 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information-Theoretic Generalization Bounds for Meta-Learning and Applications
May 09, 2020
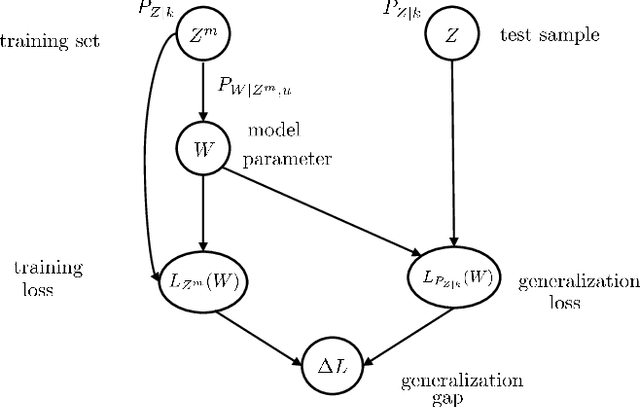
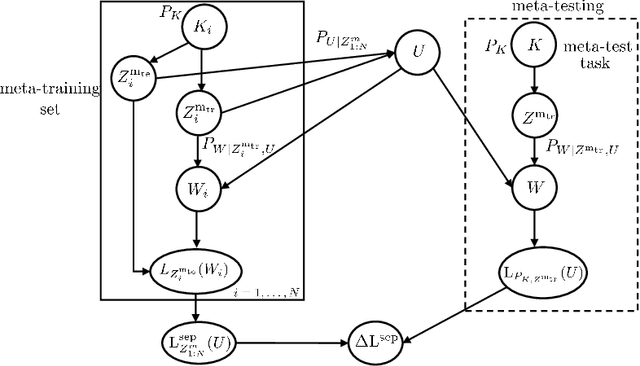
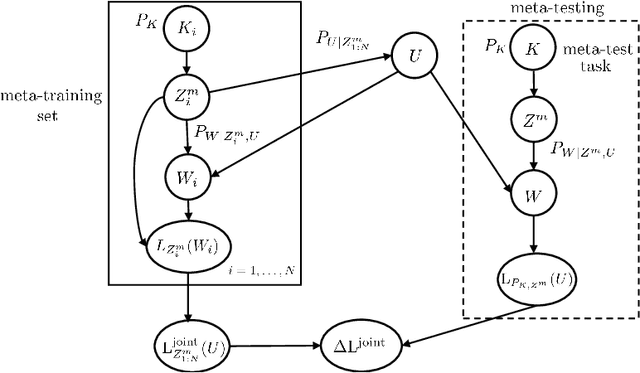
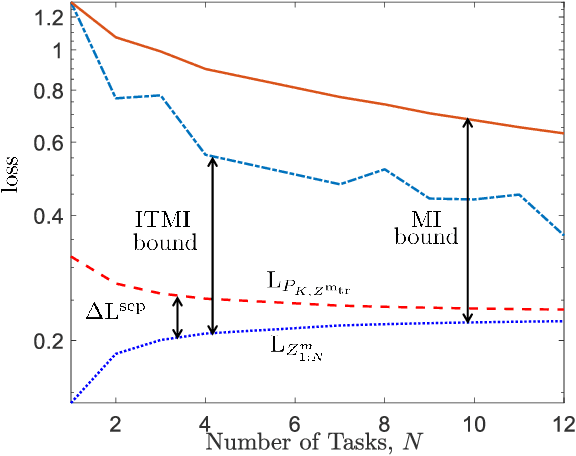
Meta-learning, or "learning to learn", refers to techniques that infer an inductive bias from data corresponding to multiple related tasks with the goal of improving the sample efficiency for new, previously unobserved, tasks. A key performance measure for meta-learning is the meta-generalization gap, that is, the difference between the average loss measured on the meta-training data and on a new, randomly selected task. This paper presents novel information-theoretic upper bounds on the meta-generalization gap. Two broad classes of meta-learning algorithms are considered that uses either separate within-task training and test sets, like MAML, or joint within-task training and test sets, like Reptile. Extending the existing work for conventional learning, an upper bound on the meta-generalization gap is derived for the former class that depends on the mutual information (MI) between the output of the meta-learning algorithm and its input meta-training data. For the latter, the derived bound includes an additional MI between the output of the per-task learning procedure and corresponding data set to capture within-task uncertainty. Tighter bounds are then developed for the two classes via novel Individual Task MI (ITMI) bounds. Applications of the derived bounds are finally discussed, including a broad class of noisy iterative algorithms for meta-learning.
CCasGNN: Collaborative Cascade Prediction Based on Graph Neural Networks
Dec 07, 2021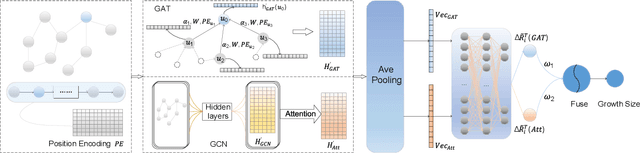
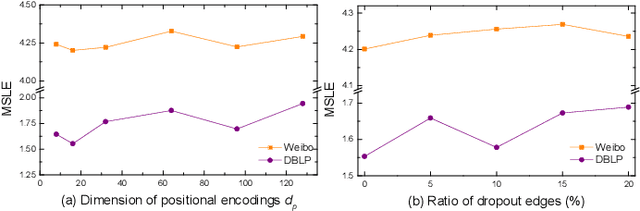
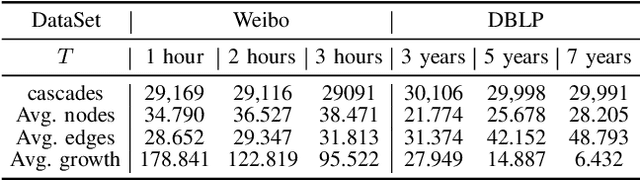
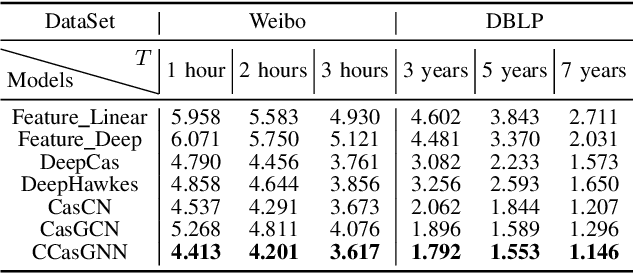
Cascade prediction aims at modeling information diffusion in the network. Most previous methods concentrate on mining either structural or sequential features from the network and the propagation path. Recent efforts devoted to combining network structure and sequence features by graph neural networks and recurrent neural networks. Nevertheless, the limitation of spectral or spatial methods restricts the improvement of prediction performance. Moreover, recurrent neural networks are time-consuming and computation-expensive, which causes the inefficiency of prediction. Here, we propose a novel method CCasGNN considering the individual profile, structural features, and sequence information. The method benefits from using a collaborative framework of GAT and GCN and stacking positional encoding into the layers of graph neural networks, which is different from all existing ones and demonstrates good performance. The experiments conducted on two real-world datasets confirm that our method significantly improves the prediction accuracy compared to state-of-the-art approaches. What's more, the ablation study investigates the contribution of each component in our method.
RerrFact: Reduced Evidence Retrieval Representations for Scientific Claim Verification
Feb 05, 2022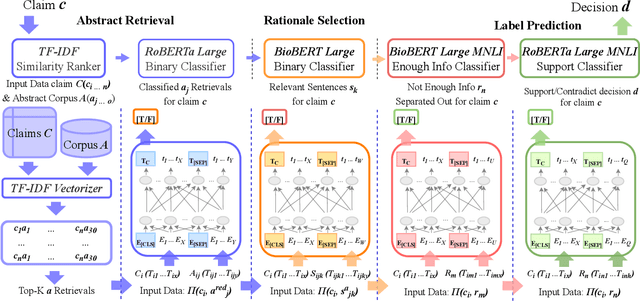



Exponential growth in digital information outlets and the race to publish has made scientific misinformation more prevalent than ever. However, the task to fact-verify a given scientific claim is not straightforward even for researchers. Scientific claim verification requires in-depth knowledge and great labor from domain experts to substantiate supporting and refuting evidence from credible scientific sources. The SciFact dataset and corresponding task provide a benchmarking leaderboard to the community to develop automatic scientific claim verification systems via extracting and assimilating relevant evidence rationales from source abstracts. In this work, we propose a modular approach that sequentially carries out binary classification for every prediction subtask as in the SciFact leaderboard. Our simple classifier-based approach uses reduced abstract representations to retrieve relevant abstracts. These are further used to train the relevant rationale-selection model. Finally, we carry out two-step stance predictions that first differentiate non-relevant rationales and then identify supporting or refuting rationales for a given claim. Experimentally, our system RerrFact with no fine-tuning, simple design, and a fraction of model parameters fairs competitively on the leaderboard against large-scale, modular, and joint modeling approaches. We make our codebase available at https://github.com/ashishrana160796/RerrFact.
Multi-relation Message Passing for Multi-label Text Classification
Feb 10, 2022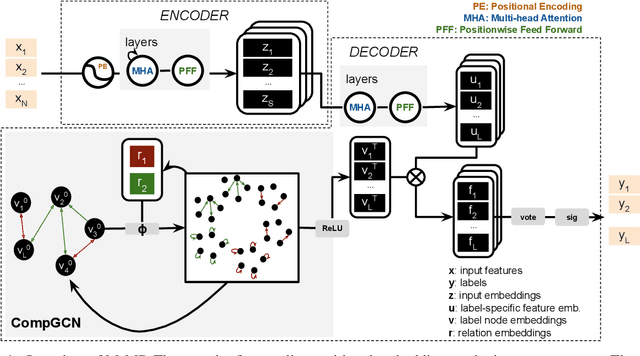

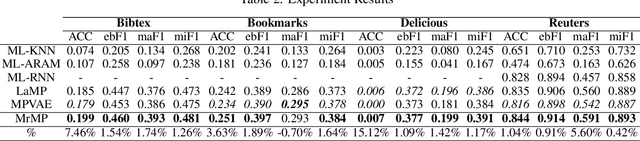
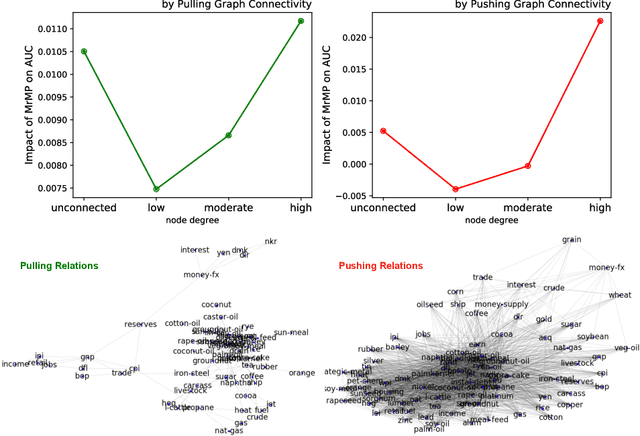
A well-known challenge associated with the multi-label classification problem is modelling dependencies between labels. Most attempts at modelling label dependencies focus on co-occurrences, ignoring the valuable information that can be extracted by detecting label subsets that rarely occur together. For example, consider customer product reviews; a product probably would not simultaneously be tagged by both "recommended" (i.e., reviewer is happy and recommends the product) and "urgent" (i.e., the review suggests immediate action to remedy an unsatisfactory experience). Aside from the consideration of positive and negative dependencies, the direction of a relationship should also be considered. For a multi-label image classification problem, the "ship" and "sea" labels have an obvious dependency, but the presence of the former implies the latter much more strongly than the other way around. These examples motivate the modelling of multiple types of bi-directional relationships between labels. In this paper, we propose a novel method, entitled Multi-relation Message Passing (MrMP), for the multi-label classification problem. Experiments on benchmark multi-label text classification datasets show that the MrMP module yields similar or superior performance compared to state-of-the-art methods. The approach imposes only minor additional computational and memory overheads.
Structural Combinatorial of Network Information System of Systems based on Evolutionary Optimization Method
Feb 22, 2020
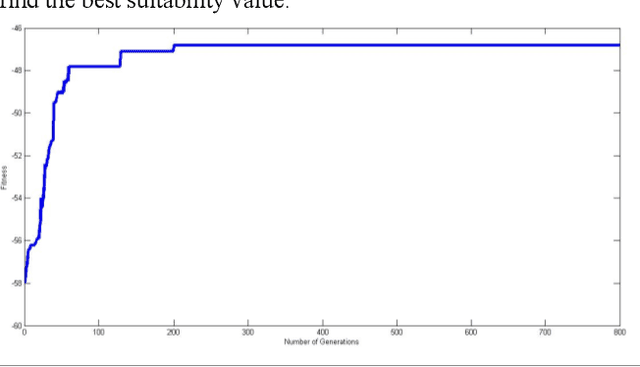
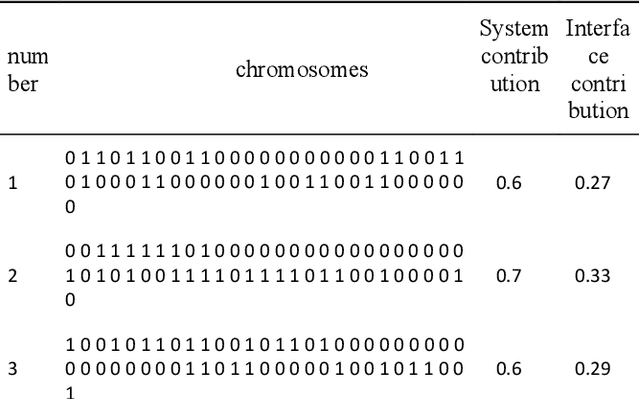
The network information system is a military information network system with evolution characteristics. Evolution is a process of replacement between disorder and order, chaos and equilibrium. Given that the concept of evolution originates from biological systems, in this article, the evolution of network information architecture is analyzed by genetic algorithms, and the network information architecture is represented by chromosomes. Besides, the genetic algorithm is also applied to find the optimal chromosome in the architecture space. The evolutionary simulation is used to predict the optimal scheme of the network information architecture and provide a reference for system construction.
Polyphone disambiguation and accent prediction using pre-trained language models in Japanese TTS front-end
Jan 24, 2022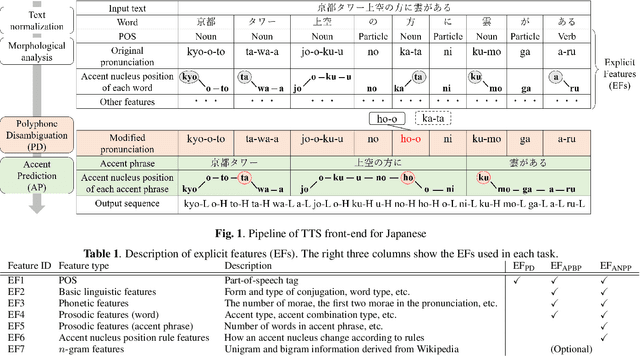



Although end-to-end text-to-speech (TTS) models can generate natural speech, challenges still remain when it comes to estimating sentence-level phonetic and prosodic information from raw text in Japanese TTS systems. In this paper, we propose a method for polyphone disambiguation (PD) and accent prediction (AP). The proposed method incorporates explicit features extracted from morphological analysis and implicit features extracted from pre-trained language models (PLMs). We use BERT and Flair embeddings as implicit features and examine how to combine them with explicit features. Our objective evaluation results showed that the proposed method improved the accuracy by 5.7 points in PD and 6.0 points in AP. Moreover, the perceptual listening test results confirmed that a TTS system employing our proposed model as a front-end achieved a mean opinion score close to that of synthesized speech with ground-truth pronunciation and accent in terms of naturalness.
Spatiotemporal Analysis Using Riemannian Composition of Diffusion Operators
Jan 21, 2022Multivariate time-series have become abundant in recent years, as many data-acquisition systems record information through multiple sensors simultaneously. In this paper, we assume the variables pertain to some geometry and present an operator-based approach for spatiotemporal analysis. Our approach combines three components that are often considered separately: (i) manifold learning for building operators representing the geometry of the variables, (ii) Riemannian geometry of symmetric positive-definite matrices for multiscale composition of operators corresponding to different time samples, and (iii) spectral analysis of the composite operators for extracting different dynamic modes. We propose a method that is analogous to the classical wavelet analysis, which we term Riemannian multi-resolution analysis (RMRA). We provide some theoretical results on the spectral analysis of the composite operators, and we demonstrate the proposed method on simulations and on real data.
Improved 2D Keypoint Detection in Out-of-Balance and Fall Situations -- combining input rotations and a kinematic model
Dec 22, 2021
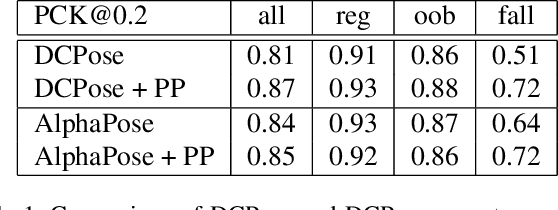
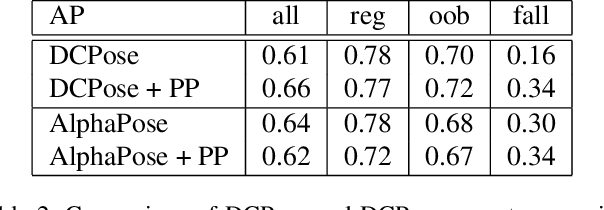
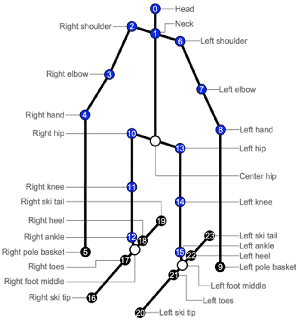
Injury analysis may be one of the most beneficial applications of deep learning based human pose estimation. To facilitate further research on this topic, we provide an injury specific 2D dataset for alpine skiing, covering in total 533 images. We further propose a post processing routine, that combines rotational information with a simple kinematic model. We could improve detection results in fall situations by up to 21% regarding the PCK@0.2 metric.
Learning To Generate Piano Music With Sustain Pedals
Nov 01, 2021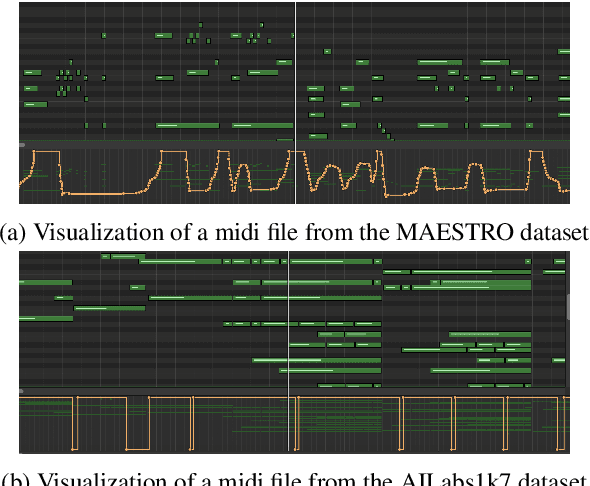
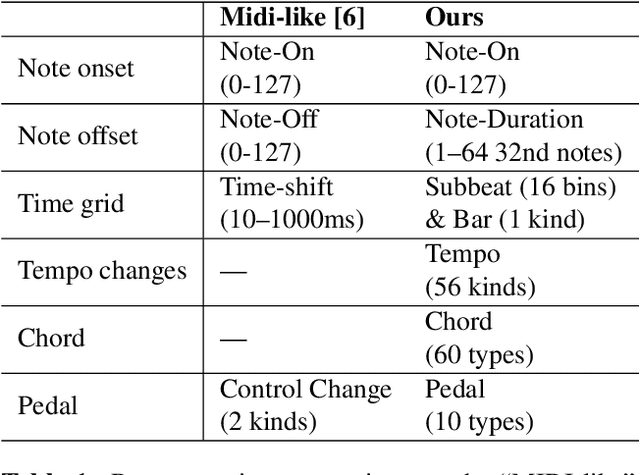
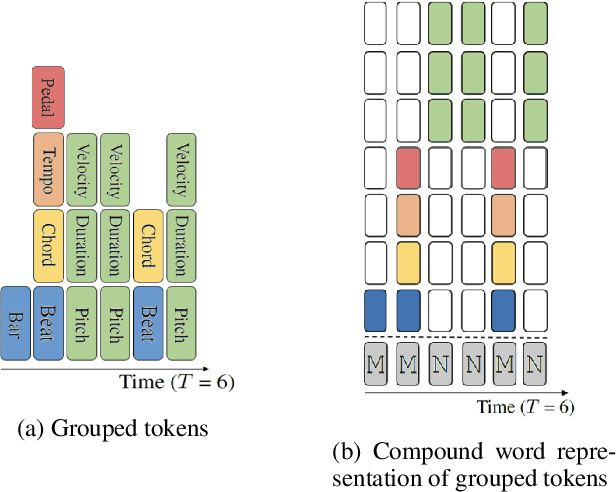
Recent years have witnessed a growing interest in research related to the detection of piano pedals from audio signals in the music information retrieval community. However, to our best knowledge, recent generative models for symbolic music have rarely taken piano pedals into account. In this work, we employ the transcription model proposed by Kong et al. to get pedal information from the audio recordings of piano performance in the AILabs1k7 dataset, and then modify the Compound Word Transformer proposed by Hsiao et al. to build a Transformer decoder that generates pedal-related tokens along with other musical tokens. While the work is done by using inferred sustain pedal information as training data, the result shows hope for further improvement and the importance of the involvement of sustain pedal in tasks of piano performance generations.
Beyond ImageNet Attack: Towards Crafting Adversarial Examples for Black-box Domains
Feb 10, 2022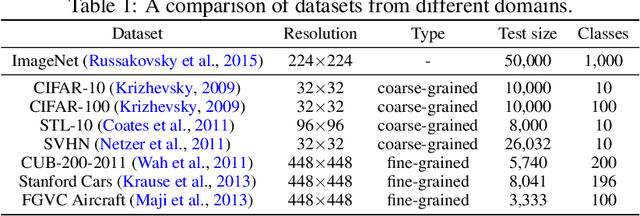
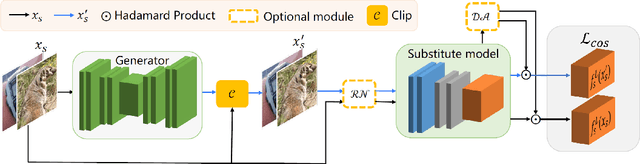
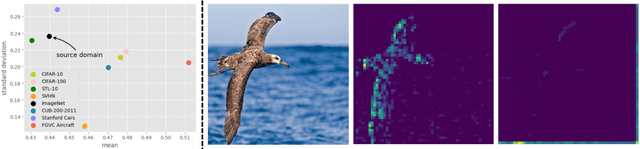
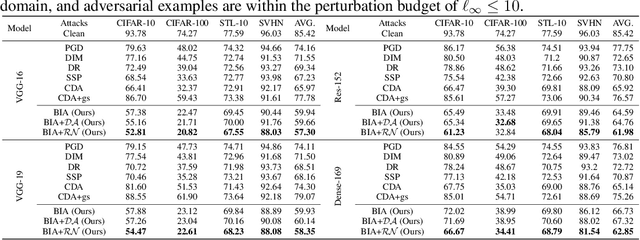
Adversarial examples have posed a severe threat to deep neural networks due to their transferable nature. Currently, various works have paid great efforts to enhance the cross-model transferability, which mostly assume the substitute model is trained in the same domain as the target model. However, in reality, the relevant information of the deployed model is unlikely to leak. Hence, it is vital to build a more practical black-box threat model to overcome this limitation and evaluate the vulnerability of deployed models. In this paper, with only the knowledge of the ImageNet domain, we propose a Beyond ImageNet Attack (BIA) to investigate the transferability towards black-box domains (unknown classification tasks). Specifically, we leverage a generative model to learn the adversarial function for disrupting low-level features of input images. Based on this framework, we further propose two variants to narrow the gap between the source and target domains from the data and model perspectives, respectively. Extensive experiments on coarse-grained and fine-grained domains demonstrate the effectiveness of our proposed methods. Notably, our methods outperform state-of-the-art approaches by up to 7.71\% (towards coarse-grained domains) and 25.91\% (towards fine-grained domains) on average. Our code is available at \url{https://github.com/qilong-zhang/Beyond-ImageNet-Attack}.