 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Splicing ViT Features for Semantic Appearance Transfer
Jan 02, 2022


We present a method for semantically transferring the visual appearance of one natural image to another. Specifically, our goal is to generate an image in which objects in a source structure image are "painted" with the visual appearance of their semantically related objects in a target appearance image. Our method works by training a generator given only a single structure/appearance image pair as input. To integrate semantic information into our framework - a pivotal component in tackling this task - our key idea is to leverage a pre-trained and fixed Vision Transformer (ViT) model which serves as an external semantic prior. Specifically, we derive novel representations of structure and appearance extracted from deep ViT features, untwisting them from the learned self-attention modules. We then establish an objective function that splices the desired structure and appearance representations, interweaving them together in the space of ViT features. Our framework, which we term "Splice", does not involve adversarial training, nor does it require any additional input information such as semantic segmentation or correspondences, and can generate high-resolution results, e.g., work in HD. We demonstrate high quality results on a variety of in-the-wild image pairs, under significant variations in the number of objects, their pose and appearance.
Single Trajectory Nonparametric Learning of Nonlinear Dynamics
Feb 16, 2022
Given a single trajectory of a dynamical system, we analyze the performance of the nonparametric least squares estimator (LSE). More precisely, we give nonasymptotic expected $l^2$-distance bounds between the LSE and the true regression function, where expectation is evaluated on a fresh, counterfactual, trajectory. We leverage recently developed information-theoretic methods to establish the optimality of the LSE for nonparametric hypotheses classes in terms of supremum norm metric entropy and a subgaussian parameter. Next, we relate this subgaussian parameter to the stability of the underlying process using notions from dynamical systems theory. When combined, these developments lead to rate-optimal error bounds that scale as $T^{-1/(2+q)}$ for suitably stable processes and hypothesis classes with metric entropy growth of order $\delta^{-q}$. Here, $T$ is the length of the observed trajectory, $\delta \in \mathbb{R}_+$ is the packing granularity and $q\in (0,2)$ is a complexity term. Finally, we specialize our results to a number of scenarios of practical interest, such as Lipschitz dynamics, generalized linear models, and dynamics described by functions in certain classes of Reproducing Kernel Hilbert Spaces (RKHS).
Large-Scale Inventory Optimization: A Recurrent-Neural-Networks-Inspired Simulation Approach
Jan 15, 2022
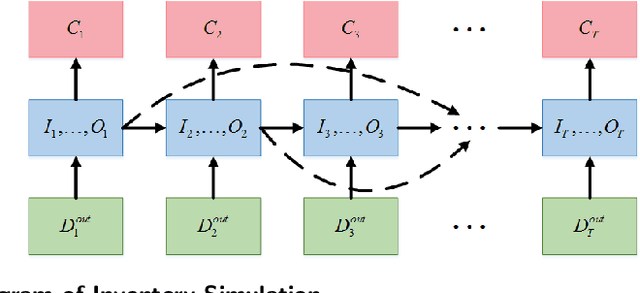
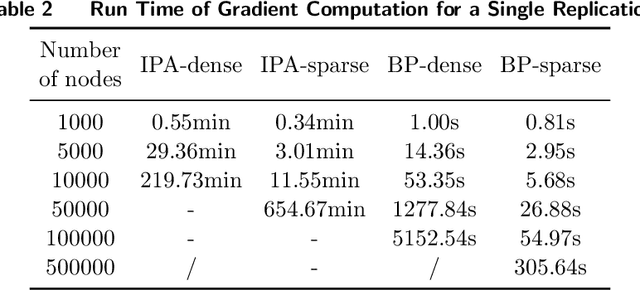
Many large-scale production networks include thousands types of final products and tens to hundreds thousands types of raw materials and intermediate products. These networks face complicated inventory management decisions, which are often too complicated for inventory models and too large for simulation models. In this paper, by combing efficient computational tools of recurrent neural networks (RNN) and the structural information of production networks, we propose a RNN inspired simulation approach that may be thousands times faster than existing simulation approach and is capable of solving large-scale inventory optimization problems in a reasonable amount of time.
Adaptive Resonance Theory-based Topological Clustering with a Divisive Hierarchical Structure Capable of Continual Learning
Jan 26, 2022
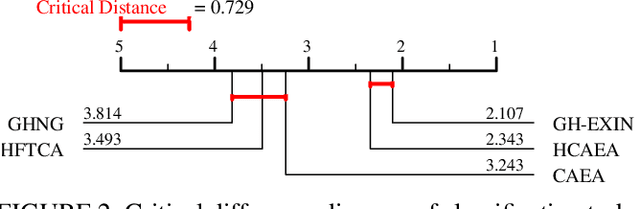
Thanks to an ability for handling the plasticity-stability dilemma, Adaptive Resonance Theory (ART) is considered as an effective approach for realizing continual learning. In general, however, the clustering performance of ART-based algorithms strongly depends on a similarity threshold, i.e., a vigilance parameter, which is data-dependent and specified by hand. This paper proposes an ART-based topological clustering algorithm with a mechanism that automatically estimates a similarity threshold from a distribution of data points. In addition, for the improving information extraction performance, a divisive hierarchical clustering algorithm capable of continual learning is proposed by introducing a hierarchical structure to the proposed algorithm. Simulation experiments show that the proposed algorithm shows the comparative clustering performance compared with recently proposed hierarchical clustering algorithms.
Estimating Causal Effects of Multi-Aspect Online Reviews with Multi-Modal Proxies
Jan 02, 2022
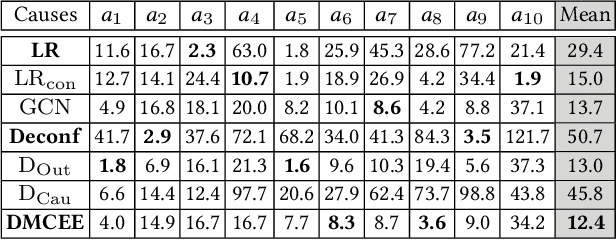
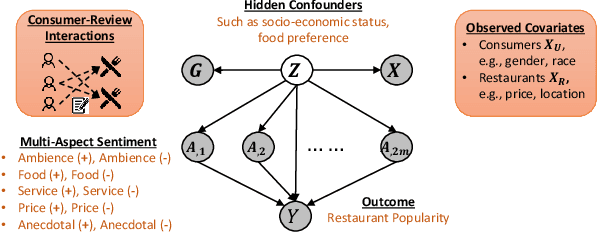
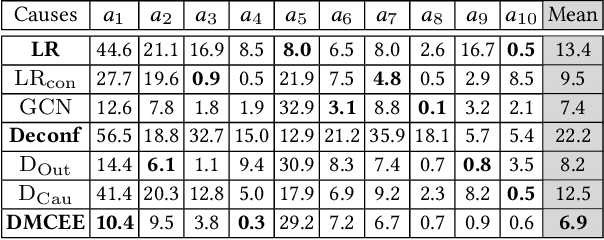
Online reviews enable consumers to engage with companies and provide important feedback. Due to the complexity of the high-dimensional text, these reviews are often simplified as a single numerical score, e.g., ratings or sentiment scores. This work empirically examines the causal effects of user-generated online reviews on a granular level: we consider multiple aspects, e.g., the Food and Service of a restaurant. Understanding consumers' opinions toward different aspects can help evaluate business performance in detail and strategize business operations effectively. Specifically, we aim to answer interventional questions such as What will the restaurant popularity be if the quality w.r.t. its aspect Service is increased by 10%? The defining challenge of causal inference with observational data is the presence of "confounder", which might not be observed or measured, e.g., consumers' preference to food type, rendering the estimated effects biased and high-variance. To address this challenge, we have recourse to the multi-modal proxies such as the consumer profile information and interactions between consumers and businesses. We show how to effectively leverage the rich information to identify and estimate causal effects of multiple aspects embedded in online reviews. Empirical evaluations on synthetic and real-world data corroborate the efficacy and shed light on the actionable insight of the proposed approach.
Efficient Video Segmentation Models with Per-frame Inference
Feb 24, 2022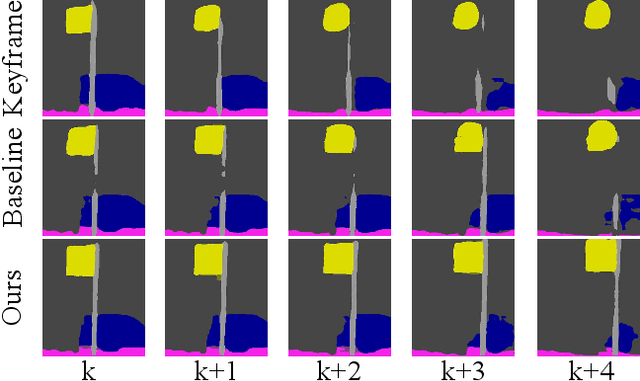
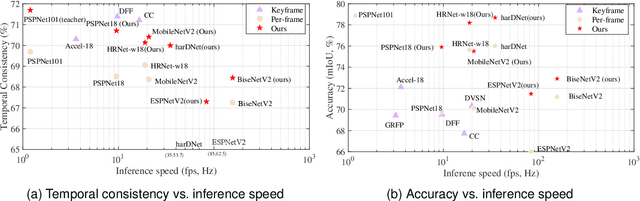
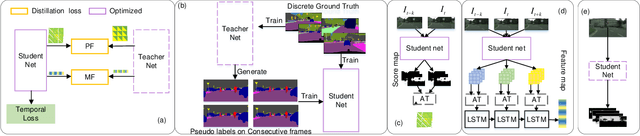
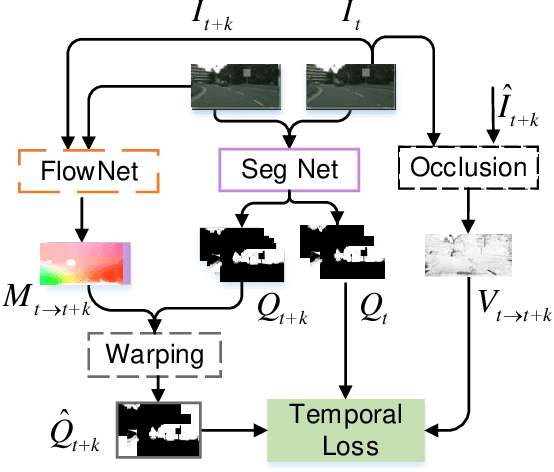
Most existing real-time deep models trained with each frame independently may produce inconsistent results across the temporal axis when tested on a video sequence. A few methods take the correlations in the video sequence into account,e.g., by propagating the results to the neighboring frames using optical flow or extracting frame representations using multi-frame information, which may lead to inaccurate results or unbalanced latency. In this work, we focus on improving the temporal consistency without introducing computation overhead in inference. To this end, we perform inference at each frame. Temporal consistency is achieved by learning from video frames with extra constraints during the training phase. introduced for inference. We propose several techniques to learn from the video sequence, including a temporal consistency loss and online/offline knowledge distillation methods. On the task of semantic video segmentation, weighing among accuracy, temporal smoothness, and efficiency, our proposed method outperforms keyframe-based methods and a few baseline methods that are trained with each frame independently, on datasets including Cityscapes, Camvid, and 300VW-Mask. We further apply our training method to video instance segmentation on YouTubeVISand develop an application of portrait matting in video sequences, by segmenting temporally consistent instance-level trimaps across frames. Experiments show superior qualitative and quantitative results. Code is available at: https://git.io/vidseg.
Resource Allocation for Single Carrier Massive MIMO Systems
Feb 28, 2022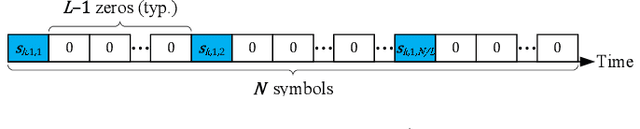
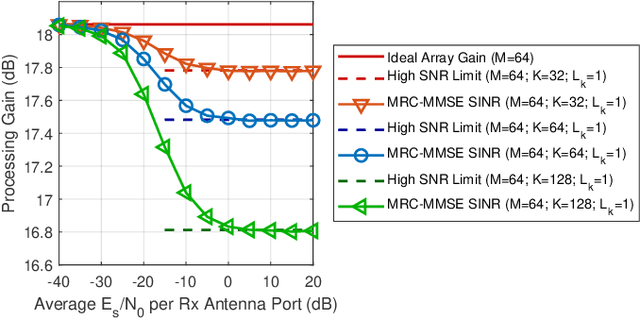

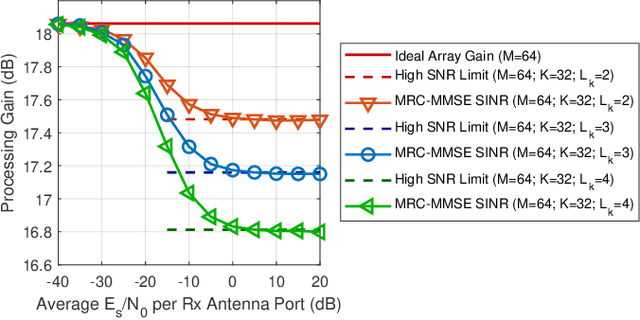
Resource allocation in orthogonal frequency division multiplexing (OFDM) systems is performed through allocating blocks of subcarriers to each user. Even though OFDM is the primary waveform for 5G NR systems, research reports have noted that single carrier modulation (SCM) offers several advantages over OFDM in massive multiple input multiple output (MIMO) systems, making it a preferred candidate for some future applications such as massive machine type communications (mMTC). This paper presents a method for SCM resource allocation and the relevant information recovery algorithms at the receiver. Our emphasis is on cyclic prefixed SCM, where highly flexible and efficient frequency domain detection algorithms enable the operation of many simultaneous users in a massive MIMO uplink scenario. The proposed resource allocation method allows the number of users to exceed the number of antennas at the base station (BS). Each single carrier transmission is partitioned into $L$ interleaved streams, and each user is allocated a number of such streams. One major benefit of SCM is that each data symbol is spread over the entire bandwidth. As such, the receiver performance is dictated by the average channel gain across the transmission band rather than the channel gain at a given frequency bin or a small group of frequencies. In the proposed setup, each stream may be thought of as a resource block in SCM, analogous to resource blocks in OFDM. Hence, in the context of this paper, the terms resource blocks and streams may be used interchangeably.
TSAX is Trending
Dec 24, 2021
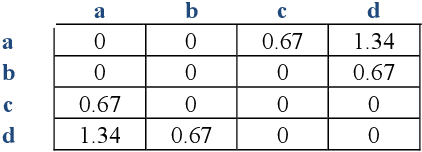
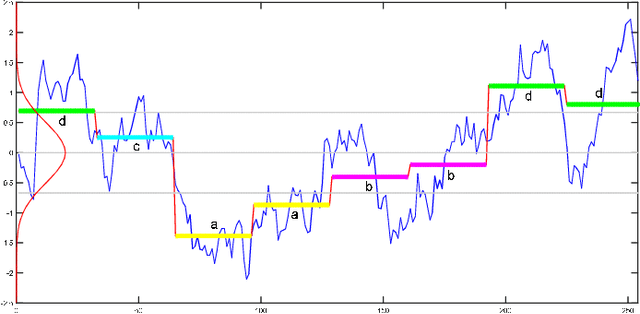
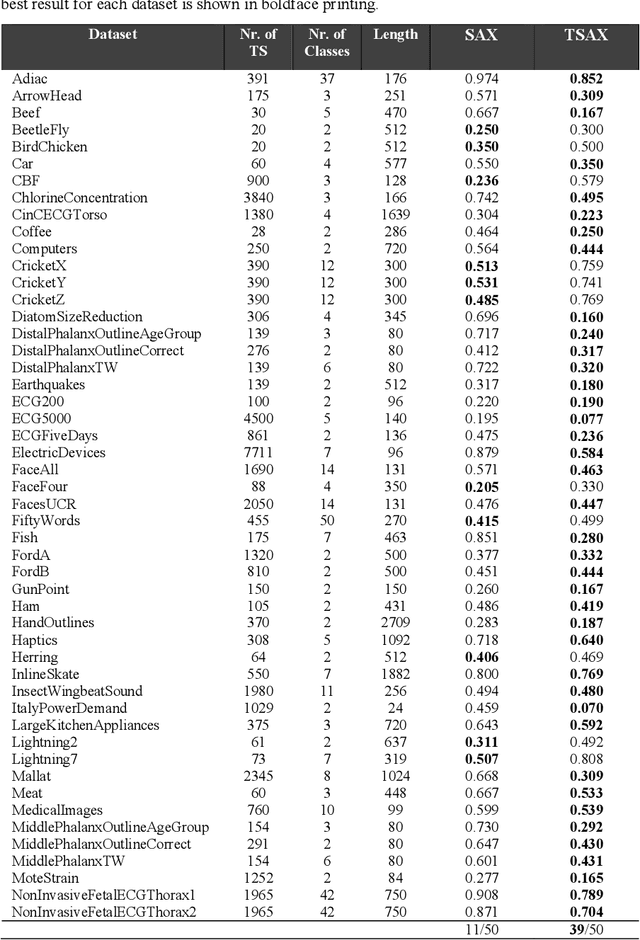
Time series mining is an important branch of data mining, as time series data is ubiquitous and has many applications in several domains. The main task in time series mining is classification. Time series representation methods play an important role in time series classification and other time series mining tasks. One of the most popular representation methods of time series data is the Symbolic Aggregate approXimation (SAX). The secret behind its popularity is its simplicity and efficiency. SAX has however one major drawback, which is its inability to represent trend information. Several methods have been proposed to enable SAX to capture trend information, but this comes at the expense of complex processing, preprocessing, or post-processing procedures. In this paper we present a new modification of SAX that we call Trending SAX (TSAX), which only adds minimal complexity to SAX, but substantially improves its performance in time series classification. This is validated experimentally on 50 datasets. The results show the superior performance of our method, as it gives a smaller classification error on 39 datasets compared with SAX.
* 21st International Conference on Computational Science (ICCS 2021)
Random Orthogonalization for Federated Learning in Massive MIMO Systems
Jan 29, 2022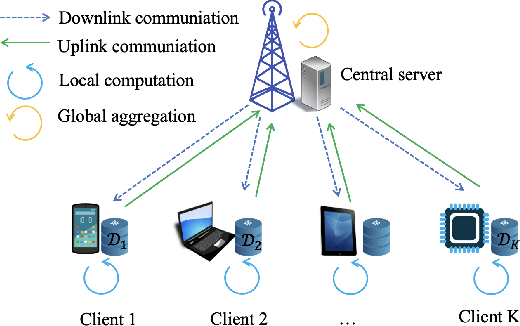

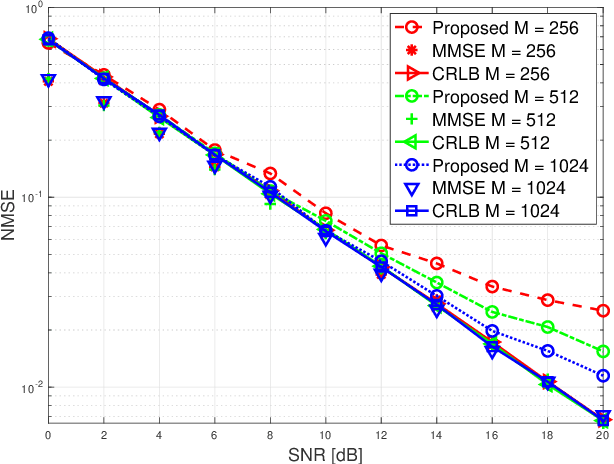
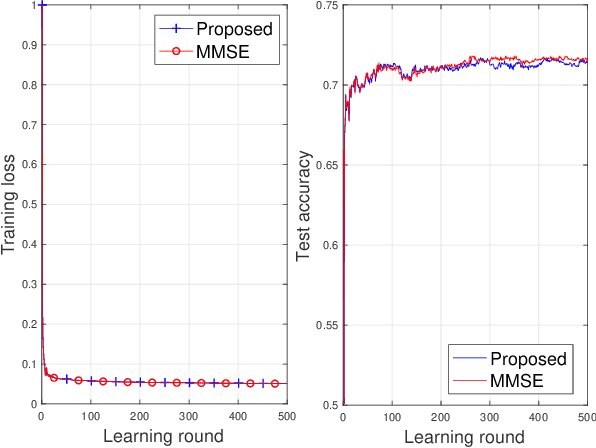
We propose a novel uplink communication method, coined random orthogonalization, for federated learning (FL) in a massive multiple-input and multiple-output (MIMO) wireless system. The key novelty of random orthogonalization comes from the tight coupling of FL model aggregation and two unique characteristics of massive MIMO - channel hardening and favorable propagation. As a result, random orthogonalization can achieve natural over-the-air model aggregation without requiring transmitter side channel state information, while significantly reducing the channel estimation overhead at the receiver. Theoretical analyses with respect to both communication and machine learning performances are carried out. In particular, an explicit relationship among the convergence rate, the number of clients and the number of antennas is established. Experimental results validate the effectiveness and efficiency of random orthogonalization for FL in massive MIMO.
HDC-MiniROCKET: Explicit Time Encoding in Time Series Classification with Hyperdimensional Computing
Feb 16, 2022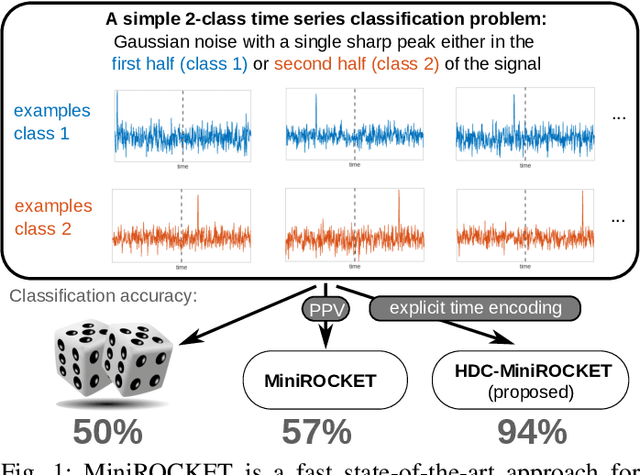
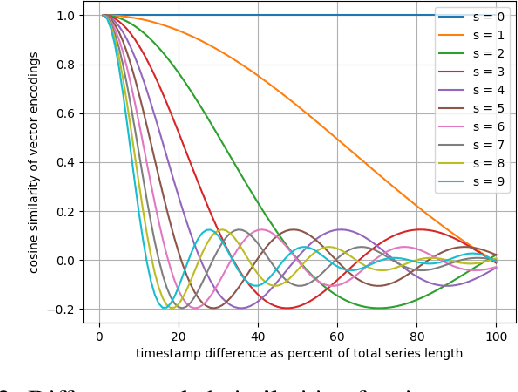
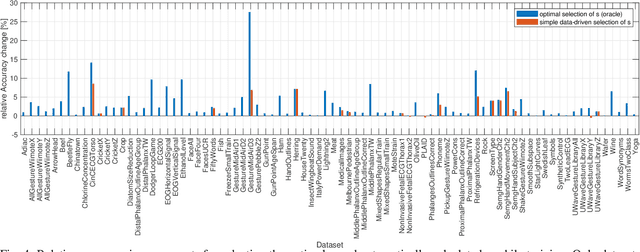
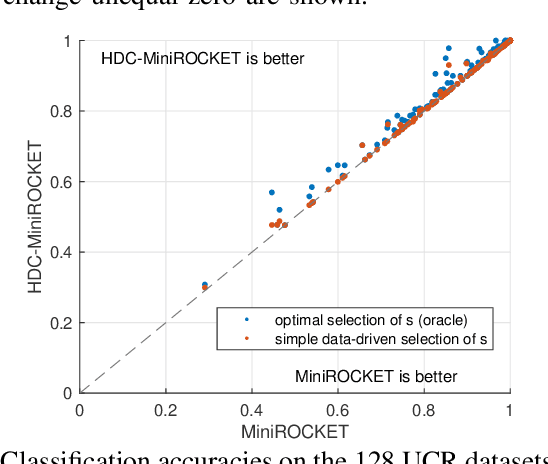
Classification of time series data is an important task for many application domains. One of the best existing methods for this task, in terms of accuracy and computation time, is MiniROCKET. In this work, we extend this approach to provide better global temporal encodings using hyperdimensional computing (HDC) mechanisms. HDC (also known as Vector Symbolic Architectures, VSA) is a general method to explicitly represent and process information in high-dimensional vectors. It has previously been used successfully in combination with deep neural networks and other signal processing algorithms. We argue that the internal high-dimensional representation of MiniROCKET is well suited to be complemented by the algebra of HDC. This leads to a more general formulation, HDC-MiniROCKET, where the original algorithm is only a special case. We will discuss and demonstrate that HDC-MiniROCKET can systematically overcome catastrophic failures of MiniROCKET on simple synthetic datasets. These results are confirmed by experiments on the 128 datasets from the UCR time series classification benchmark. The extension with HDC can achieve considerably better results on datasets with high temporal dependence without increasing the computational effort for inference.