 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Revisiting Over-Smoothness in Text to Speech
Feb 26, 2022



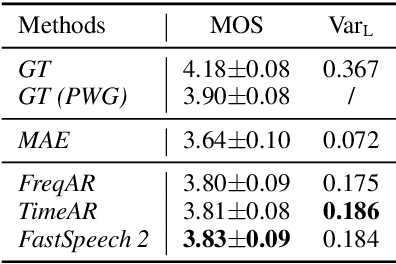
Non-autoregressive text to speech (NAR-TTS) models have attracted much attention from both academia and industry due to their fast generation speed. One limitation of NAR-TTS models is that they ignore the correlation in time and frequency domains while generating speech mel-spectrograms, and thus cause blurry and over-smoothed results. In this work, we revisit this over-smoothing problem from a novel perspective: the degree of over-smoothness is determined by the gap between the complexity of data distributions and the capability of modeling methods. Both simplifying data distributions and improving modeling methods can alleviate the problem. Accordingly, we first study methods reducing the complexity of data distributions. Then we conduct a comprehensive study on NAR-TTS models that use some advanced modeling methods. Based on these studies, we find that 1) methods that provide additional condition inputs reduce the complexity of data distributions to model, thus alleviating the over-smoothing problem and achieving better voice quality. 2) Among advanced modeling methods, Laplacian mixture loss performs well at modeling multimodal distributions and enjoys its simplicity, while GAN and Glow achieve the best voice quality while suffering from increased training or model complexity. 3) The two categories of methods can be combined to further alleviate the over-smoothness and improve the voice quality. 4) Our experiments on the multi-speaker dataset lead to similar conclusions as above and providing more variance information can reduce the difficulty of modeling the target data distribution and alleviate the requirements for model capacity.
Graph Attention Retrospective
Feb 26, 2022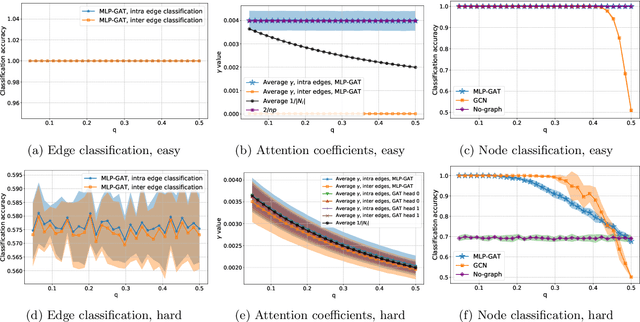
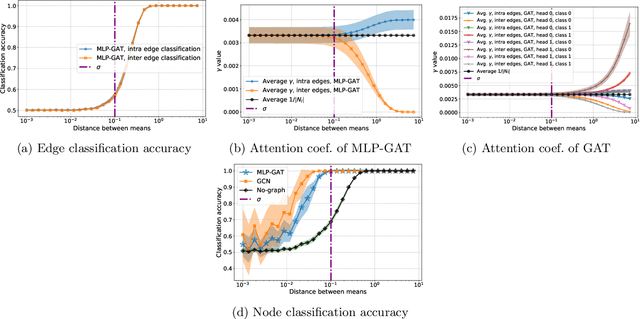
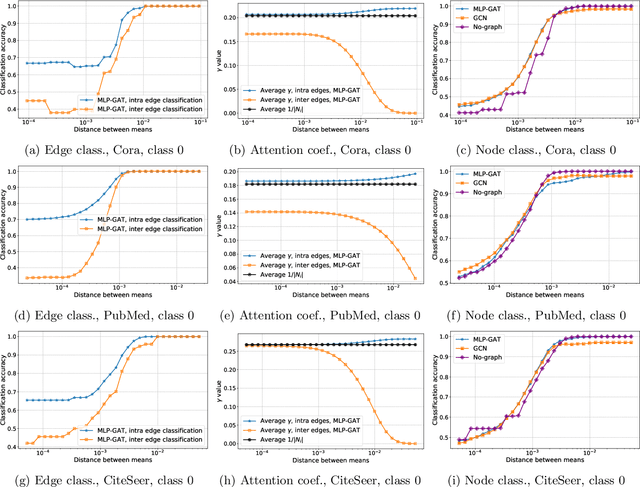
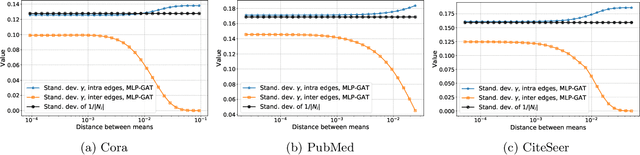
Graph-based learning is a rapidly growing sub-field of machine learning with applications in social networks, citation networks, and bioinformatics. One of the most popular type of models is graph attention networks. These models were introduced to allow a node to aggregate information from the features of neighbor nodes in a non-uniform way in contrast to simple graph convolution which does not distinguish the neighbors of a node. In this paper, we study theoretically this expected behaviour of graph attention networks. We prove multiple results on the performance of the graph attention mechanism for the problem of node classification for a contextual stochastic block model. Here the features of the nodes are obtained from a mixture of Gaussians and the edges from a stochastic block model where the features and the edges are coupled in a natural way. First, we show that in an "easy" regime, where the distance between the means of the Gaussians is large enough, graph attention maintains the weights of intra-class edges and significantly reduces the weights of the inter-class edges. As a corollary, we show that this implies perfect node classification independent of the weights of inter-class edges. However, a classical argument shows that in the "easy" regime, the graph is not needed at all to classify the data with high probability. In the "hard" regime, we show that every attention mechanism fails to distinguish intra-class from inter-class edges. We evaluate our theoretical results on synthetic and real-world data.
Safe Optimal Design with Applications in Policy Learning
Nov 08, 2021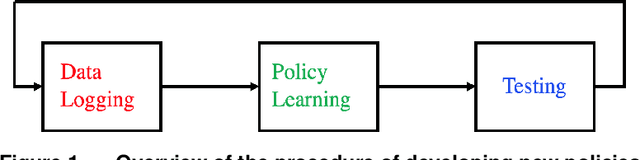
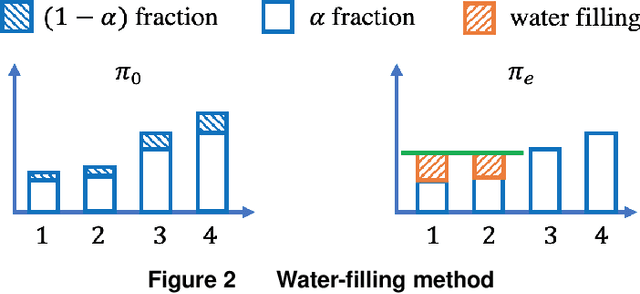
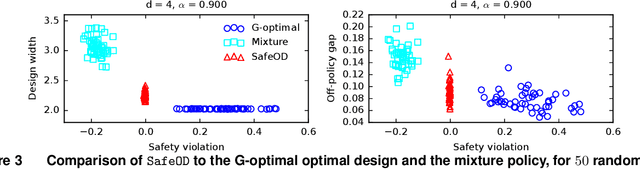
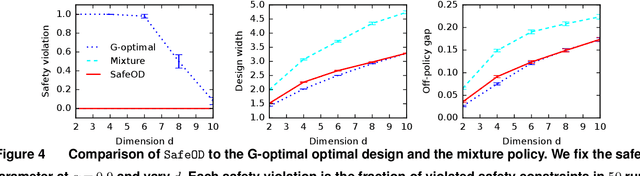
Motivated by practical needs in online experimentation and off-policy learning, we study the problem of safe optimal design, where we develop a data logging policy that efficiently explores while achieving competitive rewards with a baseline production policy. We first show, perhaps surprisingly, that a common practice of mixing the production policy with uniform exploration, despite being safe, is sub-optimal in maximizing information gain. Then we propose a safe optimal logging policy for the case when no side information about the actions' expected rewards is available. We improve upon this design by considering side information and also extend both approaches to a large number of actions with a linear reward model. We analyze how our data logging policies impact errors in off-policy learning. Finally, we empirically validate the benefit of our designs by conducting extensive experiments.
Cooperative Online Learning in Stochastic and Adversarial MDPs
Jan 31, 2022
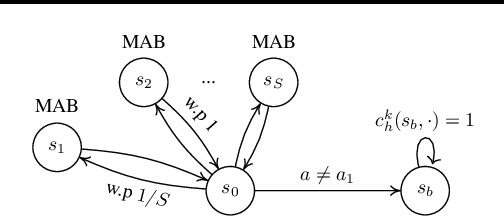
We study cooperative online learning in stochastic and adversarial Markov decision process (MDP). That is, in each episode, $m$ agents interact with an MDP simultaneously and share information in order to minimize their individual regret. We consider environments with two types of randomness: \emph{fresh} -- where each agent's trajectory is sampled i.i.d, and \emph{non-fresh} -- where the realization is shared by all agents (but each agent's trajectory is also affected by its own actions). More precisely, with non-fresh randomness the realization of every cost and transition is fixed at the start of each episode, and agents that take the same action in the same state at the same time observe the same cost and next state. We thoroughly analyze all relevant settings, highlight the challenges and differences between the models, and prove nearly-matching regret lower and upper bounds. To our knowledge, we are the first to consider cooperative reinforcement learning (RL) with either non-fresh randomness or in adversarial MDPs.
Unsupervised Anomaly Detection in MR Images using Multi-Contrast Information
May 19, 2021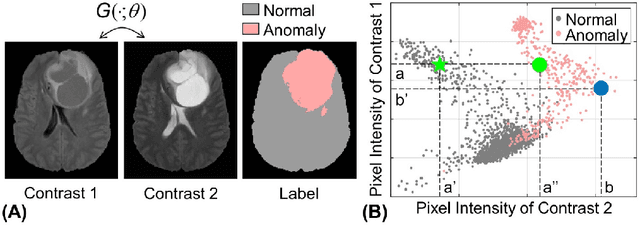
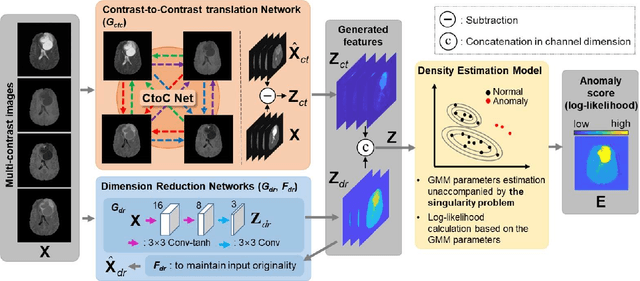
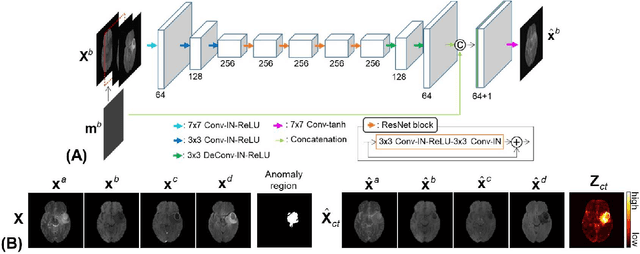
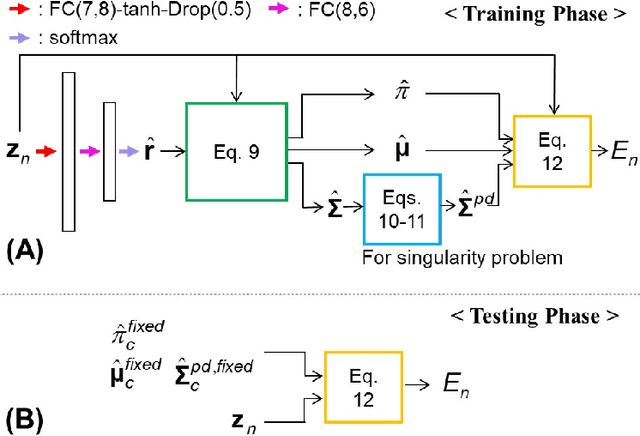
Anomaly detection in medical imaging is to distinguish the relevant biomarkers of diseases from those of normal tissues. Deep supervised learning methods have shown potentials in various detection tasks, but its performances would be limited in medical imaging fields where collecting annotated anomaly data is limited and labor-intensive. Therefore, unsupervised anomaly detection can be an effective tool for clinical practices, which uses only unlabeled normal images as training data. In this paper, we developed an unsupervised learning framework for pixel-wise anomaly detection in multi-contrast magnetic resonance imaging (MRI). The framework has two steps of feature generation and density estimation with Gaussian mixture model (GMM). A feature is derived through the learning of contrast-to-contrast translation that effectively captures the normal tissue characteristics in multi-contrast MRI. The feature is collaboratively used with another feature that is the low-dimensional representation of multi-contrast images. In density estimation using GMM, a simple but efficient way is introduced to handle the singularity problem which interrupts the joint learning process. The proposed method outperforms previous anomaly detection approaches. Quantitative and qualitative analyses demonstrate the effectiveness of the proposed method in anomaly detection for multi-contrast MRI.
DyHGCN: A Dynamic Heterogeneous Graph Convolutional Network to Learn Users' Dynamic Preferences for Information Diffusion Prediction
Jun 09, 2020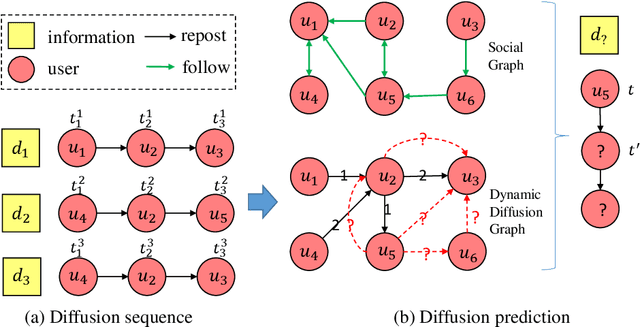
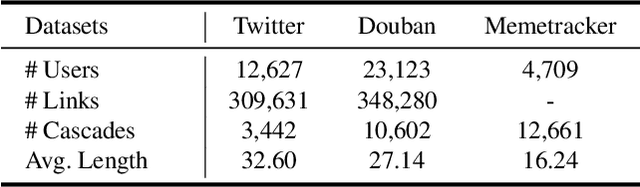
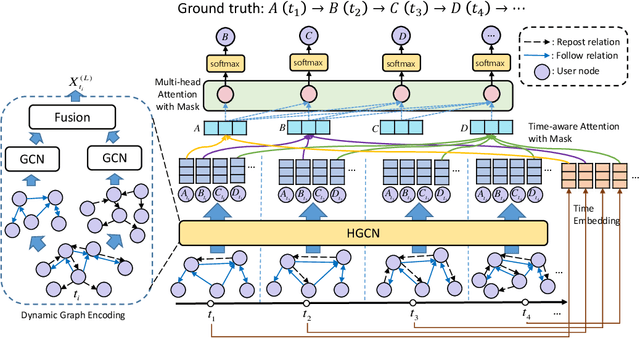
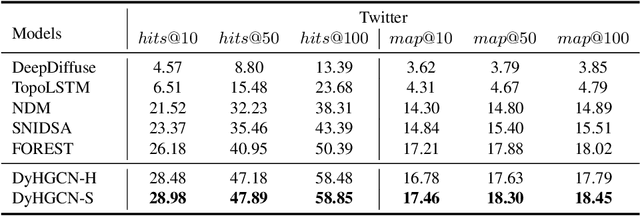
Information diffusion prediction is a fundamental task for understanding the information propagation process. It has wide applications in such as misinformation spreading prediction and malicious account detection. Previous works either concentrate on utilizing the context of a single diffusion sequence or using the social network among users for information diffusion prediction. However, the diffusion paths of different messages naturally constitute a dynamic diffusion graph. For one thing, previous works cannot jointly utilize both the social network and diffusion graph for prediction, which is insufficient to model the complexity of the diffusion process and results in unsatisfactory prediction performance. For another, they cannot learn users' dynamic preferences. Intuitively, users' preferences are changing as time goes on and users' personal preference determines whether the user will repost the information. Thus, it is beneficial to consider users' dynamic preferences in information diffusion prediction. In this paper, we propose a novel dynamic heterogeneous graph convolutional network (DyHGCN) to jointly learn the structural characteristics of the social graph and dynamic diffusion graph. Then, we encode the temporal information into the heterogeneous graph to learn the users' dynamic preferences. Finally, we apply multi-head attention to capture the context-dependency of the current diffusion path to facilitate the information diffusion prediction task. Experimental results show that DyHGCN significantly outperforms the state-of-the-art models on three public datasets, which shows the effectiveness of the proposed model.
Convex Polytope Modelling for Unsupervised Derivation of Semantic Structure for Data-efficient Natural Language Understanding
Jan 25, 2022
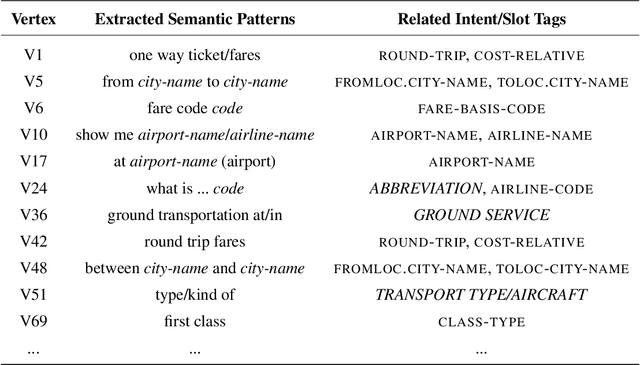
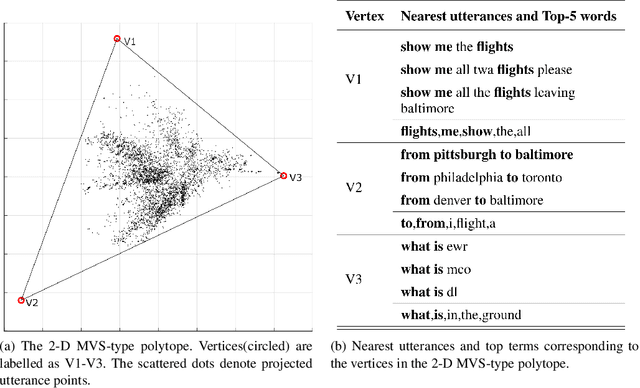
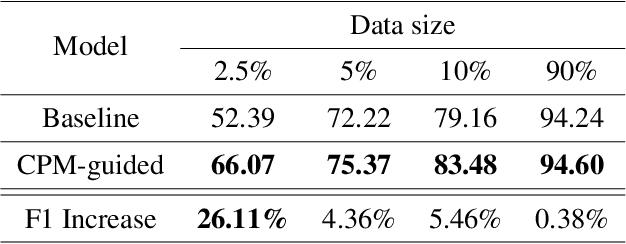
Popular approaches for Natural Language Understanding (NLU) usually rely on a huge amount of annotated data or handcrafted rules, which is laborious and not adaptive to domain extension. We recently proposed a Convex-Polytopic-Model-based framework that shows great potential in automatically extracting semantic patterns by exploiting the raw dialog corpus. The extracted semantic patterns can be used to generate semantic frames, which is essential in assisting NLU tasks. This paper further studies the CPM model in depth and visualizes its high interpretability and transparency at various levels. We show that this framework can exploit semantic-frame-related features in the corpus, reveal the underlying semantic structure of the utterances, and boost the performance of the state-of-the-art NLU model with minimal supervision. We conduct our experiments on the ATIS (Air Travel Information System) corpus.
Compositionality-Aware Graph2Seq Learning
Jan 28, 2022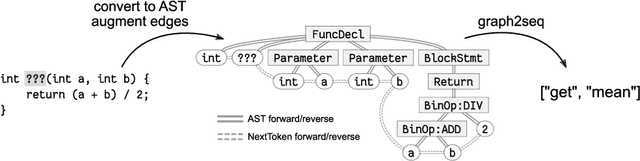
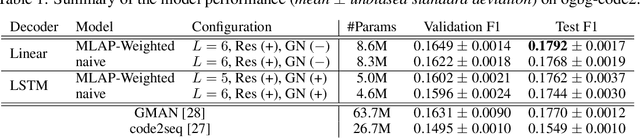
Graphs are a highly expressive data structure, but it is often difficult for humans to find patterns from a complex graph. Hence, generating human-interpretable sequences from graphs have gained interest, called graph2seq learning. It is expected that the compositionality in a graph can be associated to the compositionality in the output sequence in many graph2seq tasks. Therefore, applying compositionality-aware GNN architecture would improve the model performance. In this study, we adopt the multi-level attention pooling (MLAP) architecture, that can aggregate graph representations from multiple levels of information localities. As a real-world example, we take up the extreme source code summarization task, where a model estimate the name of a program function from its source code. We demonstrate that the model having the MLAP architecture outperform the previous state-of-the-art model with more than seven times fewer parameters than it.
PostGAN: A GAN-Based Post-Processor to Enhance the Quality of Coded Speech
Jan 31, 2022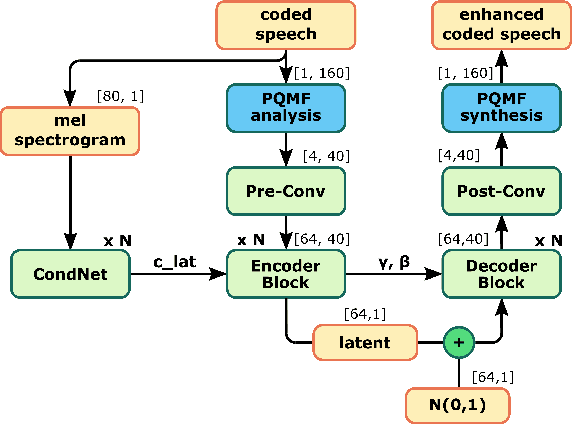
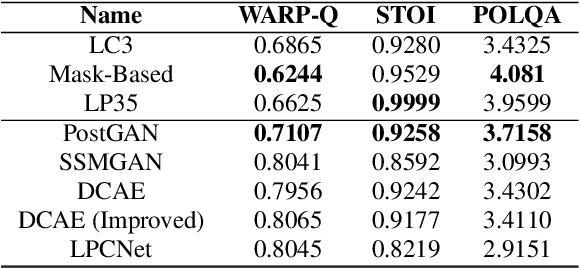
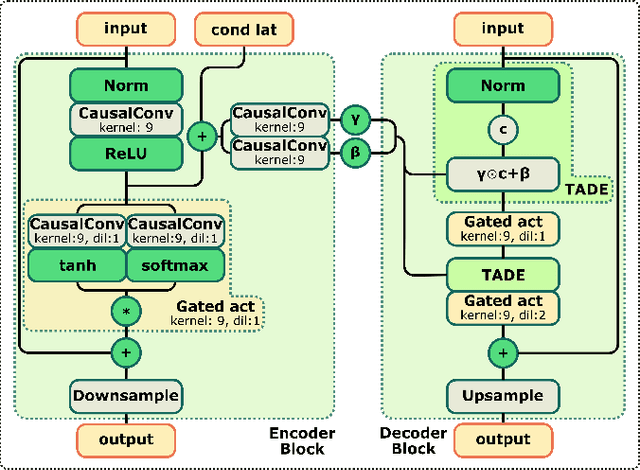
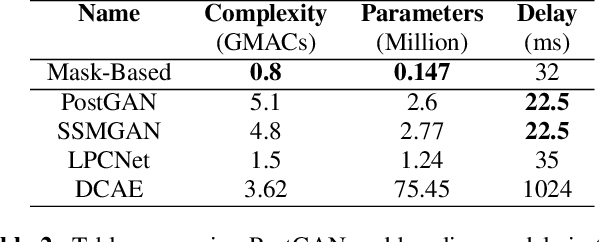
The quality of speech coded by transform coding is affected by various artefacts especially when bitrates to quantize the frequency components become too low. In order to mitigate these coding artefacts and enhance the quality of coded speech, a post-processor that relies on a-priori information transmitted from the encoder is traditionally employed at the decoder side. In recent years, several data-driven post-postprocessors have been proposed which were shown to outperform traditional approaches. In this paper, we propose PostGAN, a GAN-based neural post-processor that operates in the sub-band domain and relies on the U-Net architecture and a learned affine transform. It has been tested on the recently standardized low-complexity, low-delay bluetooth codec (LC3) for wideband speech at the lowest bitrate (16 kbit/s). Subjective evaluations and objective scores show that the newly introduced post-processor surpasses previously published methods and can improve the quality of coded speech by around 20 MUSHRA points.
Accelerated Information Gradient flow
Sep 04, 2019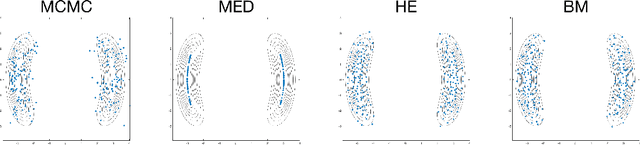
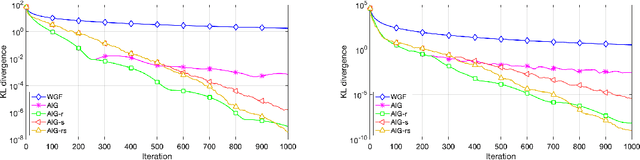
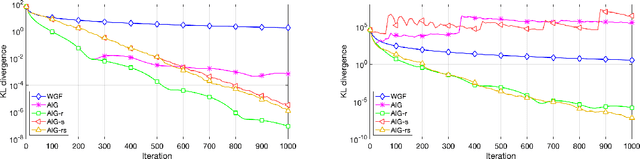
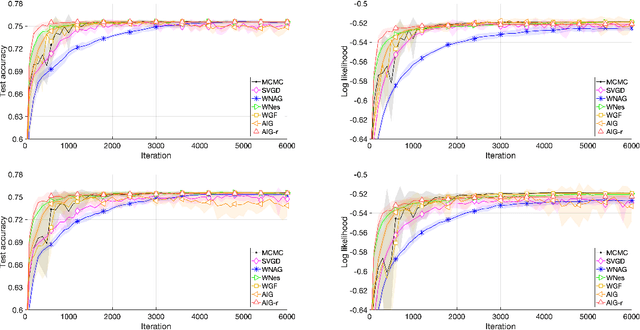
We present a systematic framework for the Nesterov's accelerated gradient flows in the spaces of probabilities embedded with information metrics. Here two metrics are considered, including both the Fisher-Rao metric and the Wasserstein-$2$ metric. For the Wasserstein-$2$ metric case, we prove the convergence properties of the accelerated gradient flows, and introduce their formulations in Gaussian families. Furthermore, we propose a practical discrete-time algorithm in particle implementations with an adaptive restart technique. We formulate a novel bandwidth selection method, which learns the Wasserstein-$2$ gradient direction from Brownian-motion samples. Experimental results including Bayesian inference show the strength of the current method compared with the state-of-the-art.