 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Stochastic Blockmodels with Edge Information
Apr 03, 2019
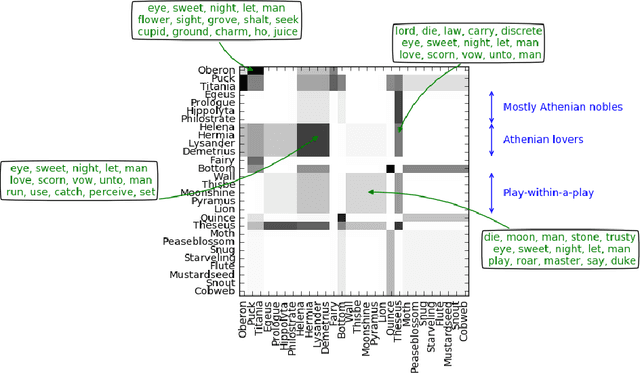
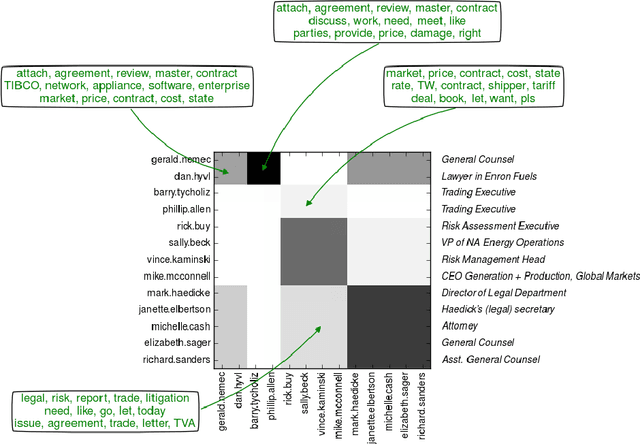
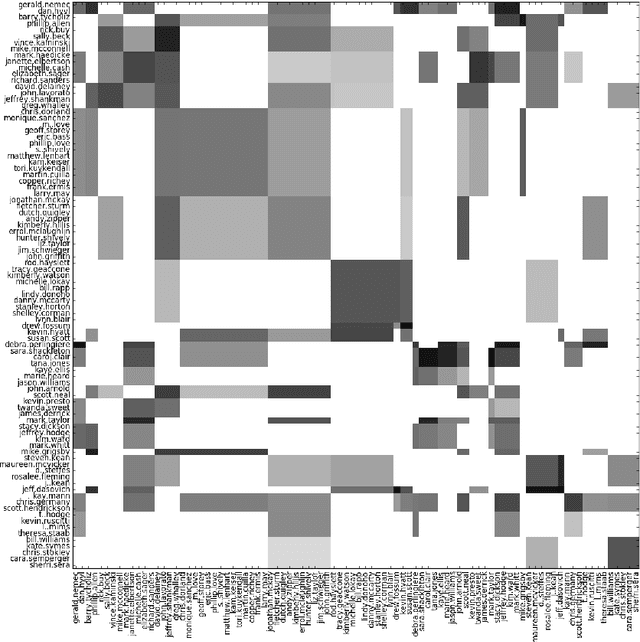

Stochastic blockmodels allow us to represent networks in terms of a latent community structure, often yielding intuitions about the underlying social structure. Typically, this structure is inferred based only on a binary network representing the presence or absence of interactions between nodes, which limits the amount of information that can be extracted from the data. In practice, many interaction networks contain much more information about the relationship between two nodes. For example, in an email network, the volume of communication between two users and the content of that communication can give us information about both the strength and the nature of their relationship. In this paper, we propose the Topic Blockmodel, a stochastic blockmodel that uses a count-based topic model to capture the interaction modalities within and between latent communities. By explicitly incorporating information sent between nodes in our network representation, we are able to address questions of interest in real-world situations, such as predicting recipients for an email message or inferring the content of an unopened email. Further, by considering topics associated with a pair of communities, we are better able to interpret the nature of each community and the manner in which it interacts with other communities.
A Transfer Learning Pipeline for Educational Resource Discovery with Application in Leading Paragraph Generation
Jan 07, 2022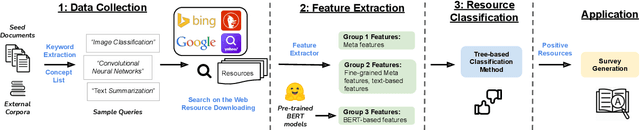

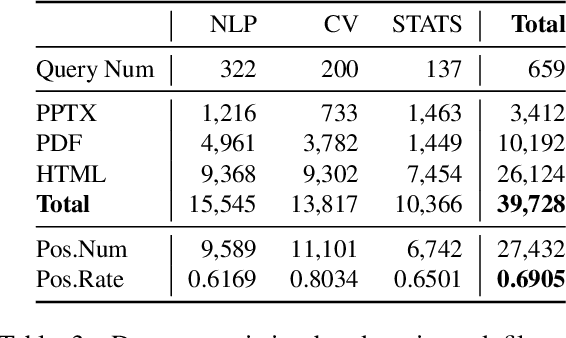
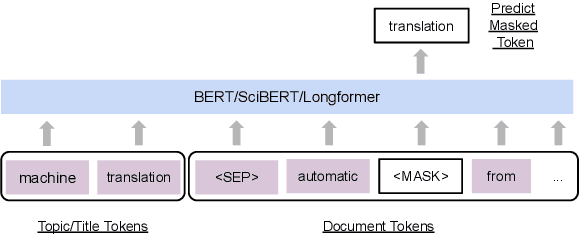
Effective human learning depends on a wide selection of educational materials that align with the learner's current understanding of the topic. While the Internet has revolutionized human learning or education, a substantial resource accessibility barrier still exists. Namely, the excess of online information can make it challenging to navigate and discover high-quality learning materials. In this paper, we propose the educational resource discovery (ERD) pipeline that automates web resource discovery for novel domains. The pipeline consists of three main steps: data collection, feature extraction, and resource classification. We start with a known source domain and conduct resource discovery on two unseen target domains via transfer learning. We first collect frequent queries from a set of seed documents and search on the web to obtain candidate resources, such as lecture slides and introductory blog posts. Then we introduce a novel pretrained information retrieval deep neural network model, query-document masked language modeling (QD-MLM), to extract deep features of these candidate resources. We apply a tree-based classifier to decide whether the candidate is a positive learning resource. The pipeline achieves F1 scores of 0.94 and 0.82 when evaluated on two similar but novel target domains. Finally, we demonstrate how this pipeline can benefit an application: leading paragraph generation for surveys. This is the first study that considers various web resources for survey generation, to the best of our knowledge. We also release a corpus of 39,728 manually labeled web resources and 659 queries from NLP, Computer Vision (CV), and Statistics (STATS).
DocSegTr: An Instance-Level End-to-End Document Image Segmentation Transformer
Jan 27, 2022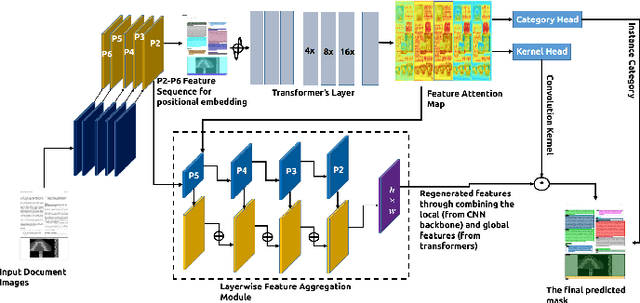
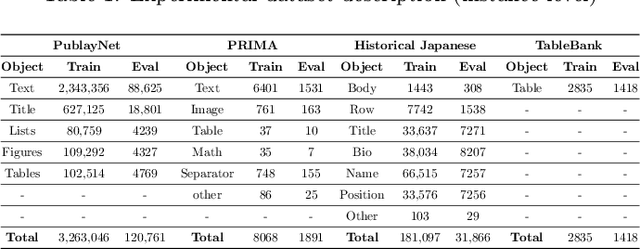

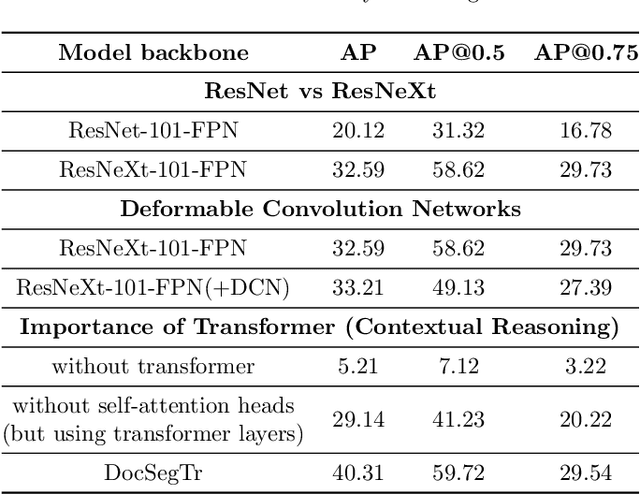
Understanding documents with rich layouts is an essential step towards information extraction. Business intelligence processes often require the extraction of useful semantic content from documents at a large scale for subsequent decision-making tasks. In this context, instance-level segmentation of different document objects(title, sections, figures, tables and so on) has emerged as an interesting problem for the document layout analysis community. To advance the research in this direction, we present a transformer-based model for end-to-end segmentation of complex layouts in document images. To our knowledge, this is the first work on transformer-based document segmentation. Extensive experimentation on the PubLayNet dataset shows that our model achieved comparable or better segmentation performance than the existing state-of-the-art approaches. We hope our simple and flexible framework could serve as a promising baseline for instance-level recognition tasks in document images.
Non-Coherent MIMO-OFDM Uplink empowered by the Spatial Diversity in Reflecting Surfaces
Feb 04, 2022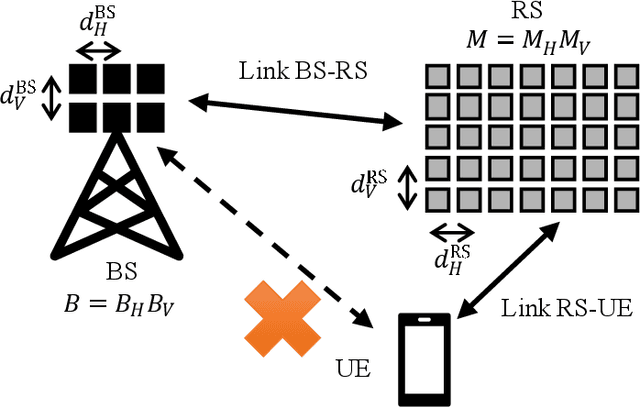
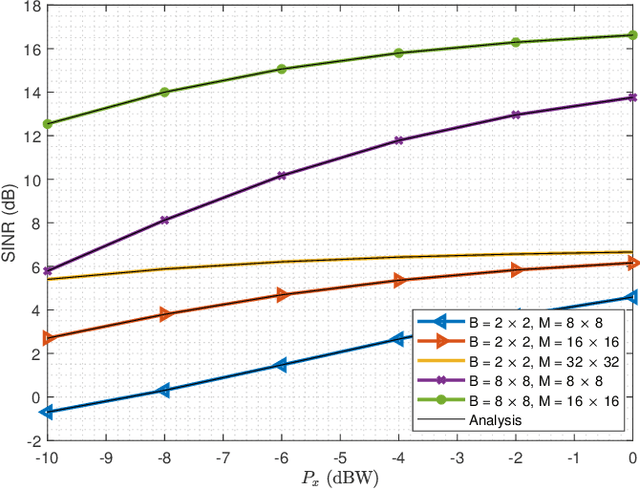
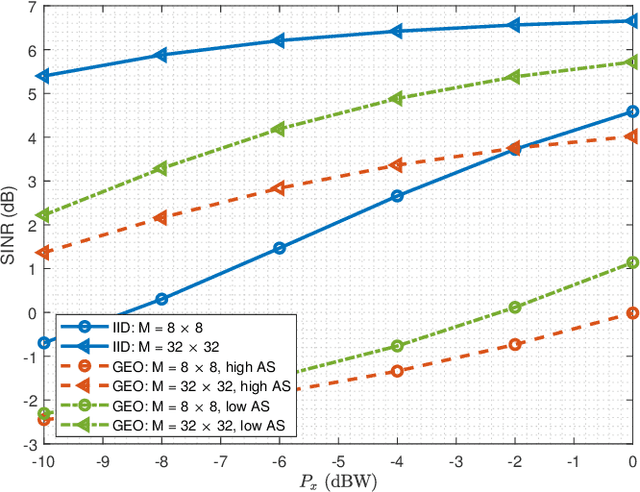
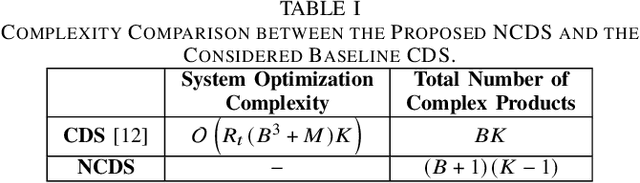
Reflecting Surfaces (RSs) are being lately envisioned as an energy efficient solution capable of enhancing the signal coverage in cases where obstacles block the direct communication from Base Stations (BSs), especially at high frequency bands due to attenuation loss increase. In the current literature, wireless communications via RSs are exclusively based on traditional coherent demodulation, which necessitates the estimation of accurate Channel State Information (CSI). However, this requirement results in an increased overhead, especially in time-varying channels, which reduces the resources that can be used for data communication. In this paper, we consider the uplink between a single-antenna user and a multi-antenna BS and present a novel RS-empowered Orthogonal Frequency Division Multiplexing (OFDM) communication system based on the differential phase shift keying, which is suitable for high noise and/or mobility scenarios. As a benchmark, analytical expressions for the Signal-to-Interference and Noise Ratio (SINR) of the proposed system are presented. Our extensive simulation results verify the accuracy of the presented analysis and showcase the performance and superiority of the proposed system over coherent demodulation.
Communication-Efficient Consensus Mechanism for Federated Reinforcement Learning
Jan 30, 2022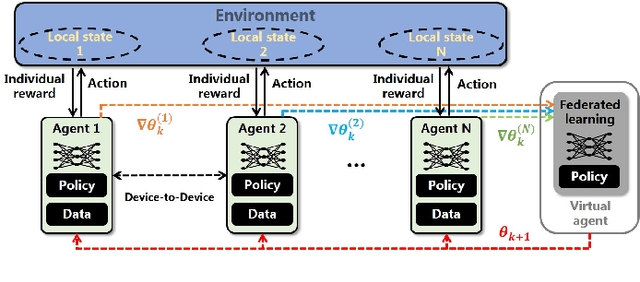
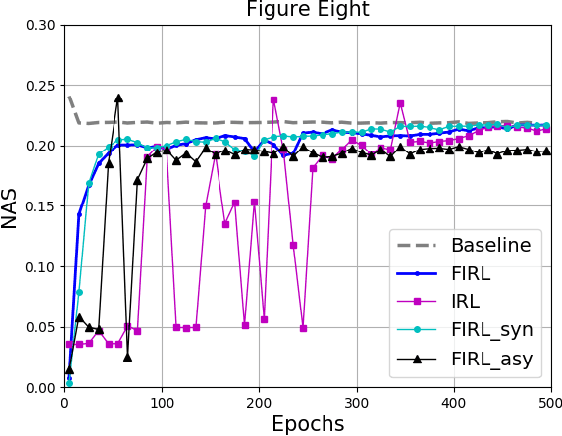
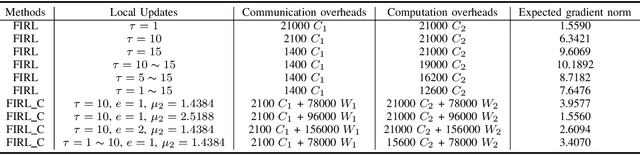
The paper considers independent reinforcement learning (IRL) for multi-agent decision-making process in the paradigm of federated learning (FL). We show that FL can clearly improve the policy performance of IRL in terms of training efficiency and stability. However, since the policy parameters are trained locally and aggregated iteratively through a central server in FL, frequent information exchange incurs a large amount of communication overheads. To reach a good balance between improving the model's convergence performance and reducing the required communication and computation overheads, this paper proposes a system utility function and develops a consensus-based optimization scheme on top of the periodic averaging method, which introduces the consensus algorithm into FL for the exchange of a model's local gradients. This paper also provides novel convergence guarantees for the developed method, and demonstrates its superior effectiveness and efficiency in improving the system utility value through theoretical analyses and numerical simulation results.
ICSML: Industrial Control Systems Machine Learning inference framework natively executing on IEC 61131-3 languages
Feb 21, 2022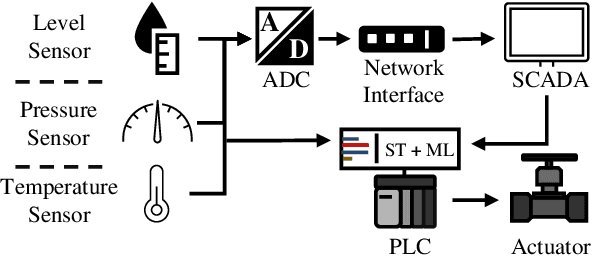
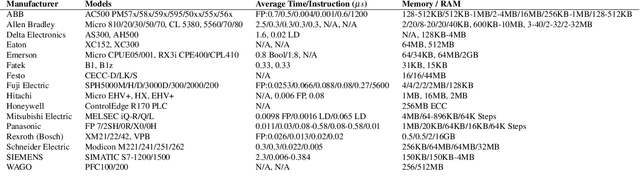
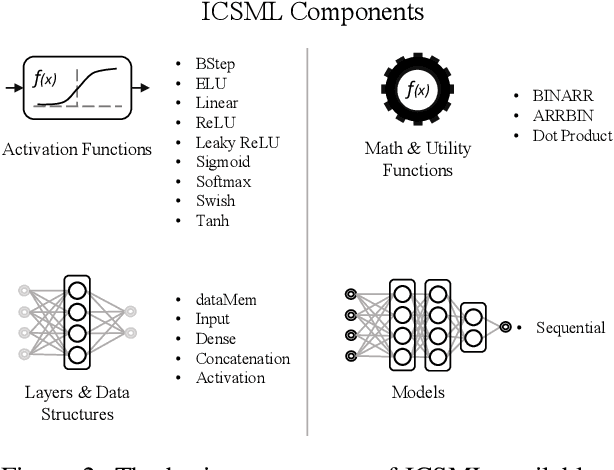
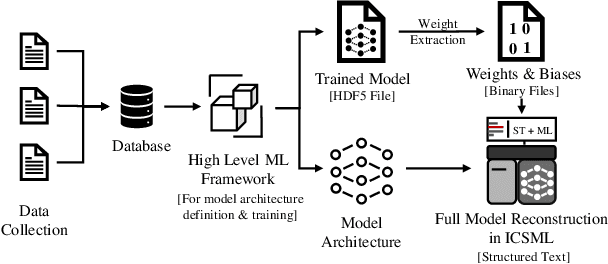
Industrial Control Systems (ICS) have played a catalytic role in enabling the 4th Industrial Revolution. ICS devices like Programmable Logic Controllers (PLCs), automate, monitor and control critical processes in industrial, energy and commercial environments. The convergence of traditional Operational Technology (OT) with Information Technology (IT) has opened a new and unique threat landscape. This has inspired defense research that focuses heavily on Machine Learning (ML) based anomaly detection methods that run on external IT hardware which means an increase in costs and the further expansion of the threat landscape. To remove this requirement, we introduce the ICS Machine Learning inference framework (ICSML) which enables the execution of ML models natively on the PLC. ICSML is implemented in IEC 61131-3 code and works around the limitations imposed by the domain-specific languages, providing a complete set of components for the creation of fully fledged ML models in a way similar to established ML frameworks. We then demonstrate a complete end-to-end methodology for creating ICS ML models using an external framework for training and ICSML for the PLC implementation. To evaluate our contributions we run a series of benchmarks studying memory and performance and compare our solution to the TFLite inference framework. Finally, to demonstrate the abilities of ICSML and to verify its non-intrusive nature, we develop and evaluate a case study of a real defense for process aware attacks against a Multi Stage Flash (MSF) desalination plant.
EGFI: Drug-Drug Interaction Extraction and Generation with Fusion of Enriched Entity and Sentence Information
Jan 25, 2021
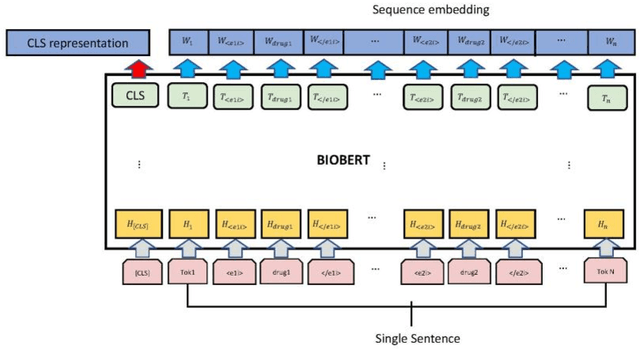
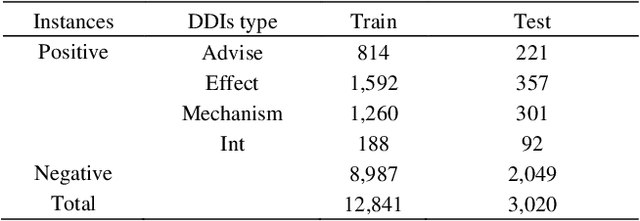
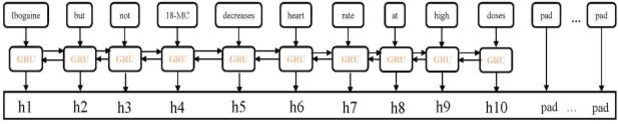
The rapid growth in literature accumulates diverse and yet comprehensive biomedical knowledge hidden to be mined such as drug interactions. However, it is difficult to extract the heterogeneous knowledge to retrieve or even discover the latest and novel knowledge in an efficient manner. To address such a problem, we propose EGFI for extracting and consolidating drug interactions from large-scale medical literature text data. Specifically, EGFI consists of two parts: classification and generation. In the classification part, EGFI encompasses the language model BioBERT which has been comprehensively pre-trained on biomedical corpus. In particular, we propose the multi-head attention mechanism and pack BiGRU to fuse multiple semantic information for rigorous context modeling. In the generation part, EGFI utilizes another pre-trained language model BioGPT-2 where the generation sentences are selected based on filtering rules. We evaluated the classification part on "DDIs 2013" dataset and "DTIs" dataset, achieving the FI score of 0.842 and 0.720 respectively. Moreover, we applied the classification part to distinguish high-quality generated sentences and verified with the exiting growth truth to confirm the filtered sentences. The generated sentences that are not recorded in DrugBank and DDIs 2013 dataset also demonstrate the potential of EGFI to identify novel drug relationships.
An Analysis Of Protected Health Information Leakage In Deep-Learning Based De-Identification Algorithms
Jan 28, 2021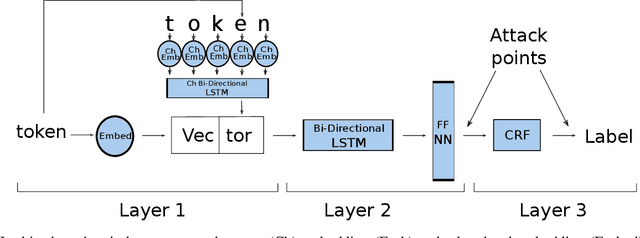
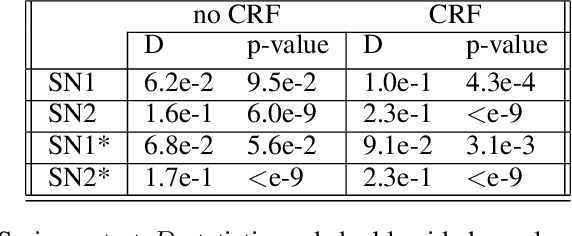
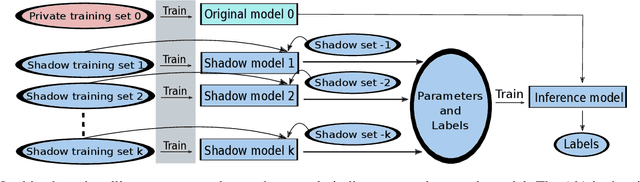
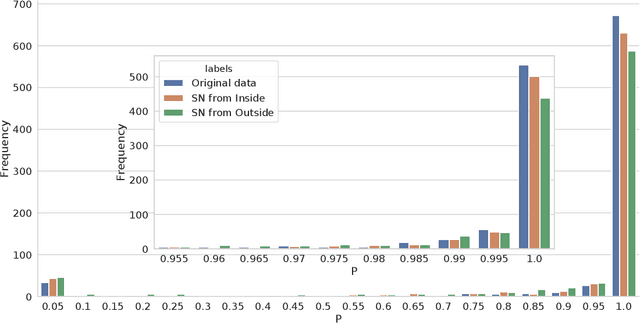
The increasing complexity of algorithms for analyzing medical data, including de-identification tasks, raises the possibility that complex algorithms are learning not just the general representation of the problem, but specifics of given individuals within the data. Modern legal frameworks specifically prohibit the intentional or accidental distribution of patient data, but have not addressed this potential avenue for leakage of such protected health information. Modern deep learning algorithms have the highest potential of such leakage due to complexity of the models. Recent research in the field has highlighted such issues in non-medical data, but all analysis is likely to be data and algorithm specific. We, therefore, chose to analyze a state-of-the-art free-text de-identification algorithm based on LSTM (Long Short-Term Memory) and its potential in encoding any individual in the training set. Using the i2b2 Challenge Data, we trained, then analyzed the model to assess whether the output of the LSTM, before the compression layer of the classifier, could be used to estimate the membership of the training data. Furthermore, we used different attacks including membership inference attack method to attack the model. Results indicate that the attacks could not identify whether members of the training data were distinguishable from non-members based on the model output. This indicates that the model does not provide any strong evidence into the identification of the individuals in the training data set and there is not yet empirical evidence it is unsafe to distribute the model for general use.
Deep Graph Learning for Spatially-Varying Indoor Lighting Prediction
Feb 13, 2022
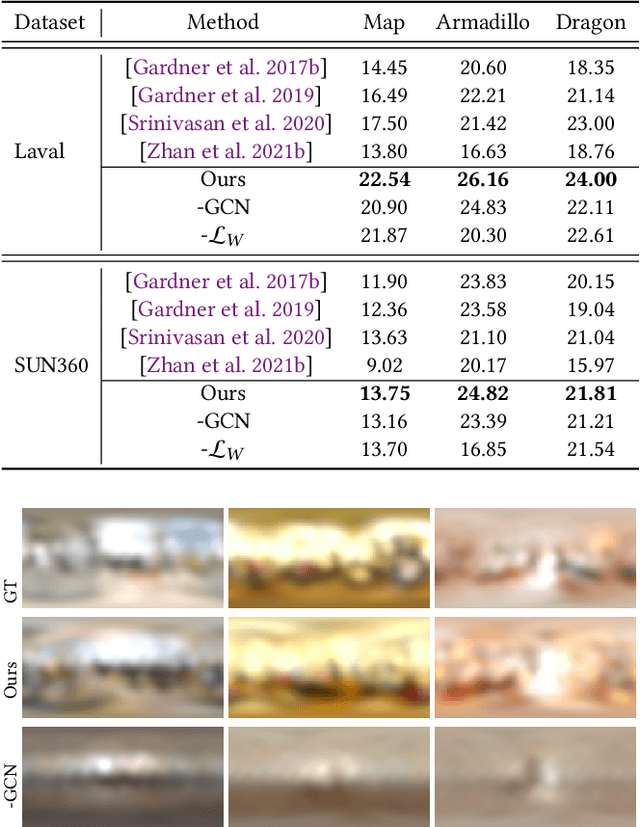


Lighting prediction from a single image is becoming increasingly important in many vision and augmented reality (AR) applications in which shading and shadow consistency between virtual and real objects should be guaranteed. However, this is a notoriously ill-posed problem, especially for indoor scenarios, because of the complexity of indoor luminaires and the limited information involved in 2D images. In this paper, we propose a graph learning-based framework for indoor lighting estimation. At its core is a new lighting model (dubbed DSGLight) based on depth-augmented Spherical Gaussians (SG) and a Graph Convolutional Network (GCN) that infers the new lighting representation from a single LDR image of limited field-of-view. Our lighting model builds 128 evenly distributed SGs over the indoor panorama, where each SG encoding the lighting and the depth around that node. The proposed GCN then learns the mapping from the input image to DSGLight. Compared with existing lighting models, our DSGLight encodes both direct lighting and indirect environmental lighting more faithfully and compactly. It also makes network training and inference more stable. The estimated depth distribution enables temporally stable shading and shadows under spatially-varying lighting. Through thorough experiments, we show that our method obviously outperforms existing methods both qualitatively and quantitatively.
Accelerated Intravascular Ultrasound Imaging using Deep Reinforcement Learning
Jan 24, 2022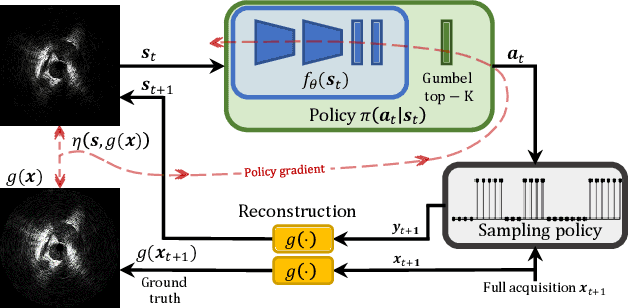
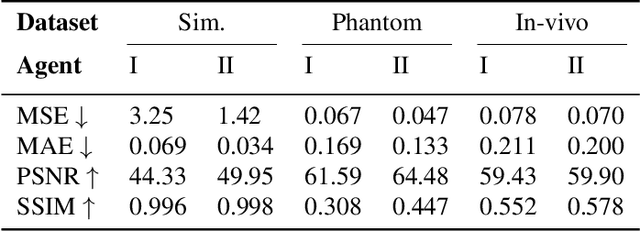

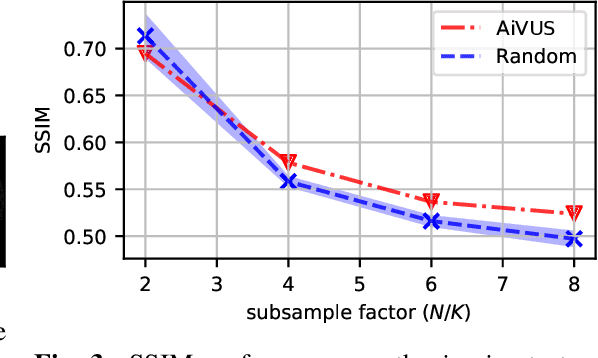
Intravascular ultrasound (IVUS) offers a unique perspective in the treatment of vascular diseases by creating a sequence of ultrasound-slices acquired from within the vessel. However, unlike conventional hand-held ultrasound, the thin catheter only provides room for a small number of physical channels for signal transfer from a transducer-array at the tip. For continued improvement of image quality and frame rate, we present the use of deep reinforcement learning to deal with the current physical information bottleneck. Valuable inspiration has come from the field of magnetic resonance imaging (MRI), where learned acquisition schemes have brought significant acceleration in image acquisition at competing image quality. To efficiently accelerate IVUS imaging, we propose a framework that utilizes deep reinforcement learning for an optimal adaptive acquisition policy on a per-frame basis enabled by actor-critic methods and Gumbel top-$K$ sampling.
* 5 pages, 3 figures, conference