 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SCROLLS: Standardized CompaRison Over Long Language Sequences
Jan 10, 2022
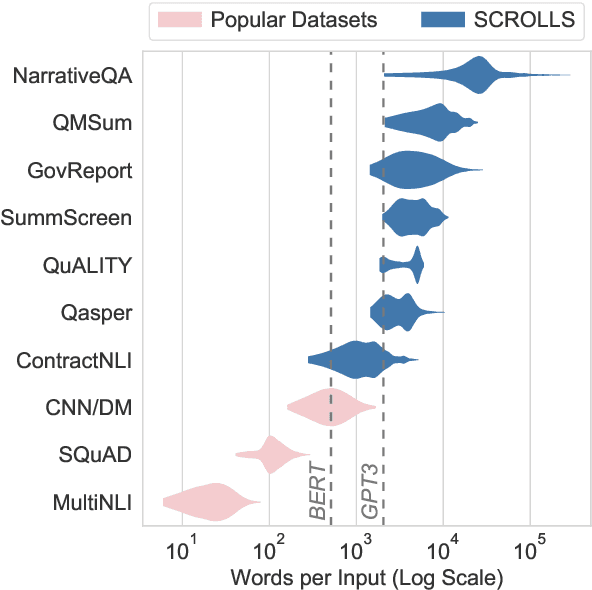
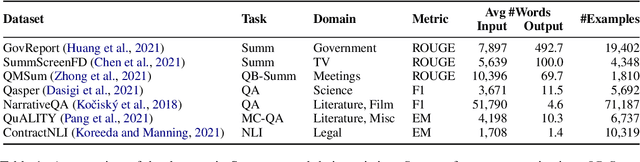

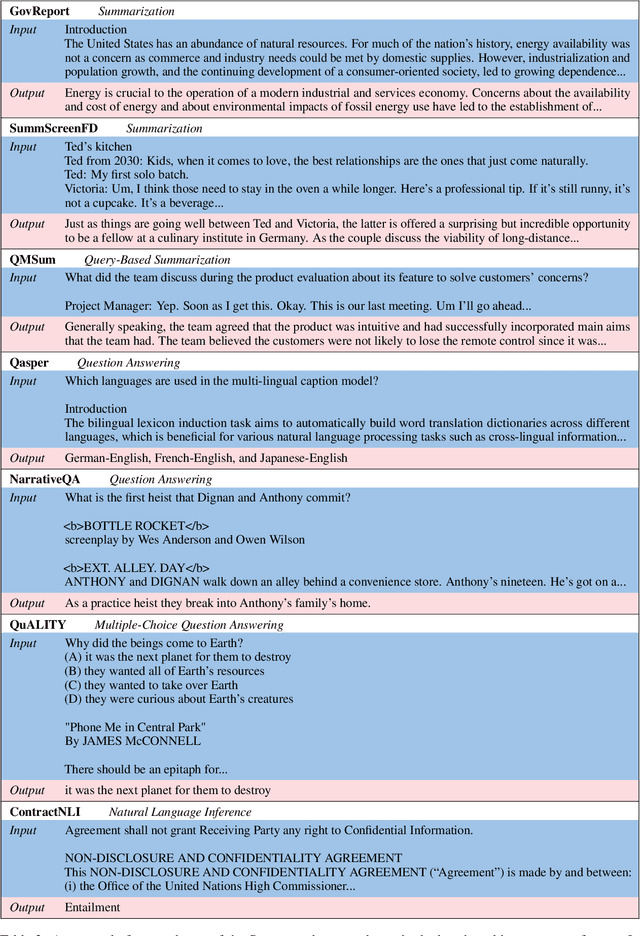
NLP benchmarks have largely focused on short texts, such as sentences and paragraphs, even though long texts comprise a considerable amount of natural language in the wild. We introduce SCROLLS, a suite of tasks that require reasoning over long texts. We examine existing long-text datasets, and handpick ones where the text is naturally long, while prioritizing tasks that involve synthesizing information across the input. SCROLLS contains summarization, question answering, and natural language inference tasks, covering multiple domains, including literature, science, business, and entertainment. Initial baselines, including Longformer Encoder-Decoder, indicate that there is ample room for improvement on SCROLLS. We make all datasets available in a unified text-to-text format and host a live leaderboard to facilitate research on model architecture and pretraining methods.
Multi-cell Non-coherent Over-the-Air Computation for Federated Edge Learning
Feb 01, 2022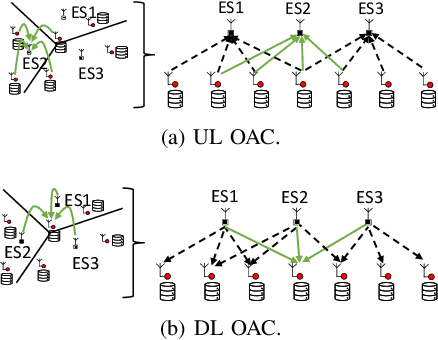
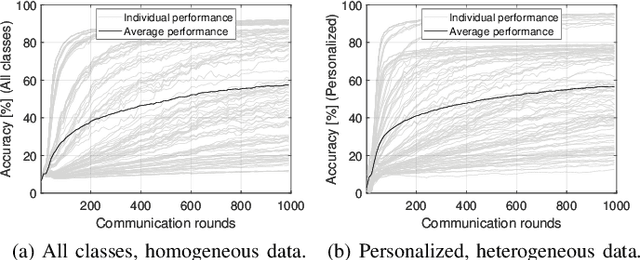
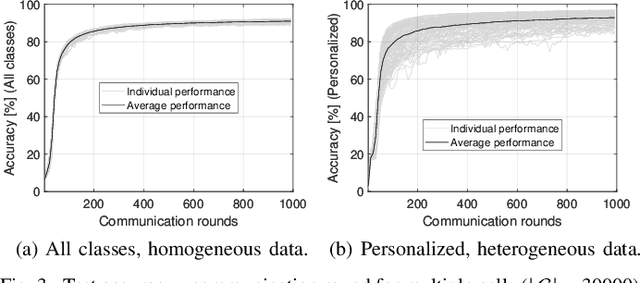
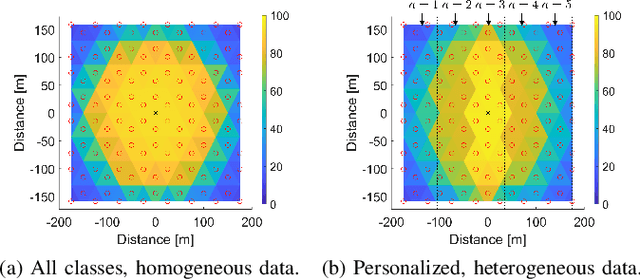
In this paper, we propose a framework where over-the-air computation (OAC) occurs in both uplink (UL) and downlink (DL), sequentially, in a multi-cell environment to address the latency and the scalability issues of federated edge learning (FEEL). To eliminate the channel state information (CSI) at the edge devices (EDs) and edge servers (ESs) and relax the time-synchronization requirement for the OAC, we use a non-coherent computation scheme, i.e., frequency-shift keying (FSK)-based majority vote (MV) (FSK-MV). With the proposed framework, multiple ESs function as the aggregation nodes in the UL and each ES determines the MVs independently. After the ESs broadcast the detected MVs, the EDs determine the sign of the gradient through another OAC in the DL. Hence, inter-cell interference is exploited for the OAC. In this study, we prove the convergence of the non-convex optimization problem for the FEEL with the proposed OAC framework. We also numerically evaluate the efficacy of the proposed method by comparing the test accuracy in both multi-cell and single-cell scenarios for both homogeneous and heterogeneous data distributions.
A comparative study of in-air trajectories at short and long distances in online handwriting
Feb 23, 2022
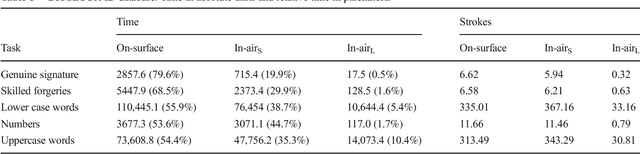
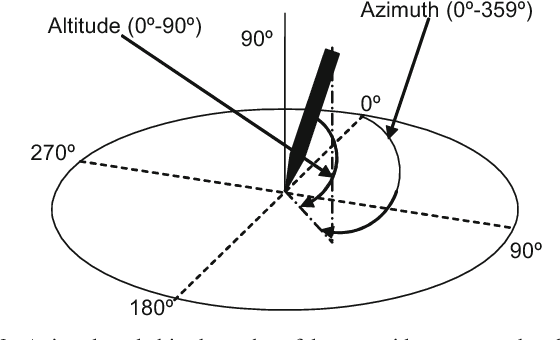
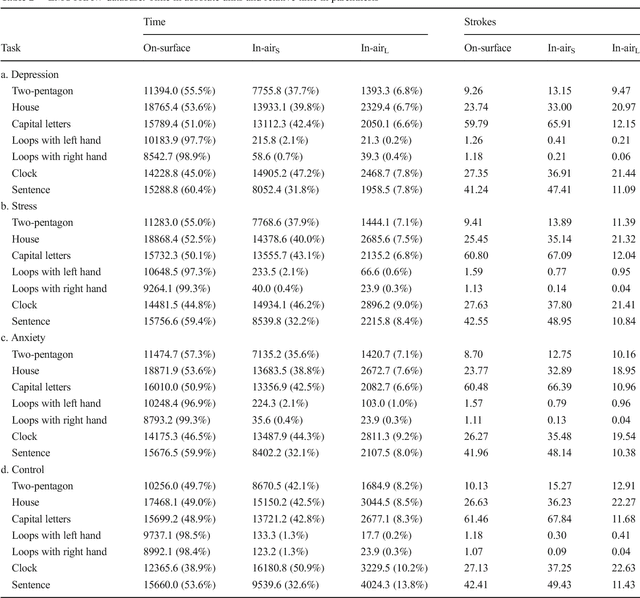
Introduction Existing literature about online handwriting analysis to support pathology diagnosis has taken advantage of in-air trajectories. A similar situation occurred in biometric security applications where the goal is to identify or verify an individual using his signature or handwriting. These studies do not consider the distance of the pen tip to the writing surface. This is due to the fact that current acquisition devices do not provide height formation. However, it is quite straightforward to differentiate movements at two different heights: a) short distance: height lower or equal to 1 cm above a surface of digitizer, the digitizer provides x and y coordinates. b) long distance: height exceeding 1 cm, the only information available is a time stamp that indicates the time that a specific stroke has spent at long distance. Although short distance has been used in several papers, long distances have been ignored and will be investigated in this paper. Methods In this paper, we will analyze a large set of databases (BIOSECURID, EMOTHAW, PaHaW, Oxygen-Therapy and SALT), which contain a total amount of 663 users and 17951 files. We have specifically studied: a) the percentage of time spent on-surface, in-air at short distance, and in-air at long distance for different user profiles (pathological and healthy users) and different tasks; b) The potential use of these signals to improve classification rates. Results and conclusions Our experimental results reveal that long-distance movements represent a very small portion of the total execution time (0.5 % in the case of signatures and 10.4% for uppercase words of BIOSECUR-ID, which is the largest database). In addition, significant differences have been found in the comparison of pathological versus control group for letter l in PaHaW database (p=0.0157) and crossed pentagons in SALT database (p=0.0122)
* 11 pages
Graph-based Algorithm Unfolding for Energy-aware Power Allocation in Wireless Networks
Jan 27, 2022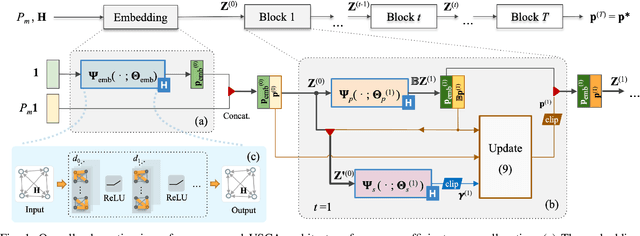
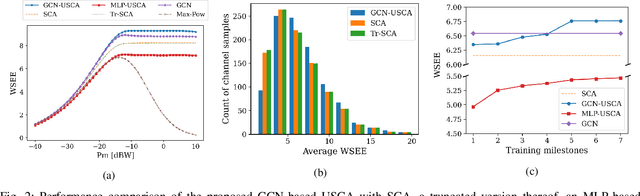
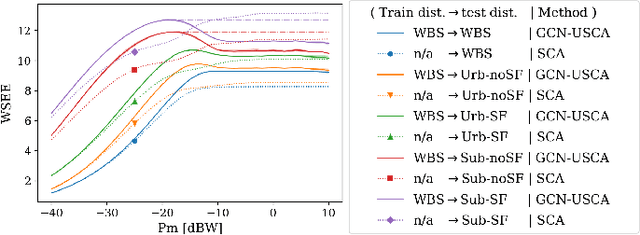
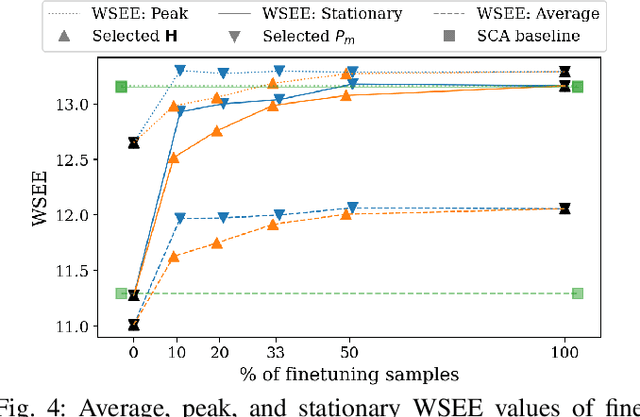
We develop a novel graph-based trainable framework to maximize the weighted sum energy efficiency (WSEE) for power allocation in wireless communication networks. To address the non-convex nature of the problem, the proposed method consists of modular structures inspired by a classical iterative suboptimal approach and enhanced with learnable components. More precisely, we propose a deep unfolding of the successive concave approximation (SCA) method. In our unfolded SCA (USCA) framework, the originally preset parameters are now learnable via graph convolutional neural networks (GCNs) that directly exploit multi-user channel state information as the underlying graph adjacency matrix. We show the permutation equivariance of the proposed architecture, which promotes generalizability across different network topologies of varying size, density, and channel distribution. The USCA framework is trained through a stochastic gradient descent approach using a progressive training strategy. The unsupervised loss is carefully devised to feature the monotonic property of the objective under maximum power constraints. Comprehensive numerical results demonstrate outstanding performance and robustness of USCA over state-of-the-art benchmarks.
When less is more: Simplifying inputs aids neural network understanding
Feb 01, 2022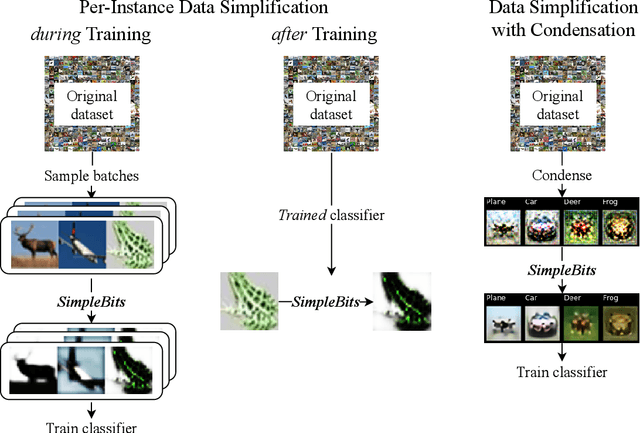

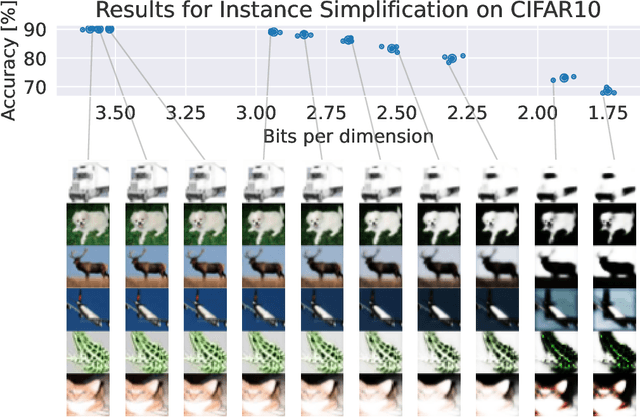
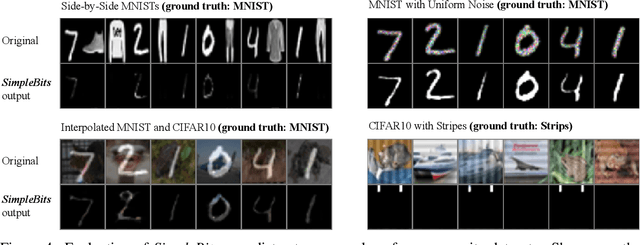
How do neural network image classifiers respond to simpler and simpler inputs? And what do such responses reveal about the learning process? To answer these questions, we need a clear measure of input simplicity (or inversely, complexity), an optimization objective that correlates with simplification, and a framework to incorporate such objective into training and inference. Lastly we need a variety of testbeds to experiment and evaluate the impact of such simplification on learning. In this work, we measure simplicity with the encoding bit size given by a pretrained generative model, and minimize the bit size to simplify inputs in training and inference. We investigate the effect of such simplification in several scenarios: conventional training, dataset condensation and post-hoc explanations. In all settings, inputs are simplified along with the original classification task, and we investigate the trade-off between input simplicity and task performance. For images with injected distractors, such simplification naturally removes superfluous information. For dataset condensation, we find that inputs can be simplified with almost no accuracy degradation. When used in post-hoc explanation, our learning-based simplification approach offers a valuable new tool to explore the basis of network decisions.
Facilitating Connected Autonomous Vehicle Operations Using Space-weighted Information Fusion and Deep Reinforcement Learning Based Control
Sep 30, 2020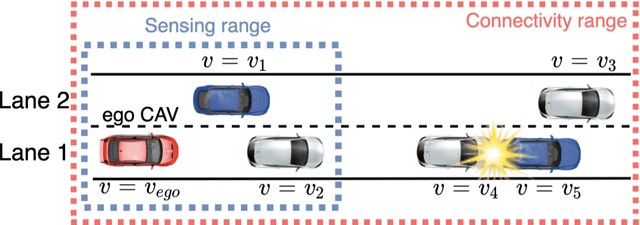
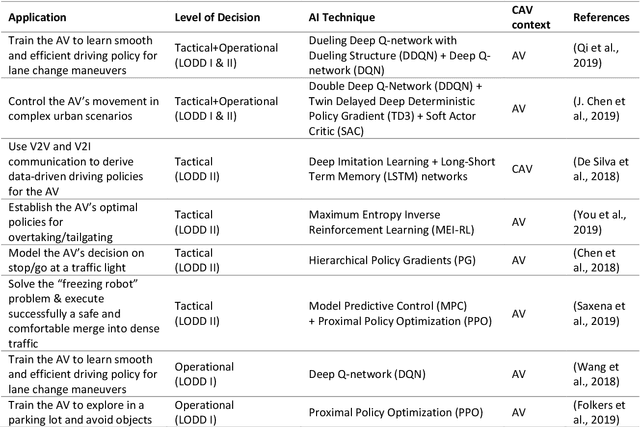
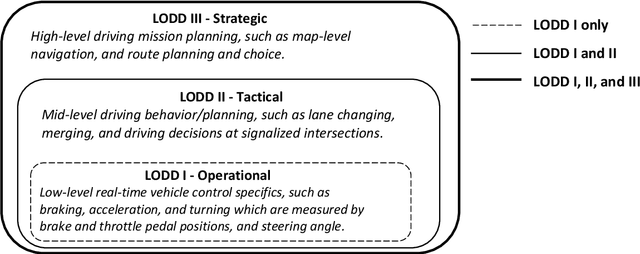
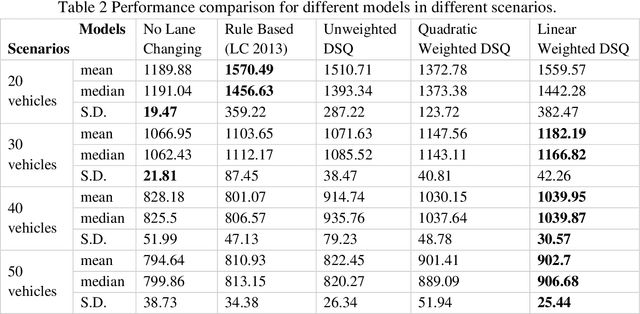
The connectivity aspect of connected autonomous vehicles (CAV) is beneficial because it facilitates dissemination of traffic-related information to vehicles through Vehicle-to-External (V2X) communication. Onboard sensing equipment including LiDAR and camera can reasonably characterize the traffic environment in the immediate locality of the CAV. However, their performance is limited by their sensor range (SR). On the other hand, longer-range information is helpful for characterizing imminent conditions downstream. By contemporaneously coalescing the short- and long-range information, the CAV can construct comprehensively its surrounding environment and thereby facilitate informed, safe, and effective movement planning in the short-term (local decisions including lane change) and long-term (route choice). In this paper, we describe a Deep Reinforcement Learning based approach that integrates the data collected through sensing and connectivity capabilities from other vehicles located in the proximity of the CAV and from those located further downstream, and we use the fused data to guide lane changing, a specific context of CAV operations. In addition, recognizing the importance of the connectivity range (CR) to the performance of not only the algorithm but also of the vehicle in the actual driving environment, the paper carried out a case study. The case study demonstrates the application of the proposed algorithm and duly identifies the appropriate CR for each level of prevailing traffic density. It is expected that implementation of the algorithm in CAVs can enhance the safety and mobility associated with CAV driving operations. From a general perspective, its implementation can provide guidance to connectivity equipment manufacturers and CAV operators, regarding the default CR settings for CAVs or the recommended CR setting in a given traffic environment.
Learning to Select the Next Reasonable Mention for Entity Linking
Dec 08, 2021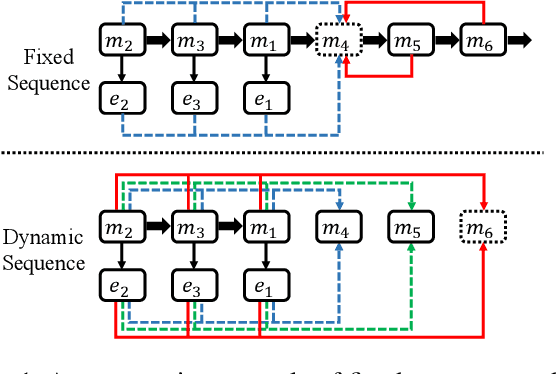
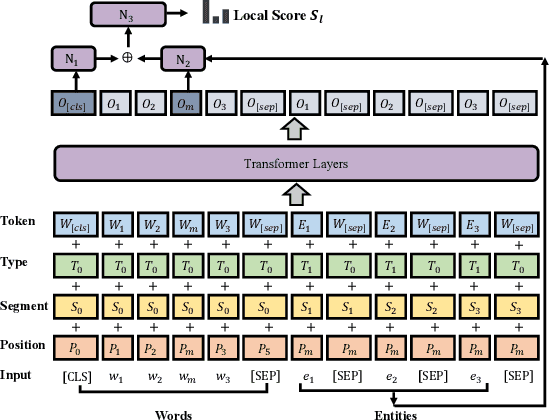
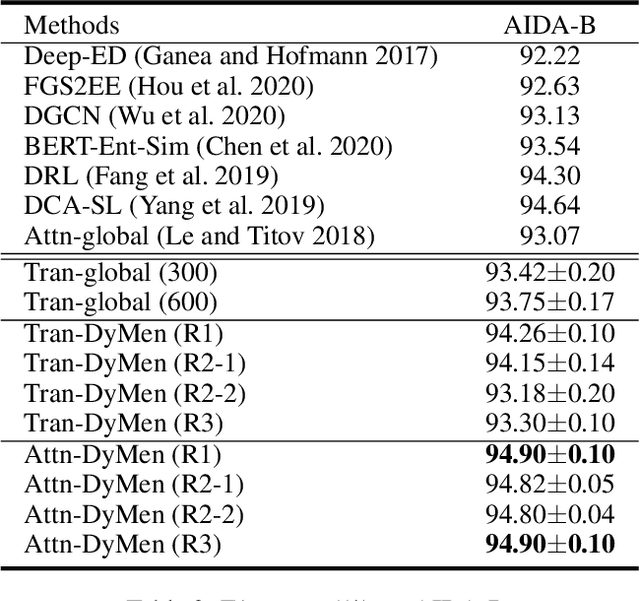
Entity linking aims to establish a link between entity mentions in a document and the corresponding entities in knowledge graphs (KGs). Previous work has shown the effectiveness of global coherence for entity linking. However, most of the existing global linking methods based on sequential decisions focus on how to utilize previously linked entities to enhance the later decisions. In those methods, the order of mention is fixed, making the model unable to adjust the subsequent linking targets according to the previously linked results, which will cause the previous information to be unreasonably utilized. To address the problem, we propose a novel model, called DyMen, to dynamically adjust the subsequent linking target based on the previously linked entities via reinforcement learning, enabling the model to select a link target that can fully use previously linked information. We sample mention by sliding window to reduce the action sampling space of reinforcement learning and maintain the semantic coherence of mention. Experiments conducted on several benchmark datasets have shown the effectiveness of the proposed model.
Graph Neural Network for Cell Tracking in Microscopy Videos
Feb 09, 2022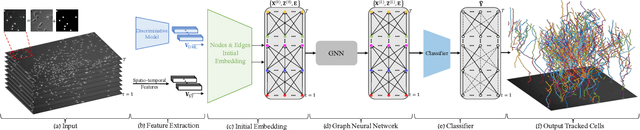
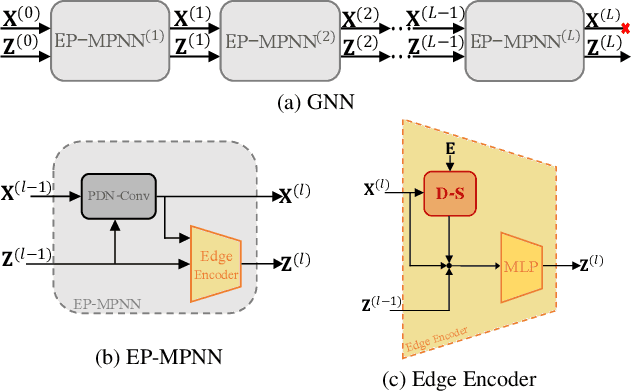
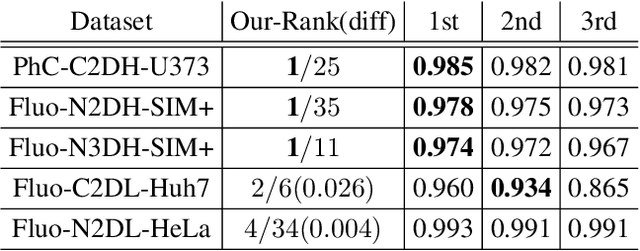
We present a novel graph neural network (GNN) approach for cell tracking in high-throughput microscopy videos. By modeling the entire time-lapse sequence as a direct graph where cell instances are represented by its nodes and their associations by its edges, we extract the entire set of cell trajectories by looking for the maximal paths in the graph. This is accomplished by several key contributions incorporated into an end-to-end deep learning framework. We exploit a deep metric learning algorithm to extract cell feature vectors that distinguish between instances of different biological cells and assemble same cell instances. We introduce a new GNN block type which enables a mutual update of node and edge feature vectors, thus facilitating the underlying message passing process. The message passing concept, whose extent is determined by the number of GNN blocks, is of fundamental importance as it enables the `flow' of information between nodes and edges much behind their neighbors in consecutive frames. Finally, we solve an edge classification problem and use the identified active edges to construct the cells' tracks and lineage trees. We demonstrate the strengths of the proposed cell tracking approach by applying it to 2D and 3D datasets of different cell types, imaging setups, and experimental conditions. We show that our framework outperforms most of the current state-of-the-art methods.
Unsupervised Hierarchical Graph Representation Learning by Mutual Information Maximization
Mar 18, 2020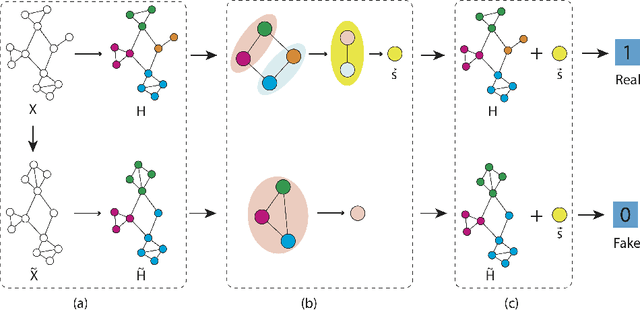
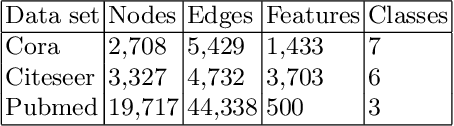
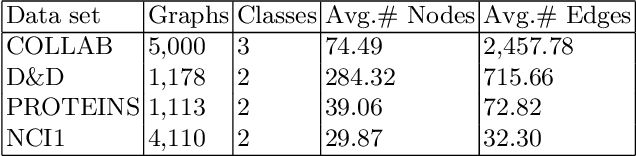
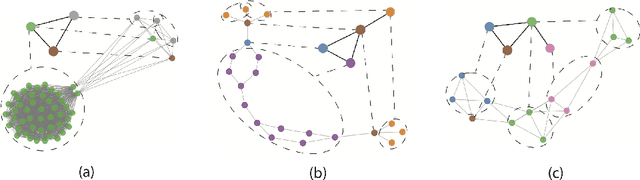
Graph representation learning based on graph neural networks (GNNs) can greatly improve the performance of downstream tasks, such as node and graph classification. However, the general GNN models cannot aggregate node information in a hierarchical manner, and thus cannot effectively capture the structural features of graphs. In addition, most of the existing hierarchical graph representation learning are supervised, which are limited by the extreme cost of acquiring labeled data. To address these issues, we present an unsupervised graph representation learning method, Unsupervised Hierarchical Graph Representation UHGR, which can generate hierarchical representations of graphs. This contrastive learning technique focuses on maximizing mutual information between "local" and high-level "global" representations, which enables us to learn the node embeddings and graph embeddings without any labeled data. To demonstrate the effectiveness of the proposed method, we perform the node and graph classification using the learned node and graph embeddings. The results show that the proposed method achieves comparable results to state-of-the-art supervised methods on several benchmarks. In addition, our visualization of hierarchical representations indicates that our method can capture meaningful and interpretable clusters.
Grad2Task: Improved Few-shot Text Classification Using Gradients for Task Representation
Jan 27, 2022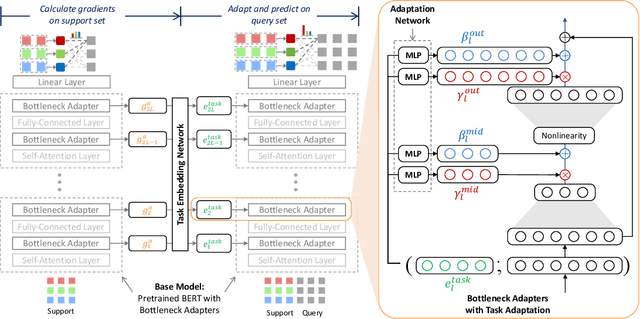
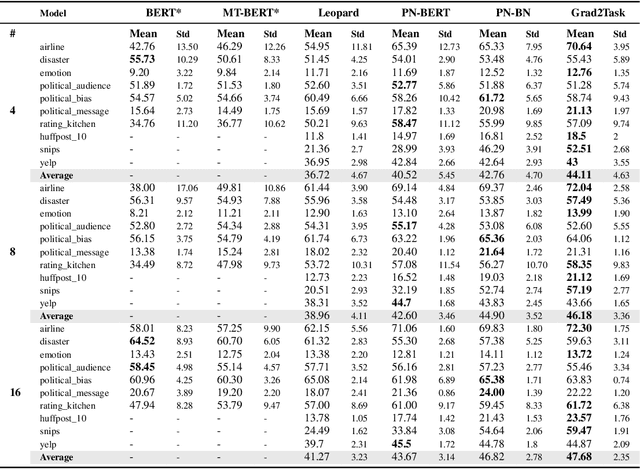
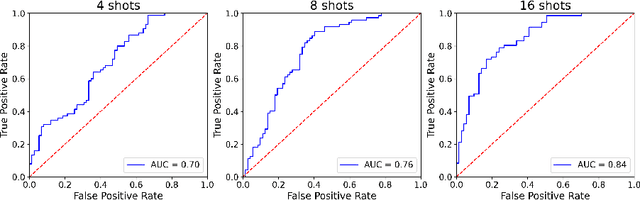
Large pretrained language models (LMs) like BERT have improved performance in many disparate natural language processing (NLP) tasks. However, fine tuning such models requires a large number of training examples for each target task. Simultaneously, many realistic NLP problems are "few shot", without a sufficiently large training set. In this work, we propose a novel conditional neural process-based approach for few-shot text classification that learns to transfer from other diverse tasks with rich annotation. Our key idea is to represent each task using gradient information from a base model and to train an adaptation network that modulates a text classifier conditioned on the task representation. While previous task-aware few-shot learners represent tasks by input encoding, our novel task representation is more powerful, as the gradient captures input-output relationships of a task. Experimental results show that our approach outperforms traditional fine-tuning, sequential transfer learning, and state-of-the-art meta learning approaches on a collection of diverse few-shot tasks. We further conducted analysis and ablations to justify our design choices.