 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Only My Model On My Data: A Privacy Preserving Approach Protecting one Model and Deceiving Unauthorized Black-Box Models
Feb 14, 2024
Deep neural networks are extensively applied to real-world tasks, such as face recognition and medical image classification, where privacy and data protection are critical. Image data, if not protected, can be exploited to infer personal or contextual information. Existing privacy preservation methods, like encryption, generate perturbed images that are unrecognizable to even humans. Adversarial attack approaches prohibit automated inference even for authorized stakeholders, limiting practical incentives for commercial and widespread adaptation. This pioneering study tackles an unexplored practical privacy preservation use case by generating human-perceivable images that maintain accurate inference by an authorized model while evading other unauthorized black-box models of similar or dissimilar objectives, and addresses the previous research gaps. The datasets employed are ImageNet, for image classification, Celeba-HQ dataset, for identity classification, and AffectNet, for emotion classification. Our results show that the generated images can successfully maintain the accuracy of a protected model and degrade the average accuracy of the unauthorized black-box models to 11.97%, 6.63%, and 55.51% on ImageNet, Celeba-HQ, and AffectNet datasets, respectively.
Image-based Deep Learning for the time-dependent prediction of fresh concrete properties
Feb 09, 2024Increasing the degree of digitisation and automation in the concrete production process can play a crucial role in reducing the CO$_2$ emissions that are associated with the production of concrete. In this paper, a method is presented that makes it possible to predict the properties of fresh concrete during the mixing process based on stereoscopic image sequences of the concretes flow behaviour. A Convolutional Neural Network (CNN) is used for the prediction, which receives the images supported by information on the mix design as input. In addition, the network receives temporal information in the form of the time difference between the time at which the images are taken and the time at which the reference values of the concretes are carried out. With this temporal information, the network implicitly learns the time-dependent behaviour of the concretes properties. The network predicts the slump flow diameter, the yield stress and the plastic viscosity. The time-dependent prediction potentially opens up the pathway to determine the temporal development of the fresh concrete properties already during mixing. This provides a huge advantage for the concrete industry. As a result, countermeasures can be taken in a timely manner. It is shown that an approach based on depth and optical flow images, supported by information of the mix design, achieves the best results.
Multi-Behavior Collaborative Filtering with Partial Order Graph Convolutional Networks
Feb 12, 2024Representing the information of multiple behaviors in the single graph collaborative filtering (CF) vector has been a long-standing challenge. This is because different behaviors naturally form separate behavior graphs and learn separate CF embeddings. Existing models merge the separate embeddings by appointing the CF embeddings for some behaviors as the primary embedding and utilizing other auxiliaries to enhance the primary embedding. However, this approach often results in the joint embedding performing well on the main tasks but poorly on the auxiliary ones. To address the problem arising from the separate behavior graphs, we propose the concept of Partial Order Graphs (POG). POG defines the partial order relation of multiple behaviors and models behavior combinations as weighted edges to merge separate behavior graphs into a joint POG. Theoretical proof verifies that POG can be generalized to any given set of multiple behaviors. Based on POG, we propose the tailored Partial Order Graph Convolutional Networks (POGCN) that convolute neighbors' information while considering the behavior relations between users and items. POGCN also introduces a partial-order BPR sampling strategy for efficient and effective multiple-behavior CF training. POGCN has been successfully deployed on the homepage of Alibaba for two months, providing recommendation services for over one billion users. Extensive offline experiments conducted on three public benchmark datasets demonstrate that POGCN outperforms state-of-the-art multi-behavior baselines across all types of behaviors. Furthermore, online A/B tests confirm the superiority of POGCN in billion-scale recommender systems.
VCR: Video representation for Contextual Retrieval
Feb 12, 2024Streamlining content discovery within media archives requires integrating advanced data representations and effective visualization techniques for clear communication of video topics to users. The proposed system addresses the challenge of efficiently navigating large video collections by exploiting a fusion of visual, audio, and textual features to accurately index and categorize video content through a text-based method. Additionally, semantic embeddings are employed to provide contextually relevant information and recommendations to users, resulting in an intuitive and engaging exploratory experience over our topics ontology map using OpenAI GPT-4.
Enhancing Cybersecurity Resilience in Finance with Deep Learning for Advanced Threat Detection
Feb 15, 2024In the age of the Internet, people's lives are increasingly dependent on today's network technology. However, network technology is a double-edged sword, bringing convenience to people but also posing many security challenges. Maintaining network security and protecting the legitimate interests of users is at the heart of network construction. Threat detection is an important part of a complete and effective defense system. In the field of network information security, the technical update of network attack and network protection is spiraling. How to effectively detect unknown threats is one of the concerns of network protection. Currently, network threat detection is usually based on rules and traditional machine learning methods, which create artificial rules or extract common spatiotemporal features, which cannot be applied to large-scale data applications, and the emergence of unknown threats causes the detection accuracy of the original model to decline. With this in mind, this paper uses deep learning for advanced threat detection to improve cybersecurity resilienc e in the financial industry. Many network security researchers have shifted their focus to exceptio n-based intrusion detection techniques. The detection technology mainly uses statistical machine learning methods - collecting normal program and network behavior data, extracting multidimensional features, and training decision machine learning models on this basis (commonly used include naive Bayes, decision trees, support vector machines, random forests, etc.). In the detection phase, program code or network behavior that deviates from the normal value beyond the tolerance is considered malicious code or network attack behavior.
User Modeling and User Profiling: A Comprehensive Survey
Feb 15, 2024The integration of artificial intelligence (AI) into daily life, particularly through information retrieval and recommender systems, has necessitated advanced user modeling and profiling techniques to deliver personalized experiences. These techniques aim to construct accurate user representations based on the rich amounts of data generated through interactions with these systems. This paper presents a comprehensive survey of the current state, evolution, and future directions of user modeling and profiling research. We provide a historical overview, tracing the development from early stereotype models to the latest deep learning techniques, and propose a novel taxonomy that encompasses all active topics in this research area, including recent trends. Our survey highlights the paradigm shifts towards more sophisticated user profiling methods, emphasizing implicit data collection, multi-behavior modeling, and the integration of graph data structures. We also address the critical need for privacy-preserving techniques and the push towards explainability and fairness in user modeling approaches. By examining the definitions of core terminology, we aim to clarify ambiguities and foster a clearer understanding of the field by proposing two novel encyclopedic definitions of the main terms. Furthermore, we explore the application of user modeling in various domains, such as fake news detection, cybersecurity, and personalized education. This survey serves as a comprehensive resource for researchers and practitioners, offering insights into the evolution of user modeling and profiling and guiding the development of more personalized, ethical, and effective AI systems.
Can Large Language Models Detect Rumors on Social Media?
Feb 08, 2024In this work, we investigate to use Large Language Models (LLMs) for rumor detection on social media. However, it is challenging for LLMs to reason over the entire propagation information on social media, which contains news contents and numerous comments, due to LLMs may not concentrate on key clues in the complex propagation information, and have trouble in reasoning when facing massive and redundant information. Accordingly, we propose an LLM-empowered Rumor Detection (LeRuD) approach, in which we design prompts to teach LLMs to reason over important clues in news and comments, and divide the entire propagation information into a Chain-of-Propagation for reducing LLMs' burden. We conduct extensive experiments on the Twitter and Weibo datasets, and LeRuD outperforms several state-of-the-art rumor detection models by 3.2% to 7.7%. Meanwhile, by applying LLMs, LeRuD requires no data for training, and thus shows more promising rumor detection ability in few-shot or zero-shot scenarios.
Electromagnetic Information Theory: Fundamentals and Applications for 6G Wireless Communication Systems
Jan 17, 2024In wireless communications, electromagnetic theory and information theory constitute a pair of fundamental theories, bridged by antenna theory and wireless propagation channel modeling theory. Up to the fifth generation (5G) wireless communication networks, these four theories have been developing relatively independently. However, in sixth generation (6G) space-air-ground-sea wireless communication networks, seamless coverage is expected in the three-dimensional (3D) space, potentially necessitating the acquisition of channel state information (CSI) and channel capacity calculation at anywhere and any time. Additionally, the key 6G technologies such as ultra-massive multiple-input multiple-output (MIMO) and holographic MIMO achieves intricate interaction of the antennas and wireless propagation environments, which necessitates the joint modeling of antennas and wireless propagation channels. To address the challenges in 6G, the integration of the above four theories becomes inevitable, leading to the concept of the so-called electromagnetic information theory (EIT). In this article, a suite of 6G key technologies is highlighted. Then, the concepts and relationships of the four theories are unveiled. Finally, the necessity and benefits of integrating them into the EIT are revealed.
Multimodal Clinical Trial Outcome Prediction with Large Language Models
Feb 09, 2024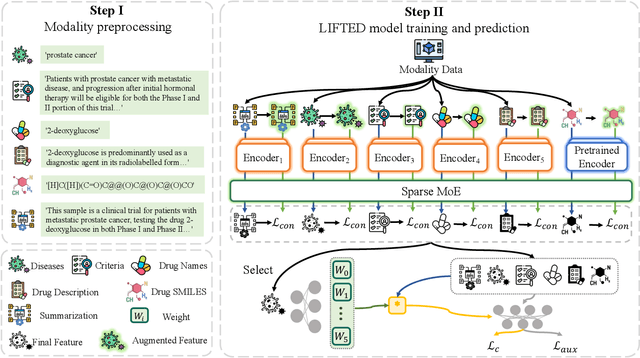
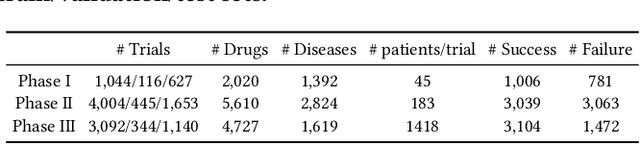
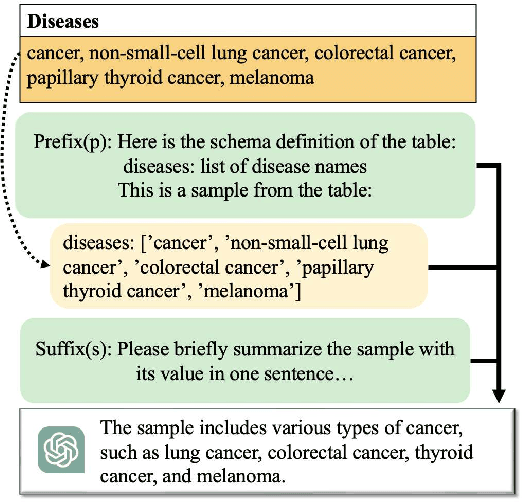
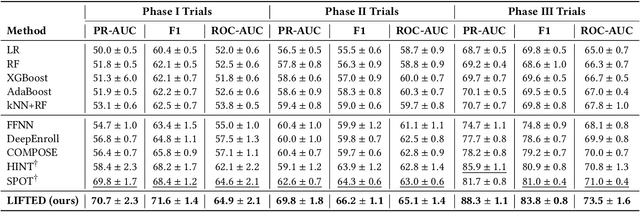
The clinical trial is a pivotal and costly process, often spanning multiple years and requiring substantial financial resources. Therefore, the development of clinical trial outcome prediction models aims to exclude drugs likely to fail and holds the potential for significant cost savings. Recent data-driven attempts leverage deep learning methods to integrate multimodal data for predicting clinical trial outcomes. However, these approaches rely on manually designed modal-specific encoders, which limits both the extensibility to adapt new modalities and the ability to discern similar information patterns across different modalities. To address these issues, we propose a multimodal mixture-of-experts (LIFTED) approach for clinical trial outcome prediction. Specifically, LIFTED unifies different modality data by transforming them into natural language descriptions. Then, LIFTED constructs unified noise-resilient encoders to extract information from modal-specific language descriptions. Subsequently, a sparse Mixture-of-Experts framework is employed to further refine the representations, enabling LIFTED to identify similar information patterns across different modalities and extract more consistent representations from those patterns using the same expert model. Finally, a mixture-of-experts module is further employed to dynamically integrate different modality representations for prediction, which gives LIFTED the ability to automatically weigh different modalities and pay more attention to critical information. The experiments demonstrate that LIFTED significantly enhances performance in predicting clinical trial outcomes across all three phases compared to the best baseline, showcasing the effectiveness of our proposed key components.
Link-aware link prediction over temporal graph by pattern recognition
Feb 11, 2024A temporal graph can be considered as a stream of links, each of which represents an interaction between two nodes at a certain time. On temporal graphs, link prediction is a common task, which aims to answer whether the query link is true or not. To do this task, previous methods usually focus on the learning of representations of the two nodes in the query link. We point out that the learned representation by their models may encode too much information with side effects for link prediction because they have not utilized the information of the query link, i.e., they are link-unaware. Based on this observation, we propose a link-aware model: historical links and the query link are input together into the following model layers to distinguish whether this input implies a reasonable pattern that ends with the query link. During this process, we focus on the modeling of link evolution patterns rather than node representations. Experiments on six datasets show that our model achieves strong performances compared with state-of-the-art baselines, and the results of link prediction are interpretable. The code and datasets are available on the project website: https://github.com/lbq8942/TGACN.