 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Clinical Trial Outcome Prediction with Large Language Models
Feb 09, 2024
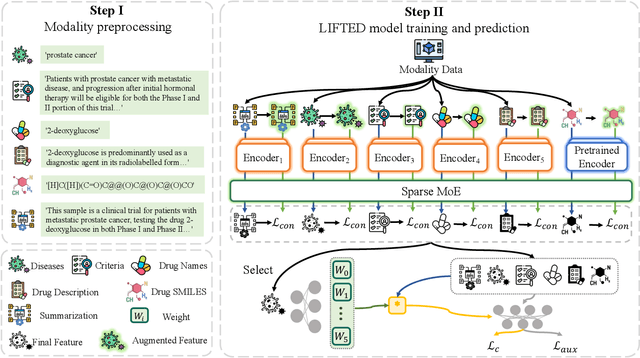
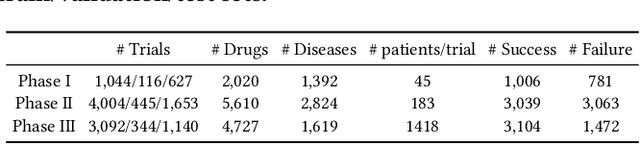
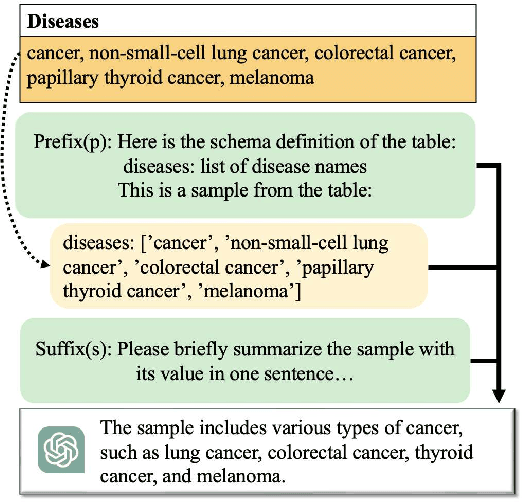
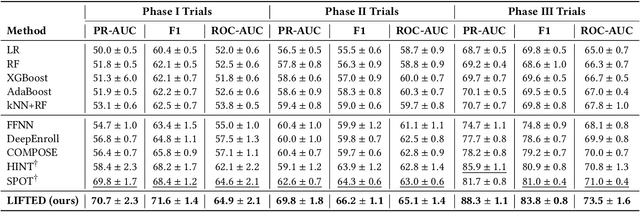
The clinical trial is a pivotal and costly process, often spanning multiple years and requiring substantial financial resources. Therefore, the development of clinical trial outcome prediction models aims to exclude drugs likely to fail and holds the potential for significant cost savings. Recent data-driven attempts leverage deep learning methods to integrate multimodal data for predicting clinical trial outcomes. However, these approaches rely on manually designed modal-specific encoders, which limits both the extensibility to adapt new modalities and the ability to discern similar information patterns across different modalities. To address these issues, we propose a multimodal mixture-of-experts (LIFTED) approach for clinical trial outcome prediction. Specifically, LIFTED unifies different modality data by transforming them into natural language descriptions. Then, LIFTED constructs unified noise-resilient encoders to extract information from modal-specific language descriptions. Subsequently, a sparse Mixture-of-Experts framework is employed to further refine the representations, enabling LIFTED to identify similar information patterns across different modalities and extract more consistent representations from those patterns using the same expert model. Finally, a mixture-of-experts module is further employed to dynamically integrate different modality representations for prediction, which gives LIFTED the ability to automatically weigh different modalities and pay more attention to critical information. The experiments demonstrate that LIFTED significantly enhances performance in predicting clinical trial outcomes across all three phases compared to the best baseline, showcasing the effectiveness of our proposed key components.
Enhancing Cybersecurity Resilience in Finance with Deep Learning for Advanced Threat Detection
Feb 15, 2024In the age of the Internet, people's lives are increasingly dependent on today's network technology. However, network technology is a double-edged sword, bringing convenience to people but also posing many security challenges. Maintaining network security and protecting the legitimate interests of users is at the heart of network construction. Threat detection is an important part of a complete and effective defense system. In the field of network information security, the technical update of network attack and network protection is spiraling. How to effectively detect unknown threats is one of the concerns of network protection. Currently, network threat detection is usually based on rules and traditional machine learning methods, which create artificial rules or extract common spatiotemporal features, which cannot be applied to large-scale data applications, and the emergence of unknown threats causes the detection accuracy of the original model to decline. With this in mind, this paper uses deep learning for advanced threat detection to improve cybersecurity resilienc e in the financial industry. Many network security researchers have shifted their focus to exceptio n-based intrusion detection techniques. The detection technology mainly uses statistical machine learning methods - collecting normal program and network behavior data, extracting multidimensional features, and training decision machine learning models on this basis (commonly used include naive Bayes, decision trees, support vector machines, random forests, etc.). In the detection phase, program code or network behavior that deviates from the normal value beyond the tolerance is considered malicious code or network attack behavior.
User Modeling and User Profiling: A Comprehensive Survey
Feb 15, 2024The integration of artificial intelligence (AI) into daily life, particularly through information retrieval and recommender systems, has necessitated advanced user modeling and profiling techniques to deliver personalized experiences. These techniques aim to construct accurate user representations based on the rich amounts of data generated through interactions with these systems. This paper presents a comprehensive survey of the current state, evolution, and future directions of user modeling and profiling research. We provide a historical overview, tracing the development from early stereotype models to the latest deep learning techniques, and propose a novel taxonomy that encompasses all active topics in this research area, including recent trends. Our survey highlights the paradigm shifts towards more sophisticated user profiling methods, emphasizing implicit data collection, multi-behavior modeling, and the integration of graph data structures. We also address the critical need for privacy-preserving techniques and the push towards explainability and fairness in user modeling approaches. By examining the definitions of core terminology, we aim to clarify ambiguities and foster a clearer understanding of the field by proposing two novel encyclopedic definitions of the main terms. Furthermore, we explore the application of user modeling in various domains, such as fake news detection, cybersecurity, and personalized education. This survey serves as a comprehensive resource for researchers and practitioners, offering insights into the evolution of user modeling and profiling and guiding the development of more personalized, ethical, and effective AI systems.
Link-aware link prediction over temporal graph by pattern recognition
Feb 11, 2024A temporal graph can be considered as a stream of links, each of which represents an interaction between two nodes at a certain time. On temporal graphs, link prediction is a common task, which aims to answer whether the query link is true or not. To do this task, previous methods usually focus on the learning of representations of the two nodes in the query link. We point out that the learned representation by their models may encode too much information with side effects for link prediction because they have not utilized the information of the query link, i.e., they are link-unaware. Based on this observation, we propose a link-aware model: historical links and the query link are input together into the following model layers to distinguish whether this input implies a reasonable pattern that ends with the query link. During this process, we focus on the modeling of link evolution patterns rather than node representations. Experiments on six datasets show that our model achieves strong performances compared with state-of-the-art baselines, and the results of link prediction are interpretable. The code and datasets are available on the project website: https://github.com/lbq8942/TGACN.
A novel spatial-frequency domain network for zero-shot incremental learning
Feb 11, 2024Zero-shot incremental learning aims to enable the model to generalize to new classes without forgetting previously learned classes. However, the semantic gap between old and new sample classes can lead to catastrophic forgetting. Additionally, existing algorithms lack capturing significant information from each sample image domain, impairing models' classification performance. Therefore, this paper proposes a novel Spatial-Frequency Domain Network (SFDNet) which contains a Spatial-Frequency Feature Extraction (SFFE) module and Attention Feature Alignment (AFA) module to improve the Zero-Shot Translation for Class Incremental algorithm. Firstly, SFFE module is designed which contains a dual attention mechanism for obtaining salient spatial-frequency feature information. Secondly, a novel feature fusion module is conducted for obtaining fused spatial-frequency domain features. Thirdly, the Nearest Class Mean classifier is utilized to select the most suitable category. Finally, iteration between tasks is performed using the Zero-Shot Translation model. The proposed SFDNet has the ability to effectively extract spatial-frequency feature representation from input images, improve the accuracy of image classification, and fundamentally alleviate catastrophic forgetting. Extensive experiments on the CUB 200-2011 and CIFAR100 datasets demonstrate that our proposed algorithm outperforms state-of-the-art incremental learning algorithms.
A Robotic Cyber-Physical System for Automated Reality Capture and Visualization in Construction Progress Monitoring
Feb 10, 2024Effective progress monitoring is crucial for the successful delivery of the construction project within the stipulated time and budget. Construction projects are often monitored irregularly through time-consuming physical site visits by multiple project stakeholders. Remote monitoring using robotic cyber-physical systems (CPS) can make the process more efficient and safer. This article presents a conceptual framework for robotic CPS for automated reality capture and visualization for remote progress monitoring in construction. The CPS integrates quadruped robot, Building Information Modelling (BIM), and 360{\deg} reality capturing to autonomously capture, and visualize up-to-date site information. Additionally, the study explores the factors affecting acceptance of the proposed robotic CPS through semi-structured interviews with seventeen progress monitoring experts. The findings will guide construction management teams in adopting CPS in construction and drive further research in the human-centered development of CPS for construction.
CataractBot: An LLM-Powered Expert-in-the-Loop Chatbot for Cataract Patients
Feb 07, 2024The healthcare landscape is evolving, with patients seeking more reliable information about their health conditions, treatment options, and potential risks. Despite the abundance of information sources, the digital age overwhelms individuals with excess, often inaccurate information. Patients primarily trust doctors and hospital staff, highlighting the need for expert-endorsed health information. However, the pressure on experts has led to reduced communication time, impacting information sharing. To address this gap, we propose CataractBot, an experts-in-the-loop chatbot powered by large language models (LLMs). Developed in collaboration with a tertiary eye hospital in India, CataractBot answers cataract surgery related questions instantly by querying a curated knowledge base, and provides expert-verified responses asynchronously. CataractBot features multimodal support and multilingual capabilities. In an in-the-wild deployment study with 49 participants, CataractBot proved valuable, providing anytime accessibility, saving time, and accommodating diverse literacy levels. Trust was established through expert verification. Broadly, our results could inform future work on designing expert-mediated LLM bots.
SumRec: A Framework for Recommendation using Open-Domain Dialogue
Feb 07, 2024Chat dialogues contain considerable useful information about a speaker's interests, preferences, and experiences.Thus, knowledge from open-domain chat dialogue can be used to personalize various systems and offer recommendations for advanced information.This study proposed a novel framework SumRec for recommending information from open-domain chat dialogue.The study also examined the framework using ChatRec, a newly constructed dataset for training and evaluation. To extract the speaker and item characteristics, the SumRec framework employs a large language model (LLM) to generate a summary of the speaker information from a dialogue and to recommend information about an item according to the type of user.The speaker and item information are then input into a score estimation model, generating a recommendation score.Experimental results show that the SumRec framework provides better recommendations than the baseline method of using dialogues and item descriptions in their original form. Our dataset and code is publicly available at https://github.com/Ryutaro-A/SumRec
Diff-RNTraj: A Structure-aware Diffusion Model for Road Network-constrained Trajectory Generation
Feb 12, 2024Trajectory data is essential for various applications as it records the movement of vehicles. However, publicly available trajectory datasets remain limited in scale due to privacy concerns, which hinders the development of trajectory data mining and trajectory-based applications. To address this issue, some methods for generating synthetic trajectories have been proposed to expand the scale of the dataset. However, all existing methods generate trajectories in the geographical coordinate system, which poses two limitations for their utilization in practical applications: 1) the inability to ensure that the generated trajectories are constrained on the road. 2) the lack of road-related information. In this paper, we propose a new problem to meet the practical application need, \emph{i.e.}, road network-constrained trajectory (RNTraj) generation, which can directly generate trajectories on the road network with road-related information. RNTraj is a hybrid type of data, in which each point is represented by a discrete road segment and a continuous moving rate. To generate RNTraj, we design a diffusion model called Diff-RNTraj. This model can effectively handle the hybrid RNTraj using a continuous diffusion framework by incorporating a pre-training strategy to embed hybrid RNTraj into continuous representations. During the sampling stage, a RNTraj decoder is designed to map the continuous representation generated by the diffusion model back to the hybrid RNTraj format. Furthermore, Diff-RNTraj introduces a novel loss function to enhance the spatial validity of the generated trajectories. Extensive experiments conducted on two real-world trajectory datasets demonstrate the effectiveness of the proposed model.
EmojiCrypt: Prompt Encryption for Secure Communication with Large Language Models
Feb 12, 2024Cloud-based large language models (LLMs) such as ChatGPT have increasingly become integral to daily operations, serving as vital tools across various applications. While these models offer substantial benefits in terms of accessibility and functionality, they also introduce significant privacy concerns: the transmission and storage of user data in cloud infrastructures pose substantial risks of data breaches and unauthorized access to sensitive information; even if the transmission and storage of data is encrypted, the LLM service provider itself still knows the real contents of the data, preventing individuals or entities from confidently using such LLM services. To address these concerns, this paper proposes a simple yet effective mechanism EmojiCrypt to protect user privacy. It uses Emoji to encrypt the user inputs before sending them to LLM, effectively rendering them indecipherable to human or LLM's examination while retaining the original intent of the prompt, thus ensuring the model's performance remains unaffected. We conduct experiments on three tasks, personalized recommendation, sentiment analysis, and tabular data analysis. Experiment results reveal that EmojiCrypt can encrypt personal information within prompts in such a manner that not only prevents the discernment of sensitive data by humans or LLM itself, but also maintains or even improves the precision without further tuning, achieving comparable or even better task accuracy than directly prompting the LLM without prompt encryption. These results highlight the practicality of adopting encryption measures that safeguard user privacy without compromising the functional integrity and performance of LLMs. Code and dataset are available at https://github.com/agiresearch/EmojiCrypt.