep networks. For robust learning, a prominent two-stage pipeline alternates between eliminating possible incorrect labels and semi-supervised training. However, discarding part of observed labels could result in a loss of information, especially when the corruption is not completely random, e.g., class-dependent or instance-dependent. Moreover, from the training dynamics of a representative two-stage method DivideMix, we identify the domination of confirmation bias: Pseudo-labels fail to correct a considerable amount of noisy labels and consequently, the errors accumulate. To sufficiently exploit information from observed labels and mitigate wrong corrections, we propose Robust Label Refurbishment (Robust LR)-a new hybrid method that integrates pseudo-labeling and confidence estimation techniques to refurbish noisy labels. We show that our method successfully alleviates the damage of both label noise and confirmation bias. As a result, it achieves state-of-the-art results across datasets and noise types. For example, Robust LR achieves up to 4.5% absolute top-1 accuracy improvement over the previous best on the real-world noisy dataset WebVision.
Contextualize differential privacy in image database: a lightweight image differential privacy approach based on principle component analysis inverse
Feb 19, 2022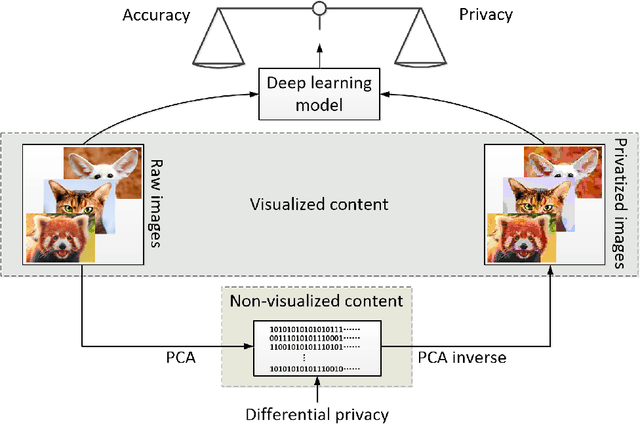


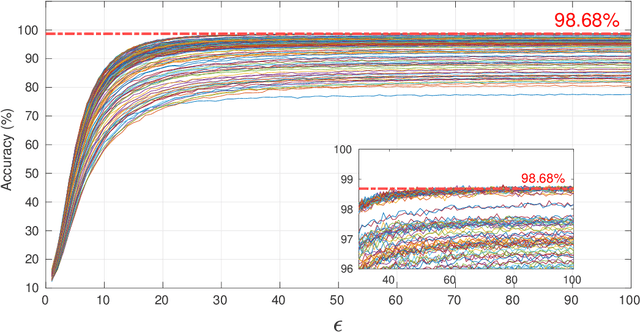
Differential privacy (DP) has been the de-facto standard to preserve privacy-sensitive information in database. Nevertheless, there lacks a clear and convincing contextualization of DP in image database, where individual images' indistinguishable contribution to a certain analysis can be achieved and observed when DP is exerted. As a result, the privacy-accuracy trade-off due to integrating DP is insufficiently demonstrated in the context of differentially-private image database. This work aims at contextualizing DP in image database by an explicit and intuitive demonstration of integrating conceptional differential privacy with images. To this end, we design a lightweight approach dedicating to privatizing image database as a whole and preserving the statistical semantics of the image database to an adjustable level, while making individual images' contribution to such statistics indistinguishable. The designed approach leverages principle component analysis (PCA) to reduce the raw image with large amount of attributes to a lower dimensional space whereby DP is performed, so as to decrease the DP load of calculating sensitivity attribute-by-attribute. The DP-exerted image data, which is not visible in its privatized format, is visualized through PCA inverse such that both a human and machine inspector can evaluate the privatization and quantify the privacy-accuracy trade-off in an analysis on the privatized image database. Using the devised approach, we demonstrate the contextualization of DP in images by two use cases based on deep learning models, where we show the indistinguishability of individual images induced by DP and the privatized images' retention of statistical semantics in deep learning tasks, which is elaborated by quantitative analyses on the privacy-accuracy trade-off under different privatization settings.
Recognizing Vector Graphics without Rasterization
Nov 12, 2021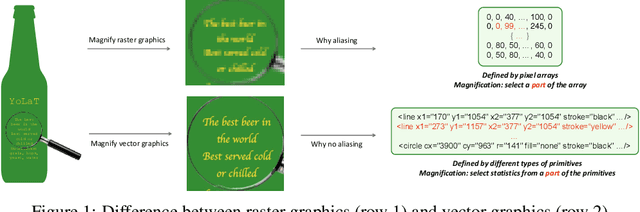
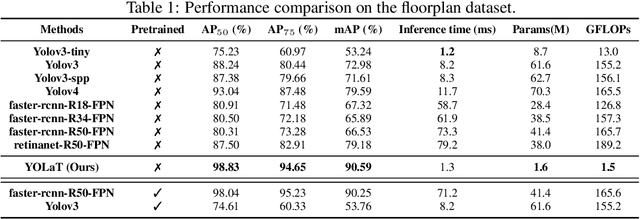
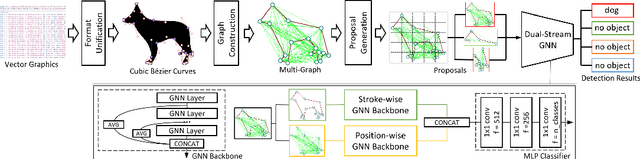
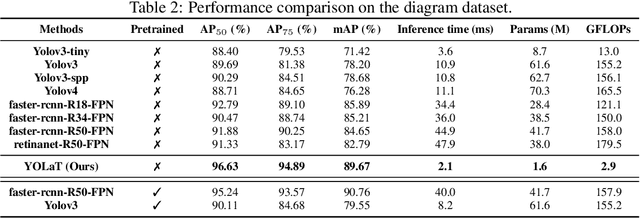
In this paper, we consider a different data format for images: vector graphics. In contrast to raster graphics which are widely used in image recognition, vector graphics can be scaled up or down into any resolution without aliasing or information loss, due to the analytic representation of the primitives in the document. Furthermore, vector graphics are able to give extra structural information on how low-level elements group together to form high level shapes or structures. These merits of graphic vectors have not been fully leveraged in existing methods. To explore this data format, we target on the fundamental recognition tasks: object localization and classification. We propose an efficient CNN-free pipeline that does not render the graphic into pixels (i.e. rasterization), and takes textual document of the vector graphics as input, called YOLaT (You Only Look at Text). YOLaT builds multi-graphs to model the structural and spatial information in vector graphics, and a dual-stream graph neural network is proposed to detect objects from the graph. Our experiments show that by directly operating on vector graphics, YOLaT out-performs raster-graphic based object detection baselines in terms of both average precision and efficiency.
Video-based Facial Micro-Expression Analysis: A Survey of Datasets, Features and Algorithms
Feb 16, 2022
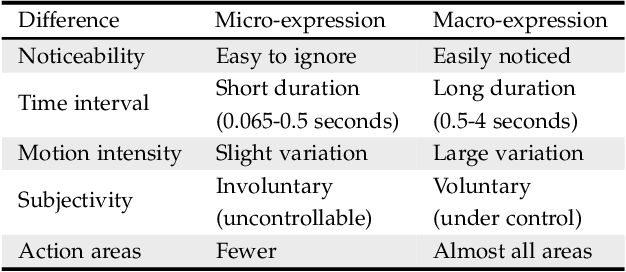
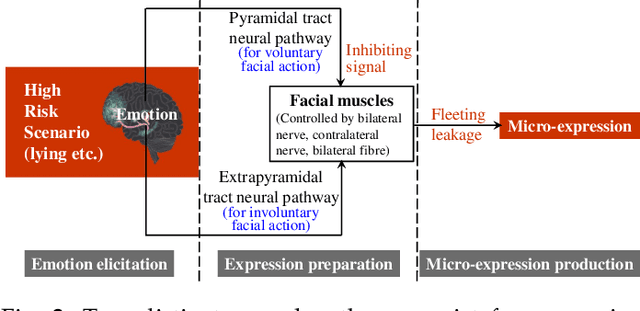
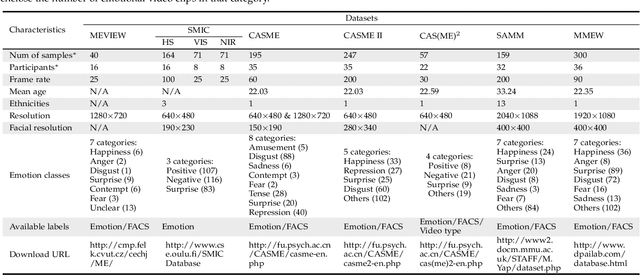
Unlike the conventional facial expressions, micro-expressions are involuntary and transient facial expressions capable of revealing the genuine emotions that people attempt to hide. Therefore, they can provide important information in a broad range of applications such as lie detection, criminal detection, etc. Since micro-expressions are transient and of low intensity, however, their detection and recognition is difficult and relies heavily on expert experiences. Due to its intrinsic particularity and complexity, video-based micro-expression analysis is attractive but challenging, and has recently become an active area of research. Although there have been numerous developments in this area, thus far there has been no comprehensive survey that provides researchers with a systematic overview of these developments with a unified evaluation. Accordingly, in this survey paper, we first highlight the key differences between macro- and micro-expressions, then use these differences to guide our research survey of video-based micro-expression analysis in a cascaded structure, encompassing the neuropsychological basis, datasets, features, spotting algorithms, recognition algorithms, applications and evaluation of state-of-the-art approaches. For each aspect, the basic techniques, advanced developments and major challenges are addressed and discussed. Furthermore, after considering the limitations of existing micro-expression datasets, we present and release a new dataset - called micro-and-macro expression warehouse (MMEW) - containing more video samples and more labeled emotion types. We then perform a unified comparison of representative methods on CAS(ME)2 for spotting, and on MMEW and SAMM for recognition, respectively. Finally, some potential future research directions are explored and outlined.
A Mini-Block Natural Gradient Method for Deep Neural Networks
Feb 08, 2022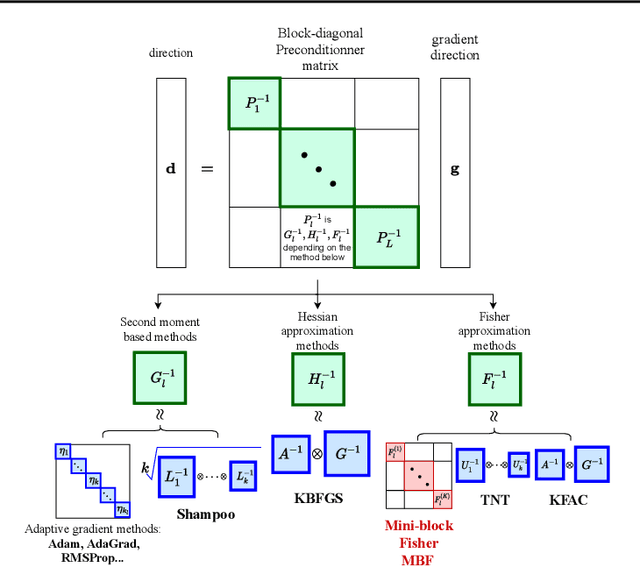
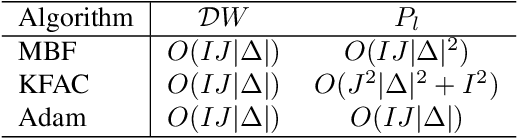
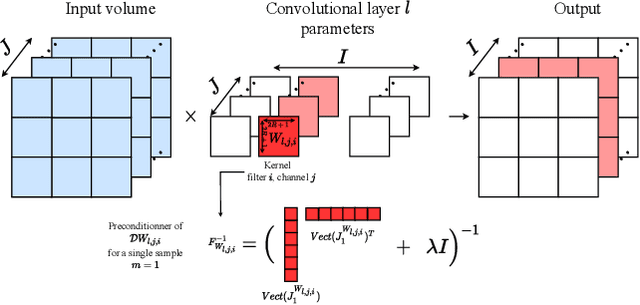

The training of deep neural networks (DNNs) is currently predominantly done using first-order methods. Some of these methods (e.g., Adam, AdaGrad, and RMSprop, and their variants) incorporate a small amount of curvature information by using a diagonal matrix to precondition the stochastic gradient. Recently, effective second-order methods, such as KFAC, K-BFGS, Shampoo, and TNT, have been developed for training DNNs, by preconditioning the stochastic gradient by layer-wise block-diagonal matrices. Here we propose and analyze the convergence of an approximate natural gradient method, mini-block Fisher (MBF), that lies in between these two classes of methods. Specifically, our method uses a block-diagonal approximation to the Fisher matrix, where for each layer in the DNN, whether it is convolutional or feed-forward and fully connected, the associated diagonal block is also block-diagonal and is composed of a large number of mini-blocks of modest size. Our novel approach utilizes the parallelism of GPUs to efficiently perform computations on the large number of matrices in each layer. Consequently, MBF's per-iteration computational cost is only slightly higher than it is for first-order methods. Finally, the performance of our proposed method is compared to that of several baseline methods, on both Auto-encoder and CNN problems, to validate its effectiveness both in terms of time efficiency and generalization power.