 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Intelligent Reflecting Surface-Aided Spectrum Sensing for Cognitive Radio
Feb 05, 2022
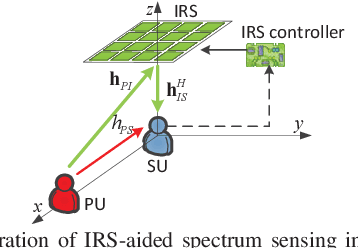
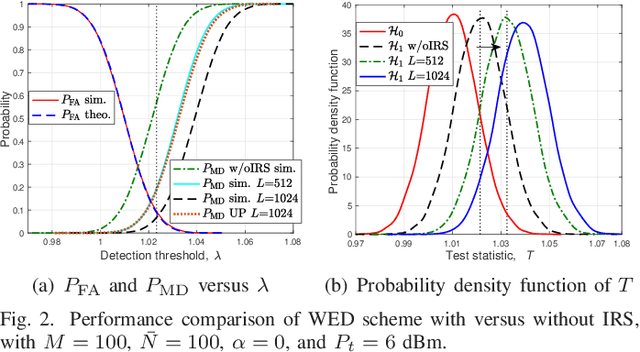
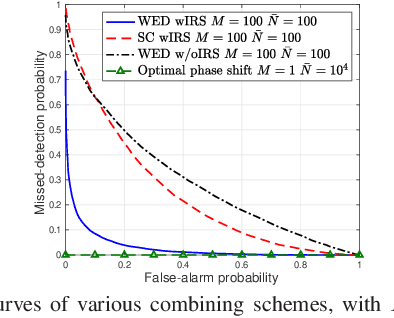
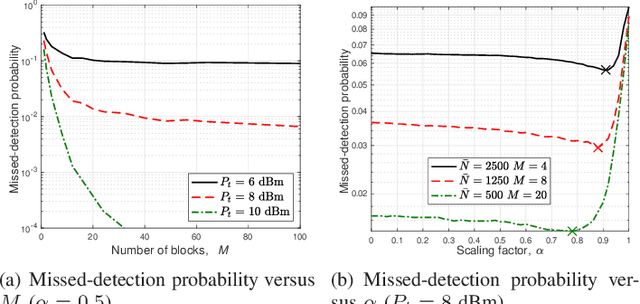
Spectrum sensing is a key enabling technique for cognitive radio (CR), which provides essential information on the spectrum availability. However, due to severe wireless channel fading and path loss, the primary user (PU) signals received at the CR or secondary user (SU) can be practically too weak for reliable detection. To tackle this issue, we consider in this letter a new intelligent reflecting surface (IRS)-aided spectrum sensing scheme for CR, by exploiting the large aperture and passive beamforming gains of IRS to boost the PU signal strength received at the SU to facilitate its spectrum sensing. Specifically, by dynamically changing the IRS reflection over time according to a given codebook, its reflected signal power varies substantially at the SU, which is utilized for opportunistic signal detection. Furthermore, we propose a weighted energy detection method by combining the received signal power values over different IRS reflections, which significantly improves the detection performance. Simulation results validate the performance gain of the proposed IRS-aided spectrum sensing scheme, as compared to different benchmark schemes.
* Accepted by IEEE Wireless Communications Letters (5 pages, 4 figures)
Learning on Arbitrary Graph Topologies via Predictive Coding
Feb 05, 2022

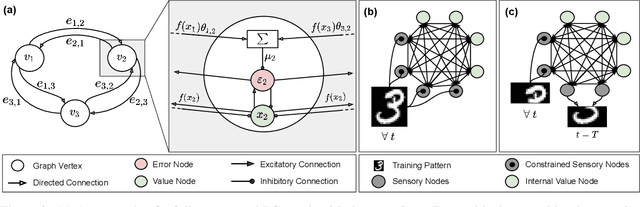

Training with backpropagation (BP) in standard deep learning consists of two main steps: a forward pass that maps a data point to its prediction, and a backward pass that propagates the error of this prediction back through the network. This process is highly effective when the goal is to minimize a specific objective function. However, it does not allow training on networks with cyclic or backward connections. This is an obstacle to reaching brain-like capabilities, as the highly complex heterarchical structure of the neural connections in the neocortex are potentially fundamental for its effectiveness. In this paper, we show how predictive coding (PC), a theory of information processing in the cortex, can be used to perform inference and learning on arbitrary graph topologies. We experimentally show how this formulation, called PC graphs, can be used to flexibly perform different tasks with the same network by simply stimulating specific neurons, and investigate how the topology of the graph influences the final performance. We conclude by comparing against simple baselines trained~with~BP.
You Only Cut Once: Boosting Data Augmentation with a Single Cut
Jan 28, 2022
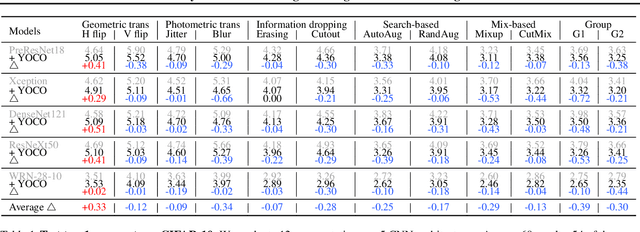

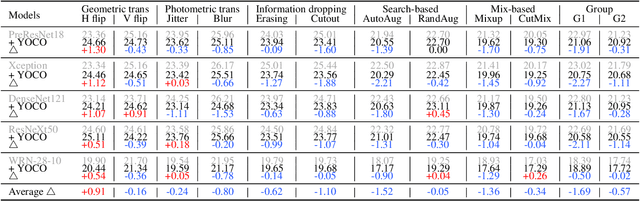
We present You Only Cut Once (YOCO) for performing data augmentations. YOCO cuts one image into two pieces and performs data augmentations individually within each piece. Applying YOCO improves the diversity of the augmentation per sample and encourages neural networks to recognize objects from partial information. YOCO enjoys the properties of parameter-free, easy usage, and boosting almost all augmentations for free. Thorough experiments are conducted to evaluate its effectiveness. We first demonstrate that YOCO can be seamlessly applied to varying data augmentations, neural network architectures, and brings performance gains on CIFAR and ImageNet classification tasks, sometimes surpassing conventional image-level augmentation by large margins. Moreover, we show YOCO benefits contrastive pre-training toward a more powerful representation that can be better transferred to multiple downstream tasks. Finally, we study a number of variants of YOCO and empirically analyze the performance for respective settings. Code is available at GitHub.
Differential Modulation in Massive MIMO With Low-Resolution ADCs
Nov 12, 2021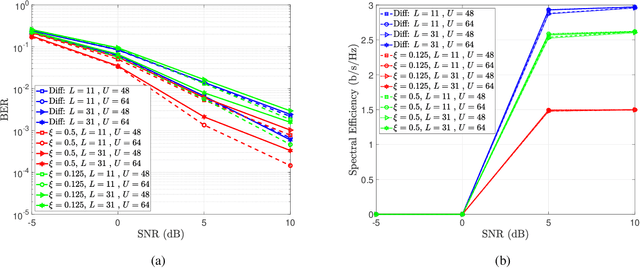
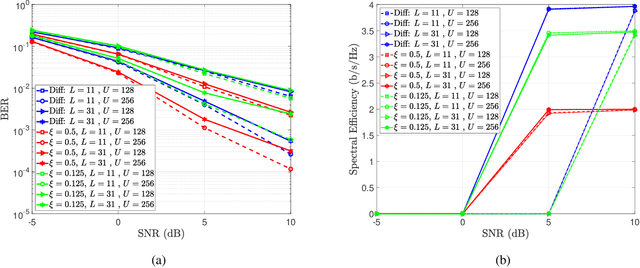
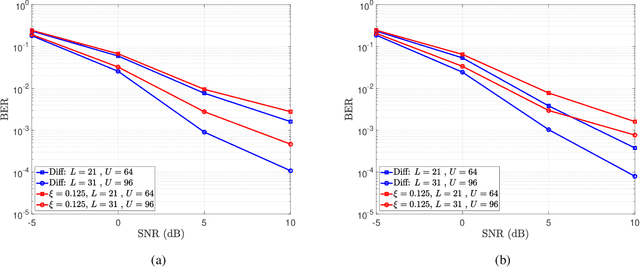
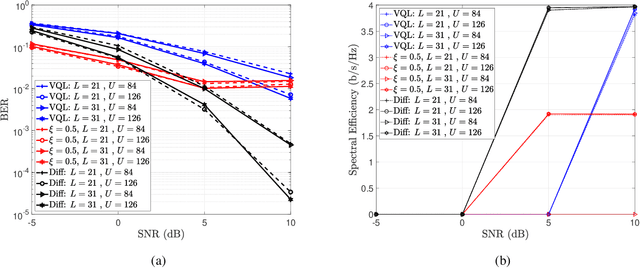
In this paper, we present a differential modulation and detection scheme for use in the uplink of a system with a large number of antennas at the base station, each equipped with low-resolution analog-to-digital converters (ADCs). We derive an expression for the maximum likelihood (ML) detector of a differentially encoded phase information symbol received by a base station operating in the low-resolution ADC regime. We also present an equal performing reduced complexity receiver for detecting the phase information. To increase the supported data rate, we also present a maximum likelihood expression to detect differential amplitude phase shift keying symbols with low-resolution ADCs. We note that the derived detectors are unable to detect the amplitude information. To overcome this limitation, we use the Bussgang Theorem and the Central Limit Theorem (CLT) to develop two detectors capable of detecting the amplitude information. We numerically show that while the first amplitude detector requires multiple quantization bits for acceptable performance, similar performance can be achieved using one-bit ADCs by grouping the receive antennas and employing variable quantization levels (VQL) across distinct antenna groups. We validate the performance of the proposed detectors through simulations and show a comparison with corresponding coherent detectors. Finally, we present a complexity analysis of the proposed low-resolution differential detectors
Robust Estimation of Discrete Distributions under Local Differential Privacy
Feb 14, 2022Although robust learning and local differential privacy are both widely studied fields of research, combining the two settings is an almost unexplored topic. We consider the problem of estimating a discrete distribution in total variation from $n$ contaminated data batches under a local differential privacy constraint. A fraction $1-\epsilon$ of the batches contain $k$ i.i.d. samples drawn from a discrete distribution $p$ over $d$ elements. To protect the users' privacy, each of the samples is privatized using an $\alpha$-locally differentially private mechanism. The remaining $\epsilon n $ batches are an adversarial contamination. The minimax rate of estimation under contamination alone, with no privacy, is known to be $\epsilon/\sqrt{k}+\sqrt{d/kn}$, up to a $\sqrt{\log(1/\epsilon)}$ factor. Under the privacy constraint alone, the minimax rate of estimation is $\sqrt{d^2/\alpha^2 kn}$. We show that combining the two constraints leads to a minimax estimation rate of $\epsilon\sqrt{d/\alpha^2 k}+\sqrt{d^2/\alpha^2 kn}$ up to a $\sqrt{\log(1/\epsilon)}$ factor, larger than the sum of the two separate rates. We provide a polynomial-time algorithm achieving this bound, as well as a matching information theoretic lower bound.
TATTOOED: A Robust Deep Neural Network Watermarking Scheme based on Spread-Spectrum Channel Coding
Feb 22, 2022
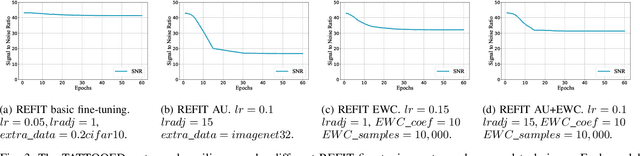
The proliferation of deep learning applications in several areas has led to the rapid adoption of such solutions from an ever-growing number of institutions and companies. These entities' deep neural network (DNN) models are often trained on proprietary data. They require powerful computational resources, with the resulting DNN models being incorporated in the company's work pipeline or provided as a service. Being trained on proprietary information, these models provide a competitive edge for the owner company. At the same time, these models can be attractive to competitors (or malicious entities), which can employ state-of-the-art security attacks to obtain and use these models for their benefit. As these attacks are hard to prevent, it becomes imperative to have mechanisms that enable an affected entity to verify the ownership of its DNN with high confidence. This paper presents TATTOOED, a robust and efficient DNN watermarking technique based on spread-spectrum channel coding. TATTOOED has a negligible effect on the performance of the DNN model and is robust against several state-of-the-art mechanisms used to remove watermarks from DNNs. Our results show that TATTOOED is robust to such removal techniques even in extreme scenarios. For example, if the removal techniques such as fine-tuning and parameter pruning change as much as 99% of the model parameters, the TATTOOED watermark is still present in full in the DNN model and ensures ownership verification.
Neural Approximation of Extended Persistent Homology on Graphs
Jan 28, 2022

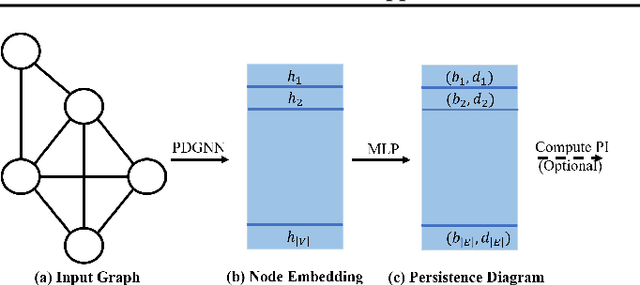
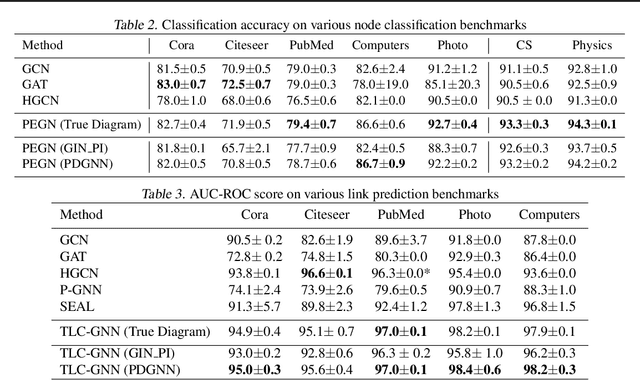
Persistent homology is a widely used theory in topological data analysis. In the context of graph learning, topological features based on persistent homology have been used to capture potentially high-order structural information so as to augment existing graph neural network methods. However, computing extended persistent homology summaries remains slow for large and dense graphs, especially since in learning applications one has to carry out this computation potentially many times. Inspired by recent success in neural algorithmic reasoning, we propose a novel learning method to compute extended persistence diagrams on graphs. The proposed neural network aims to simulate a specific algorithm and learns to compute extended persistence diagrams for new graphs efficiently. Experiments on approximating extended persistence diagrams and several downstream graph representation learning tasks demonstrate the effectiveness of our method. Our method is also efficient; on large and dense graphs, we accelerate the computation by nearly 100 times.
Information Theoretic Sample Complexity Lower Bound for Feed-Forward Fully-Connected Deep Networks
Jul 01, 2020In this paper, we study the sample complexity lower bound of a $d$-layer feed-forward, fully-connected neural network for binary classification, using information-theoretic tools. Specifically, we propose a backward data generating process, where the input is generated based on the binary output, and the network is parametrized by weight parameters for the hidden layers. The sample complexity lower bound is of order $\Omega(\log(r) + p / (r d))$, where $p$ is the dimension of the input, $r$ is the rank of the weight matrices, and $d$ is the number of hidden layers. To the best of our knowledge, our result is the first information theoretic sample complexity lower bound.
L_DMI: An Information-theoretic Noise-robust Loss Function
Sep 08, 2019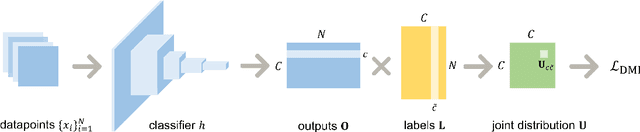

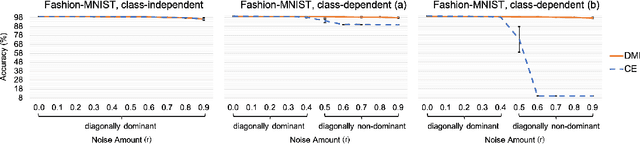
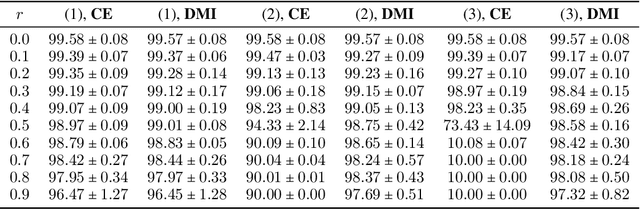
Accurately annotating large scale dataset is notoriously expensive both in time and in money. Although acquiring low-quality-annotated dataset can be much cheaper, it often badly damages the performance of trained models when using such dataset without particular treatment. Various of methods have been proposed for learning with noisy labels. However, they only handle limited kinds of noise patterns, require auxiliary information (e.g,, the noise transition matrix), or lack theoretical justification. In this paper, we propose a novel information-theoretic loss function, $\mathcal{L}_{\rm DMI}$, for training deep neural networks robust to label noise. The core of $\mathcal{L}_{\rm DMI}$ is a generalized version of mutual information, termed Determinant based Mutual Information (DMI), which is not only information-monotone but also relatively invariant. \emph{To the best of our knowledge, $\mathcal{L}_{\rm DMI}$ is the first loss function that is provably not sensitive to noise patterns and noise amounts, and it can be applied to any existing classification neural networks straightforwardly without any auxiliary information}. In addition to theoretical justification, we also empirically show that using $\mathcal{L}_{\rm DMI}$ outperforms all other counterparts in the classification task on Fashion-MNIST, CIFAR-10, Dogs vs. Cats datasets with a variety of synthesized noise patterns and noise amounts as well as a real-world dataset Clothing1M. Codes are available at https://github.com/Newbeeer/L_DMI
Learning Semantics for Visual Place Recognition through Multi-Scale Attention
Jan 25, 2022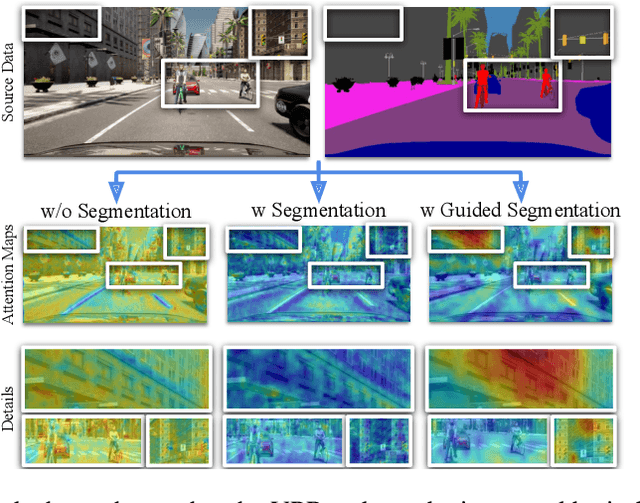
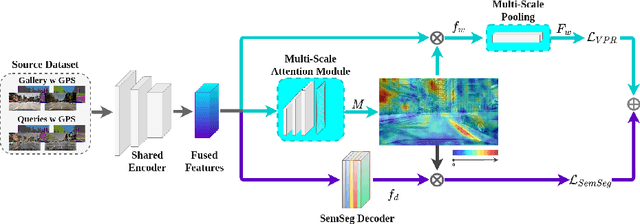
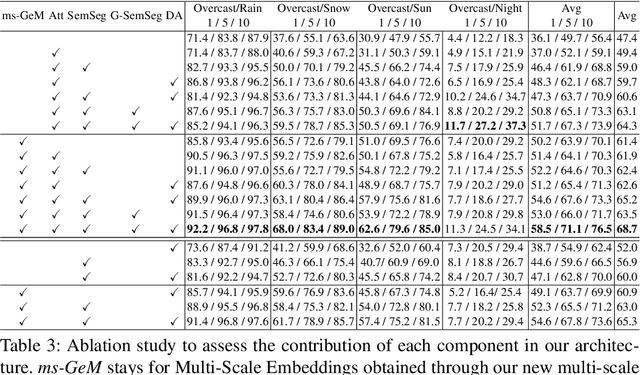
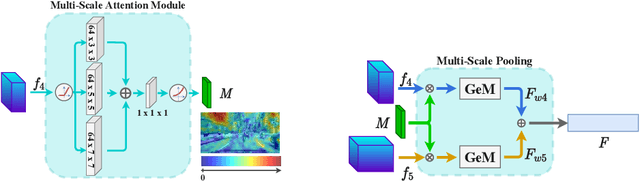
In this paper we address the task of visual place recognition (VPR), where the goal is to retrieve the correct GPS coordinates of a given query image against a huge geotagged gallery. While recent works have shown that building descriptors incorporating semantic and appearance information is beneficial, current state-of-the-art methods opt for a top down definition of the significant semantic content. Here we present the first VPR algorithm that learns robust global embeddings from both visual appearance and semantic content of the data, with the segmentation process being dynamically guided by the recognition of places through a multi-scale attention module. Experiments on various scenarios validate this new approach and demonstrate its performance against state-of-the-art methods. Finally, we propose the first synthetic-world dataset suited for both place recognition and segmentation tasks.