 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Texture Characterization of Histopathologic Images Using Ecological Diversity Measures and Discrete Wavelet Transform
Feb 27, 2022

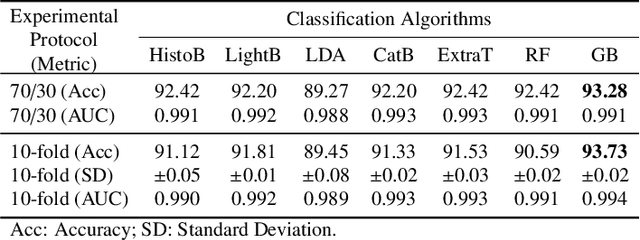
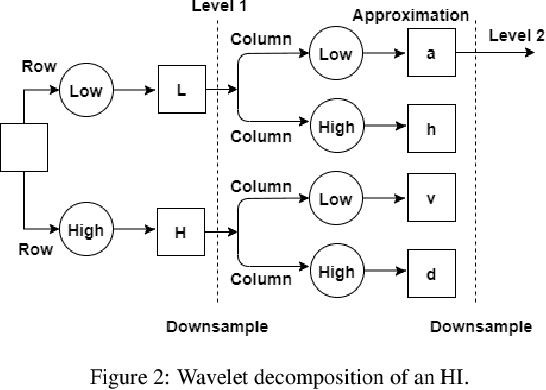
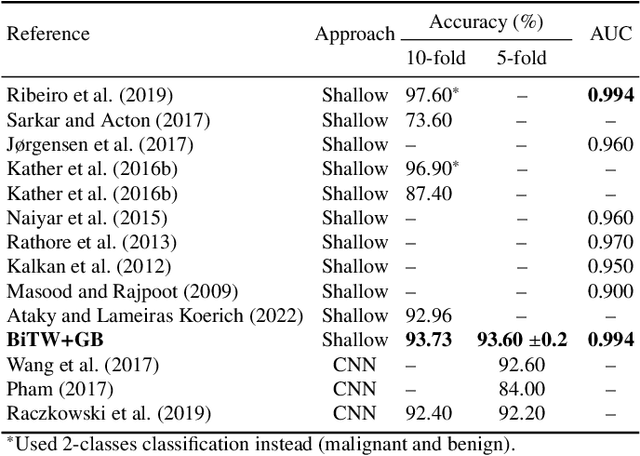
Breast cancer is a health problem that affects mainly the female population. An early detection increases the chances of effective treatment, improving the prognosis of the disease. In this regard, computational tools have been proposed to assist the specialist in interpreting the breast digital image exam, providing features for detecting and diagnosing tumors and cancerous cells. Nonetheless, detecting tumors with a high sensitivity rate and reducing the false positives rate is still challenging. Texture descriptors have been quite popular in medical image analysis, particularly in histopathologic images (HI), due to the variability of both the texture found in such images and the tissue appearance due to irregularity in the staining process. Such variability may exist depending on differences in staining protocol such as fixation, inconsistency in the staining condition, and reagents, either between laboratories or in the same laboratory. Textural feature extraction for quantifying HI information in a discriminant way is challenging given the distribution of intrinsic properties of such images forms a non-deterministic complex system. This paper proposes a method for characterizing texture across HIs with a considerable success rate. By employing ecological diversity measures and discrete wavelet transform, it is possible to quantify the intrinsic properties of such images with promising accuracy on two HI datasets compared with state-of-the-art methods.
Joint CNN and Transformer Network via weakly supervised Learning for efficient crowd counting
Mar 12, 2022

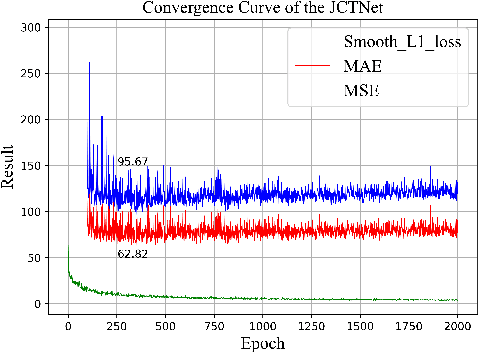
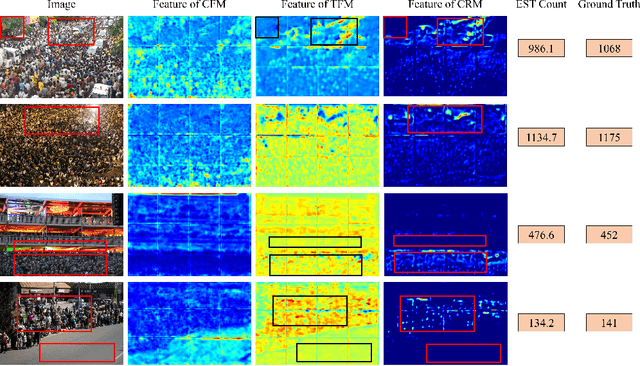
Currently, for crowd counting, the fully supervised methods via density map estimation are the mainstream research directions. However, such methods need location-level annotation of persons in an image, which is time-consuming and laborious. Therefore, the weakly supervised method just relying upon the count-level annotation is urgently needed. Since CNN is not suitable for modeling the global context and the interactions between image patches, crowd counting with weakly supervised learning via CNN generally can not show good performance. The weakly supervised model via Transformer was sequentially proposed to model the global context and learn contrast features. However, the transformer directly partitions the crowd images into a series of tokens, which may not be a good choice due to each pedestrian being an independent individual, and the parameter number of the network is very large. Hence, we propose a Joint CNN and Transformer Network (JCTNet) via weakly supervised learning for crowd counting in this paper. JCTNet consists of three parts: CNN feature extraction module (CFM), Transformer feature extraction module (TFM), and counting regression module (CRM). In particular, the CFM extracts crowd semantic information features, then sends their patch partitions to TRM for modeling global context, and CRM is used to predict the number of people. Extensive experiments and visualizations demonstrate that JCTNet can effectively focus on the crowd regions and obtain superior weakly supervised counting performance on five mainstream datasets. The number of parameters of the model can be reduced by about 67%~73% compared with the pure Transformer works. We also tried to explain the phenomenon that a model constrained only by count-level annotations can still focus on the crowd regions. We believe our work can promote further research in this field.
Controlling the Quality of Distillation in Response-Based Network Compression
Dec 19, 2021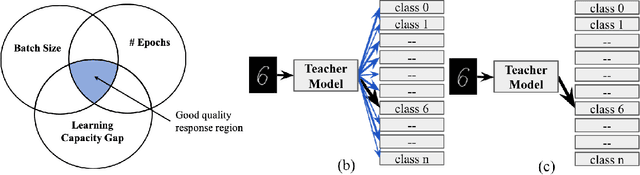


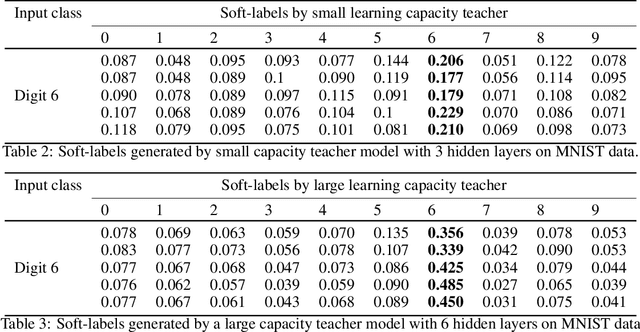
The performance of a distillation-based compressed network is governed by the quality of distillation. The reason for the suboptimal distillation of a large network (teacher) to a smaller network (student) is largely attributed to the gap in the learning capacities of given teacher-student pair. While it is hard to distill all the knowledge of a teacher, the quality of distillation can be controlled to a large extent to achieve better performance. Our experiments show that the quality of distillation is largely governed by the quality of teacher's response, which in turn is heavily affected by the presence of similarity information in its response. A well-trained large capacity teacher loses similarity information between classes in the process of learning fine-grained discriminative properties for classification. The absence of similarity information causes the distillation process to be reduced from one example-many class learning to one example-one class learning, thereby throttling the flow of diverse knowledge from the teacher. With the implicit assumption that only the instilled knowledge can be distilled, instead of focusing only on the knowledge distilling process, we scrutinize the knowledge inculcation process. We argue that for a given teacher-student pair, the quality of distillation can be improved by finding the sweet spot between batch size and number of epochs while training the teacher. We discuss the steps to find this sweet spot for better distillation. We also propose the distillation hypothesis to differentiate the behavior of the distillation process between knowledge distillation and regularization effect. We conduct all our experiments on three different datasets.
FMP: Toward Fair Graph Message Passing against Topology Bias
Feb 08, 2022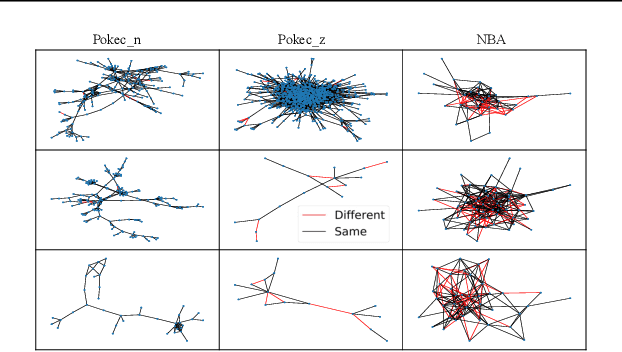

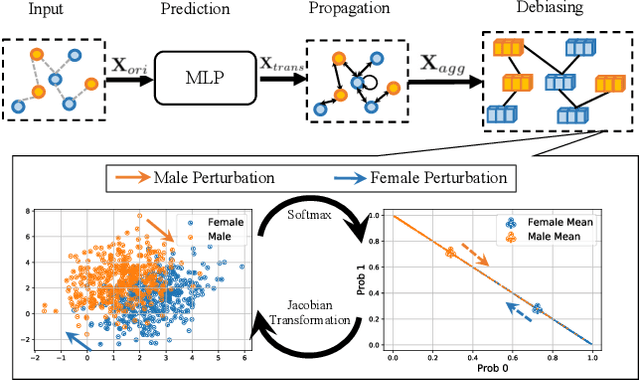

Despite recent advances in achieving fair representations and predictions through regularization, adversarial debiasing, and contrastive learning in graph neural networks (GNNs), the working mechanism (i.e., message passing) behind GNNs inducing unfairness issue remains unknown. In this work, we theoretically and experimentally demonstrate that representative aggregation in message-passing schemes accumulates bias in node representation due to topology bias induced by graph topology. Thus, a \textsf{F}air \textsf{M}essage \textsf{P}assing (FMP) scheme is proposed to aggregate useful information from neighbors but minimize the effect of topology bias in a unified framework considering graph smoothness and fairness objectives. The proposed FMP is effective, transparent, and compatible with back-propagation training. An acceleration approach on gradient calculation is also adopted to improve algorithm efficiency. Experiments on node classification tasks demonstrate that the proposed FMP outperforms the state-of-the-art baselines in effectively and efficiently mitigating bias on three real-world datasets.
On the Importance of Local Information in Transformer Based Models
Aug 13, 2020


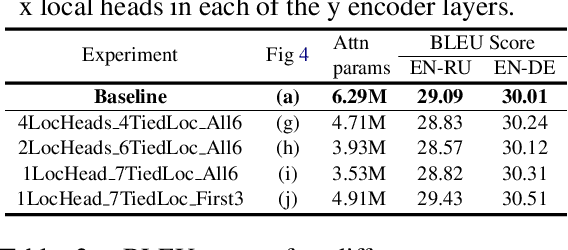
The self-attention module is a key component of Transformer-based models, wherein each token pays attention to every other token. Recent studies have shown that these heads exhibit syntactic, semantic, or local behaviour. Some studies have also identified promise in restricting this attention to be local, i.e., a token attending to other tokens only in a small neighbourhood around it. However, no conclusive evidence exists that such local attention alone is sufficient to achieve high accuracy on multiple NLP tasks. In this work, we systematically analyse the role of locality information in learnt models and contrast it with the role of syntactic information. More specifically, we first do a sensitivity analysis and show that, at every layer, the representation of a token is much more sensitive to tokens in a small neighborhood around it than to tokens which are syntactically related to it. We then define an attention bias metric to determine whether a head pays more attention to local tokens or to syntactically related tokens. We show that a larger fraction of heads have a locality bias as compared to a syntactic bias. Having established the importance of local attention heads, we train and evaluate models where varying fractions of the attention heads are constrained to be local. Such models would be more efficient as they would have fewer computations in the attention layer. We evaluate these models on 4 GLUE datasets (QQP, SST-2, MRPC, QNLI) and 2 MT datasets (En-De, En-Ru) and clearly demonstrate that such constrained models have comparable performance to the unconstrained models. Through this systematic evaluation we establish that attention in Transformer-based models can be constrained to be local without affecting performance.
Hyper-Convolutions via Implicit Kernels for Medical Imaging
Feb 06, 2022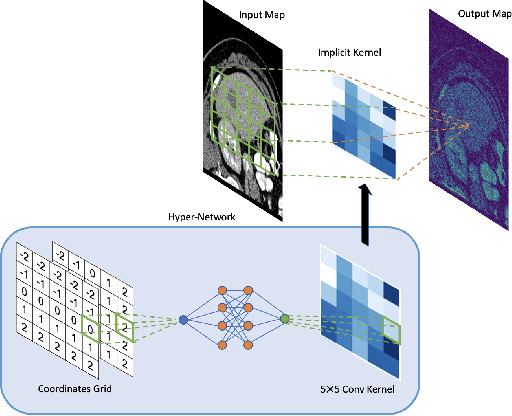
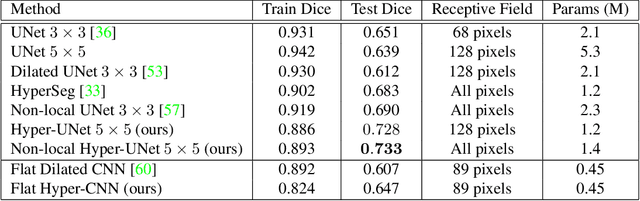
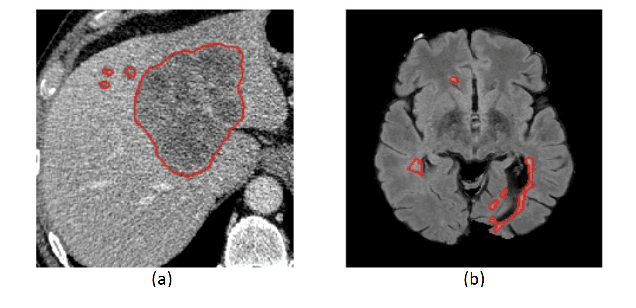
The convolutional neural network (CNN) is one of the most commonly used architectures for computer vision tasks. The key building block of a CNN is the convolutional kernel that aggregates information from the pixel neighborhood and shares weights across all pixels. A standard CNN's capacity, and thus its performance, is directly related to the number of learnable kernel weights, which is determined by the number of channels and the kernel size (support). In this paper, we present the \textit{hyper-convolution}, a novel building block that implicitly encodes the convolutional kernel using spatial coordinates. Hyper-convolutions decouple kernel size from the total number of learnable parameters, enabling a more flexible architecture design. We demonstrate in our experiments that replacing regular convolutions with hyper-convolutions can improve performance with less parameters, and increase robustness against noise. We provide our code here: \emph{https://github.com/tym002/Hyper-Convolution}
Optimality in Noisy Importance Sampling
Jan 07, 2022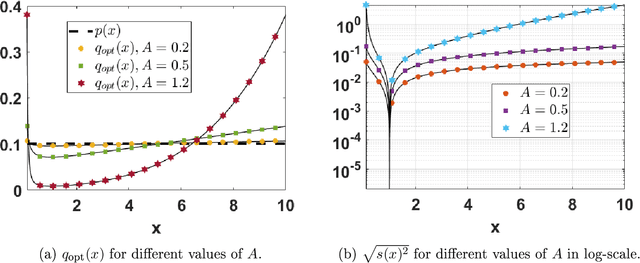
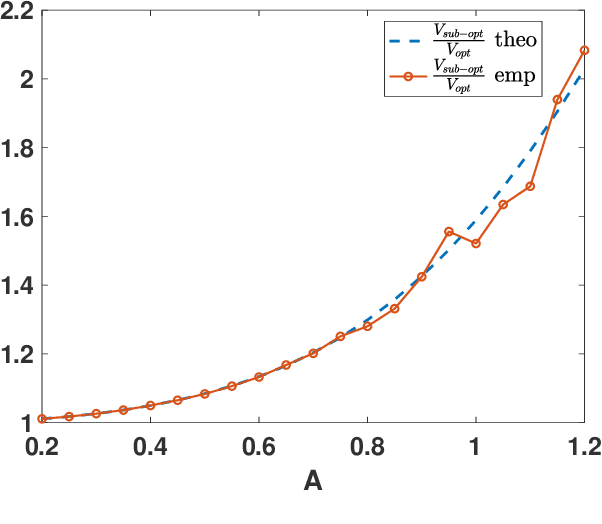
In this work, we analyze the noisy importance sampling (IS), i.e., IS working with noisy evaluations of the target density. We present the general framework and derive optimal proposal densities for noisy IS estimators. The optimal proposals incorporate the information of the variance of the noisy realizations, proposing points in regions where the noise power is higher. We also compare the use of the optimal proposals with previous optimality approaches considered in a noisy IS framework.
Generalized Difference Coder: A Novel Conditional Autoencoder Structure for Video Compression
Dec 15, 2021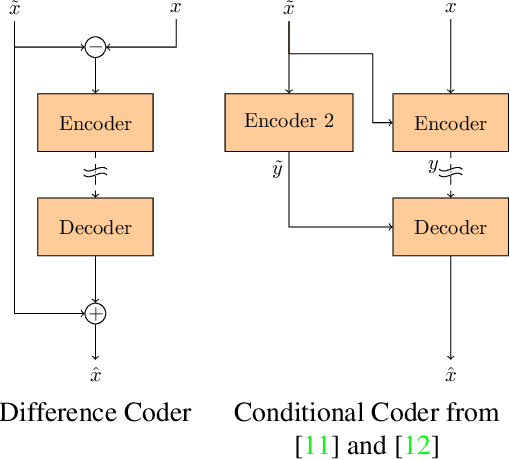
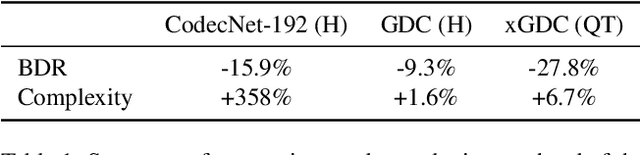
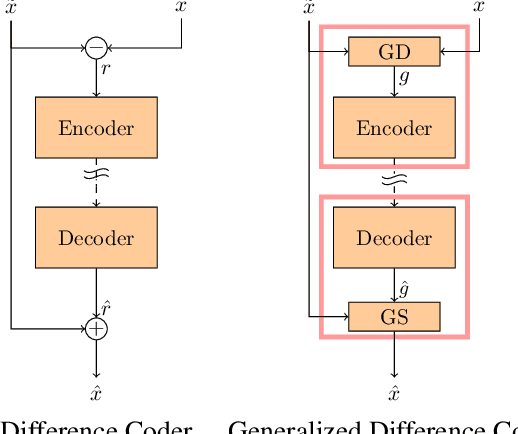
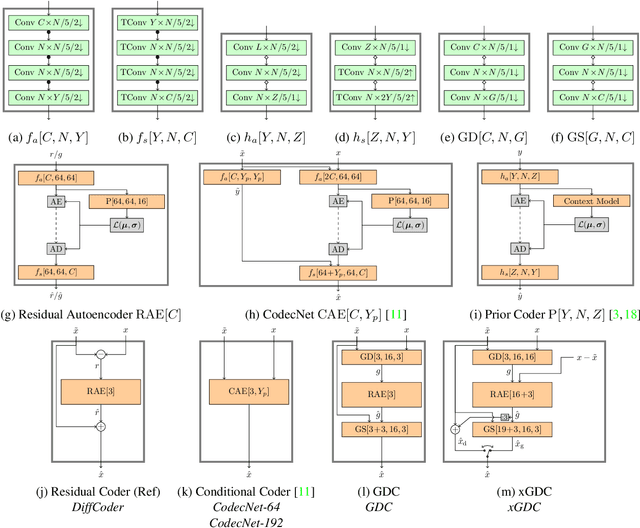
Motion compensated inter prediction is a common component of all video coders. The concept was established in traditional hybrid coding and successfully transferred to learning-based video compression. To compress the residual signal after prediction, usually the difference of the two signals is compressed using a standard autoencoder. However, information theory tells us that a general conditional coder is more efficient. In this paper, we provide a solid foundation based on information theory and Shannon entropy to show the potentials but also the limits of conditional coding. Building on those results, we then propose the generalized difference coder, a special case of a conditional coder designed to avoid limiting bottlenecks. With this coder, we are able to achieve average rate savings of 27.8% compared to a standard autoencoder, by only adding a moderate complexity overhead of less than 7%.
Summarising and Comparing Agent Dynamics with Contrastive Spatiotemporal Abstraction
Jan 17, 2022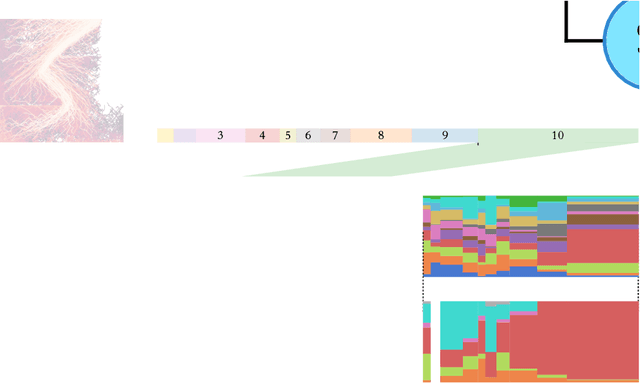
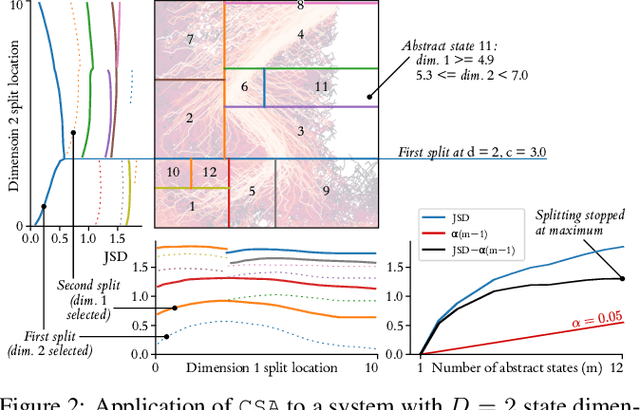
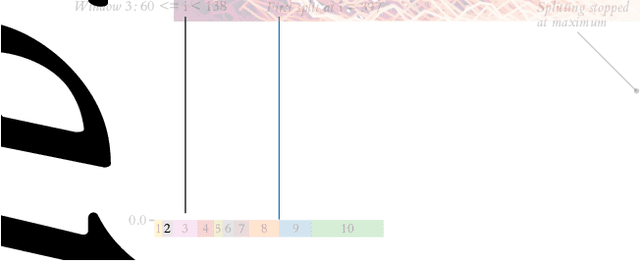
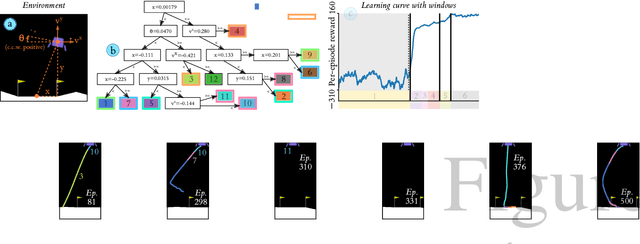
We introduce a data-driven, model-agnostic technique for generating a human-interpretable summary of the salient points of contrast within an evolving dynamical system, such as the learning process of a control agent. It involves the aggregation of transition data along both spatial and temporal dimensions according to an information-theoretic divergence measure. A practical algorithm is outlined for continuous state spaces, and deployed to summarise the learning histories of deep reinforcement learning agents with the aid of graphical and textual communication methods. We expect our method to be complementary to existing techniques in the realm of agent interpretability.
PerFED-GAN: Personalized Federated Learning via Generative Adversarial Networks
Feb 18, 2022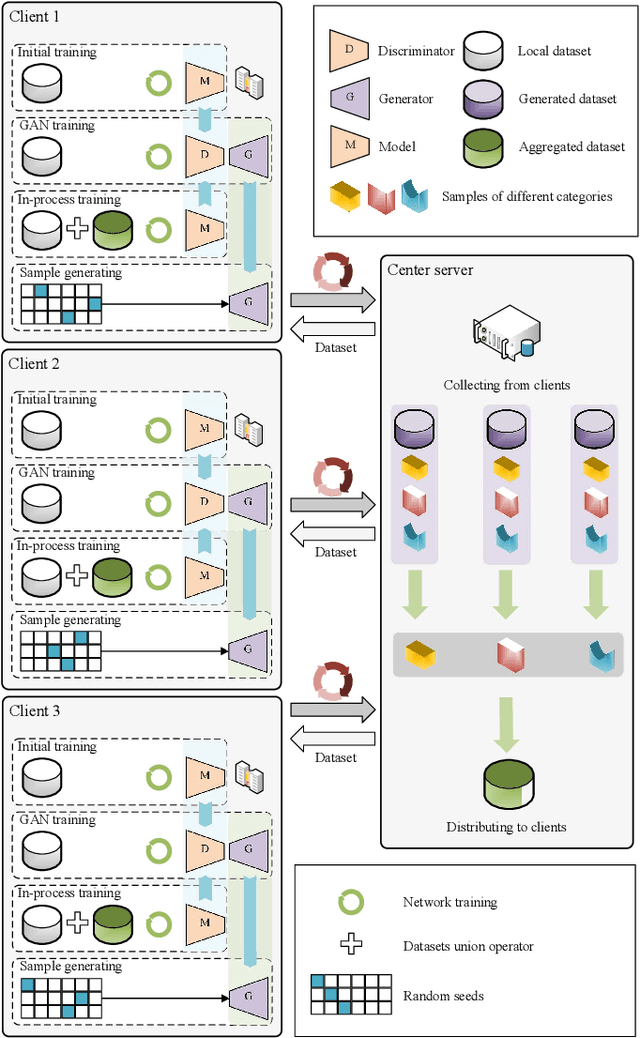
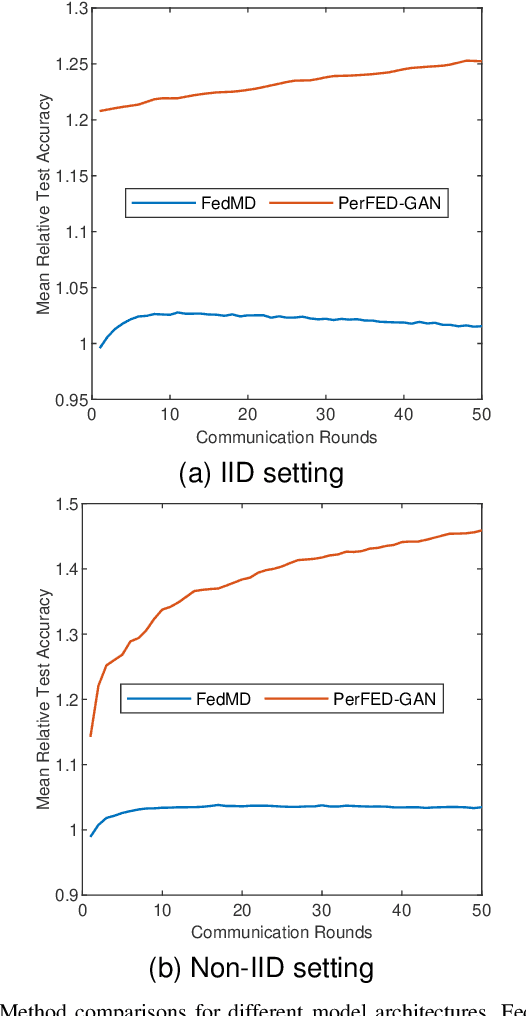
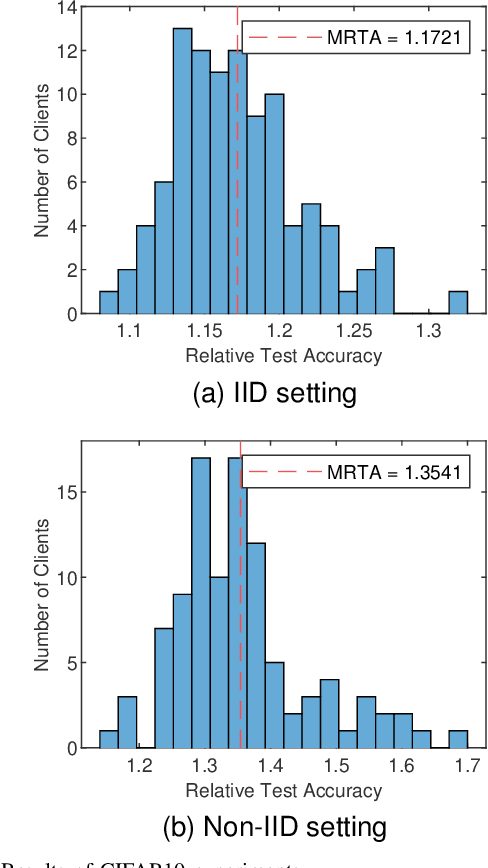
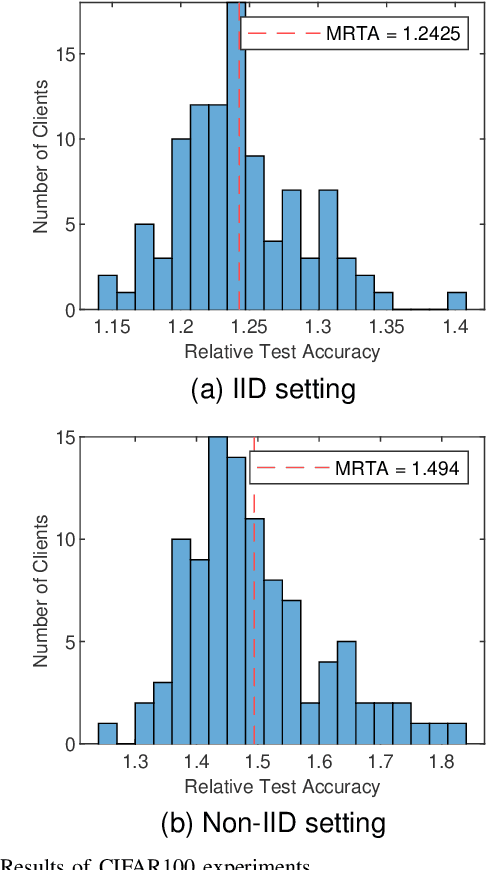
Federated learning is gaining popularity as a distributed machine learning method that can be used to deploy AI-dependent IoT applications while protecting client data privacy and security. Due to the differences of clients, a single global model may not perform well on all clients, so the personalized federated learning method, which trains a personalized model for each client that better suits its individual needs, becomes a research hotspot. Most personalized federated learning research, however, focuses on data heterogeneity while ignoring the need for model architecture heterogeneity. Most existing federated learning methods uniformly set the model architecture of all clients participating in federated learning, which is inconvenient for each client's individual model and local data distribution requirements, and also increases the risk of client model leakage. This paper proposes a federated learning method based on co-training and generative adversarial networks(GANs) that allows each client to design its own model to participate in federated learning training independently without sharing any model architecture or parameter information with other clients or a center. In our experiments, the proposed method outperforms the existing methods in mean test accuracy by 42% when the client's model architecture and data distribution vary significantly.