 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Structured access to AI capabilities: an emerging paradigm for safe AI deployment
Jan 13, 2022
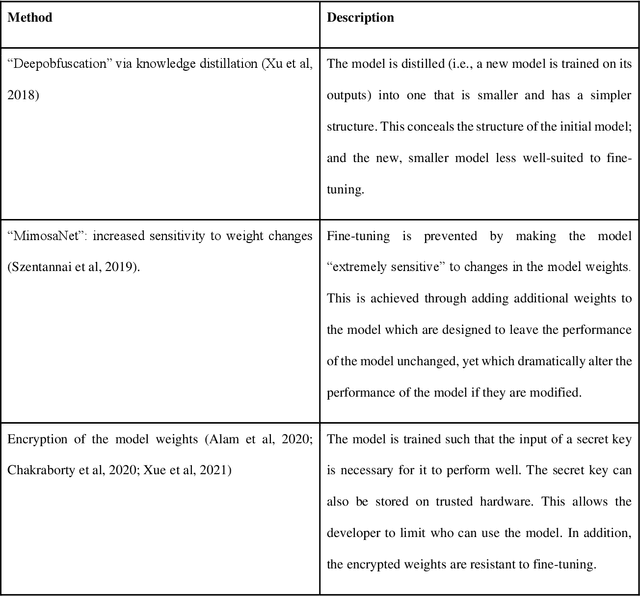
Structured capability access ("SCA") is an emerging paradigm for the safe deployment of artificial intelligence (AI). Instead of openly disseminating AI systems, developers facilitate controlled, arm's length interactions with their AI systems. The aim is to prevent dangerous AI capabilities from being widely accessible, whilst preserving access to AI capabilities that can be used safely. The developer must both restrict how the AI system can be used, and prevent the user from circumventing these restrictions through modification or reverse engineering of the AI system. SCA is most effective when implemented through cloud-based AI services, rather than disseminating AI software that runs locally on users' hardware. Cloud-based interfaces provide the AI developer greater scope for controlling how the AI system is used, and for protecting against unauthorized modifications to the system's design. This chapter expands the discussion of "publication norms" in the AI community, which to date has focused on the question of how the informational content of AI research projects should be disseminated (e.g., code and models). Although this is an important question, there are limits to what can be achieved through the control of information flows. SCA views AI software not only as information that can be shared but also as a tool with which users can have arm's length interactions. There are early examples of SCA being practiced by AI developers, but there is much room for further development, both in the functionality of cloud-based interfaces and in the wider institutional framework.
Fuzziness-based Spatial-Spectral Class Discriminant Information Preserving Active Learning for Hyperspectral Image Classification
May 28, 2020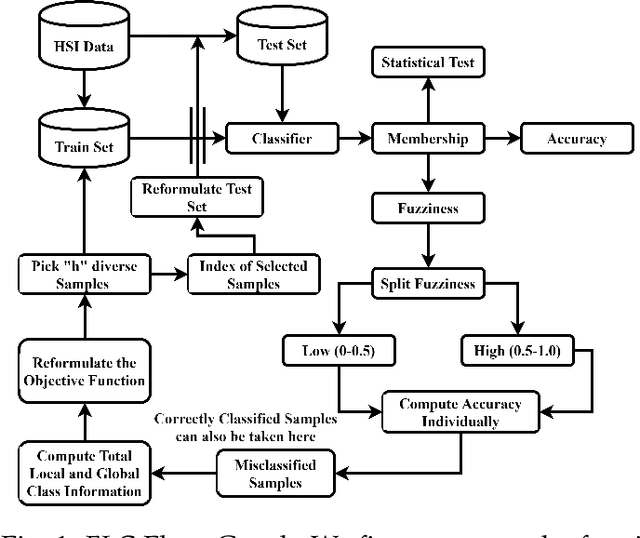
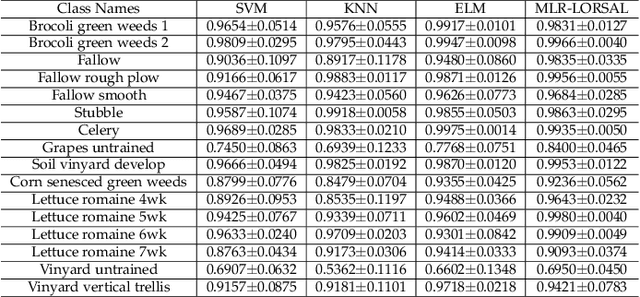
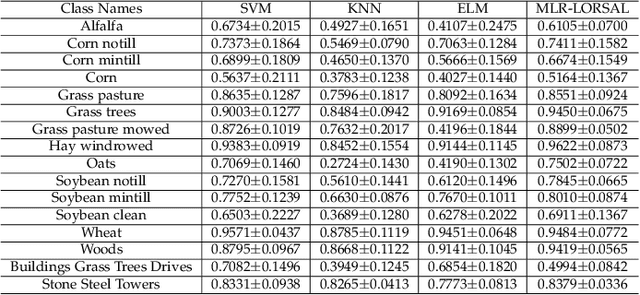
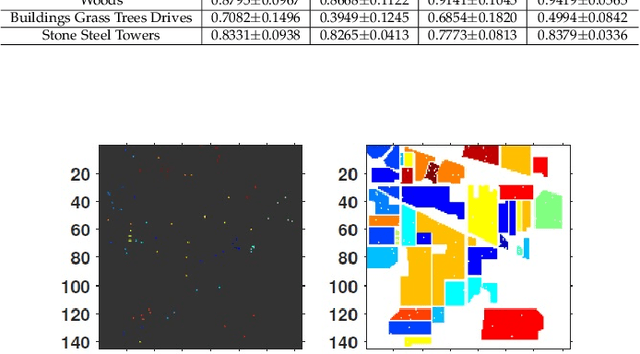
Traditional Active/Self/Interactive Learning for Hyperspectral Image Classification (HSIC) increases the size of the training set without considering the class scatters and randomness among the existing and new samples. Second, very limited research has been carried out on joint spectral-spatial information and finally, a minor but still worth mentioning is the stopping criteria which not being much considered by the community. Therefore, this work proposes a novel fuzziness-based spatial-spectral within and between for both local and global class discriminant information preserving (FLG) method. We first investigate a spatial prior fuzziness-based misclassified sample information. We then compute the total local and global for both within and between class information and formulate it in a fine-grained manner. Later this information is fed to a discriminative objective function to query the heterogeneous samples which eliminate the randomness among the training samples. Experimental results on benchmark HSI datasets demonstrate the effectiveness of the FLG method on Generative, Extreme Learning Machine and Sparse Multinomial Logistic Regression (SMLR)-LORSAL classifiers.
Incremental Mining of Frequent Serial Episodes Considering Multiple Occurrence
Feb 03, 2022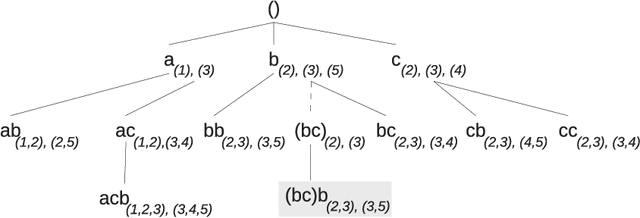
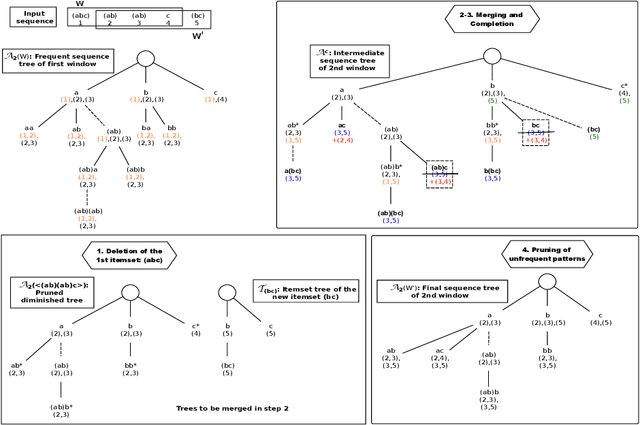
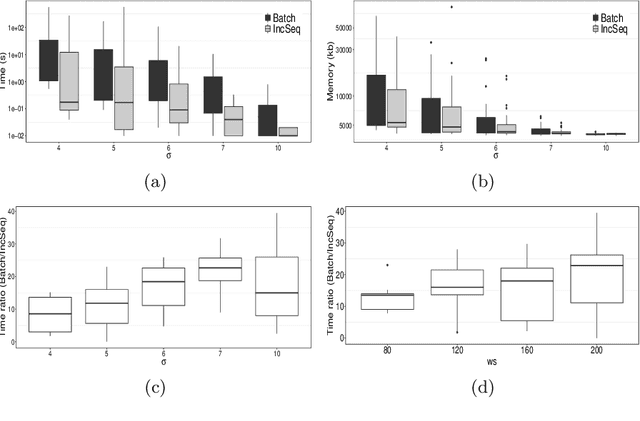

The need to analyze information from streams arises in a variety of applications. One of the fundamental research directions is to mine sequential patterns over data streams. Current studies mine series of items based on the existence of the pattern in transactions but pay no attention to the series of itemsets and their multiple occurrences. The pattern over a window of itemsets stream and their multiple occurrences, however, provides additional capability to recognize the essential characteristics of the patterns and the inter-relationships among them that are unidentifiable by the existing items and existence based studies. In this paper, we study such a new sequential pattern mining problem and propose a corresponding efficient sequential miner with novel strategies to prune search space efficiently. Experiments on both real and synthetic data show the utility of our approach.
A Differential Attention Fusion Model Based on Transformer for Time Series Forecasting
Feb 23, 2022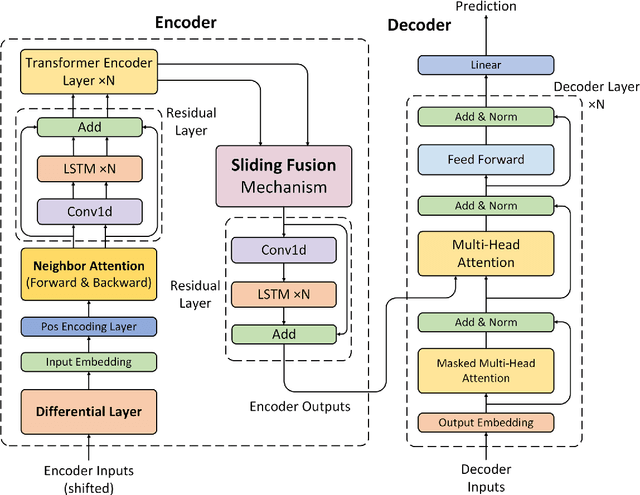
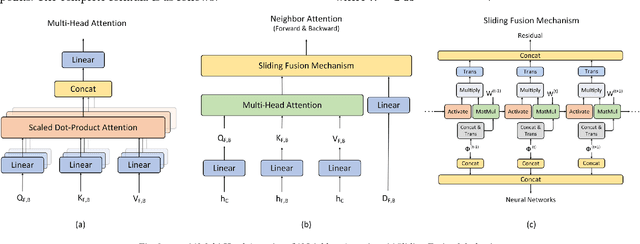
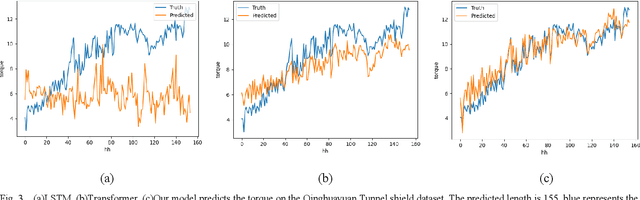
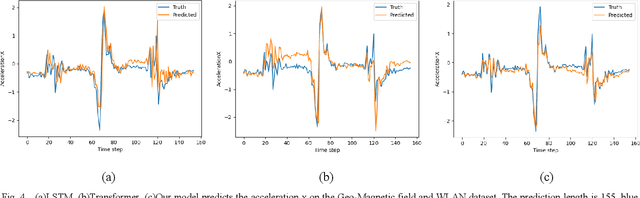
Time series forecasting is widely used in the fields of equipment life cycle forecasting, weather forecasting, traffic flow forecasting, and other fields. Recently, some scholars have tried to apply Transformer to time series forecasting because of its powerful parallel training ability. However, the existing Transformer methods do not pay enough attention to the small time segments that play a decisive role in prediction, making it insensitive to small changes that affect the trend of time series, and it is difficult to effectively learn continuous time-dependent features. To solve this problem, we propose a differential attention fusion model based on Transformer, which designs the differential layer, neighbor attention, sliding fusion mechanism, and residual layer on the basis of classical Transformer architecture. Specifically, the differences of adjacent time points are extracted and focused by difference and neighbor attention. The sliding fusion mechanism fuses various features of each time point so that the data can participate in encoding and decoding without losing important information. The residual layer including convolution and LSTM further learns the dependence between time points and enables our model to carry out deeper training. A large number of experiments on three datasets show that the prediction results produced by our method are favorably comparable to the state-of-the-art.
LIDAR data based Segmentation and Localization using Open Street Maps for Rural Roads
Feb 19, 2022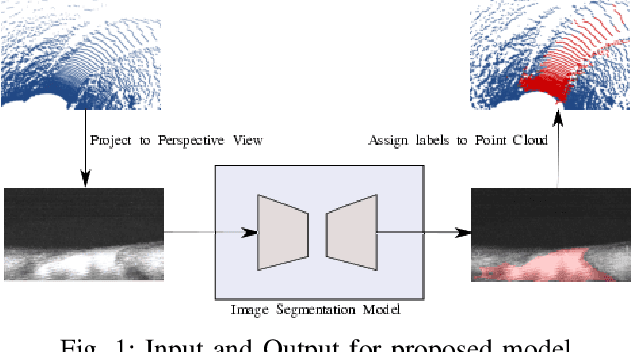
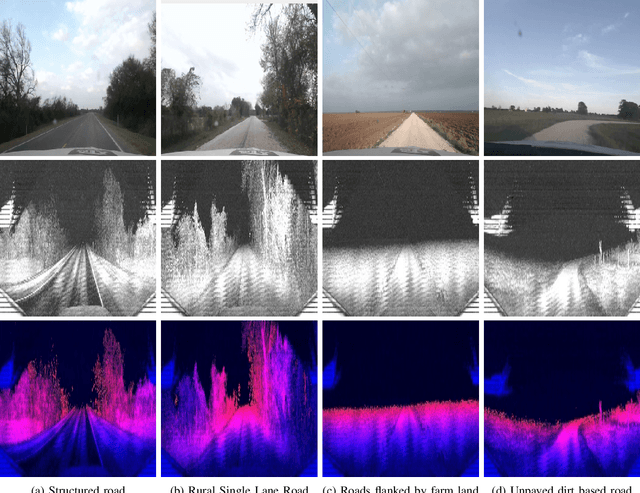
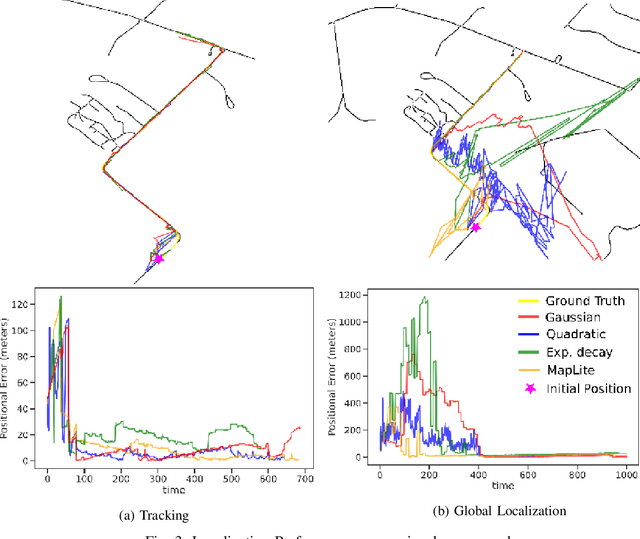
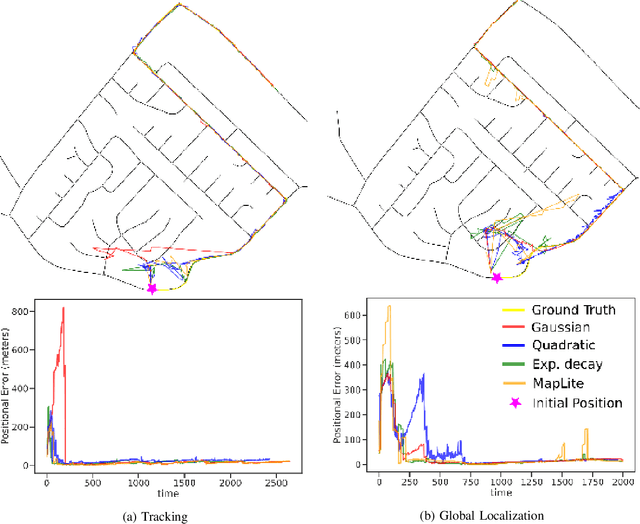
Accurate pose estimation is a fundamental ability that all mobile robots must posses in order to traverse robustly in a given environment. Much like a human, this ability is dependent on the robot's understanding of a given scene. For Autonomous Vehicles (AV's), detailed 3D maps created beforehand are widely used to augment the perceptive abilities and estimate pose based on current sensor measurements. This approach however is less suited for rural communities that are sparsely connected and cover large areas. To deal with the challenge of localizing a vehicle in a rural setting, this paper presents a data-set of rural road scenes, along with an approach for fast segmentation of roads using LIDAR point clouds. The segmented point cloud in concert with road network information from Open Street Maps (OSM) is used for pose estimation. We propose two measurement models which are compared with state of the art methods for localization on OSM for tracking as well as global localization. The results show that the proposed algorithm is able to estimate pose within a 2 sq. km area with mean accuracy of 6.5 meters.
Image Difference Captioning with Pre-training and Contrastive Learning
Feb 09, 2022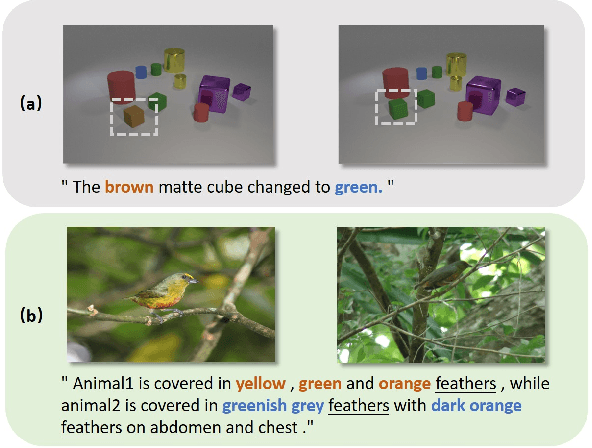
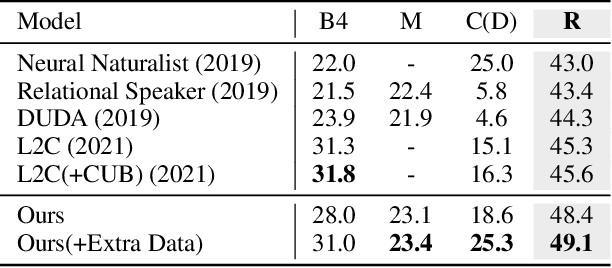
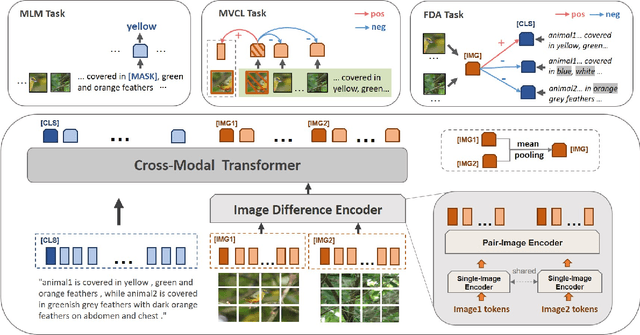
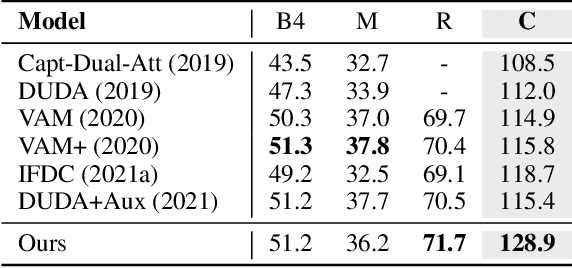
The Image Difference Captioning (IDC) task aims to describe the visual differences between two similar images with natural language. The major challenges of this task lie in two aspects: 1) fine-grained visual differences that require learning stronger vision and language association and 2) high-cost of manual annotations that leads to limited supervised data. To address these challenges, we propose a new modeling framework following the pre-training-finetuning paradigm. Specifically, we design three self-supervised tasks and contrastive learning strategies to align visual differences and text descriptions at a fine-grained level. Moreover, we propose a data expansion strategy to utilize extra cross-task supervision information, such as data for fine-grained image classification, to alleviate the limitation of available supervised IDC data. Extensive experiments on two IDC benchmark datasets, CLEVR-Change and Birds-to-Words, demonstrate the effectiveness of the proposed modeling framework. The codes and models will be released at https://github.com/yaolinli/IDC.
A resource-efficient deep learning framework for low-dose brain PET image reconstruction and analysis
Feb 14, 2022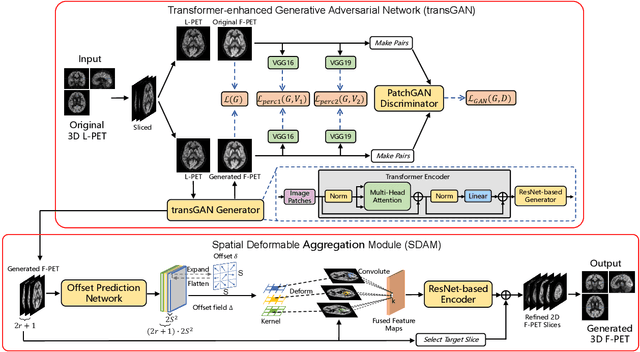

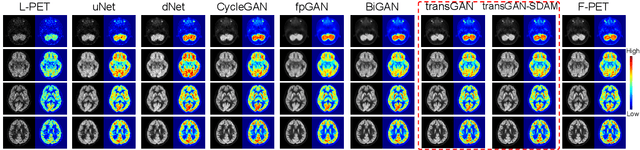

18F-fluorodeoxyglucose (18F-FDG) Positron Emission Tomography (PET) imaging usually needs a full-dose radioactive tracer to obtain satisfactory diagnostic results, which raises concerns about the potential health risks of radiation exposure, especially for pediatric patients. Reconstructing the low-dose PET (L-PET) images to the high-quality full-dose PET (F-PET) ones is an effective way that both reduces the radiation exposure and remains diagnostic accuracy. In this paper, we propose a resource-efficient deep learning framework for L-PET reconstruction and analysis, referred to as transGAN-SDAM, to generate F-PET from corresponding L-PET, and quantify the standard uptake value ratios (SUVRs) of these generated F-PET at whole brain. The transGAN-SDAM consists of two modules: a transformer-encoded Generative Adversarial Network (transGAN) and a Spatial Deformable Aggregation Module (SDAM). The transGAN generates higher quality F-PET images, and then the SDAM integrates the spatial information of a sequence of generated F-PET slices to synthesize whole-brain F-PET images. Experimental results demonstrate the superiority and rationality of our approach.
QA4QG: Using Question Answering to Constrain Multi-Hop Question Generation
Feb 14, 2022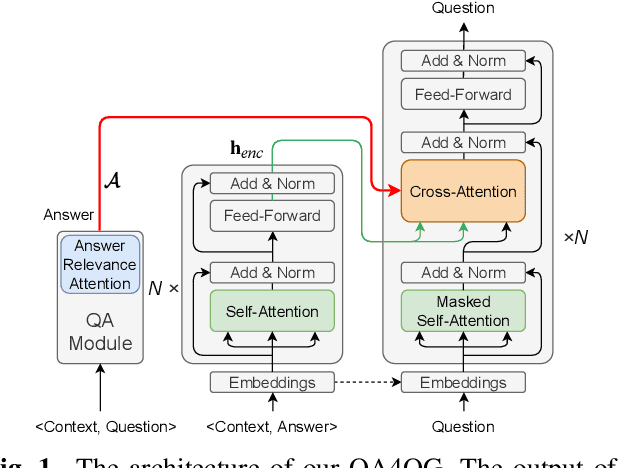
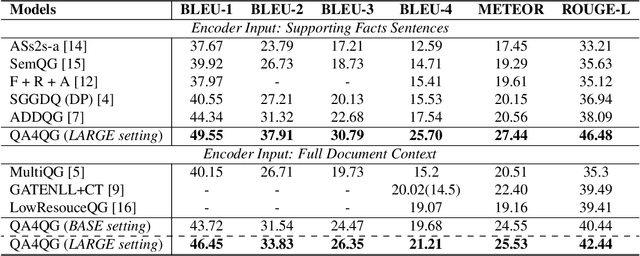
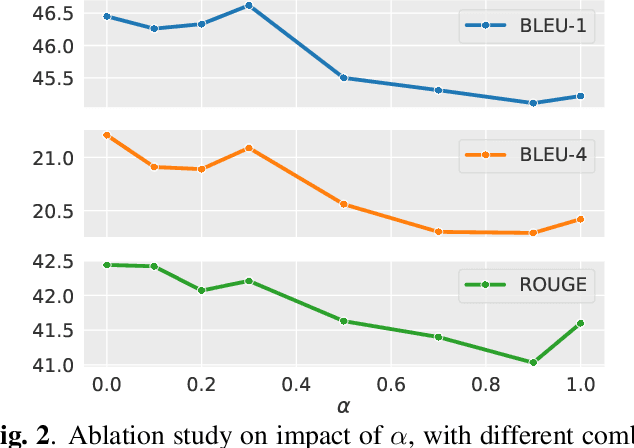
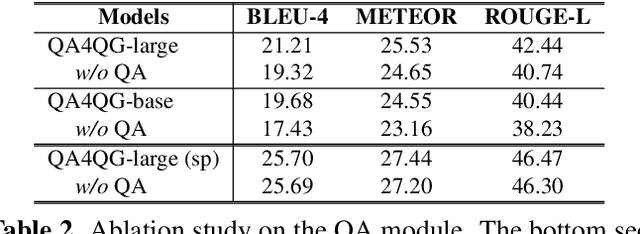
Multi-hop question generation (MQG) aims to generate complex questions which require reasoning over multiple pieces of information of the input passage. Most existing work on MQG has focused on exploring graph-based networks to equip the traditional Sequence-to-sequence framework with reasoning ability. However, these models do not take full advantage of the constraint between questions and answers. Furthermore, studies on multi-hop question answering (QA) suggest that Transformers can replace the graph structure for multi-hop reasoning. Therefore, in this work, we propose a novel framework, QA4QG, a QA-augmented BART-based framework for MQG. It augments the standard BART model with an additional multi-hop QA module to further constrain the generated question. Our results on the HotpotQA dataset show that QA4QG outperforms all state-of-the-art models, with an increase of 8 BLEU-4 and 8 ROUGE points compared to the best results previously reported. Our work suggests the advantage of introducing pre-trained language models and QA module for the MQG task.
Mutual Information Regularized Identity-aware Facial ExpressionRecognition in Compressed Video
Oct 20, 2020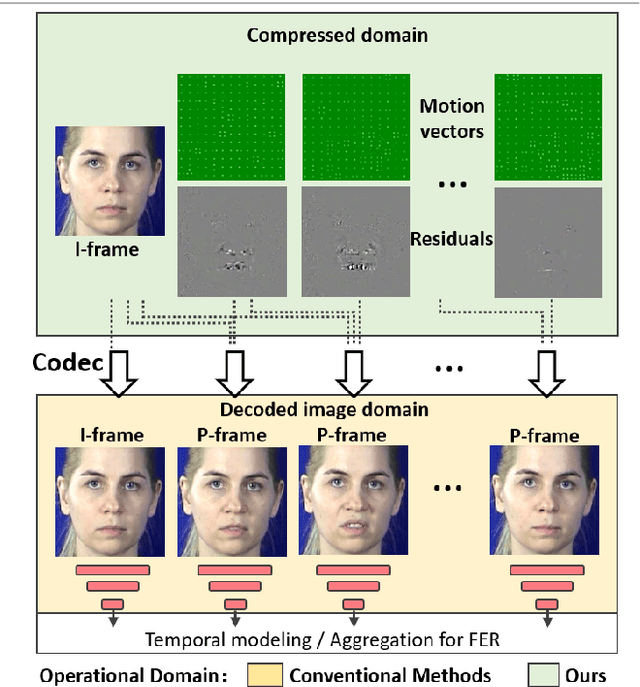
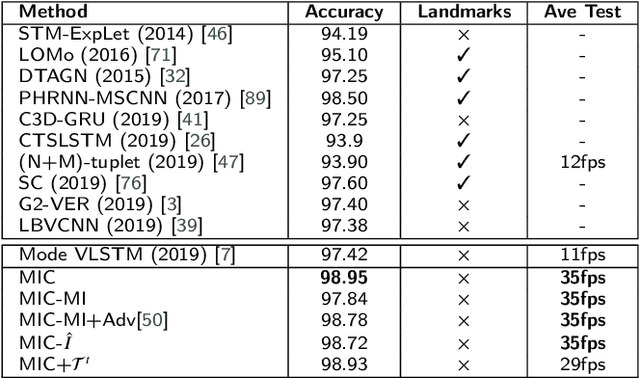
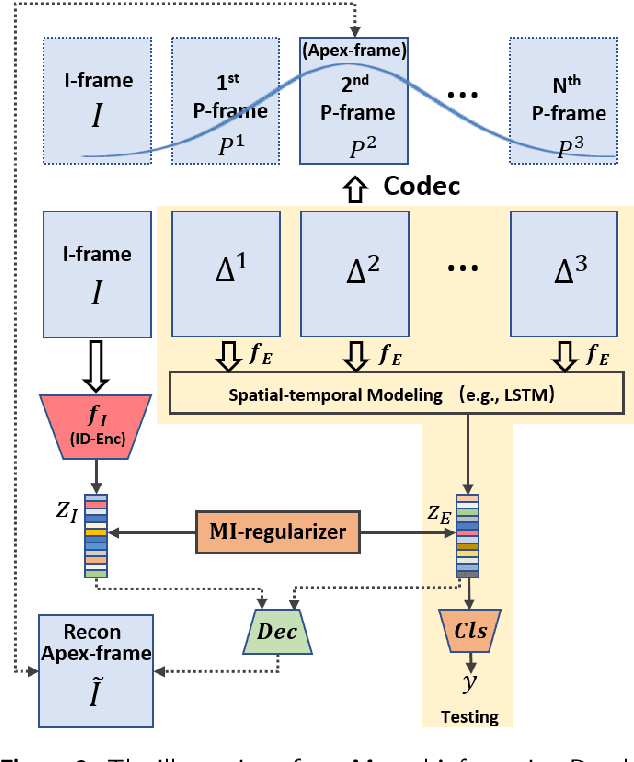
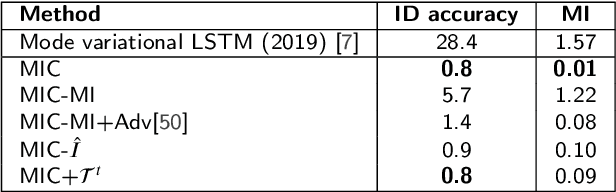
This paper targets to explore the inter-subject variations eliminated facial expression representation in the compressed video domain. Most of the previous methods process the RGB images of a sequence, while the off-the-shelf and valuable expression-related muscle movement already embedded in the compression format. In the up to two orders of magnitude compressed domain, we can explicitly infer the expression from the residual frames and possible to extract identity factors from the I frame with a pre-trained face recognition network. By enforcing the marginal independent of them, the expression feature is expected to be purer for the expression and be robust to identity shifts. Specifically, we propose a novel collaborative min-min game for mutual information (MI) minimization in latent space. We do not need the identity label or multiple expression samples from the same person for identity elimination. Moreover, when the apex frame is annotated in the dataset, the complementary constraint can be further added to regularize the feature-level game. In testing, only the compressed residual frames are required to achieve expression prediction. Our solution can achieve comparable or better performance than the recent decoded image-based methods on the typical FER benchmarks with about 3 times faster inference.
Turbo-Sim: a generalised generative model with a physical latent space
Dec 21, 2021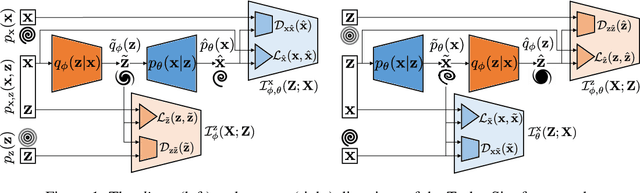

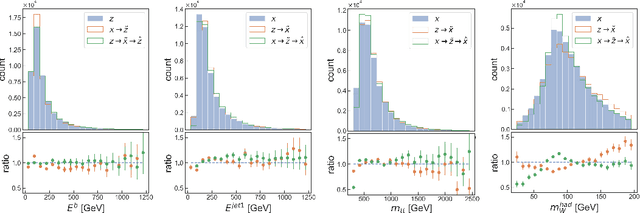
We present Turbo-Sim, a generalised autoencoder framework derived from principles of information theory that can be used as a generative model. By maximising the mutual information between the input and the output of both the encoder and the decoder, we are able to rediscover the loss terms usually found in adversarial autoencoders and generative adversarial networks, as well as various more sophisticated related models. Our generalised framework makes these models mathematically interpretable and allows for a diversity of new ones by setting the weight of each loss term separately. The framework is also independent of the intrinsic architecture of the encoder and the decoder thus leaving a wide choice for the building blocks of the whole network. We apply Turbo-Sim to a collider physics generation problem: the transformation of the properties of several particles from a theory space, right after the collision, to an observation space, right after the detection in an experiment.