 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AutoMC: Automated Model Compression based on Domain Knowledge and Progressive search strategy
Jan 24, 2022
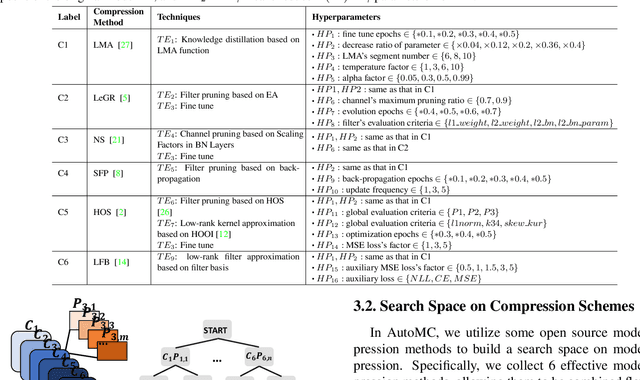
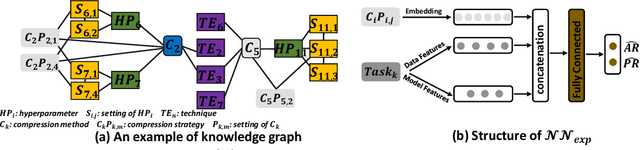
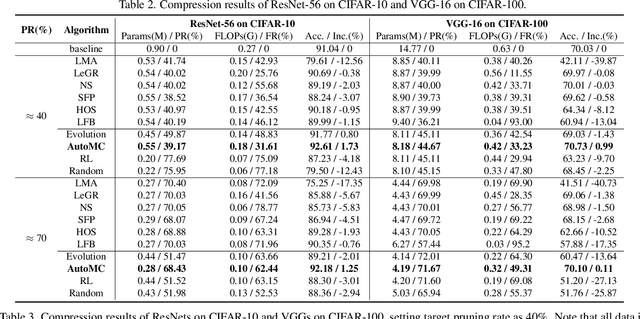
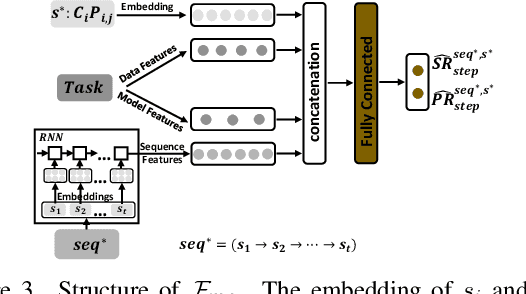
Model compression methods can reduce model complexity on the premise of maintaining acceptable performance, and thus promote the application of deep neural networks under resource constrained environments. Despite their great success, the selection of suitable compression methods and design of details of the compression scheme are difficult, requiring lots of domain knowledge as support, which is not friendly to non-expert users. To make more users easily access to the model compression scheme that best meet their needs, in this paper, we propose AutoMC, an effective automatic tool for model compression. AutoMC builds the domain knowledge on model compression to deeply understand the characteristics and advantages of each compression method under different settings. In addition, it presents a progressive search strategy to efficiently explore pareto optimal compression scheme according to the learned prior knowledge combined with the historical evaluation information. Extensive experimental results show that AutoMC can provide satisfying compression schemes within short time, demonstrating the effectiveness of AutoMC.
A Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022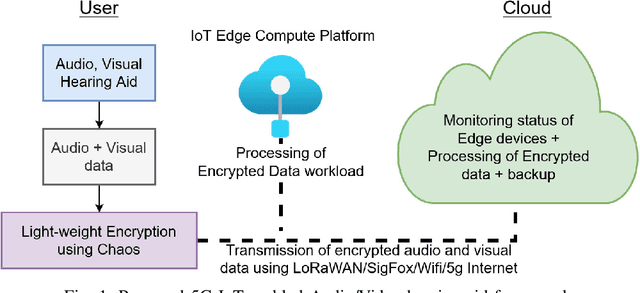

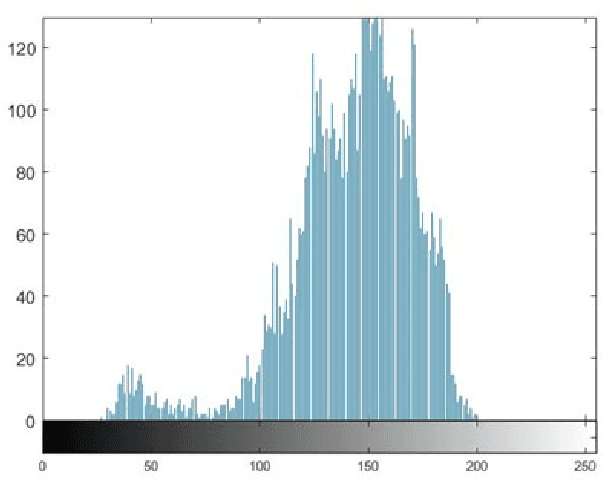
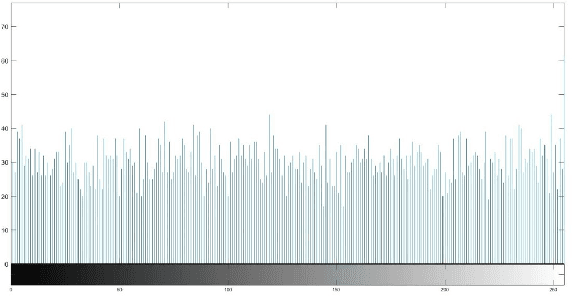
Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.
Federated Unlearning with Knowledge Distillation
Jan 24, 2022

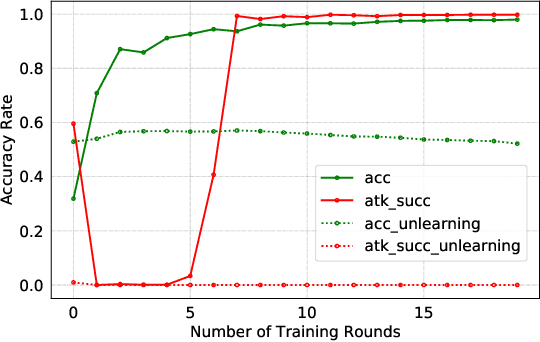
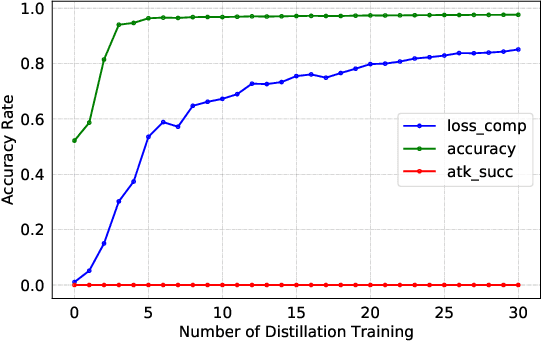
Federated Learning (FL) is designed to protect the data privacy of each client during the training process by transmitting only models instead of the original data. However, the trained model may memorize certain information about the training data. With the recent legislation on right to be forgotten, it is crucially essential for the FL model to possess the ability to forget what it has learned from each client. We propose a novel federated unlearning method to eliminate a client's contribution by subtracting the accumulated historical updates from the model and leveraging the knowledge distillation method to restore the model's performance without using any data from the clients. This method does not have any restrictions on the type of neural networks and does not rely on clients' participation, so it is practical and efficient in the FL system. We further introduce backdoor attacks in the training process to help evaluate the unlearning effect. Experiments on three canonical datasets demonstrate the effectiveness and efficiency of our method.
Multi-Modal Temporal Attention Models for Crop Mapping from Satellite Time Series
Dec 14, 2021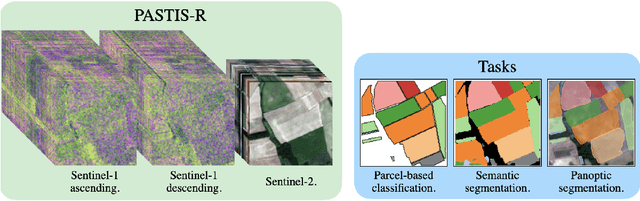
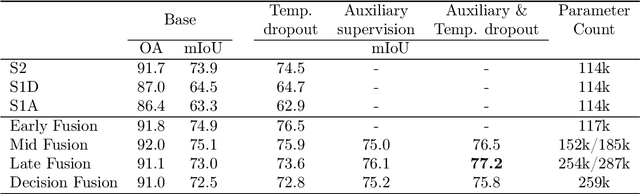
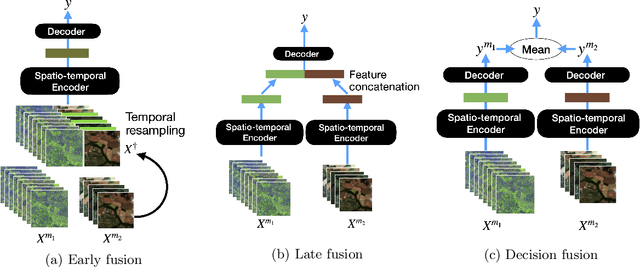
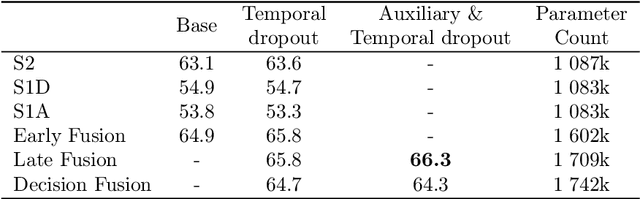
Optical and radar satellite time series are synergetic: optical images contain rich spectral information, while C-band radar captures useful geometrical information and is immune to cloud cover. Motivated by the recent success of temporal attention-based methods across multiple crop mapping tasks, we propose to investigate how these models can be adapted to operate on several modalities. We implement and evaluate multiple fusion schemes, including a novel approach and simple adjustments to the training procedure, significantly improving performance and efficiency with little added complexity. We show that most fusion schemes have advantages and drawbacks, making them relevant for specific settings. We then evaluate the benefit of multimodality across several tasks: parcel classification, pixel-based segmentation, and panoptic parcel segmentation. We show that by leveraging both optical and radar time series, multimodal temporal attention-based models can outmatch single-modality models in terms of performance and resilience to cloud cover. To conduct these experiments, we augment the PASTIS dataset with spatially aligned radar image time series. The resulting dataset, PASTIS-R, constitutes the first large-scale, multimodal, and open-access satellite time series dataset with semantic and instance annotations.
Understanding Knowledge Integration in Language Models with Graph Convolutions
Feb 15, 2022
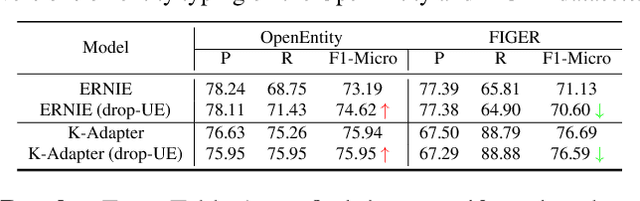
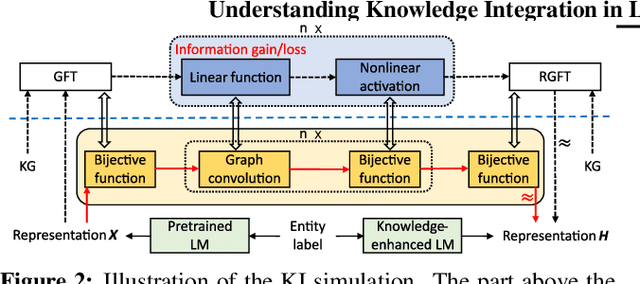
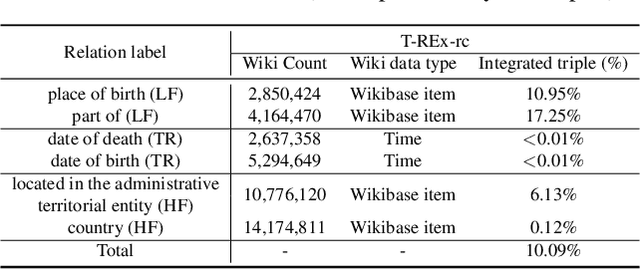
Pretrained language models (LMs) do not capture factual knowledge very well. This has led to the development of a number of knowledge integration (KI) methods which aim to incorporate external knowledge into pretrained LMs. Even though KI methods show some performance gains over vanilla LMs, the inner-workings of these methods are not well-understood. For instance, it is unclear how and what kind of knowledge is effectively integrated into these models and if such integration may lead to catastrophic forgetting of already learned knowledge. This paper revisits the KI process in these models with an information-theoretic view and shows that KI can be interpreted using a graph convolution operation. We propose a probe model called \textit{Graph Convolution Simulator} (GCS) for interpreting knowledge-enhanced LMs and exposing what kind of knowledge is integrated into these models. We conduct experiments to verify that our GCS can indeed be used to correctly interpret the KI process, and we use it to analyze two well-known knowledge-enhanced LMs: ERNIE and K-Adapter, and find that only a small amount of factual knowledge is integrated in them. We stratify knowledge in terms of various relation types and find that ERNIE and K-Adapter integrate different kinds of knowledge to different extent. Our analysis also shows that simply increasing the size of the KI corpus may not lead to better KI; fundamental advances may be needed.
Land use identification through social network interaction
Dec 05, 2021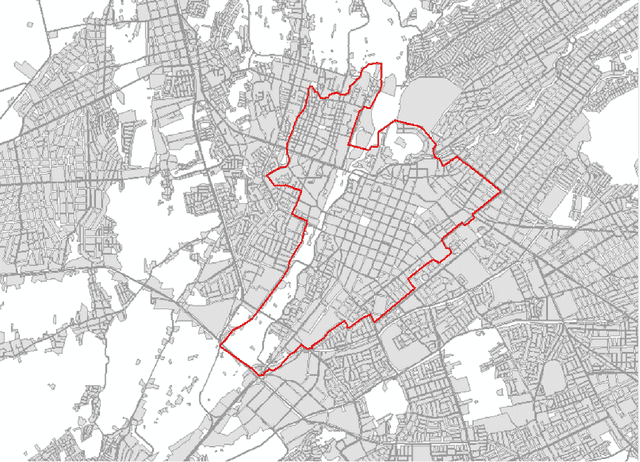
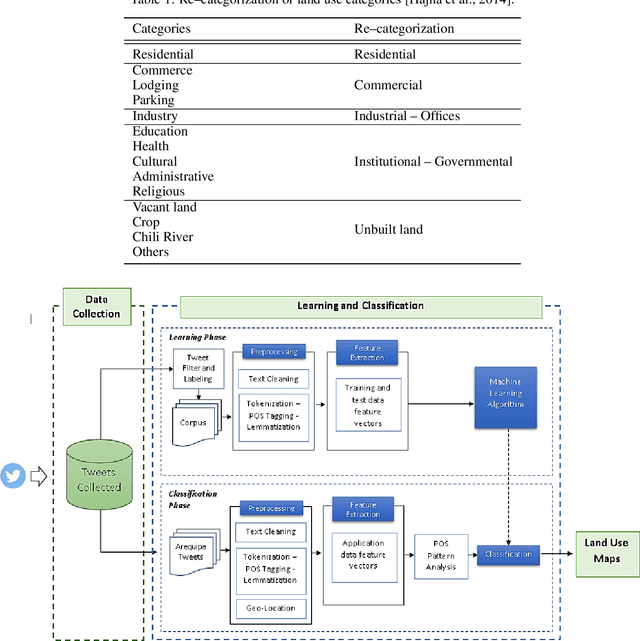
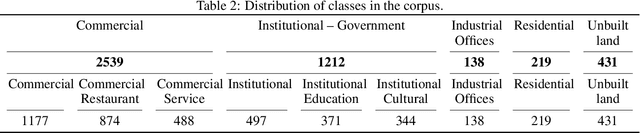

The Internet generates large volumes of data at a high rate, in particular, posts on social networks. Although social network data has numerous semantic adulterations, and is not intended to be a source of geo-spatial information, in the text of posts we find pieces of important information about how people relate to their environment, which can be used to identify interesting aspects of how human beings interact with portions of land based on their activities. This research proposes a methodology for the identification of land uses using Natural Language Processing (NLP) from the contents of the popular social network Twitter. It will be approached by identifying keywords with linguistic patterns from the text, and the geographical coordinates associated with the publication. Context-specific innovations are introduced to deal with data across South America and, in particular, in the city of Arequipa, Peru. The objective is to identify the five main land uses: residential, commercial, institutional-governmental, industrial-offices and unbuilt land. Within the framework of urban planning and sustainable urban management, the methodology contributes to the optimization of the identification techniques applied for the updating of land use cadastres, since the results achieved an accuracy of about 90%, which motivates its application in the real context. In addition, it would allow the identification of land use categories at a more detailed level, in situations such as a complex/mixed distribution building based on the amount of data collected. Finally, the methodology makes land use information available in a more up-to-date fashion and, above all, avoids the high economic cost of the non-automatic production of land use maps for cities, mostly in developing countries.
Reinforcement Learning Your Way: Agent Characterization through Policy Regularization
Jan 21, 2022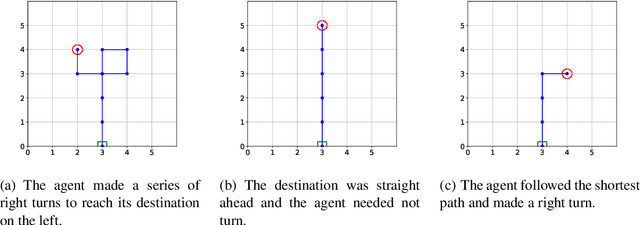
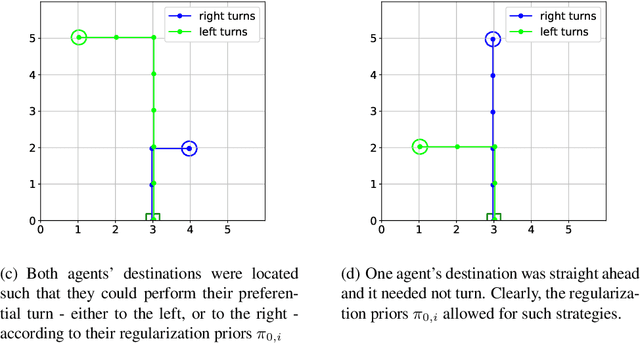
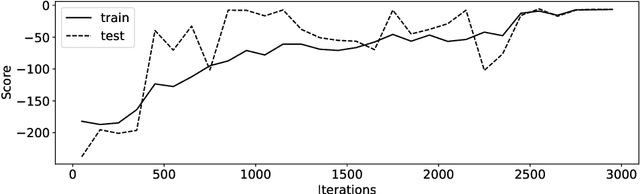
The increased complexity of state-of-the-art reinforcement learning (RL) algorithms have resulted in an opacity that inhibits explainability and understanding. This has led to the development of several post-hoc explainability methods that aim to extract information from learned policies thus aiding explainability. These methods rely on empirical observations of the policy and thus aim to generalize a characterization of agents' behaviour. In this study, we have instead developed a method to imbue a characteristic behaviour into agents' policies through regularization of their objective functions. Our method guides the agents' behaviour during learning which results in an intrinsic characterization; it connects the learning process with model explanation. We provide a formal argument and empirical evidence for the viability of our method. In future work, we intend to employ it to develop agents that optimize individual financial customers' investment portfolios based on their spending personalities.
Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images
Jan 04, 2022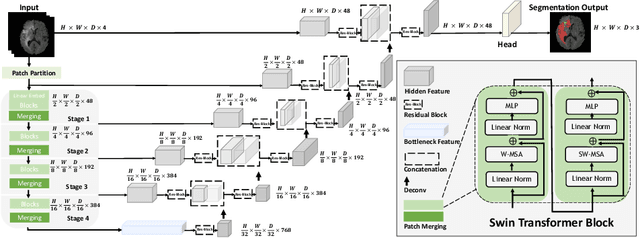

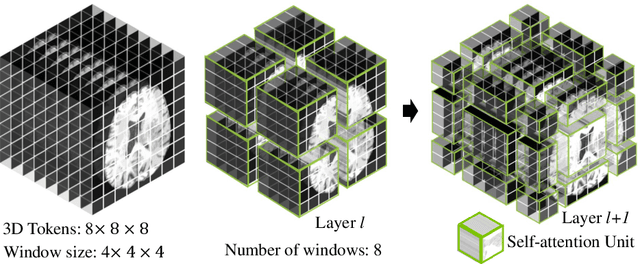
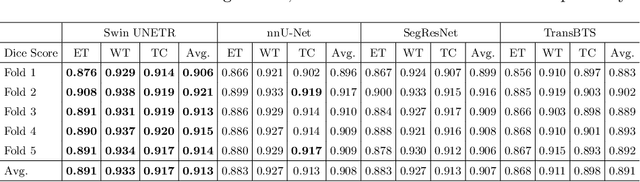
Semantic segmentation of brain tumors is a fundamental medical image analysis task involving multiple MRI imaging modalities that can assist clinicians in diagnosing the patient and successively studying the progression of the malignant entity. In recent years, Fully Convolutional Neural Networks (FCNNs) approaches have become the de facto standard for 3D medical image segmentation. The popular "U-shaped" network architecture has achieved state-of-the-art performance benchmarks on different 2D and 3D semantic segmentation tasks and across various imaging modalities. However, due to the limited kernel size of convolution layers in FCNNs, their performance of modeling long-range information is sub-optimal, and this can lead to deficiencies in the segmentation of tumors with variable sizes. On the other hand, transformer models have demonstrated excellent capabilities in capturing such long-range information in multiple domains, including natural language processing and computer vision. Inspired by the success of vision transformers and their variants, we propose a novel segmentation model termed Swin UNEt TRansformers (Swin UNETR). Specifically, the task of 3D brain tumor semantic segmentation is reformulated as a sequence to sequence prediction problem wherein multi-modal input data is projected into a 1D sequence of embedding and used as an input to a hierarchical Swin transformer as the encoder. The swin transformer encoder extracts features at five different resolutions by utilizing shifted windows for computing self-attention and is connected to an FCNN-based decoder at each resolution via skip connections. We have participated in BraTS 2021 segmentation challenge, and our proposed model ranks among the top-performing approaches in the validation phase. Code: https://monai.io/research/swin-unetr
FINO: Flow-based Joint Image and Noise Model
Nov 11, 2021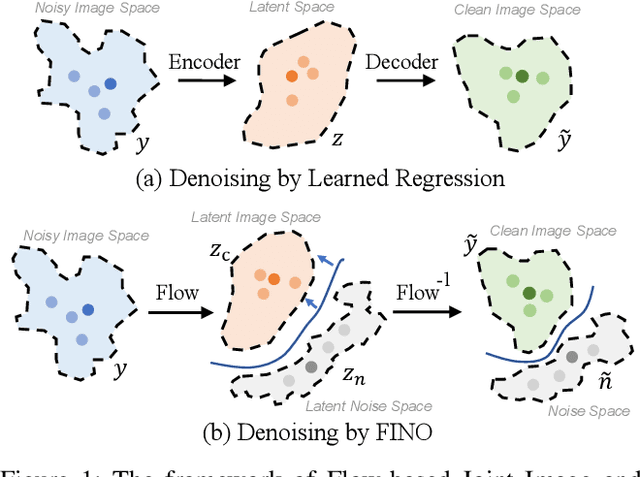
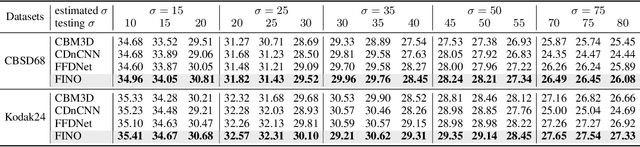
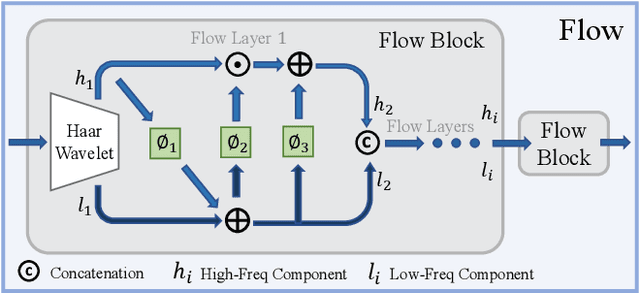
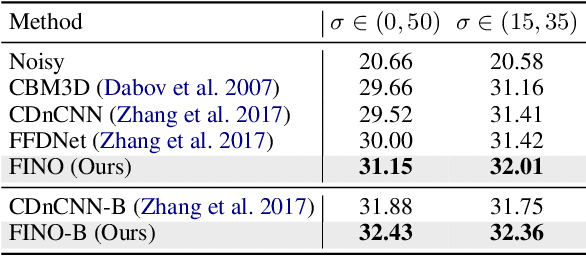
One of the fundamental challenges in image restoration is denoising, where the objective is to estimate the clean image from its noisy measurements. To tackle such an ill-posed inverse problem, the existing denoising approaches generally focus on exploiting effective natural image priors. The utilization and analysis of the noise model are often ignored, although the noise model can provide complementary information to the denoising algorithms. In this paper, we propose a novel Flow-based joint Image and NOise model (FINO) that distinctly decouples the image and noise in the latent space and losslessly reconstructs them via a series of invertible transformations. We further present a variable swapping strategy to align structural information in images and a noise correlation matrix to constrain the noise based on spatially minimized correlation information. Experimental results demonstrate FINO's capacity to remove both synthetic additive white Gaussian noise (AWGN) and real noise. Furthermore, the generalization of FINO to the removal of spatially variant noise and noise with inaccurate estimation surpasses that of the popular and state-of-the-art methods by large margins.
Case law retrieval: problems, methods, challenges and evaluations in the last 20 years
Feb 15, 2022Case law retrieval is the retrieval of judicial decisions relevant to a legal question. Case law retrieval comprises a significant amount of a lawyer's time, and is important to ensure accurate advice and reduce workload. We survey methods for case law retrieval from the past 20 years and outline the problems and challenges facing evaluation of case law retrieval systems going forward. Limited published work has focused on improving ranking in ad-hoc case law retrieval. But there has been significant work in other areas of case law retrieval, and legal information retrieval generally. This is likely due to legal search providers being unwilling to give up the secrets of their success to competitors. Most evaluations of case law retrieval have been undertaken on small collections and focus on related tasks such as question-answer systems or recommender systems. Work has not focused on Cranfield style evaluations and baselines of methods for case law retrieval on publicly available test collections are not present. This presents a major challenge going forward. But there are reasons to question the extent of this problem, at least in a commercial setting. Without test collections to baseline approaches it cannot be known whether methods are promising. Works by commercial legal search providers show the effectiveness of natural language systems as well as query expansion for case law retrieval. Machine learning is being applied to more and more legal search tasks, and undoubtedly this represents the future of case law retrieval.