 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spectro Temporal EEG Biomarkers For Binary Emotion Classification
Feb 02, 2022
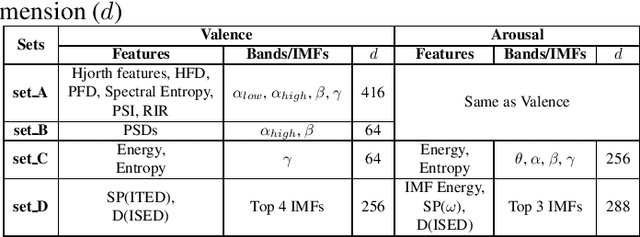
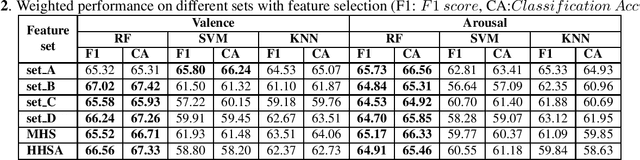
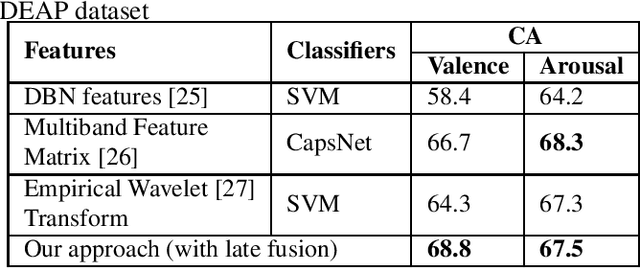
Electroencephalogram (EEG) is one of the most reliable physiological signal for emotion detection. Being non-stationary in nature, EEGs are better analysed by spectro temporal representations. Standard features like Discrete Wavelet Transformation (DWT) can represent temporal changes in spectral dynamics of an EEG, but is insufficient to extract information other way around, i.e. spectral changes in temporal dynamics. On the other hand, Empirical mode decomposition (EMD) based features can be useful to bridge the above mentioned gap. Towards this direction, we extract two novel features on top of EMD, namely, (a) marginal hilbert spectrum (MHS) and (b) Holo-Hilbert spectral analysis (HHSA) based on EMD, to better represent emotions in 2D arousal-valence (A-V) space. The usefulness of these features for EEG emotion classification is investigated through extensive experiments using state-of-the-art classifiers. In addition, experiments conducted on DEAP dataset for binary emotion classification in both A-V space, reveal the efficacy of the proposed features over the standard set of temporal and spectral features.
Tracking and Long-Term Identification Using Non-Visual Markers
Dec 13, 2021
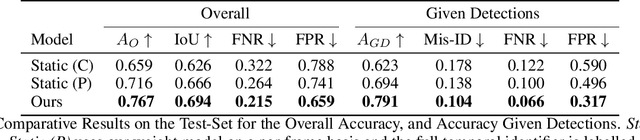
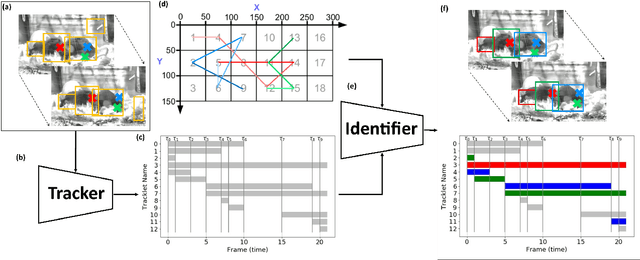

Our objective is to track and identify mice in a cluttered home-cage environment, as a precursor to automated behaviour recognition for biological research. This is a very challenging problem due to (i) the lack of distinguishing visual features for each mouse, and (ii) the close confines of the scene with constant occlusion, making standard visual tracking approaches unusable. However, a coarse estimate of each mouse's location is available from a unique RFID implant, so there is the potential to optimally combine information from (weak) tracking with coarse information on identity. To achieve our objective, we make the following key contributions: (a) the formulation of the identification problem as an assignment problem (solved using Integer Linear Programming), and (b) a novel probabilistic model of the affinity between tracklets and RFID data. The latter is a crucial part of the model, as it provides a principled probabilistic treatment of object detections given coarse localisation. Our approach achieves 77% accuracy on this identification problem, and is able to reject spurious detections when the animals are hidden.
Design Theory to improve health evidence retrieval
Nov 10, 2021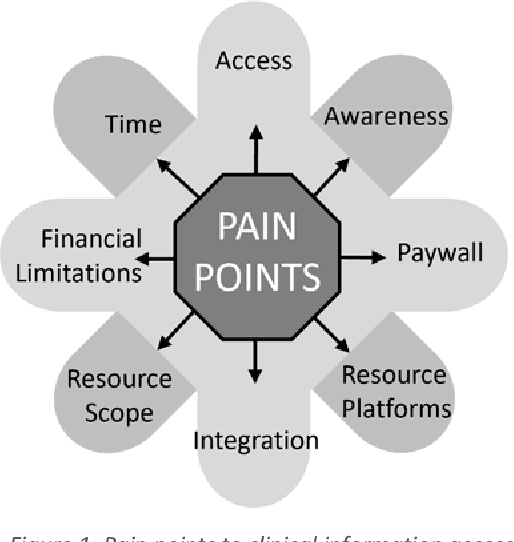
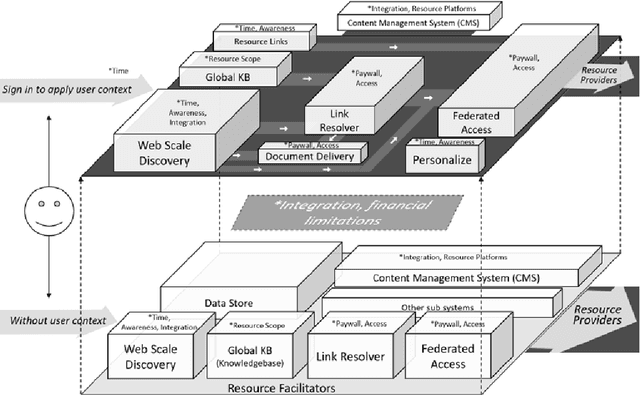
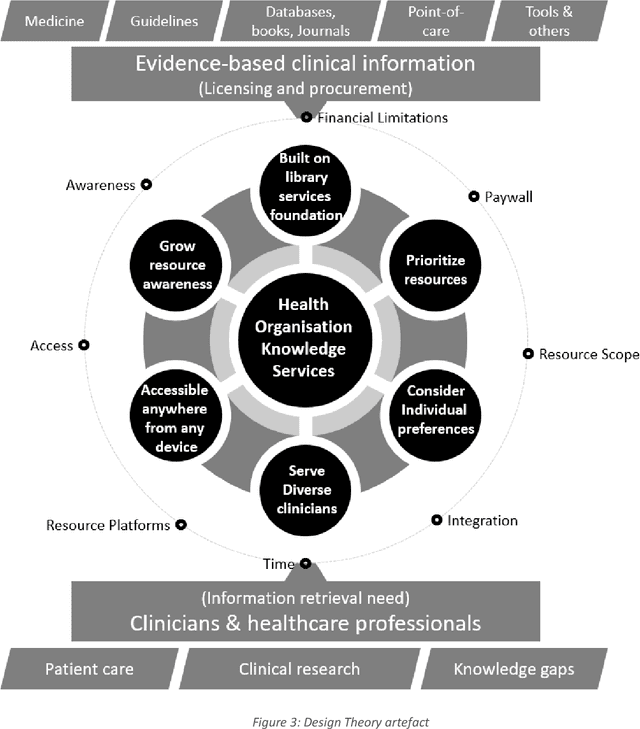
Objective: Our study objective is to design a feasible technology solution for health organizations to remove barriers to evidence-based clinical information retrieval, and improve Evidence-Based Practice. Methods: Literature from 2010 to 2020 was reviewed to define problems in evidence-based clinical information retrieval with recommendations from literature used to define solution objectives. Design Science Research is used to complete three projects in a research stream using cloud services such as Web-Scale Discovery, Content Management System, Federated Access, Global Knowledgebase, and Document Delivery. Design thinking, systems thinking, and user-oriented theory of information need are adopted to construct a design theory. Results: The research stream produced three novel and innovative artefacts: a contextual model, a unified architecture, and a context-aware unified architecture which we evaluate as part of academic reviews, scholarly publications, and conference proceedings in various research stream stages. A fourth artefact or design theory is presented to generalize results as mature knowledge.
One-shot Scene Graph Generation
Feb 26, 2022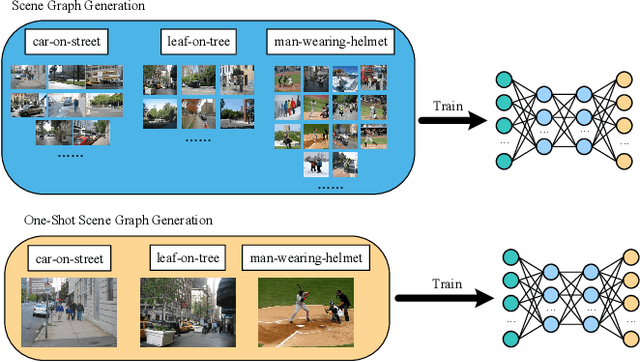
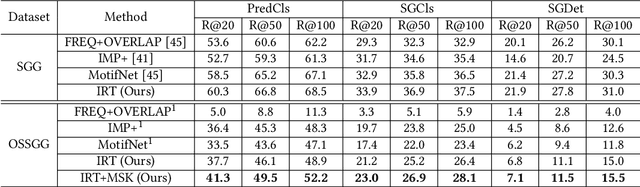
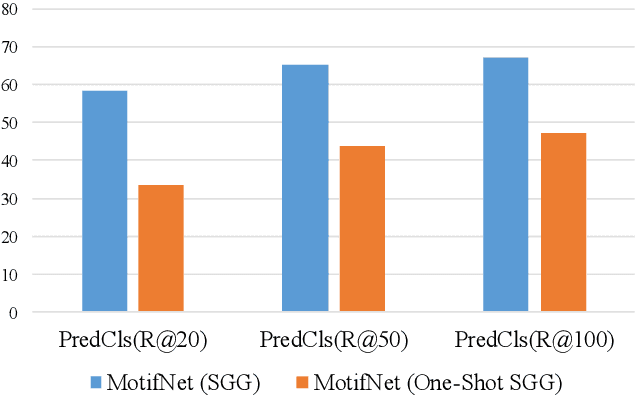
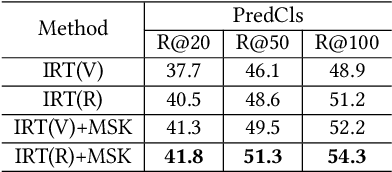
As a structured representation of the image content, the visual scene graph (visual relationship) acts as a bridge between computer vision and natural language processing. Existing models on the scene graph generation task notoriously require tens or hundreds of labeled samples. By contrast, human beings can learn visual relationships from a few or even one example. Inspired by this, we design a task named One-Shot Scene Graph Generation, where each relationship triplet (e.g., "dog-has-head") comes from only one labeled example. The key insight is that rather than learning from scratch, one can utilize rich prior knowledge. In this paper, we propose Multiple Structured Knowledge (Relational Knowledge and Commonsense Knowledge) for the one-shot scene graph generation task. Specifically, the Relational Knowledge represents the prior knowledge of relationships between entities extracted from the visual content, e.g., the visual relationships "standing in", "sitting in", and "lying in" may exist between "dog" and "yard", while the Commonsense Knowledge encodes "sense-making" knowledge like "dog can guard yard". By organizing these two kinds of knowledge in a graph structure, Graph Convolution Networks (GCNs) are used to extract knowledge-embedded semantic features of the entities. Besides, instead of extracting isolated visual features from each entity generated by Faster R-CNN, we utilize an Instance Relation Transformer encoder to fully explore their context information. Based on a constructed one-shot dataset, the experimental results show that our method significantly outperforms existing state-of-the-art methods by a large margin. Ablation studies also verify the effectiveness of the Instance Relation Transformer encoder and the Multiple Structured Knowledge.
Incentive Compatible Pareto Alignment for Multi-Source Large Graphs
Dec 06, 2021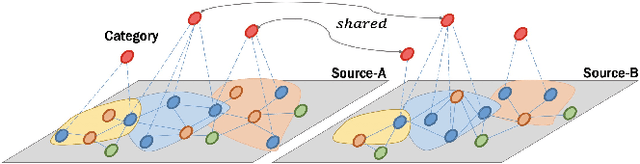
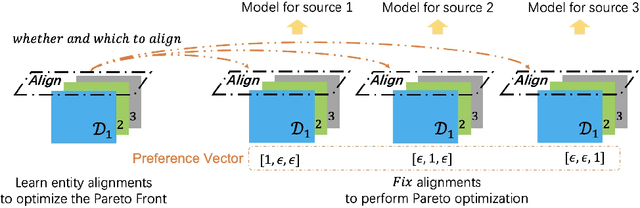
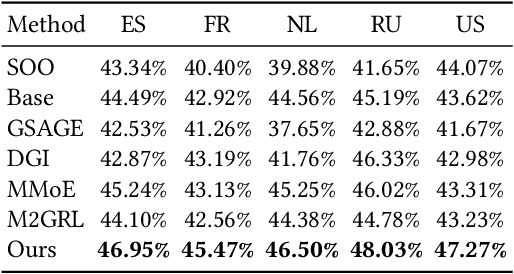
In this paper, we focus on learning effective entity matching models over multi-source large-scale data. For real applications, we relax typical assumptions that data distributions/spaces, or entity identities are shared between sources, and propose a Relaxed Multi-source Large-scale Entity-matching (RMLE) problem. Challenges of the problem include 1) how to align large-scale entities between sources to share information and 2) how to mitigate negative transfer from joint learning multi-source data. What's worse, one practical issue is the entanglement between both challenges. Specifically, incorrect alignments may increase negative transfer; while mitigating negative transfer for one source may result in poorly learned representations for other sources and then decrease alignment accuracy. To handle the entangled challenges, we point out that the key is to optimize information sharing first based on Pareto front optimization, by showing that information sharing significantly influences the Pareto front which depicts lower bounds of negative transfer. Consequently, we proposed an Incentive Compatible Pareto Alignment (ICPA) method to first optimize cross-source alignments based on Pareto front optimization, then mitigate negative transfer constrained on the optimized alignments. This mechanism renders each source can learn based on its true preference without worrying about deteriorating representations of other sources. Specifically, the Pareto front optimization encourages minimizing lower bounds of negative transfer, which optimizes whether and which to align. Comprehensive empirical evaluation results on four large-scale datasets are provided to demonstrate the effectiveness and superiority of ICPA. Online A/B test results at a search advertising platform also demonstrate the effectiveness of ICPA in production environments.
Variational Neural Cellular Automata
Feb 02, 2022
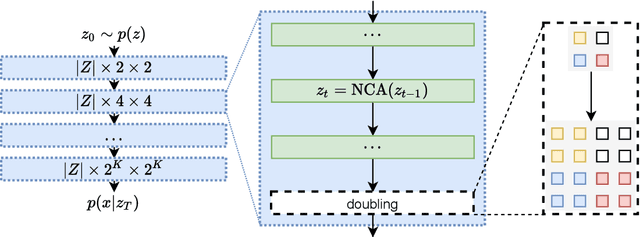


In nature, the process of cellular growth and differentiation has lead to an amazing diversity of organisms -- algae, starfish, giant sequoia, tardigrades, and orcas are all created by the same generative process. Inspired by the incredible diversity of this biological generative process, we propose a generative model, the Variational Neural Cellular Automata (VNCA), which is loosely inspired by the biological processes of cellular growth and differentiation. Unlike previous related works, the VNCA is a proper probabilistic generative model, and we evaluate it according to best practices. We find that the VNCA learns to reconstruct samples well and that despite its relatively few parameters and simple local-only communication, the VNCA can learn to generate a large variety of output from information encoded in a common vector format. While there is a significant gap to the current state-of-the-art in terms of generative modeling performance, we show that the VNCA can learn a purely self-organizing generative process of data. Additionally, we show that the VNCA can learn a distribution of stable attractors that can recover from significant damage.
Joint Global and Local Hierarchical Priors for Learned Image Compression
Dec 08, 2021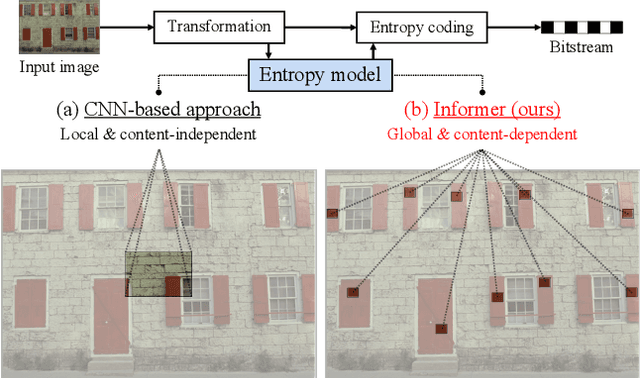


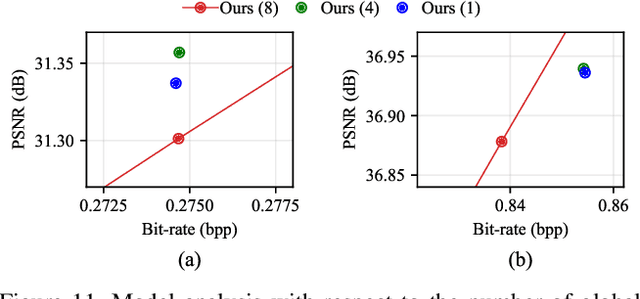
Recently, learned image compression methods have shown superior performance compared to the traditional hand-crafted image codecs including BPG. One of the fundamental research directions in learned image compression is to develop entropy models that accurately estimate the probability distribution of the quantized latent representation. Like other vision tasks, most of the recent learned entropy models are based on convolutional neural networks (CNNs). However, CNNs have a limitation in modeling dependencies between distant regions due to their nature of local connectivity, which can be a significant bottleneck in image compression where reducing spatial redundancy is a key point. To address this issue, we propose a novel entropy model called Information Transformer (Informer) that exploits both local and global information in a content-dependent manner using an attention mechanism. Our experiments demonstrate that Informer improves rate-distortion performance over the state-of-the-art methods on the Kodak and Tecnick datasets without the quadratic computational complexity problem.
Adaptive Methods for Aggregated Domain Generalization
Dec 23, 2021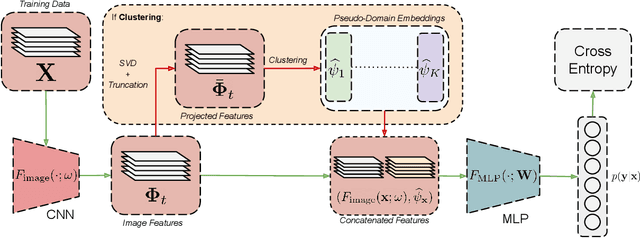
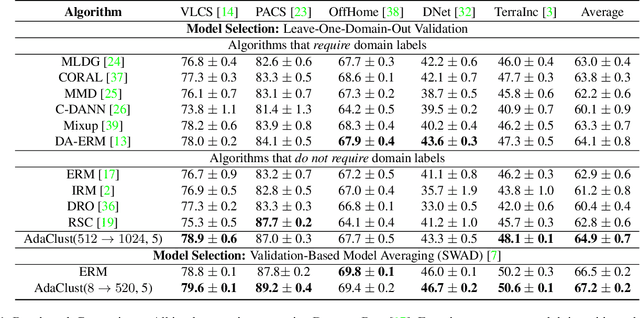
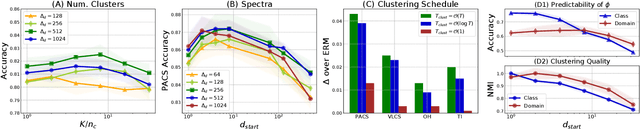
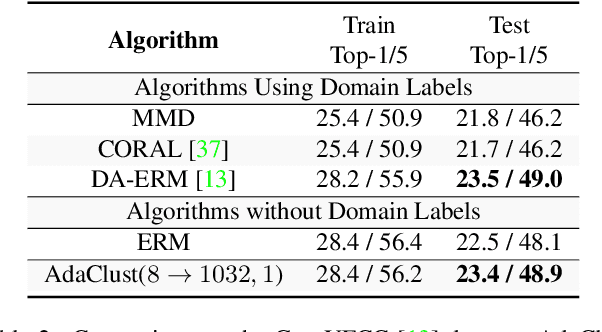
Domain generalization involves learning a classifier from a heterogeneous collection of training sources such that it generalizes to data drawn from similar unknown target domains, with applications in large-scale learning and personalized inference. In many settings, privacy concerns prohibit obtaining domain labels for the training data samples, and instead only have an aggregated collection of training points. Existing approaches that utilize domain labels to create domain-invariant feature representations are inapplicable in this setting, requiring alternative approaches to learn generalizable classifiers. In this paper, we propose a domain-adaptive approach to this problem, which operates in two steps: (a) we cluster training data within a carefully chosen feature space to create pseudo-domains, and (b) using these pseudo-domains we learn a domain-adaptive classifier that makes predictions using information about both the input and the pseudo-domain it belongs to. Our approach achieves state-of-the-art performance on a variety of domain generalization benchmarks without using domain labels whatsoever. Furthermore, we provide novel theoretical guarantees on domain generalization using cluster information. Our approach is amenable to ensemble-based methods and provides substantial gains even on large-scale benchmark datasets. The code can be found at: https://github.com/xavierohan/AdaClust_DomainBed
Fighting Fire with Fire: Contrastive Debiasing without Bias-free Data via Generative Bias-transformation
Dec 02, 2021
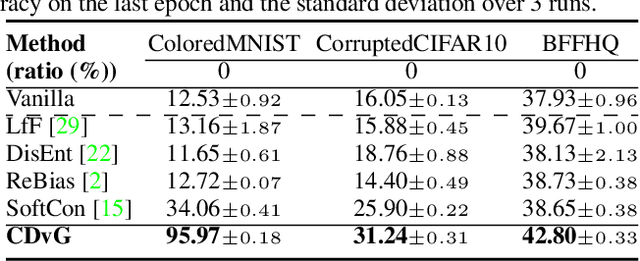

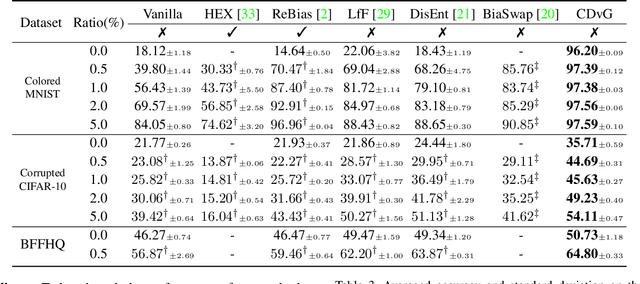
Despite their remarkable ability to generalize with over-capacity networks, deep neural networks often learn to abuse spurious biases in the data instead of using the actual task-related information. Since such shortcuts are only effective within the collected dataset, the resulting biased model underperforms on real-world inputs, or cause unintended social repercussions such as gender discrimination. To counteract the influence of bias, existing methods either exploit auxiliary information which is rarely obtainable in practice, or sift for bias-free samples in the training data, hoping for the sufficient existence of clean samples. However, such presumptions about the data are not always guaranteed. In this paper, we propose Contrastive Debiasing via Generative Bias-transformation~(CDvG) which is capable of operating in more general environments where existing methods break down due to unmet presumptions such as insufficient bias-free samples. Motivated by our observation that not only discriminative models, as previously known, but also generative models tend to focus on the bias when possible, CDvG uses a translation model to transform the bias in the sample to another mode of bias while preserving task-relevant information. Through contrastive learning, we set transformed biased views against another, learning bias-invariant representations. Experimental results on synthetic and real-world datasets demonstrate that our framework outperforms the current state-of-the-arts, and effectively prevents the models from being biased even when bias-free samples are extremely scarce.
A Dual-Perception Graph Neural Network with Multi-hop Graph Generator
Oct 22, 2021
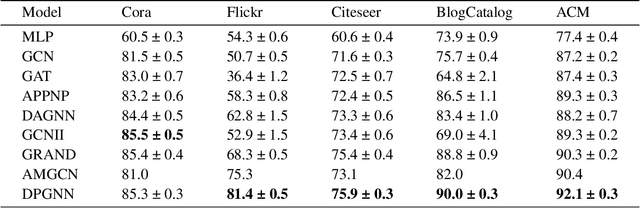
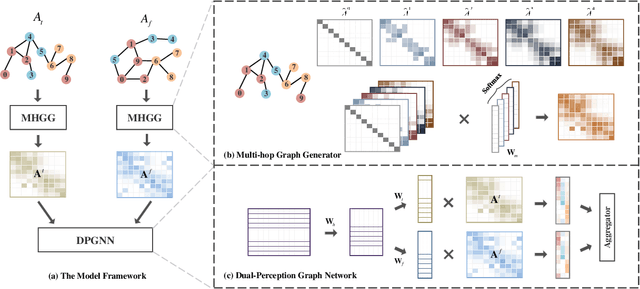
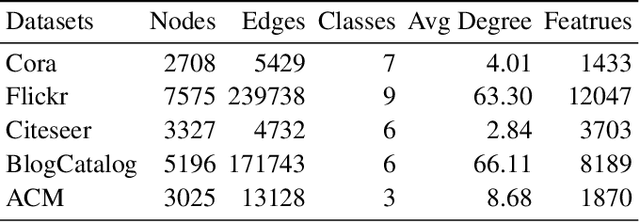
Graph neural networks (GNNs) have drawn increasing attention in recent years and achieved remarkable performance in many graph-based tasks, especially in semi-supervised learning on graphs. However, most existing GNNs excessively rely on topological structures and aggregate multi-hop neighborhood information by simply stacking network layers, which may introduce superfluous noise information, limit the expressive power of GNNs and lead to the over-smoothing problem ultimately. In light of this, we propose a novel Dual-Perception Graph Neural Network (DPGNN) to address these issues. In DPGNN, we utilize node features to construct a feature graph, and perform node representations learning based on the original topology graph and the constructed feature graph simultaneously, which conduce to capture the structural neighborhood information and the feature-related information. Furthermore, we design a Multi-Hop Graph Generator (MHGG), which applies a node-to-hop attention mechanism to aggregate node-specific multi-hop neighborhood information adaptively. Finally, we apply self-ensembling to form a consistent prediction for unlabeled node representations. Experimental results on five datasets with different topological structures demonstrate that our proposed DPGNN outperforms all the latest state-of-the-art models on all datasets, which proves the superiority and versatility of our model. The source code of our model is available at https://github.com.