 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information-Theoretic Generalization Bounds for Meta-Learning and Applications
May 09, 2020
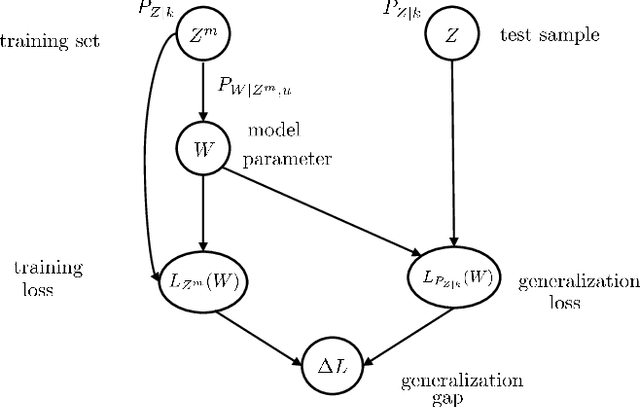
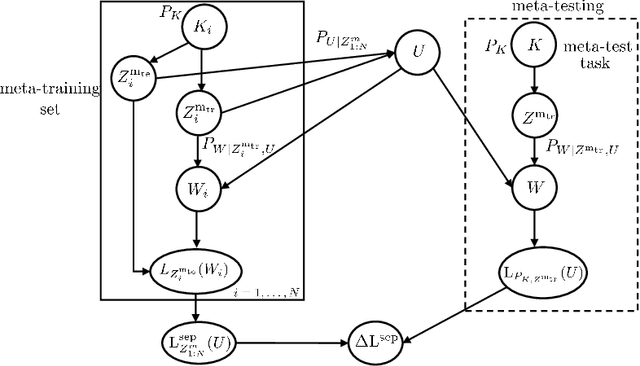
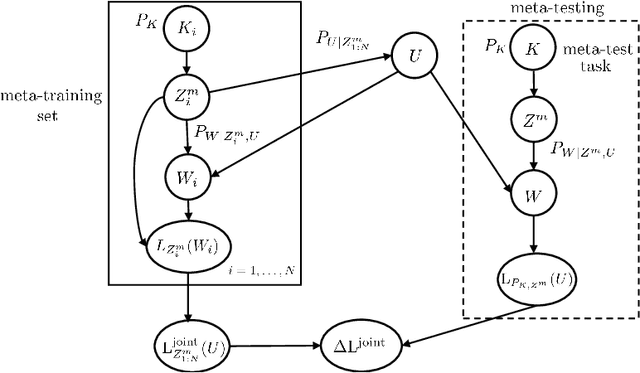
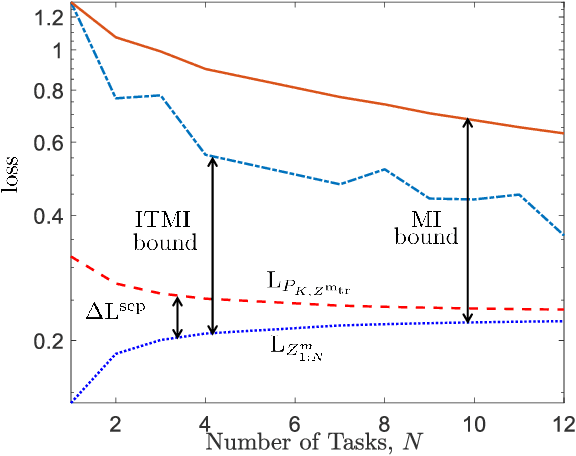
Meta-learning, or "learning to learn", refers to techniques that infer an inductive bias from data corresponding to multiple related tasks with the goal of improving the sample efficiency for new, previously unobserved, tasks. A key performance measure for meta-learning is the meta-generalization gap, that is, the difference between the average loss measured on the meta-training data and on a new, randomly selected task. This paper presents novel information-theoretic upper bounds on the meta-generalization gap. Two broad classes of meta-learning algorithms are considered that uses either separate within-task training and test sets, like MAML, or joint within-task training and test sets, like Reptile. Extending the existing work for conventional learning, an upper bound on the meta-generalization gap is derived for the former class that depends on the mutual information (MI) between the output of the meta-learning algorithm and its input meta-training data. For the latter, the derived bound includes an additional MI between the output of the per-task learning procedure and corresponding data set to capture within-task uncertainty. Tighter bounds are then developed for the two classes via novel Individual Task MI (ITMI) bounds. Applications of the derived bounds are finally discussed, including a broad class of noisy iterative algorithms for meta-learning.
Multiview Transformers for Video Recognition
Jan 20, 2022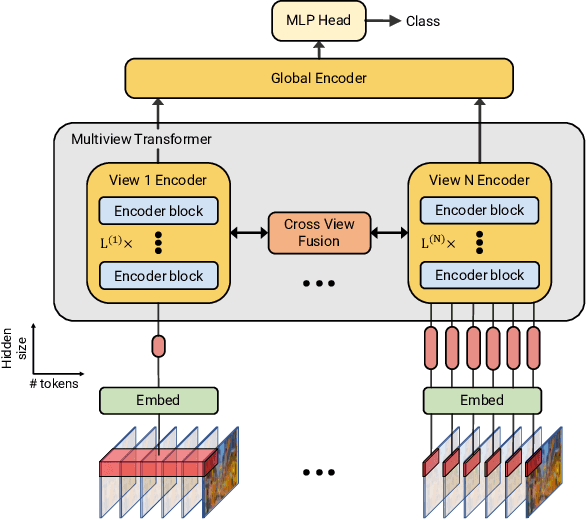
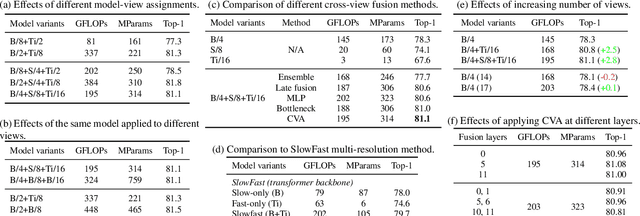
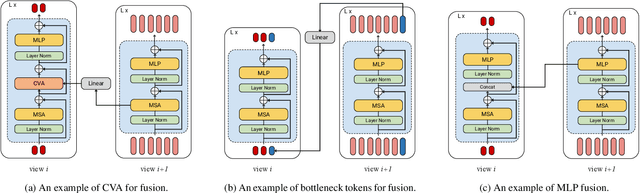
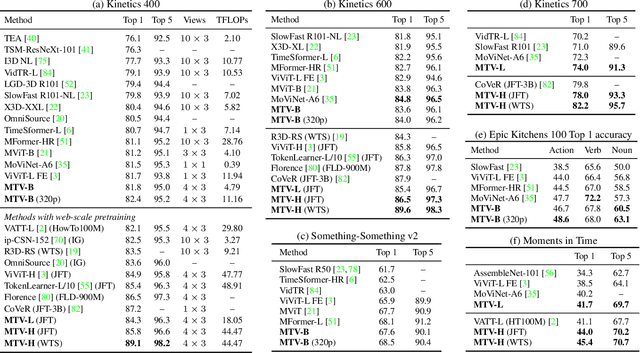
Video understanding requires reasoning at multiple spatiotemporal resolutions -- from short fine-grained motions to events taking place over longer durations. Although transformer architectures have recently advanced the state-of-the-art, they have not explicitly modelled different spatiotemporal resolutions. To this end, we present Multiview Transformers for Video Recognition (MTV). Our model consists of separate encoders to represent different views of the input video with lateral connections to fuse information across views. We present thorough ablation studies of our model and show that MTV consistently performs better than single-view counterparts in terms of accuracy and computational cost across a range of model sizes. Furthermore, we achieve state-of-the-art results on five standard datasets, and improve even further with large-scale pretraining. We will release code and pretrained checkpoints.
Policy Optimization for Stochastic Shortest Path
Feb 07, 2022Policy optimization is among the most popular and successful reinforcement learning algorithms, and there is increasing interest in understanding its theoretical guarantees. In this work, we initiate the study of policy optimization for the stochastic shortest path (SSP) problem, a goal-oriented reinforcement learning model that strictly generalizes the finite-horizon model and better captures many applications. We consider a wide range of settings, including stochastic and adversarial environments under full information or bandit feedback, and propose a policy optimization algorithm for each setting that makes use of novel correction terms and/or variants of dilated bonuses (Luo et al., 2021). For most settings, our algorithm is shown to achieve a near-optimal regret bound. One key technical contribution of this work is a new approximation scheme to tackle SSP problems that we call \textit{stacked discounted approximation} and use in all our proposed algorithms. Unlike the finite-horizon approximation that is heavily used in recent SSP algorithms, our new approximation enables us to learn a near-stationary policy with only logarithmic changes during an episode and could lead to an exponential improvement in space complexity.
LaTr: Layout-Aware Transformer for Scene-Text VQA
Dec 24, 2021
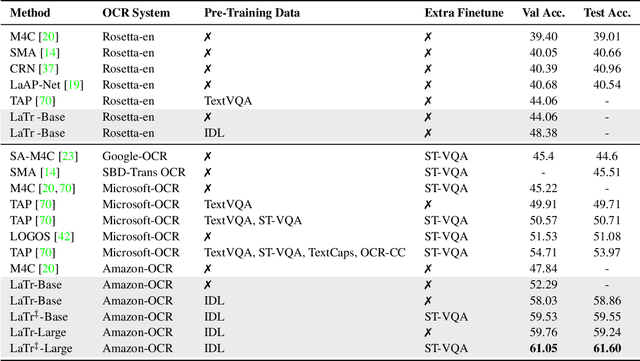
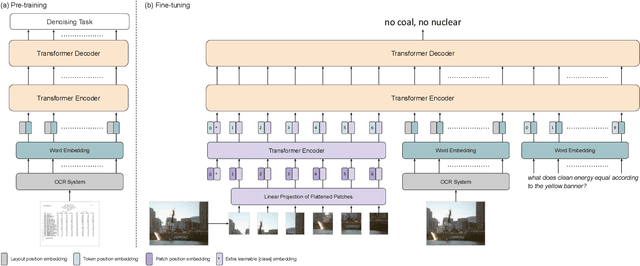
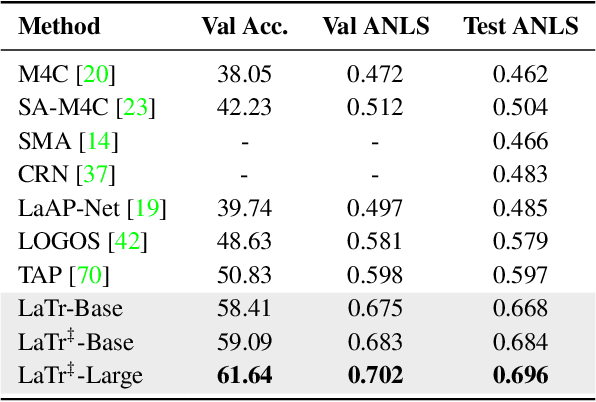
We propose a novel multimodal architecture for Scene Text Visual Question Answering (STVQA), named Layout-Aware Transformer (LaTr). The task of STVQA requires models to reason over different modalities. Thus, we first investigate the impact of each modality, and reveal the importance of the language module, especially when enriched with layout information. Accounting for this, we propose a single objective pre-training scheme that requires only text and spatial cues. We show that applying this pre-training scheme on scanned documents has certain advantages over using natural images, despite the domain gap. Scanned documents are easy to procure, text-dense and have a variety of layouts, helping the model learn various spatial cues (e.g. left-of, below etc.) by tying together language and layout information. Compared to existing approaches, our method performs vocabulary-free decoding and, as shown, generalizes well beyond the training vocabulary. We further demonstrate that LaTr improves robustness towards OCR errors, a common reason for failure cases in STVQA. In addition, by leveraging a vision transformer, we eliminate the need for an external object detector. LaTr outperforms state-of-the-art STVQA methods on multiple datasets. In particular, +7.6% on TextVQA, +10.8% on ST-VQA and +4.0% on OCR-VQA (all absolute accuracy numbers).
Reliable Inlier Evaluation for Unsupervised Point Cloud Registration
Feb 23, 2022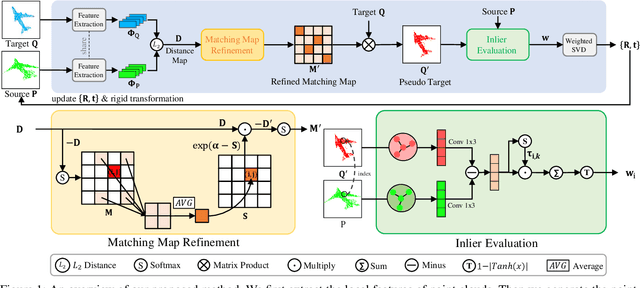
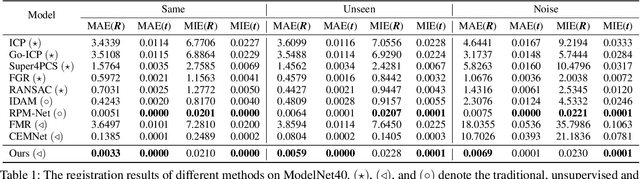
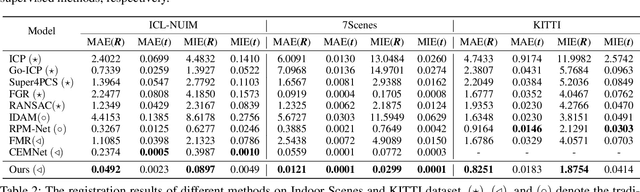
Unsupervised point cloud registration algorithm usually suffers from the unsatisfied registration precision in the partially overlapping problem due to the lack of effective inlier evaluation. In this paper, we propose a neighborhood consensus based reliable inlier evaluation method for robust unsupervised point cloud registration. It is expected to capture the discriminative geometric difference between the source neighborhood and the corresponding pseudo target neighborhood for effective inlier distinction. Specifically, our model consists of a matching map refinement module and an inlier evaluation module. In our matching map refinement module, we improve the point-wise matching map estimation by integrating the matching scores of neighbors into it. The aggregated neighborhood information potentially facilitates the discriminative map construction so that high-quality correspondences can be provided for generating the pseudo target point cloud. Based on the observation that the outlier has the significant structure-wise difference between its source neighborhood and corresponding pseudo target neighborhood while this difference for inlier is small, the inlier evaluation module exploits this difference to score the inlier confidence for each estimated correspondence. In particular, we construct an effective graph representation for capturing this geometric difference between the neighborhoods. Finally, with the learned correspondences and the corresponding inlier confidence, we use the weighted SVD algorithm for transformation estimation. Under the unsupervised setting, we exploit the Huber function based global alignment loss, the local neighborhood consensus loss, and spatial consistency loss for model optimization. The experimental results on extensive datasets demonstrate that our unsupervised point cloud registration method can yield comparable performance.
ASR-Aware End-to-end Neural Diarization
Feb 02, 2022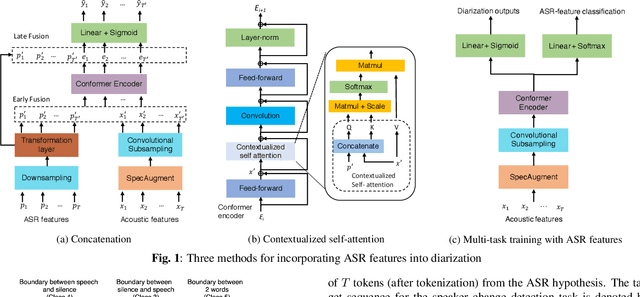
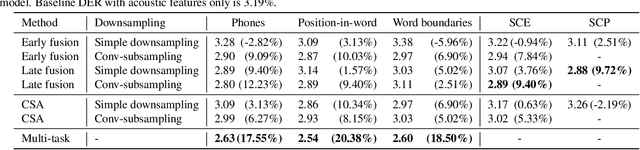
We present a Conformer-based end-to-end neural diarization (EEND) model that uses both acoustic input and features derived from an automatic speech recognition (ASR) model. Two categories of features are explored: features derived directly from ASR output (phones, position-in-word and word boundaries) and features derived from a lexical speaker change detection model, trained by fine-tuning a pretrained BERT model on the ASR output. Three modifications to the Conformer-based EEND architecture are proposed to incorporate the features. First, ASR features are concatenated with acoustic features. Second, we propose a new attention mechanism called contextualized self-attention that utilizes ASR features to build robust speaker representations. Finally, multi-task learning is used to train the model to minimize classification loss for the ASR features along with diarization loss. Experiments on the two-speaker English conversations of Switchboard+SRE data sets show that multi-task learning with position-in-word information is the most effective way of utilizing ASR features, reducing the diarization error rate (DER) by 20% relative to the baseline.
Rigorous data-driven computation of spectral properties of Koopman operators for dynamical systems
Nov 29, 2021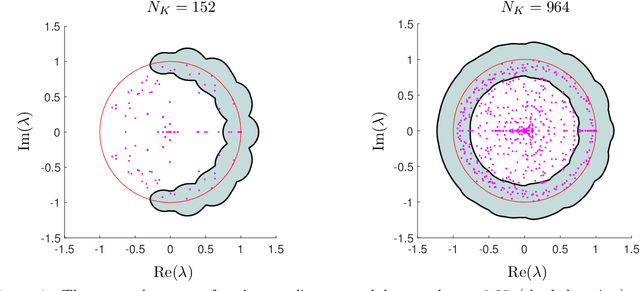
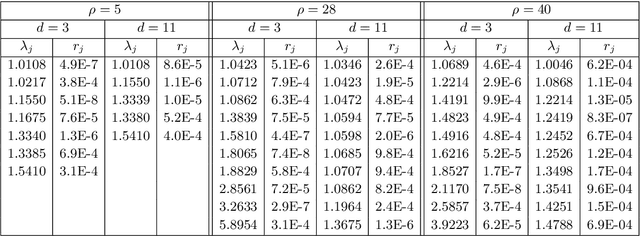
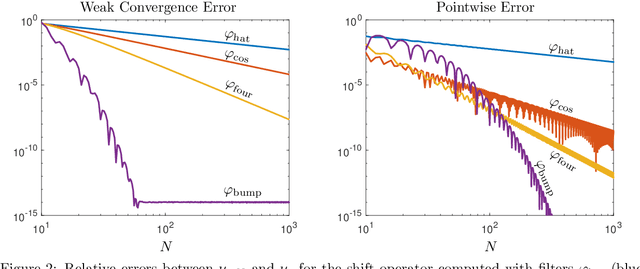

Koopman operators are infinite-dimensional operators that globally linearize nonlinear dynamical systems, making their spectral information useful for understanding dynamics. However, Koopman operators can have continuous spectra and infinite-dimensional invariant subspaces, making computing their spectral information a considerable challenge. This paper describes data-driven algorithms with rigorous convergence guarantees for computing spectral information of Koopman operators from trajectory data. We introduce residual dynamic mode decomposition (ResDMD), which provides the first scheme for computing the spectra and pseudospectra of general Koopman operators from snapshot data without spectral pollution. Using the resolvent operator and ResDMD, we also compute smoothed approximations of spectral measures associated with measure-preserving dynamical systems. We prove explicit convergence theorems for our algorithms, which can achieve high-order convergence even for chaotic systems, when computing the density of the continuous spectrum and the discrete spectrum. We demonstrate our algorithms on the tent map, Gauss iterated map, nonlinear pendulum, double pendulum, Lorenz system, and an $11$-dimensional extended Lorenz system. Finally, we provide kernelized variants of our algorithms for dynamical systems with a high-dimensional state-space. This allows us to compute the spectral measure associated with the dynamics of a protein molecule that has a 20,046-dimensional state-space, and compute nonlinear Koopman modes with error bounds for turbulent flow past aerofoils with Reynolds number $>10^5$ that has a 295,122-dimensional state-space.
Efficient Adapter Transfer of Self-Supervised Speech Models for Automatic Speech Recognition
Feb 07, 2022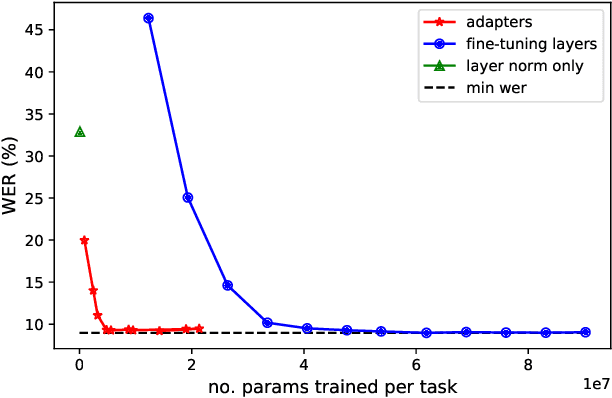
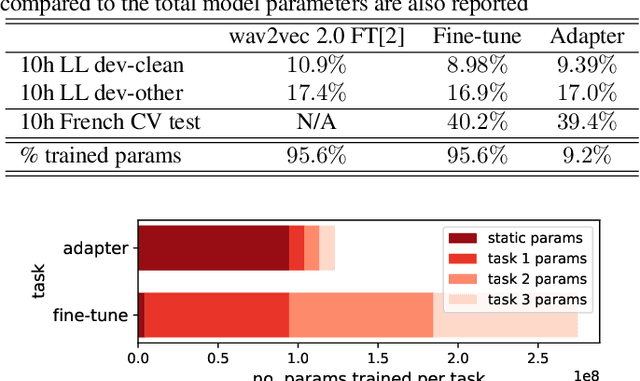

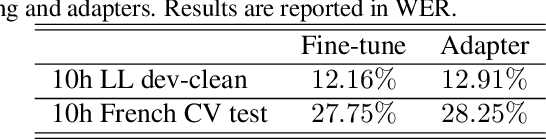
Self-supervised learning (SSL) is a powerful tool that allows learning of underlying representations from unlabeled data. Transformer based models such as wav2vec 2.0 and HuBERT are leading the field in the speech domain. Generally these models are fine-tuned on a small amount of labeled data for a downstream task such as Automatic Speech Recognition (ASR). This involves re-training the majority of the model for each task. Adapters are small lightweight modules which are commonly used in Natural Language Processing (NLP) to adapt pre-trained models to new tasks. In this paper we propose applying adapters to wav2vec 2.0 to reduce the number of parameters required for downstream ASR tasks, and increase scalability of the model to multiple tasks or languages. Using adapters we can perform ASR while training fewer than 10% of parameters per task compared to full fine-tuning with little degradation of performance. Ablations show that applying adapters into just the top few layers of the pre-trained network gives similar performance to full transfer, supporting the theory that higher pre-trained layers encode more phonemic information, and further optimizing efficiency.
An Unsupervised Attentive-Adversarial Learning Framework for Single Image Deraining
Feb 19, 2022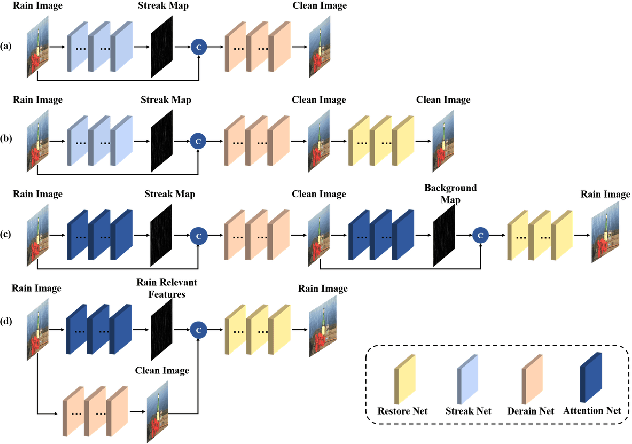



Single image deraining has been an important topic in low-level computer vision tasks. The atmospheric veiling effect (which is generated by rain accumulation, similar to fog) usually appears with the rain. Most deep learning-based single image deraining methods mainly focus on rain streak removal by disregarding this effect, which leads to low-quality deraining performance. In addition, these methods are trained only on synthetic data, hence they do not take into account real-world rainy images. To address the above issues, we propose a novel unsupervised attentive-adversarial learning framework (UALF) for single image deraining that trains on both synthetic and real rainy images while simultaneously capturing both rain streaks and rain accumulation features. UALF consists of a Rain-fog2Clean (R2C) transformation block and a Clean2Rain-fog (C2R) transformation block. In R2C, to better characterize the rain-fog fusion feature and to achieve high-quality deraining performance, we employ an attention rain-fog feature extraction network (ARFE) to exploit the self-similarity of global and local rain-fog information by learning the spatial feature correlations. Moreover, to improve the transformation ability of C2R, we design a rain-fog feature decoupling and reorganization network (RFDR) by embedding a rainy image degradation model and a mixed discriminator to preserve richer texture details. Extensive experiments on benchmark rain-fog and rain datasets show that UALF outperforms state-of-the-art deraining methods. We also conduct defogging performance evaluation experiments to further demonstrate the effectiveness of UALF
Semantic-aware Speech to Text Transmission with Redundancy Removal
Feb 07, 2022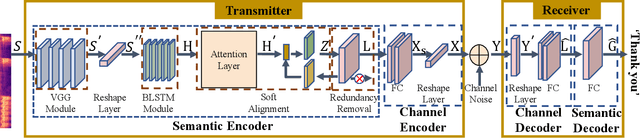
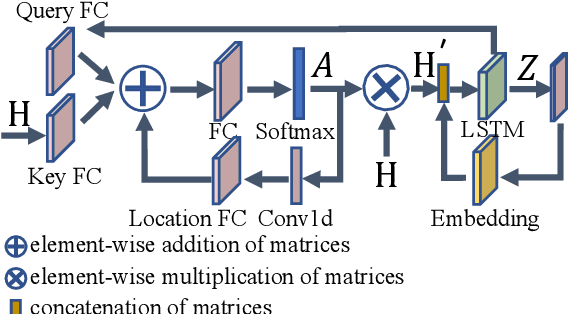
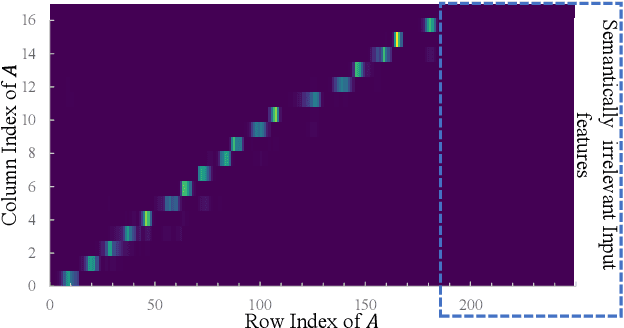
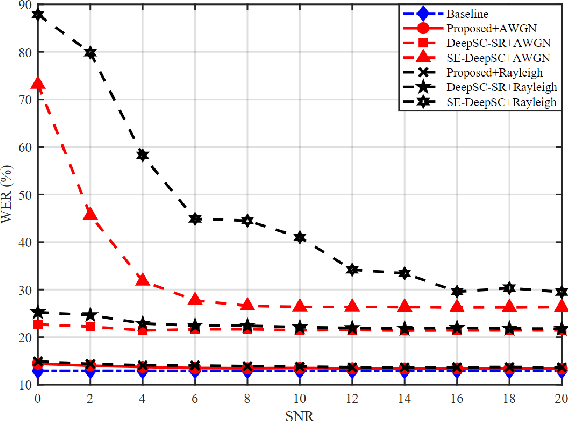
Deep learning (DL) based semantic communication methods have been explored for the efficient transmission of images, text, and speech in recent years. In contrast to traditional wireless communication methods that focus on the transmission of abstract symbols, semantic communication approaches attempt to achieve better transmission efficiency by only sending the semantic-related information of the source data. In this paper, we consider semantic-oriented speech to text transmission. We propose a novel end-to-end DL-based transceiver, which includes an attention-based soft alignment module and a redundancy removal module to compress the transmitted data. In particular, the former extracts only the text-related semantic features, and the latter further drops the semantically redundant content, greatly reducing the amount of semantic redundancy compared to existing methods. We also propose a two-stage training scheme, which speeds up the training of the proposed DL model. The simulation results indicate that our proposed method outperforms current methods in terms of the accuracy of the received text and transmission efficiency. Moreover, the proposed method also has a smaller model size and shorter end-to-end runtime.