 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Specializing Word Embeddings (for Parsing) by Information Bottleneck
Oct 01, 2019
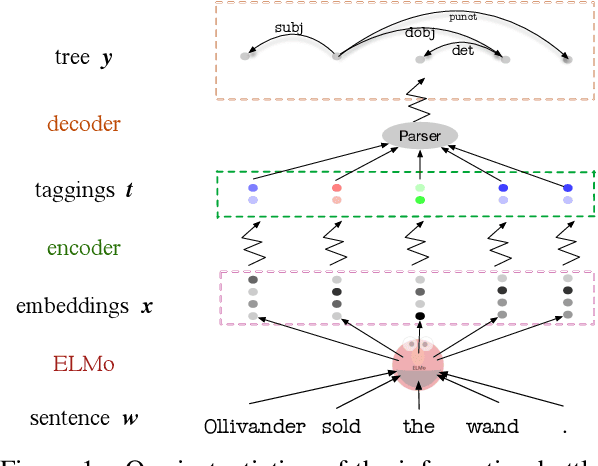
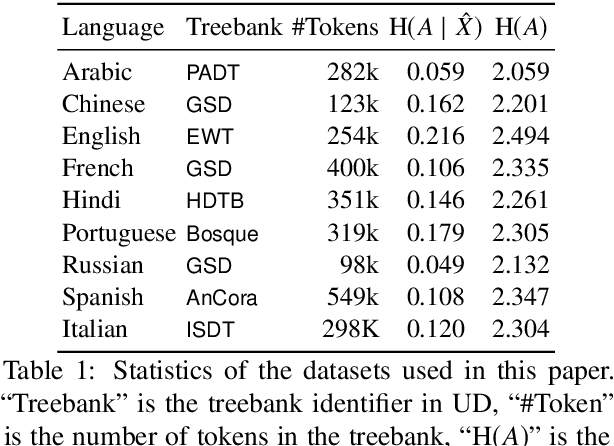
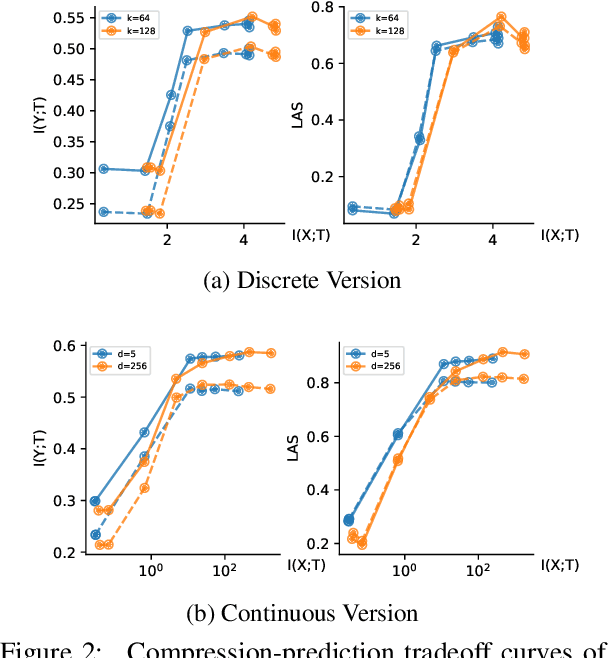
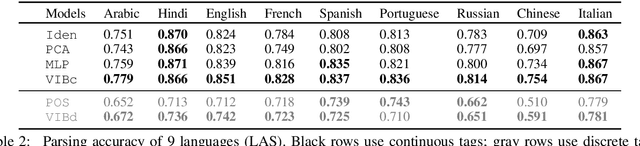
Pre-trained word embeddings like ELMo and BERT contain rich syntactic and semantic information, resulting in state-of-the-art performance on various tasks. We propose a very fast variational information bottleneck (VIB) method to nonlinearly compress these embeddings, keeping only the information that helps a discriminative parser. We compress each word embedding to either a discrete tag or a continuous vector. In the discrete version, our automatically compressed tags form an alternative tag set: we show experimentally that our tags capture most of the information in traditional POS tag annotations, but our tag sequences can be parsed more accurately at the same level of tag granularity. In the continuous version, we show experimentally that moderately compressing the word embeddings by our method yields a more accurate parser in 8 of 9 languages, unlike simple dimensionality reduction.
Gendered Language in Resumes and its Implications for Algorithmic Bias in Hiring
Dec 16, 2021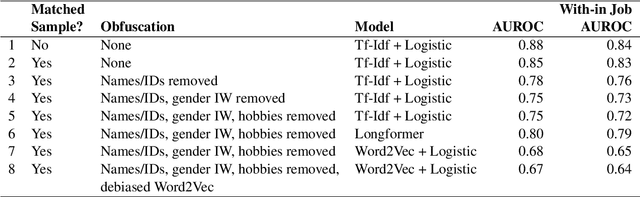
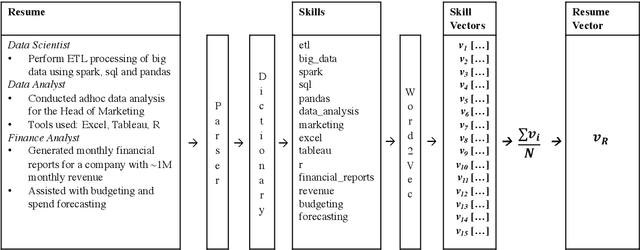
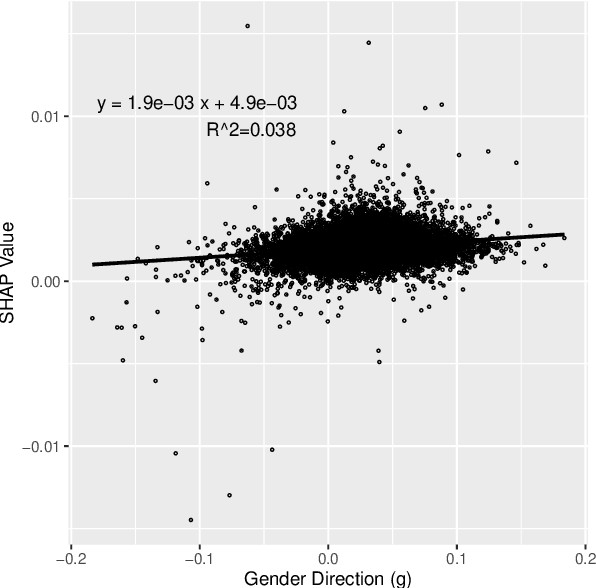
Despite growing concerns around gender bias in NLP models used in algorithmic hiring, there is little empirical work studying the extent and nature of gendered language in resumes. Using a corpus of 709k resumes from IT firms, we train a series of models to classify the gender of the applicant, thereby measuring the extent of gendered information encoded in resumes. We also investigate whether it is possible to obfuscate gender from resumes by removing gender identifiers, hobbies, gender sub-space in embedding models, etc. We find that there is a significant amount of gendered information in resumes even after obfuscation. A simple Tf-Idf model can learn to classify gender with AUROC=0.75, and more sophisticated transformer-based models achieve AUROC=0.8. We further find that gender predictive values have low correlation with gender direction of embeddings -- meaning that, what is predictive of gender is much more than what is "gendered" in the masculine/feminine sense. We discuss the algorithmic bias and fairness implications of these findings in the hiring context.
ICSML: Industrial Control Systems Machine Learning inference framework natively executing on IEC 61131-3 languages
Feb 21, 2022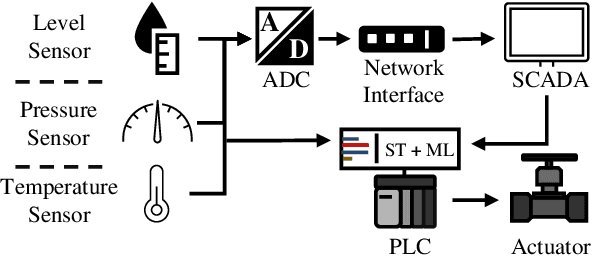
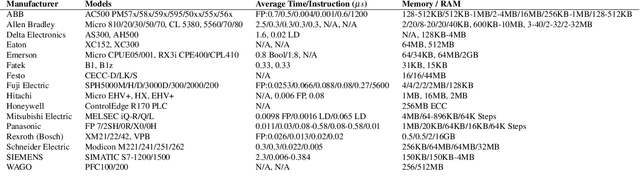
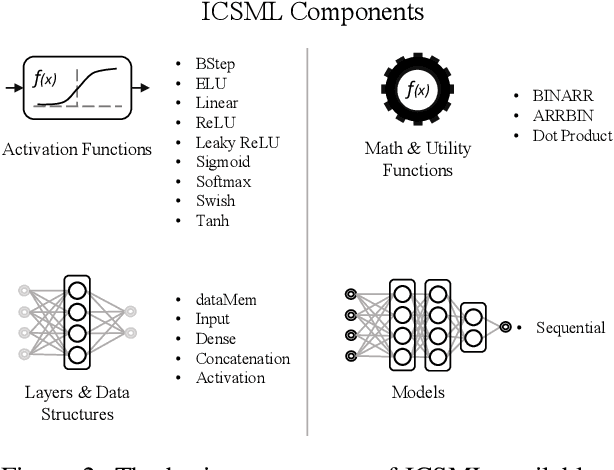
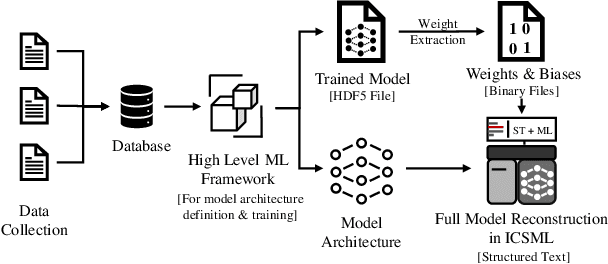
Industrial Control Systems (ICS) have played a catalytic role in enabling the 4th Industrial Revolution. ICS devices like Programmable Logic Controllers (PLCs), automate, monitor and control critical processes in industrial, energy and commercial environments. The convergence of traditional Operational Technology (OT) with Information Technology (IT) has opened a new and unique threat landscape. This has inspired defense research that focuses heavily on Machine Learning (ML) based anomaly detection methods that run on external IT hardware which means an increase in costs and the further expansion of the threat landscape. To remove this requirement, we introduce the ICS Machine Learning inference framework (ICSML) which enables the execution of ML models natively on the PLC. ICSML is implemented in IEC 61131-3 code and works around the limitations imposed by the domain-specific languages, providing a complete set of components for the creation of fully fledged ML models in a way similar to established ML frameworks. We then demonstrate a complete end-to-end methodology for creating ICS ML models using an external framework for training and ICSML for the PLC implementation. To evaluate our contributions we run a series of benchmarks studying memory and performance and compare our solution to the TFLite inference framework. Finally, to demonstrate the abilities of ICSML and to verify its non-intrusive nature, we develop and evaluate a case study of a real defense for process aware attacks against a Multi Stage Flash (MSF) desalination plant.
Joint Information Preservation for Heterogeneous Domain Adaptation
May 22, 2019
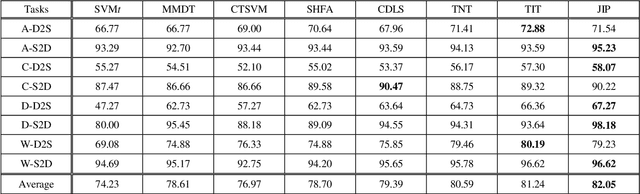
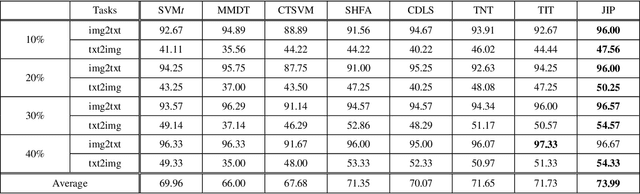
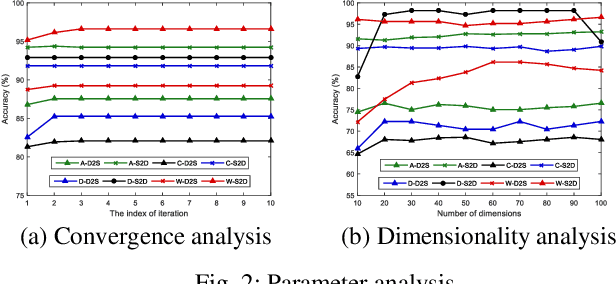
Domain adaptation aims to assist the modeling tasks of the target domain with knowledge of the source domain. The two domains often lie in different feature spaces due to diverse data collection methods, which leads to the more challenging task of heterogeneous domain adaptation (HDA). A core issue of HDA is how to preserve the information of the original data during adaptation. In this paper, we propose a joint information preservation method to deal with the problem. The method preserves the information of the original data from two aspects. On the one hand, although paired samples often exist between the two domains of the HDA, current algorithms do not utilize such information sufficiently. The proposed method preserves the paired information by maximizing the correlation of the paired samples in the shared subspace. On the other hand, the proposed method improves the strategy of preserving the structural information of the original data, where the local and global structural information are preserved simultaneously. Finally, the joint information preservation is integrated by distribution matching. Experimental results show the superiority of the proposed method over the state-of-the-art HDA algorithms.
Differential Modulation in Massive MIMO With Low-Resolution ADCs
Nov 12, 2021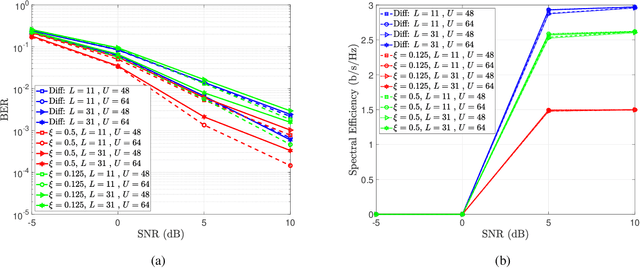
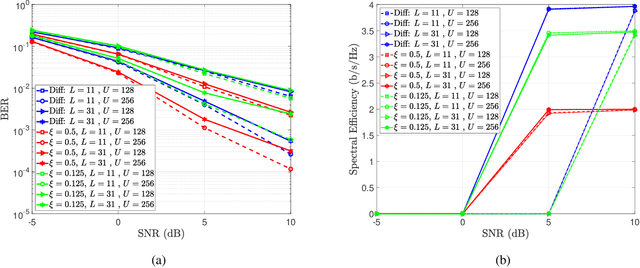
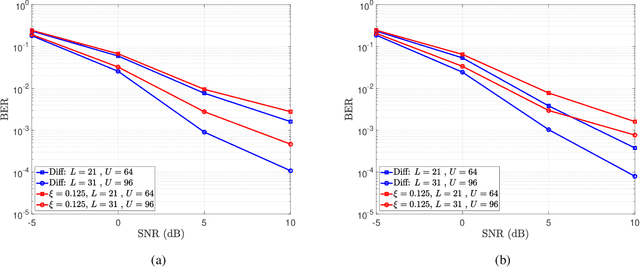
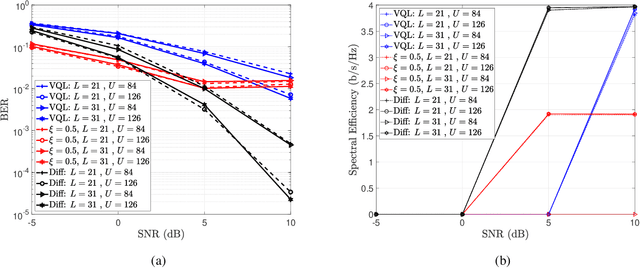
In this paper, we present a differential modulation and detection scheme for use in the uplink of a system with a large number of antennas at the base station, each equipped with low-resolution analog-to-digital converters (ADCs). We derive an expression for the maximum likelihood (ML) detector of a differentially encoded phase information symbol received by a base station operating in the low-resolution ADC regime. We also present an equal performing reduced complexity receiver for detecting the phase information. To increase the supported data rate, we also present a maximum likelihood expression to detect differential amplitude phase shift keying symbols with low-resolution ADCs. We note that the derived detectors are unable to detect the amplitude information. To overcome this limitation, we use the Bussgang Theorem and the Central Limit Theorem (CLT) to develop two detectors capable of detecting the amplitude information. We numerically show that while the first amplitude detector requires multiple quantization bits for acceptable performance, similar performance can be achieved using one-bit ADCs by grouping the receive antennas and employing variable quantization levels (VQL) across distinct antenna groups. We validate the performance of the proposed detectors through simulations and show a comparison with corresponding coherent detectors. Finally, we present a complexity analysis of the proposed low-resolution differential detectors
An Inference Approach To Question Answering Over Knowledge Graphs
Dec 21, 2021
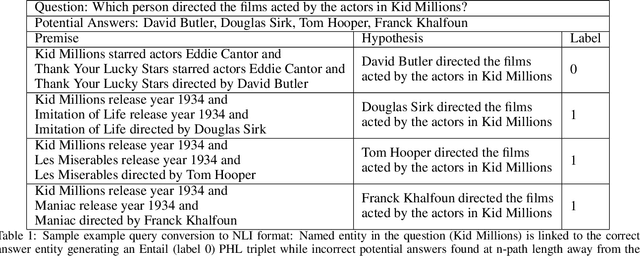
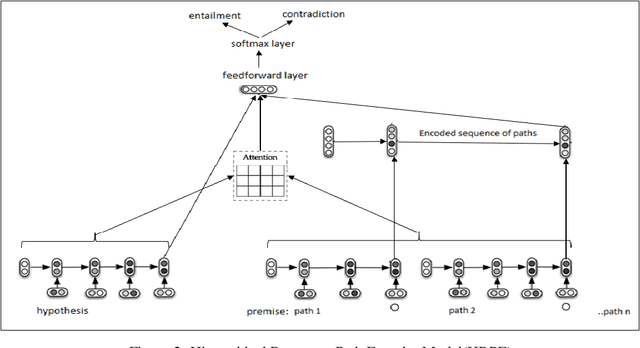
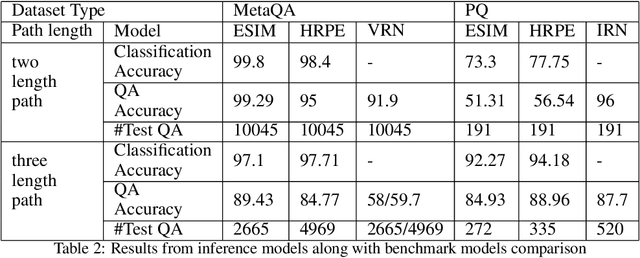
Knowledge Graphs (KG) act as a great tool for holding distilled information from large natural language text corpora. The problem of natural language querying over knowledge graphs is essential for the human consumption of this information. This problem is typically addressed by converting the natural language query to a structured query and then firing the structured query on the KG. Direct answering models over knowledge graphs in literature are very few. The query conversion models and direct models both require specific training data pertaining to the domain of the knowledge graph. In this work, we convert the problem of natural language querying over knowledge graphs to an inference problem over premise-hypothesis pairs. Using trained deep learning models for the converted proxy inferencing problem, we provide the solution for the original natural language querying problem. Our method achieves over 90% accuracy on MetaQA dataset, beating the existing state-of-the-art. We also propose a model for inferencing called Hierarchical Recurrent Path Encoder(HRPE). The inferencing models can be fine-tuned to be used across domains with less training data. Our approach does not require large domain-specific training data for querying on new knowledge graphs from different domains.
Deep Graph Learning for Spatially-Varying Indoor Lighting Prediction
Feb 13, 2022
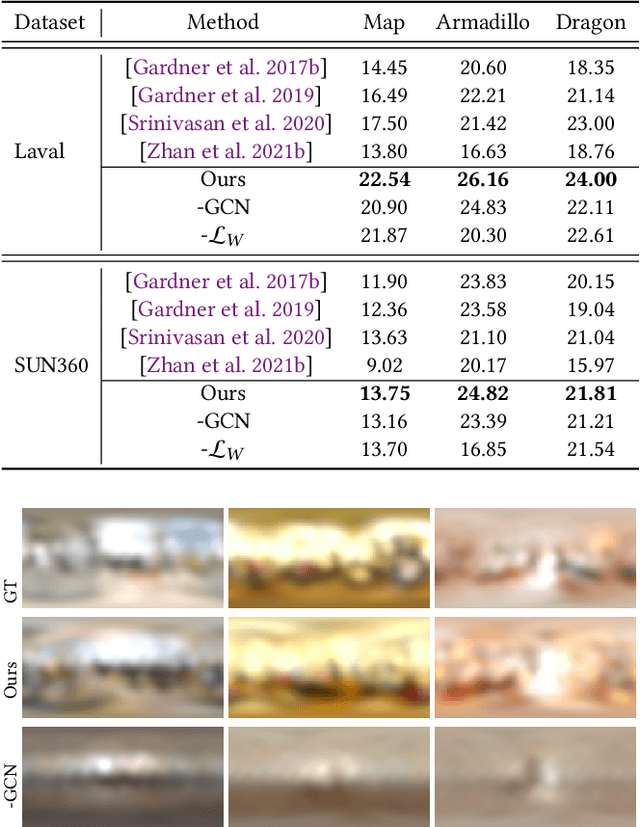


Lighting prediction from a single image is becoming increasingly important in many vision and augmented reality (AR) applications in which shading and shadow consistency between virtual and real objects should be guaranteed. However, this is a notoriously ill-posed problem, especially for indoor scenarios, because of the complexity of indoor luminaires and the limited information involved in 2D images. In this paper, we propose a graph learning-based framework for indoor lighting estimation. At its core is a new lighting model (dubbed DSGLight) based on depth-augmented Spherical Gaussians (SG) and a Graph Convolutional Network (GCN) that infers the new lighting representation from a single LDR image of limited field-of-view. Our lighting model builds 128 evenly distributed SGs over the indoor panorama, where each SG encoding the lighting and the depth around that node. The proposed GCN then learns the mapping from the input image to DSGLight. Compared with existing lighting models, our DSGLight encodes both direct lighting and indirect environmental lighting more faithfully and compactly. It also makes network training and inference more stable. The estimated depth distribution enables temporally stable shading and shadows under spatially-varying lighting. Through thorough experiments, we show that our method obviously outperforms existing methods both qualitatively and quantitatively.
Adaptive Data Analysis with Correlated Observations
Jan 21, 2022The vast majority of the work on adaptive data analysis focuses on the case where the samples in the dataset are independent. Several approaches and tools have been successfully applied in this context, such as differential privacy, max-information, compression arguments, and more. The situation is far less well-understood without the independence assumption. We embark on a systematic study of the possibilities of adaptive data analysis with correlated observations. First, we show that, in some cases, differential privacy guarantees generalization even when there are dependencies within the sample, which we quantify using a notion we call Gibbs-dependence. We complement this result with a tight negative example. Second, we show that the connection between transcript-compression and adaptive data analysis can be extended to the non-iid setting.
Non-Coherent MIMO-OFDM Uplink empowered by the Spatial Diversity in Reflecting Surfaces
Feb 04, 2022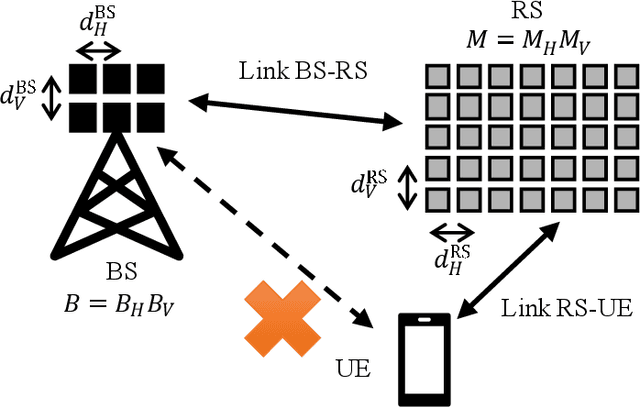
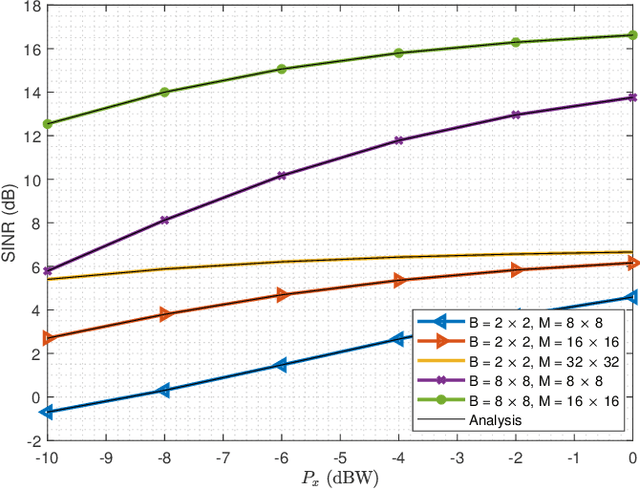
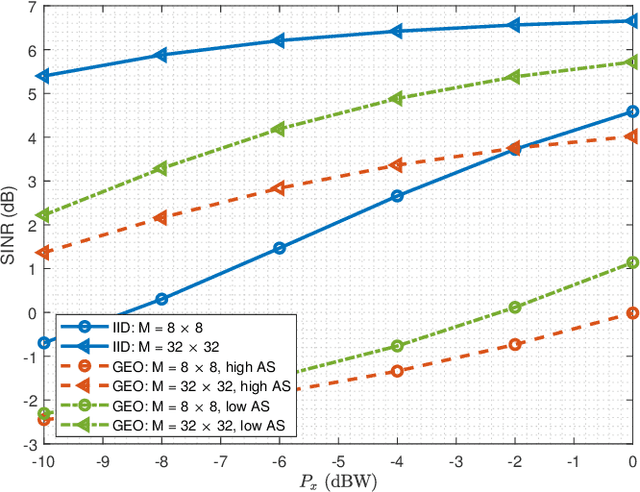
Reflecting Surfaces (RSs) are being lately envisioned as an energy efficient solution capable of enhancing the signal coverage in cases where obstacles block the direct communication from Base Stations (BSs), especially at high frequency bands due to attenuation loss increase. In the current literature, wireless communications via RSs are exclusively based on traditional coherent demodulation, which necessitates the estimation of accurate Channel State Information (CSI). However, this requirement results in an increased overhead, especially in time-varying channels, which reduces the resources that can be used for data communication. In this paper, we consider the uplink between a single-antenna user and a multi-antenna BS and present a novel RS-empowered Orthogonal Frequency Division Multiplexing (OFDM) communication system based on the differential phase shift keying, which is suitable for high noise and/or mobility scenarios. As a benchmark, analytical expressions for the Signal-to-Interference and Noise Ratio (SINR) of the proposed system are presented. Our extensive simulation results verify the accuracy of the presented analysis and showcase the performance and superiority of the proposed system over coherent demodulation.
Deep Feature based Cross-slide Registration
Feb 27, 2022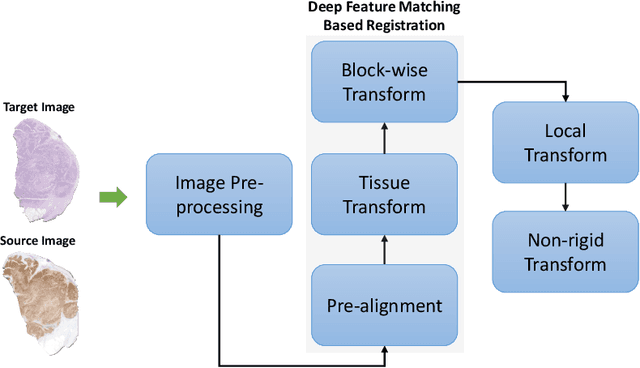
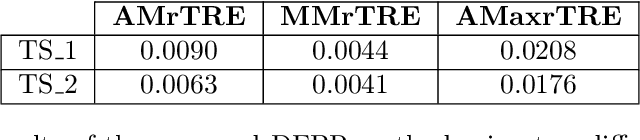
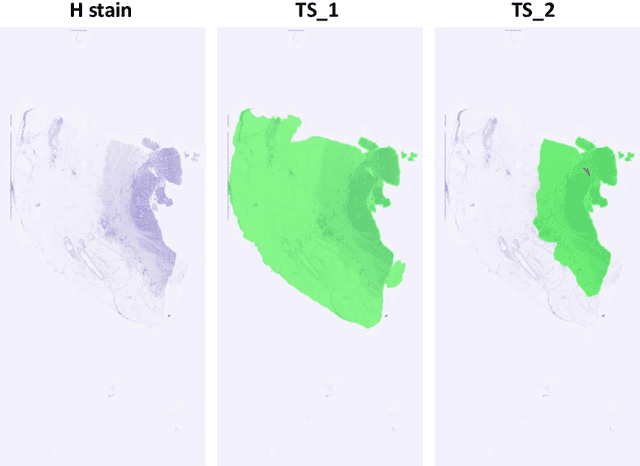
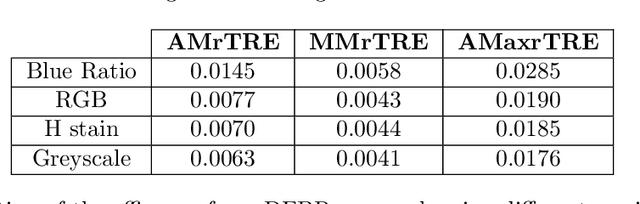
Cross-slide image analysis provides additional information by analysing the expression of different biomarkers as compared to a single slide analysis. Slides stained with different biomarkers are analysed side by side which may reveal unknown relations between the different biomarkers. During the slide preparation, a tissue section may be placed at an arbitrary orientation as compared to other sections of the same tissue block. The problem is compounded by the fact that tissue contents are likely to change from one section to the next and there may be unique artefacts on some of the slides. This makes registration of each section to a reference section of the same tissue block an important pre-requisite task before any cross-slide analysis. We propose a deep feature based registration (DFBR) method which utilises data-driven features to estimate the rigid transformation. We adopted a multi-stage strategy for improving the quality of registration. We also developed a visualisation tool to view registered pairs of WSIs at different magnifications. With the help of this tool, one can apply a transformation on the fly without the need to generate transformed source WSI in a pyramidal form. We compared the performance of data-driven features with that of hand-crafted features on the COMET dataset. Our approach can align the images with low registration errors. Generally, the success of non-rigid registration is dependent on the quality of rigid registration. To evaluate the efficacy of the DFBR method, the first two steps of the ANHIR winner's framework are replaced with our DFBR to register challenge provided image pairs. The modified framework produce comparable results to that of challenge winning team.