 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Rational Selection of Goal Operations and the Integration ofSearch Strategies with Goal-Driven Autonomy
Jan 21, 2022

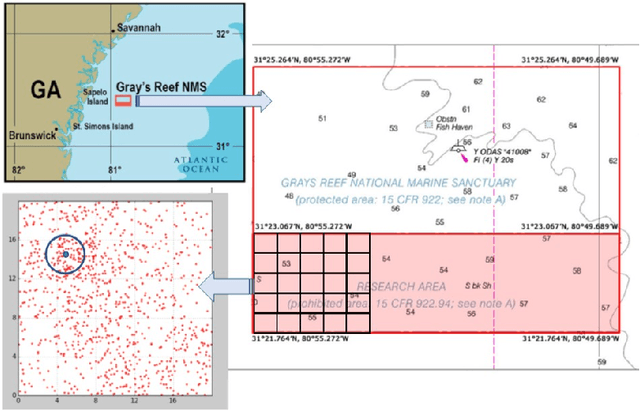


Intelligent physical systems as embodied cognitive systems must perform high-level reasoning while concurrently managing an underlying control architecture. The link between cognition and control must manage the problem of converting continuous values from the real world to symbolic representations (and back). To generate effective behaviors, reasoning must include a capacity to replan, acquire and update new information, detect and respond to anomalies, and perform various operations on system goals. But, these processes are not independent and need further exploration. This paper examines an agent's choices when multiple goal operations co-occur and interact, and it establishes a method of choosing between them. We demonstrate the benefits and discuss the trade offs involved with this and show positive results in a dynamic marine search task.
Random Ferns for Semantic Segmentation of PolSAR Images
Feb 07, 2022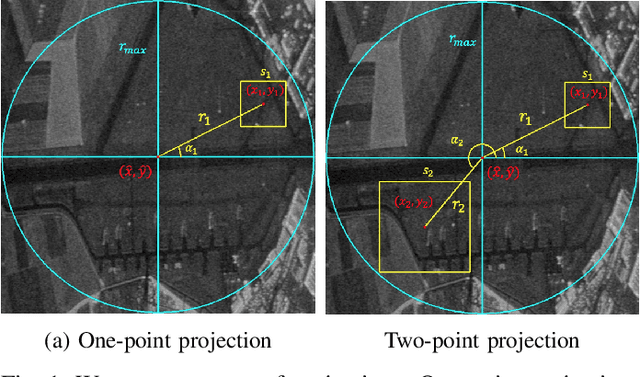
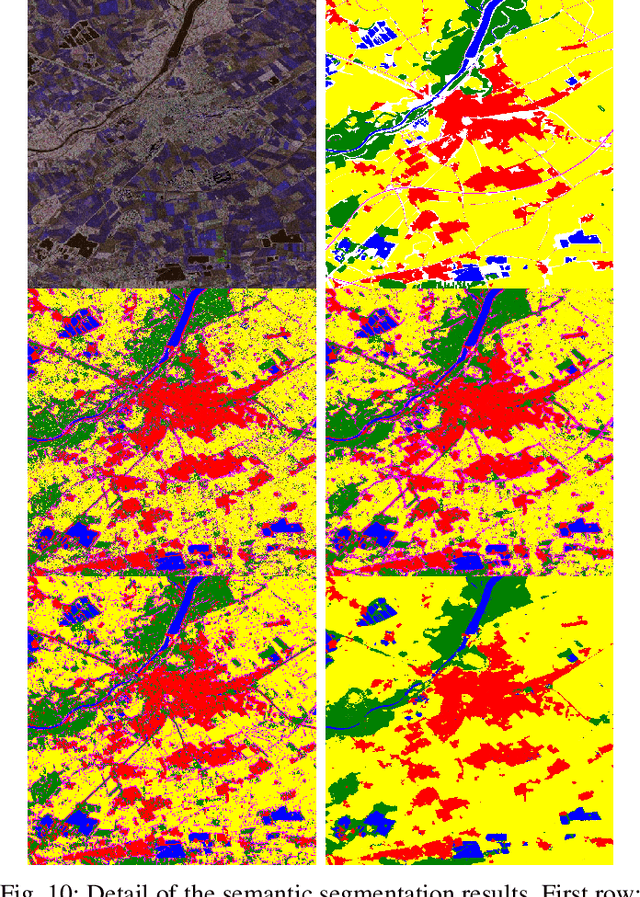
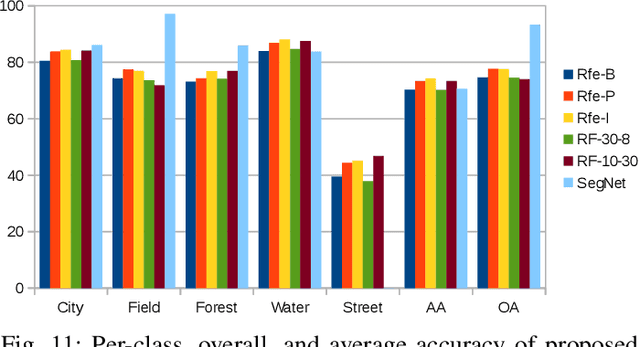
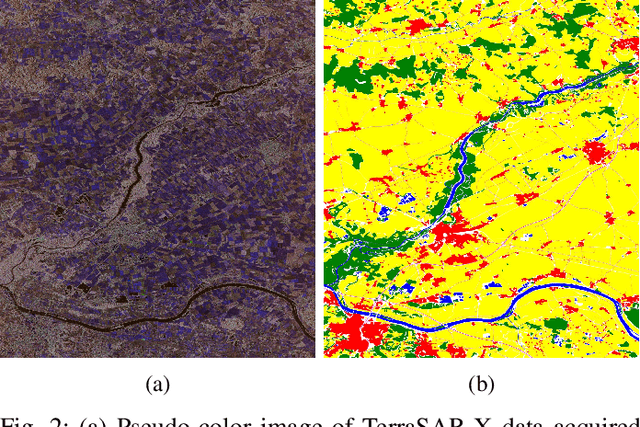
Random Ferns -- as a less known example of Ensemble Learning -- have been successfully applied in many Computer Vision applications ranging from keypoint matching to object detection. This paper extends the Random Fern framework to the semantic segmentation of polarimetric synthetic aperture radar images. By using internal projections that are defined over the space of Hermitian matrices, the proposed classifier can be directly applied to the polarimetric covariance matrices without the need to explicitly compute predefined image features. Furthermore, two distinct optimization strategies are proposed: The first based on pre-selection and grouping of internal binary features before the creation of the classifier; and the second based on iteratively improving the properties of a given Random Fern. Both strategies are able to boost the performance by filtering features that are either redundant or have a low information content and by grouping correlated features to best fulfill the independence assumptions made by the Random Fern classifier. Experiments show that results can be achieved that are similar to a more complex Random Forest model and competitive to a deep learning baseline.
Explaining Graph-level Predictions with Communication Structure-Aware Cooperative Games
Feb 16, 2022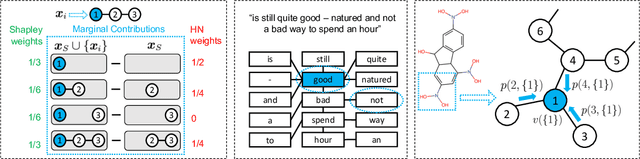
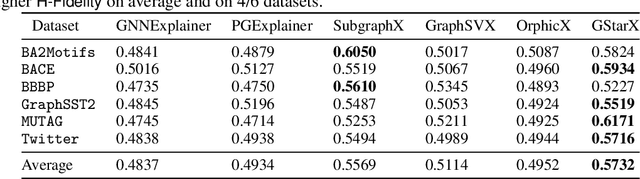
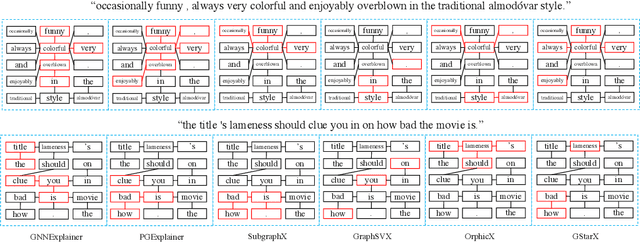
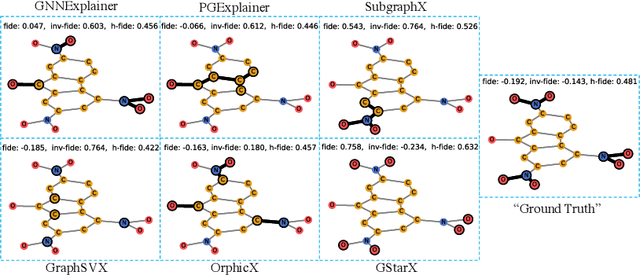
Explaining predictions made by machine learning models is important and have attracted an increased interest. The Shapley value from cooperative game theory has been proposed as a prime approach to compute feature importances towards predictions, especially for images, text, tabular data, and recently graph neural networks (GNNs) on graphs. In this work, we revisit the appropriateness of the Shapley value for graph explanation, where the task is to identify the most important subgraph and constituent nodes for graph-level predictions. We purport that the Shapley value is a no-ideal choice for graph data because it is by definition not structure-aware. We propose a Graph Structure-aware eXplanation (GStarX) method to leverage the critical graph structure information to improve the explanation. Specifically, we propose a scoring function based on a new structure-aware value from the cooperative game theory called the HN value. When used to score node importance, the HN value utilizes graph structures to attribute cooperation surplus between neighbor nodes, resembling message passing in GNNs, so that node importance scores reflect not only the node feature importance, but also the structural roles. We demonstrate that GstarX produces qualitatively more intuitive explanations, and quantitatively improves over strong baselines on chemical graph property prediction and text graph sentiment classification.
Non parametric estimation of causal populations in a counterfactual scenario
Dec 08, 2021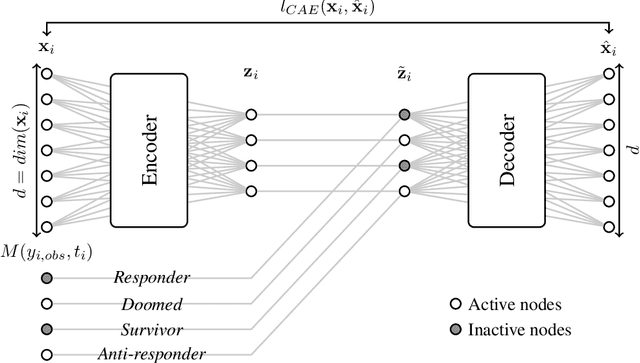
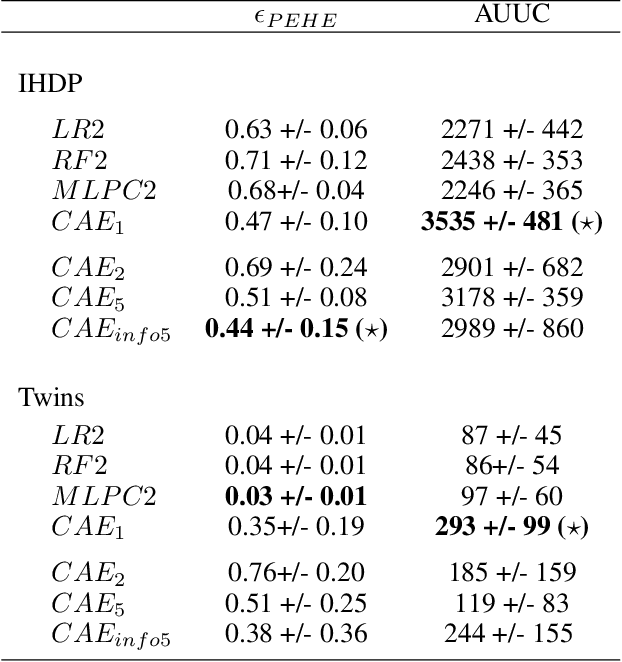
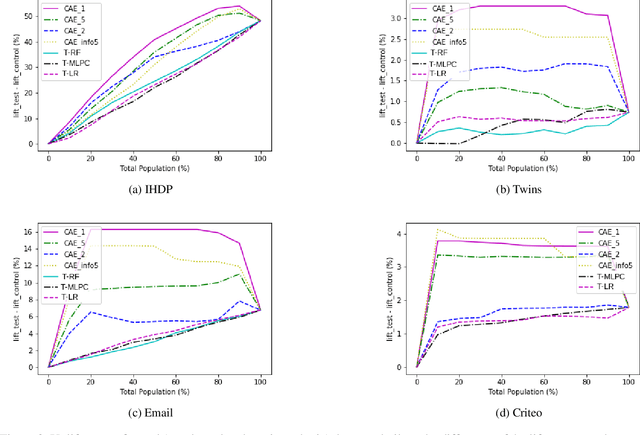
In causality, estimating the effect of a treatment without confounding inference remains a major issue because requires to assess the outcome in both case with and without treatment. Not being able to observe simultaneously both of them, the estimation of potential outcome remains a challenging task. We propose an innovative approach where the problem is reformulated as a missing data model. The aim is to estimate the hidden distribution of \emph{causal populations}, defined as a function of treatment and outcome. A Causal Auto-Encoder (CAE), enhanced by a prior dependent on treatment and outcome information, assimilates the latent space to the probability distribution of the target populations. The features are reconstructed after being reduced to a latent space and constrained by a mask introduced in the intermediate layer of the network, containing treatment and outcome information.
Aerial Images Meet Crowdsourced Trajectories: A New Approach to Robust Road Extraction
Nov 30, 2021
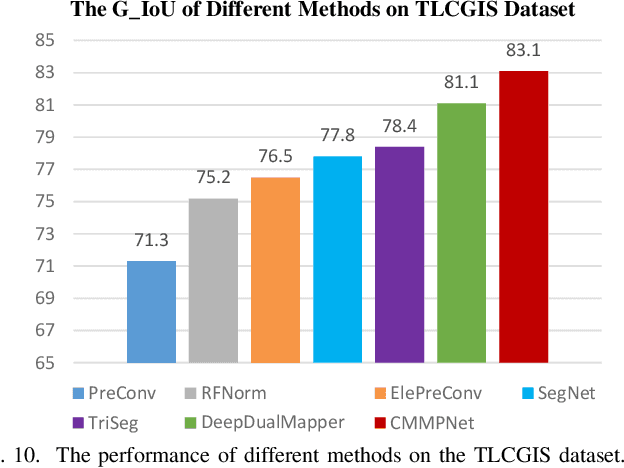
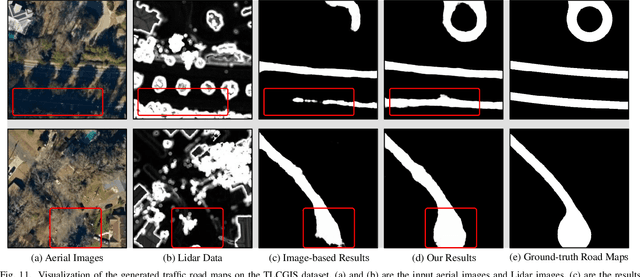
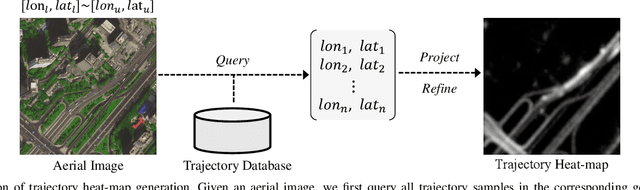
Land remote sensing analysis is a crucial research in earth science. In this work, we focus on a challenging task of land analysis, i.e., automatic extraction of traffic roads from remote sensing data, which has widespread applications in urban development and expansion estimation. Nevertheless, conventional methods either only utilized the limited information of aerial images, or simply fused multimodal information (e.g., vehicle trajectories), thus cannot well recognize unconstrained roads. To facilitate this problem, we introduce a novel neural network framework termed Cross-Modal Message Propagation Network (CMMPNet), which fully benefits the complementary different modal data (i.e., aerial images and crowdsourced trajectories). Specifically, CMMPNet is composed of two deep Auto-Encoders for modality-specific representation learning and a tailor-designed Dual Enhancement Module for cross-modal representation refinement. In particular, the complementary information of each modality is comprehensively extracted and dynamically propagated to enhance the representation of another modality. Extensive experiments on three real-world benchmarks demonstrate the effectiveness of our CMMPNet for robust road extraction benefiting from blending different modal data, either using image and trajectory data or image and Lidar data. From the experimental results, we observe that the proposed approach outperforms current state-of-the-art methods by large margins.
An Efficient Combinatorial Optimization Model Using Learning-to-Rank Distillation
Dec 24, 2021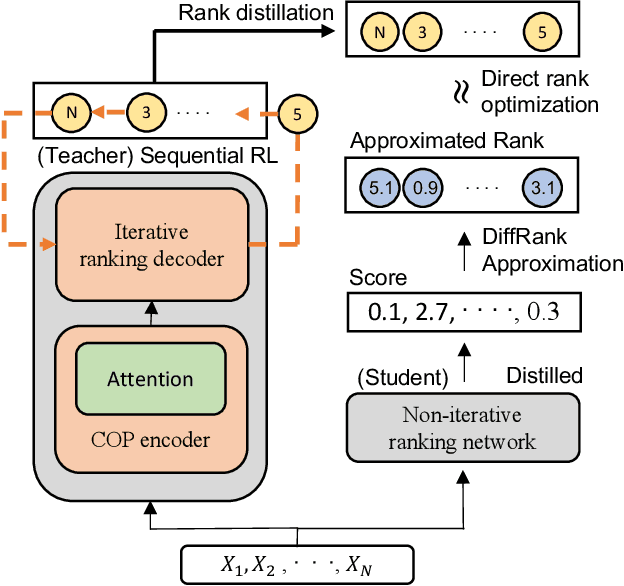
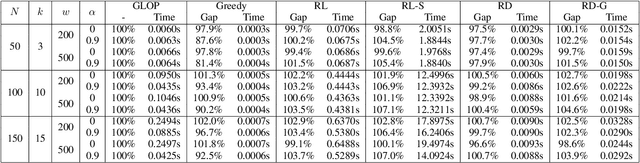
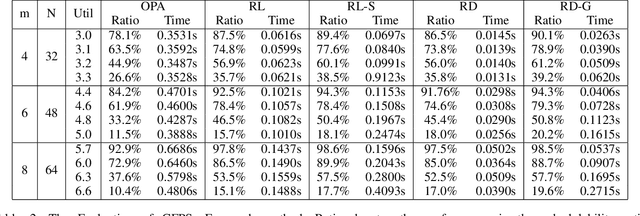
Recently, deep reinforcement learning (RL) has proven its feasibility in solving combinatorial optimization problems (COPs). The learning-to-rank techniques have been studied in the field of information retrieval. While several COPs can be formulated as the prioritization of input items, as is common in the information retrieval, it has not been fully explored how the learning-to-rank techniques can be incorporated into deep RL for COPs. In this paper, we present the learning-to-rank distillation-based COP framework, where a high-performance ranking policy obtained by RL for a COP can be distilled into a non-iterative, simple model, thereby achieving a low-latency COP solver. Specifically, we employ the approximated ranking distillation to render a score-based ranking model learnable via gradient descent. Furthermore, we use the efficient sequence sampling to improve the inference performance with a limited delay. With the framework, we demonstrate that a distilled model not only achieves comparable performance to its respective, high-performance RL, but also provides several times faster inferences. We evaluate the framework with several COPs such as priority-based task scheduling and multidimensional knapsack, demonstrating the benefits of the framework in terms of inference latency and performance.
Collaborative Training of Heterogeneous Reinforcement Learning Agents in Environments with Sparse Rewards: What and When to Share?
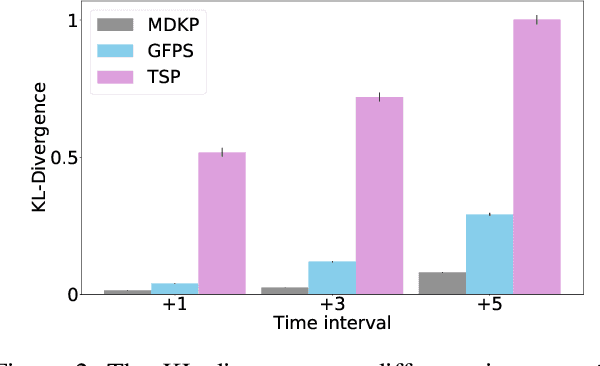
Feb 24, 2022
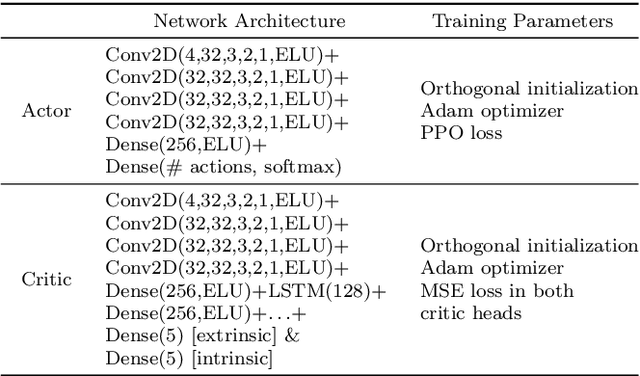
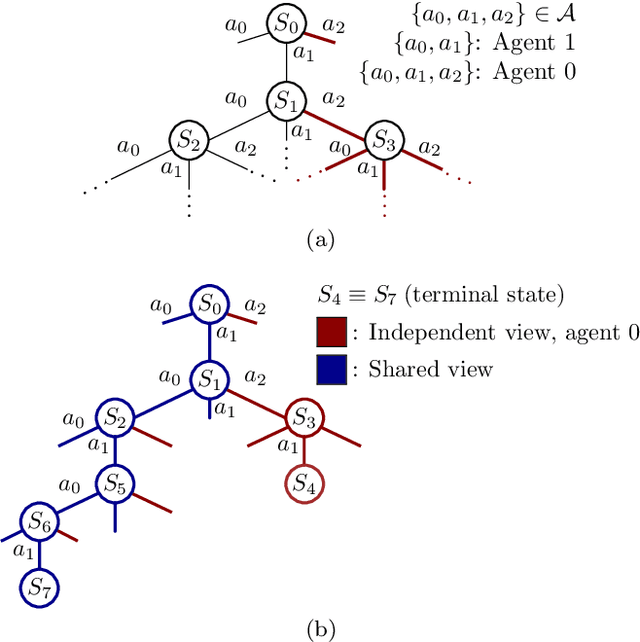
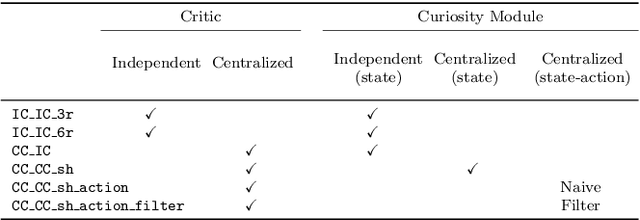
In the early stages of human life, babies develop their skills by exploring different scenarios motivated by their inherent satisfaction rather than by extrinsic rewards from the environment. This behavior, referred to as intrinsic motivation, has emerged as one solution to address the exploration challenge derived from reinforcement learning environments with sparse rewards. Diverse exploration approaches have been proposed to accelerate the learning process over single- and multi-agent problems with homogeneous agents. However, scarce studies have elaborated on collaborative learning frameworks between heterogeneous agents deployed into the same environment, but interacting with different instances of the latter without any prior knowledge. Beyond the heterogeneity, each agent's characteristics grant access only to a subset of the full state space, which may hide different exploration strategies and optimal solutions. In this work we combine ideas from intrinsic motivation and transfer learning. Specifically, we focus on sharing parameters in actor-critic model architectures and on combining information obtained through intrinsic motivation with the aim of having a more efficient exploration and faster learning. We test our strategies through experiments performed over a modified ViZDooM's My Way Home scenario, which is more challenging than its original version and allows evaluating the heterogeneity between agents. Our results reveal different ways in which a collaborative framework with little additional computational cost can outperform an independent learning process without knowledge sharing. Additionally, we depict the need for modulating correctly the importance between the extrinsic and intrinsic rewards to avoid undesired agent behaviors.
Constraining cosmological parameters from N-body simulations with Bayesian Neural Networks
Dec 22, 2021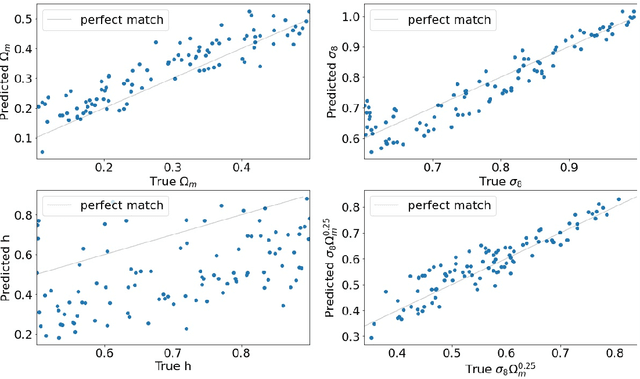
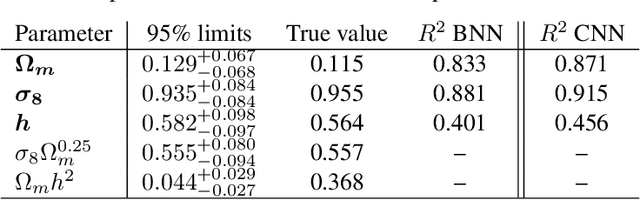
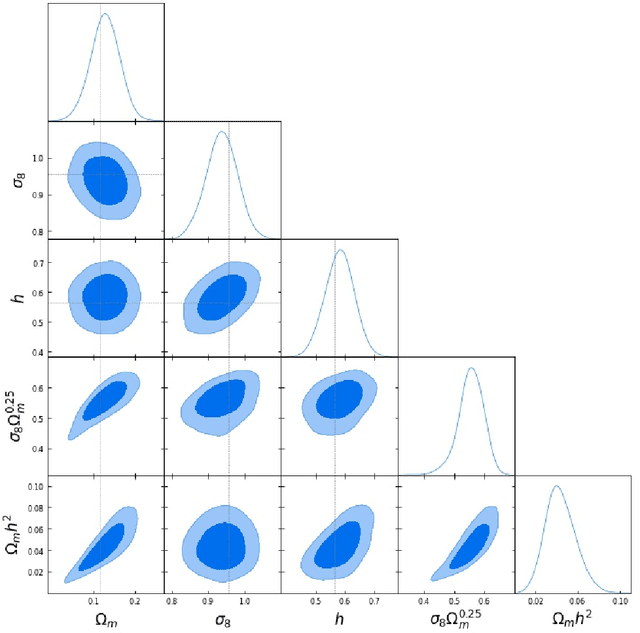
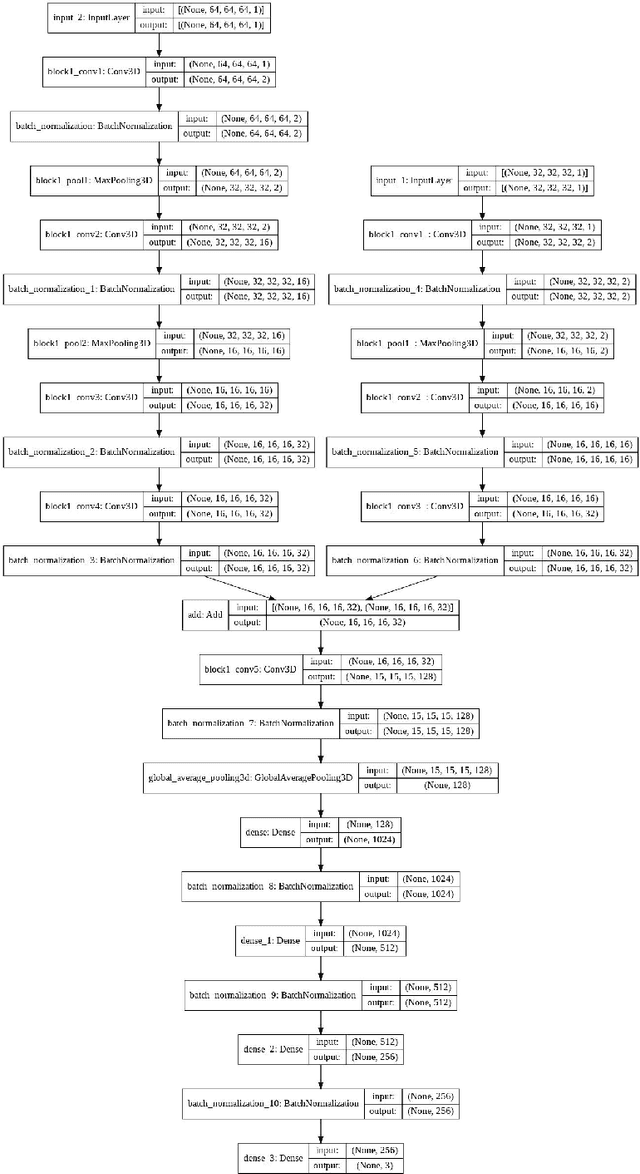
In this paper, we use The Quijote simulations in order to extract the cosmological parameters through Bayesian Neural Networks. This kind of model has a remarkable ability to estimate the associated uncertainty, which is one of the ultimate goals in the precision cosmology era. We demonstrate the advantages of BNNs for extracting more complex output distributions and non-Gaussianities information from the simulations.
A Comprehensive Analysis of Information Leakage in Deep Transfer Learning
Sep 04, 2020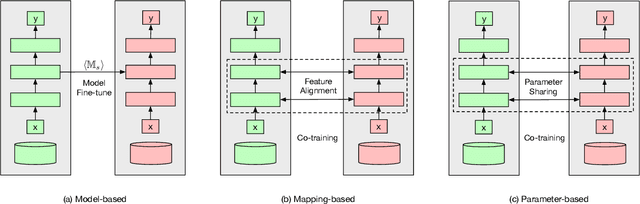

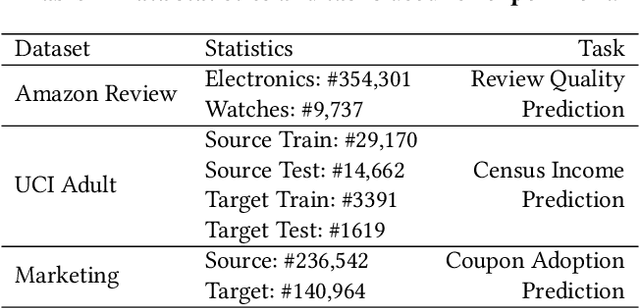
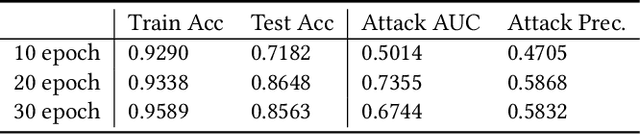
Transfer learning is widely used for transferring knowledge from a source domain to the target domain where the labeled data is scarce. Recently, deep transfer learning has achieved remarkable progress in various applications. However, the source and target datasets usually belong to two different organizations in many real-world scenarios, potential privacy issues in deep transfer learning are posed. In this study, to thoroughly analyze the potential privacy leakage in deep transfer learning, we first divide previous methods into three categories. Based on that, we demonstrate specific threats that lead to unintentional privacy leakage in each category. Additionally, we also provide some solutions to prevent these threats. To the best of our knowledge, our study is the first to provide a thorough analysis of the information leakage issues in deep transfer learning methods and provide potential solutions to the issue. Extensive experiments on two public datasets and an industry dataset are conducted to show the privacy leakage under different deep transfer learning settings and defense solution effectiveness.
Learning Multi-granularity User Intent Unit for Session-based Recommendation
Jan 10, 2022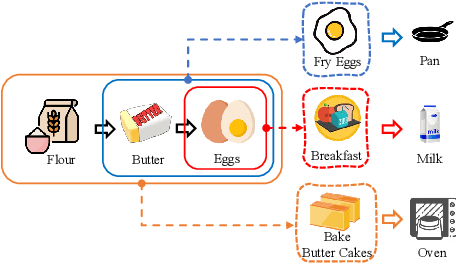
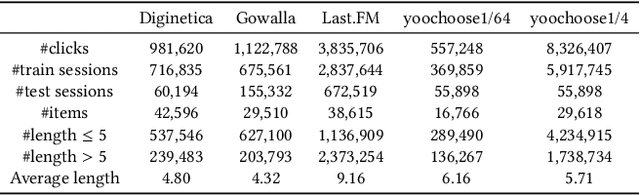
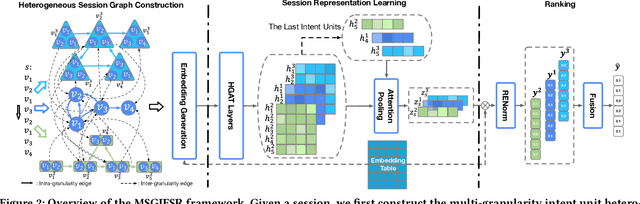
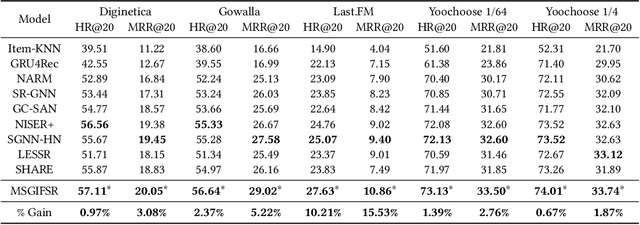
Session-based recommendation aims to predict a user's next action based on previous actions in the current session. The major challenge is to capture authentic and complete user preferences in the entire session. Recent work utilizes graph structure to represent the entire session and adopts Graph Neural Network to encode session information. This modeling choice has been proved to be effective and achieved remarkable results. However, most of the existing studies only consider each item within the session independently and do not capture session semantics from a high-level perspective. Such limitation often leads to severe information loss and increases the difficulty of capturing long-range dependencies within a session. Intuitively, compared with individual items, a session snippet, i.e., a group of locally consecutive items, is able to provide supplemental user intents which are hardly captured by existing methods. In this work, we propose to learn multi-granularity consecutive user intent unit to improve the recommendation performance. Specifically, we creatively propose Multi-granularity Intent Heterogeneous Session Graph which captures the interactions between different granularity intent units and relieves the burden of long-dependency. Moreover, we propose the Intent Fusion Ranking module to compose the recommendation results from various granularity user intents. Compared with current methods that only leverage intents from individual items, IFR benefits from different granularity user intents to generate more accurate and comprehensive session representation, thus eventually boosting recommendation performance. We conduct extensive experiments on five session-based recommendation datasets and the results demonstrate the effectiveness of our method.