 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HC4: A New Suite of Test Collections for Ad Hoc CLIR
Jan 24, 2022
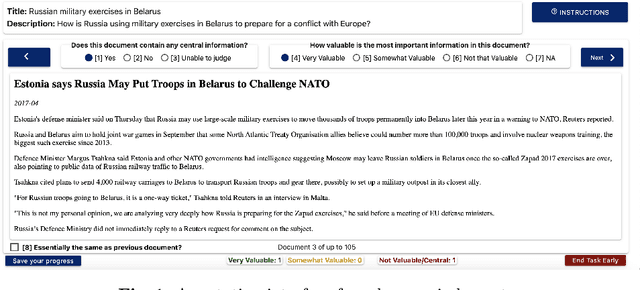
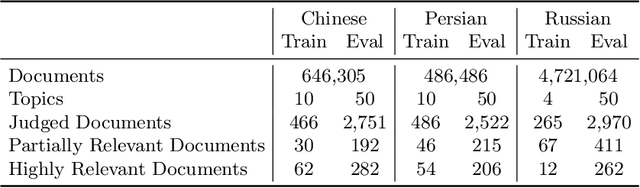


HC4 is a new suite of test collections for ad hoc Cross-Language Information Retrieval (CLIR), with Common Crawl News documents in Chinese, Persian, and Russian, topics in English and in the document languages, and graded relevance judgments. New test collections are needed because existing CLIR test collections built using pooling of traditional CLIR runs have systematic gaps in their relevance judgments when used to evaluate neural CLIR methods. The HC4 collections contain 60 topics and about half a million documents for each of Chinese and Persian, and 54 topics and five million documents for Russian. Active learning was used to determine which documents to annotate after being seeded using interactive search and judgment. Documents were judged on a three-grade relevance scale. This paper describes the design and construction of the new test collections and provides baseline results for demonstrating their utility for evaluating systems.
Ask "Who", Not "What": Bitcoin Volatility Forecasting with Twitter Data
Oct 27, 2021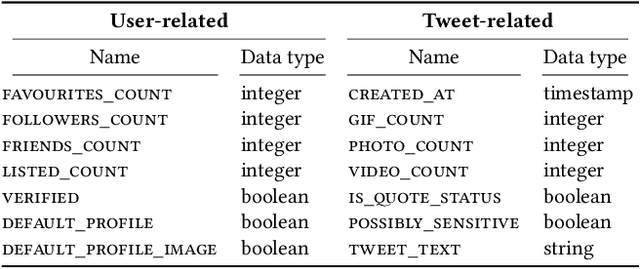
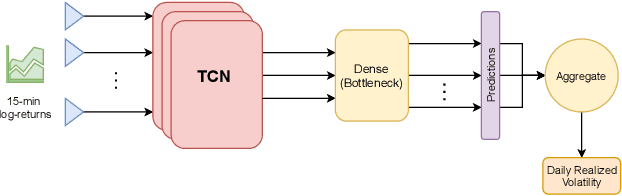
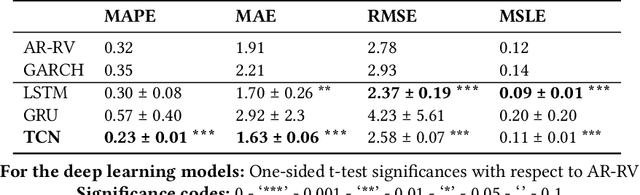
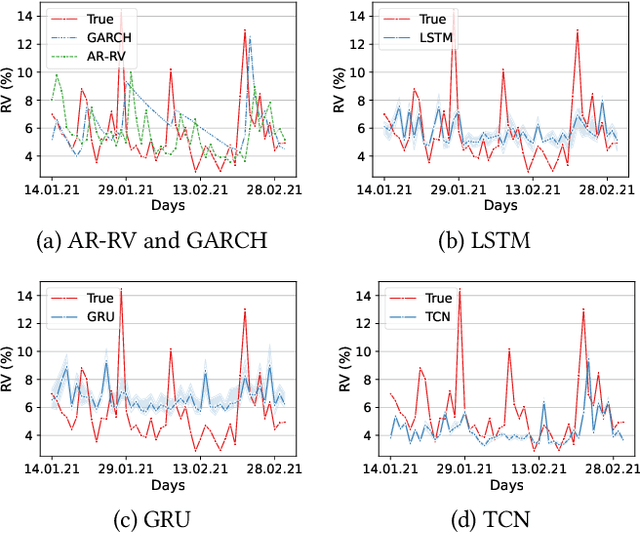
Understanding the variations in trading price (volatility), and its response to external information is a well-studied topic in finance. In this study, we focus on volatility predictions for a relatively new asset class of cryptocurrencies (in particular, Bitcoin) using deep learning representations of public social media data from Twitter. For the field work, we extracted semantic information and user interaction statistics from over 30 million Bitcoin-related tweets, in conjunction with 15-minute intraday price data over a 144-day horizon. Using this data, we built several deep learning architectures that utilized a combination of the gathered information. For all architectures, we conducted ablation studies to assess the influence of each component and feature set in our model. We found statistical evidences for the hypotheses that: (i) temporal convolutional networks perform significantly better than both autoregressive and other deep learning-based models in the literature, and (ii) the tweet author meta-information, even detached from the tweet itself, is a better predictor than the semantic content and tweet volume statistics.
Total variation-based phase retrieval for diffraction tomography
Jan 27, 2022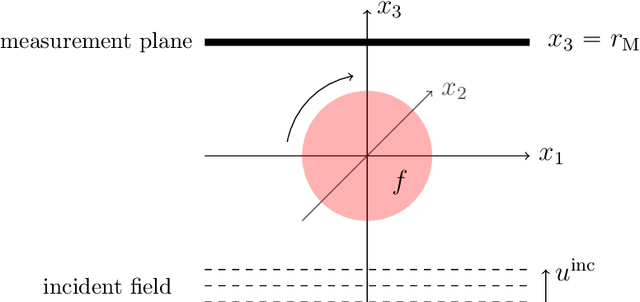

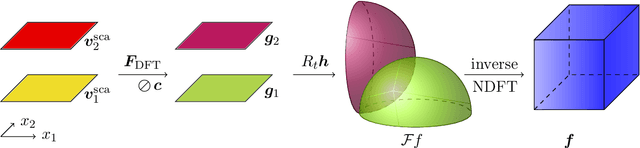

In optical diffraction tomography (ODT), the three-dimensional scattering potential of a microscopic object rotating around its center is recovered by a series of illuminations with coherent light. Reconstruction algorithms such as the filtered backpropagation require knowledge of the complex-valued wave at the measurement plane, whereas often only intensities, i.e., phaseless measurements, are available in practice. We propose a new reconstruction approach for ODT with unknown phase information based on three key ingredients. First, the light propagation is modeled using Born's approximation enabling us to use the Fourier diffraction theorem. Second, we stabilize the inversion of the non-uniform discrete Fourier transform via total variation regularization utilizing a primal-dual iteration, which also yields a novel numerical inversion formula for ODT with known phase. The third ingredient is a hybrid input-output scheme. We achieved convincing numerical results, which indicate that ODT with phaseless data is possible. The so-obtained 2D and 3D reconstructions are even comparable to the ones with known phase.
Sparse Structure Learning via Graph Neural Networks for Inductive Document Classification
Dec 13, 2021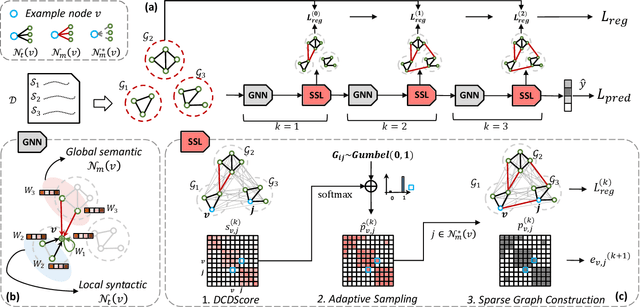

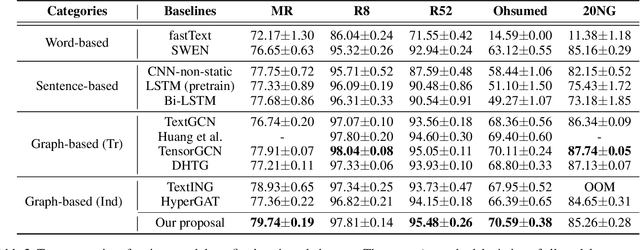
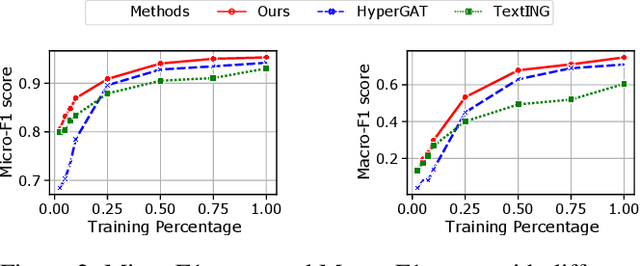
Recently, graph neural networks (GNNs) have been widely used for document classification. However, most existing methods are based on static word co-occurrence graphs without sentence-level information, which poses three challenges:(1) word ambiguity, (2) word synonymity, and (3) dynamic contextual dependency. To address these challenges, we propose a novel GNN-based sparse structure learning model for inductive document classification. Specifically, a document-level graph is initially generated by a disjoint union of sentence-level word co-occurrence graphs. Our model collects a set of trainable edges connecting disjoint words between sentences and employs structure learning to sparsely select edges with dynamic contextual dependencies. Graphs with sparse structures can jointly exploit local and global contextual information in documents through GNNs. For inductive learning, the refined document graph is further fed into a general readout function for graph-level classification and optimization in an end-to-end manner. Extensive experiments on several real-world datasets demonstrate that the proposed model outperforms most state-of-the-art results, and reveal the necessity to learn sparse structures for each document.
ConvMixer: Feature Interactive Convolution with Curriculum Learning for Small Footprint and Noisy Far-field Keyword Spotting
Jan 15, 2022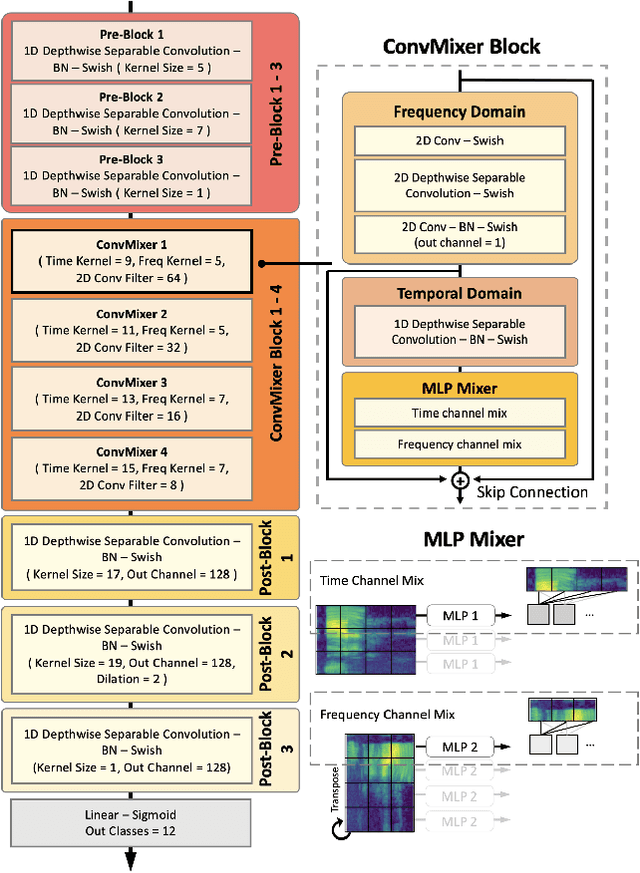
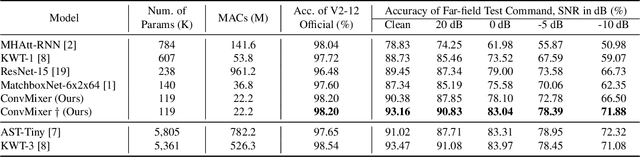
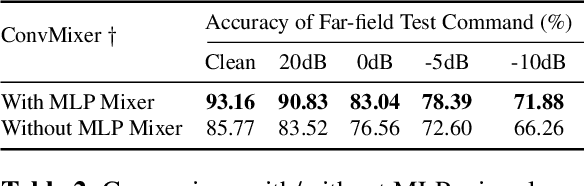
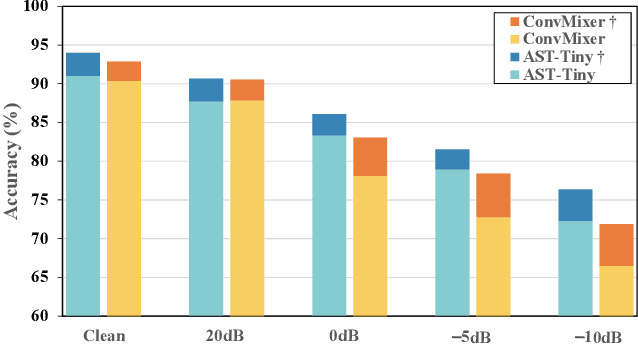
Building efficient architecture in neural speech processing is paramount to success in keyword spotting deployment. However, it is very challenging for lightweight models to achieve noise robustness with concise neural operations. In a real-world application, the user environment is typically noisy and may also contain reverberations. We proposed a novel feature interactive convolutional model with merely 100K parameters to tackle this under the noisy far-field condition. The interactive unit is proposed in place of the attention module that promotes the flow of information with more efficient computations. Moreover, curriculum-based multi-condition training is adopted to attain better noise robustness. Our model achieves 98.2% top-1 accuracy on Google Speech Command V2-12 and is competitive against large transformer models under the designed noise condition.
Exploring and Distilling Cross-Modal Information for Image Captioning
Mar 15, 2020
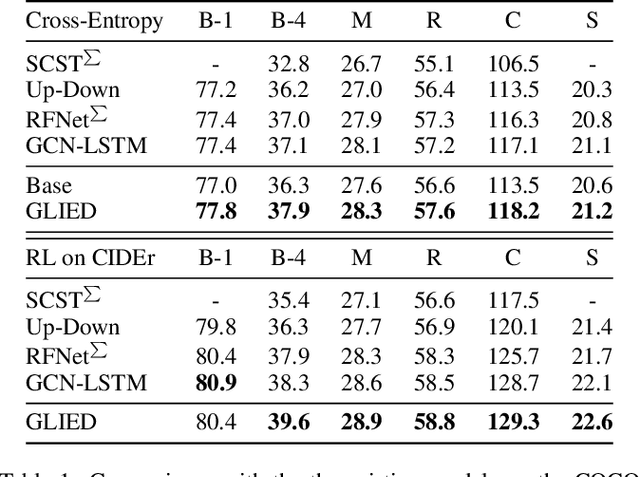
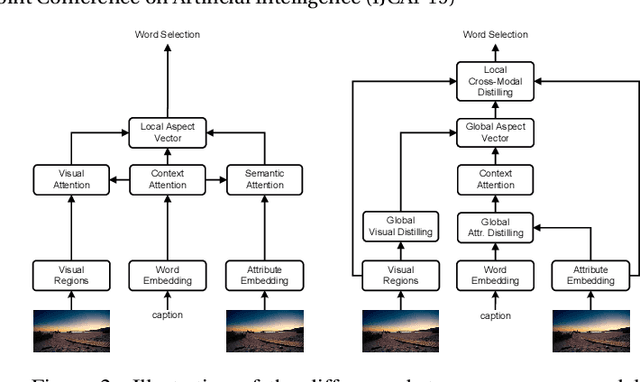
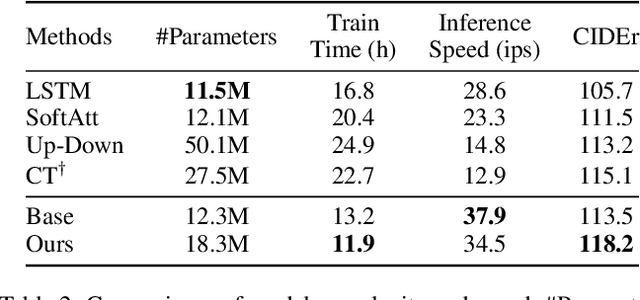
Recently, attention-based encoder-decoder models have been used extensively in image captioning. Yet there is still great difficulty for the current methods to achieve deep image understanding. In this work, we argue that such understanding requires visual attention to correlated image regions and semantic attention to coherent attributes of interest. Based on the Transformer, to perform effective attention, we explore image captioning from a cross-modal perspective and propose the Global-and-Local Information Exploring-and-Distilling approach that explores and distills the source information in vision and language. It globally provides the aspect vector, a spatial and relational representation of images based on caption contexts, through the extraction of salient region groupings and attribute collocations, and locally extracts the fine-grained regions and attributes in reference to the aspect vector for word selection. Our Transformer-based model achieves a CIDEr score of 129.3 in offline COCO evaluation on the COCO testing set with remarkable efficiency in terms of accuracy, speed, and parameter budget.
How and what to learn:The modes of machine learning
Feb 28, 2022
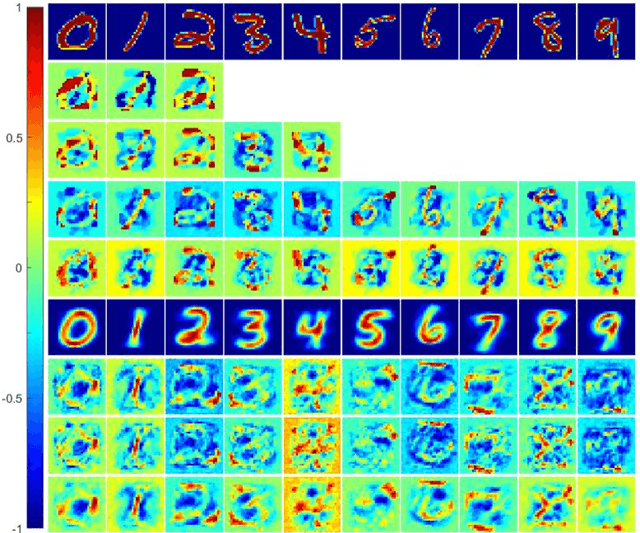
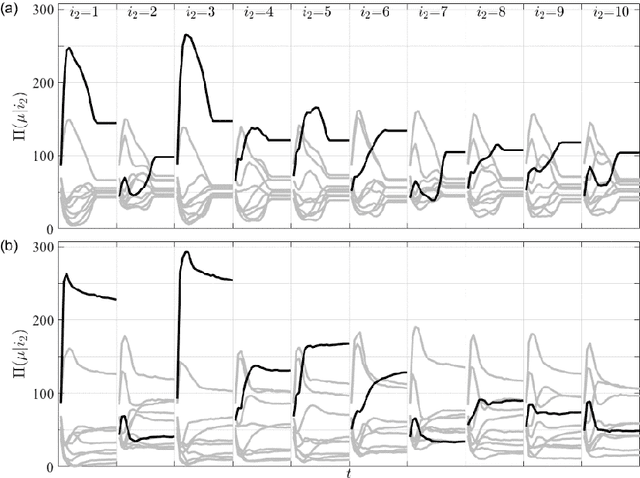
We proposal a new approach, namely the weight pathway analysis (WPA), to study the mechanism of multilayer neural networks. The weight pathways linking neurons longitudinally from input neurons to output neurons are considered as the basic units of a neural network. We decompose a neural network into a series of subnetworks of weight pathways, and establish characteristic maps for these subnetworks. The parameters of a characteristic map can be visualized, providing a longitudinal perspective of the network and making the neural network explainable. Using WPA, we discover that a neural network stores and utilizes information in a "holographic" way, that is, the network encodes all training samples in a coherent structure. An input vector interacts with this "holographic" structure to enhance or suppress each subnetwork which working together to produce the correct activities in the output neurons to recognize the input sample. Furthermore, with WPA, we reveal fundamental learning modes of a neural network: the linear learning mode and the nonlinear learning mode. The former extracts linearly separable features while the latter extracts linearly inseparable features. It is found that hidden-layer neurons self-organize into different classes in the later stages of the learning process. It is further discovered that the key strategy to improve the performance of a neural network is to control the ratio of the two learning modes to match that of the linear and the nonlinear features, and that increasing the width or the depth of a neural network helps this ratio controlling process. This provides theoretical ground for the practice of optimizing a neural network via increasing its width or its depth. The knowledge gained with WPA enables us to understand the fundamental questions such as what to learn, how to learn, and how can learn well.
Positional Encoding Augmented GAN for the Assessment of Wind Flow for Pedestrian Comfort in Urban Areas
Jan 04, 2022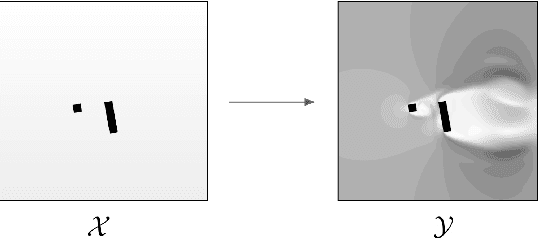
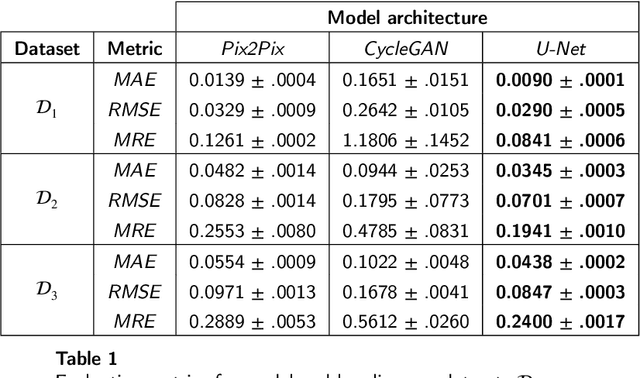
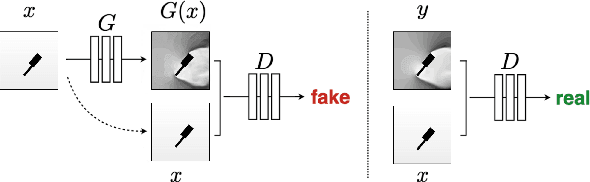

Approximating wind flows using computational fluid dynamics (CFD) methods can be time-consuming. Creating a tool for interactively designing prototypes while observing the wind flow change requires simpler models to simulate faster. Instead of running numerical approximations resulting in detailed calculations, data-driven methods and deep learning might be able to give similar results in a fraction of the time. This work rephrases the problem from computing 3D flow fields using CFD to a 2D image-to-image translation-based problem on the building footprints to predict the flow field at pedestrian height level. We investigate the use of generative adversarial networks (GAN), such as Pix2Pix [1] and CycleGAN [2] representing state-of-the-art for image-to-image translation task in various domains as well as U-Net autoencoder [3]. The models can learn the underlying distribution of a dataset in a data-driven manner, which we argue can help the model learn the underlying Reynolds-averaged Navier-Stokes (RANS) equations from CFD. We experiment on novel simulated datasets on various three-dimensional bluff-shaped buildings with and without height information. Moreover, we present an extensive qualitative and quantitative evaluation of the generated images for a selection of models and compare their performance with the simulations delivered by CFD. We then show that adding positional data to the input can produce more accurate results by proposing a general framework for injecting such information on the different architectures. Furthermore, we show that the models performances improve by applying attention mechanisms and spectral normalization to facilitate stable training.
SleepPPG-Net: a deep learning algorithm for robust sleep staging from continuous photoplethysmography
Feb 18, 2022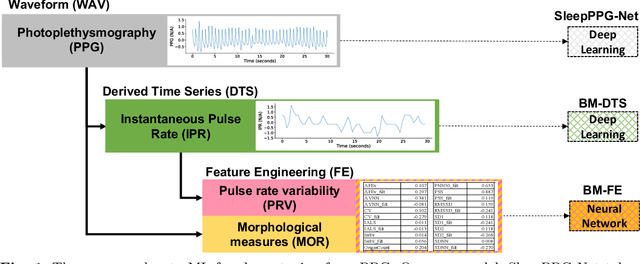
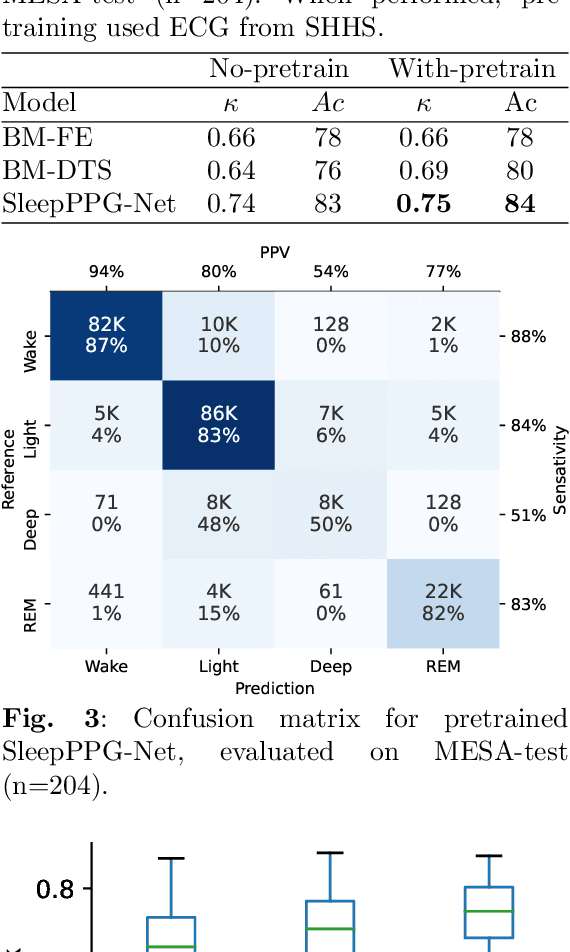
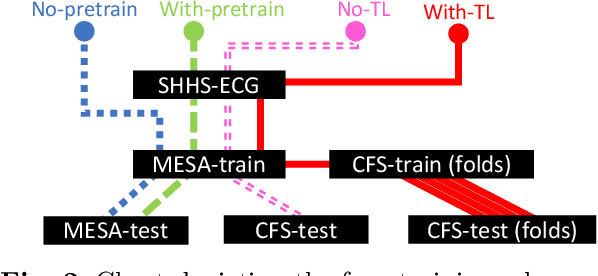
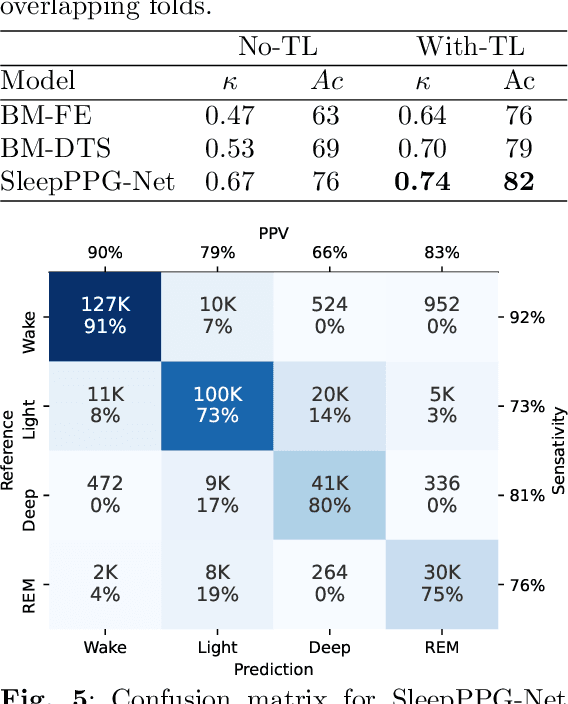
Introduction: Sleep staging is an essential component in the diagnosis of sleep disorders and management of sleep health. It is traditionally measured in a clinical setting and requires a labor-intensive labeling process. We hypothesize that it is possible to perform robust 4-class sleep staging using the raw photoplethysmography (PPG) time series and modern advances in deep learning (DL). Methods: We used two publicly available sleep databases that included raw PPG recordings, totalling 2,374 patients and 23,055 hours. We developed SleepPPG-Net, a DL model for 4-class sleep staging from the raw PPG time series. SleepPPG-Net was trained end-to-end and consists of a residual convolutional network for automatic feature extraction and a temporal convolutional network to capture long-range contextual information. We benchmarked the performance of SleepPPG-Net against models based on the best-reported state-of-the-art (SOTA) algorithms. Results: When benchmarked on a held-out test set, SleepPPG-Net obtained a median Cohen's Kappa ($\kappa$) score of 0.75 against 0.69 for the best SOTA approach. SleepPPG-Net showed good generalization performance to an external database, obtaining a $\kappa$ score of 0.74 after transfer learning. Perspective: Overall, SleepPPG-Net provides new SOTA performance. In addition, performance is high enough to open the path to the development of wearables that meet the requirements for usage in clinical applications such as the diagnosis and monitoring of obstructive sleep apnea.
Datamodels: Predicting Predictions from Training Data
Feb 01, 2022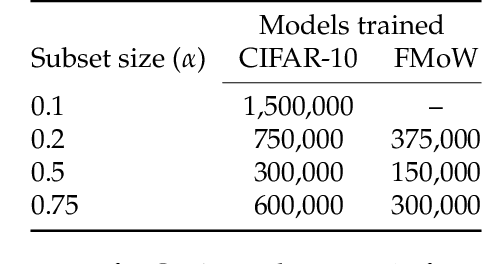


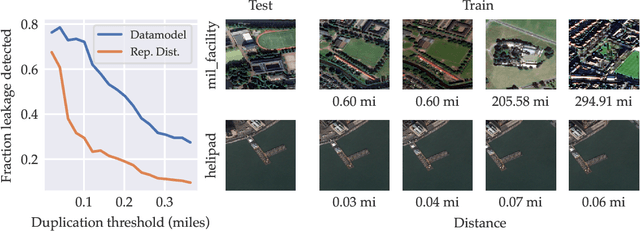
We present a conceptual framework, datamodeling, for analyzing the behavior of a model class in terms of the training data. For any fixed "target" example $x$, training set $S$, and learning algorithm, a datamodel is a parameterized function $2^S \to \mathbb{R}$ that for any subset of $S' \subset S$ -- using only information about which examples of $S$ are contained in $S'$ -- predicts the outcome of training a model on $S'$ and evaluating on $x$. Despite the potential complexity of the underlying process being approximated (e.g., end-to-end training and evaluation of deep neural networks), we show that even simple linear datamodels can successfully predict model outputs. We then demonstrate that datamodels give rise to a variety of applications, such as: accurately predicting the effect of dataset counterfactuals; identifying brittle predictions; finding semantically similar examples; quantifying train-test leakage; and embedding data into a well-behaved and feature-rich representation space. Data for this paper (including pre-computed datamodels as well as raw predictions from four million trained deep neural networks) is available at https://github.com/MadryLab/datamodels-data .