 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Retroformer: Pushing the Limits of Interpretable End-to-end Retrosynthesis Transformer
Jan 29, 2022
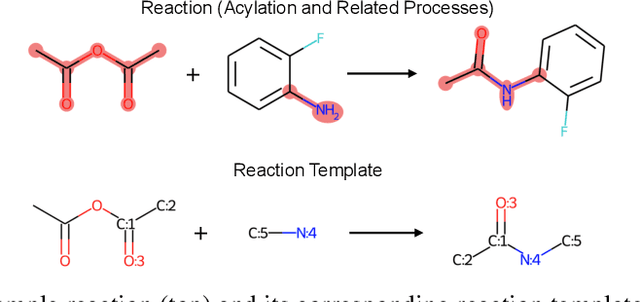
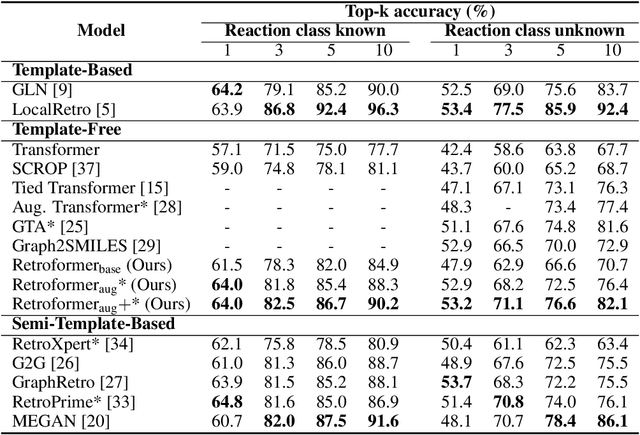
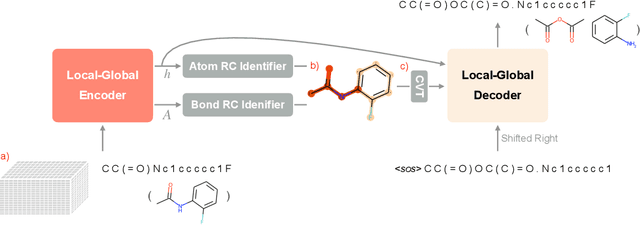
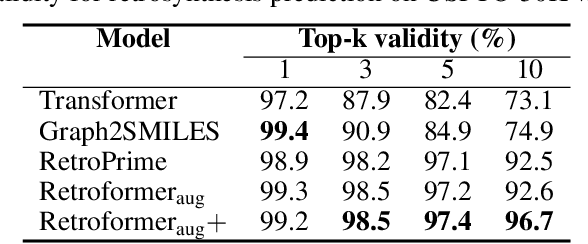
Retrosynthesis prediction is one of the fundamental challenges in organic synthesis. The task is to predict the reactants given a core product. With the advancement of machine learning, computer-aided synthesis planning has gained increasing interest. Numerous methods were proposed to solve this problem with different levels of dependency on additional chemical knowledge. In this paper, we propose Retroformer, a novel Transformer-based architecture for retrosynthesis prediction without relying on any cheminformatics tools for molecule editing. Via the proposed local attention head, the model can jointly encode the molecular sequence and graph, and efficiently exchange information between the local reactive region and the global reaction context. Retroformer reaches the new state-of-the-art accuracy for the end-to-end template-free retrosynthesis, and improves over many strong baselines on better molecule and reaction validity. In addition, its generative procedure is highly interpretable and controllable. Overall, Retroformer pushes the limits of the reaction reasoning ability of deep generative models.
Technical Report: A Hierarchical Deliberative-Reactive System Architecture for Task and Motion Planning in Partially Known Environments
Feb 03, 2022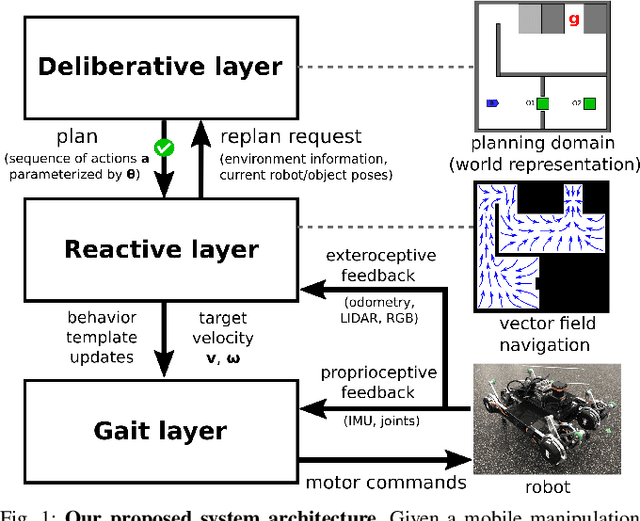
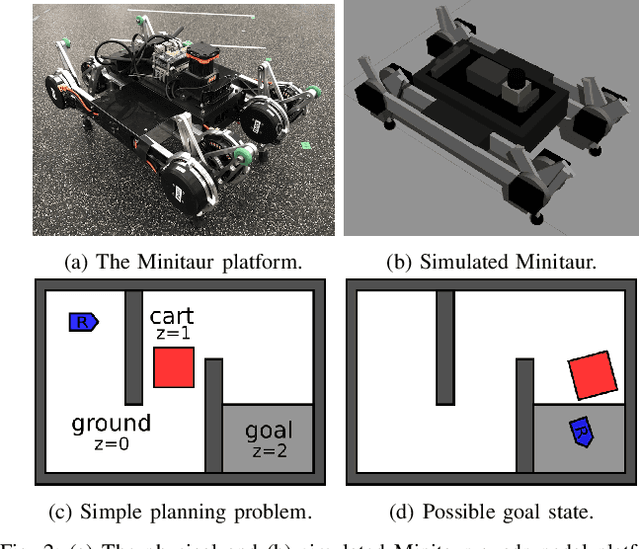
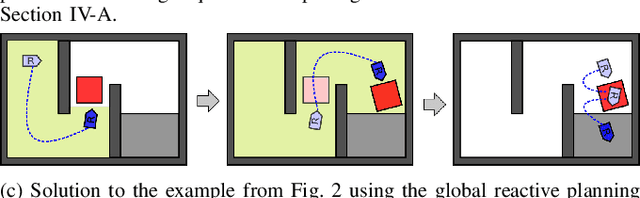
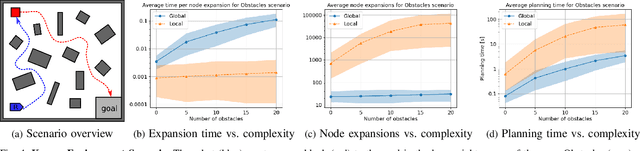
We describe a task and motion planning architecture for highly dynamic systems that combines a domain-independent sampling-based deliberative planning algorithm with a global reactive planner. We leverage the recent development of a reactive, vector field planner that provides guarantees of reachability to large regions of the environment even in the face of unknown or unforeseen obstacles. The reachability guarantees can be formalized using contracts that allow a deliberative planner to reason purely in terms of those contracts and synthesize a plan by choosing a sequence of reactive behaviors and their target configurations, without evaluating specific motion plans between targets. This reduces both the search depth at which plans will be found, and the number of samples required to ensure a plan exists, while crucially preserving correctness guarantees. The result is reduced computational cost of synthesizing plans, and increased robustness of generated plans to actuator noise, model misspecification, or unknown obstacles. Simulation studies show that our hierarchical planning and execution architecture can solve complex navigation and rearrangement tasks, even when faced with narrow passageways or incomplete world information.
Detection of Correlated Alarms Using Graph Embedding
Jan 17, 2022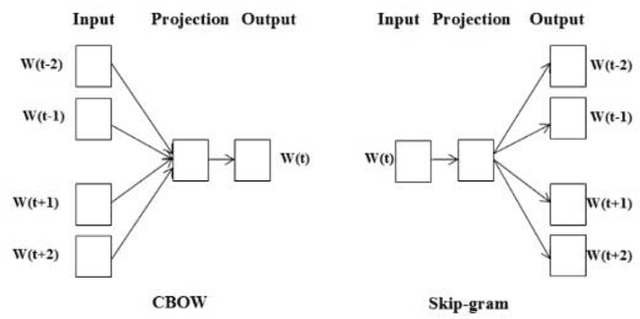
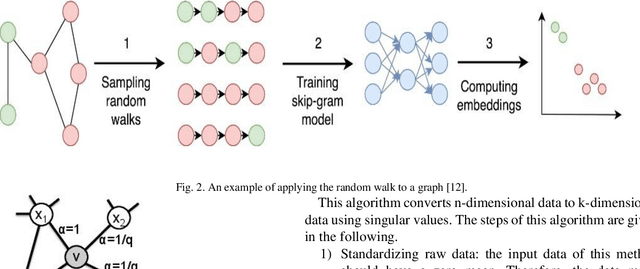
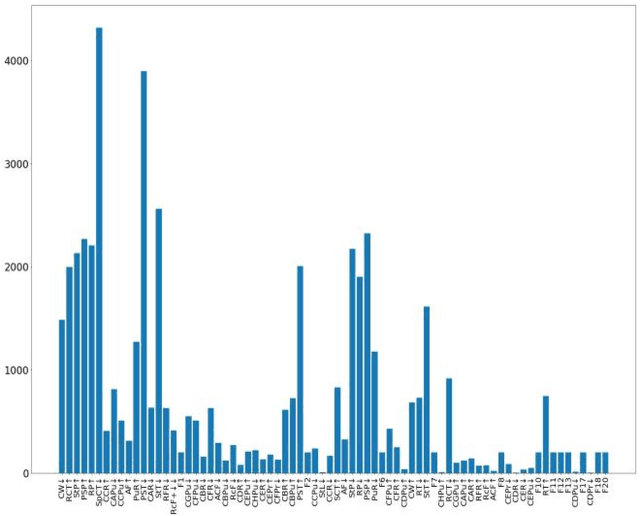
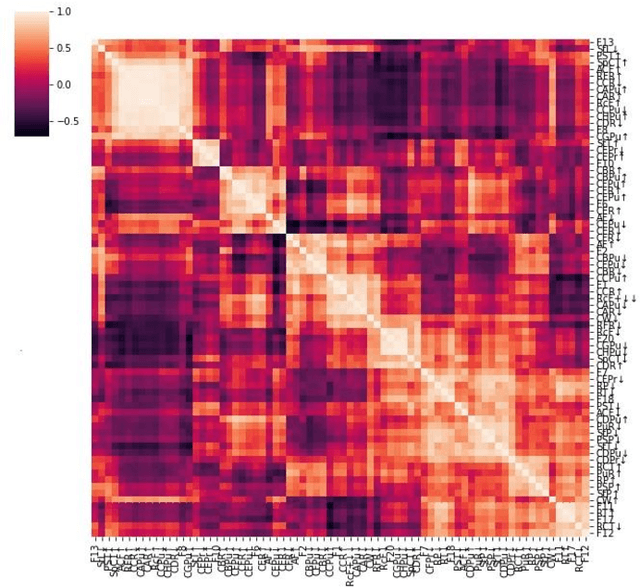
Industrial alarm systems have recently progressed considerably in terms of network complexity and the number of alarms. The increase in complexity and number of alarms presents challenges in these systems that decrease system efficiency and cause distrust of the operator, which might result in widespread damages. One contributing factor in alarm inefficiency is the correlated alarms. These alarms do not contain new information and only confuse the operator. This paper tries to present a novel method for detecting correlated alarms based on artificial intelligence methods to help the operator. The proposed method is based on graph embedding and alarm clustering, resulting in the detection of correlated alarms. To evaluate the proposed method, a case study is conducted on the well-known Tennessee-Eastman process.
Minimizing Entropy to Discover Good Solutions to Recurrent Mixed Integer Programs
Feb 07, 2022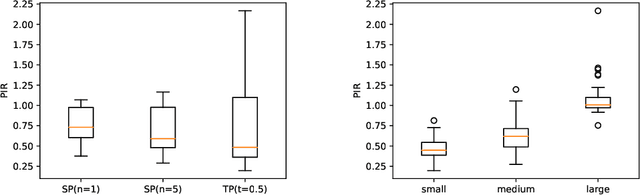
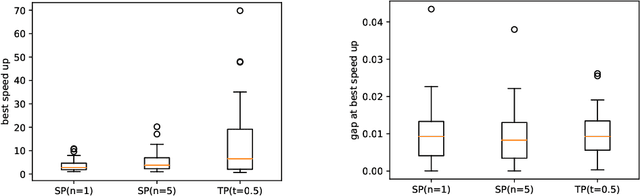
Current state-of-the-art solvers for mixed-integer programming (MIP) problems are designed to perform well on a wide range of problems. However, for many real-world use cases, problem instances come from a narrow distribution. This has motivated the development of specialized methods that can exploit the information in historical datasets to guide the design of heuristics. Recent works have shown that machine learning (ML) can be integrated with an MIP solver to inject domain knowledge and efficiently close the optimality gap. This hybridization is usually done with deep learning (DL), which requires a large dataset and extensive hyperparameter tuning to perform well. This paper proposes an online heuristic that uses the notion of entropy to efficiently build a model with minimal training data and tuning. We test our method on the locomotive assignment problem (LAP), a recurring real-world problem that is challenging to solve at scale. Experimental results show a speed up of an order of magnitude compared to a general purpose solver (CPLEX) with a relative gap of less than 2%. We also observe that for some instances our method can discover better solutions than CPLEX within the time limit.
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Feb 07, 2022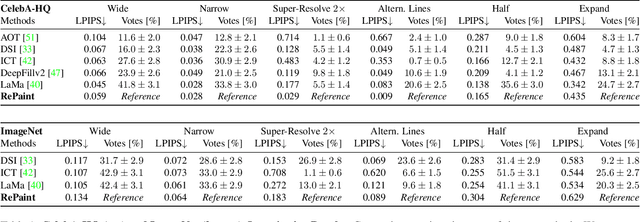
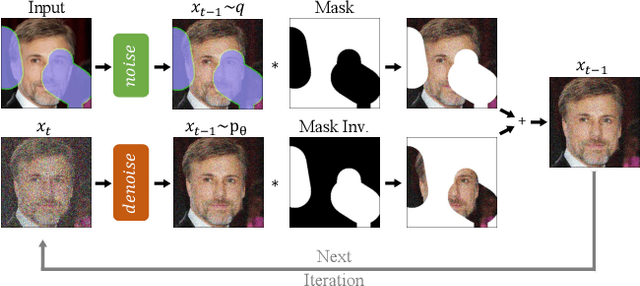


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
How semantic and geometric information mutually reinforce each other in ToF object localization
Aug 27, 2020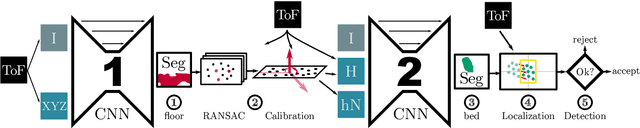

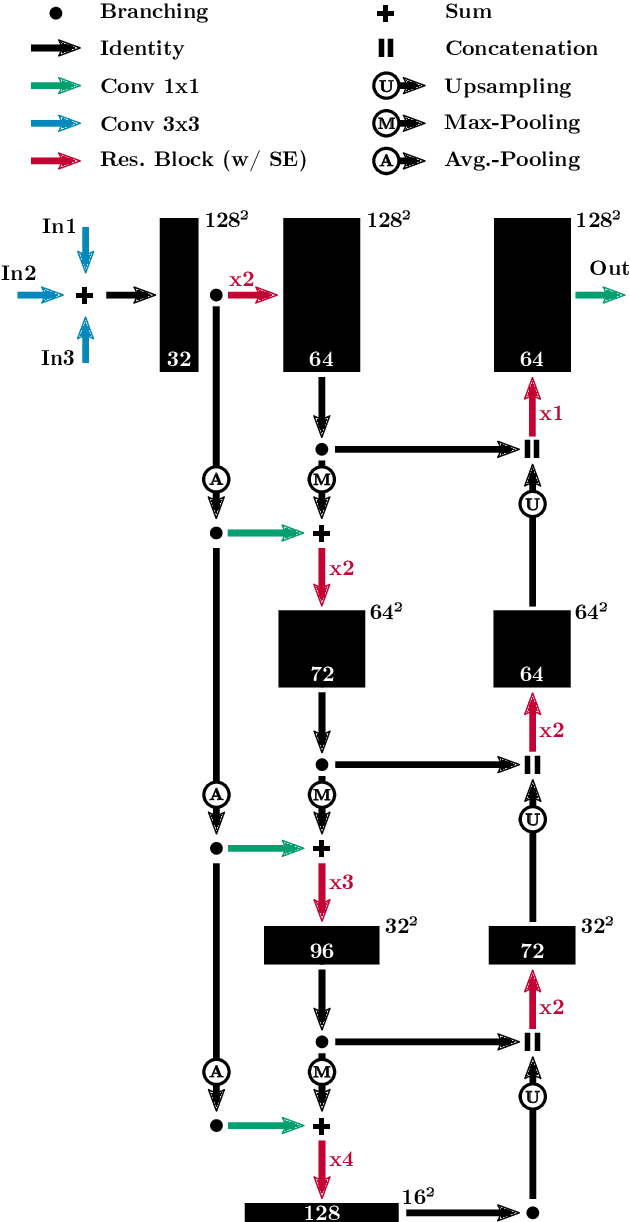
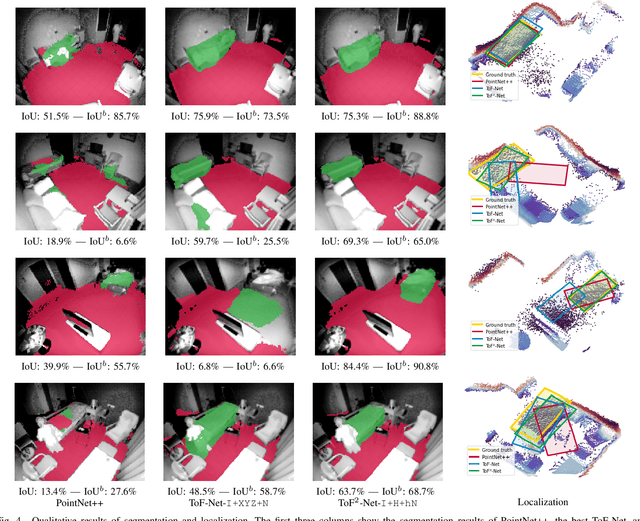
We propose a novel approach to localize a 3D object from the intensity and depth information images provided by a Time-of-Flight (ToF) sensor. Our method uses two CNNs. The first one uses raw depth and intensity images as input, to segment the floor pixels, from which the extrinsic parameters of the camera are estimated. The second CNN is in charge of segmenting the object-of-interest. As a main innovation, it exploits the calibration estimated from the prediction of the first CNN to represent the geometric depth information in a coordinate system that is attached to the ground, and is thus independent of the camera elevation. In practice, both the height of pixels with respect to the ground, and the orientation of normals to the point cloud are provided as input to the second CNN. Given the segmentation predicted by the second CNN, the object is localized based on point cloud alignment with a reference model. Our experiments demonstrate that our proposed two-step approach improves segmentation and localization accuracy by a significant margin compared to a conventional CNN architecture, ignoring calibration and height maps, but also compared to PointNet++.
Policy Optimization for Stochastic Shortest Path
Feb 07, 2022Policy optimization is among the most popular and successful reinforcement learning algorithms, and there is increasing interest in understanding its theoretical guarantees. In this work, we initiate the study of policy optimization for the stochastic shortest path (SSP) problem, a goal-oriented reinforcement learning model that strictly generalizes the finite-horizon model and better captures many applications. We consider a wide range of settings, including stochastic and adversarial environments under full information or bandit feedback, and propose a policy optimization algorithm for each setting that makes use of novel correction terms and/or variants of dilated bonuses (Luo et al., 2021). For most settings, our algorithm is shown to achieve a near-optimal regret bound. One key technical contribution of this work is a new approximation scheme to tackle SSP problems that we call \textit{stacked discounted approximation} and use in all our proposed algorithms. Unlike the finite-horizon approximation that is heavily used in recent SSP algorithms, our new approximation enables us to learn a near-stationary policy with only logarithmic changes during an episode and could lead to an exponential improvement in space complexity.
Reliable Inlier Evaluation for Unsupervised Point Cloud Registration
Feb 23, 2022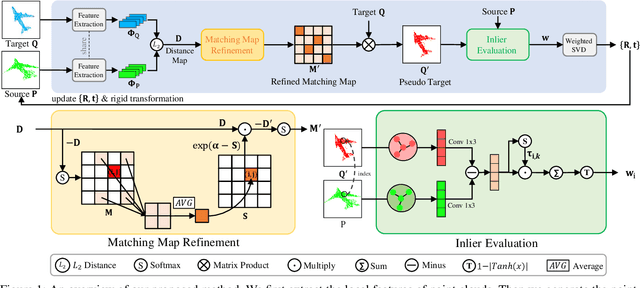
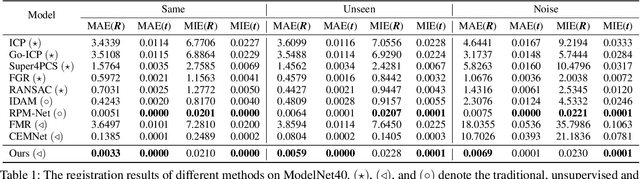
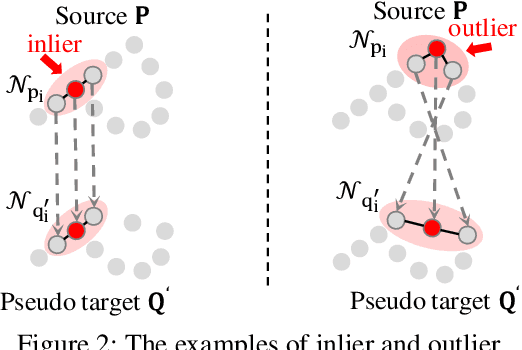
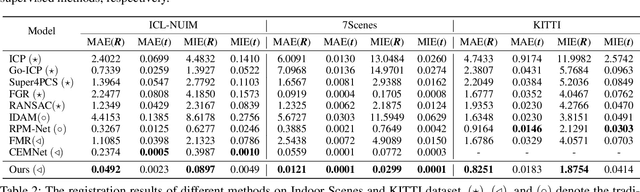
Unsupervised point cloud registration algorithm usually suffers from the unsatisfied registration precision in the partially overlapping problem due to the lack of effective inlier evaluation. In this paper, we propose a neighborhood consensus based reliable inlier evaluation method for robust unsupervised point cloud registration. It is expected to capture the discriminative geometric difference between the source neighborhood and the corresponding pseudo target neighborhood for effective inlier distinction. Specifically, our model consists of a matching map refinement module and an inlier evaluation module. In our matching map refinement module, we improve the point-wise matching map estimation by integrating the matching scores of neighbors into it. The aggregated neighborhood information potentially facilitates the discriminative map construction so that high-quality correspondences can be provided for generating the pseudo target point cloud. Based on the observation that the outlier has the significant structure-wise difference between its source neighborhood and corresponding pseudo target neighborhood while this difference for inlier is small, the inlier evaluation module exploits this difference to score the inlier confidence for each estimated correspondence. In particular, we construct an effective graph representation for capturing this geometric difference between the neighborhoods. Finally, with the learned correspondences and the corresponding inlier confidence, we use the weighted SVD algorithm for transformation estimation. Under the unsupervised setting, we exploit the Huber function based global alignment loss, the local neighborhood consensus loss, and spatial consistency loss for model optimization. The experimental results on extensive datasets demonstrate that our unsupervised point cloud registration method can yield comparable performance.
Multiview Transformers for Video Recognition
Jan 20, 2022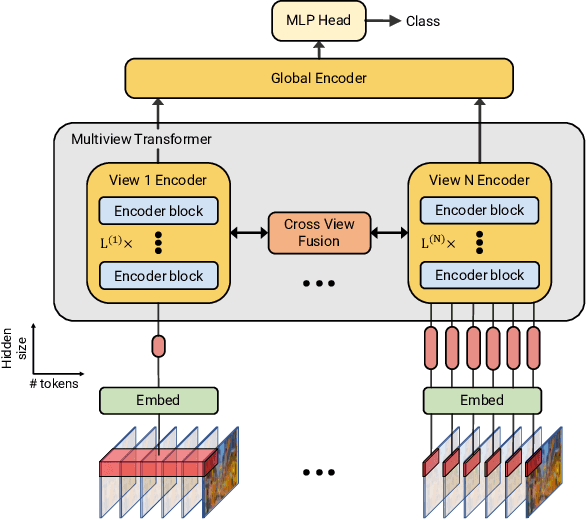
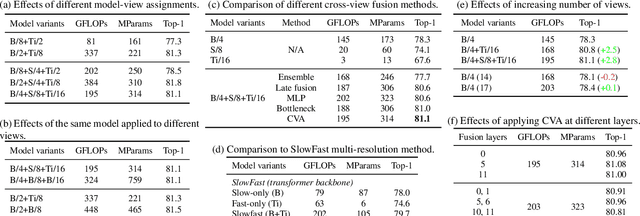
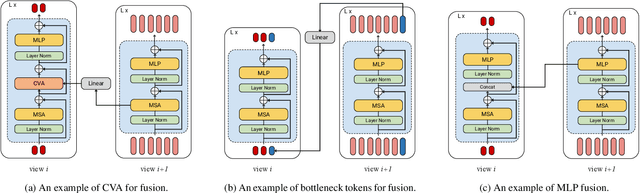
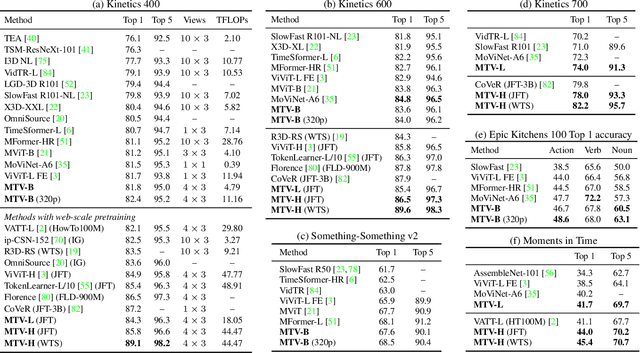
Video understanding requires reasoning at multiple spatiotemporal resolutions -- from short fine-grained motions to events taking place over longer durations. Although transformer architectures have recently advanced the state-of-the-art, they have not explicitly modelled different spatiotemporal resolutions. To this end, we present Multiview Transformers for Video Recognition (MTV). Our model consists of separate encoders to represent different views of the input video with lateral connections to fuse information across views. We present thorough ablation studies of our model and show that MTV consistently performs better than single-view counterparts in terms of accuracy and computational cost across a range of model sizes. Furthermore, we achieve state-of-the-art results on five standard datasets, and improve even further with large-scale pretraining. We will release code and pretrained checkpoints.
An Unsupervised Attentive-Adversarial Learning Framework for Single Image Deraining
Feb 19, 2022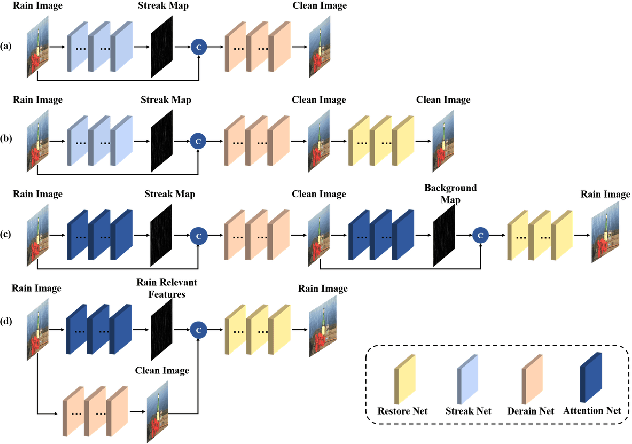



Single image deraining has been an important topic in low-level computer vision tasks. The atmospheric veiling effect (which is generated by rain accumulation, similar to fog) usually appears with the rain. Most deep learning-based single image deraining methods mainly focus on rain streak removal by disregarding this effect, which leads to low-quality deraining performance. In addition, these methods are trained only on synthetic data, hence they do not take into account real-world rainy images. To address the above issues, we propose a novel unsupervised attentive-adversarial learning framework (UALF) for single image deraining that trains on both synthetic and real rainy images while simultaneously capturing both rain streaks and rain accumulation features. UALF consists of a Rain-fog2Clean (R2C) transformation block and a Clean2Rain-fog (C2R) transformation block. In R2C, to better characterize the rain-fog fusion feature and to achieve high-quality deraining performance, we employ an attention rain-fog feature extraction network (ARFE) to exploit the self-similarity of global and local rain-fog information by learning the spatial feature correlations. Moreover, to improve the transformation ability of C2R, we design a rain-fog feature decoupling and reorganization network (RFDR) by embedding a rainy image degradation model and a mixed discriminator to preserve richer texture details. Extensive experiments on benchmark rain-fog and rain datasets show that UALF outperforms state-of-the-art deraining methods. We also conduct defogging performance evaluation experiments to further demonstrate the effectiveness of UALF