 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-modal land cover mapping of remote sensing images using pyramid attention and gated fusion networks
Nov 06, 2021


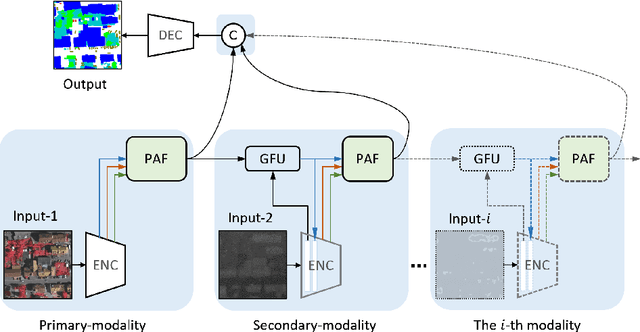
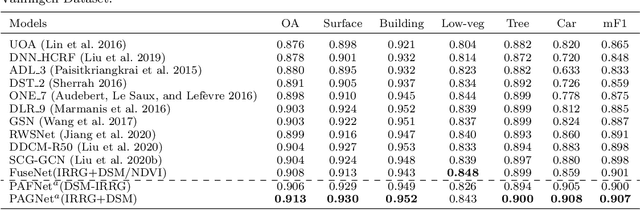
Multi-modality data is becoming readily available in remote sensing (RS) and can provide complementary information about the Earth's surface. Effective fusion of multi-modal information is thus important for various applications in RS, but also very challenging due to large domain differences, noise, and redundancies. There is a lack of effective and scalable fusion techniques for bridging multiple modality encoders and fully exploiting complementary information. To this end, we propose a new multi-modality network (MultiModNet) for land cover mapping of multi-modal remote sensing data based on a novel pyramid attention fusion (PAF) module and a gated fusion unit (GFU). The PAF module is designed to efficiently obtain rich fine-grained contextual representations from each modality with a built-in cross-level and cross-view attention fusion mechanism, and the GFU module utilizes a novel gating mechanism for early merging of features, thereby diminishing hidden redundancies and noise. This enables supplementary modalities to effectively extract the most valuable and complementary information for late feature fusion. Extensive experiments on two representative RS benchmark datasets demonstrate the effectiveness, robustness, and superiority of the MultiModNet for multi-modal land cover classification.
Information-Theoretic Generalization Bounds for Meta-Learning and Applications
May 14, 2020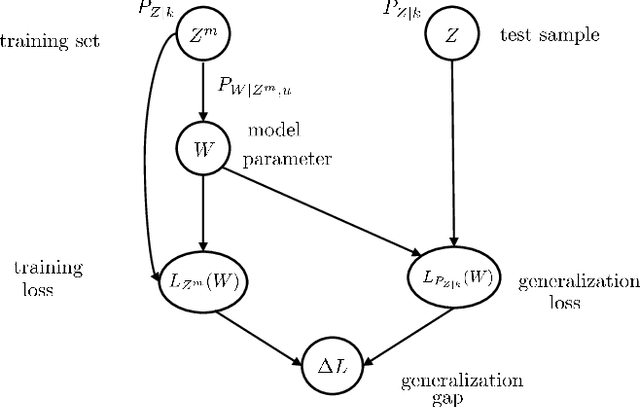
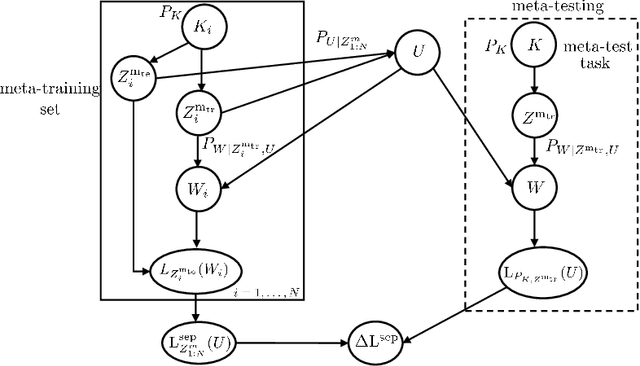
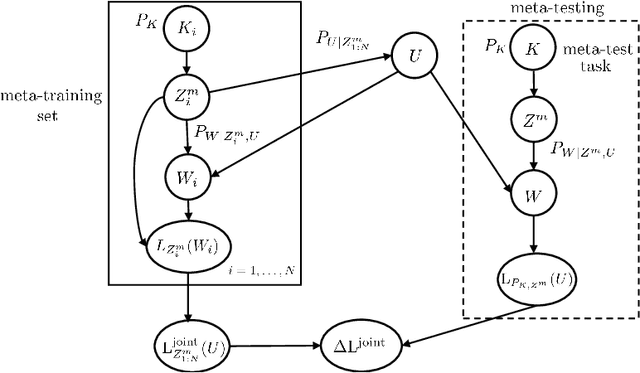
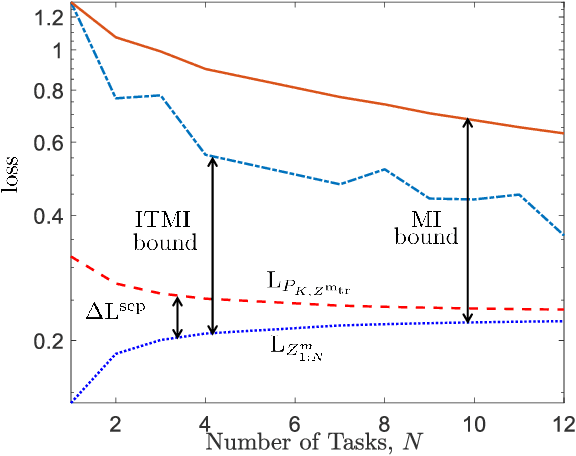
Meta-learning, or "learning to learn", refers to techniques that infer an inductive bias from data corresponding to multiple related tasks with the goal of improving the sample efficiency for new, previously unobserved, tasks. A key performance measure for meta-learning is the meta-generalization gap, that is, the difference between the average loss measured on the meta-training data and on a new, randomly selected task. This paper presents novel information-theoretic upper bounds on the meta-generalization gap. Two broad classes of meta-learning algorithms are considered that uses either separate within-task training and test sets, like MAML, or joint within-task training and test sets, like Reptile. Extending the existing work for conventional learning, an upper bound on the meta-generalization gap is derived for the former class that depends on the mutual information (MI) between the output of the meta-learning algorithm and its input meta-training data. For the latter, the derived bound includes an additional MI between the output of the per-task learning procedure and corresponding data set to capture within-task uncertainty. Tighter bounds are then developed, under given technical conditions, for the two classes via novel Individual Task MI (ITMI) bounds. Applications of the derived bounds are finally discussed, including a broad class of noisy iterative algorithms for meta-learning.
Ranging-Based Localizability-Constrained Deployment of Mobile Robotic Networks
Feb 01, 2022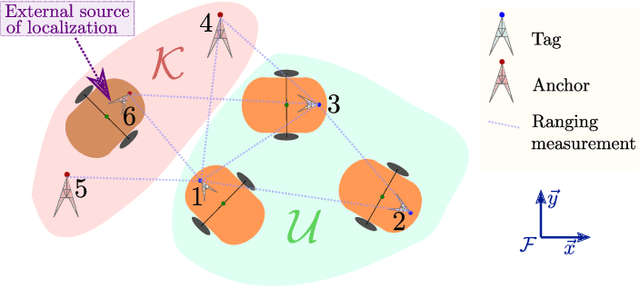
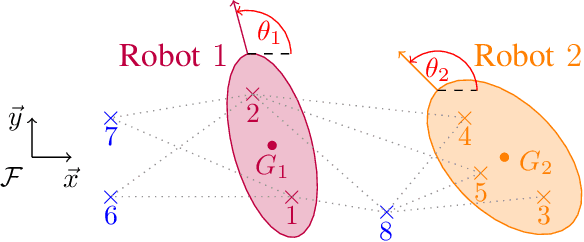
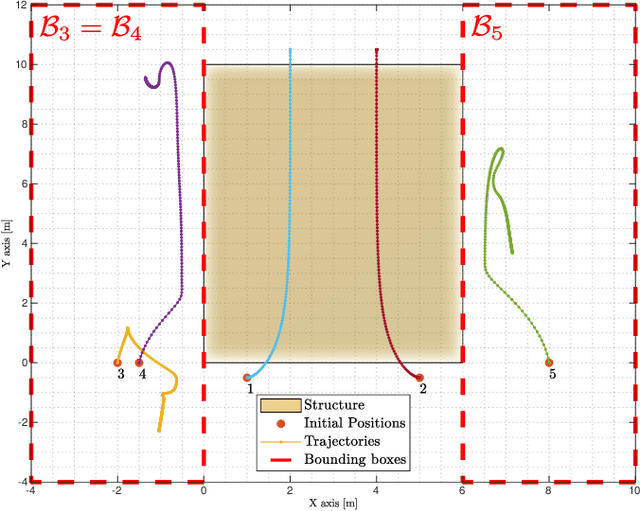
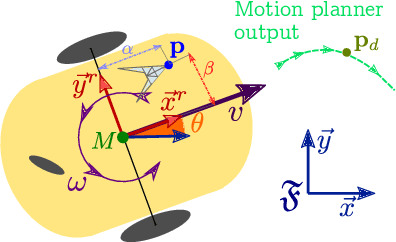
In cooperative localization schemes for robotic networks relying on noisy range measurements between agents, the achievable positioning accuracy strongly depends on the network geometry. This motivates the problem of planning robot trajectories in such multi-robot systems in a way that maintains high localization accuracy. We present potential-based planning methods, where localizability potentials are introduced to characterize the quality of the network geometry for cooperative position estimation. These potentials are based on Cram\'er Rao Lower Bounds (CRLB) and provide a theoretical lower bound on the error covariance achievable by any unbiased position estimator. In the process, we establish connections between CRLBs and the theory of graph rigidity, which has been previously used to plan the motion of robotic networks. We develop decentralized deployment algorithms appropriate for large networks, and we use equality-constrained CRLBs to extend the concept of localizability to scenarios where additional information about the relative positions of the ranging sensors is known. We illustrate the resulting robot deployment methodology through simulated examples.
SECP-Net: SE-Connection Pyramid Network of Organ At Risk Segmentation for Nasopharyngeal Carcinoma
Dec 28, 2021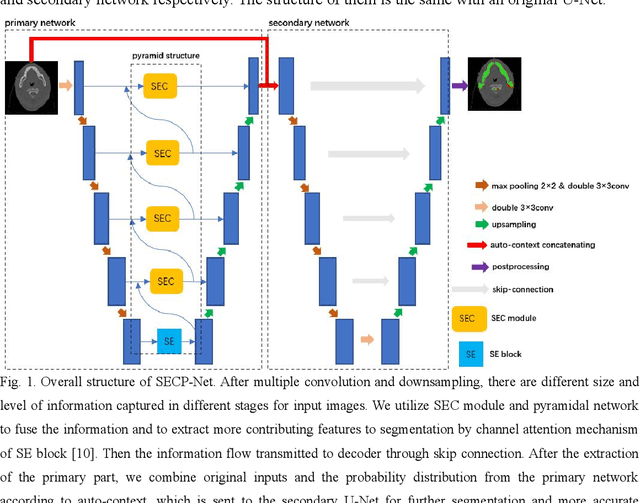
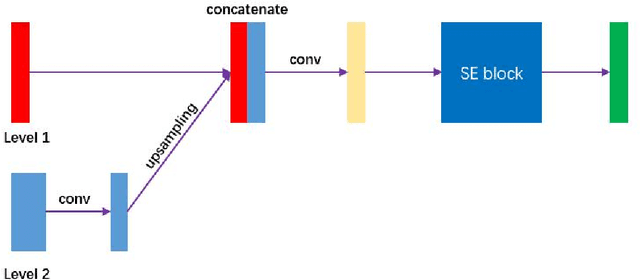
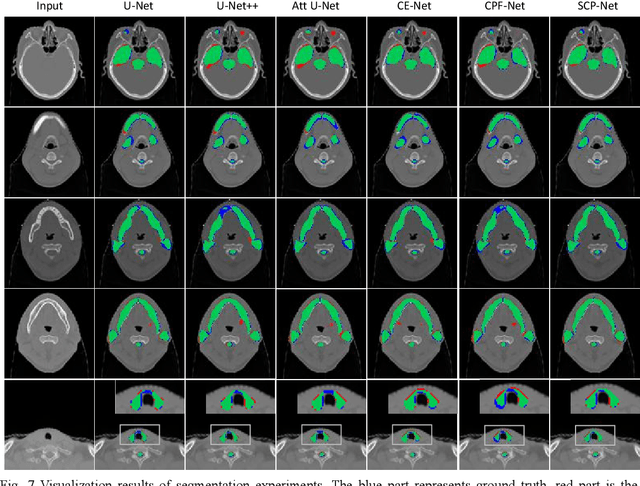
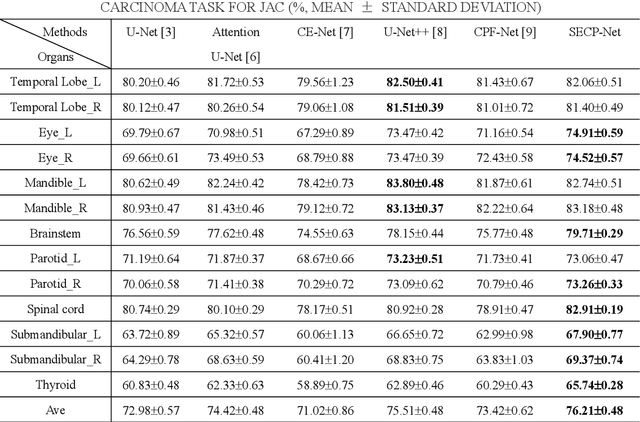
Nasopharyngeal carcinoma (NPC) is a kind of malignant tumor. Accurate and automatic segmentation of organs at risk (OAR) of computed tomography (CT) images is clinically significant. In recent years, deep learning models represented by U-Net have been widely applied in medical image segmentation tasks, which can help doctors with reduction of workload and get accurate results more quickly. In OAR segmentation of NPC, the sizes of OAR are variable, especially, some of them are small. Traditional deep neural networks underperform during segmentation due to the lack use of global and multi-size information. This paper proposes a new SE-Connection Pyramid Network (SECP-Net). SECP-Net extracts global and multi-size information flow with se connection (SEC) modules and a pyramid structure of network for improving the segmentation performance, especially that of small organs. SECP-Net also designs an auto-context cascaded network to further improve the segmentation performance. Comparative experiments are conducted between SECP-Net and other recently methods on a dataset with CT images of head and neck. Five-fold cross validation is used to evaluate the performance based on two metrics, i.e., Dice and Jaccard similarity. Experimental results show that SECP-Net can achieve SOTA performance in this challenging task.
A Survey on Temporal Reasoning for Temporal Information Extraction from Text (Extended Abstract)
May 15, 2020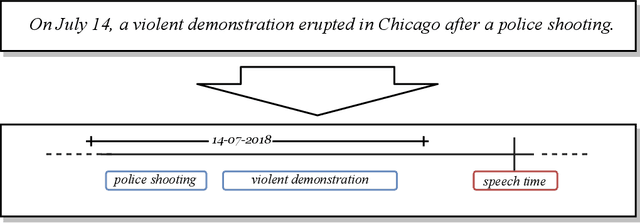

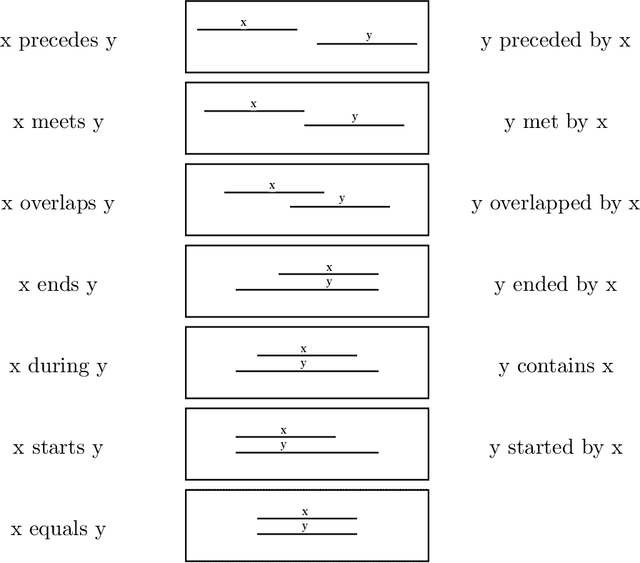
Time is deeply woven into how people perceive, and communicate about the world. Almost unconsciously, we provide our language utterances with temporal cues, like verb tenses, and we can hardly produce sentences without such cues. Extracting temporal cues from text, and constructing a global temporal view about the order of described events is a major challenge of automatic natural language understanding. Temporal reasoning, the process of combining different temporal cues into a coherent temporal view, plays a central role in temporal information extraction. This article presents a comprehensive survey of the research from the past decades on temporal reasoning for automatic temporal information extraction from text, providing a case study on the integration of symbolic reasoning with machine learning-based information extraction systems.
GuidedMix-Net: Semi-supervised Semantic Segmentation by Using Labeled Images as Reference
Dec 28, 2021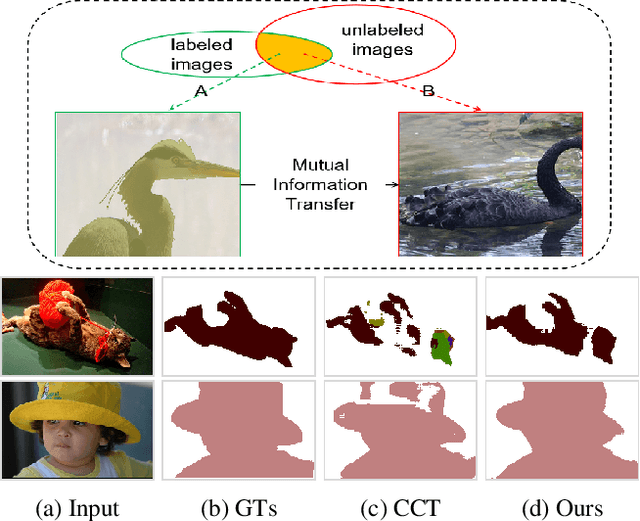
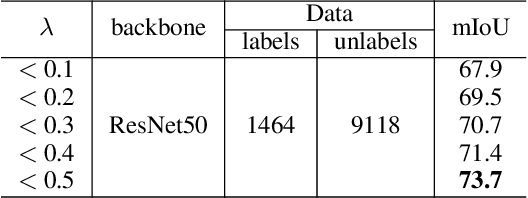
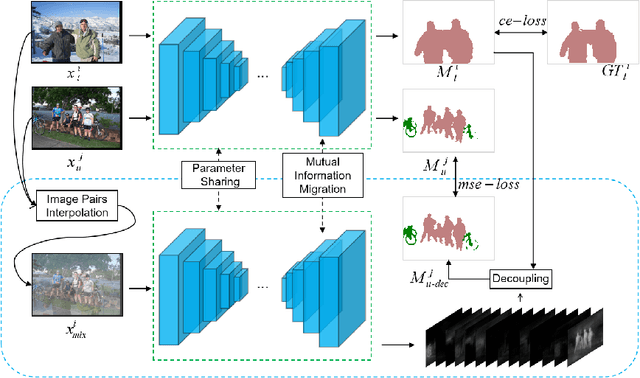
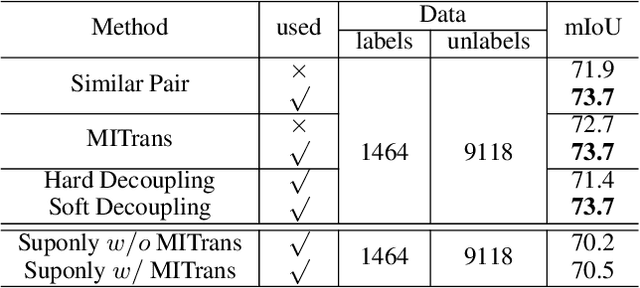
Semi-supervised learning is a challenging problem which aims to construct a model by learning from limited labeled examples. Numerous methods for this task focus on utilizing the predictions of unlabeled instances consistency alone to regularize networks. However, treating labeled and unlabeled data separately often leads to the discarding of mass prior knowledge learned from the labeled examples. %, and failure to mine the feature interaction between the labeled and unlabeled image pairs. In this paper, we propose a novel method for semi-supervised semantic segmentation named GuidedMix-Net, by leveraging labeled information to guide the learning of unlabeled instances. Specifically, GuidedMix-Net employs three operations: 1) interpolation of similar labeled-unlabeled image pairs; 2) transfer of mutual information; 3) generalization of pseudo masks. It enables segmentation models can learning the higher-quality pseudo masks of unlabeled data by transfer the knowledge from labeled samples to unlabeled data. Along with supervised learning for labeled data, the prediction of unlabeled data is jointly learned with the generated pseudo masks from the mixed data. Extensive experiments on PASCAL VOC 2012, and Cityscapes demonstrate the effectiveness of our GuidedMix-Net, which achieves competitive segmentation accuracy and significantly improves the mIoU by +7$\%$ compared to previous approaches.
Towards Further Understanding of Sparse Filtering via Information Bottleneck
Oct 20, 2019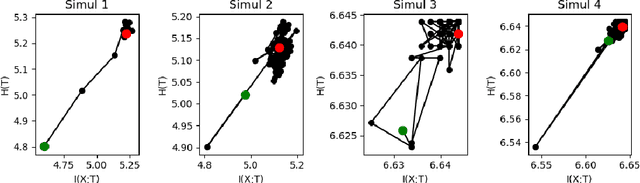
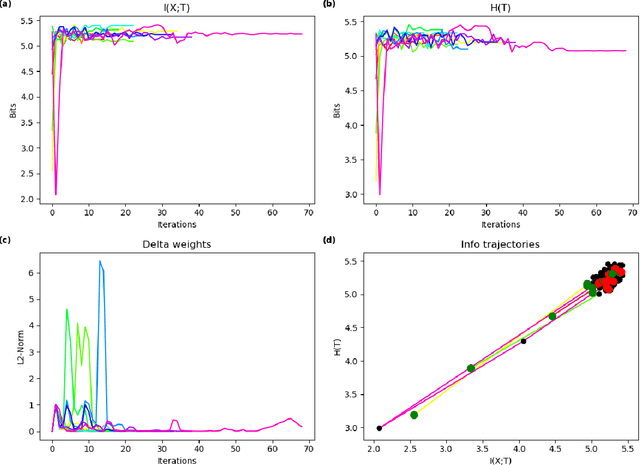
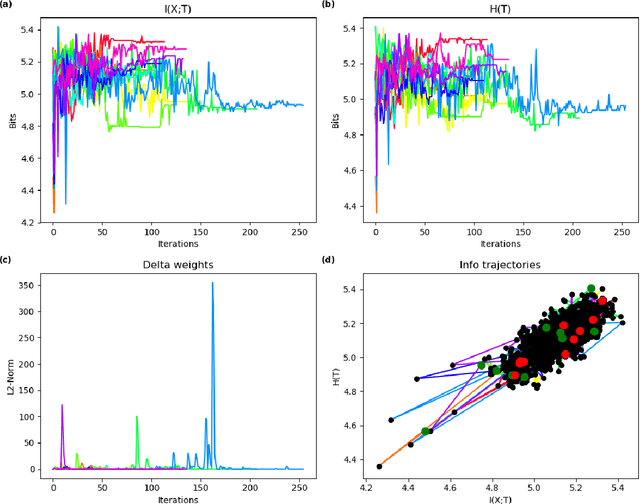
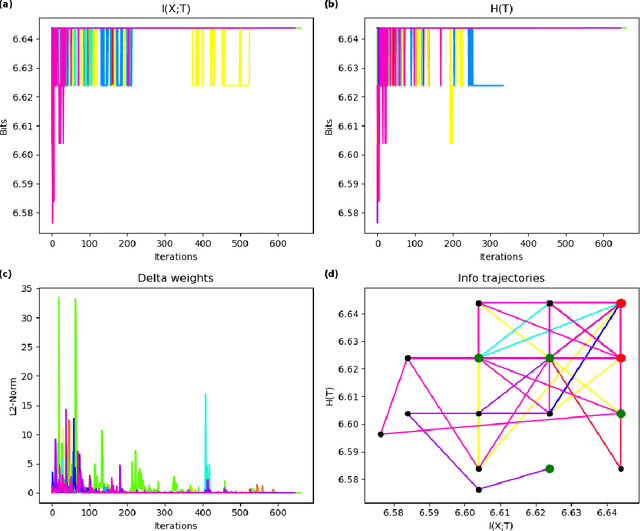
In this paper we examine a formalization of feature distribution learning (FDL) in information-theoretic terms relying on the analytical approach and on the tools already used in the study of the information bottleneck (IB). It has been conjectured that the behavior of FDL algorithms could be expressed as an optimization problem over two information-theoretic quantities: the mutual information of the data with the learned representations and the entropy of the learned distribution. In particular, such a formulation was offered in order to explain the success of the most prominent FDL algorithm, sparse filtering (SF). This conjecture was, however, left unproven. In this work, we aim at providing preliminary empirical support to this conjecture by performing experiments reminiscent of the work done on deep neural networks in the context of the IB research. Specifically, we borrow the idea of using information planes to analyze the behavior of the SF algorithm and gain insights on its dynamics. A confirmation of the conjecture about the dynamics of FDL may provide solid ground to develop information-theoretic tools to assess the quality of the learning process in FDL, and it may be extended to other unsupervised learning algorithms.
Using Deep Learning to Bootstrap Abstractions for Hierarchical Robot Planning
Feb 11, 2022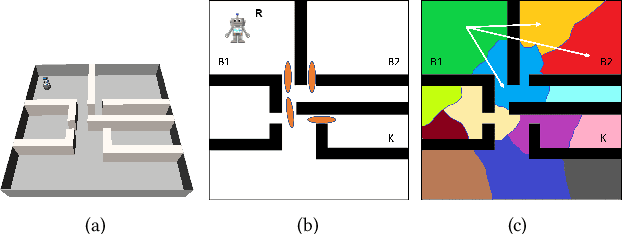
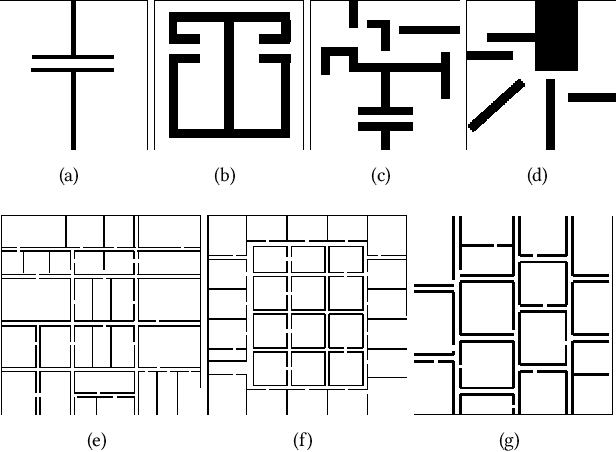
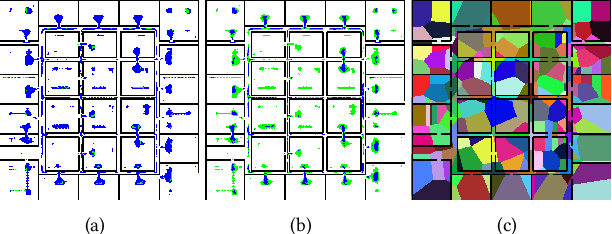
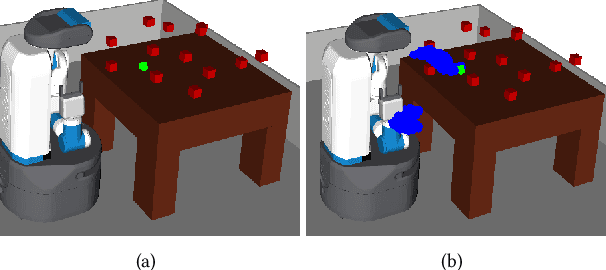
This paper addresses the problem of learning abstractions that boost robot planning performance while providing strong guarantees of reliability. Although state-of-the-art hierarchical robot planning algorithms allow robots to efficiently compute long-horizon motion plans for achieving user desired tasks, these methods typically rely upon environment-dependent state and action abstractions that need to be hand-designed by experts. We present a new approach for bootstrapping the entire hierarchical planning process. This allows us to compute abstract states and actions for new environments automatically using the critical regions predicted by a deep neural network with an auto-generated robot-specific architecture. We show that the learned abstractions can be used with a novel multi-source bi-directional hierarchical robot planning algorithm that is sound and probabilistically complete. An extensive empirical evaluation on twenty different settings using holonomic and non-holonomic robots shows that (a) our learned abstractions provide the information necessary for efficient multi-source hierarchical planning; and that (b) this approach of learning, abstractions, and planning outperforms state-of-the-art baselines by nearly a factor of ten in terms of planning time on test environments not seen during training.
A Communication-efficient Federated learning assisted by Central data: Implementation of vertical training into Horizontal Federated learning
Dec 03, 2021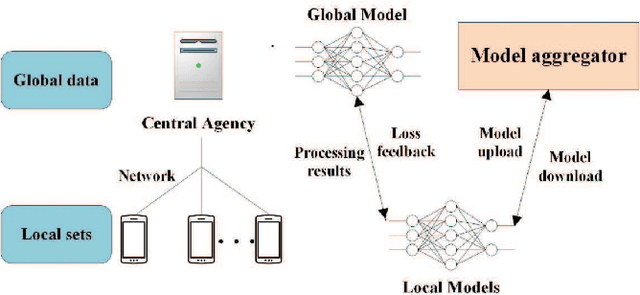
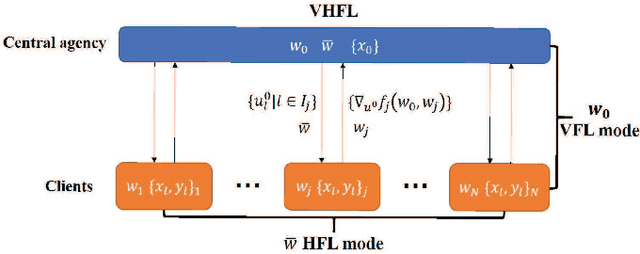
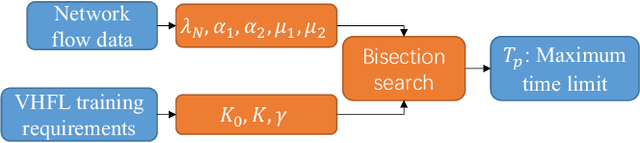
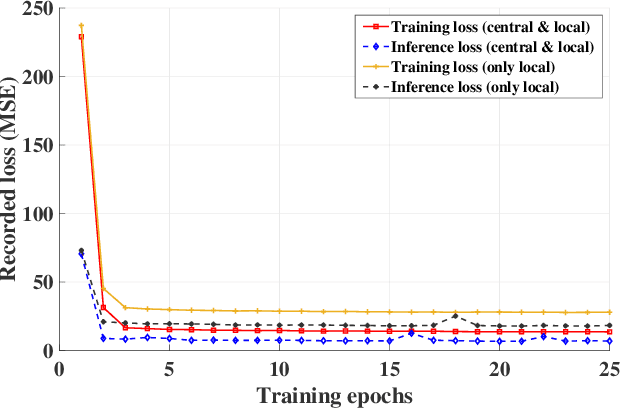
Federated learning (FL) has emerged to jointly train a model with distributed data sets in IoT while avoiding the need for central data collection. Due to limited observation range, such data sets can only reflect local information, which limits the quality of trained models. In practical network, the global information and local observations always coexist, which requires joint consideration for learning to make reasonable policy. However, in horizontal FL among distributed clients, the central agency only acts as a model aggregator without utilizing its global features to further improve the model. This could largely degrade the performance in some missions such as flow prediction, where the global information could obviously enhance the accuracy. Meanwhile, such global feature may not be directly transmitted to agents for data security. Then how to utilize the global observation residing in the central agency while protecting its safety rises up as an important problem in FL. In this paper, we developed the vertical-horizontal federated learning (VHFL) process, where the global feature is shared with the agents in a procedure similar to vertical FL without extra communication rounds. Considering the delay and packet loss, we analyzed its convergence in the network system and validated its performance by experiments. The proposed VHFL could enhance the accuracy compared with the horizontal FL while protecting the security of global data.
A Newton-type algorithm for federated learning based on incremental Hessian eigenvector sharing
Feb 11, 2022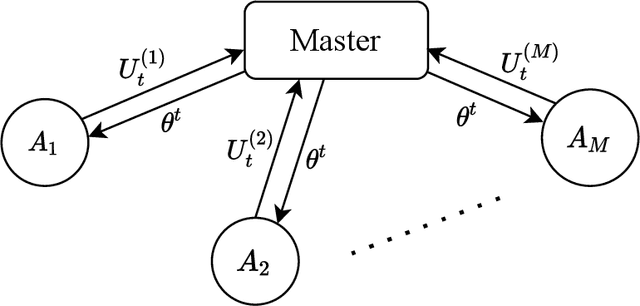
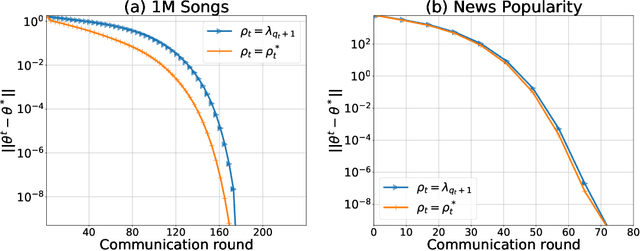
There is a growing interest in the decentralized optimization framework that goes under the name of Federated Learning (FL). In particular, much attention is being turned to FL scenarios where the network is strongly heterogeneous in terms of communication resources (e.g., bandwidth) and data distribution. In these cases, communication between local machines (agents) and the central server (Master) is a main consideration. In this work, we present an original communication-constrained Newton-type (NT) algorithm designed to accelerate FL in such heterogeneous scenarios. The algorithm is by design robust to non i.i.d. data distributions, handles heterogeneity of agents' communication resources (CRs), only requires sporadic Hessian computations, and achieves super-linear convergence. This is possible thanks to an incremental strategy, based on a singular value decomposition (SVD) of the local Hessian matrices, which exploits (possibly) outdated second-order information. The proposed solution is thoroughly validated on real datasets by assessing (i) the number of communication rounds required for convergence, (ii) the overall amount of data transmitted and (iii) the number of local Hessian computations required. For all these metrics, the proposed approach shows superior performance against state-of-the art techniques like GIANT and FedNL.