 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Detection of Correlated Alarms Using Graph Embedding
Jan 17, 2022
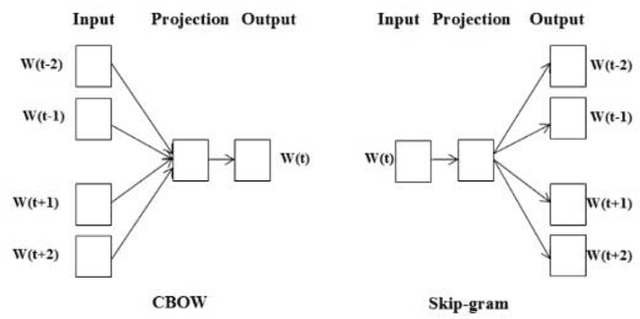
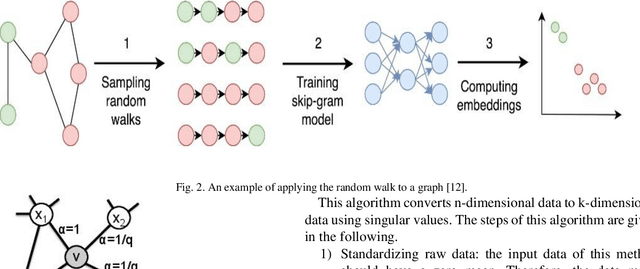
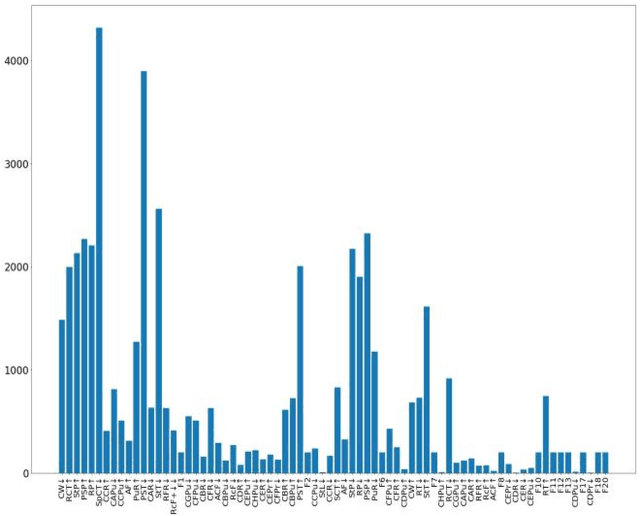
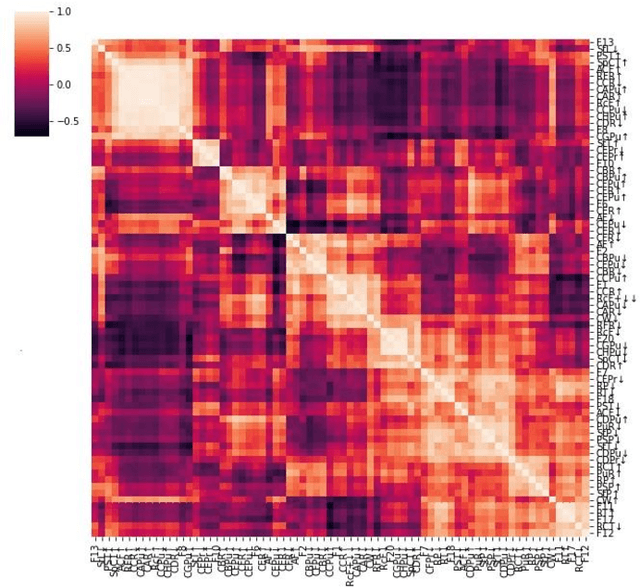
Industrial alarm systems have recently progressed considerably in terms of network complexity and the number of alarms. The increase in complexity and number of alarms presents challenges in these systems that decrease system efficiency and cause distrust of the operator, which might result in widespread damages. One contributing factor in alarm inefficiency is the correlated alarms. These alarms do not contain new information and only confuse the operator. This paper tries to present a novel method for detecting correlated alarms based on artificial intelligence methods to help the operator. The proposed method is based on graph embedding and alarm clustering, resulting in the detection of correlated alarms. To evaluate the proposed method, a case study is conducted on the well-known Tennessee-Eastman process.
Invertible Tabular GANs: Killing Two Birds with OneStone for Tabular Data Synthesis
Feb 08, 2022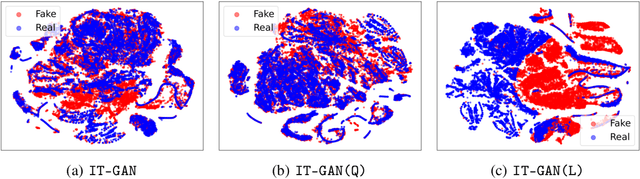
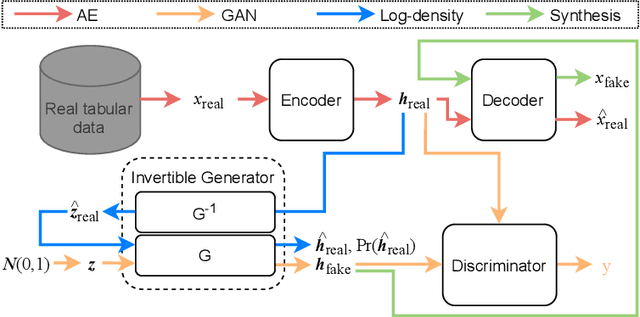
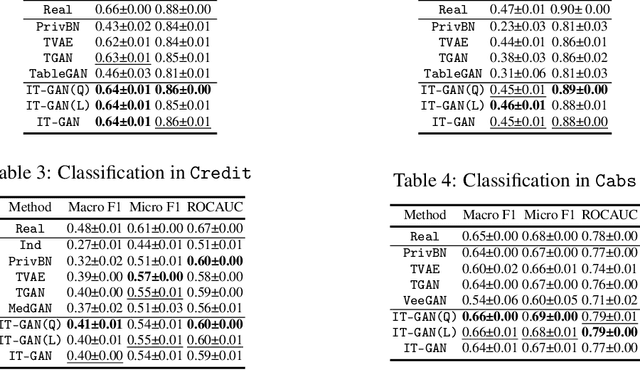
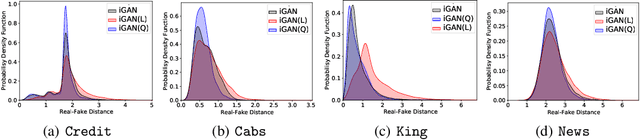
Tabular data synthesis has received wide attention in the literature. This is because available data is often limited, incomplete, or cannot be obtained easily, and data privacy is becoming increasingly important. In this work, we present a generalized GAN framework for tabular synthesis, which combines the adversarial training of GANs and the negative log-density regularization of invertible neural networks. The proposed framework can be used for two distinctive objectives. First, we can further improve the synthesis quality, by decreasing the negative log-density of real records in the process of adversarial training. On the other hand, by increasing the negative log-density of real records, realistic fake records can be synthesized in a way that they are not too much close to real records and reduce the chance of potential information leakage. We conduct experiments with real-world datasets for classification, regression, and privacy attacks. In general, the proposed method demonstrates the best synthesis quality (in terms of task-oriented evaluation metrics, e.g., F1) when decreasing the negative log-density during the adversarial training. If increasing the negative log-density, our experimental results show that the distance between real and fake records increases, enhancing robustness against privacy attacks.
Random Graph Matching in Geometric Models: the Case of Complete Graphs
Feb 23, 2022
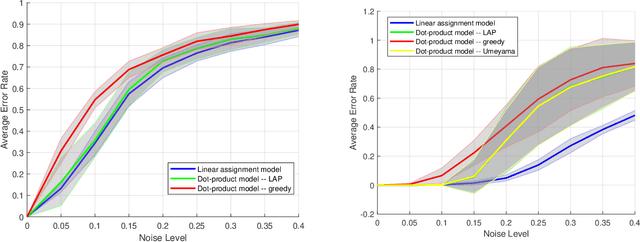
This paper studies the problem of matching two complete graphs with edge weights correlated through latent geometries, extending a recent line of research on random graph matching with independent edge weights to geometric models. Specifically, given a random permutation $\pi^*$ on $[n]$ and $n$ iid pairs of correlated Gaussian vectors $\{X_{\pi^*(i)}, Y_i\}$ in $\mathbb{R}^d$ with noise parameter $\sigma$, the edge weights are given by $A_{ij}=\kappa(X_i,X_j)$ and $B_{ij}=\kappa(Y_i,Y_j)$ for some link function $\kappa$. The goal is to recover the hidden vertex correspondence $\pi^*$ based on the observation of $A$ and $B$. We focus on the dot-product model with $\kappa(x,y)=\langle x, y \rangle$ and Euclidean distance model with $\kappa(x,y)=\|x-y\|^2$, in the low-dimensional regime of $d=o(\log n)$ wherein the underlying geometric structures are most evident. We derive an approximate maximum likelihood estimator, which provably achieves, with high probability, perfect recovery of $\pi^*$ when $\sigma=o(n^{-2/d})$ and almost perfect recovery with a vanishing fraction of errors when $\sigma=o(n^{-1/d})$. Furthermore, these conditions are shown to be information-theoretically optimal even when the latent coordinates $\{X_i\}$ and $\{Y_i\}$ are observed, complementing the recent results of [DCK19] and [KNW22] in geometric models of the planted bipartite matching problem. As a side discovery, we show that the celebrated spectral algorithm of [Ume88] emerges as a further approximation to the maximum likelihood in the geometric model.
Minimax rate of consistency for linear models with missing values
Feb 03, 2022

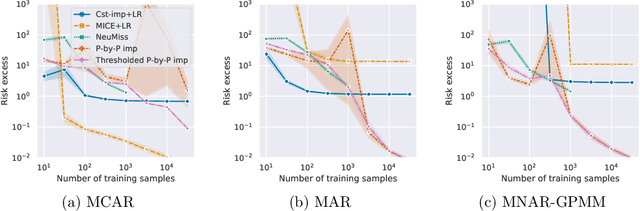
Missing values arise in most real-world data sets due to the aggregation of multiple sources and intrinsically missing information (sensor failure, unanswered questions in surveys...). In fact, the very nature of missing values usually prevents us from running standard learning algorithms. In this paper, we focus on the extensively-studied linear models, but in presence of missing values, which turns out to be quite a challenging task. Indeed, the Bayes rule can be decomposed as a sum of predictors corresponding to each missing pattern. This eventually requires to solve a number of learning tasks, exponential in the number of input features, which makes predictions impossible for current real-world datasets. First, we propose a rigorous setting to analyze a least-square type estimator and establish a bound on the excess risk which increases exponentially in the dimension. Consequently, we leverage the missing data distribution to propose a new algorithm, andderive associated adaptive risk bounds that turn out to be minimax optimal. Numerical experiments highlight the benefits of our method compared to state-of-the-art algorithms used for predictions with missing values.
Counterfactual Plans under Distributional Ambiguity
Jan 29, 2022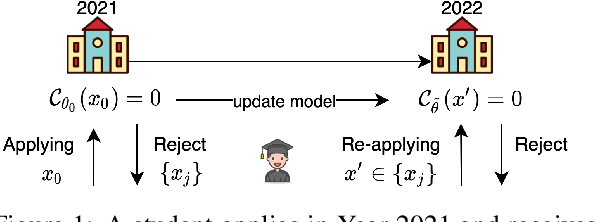

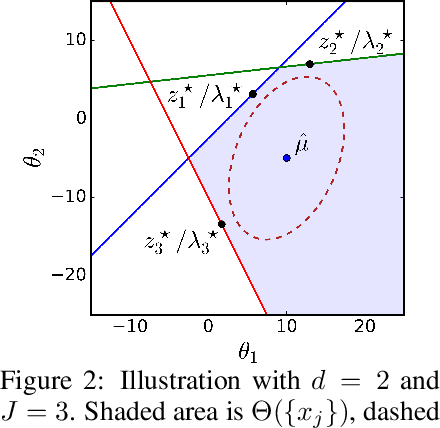
Counterfactual explanations are attracting significant attention due to the flourishing applications of machine learning models in consequential domains. A counterfactual plan consists of multiple possibilities to modify a given instance so that the model's prediction will be altered. As the predictive model can be updated subject to the future arrival of new data, a counterfactual plan may become ineffective or infeasible with respect to the future values of the model parameters. In this work, we study the counterfactual plans under model uncertainty, in which the distribution of the model parameters is partially prescribed using only the first- and second-moment information. First, we propose an uncertainty quantification tool to compute the lower and upper bounds of the probability of validity for any given counterfactual plan. We then provide corrective methods to adjust the counterfactual plan to improve the validity measure. The numerical experiments validate our bounds and demonstrate that our correction increases the robustness of the counterfactual plans in different real-world datasets.
LaTr: Layout-Aware Transformer for Scene-Text VQA
Dec 24, 2021
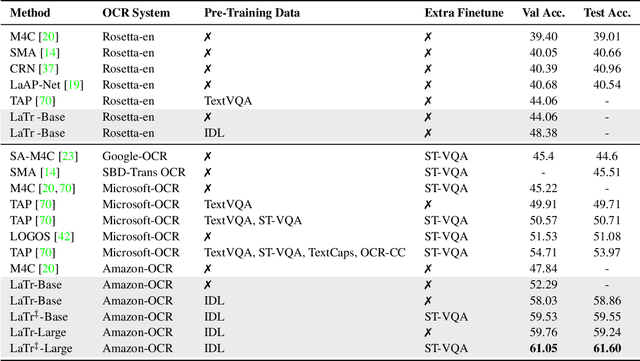
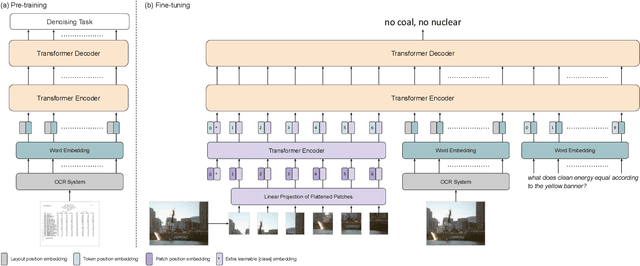
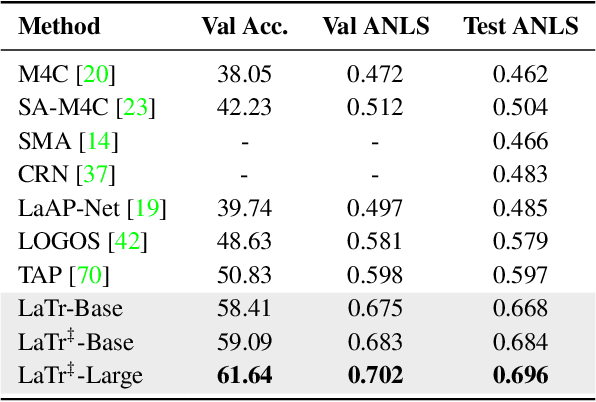
We propose a novel multimodal architecture for Scene Text Visual Question Answering (STVQA), named Layout-Aware Transformer (LaTr). The task of STVQA requires models to reason over different modalities. Thus, we first investigate the impact of each modality, and reveal the importance of the language module, especially when enriched with layout information. Accounting for this, we propose a single objective pre-training scheme that requires only text and spatial cues. We show that applying this pre-training scheme on scanned documents has certain advantages over using natural images, despite the domain gap. Scanned documents are easy to procure, text-dense and have a variety of layouts, helping the model learn various spatial cues (e.g. left-of, below etc.) by tying together language and layout information. Compared to existing approaches, our method performs vocabulary-free decoding and, as shown, generalizes well beyond the training vocabulary. We further demonstrate that LaTr improves robustness towards OCR errors, a common reason for failure cases in STVQA. In addition, by leveraging a vision transformer, we eliminate the need for an external object detector. LaTr outperforms state-of-the-art STVQA methods on multiple datasets. In particular, +7.6% on TextVQA, +10.8% on ST-VQA and +4.0% on OCR-VQA (all absolute accuracy numbers).
An Analysis Of Protected Health Information Leakage In Deep-Learning Based De-Identification Algorithms
Jan 28, 2021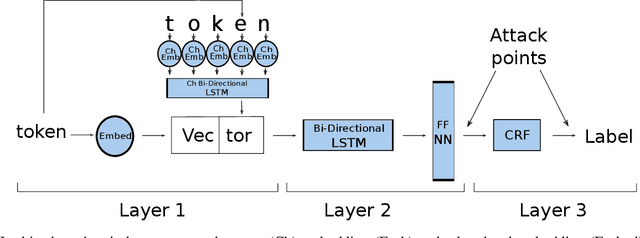
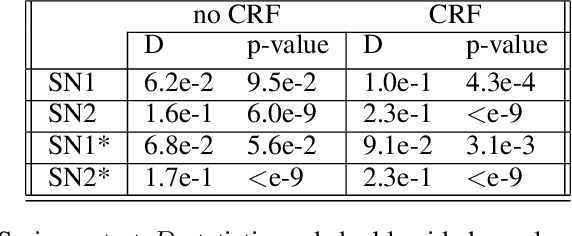
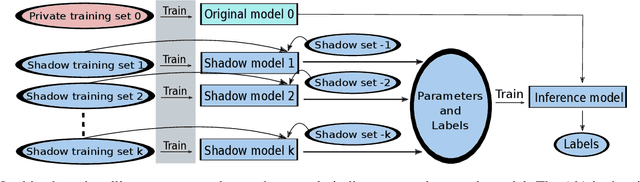
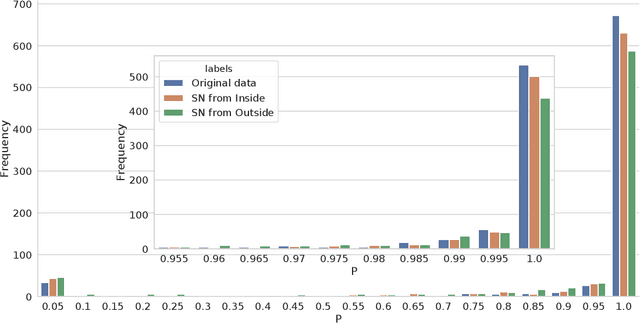
The increasing complexity of algorithms for analyzing medical data, including de-identification tasks, raises the possibility that complex algorithms are learning not just the general representation of the problem, but specifics of given individuals within the data. Modern legal frameworks specifically prohibit the intentional or accidental distribution of patient data, but have not addressed this potential avenue for leakage of such protected health information. Modern deep learning algorithms have the highest potential of such leakage due to complexity of the models. Recent research in the field has highlighted such issues in non-medical data, but all analysis is likely to be data and algorithm specific. We, therefore, chose to analyze a state-of-the-art free-text de-identification algorithm based on LSTM (Long Short-Term Memory) and its potential in encoding any individual in the training set. Using the i2b2 Challenge Data, we trained, then analyzed the model to assess whether the output of the LSTM, before the compression layer of the classifier, could be used to estimate the membership of the training data. Furthermore, we used different attacks including membership inference attack method to attack the model. Results indicate that the attacks could not identify whether members of the training data were distinguishable from non-members based on the model output. This indicates that the model does not provide any strong evidence into the identification of the individuals in the training data set and there is not yet empirical evidence it is unsafe to distribute the model for general use.
EGFI: Drug-Drug Interaction Extraction and Generation with Fusion of Enriched Entity and Sentence Information
Jan 25, 2021
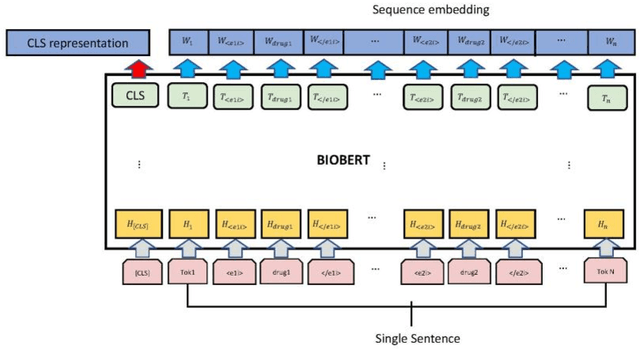
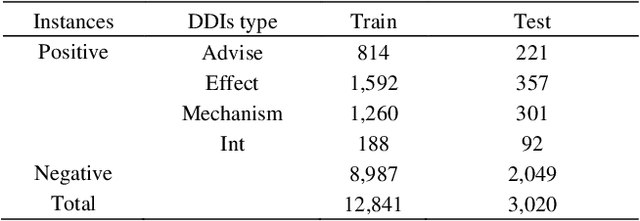
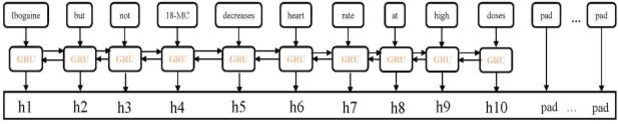
The rapid growth in literature accumulates diverse and yet comprehensive biomedical knowledge hidden to be mined such as drug interactions. However, it is difficult to extract the heterogeneous knowledge to retrieve or even discover the latest and novel knowledge in an efficient manner. To address such a problem, we propose EGFI for extracting and consolidating drug interactions from large-scale medical literature text data. Specifically, EGFI consists of two parts: classification and generation. In the classification part, EGFI encompasses the language model BioBERT which has been comprehensively pre-trained on biomedical corpus. In particular, we propose the multi-head attention mechanism and pack BiGRU to fuse multiple semantic information for rigorous context modeling. In the generation part, EGFI utilizes another pre-trained language model BioGPT-2 where the generation sentences are selected based on filtering rules. We evaluated the classification part on "DDIs 2013" dataset and "DTIs" dataset, achieving the FI score of 0.842 and 0.720 respectively. Moreover, we applied the classification part to distinguish high-quality generated sentences and verified with the exiting growth truth to confirm the filtered sentences. The generated sentences that are not recorded in DrugBank and DDIs 2013 dataset also demonstrate the potential of EGFI to identify novel drug relationships.
Retroformer: Pushing the Limits of Interpretable End-to-end Retrosynthesis Transformer
Jan 29, 2022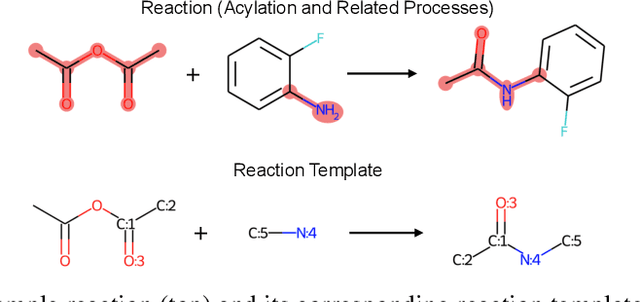
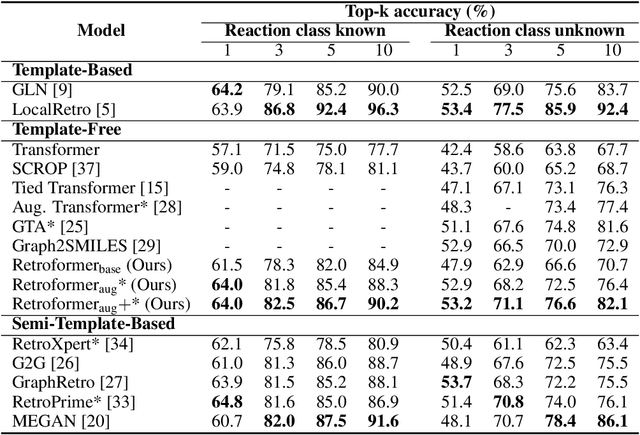
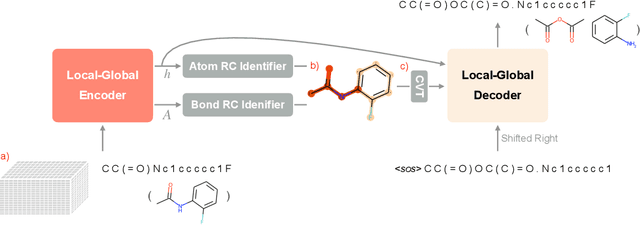
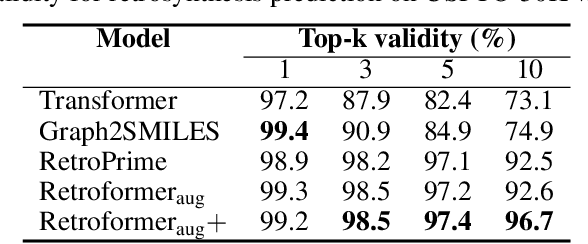
Retrosynthesis prediction is one of the fundamental challenges in organic synthesis. The task is to predict the reactants given a core product. With the advancement of machine learning, computer-aided synthesis planning has gained increasing interest. Numerous methods were proposed to solve this problem with different levels of dependency on additional chemical knowledge. In this paper, we propose Retroformer, a novel Transformer-based architecture for retrosynthesis prediction without relying on any cheminformatics tools for molecule editing. Via the proposed local attention head, the model can jointly encode the molecular sequence and graph, and efficiently exchange information between the local reactive region and the global reaction context. Retroformer reaches the new state-of-the-art accuracy for the end-to-end template-free retrosynthesis, and improves over many strong baselines on better molecule and reaction validity. In addition, its generative procedure is highly interpretable and controllable. Overall, Retroformer pushes the limits of the reaction reasoning ability of deep generative models.
ContourletNet: A Generalized Rain Removal Architecture Using Multi-Direction Hierarchical Representation
Nov 25, 2021


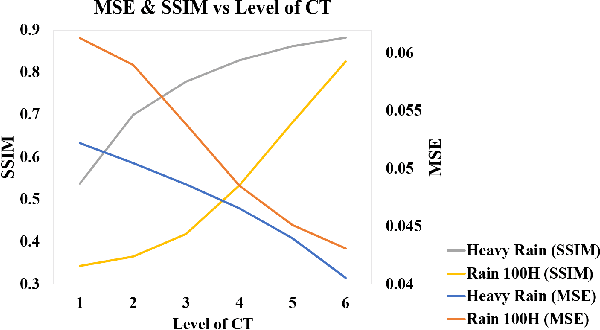
Images acquired from rainy scenes usually suffer from bad visibility which may damage the performance of computer vision applications. The rainy scenarios can be categorized into two classes: moderate rain and heavy rain scenes. Moderate rain scene mainly consists of rain streaks while heavy rain scene contains both rain streaks and the veiling effect (similar to haze). Although existing methods have achieved excellent performance on these two cases individually, it still lacks a general architecture to address both heavy rain and moderate rain scenarios effectively. In this paper, we construct a hierarchical multi-direction representation network by using the contourlet transform (CT) to address both moderate rain and heavy rain scenarios. The CT divides the image into the multi-direction subbands (MS) and the semantic subband (SS). First, the rain streak information is retrieved to the MS based on the multi-orientation property of the CT. Second, a hierarchical architecture is proposed to reconstruct the background information including damaged semantic information and the veiling effect in the SS. Last, the multi-level subband discriminator with the feedback error map is proposed. By this module, all subbands can be well optimized. This is the first architecture that can address both of the two scenarios effectively. The code is available in https://github.com/cctakaet/ContourletNet-BMVC2021.