 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neural Grapheme-to-Phoneme Conversion with Pre-trained Grapheme Models
Jan 26, 2022
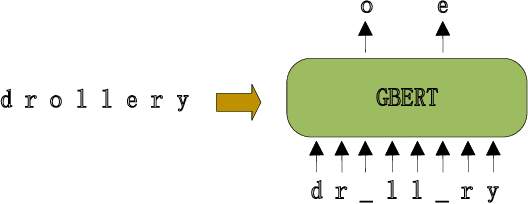

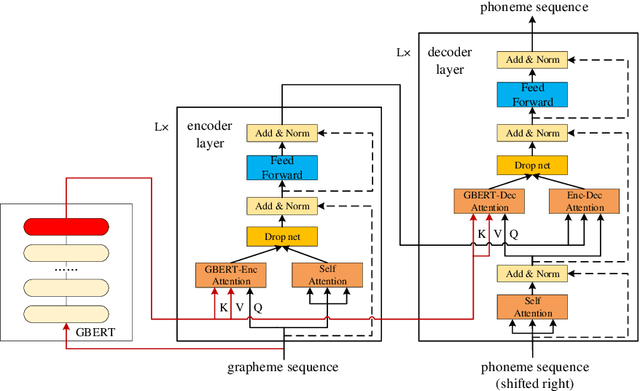
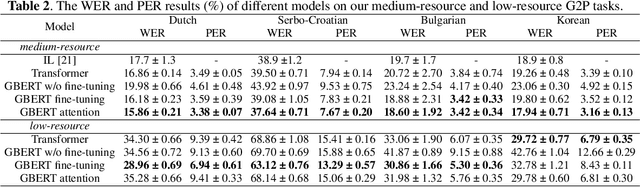
Neural network models have achieved state-of-the-art performance on grapheme-to-phoneme (G2P) conversion. However, their performance relies on large-scale pronunciation dictionaries, which may not be available for a lot of languages. Inspired by the success of the pre-trained language model BERT, this paper proposes a pre-trained grapheme model called grapheme BERT (GBERT), which is built by self-supervised training on a large, language-specific word list with only grapheme information. Furthermore, two approaches are developed to incorporate GBERT into the state-of-the-art Transformer-based G2P model, i.e., fine-tuning GBERT or fusing GBERT into the Transformer model by attention. Experimental results on the Dutch, Serbo-Croatian, Bulgarian and Korean datasets of the SIGMORPHON 2021 G2P task confirm the effectiveness of our GBERT-based G2P models under both medium-resource and low-resource data conditions.
BiFSMN: Binary Neural Network for Keyword Spotting
Feb 15, 2022



The deep neural networks, such as the Deep-FSMN, have been widely studied for keyword spotting (KWS) applications. However, computational resources for these networks are significantly constrained since they usually run on-call on edge devices. In this paper, we present BiFSMN, an accurate and extreme-efficient binary neural network for KWS. We first construct a High-frequency Enhancement Distillation scheme for the binarization-aware training, which emphasizes the high-frequency information from the full-precision network's representation that is more crucial for the optimization of the binarized network. Then, to allow the instant and adaptive accuracy-efficiency trade-offs at runtime, we also propose a Thinnable Binarization Architecture to further liberate the acceleration potential of the binarized network from the topology perspective. Moreover, we implement a Fast Bitwise Computation Kernel for BiFSMN on ARMv8 devices which fully utilizes registers and increases instruction throughput to push the limit of deployment efficiency. Extensive experiments show that BiFSMN outperforms existing binarization methods by convincing margins on various datasets and is even comparable with the full-precision counterpart (e.g., less than 3% drop on Speech Commands V1-12). We highlight that benefiting from the thinnable architecture and the optimized 1-bit implementation, BiFSMN can achieve an impressive 22.3x speedup and 15.5x storage-saving on real-world edge hardware.
A Survey on Temporal Reasoning for Temporal Information Extraction from Text (Extended Abstract)
May 15, 2020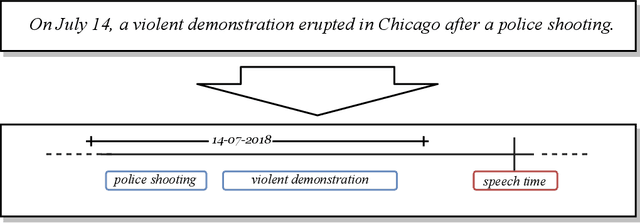

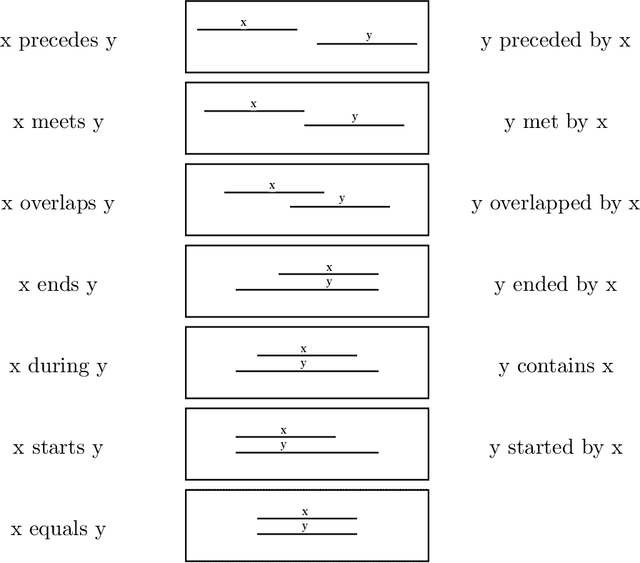
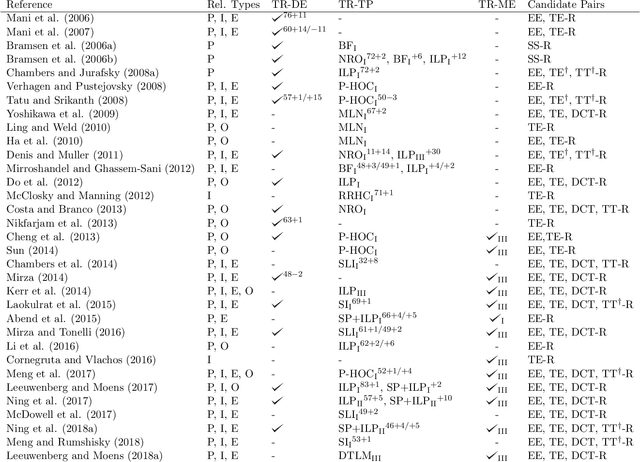
Time is deeply woven into how people perceive, and communicate about the world. Almost unconsciously, we provide our language utterances with temporal cues, like verb tenses, and we can hardly produce sentences without such cues. Extracting temporal cues from text, and constructing a global temporal view about the order of described events is a major challenge of automatic natural language understanding. Temporal reasoning, the process of combining different temporal cues into a coherent temporal view, plays a central role in temporal information extraction. This article presents a comprehensive survey of the research from the past decades on temporal reasoning for automatic temporal information extraction from text, providing a case study on the integration of symbolic reasoning with machine learning-based information extraction systems.
A Communication-efficient Federated learning assisted by Central data: Implementation of vertical training into Horizontal Federated learning
Dec 02, 2021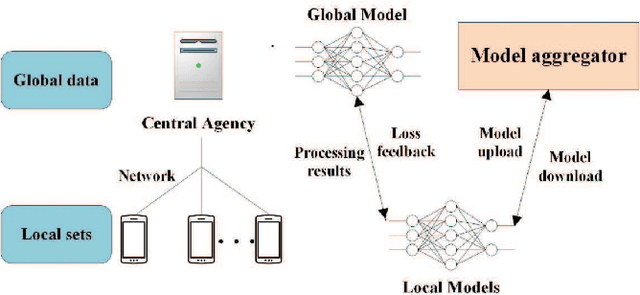
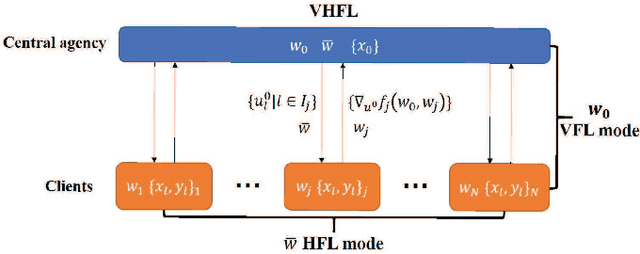
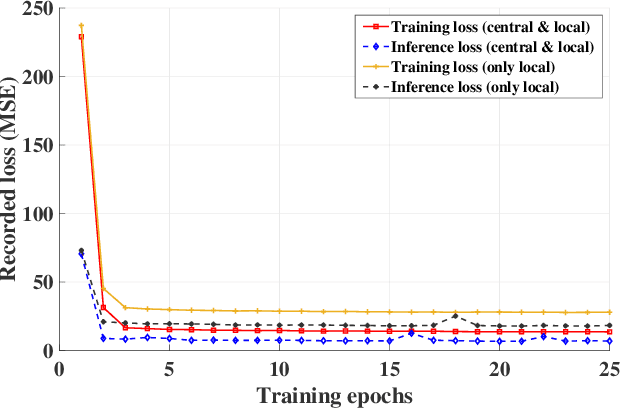
Federated learning (FL) has emerged to jointly train a model with distributed data sets in IoT while avoiding the need for central data collection. Due to limited observation range, such data sets can only reflect local information, which limits the quality of trained models. In practical network, the global information and local observations always coexist, which requires joint consideration for learning to make reasonable policy. However, in horizontal FL among distributed clients, the central agency only acts as a model aggregator without utilizing its global features to further improve the model. This could largely degrade the performance in some missions such as flow prediction, where the global information could obviously enhance the accuracy. Meanwhile, such global feature may not be directly transmitted to agents for data security. Then how to utilize the global observation residing in the central agency while protecting its safety rises up as an important problem in FL. In this paper, we developed the vertical-horizontal federated learning (VHFL) process, where the global feature is shared with the agents in a procedure similar to vertical FL without extra communication rounds. Considering the delay and packet loss, we analyzed its convergence in the network system and validated its performance by experiments. The proposed VHFL could enhance the accuracy compared with the horizontal FL while protecting the security of global data.
Revisiting Over-Smoothness in Text to Speech
Feb 26, 2022


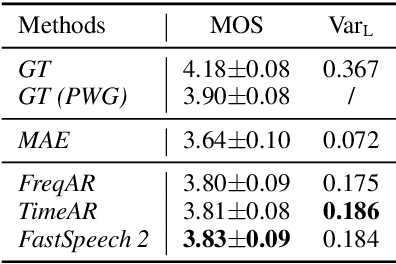
Non-autoregressive text to speech (NAR-TTS) models have attracted much attention from both academia and industry due to their fast generation speed. One limitation of NAR-TTS models is that they ignore the correlation in time and frequency domains while generating speech mel-spectrograms, and thus cause blurry and over-smoothed results. In this work, we revisit this over-smoothing problem from a novel perspective: the degree of over-smoothness is determined by the gap between the complexity of data distributions and the capability of modeling methods. Both simplifying data distributions and improving modeling methods can alleviate the problem. Accordingly, we first study methods reducing the complexity of data distributions. Then we conduct a comprehensive study on NAR-TTS models that use some advanced modeling methods. Based on these studies, we find that 1) methods that provide additional condition inputs reduce the complexity of data distributions to model, thus alleviating the over-smoothing problem and achieving better voice quality. 2) Among advanced modeling methods, Laplacian mixture loss performs well at modeling multimodal distributions and enjoys its simplicity, while GAN and Glow achieve the best voice quality while suffering from increased training or model complexity. 3) The two categories of methods can be combined to further alleviate the over-smoothness and improve the voice quality. 4) Our experiments on the multi-speaker dataset lead to similar conclusions as above and providing more variance information can reduce the difficulty of modeling the target data distribution and alleviate the requirements for model capacity.
Reinforcement Learning with Feedback from Multiple Humans with Diverse Skills
Nov 16, 2021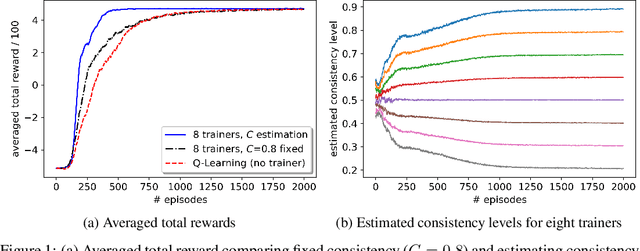
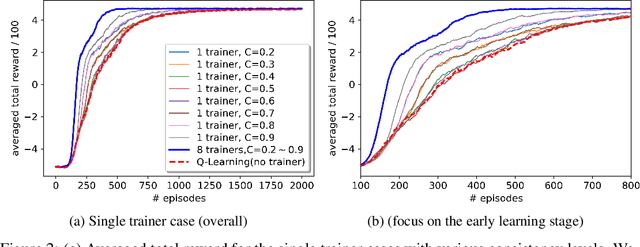
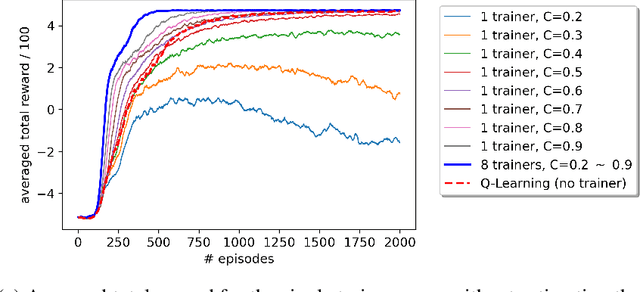
A promising approach to improve the robustness and exploration in Reinforcement Learning is collecting human feedback and that way incorporating prior knowledge of the target environment. It is, however, often too expensive to obtain enough feedback of good quality. To mitigate the issue, we aim to rely on a group of multiple experts (and non-experts) with different skill levels to generate enough feedback. Such feedback can therefore be inconsistent and infrequent. In this paper, we build upon prior work -- Advise, a Bayesian approach attempting to maximise the information gained from human feedback -- extending the algorithm to accept feedback from this larger group of humans, the trainers, while also estimating each trainer's reliability. We show how aggregating feedback from multiple trainers improves the total feedback's accuracy and make the collection process easier in two ways. Firstly, this approach addresses the case of some of the trainers being adversarial. Secondly, having access to the information about each trainer reliability provides a second layer of robustness and offers valuable information for people managing the whole system to improve the overall trust in the system. It offers an actionable tool for improving the feedback collection process or modifying the reward function design if needed. We empirically show that our approach can accurately learn the reliability of each trainer correctly and use it to maximise the information gained from the multiple trainers' feedback, even if some of the sources are adversarial.
A Compact Neural Network-based Algorithm for Robust Image Watermarking
Dec 27, 2021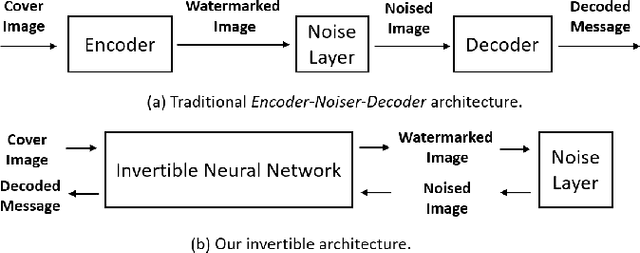
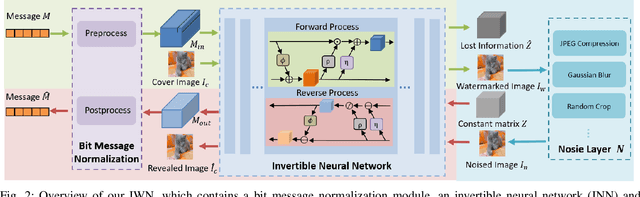
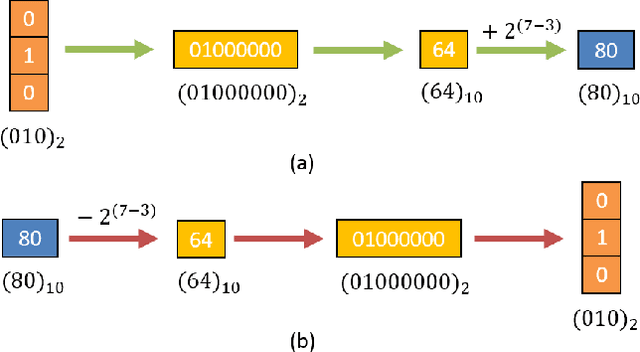
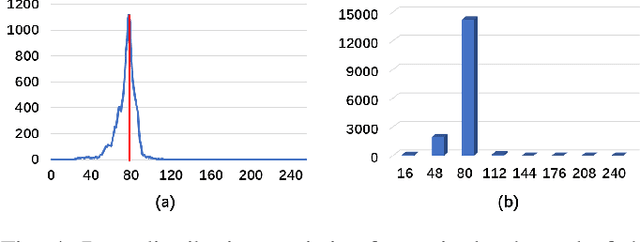
Digital image watermarking seeks to protect the digital media information from unauthorized access, where the message is embedded into the digital image and extracted from it, even some noises or distortions are applied under various data processing including lossy image compression and interactive content editing. Traditional image watermarking solutions easily suffer from robustness when specified with some prior constraints, while recent deep learning-based watermarking methods could not tackle the information loss problem well under various separate pipelines of feature encoder and decoder. In this paper, we propose a novel digital image watermarking solution with a compact neural network, named Invertible Watermarking Network (IWN). Our IWN architecture is based on a single Invertible Neural Network (INN), this bijective propagation framework enables us to effectively solve the challenge of message embedding and extraction simultaneously, by taking them as a pair of inverse problems for each other and learning a stable invertible mapping. In order to enhance the robustness of our watermarking solution, we specifically introduce a simple but effective bit message normalization module to condense the bit message to be embedded, and a noise layer is designed to simulate various practical attacks under our IWN framework. Extensive experiments demonstrate the superiority of our solution under various distortions.
Graph Attention Retrospective
Feb 26, 2022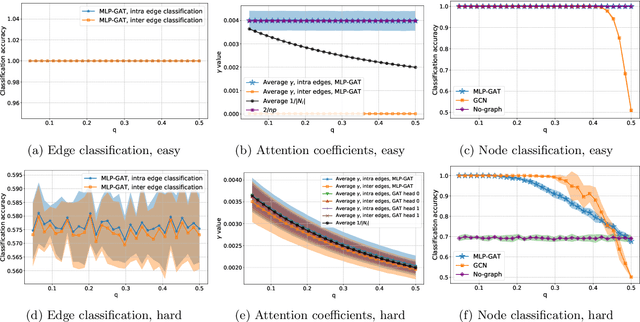
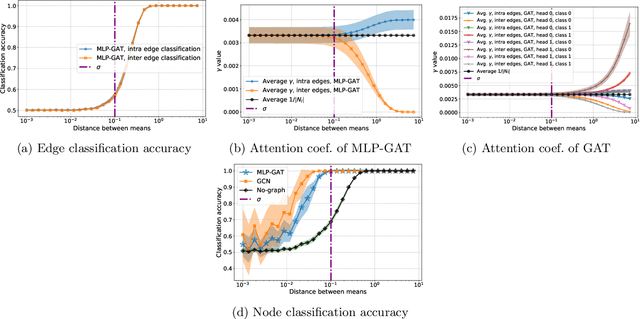
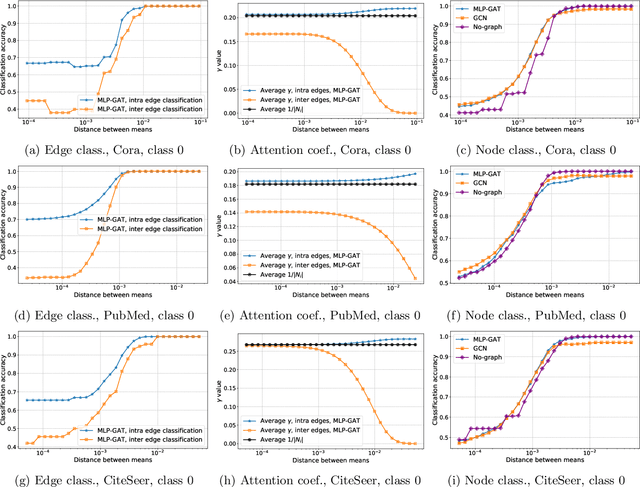
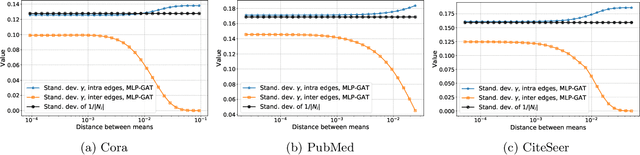
Graph-based learning is a rapidly growing sub-field of machine learning with applications in social networks, citation networks, and bioinformatics. One of the most popular type of models is graph attention networks. These models were introduced to allow a node to aggregate information from the features of neighbor nodes in a non-uniform way in contrast to simple graph convolution which does not distinguish the neighbors of a node. In this paper, we study theoretically this expected behaviour of graph attention networks. We prove multiple results on the performance of the graph attention mechanism for the problem of node classification for a contextual stochastic block model. Here the features of the nodes are obtained from a mixture of Gaussians and the edges from a stochastic block model where the features and the edges are coupled in a natural way. First, we show that in an "easy" regime, where the distance between the means of the Gaussians is large enough, graph attention maintains the weights of intra-class edges and significantly reduces the weights of the inter-class edges. As a corollary, we show that this implies perfect node classification independent of the weights of inter-class edges. However, a classical argument shows that in the "easy" regime, the graph is not needed at all to classify the data with high probability. In the "hard" regime, we show that every attention mechanism fails to distinguish intra-class from inter-class edges. We evaluate our theoretical results on synthetic and real-world data.
Towards Further Understanding of Sparse Filtering via Information Bottleneck
Oct 20, 2019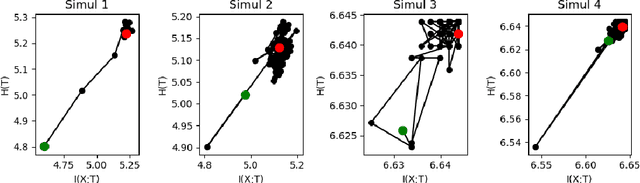
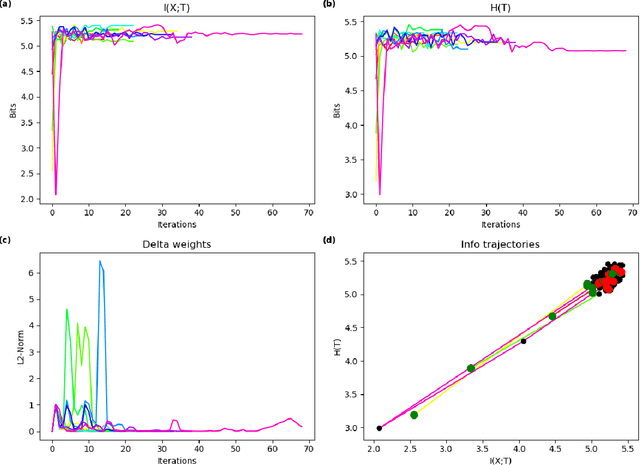
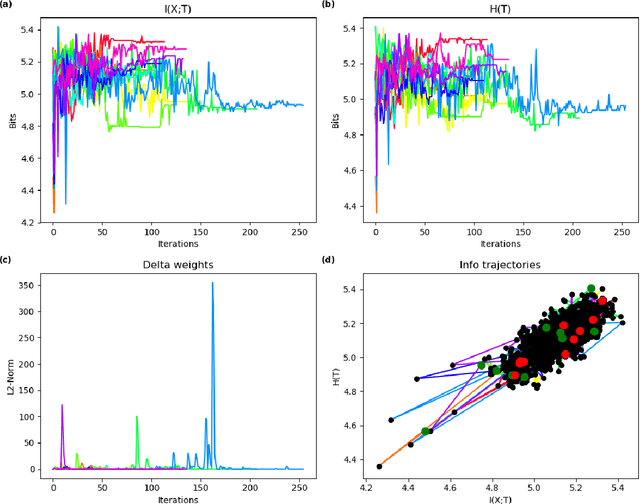
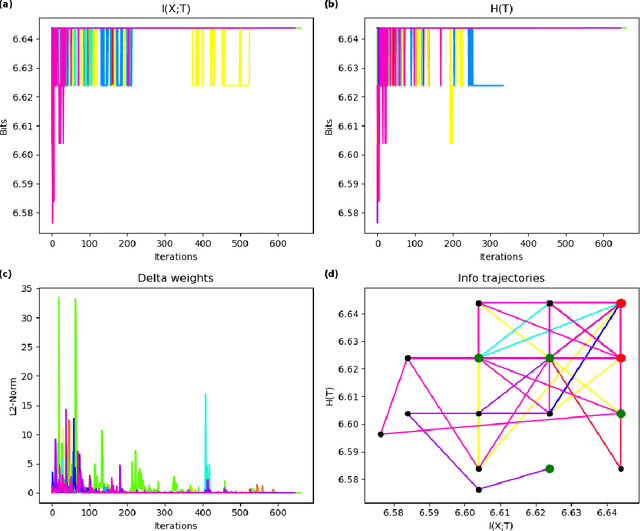
In this paper we examine a formalization of feature distribution learning (FDL) in information-theoretic terms relying on the analytical approach and on the tools already used in the study of the information bottleneck (IB). It has been conjectured that the behavior of FDL algorithms could be expressed as an optimization problem over two information-theoretic quantities: the mutual information of the data with the learned representations and the entropy of the learned distribution. In particular, such a formulation was offered in order to explain the success of the most prominent FDL algorithm, sparse filtering (SF). This conjecture was, however, left unproven. In this work, we aim at providing preliminary empirical support to this conjecture by performing experiments reminiscent of the work done on deep neural networks in the context of the IB research. Specifically, we borrow the idea of using information planes to analyze the behavior of the SF algorithm and gain insights on its dynamics. A confirmation of the conjecture about the dynamics of FDL may provide solid ground to develop information-theoretic tools to assess the quality of the learning process in FDL, and it may be extended to other unsupervised learning algorithms.
Best Arm Identification with a Fixed Budget under a Small Gap
Feb 10, 2022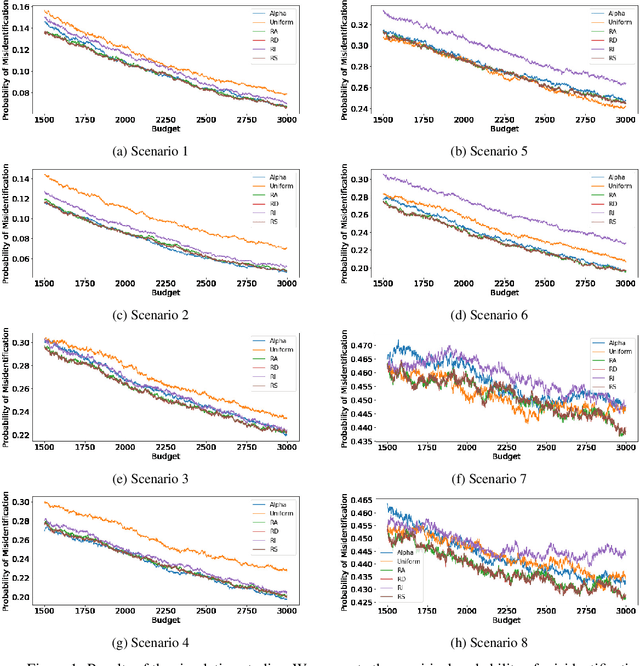
We consider the fixed-budget best arm identification problem in the multi-armed bandit problem. One of the main interests in this field is to derive a tight lower bound on the probability of misidentifying the best arm and to develop a strategy whose performance guarantee matches the lower bound. However, it has long been an open problem when the optimal allocation ratio of arm draws is unknown. In this paper, we provide an answer for this problem under which the gap between the expected rewards is small. First, we derive a tight problem-dependent lower bound, which characterizes the optimal allocation ratio that depends on the gap of the expected rewards and the Fisher information of the bandit model. Then, we propose the "RS-AIPW" strategy, which consists of the randomized sampling (RS) rule using the estimated optimal allocation ratio and the recommendation rule using the augmented inverse probability weighting (AIPW) estimator. Our proposed strategy is optimal in the sense that the performance guarantee achieves the derived lower bound under a small gap. In the course of the analysis, we present a novel large deviation bound for martingales.