 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Node-Level Differentially Private Graph Neural Networks
Nov 23, 2021
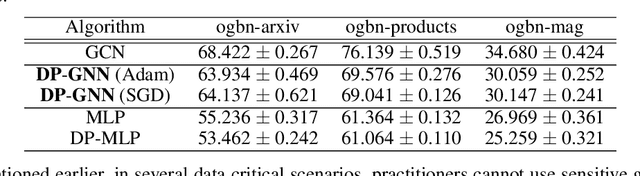
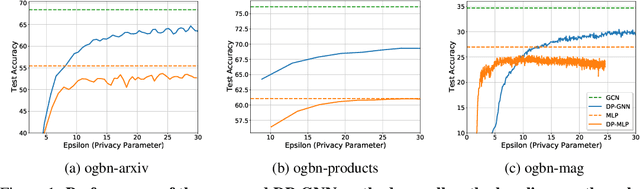
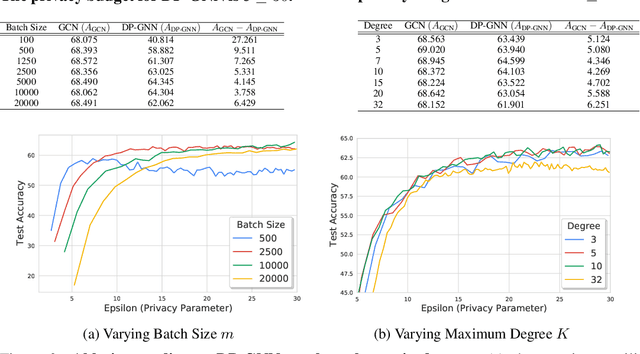
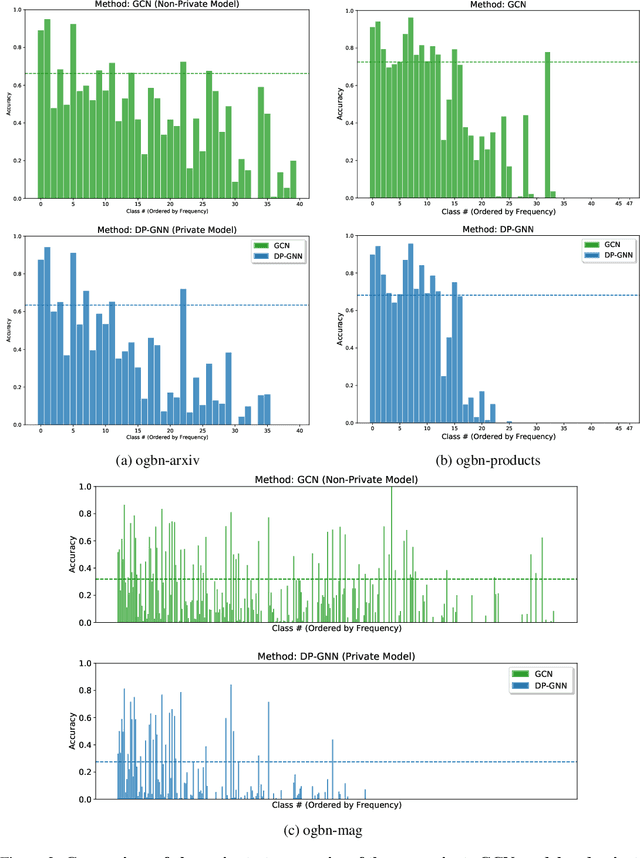
Graph Neural Networks (GNNs) are a popular technique for modelling graph-structured data that compute node-level representations via aggregation of information from the local neighborhood of each node. However, this aggregation implies increased risk of revealing sensitive information, as a node can participate in the inference for multiple nodes. This implies that standard privacy preserving machine learning techniques, such as differentially private stochastic gradient descent (DP-SGD) - which are designed for situations where each data point participates in the inference for one point only - either do not apply, or lead to inaccurate solutions. In this work, we formally define the problem of learning 1-layer GNNs with node-level privacy, and provide an algorithmic solution with a strong differential privacy guarantee. Even though each node can be involved in the inference for multiple nodes, by employing a careful sensitivity analysis anda non-trivial extension of the privacy-by-amplification technique, our method is able to provide accurate solutions with solid privacy parameters. Empirical evaluation on standard benchmarks demonstrates that our method is indeed able to learn accurate privacy preserving GNNs, while still outperforming standard non-private methods that completely ignore graph information.
Modeling Personalized Item Frequency Information for Next-basket Recommendation
May 31, 2020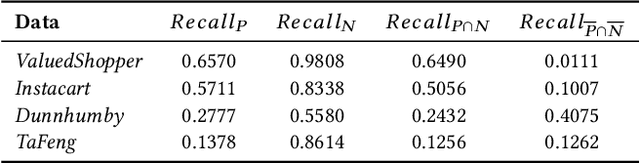
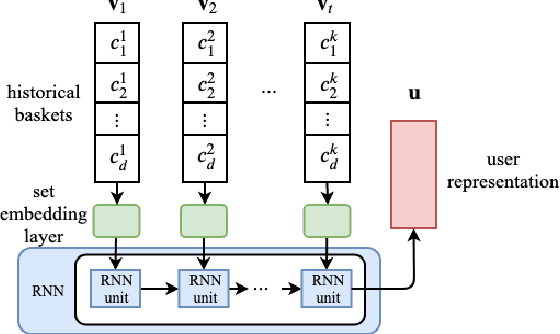
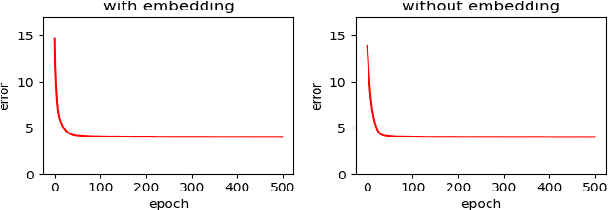
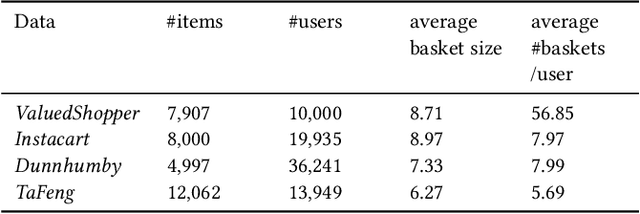
Next-basket recommendation (NBR) is prevalent in e-commerce and retail industry. In this scenario, a user purchases a set of items (a basket) at a time. NBR performs sequential modeling and recommendation based on a sequence of baskets. NBR is in general more complex than the widely studied sequential (session-based) recommendation which recommends the next item based on a sequence of items. Recurrent neural network (RNN) has proved to be very effective for sequential modeling and thus been adapted for NBR. However, we argue that existing RNNs cannot directly capture item frequency information in the recommendation scenario. Through careful analysis of real-world datasets, we find that {\em personalized item frequency} (PIF) information (which records the number of times that each item is purchased by a user) provides two critical signals for NBR. But, this has been largely ignored by existing methods. Even though existing methods such as RNN based methods have strong representation ability, our empirical results show that they fail to learn and capture PIF. As a result, existing methods cannot fully exploit the critical signals contained in PIF. Given this inherent limitation of RNNs, we propose a simple item frequency based k-nearest neighbors (kNN) method to directly utilize these critical signals. We evaluate our method on four public real-world datasets. Despite its relative simplicity, our method frequently outperforms the state-of-the-art NBR methods -- including deep learning based methods using RNNs -- when patterns associated with PIF play an important role in the data.
Neural Grapheme-to-Phoneme Conversion with Pre-trained Grapheme Models
Jan 26, 2022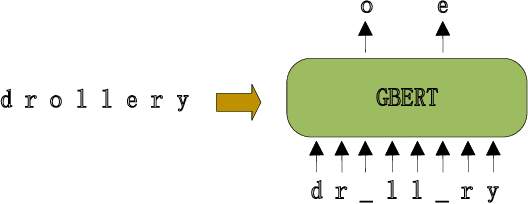

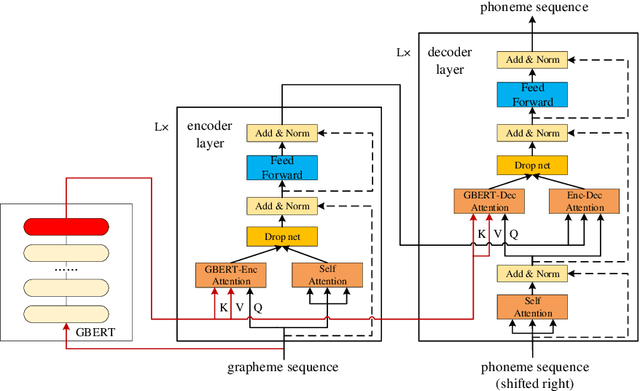
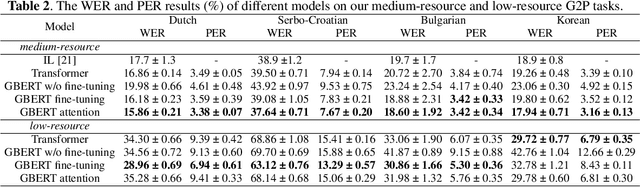
Neural network models have achieved state-of-the-art performance on grapheme-to-phoneme (G2P) conversion. However, their performance relies on large-scale pronunciation dictionaries, which may not be available for a lot of languages. Inspired by the success of the pre-trained language model BERT, this paper proposes a pre-trained grapheme model called grapheme BERT (GBERT), which is built by self-supervised training on a large, language-specific word list with only grapheme information. Furthermore, two approaches are developed to incorporate GBERT into the state-of-the-art Transformer-based G2P model, i.e., fine-tuning GBERT or fusing GBERT into the Transformer model by attention. Experimental results on the Dutch, Serbo-Croatian, Bulgarian and Korean datasets of the SIGMORPHON 2021 G2P task confirm the effectiveness of our GBERT-based G2P models under both medium-resource and low-resource data conditions.
A Compact Neural Network-based Algorithm for Robust Image Watermarking
Dec 27, 2021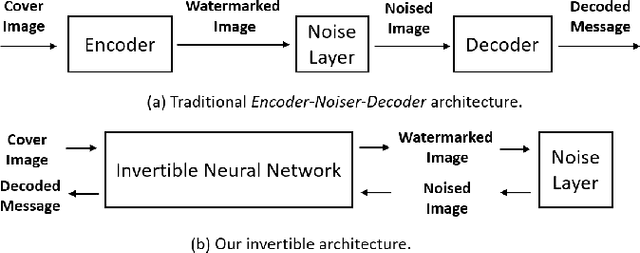
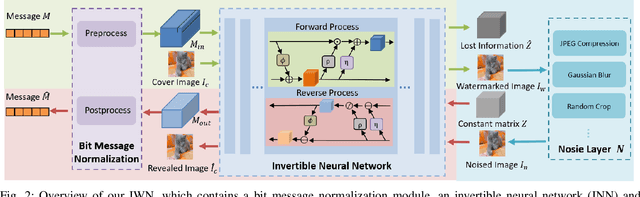
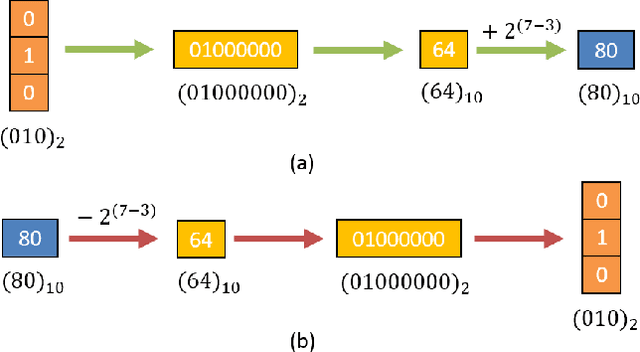
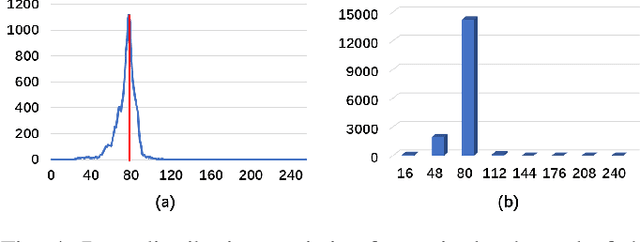
Digital image watermarking seeks to protect the digital media information from unauthorized access, where the message is embedded into the digital image and extracted from it, even some noises or distortions are applied under various data processing including lossy image compression and interactive content editing. Traditional image watermarking solutions easily suffer from robustness when specified with some prior constraints, while recent deep learning-based watermarking methods could not tackle the information loss problem well under various separate pipelines of feature encoder and decoder. In this paper, we propose a novel digital image watermarking solution with a compact neural network, named Invertible Watermarking Network (IWN). Our IWN architecture is based on a single Invertible Neural Network (INN), this bijective propagation framework enables us to effectively solve the challenge of message embedding and extraction simultaneously, by taking them as a pair of inverse problems for each other and learning a stable invertible mapping. In order to enhance the robustness of our watermarking solution, we specifically introduce a simple but effective bit message normalization module to condense the bit message to be embedded, and a noise layer is designed to simulate various practical attacks under our IWN framework. Extensive experiments demonstrate the superiority of our solution under various distortions.
Improving Unsupervised Domain Adaptation with Variational Information Bottleneck
Nov 21, 2019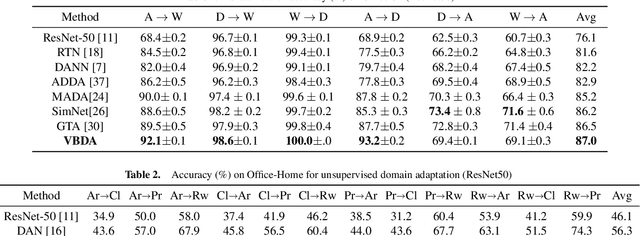
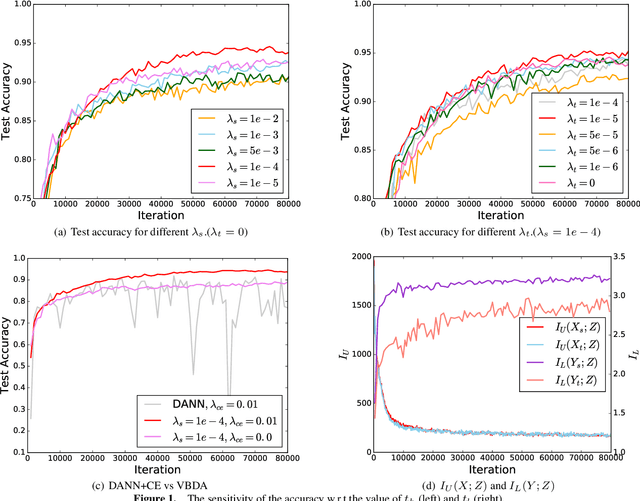
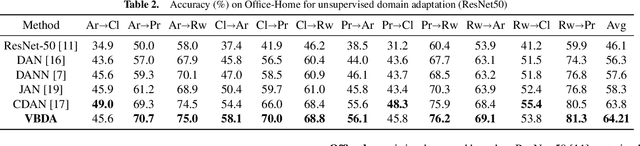
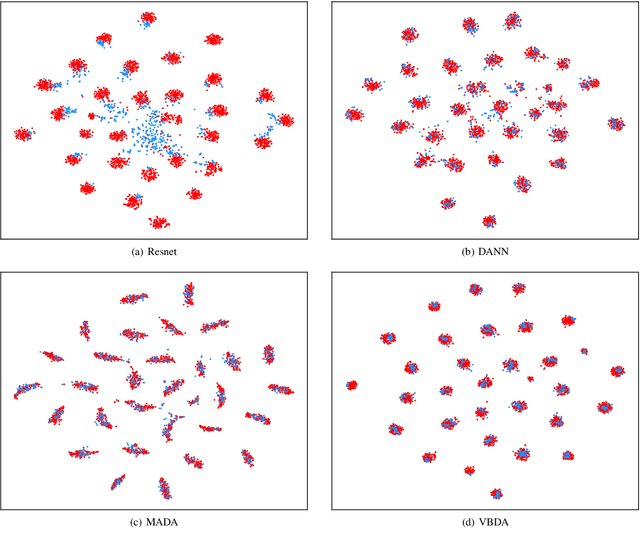
Domain adaptation aims to leverage the supervision signal of source domain to obtain an accurate model for target domain, where the labels are not available. To leverage and adapt the label information from source domain, most existing methods employ a feature extracting function and match the marginal distributions of source and target domains in a shared feature space. In this paper, from the perspective of information theory, we show that representation matching is actually an insufficient constraint on the feature space for obtaining a model with good generalization performance in target domain. We then propose variational bottleneck domain adaptation (VBDA), a new domain adaptation method which improves feature transferability by explicitly enforcing the feature extractor to ignore the task-irrelevant factors and focus on the information that is essential to the task of interest for both source and target domains. Extensive experimental results demonstrate that VBDA significantly outperforms state-of-the-art methods across three domain adaptation benchmark datasets.
Temporal Transformer Networks with Self-Supervision for Action Recognition
Dec 17, 2021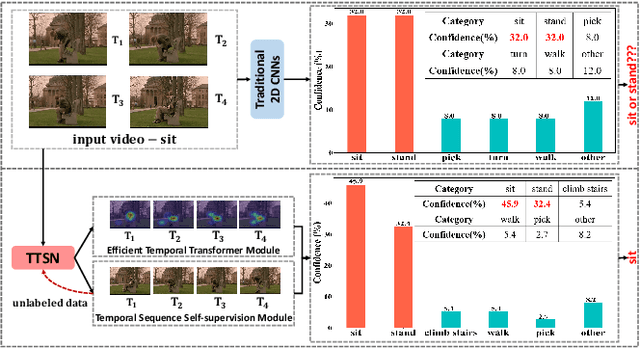
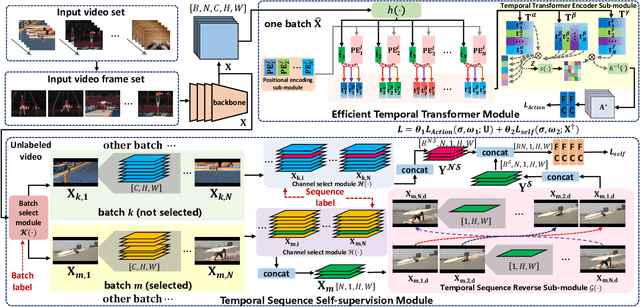
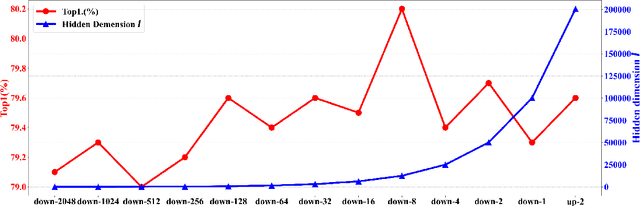
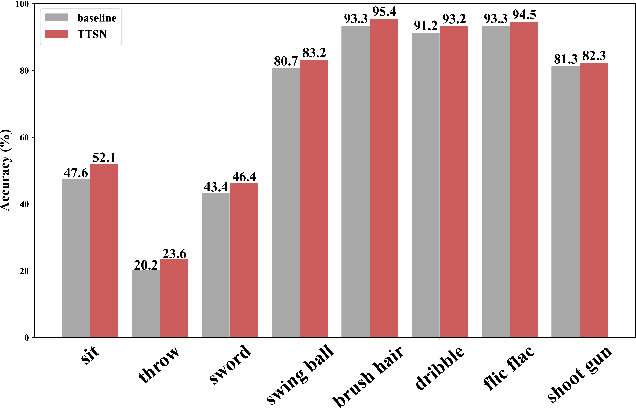
In recent years, 2D Convolutional Networks-based video action recognition has encouragingly gained wide popularity; However, constrained by the lack of long-range non-linear temporal relation modeling and reverse motion information modeling, the performance of existing models is, therefore, undercut seriously. To address this urgent problem, we introduce a startling Temporal Transformer Network with Self-supervision (TTSN). Our high-performance TTSN mainly consists of a temporal transformer module and a temporal sequence self-supervision module. Concisely speaking, we utilize the efficient temporal transformer module to model the non-linear temporal dependencies among non-local frames, which significantly enhances complex motion feature representations. The temporal sequence self-supervision module we employ unprecedentedly adopts the streamlined strategy of "random batch random channel" to reverse the sequence of video frames, allowing robust extractions of motion information representation from inversed temporal dimensions and improving the generalization capability of the model. Extensive experiments on three widely used datasets (HMDB51, UCF101, and Something-something V1) have conclusively demonstrated that our proposed TTSN is promising as it successfully achieves state-of-the-art performance for action recognition.
BiFSMN: Binary Neural Network for Keyword Spotting
Feb 15, 2022



The deep neural networks, such as the Deep-FSMN, have been widely studied for keyword spotting (KWS) applications. However, computational resources for these networks are significantly constrained since they usually run on-call on edge devices. In this paper, we present BiFSMN, an accurate and extreme-efficient binary neural network for KWS. We first construct a High-frequency Enhancement Distillation scheme for the binarization-aware training, which emphasizes the high-frequency information from the full-precision network's representation that is more crucial for the optimization of the binarized network. Then, to allow the instant and adaptive accuracy-efficiency trade-offs at runtime, we also propose a Thinnable Binarization Architecture to further liberate the acceleration potential of the binarized network from the topology perspective. Moreover, we implement a Fast Bitwise Computation Kernel for BiFSMN on ARMv8 devices which fully utilizes registers and increases instruction throughput to push the limit of deployment efficiency. Extensive experiments show that BiFSMN outperforms existing binarization methods by convincing margins on various datasets and is even comparable with the full-precision counterpart (e.g., less than 3% drop on Speech Commands V1-12). We highlight that benefiting from the thinnable architecture and the optimized 1-bit implementation, BiFSMN can achieve an impressive 22.3x speedup and 15.5x storage-saving on real-world edge hardware.
DyHGCN: A Dynamic Heterogeneous Graph Convolutional Network to Learn Users' Dynamic Preferences for Information Diffusion Prediction
Jun 09, 2020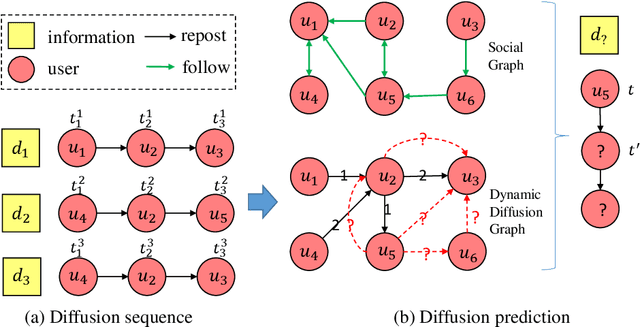
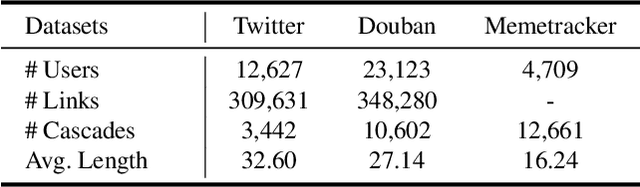
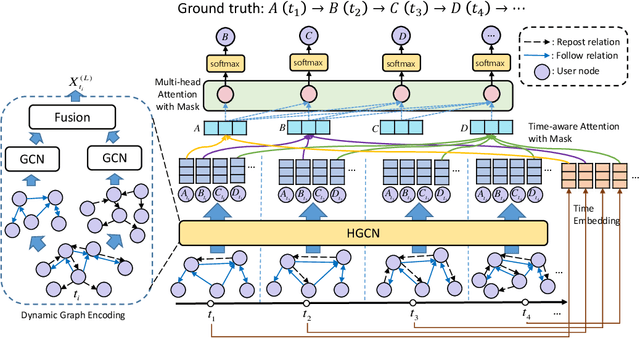
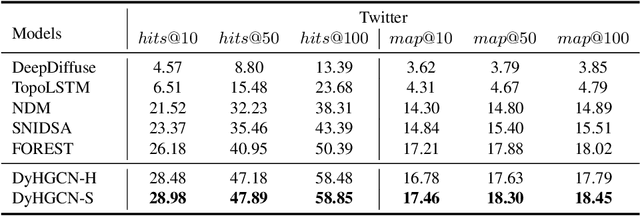
Information diffusion prediction is a fundamental task for understanding the information propagation process. It has wide applications in such as misinformation spreading prediction and malicious account detection. Previous works either concentrate on utilizing the context of a single diffusion sequence or using the social network among users for information diffusion prediction. However, the diffusion paths of different messages naturally constitute a dynamic diffusion graph. For one thing, previous works cannot jointly utilize both the social network and diffusion graph for prediction, which is insufficient to model the complexity of the diffusion process and results in unsatisfactory prediction performance. For another, they cannot learn users' dynamic preferences. Intuitively, users' preferences are changing as time goes on and users' personal preference determines whether the user will repost the information. Thus, it is beneficial to consider users' dynamic preferences in information diffusion prediction. In this paper, we propose a novel dynamic heterogeneous graph convolutional network (DyHGCN) to jointly learn the structural characteristics of the social graph and dynamic diffusion graph. Then, we encode the temporal information into the heterogeneous graph to learn the users' dynamic preferences. Finally, we apply multi-head attention to capture the context-dependency of the current diffusion path to facilitate the information diffusion prediction task. Experimental results show that DyHGCN significantly outperforms the state-of-the-art models on three public datasets, which shows the effectiveness of the proposed model.
Multi-Centroid Representation Network for Domain Adaptive Person Re-ID
Dec 22, 2021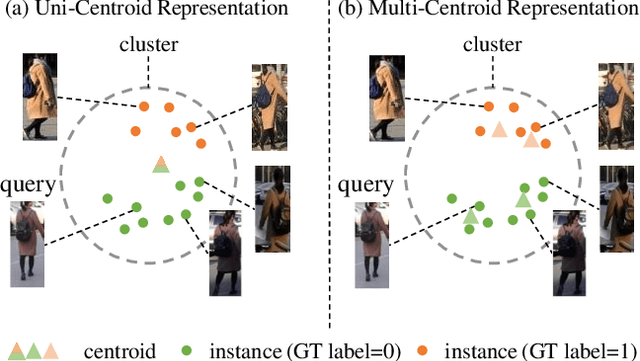
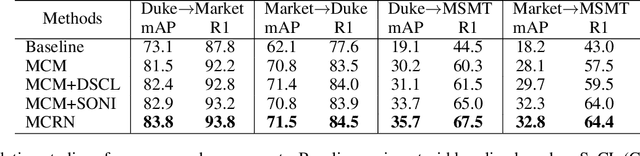
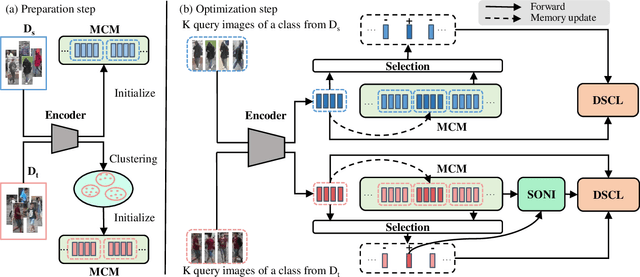
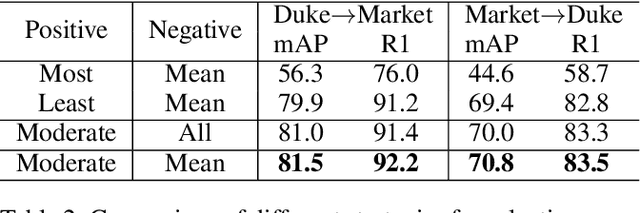
Recently, many approaches tackle the Unsupervised Domain Adaptive person re-identification (UDA re-ID) problem through pseudo-label-based contrastive learning. During training, a uni-centroid representation is obtained by simply averaging all the instance features from a cluster with the same pseudo label. However, a cluster may contain images with different identities (label noises) due to the imperfect clustering results, which makes the uni-centroid representation inappropriate. In this paper, we present a novel Multi-Centroid Memory (MCM) to adaptively capture different identity information within the cluster. MCM can effectively alleviate the issue of label noises by selecting proper positive/negative centroids for the query image. Moreover, we further propose two strategies to improve the contrastive learning process. First, we present a Domain-Specific Contrastive Learning (DSCL) mechanism to fully explore intradomain information by comparing samples only from the same domain. Second, we propose Second-Order Nearest Interpolation (SONI) to obtain abundant and informative negative samples. We integrate MCM, DSCL, and SONI into a unified framework named Multi-Centroid Representation Network (MCRN). Extensive experiments demonstrate the superiority of MCRN over state-of-the-art approaches on multiple UDA re-ID tasks and fully unsupervised re-ID tasks.
Unsupervised Anomaly Detection in MR Images using Multi-Contrast Information
May 19, 2021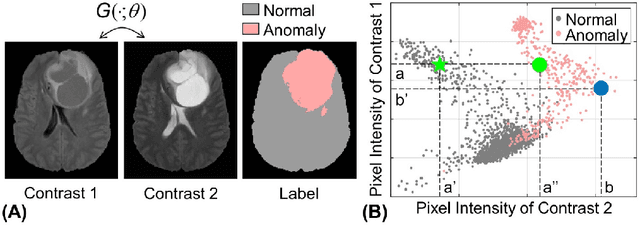
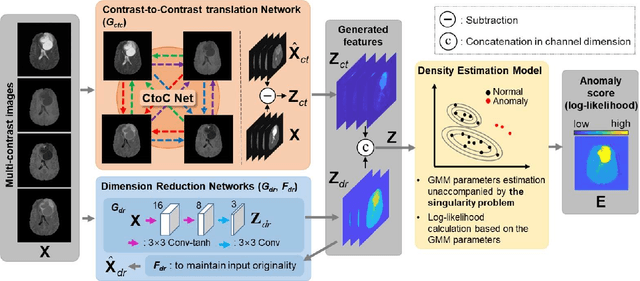
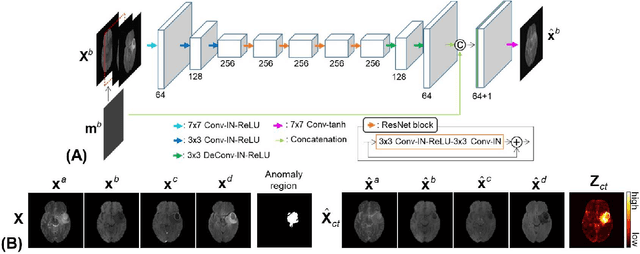
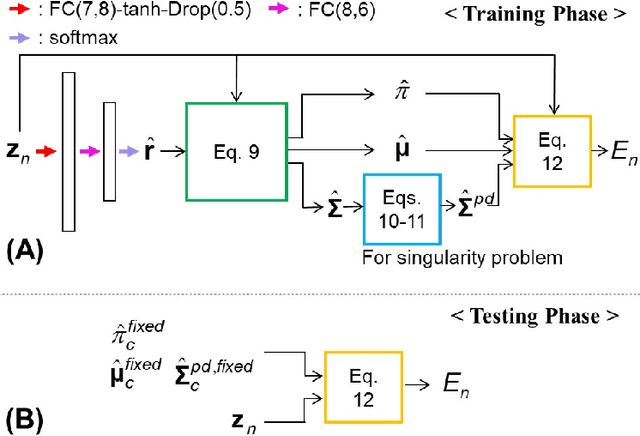
Anomaly detection in medical imaging is to distinguish the relevant biomarkers of diseases from those of normal tissues. Deep supervised learning methods have shown potentials in various detection tasks, but its performances would be limited in medical imaging fields where collecting annotated anomaly data is limited and labor-intensive. Therefore, unsupervised anomaly detection can be an effective tool for clinical practices, which uses only unlabeled normal images as training data. In this paper, we developed an unsupervised learning framework for pixel-wise anomaly detection in multi-contrast magnetic resonance imaging (MRI). The framework has two steps of feature generation and density estimation with Gaussian mixture model (GMM). A feature is derived through the learning of contrast-to-contrast translation that effectively captures the normal tissue characteristics in multi-contrast MRI. The feature is collaboratively used with another feature that is the low-dimensional representation of multi-contrast images. In density estimation using GMM, a simple but efficient way is introduced to handle the singularity problem which interrupts the joint learning process. The proposed method outperforms previous anomaly detection approaches. Quantitative and qualitative analyses demonstrate the effectiveness of the proposed method in anomaly detection for multi-contrast MRI.