 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Robust Visual Sampling Model Inspired by Receptive Field
Jan 04, 2022
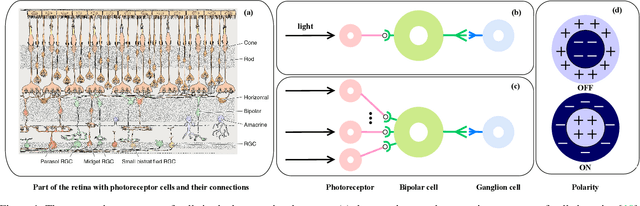
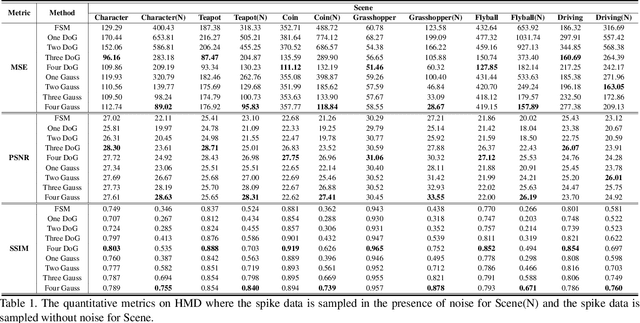
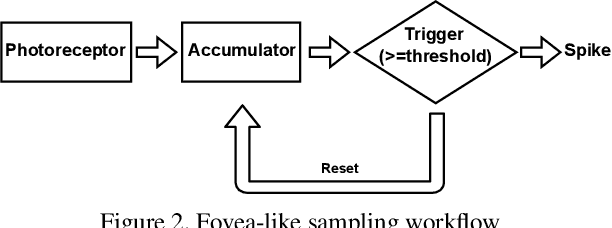

Spike camera mimicking the retina fovea can report per-pixel luminance intensity accumulation by firing spikes. As a bio-inspired vision sensor with high temporal resolution, it has a huge potential for computer vision. However, the sampling model in current Spike camera is so susceptible to quantization and noise that it cannot capture the texture details of objects effectively. In this work, a robust visual sampling model inspired by receptive field (RVSM) is proposed where wavelet filter generated by difference of Gaussian (DoG) and Gaussian filter are used to simulate receptive field. Using corresponding method similar to inverse wavelet transform, spike data from RVSM can be converted into images. To test the performance, we also propose a high-speed motion spike dataset (HMD) including a variety of motion scenes. By comparing reconstructed images in HMD, we find RVSM can improve the ability of capturing information of Spike camera greatly. More importantly, due to mimicking receptive field mechanism to collect regional information, RVSM can filter high intensity noise effectively and improves the problem that Spike camera is sensitive to noise largely. Besides, due to the strong generalization of sampling structure, RVSM is also suitable for other neuromorphic vision sensor. Above experiments are finished in a Spike camera simulator.
Exploiting long-term temporal dynamics for video captioning
Feb 22, 2022
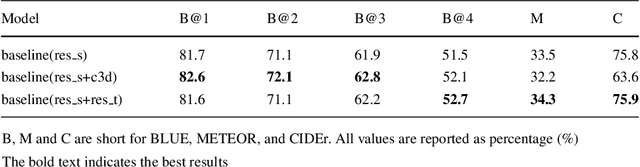
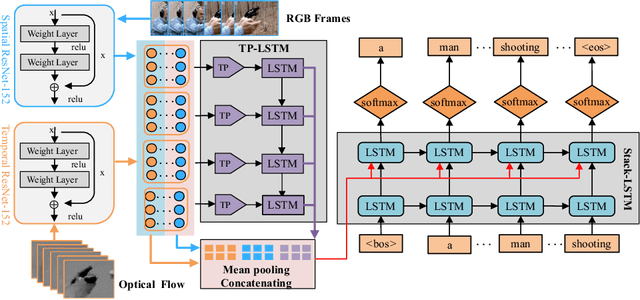
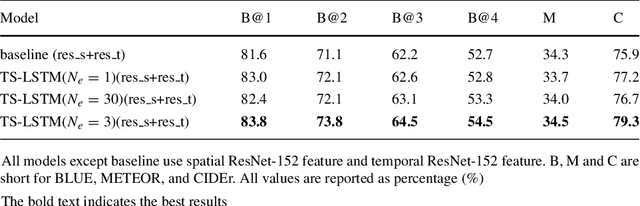
Automatically describing videos with natural language is a fundamental challenge for computer vision and natural language processing. Recently, progress in this problem has been achieved through two steps: 1) employing 2-D and/or 3-D Convolutional Neural Networks (CNNs) (e.g. VGG, ResNet or C3D) to extract spatial and/or temporal features to encode video contents; and 2) applying Recurrent Neural Networks (RNNs) to generate sentences to describe events in videos. Temporal attention-based model has gained much progress by considering the importance of each video frame. However, for a long video, especially for a video which consists of a set of sub-events, we should discover and leverage the importance of each sub-shot instead of each frame. In this paper, we propose a novel approach, namely temporal and spatial LSTM (TS-LSTM), which systematically exploits spatial and temporal dynamics within video sequences. In TS-LSTM, a temporal pooling LSTM (TP-LSTM) is designed to incorporate both spatial and temporal information to extract long-term temporal dynamics within video sub-shots; and a stacked LSTM is introduced to generate a list of words to describe the video. Experimental results obtained in two public video captioning benchmarks indicate that our TS-LSTM outperforms the state-of-the-art methods.
A Data Augmentation Method for Fully Automatic Brain Tumor Segmentation
Feb 18, 2022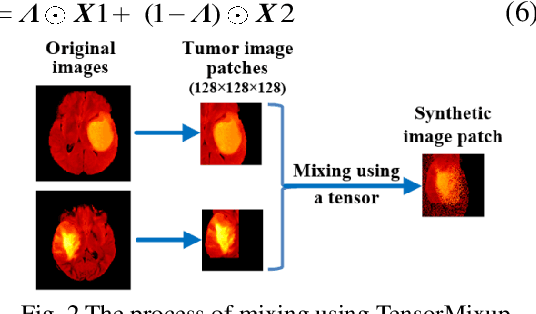

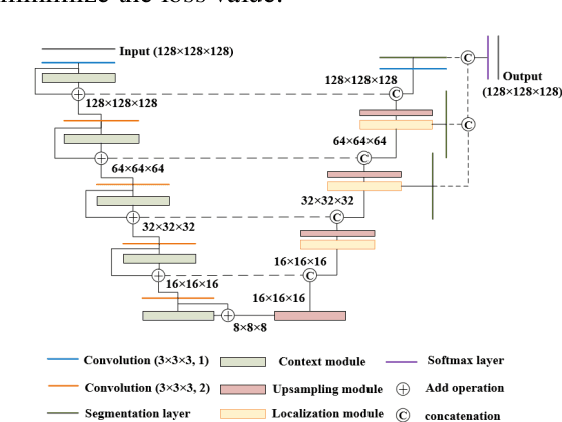
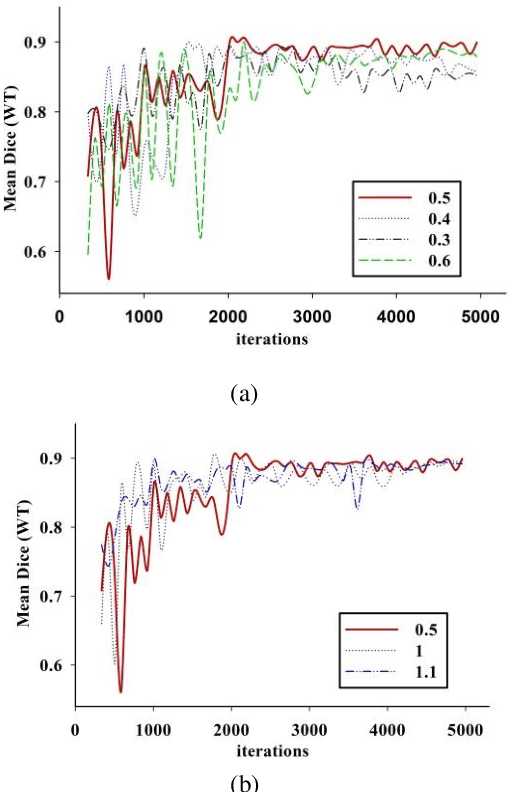
Automatic segmentation of glioma and its subregions is of great significance for diagnosis, treatment and monitoring of disease. In this paper, an augmentation method, called TensorMixup, was proposed and applied to the three dimensional U-Net architecture for brain tumor segmentation. The main ideas included that first, two image patches with size of 128 in three dimensions were selected according to glioma information of ground truth labels from the magnetic resonance imaging data of any two patients with the same modality. Next, a tensor in which all elements were independently sampled from Beta distribution was used to mix the image patches. Then the tensor was mapped to a matrix which was used to mix the one-hot encoded labels of the above image patches. Therefore, a new image and its one-hot encoded label were synthesized. Finally, the new data was used to train the model which could be used to segment glioma. The experimental results show that the mean accuracy of Dice scores are 91.32%, 85.67%, and 82.20% respectively on the whole tumor, tumor core, and enhancing tumor segmentation, which proves that the proposed TensorMixup is feasible and effective for brain tumor segmentation.
Pop Quiz! Can a Large Language Model Help With Reverse Engineering?
Feb 02, 2022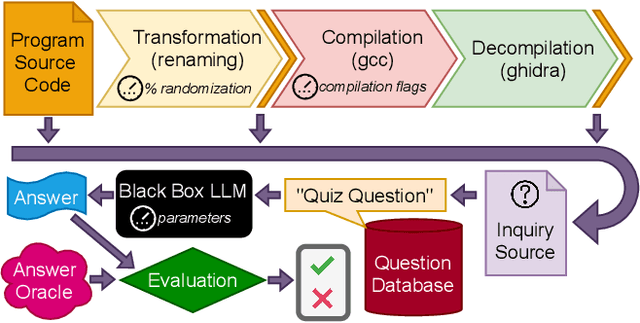
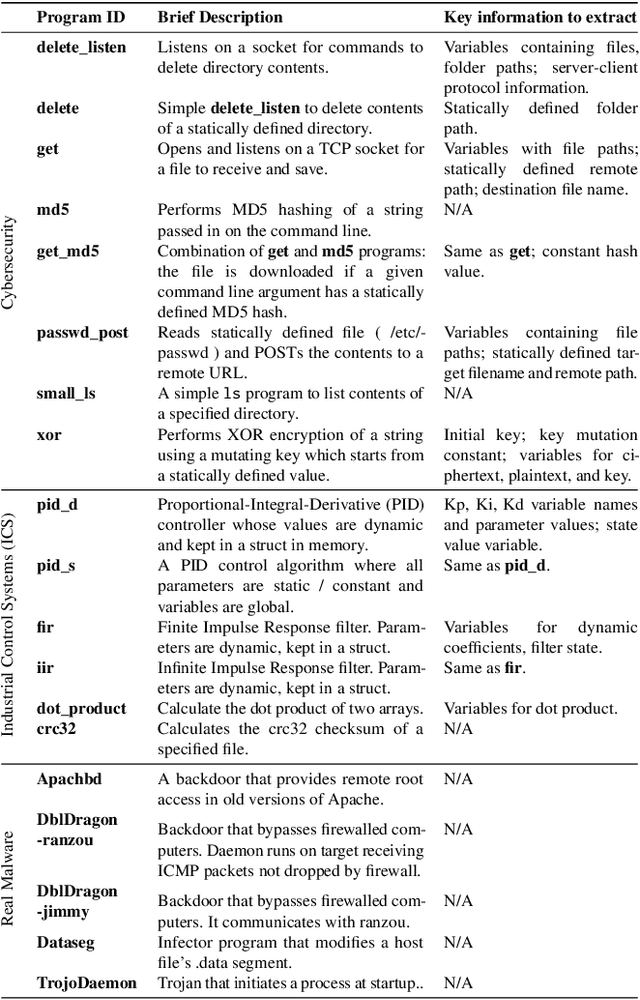

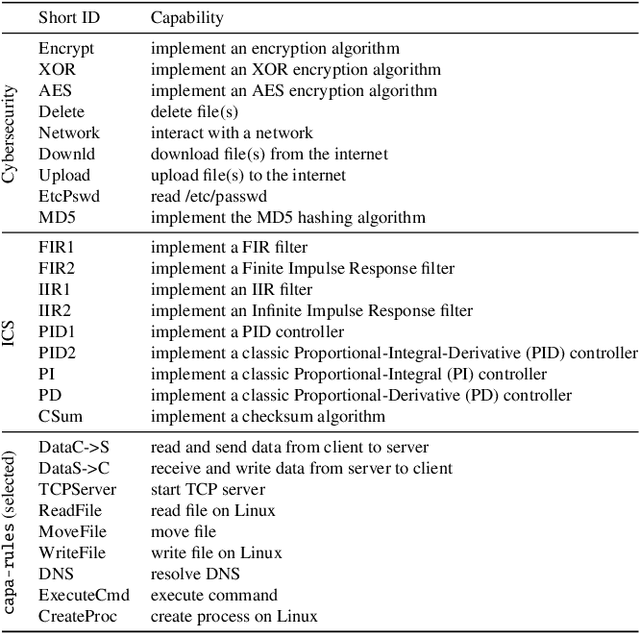
Large language models (such as OpenAI's Codex) have demonstrated impressive zero-shot multi-task capabilities in the software domain, including code explanation. In this work, we examine if this ability can be used to help with reverse engineering. Specifically, we investigate prompting Codex to identify the purpose, capabilities, and important variable names or values from code, even when the code is produced through decompilation. Alongside an examination of the model's responses in answering open-ended questions, we devise a true/false quiz framework to characterize the performance of the language model. We present an extensive quantitative analysis of the measured performance of the language model on a set of program purpose identification and information extraction tasks: of the 136,260 questions we posed, it answered 72,754 correctly. A key takeaway is that while promising, LLMs are not yet ready for zero-shot reverse engineering.
Dual Lottery Ticket Hypothesis
Mar 08, 2022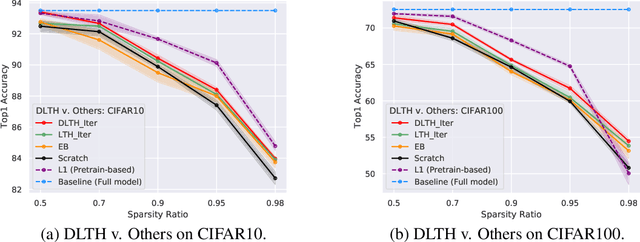

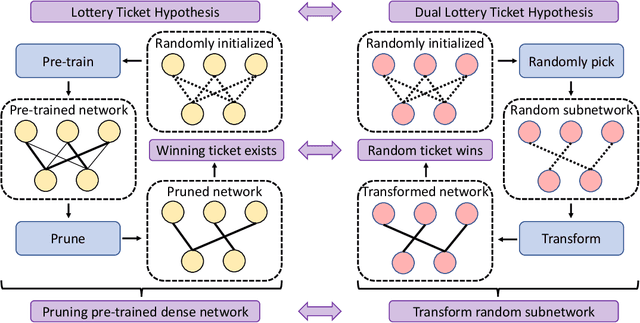
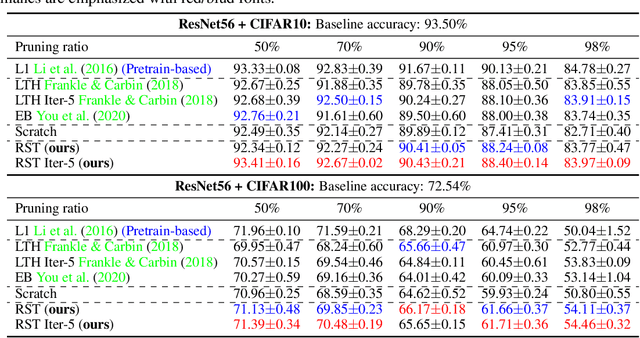
Fully exploiting the learning capacity of neural networks requires overparameterized dense networks. On the other side, directly training sparse neural networks typically results in unsatisfactory performance. Lottery Ticket Hypothesis (LTH) provides a novel view to investigate sparse network training and maintain its capacity. Concretely, it claims there exist winning tickets from a randomly initialized network found by iterative magnitude pruning and preserving promising trainability (or we say being in trainable condition). In this work, we regard the winning ticket from LTH as the subnetwork which is in trainable condition and its performance as our benchmark, then go from a complementary direction to articulate the Dual Lottery Ticket Hypothesis (DLTH): Randomly selected subnetworks from a randomly initialized dense network can be transformed into a trainable condition and achieve admirable performance compared with LTH -- random tickets in a given lottery pool can be transformed into winning tickets. Specifically, by using uniform-randomly selected subnetworks to represent the general cases, we propose a simple sparse network training strategy, Random Sparse Network Transformation (RST), to substantiate our DLTH. Concretely, we introduce a regularization term to borrow learning capacity and realize information extrusion from the weights which will be masked. After finishing the transformation for the randomly selected subnetworks, we conduct the regular finetuning to evaluate the model using fair comparisons with LTH and other strong baselines. Extensive experiments on several public datasets and comparisons with competitive approaches validate our DLTH as well as the effectiveness of the proposed model RST. Our work is expected to pave a way for inspiring new research directions of sparse network training in the future. Our code is available at https://github.com/yueb17/DLTH.
Ultra-Wideband Teach and Repeat
Feb 02, 2022Autonomously retracing a manually-taught path is desirable for many applications, and Teach and Repeat (T&R) algorithms present an approach that is suitable for long-range autonomy. In this paper, ultra-wideband (UWB) ranging-based T&R is proposed for vehicles with limited resources. By fixing single UWB transceivers at far-apart unknown locations in an indoor environment, a robot with 3 UWB transceivers builds a locally consistent map during the teach pass by fusing the range measurements under a custom ranging protocol with an on-board IMU and height measurements. The robot then uses information from the teach pass to retrace the same trajectory autonomously. The proposed ranging protocol and T&R algorithm are validated in simulation, where it is shown that the robot can successfully retrace the taught trajectory with sub-metre tracking error.
Fine-Grained Population Mobility Data-Based Community-Level COVID-19 Prediction Model
Feb 13, 2022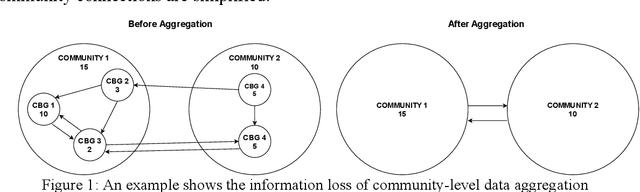
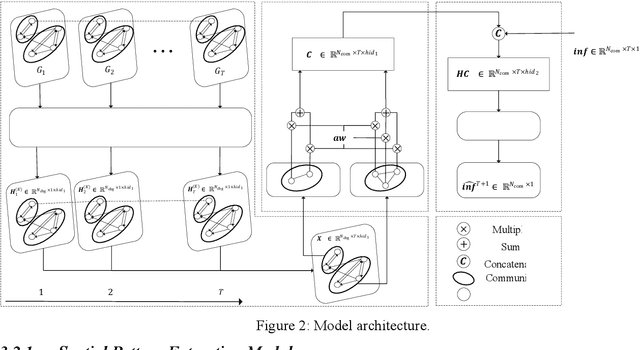
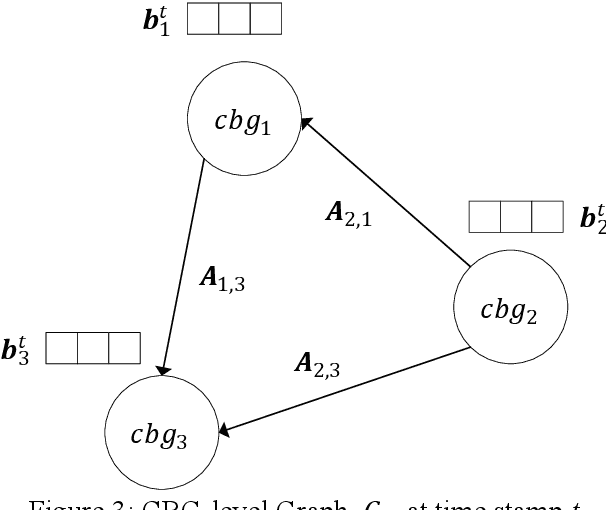
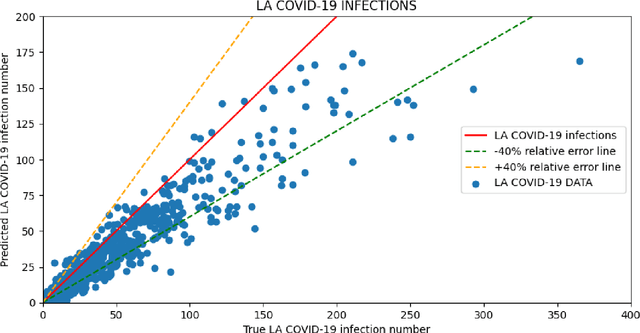
Predicting the number of infections in the anti-epidemic process is extremely beneficial to the government in developing anti-epidemic strategies, especially in fine-grained geographic units. Previous works focus on low spatial resolution prediction, e.g., county-level, and preprocess data to the same geographic level, which loses some useful information. In this paper, we propose a fine-grained population mobility data-based model (FGC-COVID) utilizing data of two geographic levels for community-level COVID-19 prediction. We use the population mobility data between Census Block Groups (CBGs), which is a finer-grained geographic level than community, to build the graph and capture the dependencies between CBGs using graph neural networks (GNNs). To mine as finer-grained patterns as possible for prediction, a spatial weighted aggregation module is introduced to aggregate the embeddings of CBGs to community level based on their geographic affiliation and spatial autocorrelation. Extensive experiments on 300 days LA city COVID-19 data indicate our model outperforms existing forecasting models on community-level COVID-19 prediction.
You only look 10647 times
Jan 16, 2022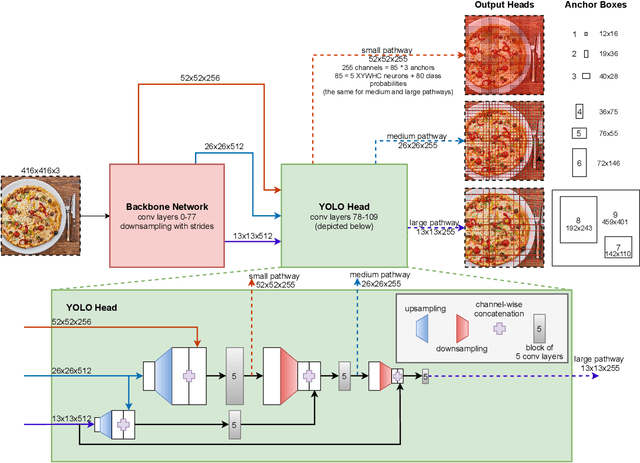



With this work we are explaining the "You Only Look Once" (YOLO) single-stage object detection approach as a parallel classification of 10647 fixed region proposals. We support this view by showing that each of YOLOs output pixel is attentive to a specific sub-region of previous layers, comparable to a local region proposal. This understanding reduces the conceptual gap between YOLO-like single-stage object detection models, RCNN-like two-stage region proposal based models, and ResNet-like image classification models. In addition, we created interactive exploration tools for a better visual understanding of the YOLO information processing streams: https://limchr.github.io/yolo_visualization
Reinforced Abstractive Summarization with Adaptive Length Controlling
Dec 17, 2021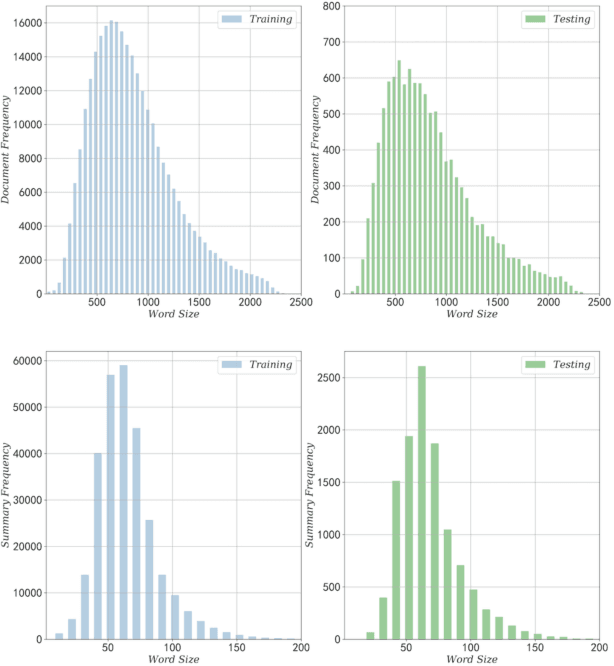

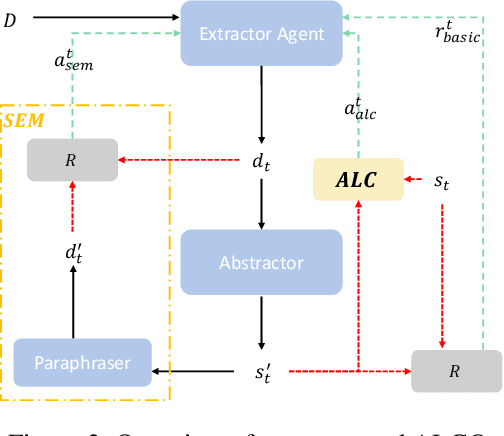
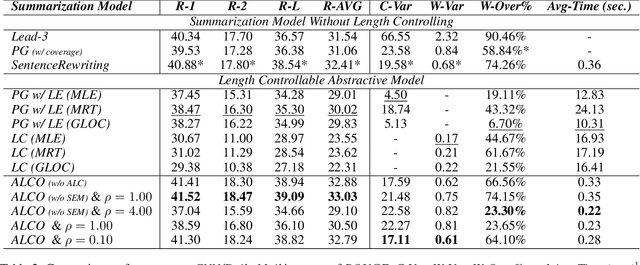
Document summarization, as a fundamental task in natural language generation, aims to generate a short and coherent summary for a given document. Controllable summarization, especially of the length, is an important issue for some practical applications, especially how to trade-off the length constraint and information integrity. In this paper, we propose an \textbf{A}daptive \textbf{L}ength \textbf{C}ontrolling \textbf{O}ptimization (\textbf{ALCO}) method to leverage two-stage abstractive summarization model via reinforcement learning. ALCO incorporates length constraint into the stage of sentence extraction to penalize the overlength extracted sentences. Meanwhile, a saliency estimation mechanism is designed to preserve the salient information in the generated sentences. A series of experiments have been conducted on a wildly-used benchmark dataset \textit{CNN/Daily Mail}. The results have shown that ALCO performs better than the popular baselines in terms of length controllability and content preservation.
Handling Imbalanced Datasets Through Optimum-Path Forest
Feb 17, 2022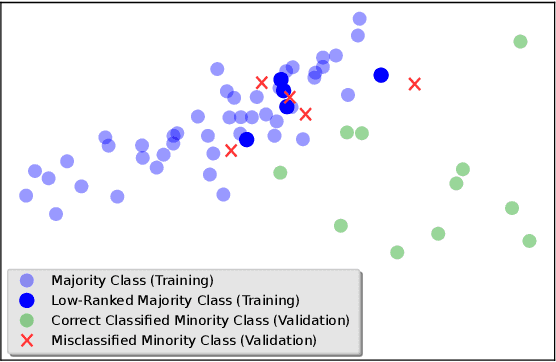
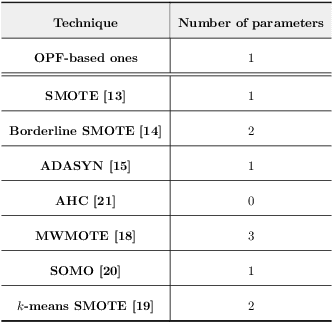
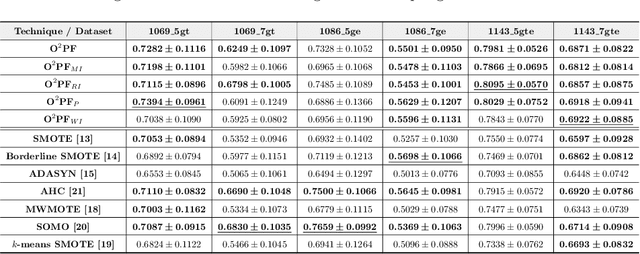
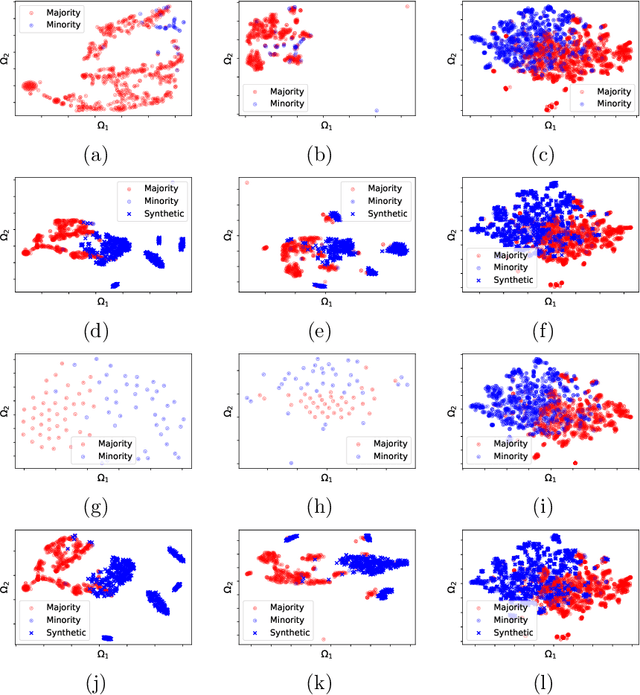
In the last decade, machine learning-based approaches became capable of performing a wide range of complex tasks sometimes better than humans, demanding a fraction of the time. Such an advance is partially due to the exponential growth in the amount of data available, which makes it possible to extract trustworthy real-world information from them. However, such data is generally imbalanced since some phenomena are more likely than others. Such a behavior yields considerable influence on the machine learning model's performance since it becomes biased on the more frequent data it receives. Despite the considerable amount of machine learning methods, a graph-based approach has attracted considerable notoriety due to the outstanding performance over many applications, i.e., the Optimum-Path Forest (OPF). In this paper, we propose three OPF-based strategies to deal with the imbalance problem: the $\text{O}^2$PF and the OPF-US, which are novel approaches for oversampling and undersampling, respectively, as well as a hybrid strategy combining both approaches. The paper also introduces a set of variants concerning the strategies mentioned above. Results compared against several state-of-the-art techniques over public and private datasets confirm the robustness of the proposed approaches.