 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mask-based Latent Reconstruction for Reinforcement Learning
Jan 28, 2022
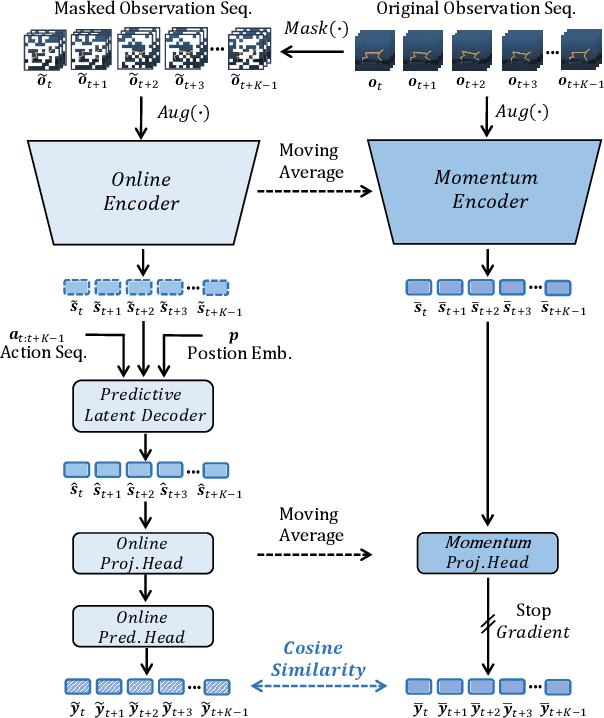
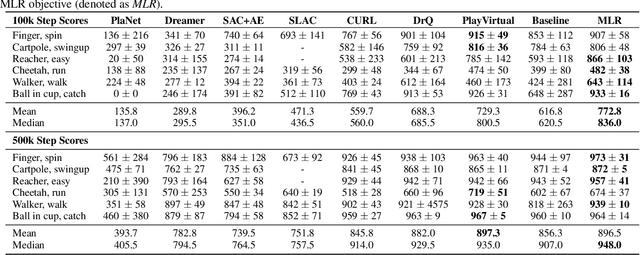
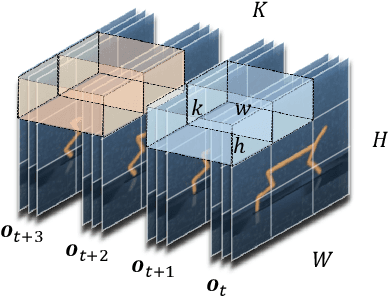
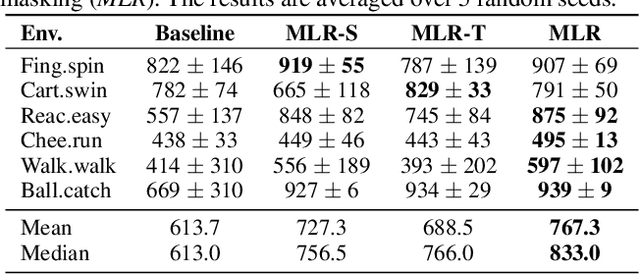
For deep reinforcement learning (RL) from pixels, learning effective state representations is crucial for achieving high performance. However, in practice, limited experience and high-dimensional input prevent effective representation learning. To address this, motivated by the success of masked modeling in other research fields, we introduce mask-based reconstruction to promote state representation learning in RL. Specifically, we propose a simple yet effective self-supervised method, Mask-based Latent Reconstruction (MLR), to predict the complete state representations in the latent space from the observations with spatially and temporally masked pixels. MLR enables the better use of context information when learning state representations to make them more informative, which facilitates RL agent training. Extensive experiments show that our MLR significantly improves the sample efficiency in RL and outperforms the state-of-the-art sample-efficient RL methods on multiple continuous benchmark environments.
Factorizer: A Scalable Interpretable Approach to Context Modeling for Medical Image Segmentation
Feb 28, 2022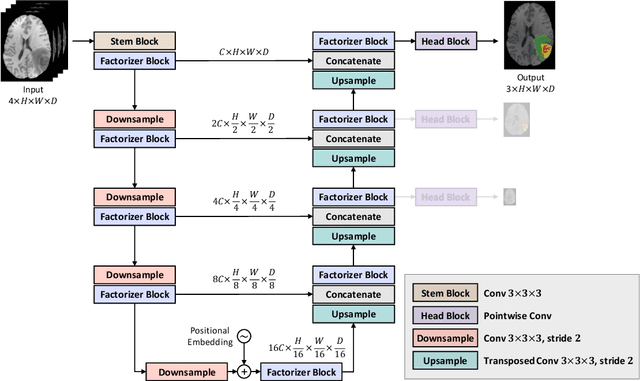
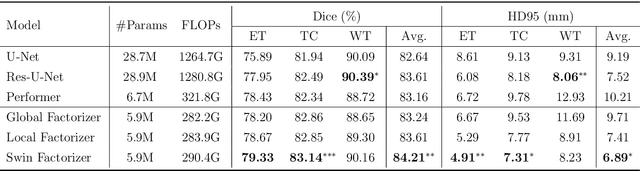
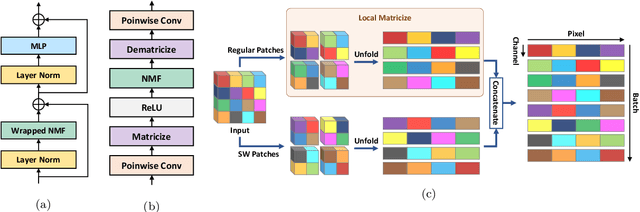
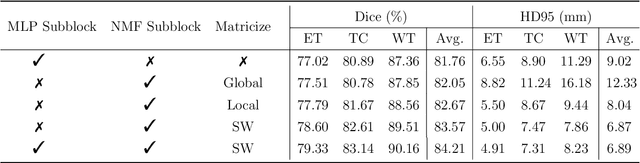
Convolutional Neural Networks (CNNs) with U-shaped architectures have dominated medical image segmentation, which is crucial for various clinical purposes. However, the inherent locality of convolution makes CNNs fail to fully exploit global context, essential for better recognition of some structures, e.g., brain lesions. Transformers have recently proved promising performance on vision tasks, including semantic segmentation, mainly due to their capability of modeling long-range dependencies. Nevertheless, the quadratic complexity of attention makes existing Transformer-based models use self-attention layers only after somehow reducing the image resolution, which limits the ability to capture global contexts present at higher resolutions. Therefore, this work introduces a family of models, dubbed Factorizer, which leverages the power of low-rank matrix factorization for constructing an end-to-end segmentation model. Specifically, we propose a linearly scalable approach to context modeling, formulating Nonnegative Matrix Factorization (NMF) as a differentiable layer integrated into a U-shaped architecture. The shifted window technique is also utilized in combination with NMF to effectively aggregate local information. Factorizers compete favorably with CNNs and Transformers in terms of accuracy, scalability, and interpretability, achieving state-of-the-art results on the BraTS dataset for brain tumor segmentation, with Dice scores of 79.33%, 83.14%, and 90.16% for enhancing tumor, tumor core, and whole tumor, respectively. Highly meaningful NMF components give an additional interpretability advantage to Factorizers over CNNs and Transformers. Moreover, our ablation studies reveal a distinctive feature of Factorizers that enables a significant speed-up in inference for a trained Factorizer without any extra steps and without sacrificing much accuracy.
Learning with Asymmetric Kernels: Least Squares and Feature Interpretation
Feb 03, 2022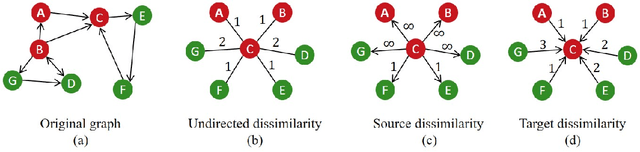
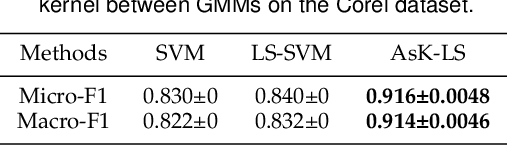
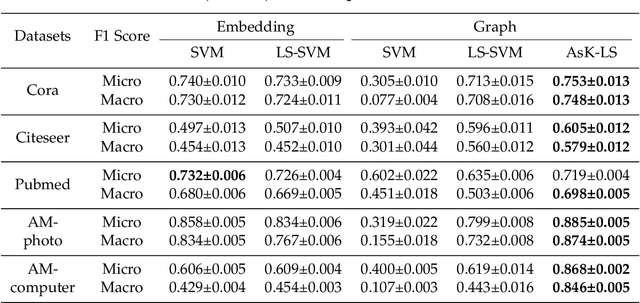
Asymmetric kernels naturally exist in real life, e.g., for conditional probability and directed graphs. However, most of the existing kernel-based learning methods require kernels to be symmetric, which prevents the use of asymmetric kernels. This paper addresses the asymmetric kernel-based learning in the framework of the least squares support vector machine named AsK-LS, resulting in the first classification method that can utilize asymmetric kernels directly. We will show that AsK-LS can learn with asymmetric features, namely source and target features, while the kernel trick remains applicable, i.e., the source and target features exist but are not necessarily known. Besides, the computational burden of AsK-LS is as cheap as dealing with symmetric kernels. Experimental results on the Corel database, directed graphs, and the UCI database will show that in the case asymmetric information is crucial, the proposed AsK-LS can learn with asymmetric kernels and performs much better than the existing kernel methods that have to do symmetrization to accommodate asymmetric kernels.
A Deep Learning Approach for Network-wide Dynamic Traffic Prediction during Hurricane Evacuation
Feb 25, 2022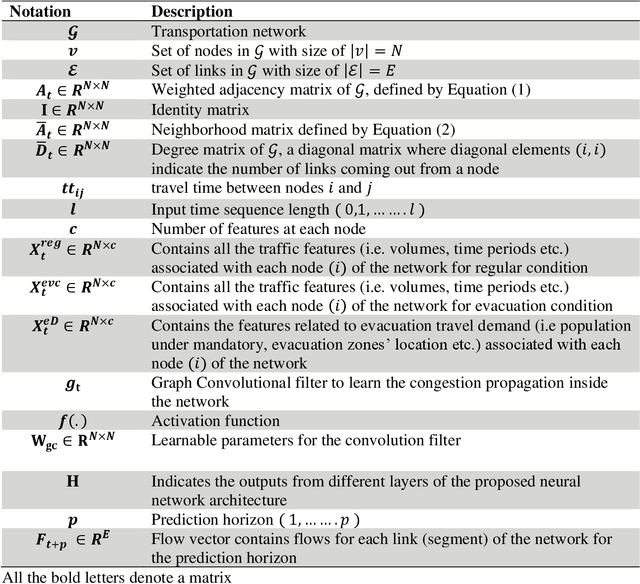
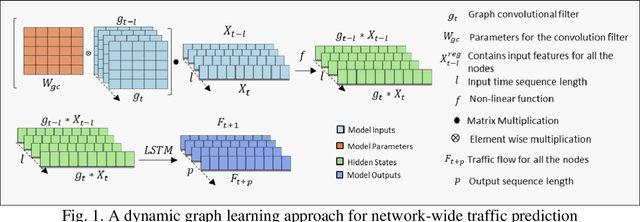
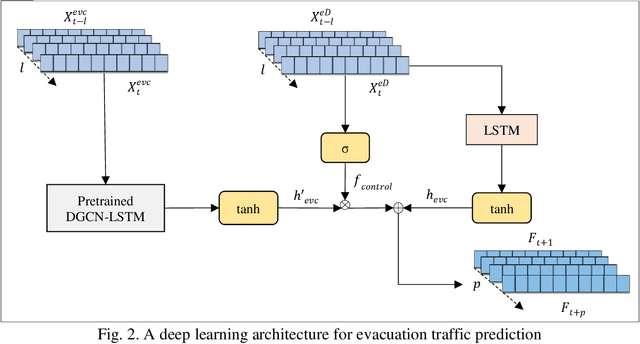

Proactive evacuation traffic management largely depends on real-time monitoring and prediction of traffic flow at a high spatiotemporal resolution. However, evacuation traffic prediction is challenging due to the uncertainties caused by sudden changes in projected hurricane paths and consequently household evacuation behavior. Moreover, modeling spatiotemporal traffic flow patterns requires extensive data over a longer time period, whereas evacuations typically last for 2 to 5 days. In this paper, we present a novel data-driven approach for predicting evacuation traffic at a network scale. We develop a dynamic graph convolution LSTM (DGCN-LSTM) model to learn the network dynamics of hurricane evacuation. We first train the model for non-evacuation period traffic data showing that the model outperforms existing deep learning models for predicting non-evacuation period traffic with an RMSE value of 226.84. However, when we apply the model for evacuation period, the RMSE value increased to 1440.99. We overcome this issue by adopting a transfer learning approach with additional features related to evacuation traffic demand such as distance from the evacuation zone, time to landfall, and other zonal level features to control the transfer of information (network dynamics) from non-evacuation periods to evacuation periods. The final transfer learned DGCN-LSTM model performs well to predict evacuation traffic flow (RMSE=399.69). The implemented model can be applied to predict evacuation traffic over a longer forecasting horizon (6 hour). It will assist transportation agencies to activate appropriate traffic management strategies to reduce delays for evacuating traffic.
Lipschitz-constrained Unsupervised Skill Discovery
Feb 08, 2022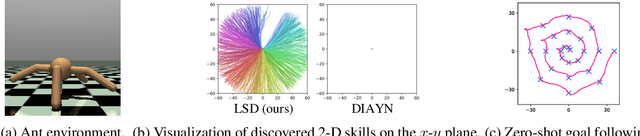

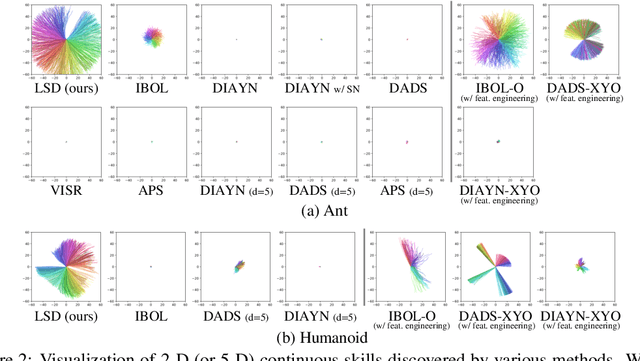
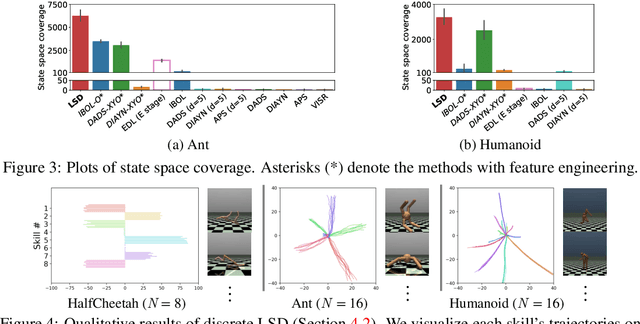
We study the problem of unsupervised skill discovery, whose goal is to learn a set of diverse and useful skills with no external reward. There have been a number of skill discovery methods based on maximizing the mutual information (MI) between skills and states. However, we point out that their MI objectives usually prefer static skills to dynamic ones, which may hinder the application for downstream tasks. To address this issue, we propose Lipschitz-constrained Skill Discovery (LSD), which encourages the agent to discover more diverse, dynamic, and far-reaching skills. Another benefit of LSD is that its learned representation function can be utilized for solving goal-following downstream tasks even in a zero-shot manner - i.e., without further training or complex planning. Through experiments on various MuJoCo robotic locomotion and manipulation environments, we demonstrate that LSD outperforms previous approaches in terms of skill diversity, state space coverage, and performance on seven downstream tasks including the challenging task of following multiple goals on Humanoid. Our code and videos are available at https://shpark.me/projects/lsd/.
Unitary-Precoded Single-Carrier Waveforms for High Mobility: Detection and Channel Estimation
Jan 25, 2022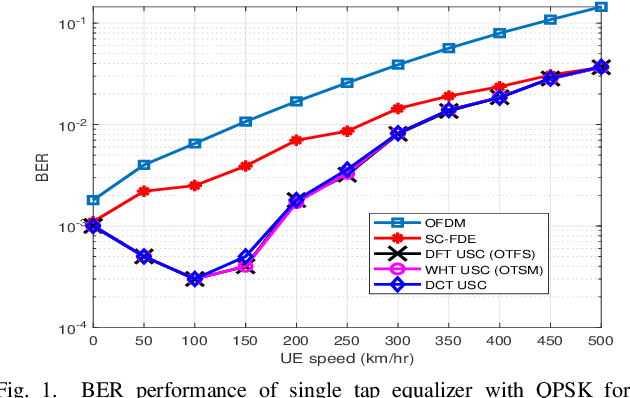
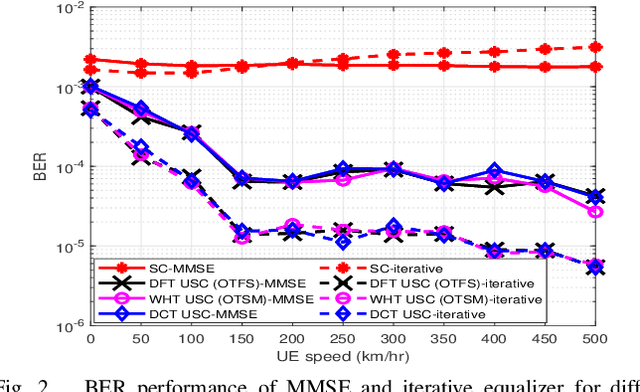
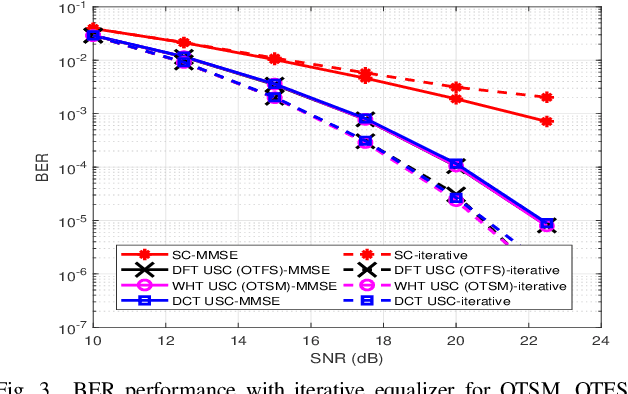
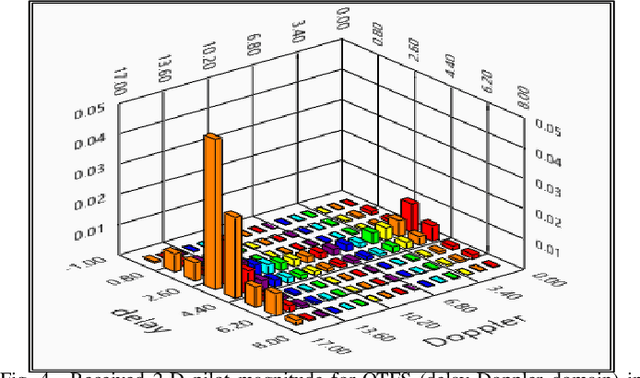
This paper presents unitary-precoded single-carrier (USC) modulation as a family of waveforms based on multiplexing the information symbols on time domain unitary basis functions. The common property of these basis functions is that they span the entire time and frequency plane. The recently proposed orthogonal time frequency space (OTFS) and orthogonal time sequency multiplexing (OTSM) based on discrete Fourier transform (DFT) and Walsh Hadamard transform (WHT), respectively, fall in the general framework of USC waveforms. In this work, we present channel estimation and detection methods that work for any USC waveform and numerically show that any choice of unitary precoding results in the same error performance. Lastly, we implement some USC systems and compare their performance with OFDM in a real-time indoor setting using an SDR platform.
3D-Aware Indoor Scene Synthesis with Depth Priors
Feb 17, 2022
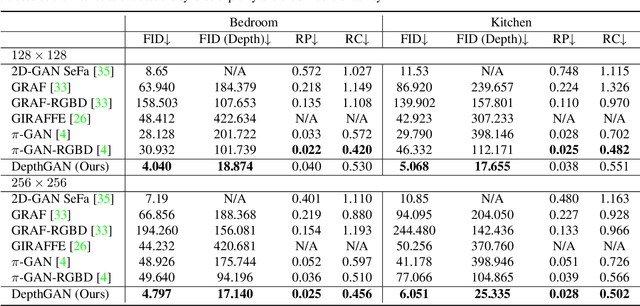
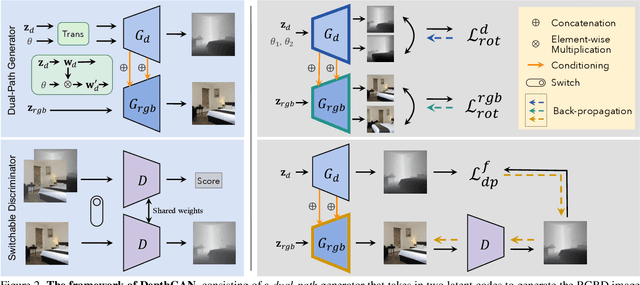
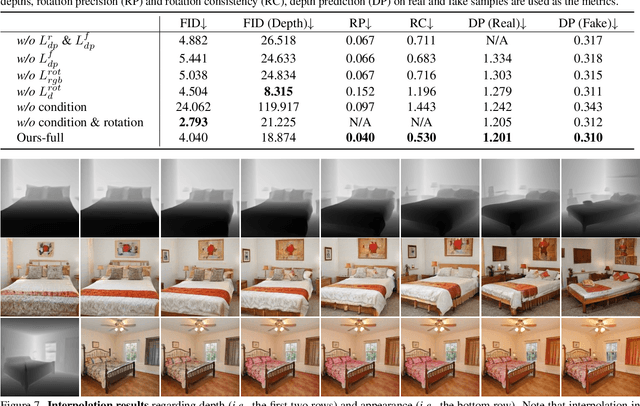
Despite the recent advancement of Generative Adversarial Networks (GANs) in learning 3D-aware image synthesis from 2D data, existing methods fail to model indoor scenes due to the large diversity of room layouts and the objects inside. We argue that indoor scenes do not have a shared intrinsic structure, and hence only using 2D images cannot adequately guide the model with the 3D geometry. In this work, we fill in this gap by introducing depth as a 3D prior. Compared with other 3D data formats, depth better fits the convolution-based generation mechanism and is more easily accessible in practice. Specifically, we propose a dual-path generator, where one path is responsible for depth generation, whose intermediate features are injected into the other path as the condition for appearance rendering. Such a design eases the 3D-aware synthesis with explicit geometry information. Meanwhile, we introduce a switchable discriminator both to differentiate real v.s. fake domains and to predict the depth from a given input. In this way, the discriminator can take the spatial arrangement into account and advise the generator to learn an appropriate depth condition. Extensive experimental results suggest that our approach is capable of synthesizing indoor scenes with impressively good quality and 3D consistency, significantly outperforming state-of-the-art alternatives.
Recommendation Unlearning
Jan 18, 2022
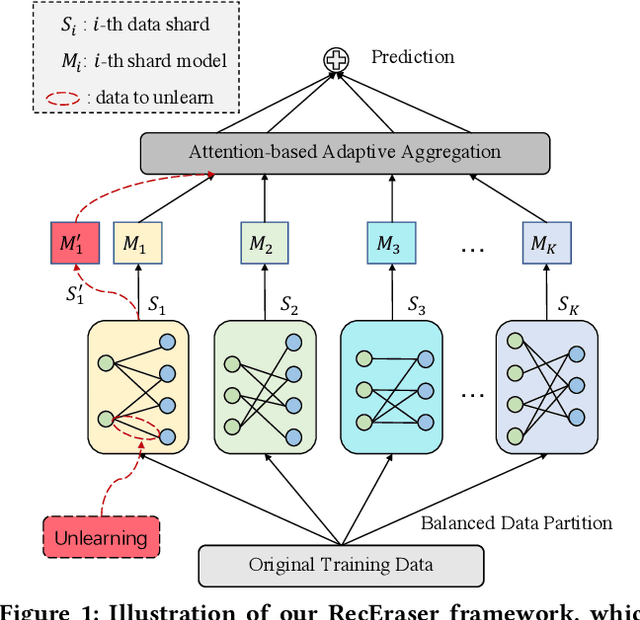
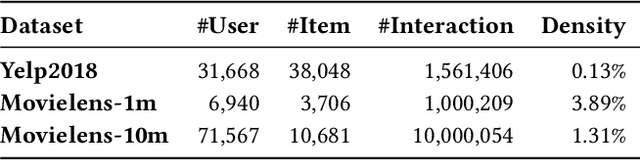
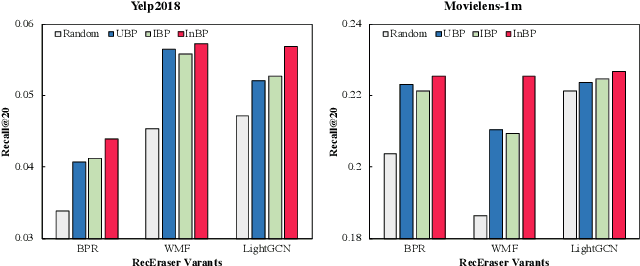
Recommender systems provide essential web services by learning users' personal preferences from collected data. However, in many cases, systems also need to forget some training data. From the perspective of privacy, several privacy regulations have recently been proposed, requiring systems to eliminate any impact of the data whose owner requests to forget. From the perspective of utility, if a system's utility is damaged by some bad data, the system needs to forget these data to regain utility. From the perspective of usability, users can delete noise and incorrect entries so that a system can provide more useful recommendations. While unlearning is very important, it has not been well-considered in existing recommender systems. Although there are some researches have studied the problem of machine unlearning in the domains of image and text data, existing methods can not been directly applied to recommendation as they are unable to consider the collaborative information. In this paper, we propose RecEraser, a general and efficient machine unlearning framework tailored to recommendation task. The main idea of RecEraser is to partition the training set into multiple shards and train a constituent model for each shard. Specifically, to keep the collaborative information of the data, we first design three novel data partition algorithms to divide training data into balanced groups based on their similarity. Then, considering that different shard models do not uniformly contribute to the final prediction, we further propose an adaptive aggregation method to improve the global model utility. Experimental results on three public benchmarks show that RecEraser can not only achieve efficient unlearning, but also outperform the state-of-the-art unlearning methods in terms of model utility. The source code can be found at https://github.com/chenchongthu/Recommendation-Unlearning
TransCG: A Large-Scale Real-World Dataset for Transparent Object Depth Completion and Grasping
Feb 17, 2022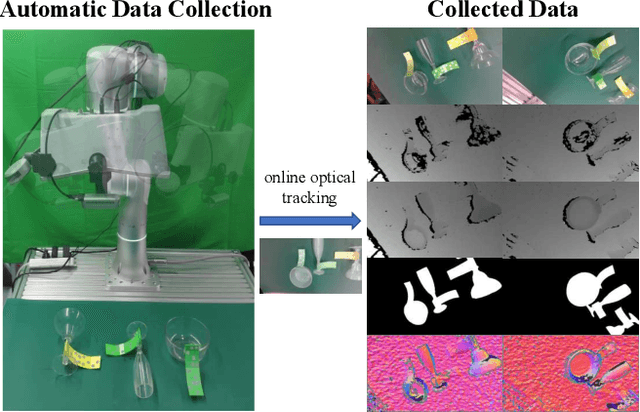

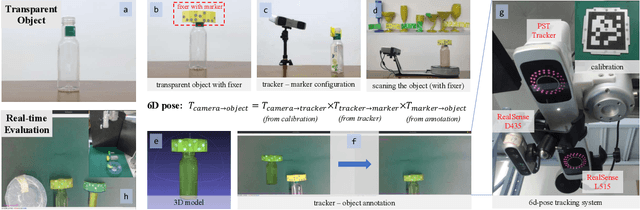
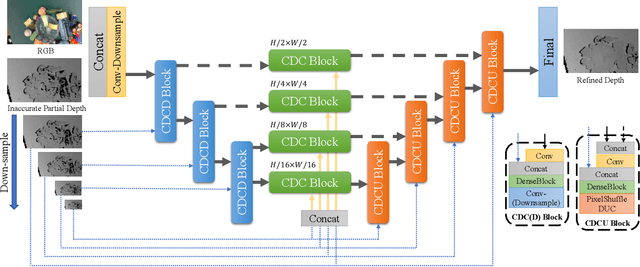
Transparent objects are common in our daily life and frequently handled in the automated production line. Robust vision-based robotic grasping and manipulation for these objects would be beneficial for automation. However, the majority of current grasping algorithms would fail in this case since they heavily rely on the depth image, while ordinary depth sensors usually fail to produce accurate depth information for transparent objects owing to the reflection and refraction of light. In this work, we address this issue by contributing a large-scale real-world dataset for transparent object depth completion, which contains 57,715 RGB-D images from 130 different scenes. Our dataset is the first large-scale real-world dataset and provides the most comprehensive annotation. Cross-domain experiments show that our dataset has a great generalization ability. Moreover, we propose an end-to-end depth completion network, which takes the RGB image and the inaccurate depth map as inputs and outputs a refined depth map. Experiments demonstrate superior efficacy, efficiency and robustness of our method over previous works, and it is able to process images of high resolutions under limited hardware resources. Real robot experiment shows that our method can also be applied to novel object grasping robustly. The full dataset and our method are publicly available at www.graspnet.net/transcg.
Graph-Relational Domain Adaptation
Feb 08, 2022
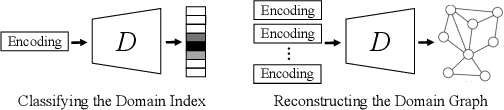
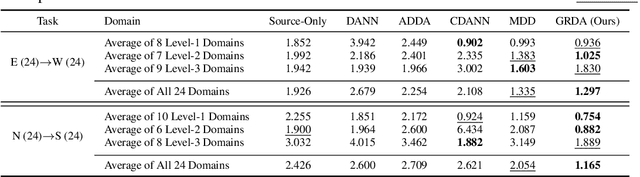
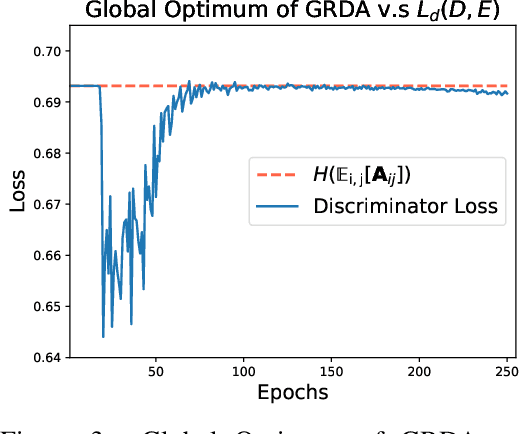
Existing domain adaptation methods tend to treat every domain equally and align them all perfectly. Such uniform alignment ignores topological structures among different domains; therefore it may be beneficial for nearby domains, but not necessarily for distant domains. In this work, we relax such uniform alignment by using a domain graph to encode domain adjacency, e.g., a graph of states in the US with each state as a domain and each edge indicating adjacency, thereby allowing domains to align flexibly based on the graph structure. We generalize the existing adversarial learning framework with a novel graph discriminator using encoding-conditioned graph embeddings. Theoretical analysis shows that at equilibrium, our method recovers classic domain adaptation when the graph is a clique, and achieves non-trivial alignment for other types of graphs. Empirical results show that our approach successfully generalizes uniform alignment, naturally incorporates domain information represented by graphs, and improves upon existing domain adaptation methods on both synthetic and real-world datasets. Code will soon be available at https://github.com/Wang-ML-Lab/GRDA.