 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adversarial Imitation Learning from Video using a State Observer
Feb 01, 2022
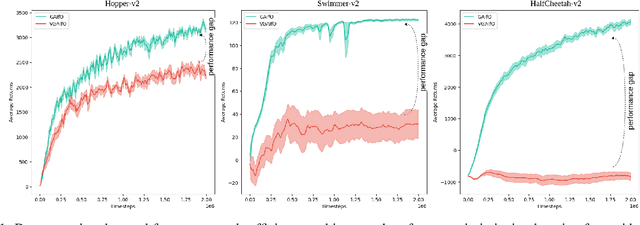
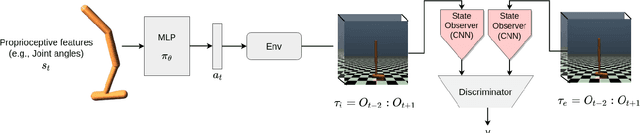
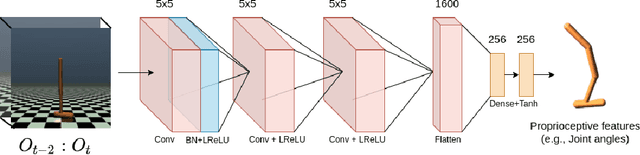
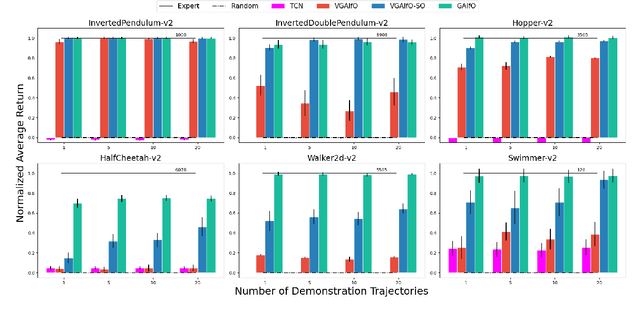
The imitation learning research community has recently made significant progress towards the goal of enabling artificial agents to imitate behaviors from video demonstrations alone. However, current state-of-the-art approaches developed for this problem exhibit high sample complexity due, in part, to the high-dimensional nature of video observations. Towards addressing this issue, we introduce here a new algorithm called Visual Generative Adversarial Imitation from Observation using a State Observer VGAIfO-SO. At its core, VGAIfO-SO seeks to address sample inefficiency using a novel, self-supervised state observer, which provides estimates of lower-dimensional proprioceptive state representations from high-dimensional images. We show experimentally in several continuous control environments that VGAIfO-SO is more sample efficient than other IfO algorithms at learning from video-only demonstrations and can sometimes even achieve performance close to the Generative Adversarial Imitation from Observation (GAIfO) algorithm that has privileged access to the demonstrator's proprioceptive state information.
Attacking Deep Reinforcement Learning-Based Traffic Signal Control Systems with Colluding Vehicles
Nov 04, 2021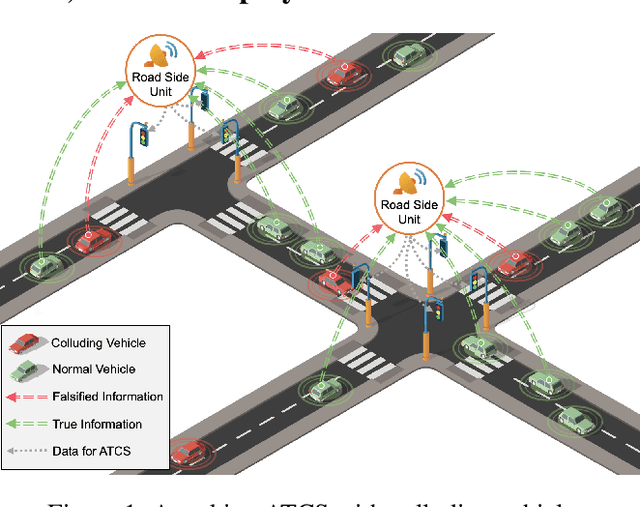

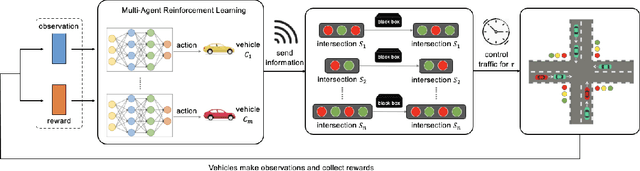
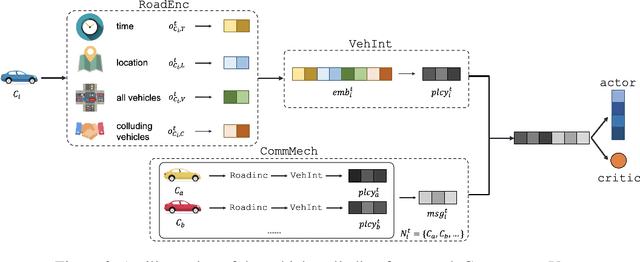
The rapid advancements of Internet of Things (IoT) and artificial intelligence (AI) have catalyzed the development of adaptive traffic signal control systems (ATCS) for smart cities. In particular, deep reinforcement learning (DRL) methods produce the state-of-the-art performance and have great potentials for practical applications. In the existing DRL-based ATCS, the controlled signals collect traffic state information from nearby vehicles, and then optimal actions (e.g., switching phases) can be determined based on the collected information. The DRL models fully "trust" that vehicles are sending the true information to the signals, making the ATCS vulnerable to adversarial attacks with falsified information. In view of this, this paper first time formulates a novel task in which a group of vehicles can cooperatively send falsified information to "cheat" DRL-based ATCS in order to save their total travel time. To solve the proposed task, we develop CollusionVeh, a generic and effective vehicle-colluding framework composed of a road situation encoder, a vehicle interpreter, and a communication mechanism. We employ our method to attack established DRL-based ATCS and demonstrate that the total travel time for the colluding vehicles can be significantly reduced with a reasonable number of learning episodes, and the colluding effect will decrease if the number of colluding vehicles increases. Additionally, insights and suggestions for the real-world deployment of DRL-based ATCS are provided. The research outcomes could help improve the reliability and robustness of the ATCS and better protect the smart mobility systems.
Specializing Word Embeddings (for Parsing) by Information Bottleneck
Oct 01, 2019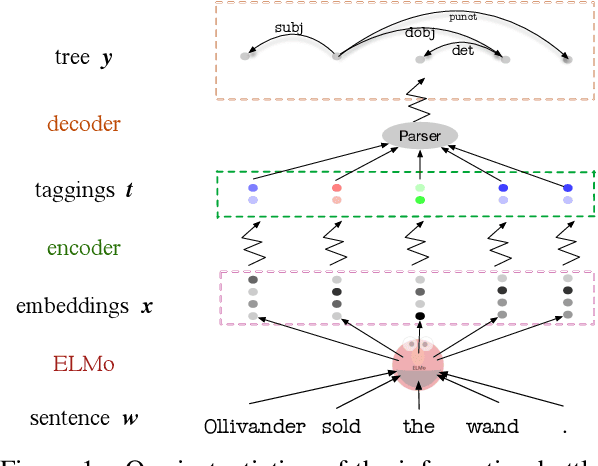
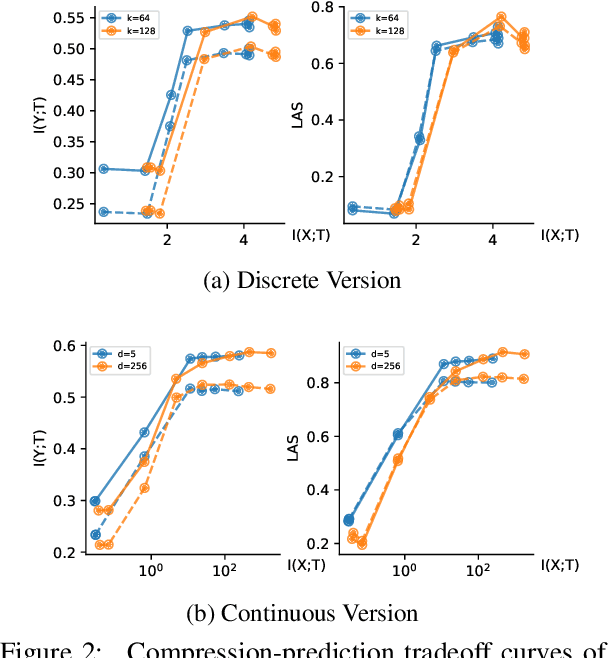
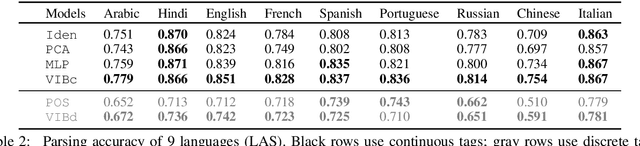
Pre-trained word embeddings like ELMo and BERT contain rich syntactic and semantic information, resulting in state-of-the-art performance on various tasks. We propose a very fast variational information bottleneck (VIB) method to nonlinearly compress these embeddings, keeping only the information that helps a discriminative parser. We compress each word embedding to either a discrete tag or a continuous vector. In the discrete version, our automatically compressed tags form an alternative tag set: we show experimentally that our tags capture most of the information in traditional POS tag annotations, but our tag sequences can be parsed more accurately at the same level of tag granularity. In the continuous version, we show experimentally that moderately compressing the word embeddings by our method yields a more accurate parser in 8 of 9 languages, unlike simple dimensionality reduction.
Landmark Guidance Independent Spatio-channel Attention and Complementary Context Information based Facial Expression Recognition
Jul 20, 2020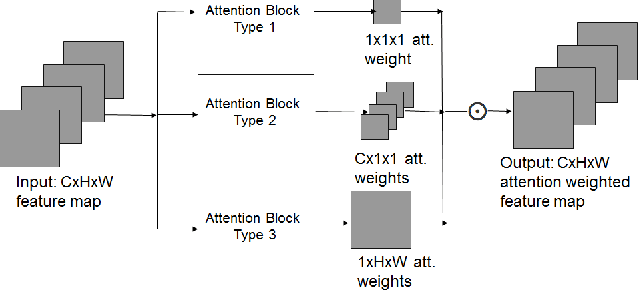



A recent trend to recognize facial expressions in the real-world scenario is to deploy attention based convolutional neural networks (CNNs) locally to signify the importance of facial regions and, combine it with global facial features and/or other complementary context information for performance gain. However, in the presence of occlusions and pose variations, different channels respond differently, and further that the response intensity of a channel differ across spatial locations. Also, modern facial expression recognition(FER) architectures rely on external sources like landmark detectors for defining attention. Failure of landmark detector will have a cascading effect on FER. Additionally, there is no emphasis laid on the relevance of features that are input to compute complementary context information. Leveraging on the aforementioned observations, an end-to-end architecture for FER is proposed in this work that obtains both local and global attention per channel per spatial location through a novel spatio-channel attention net (SCAN), without seeking any information from the landmark detectors. SCAN is complemented by a complementary context information (CCI) branch. Further, using efficient channel attention (ECA), the relevance of features input to CCI is also attended to. The representation learnt by the proposed architecture is robust to occlusions and pose variations. Robustness and superior performance of the proposed model is demonstrated on both in-lab and in-the-wild datasets (AffectNet, FERPlus, RAF-DB, FED-RO, SFEW, CK+, Oulu-CASIA and JAFFE) along with a couple of constructed face mask datasets resembling masked faces in COVID-19 scenario. Codes will be made publicly available.
Decentralized Task Offloading in Edge Computing: A Multi-User Multi-Armed Bandit Approach
Dec 28, 2021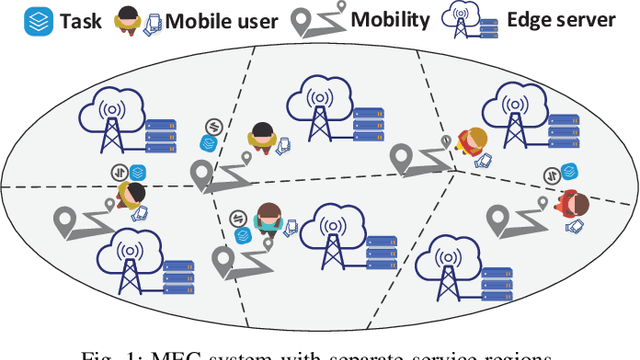
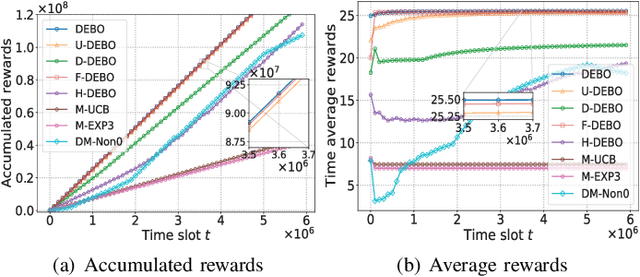
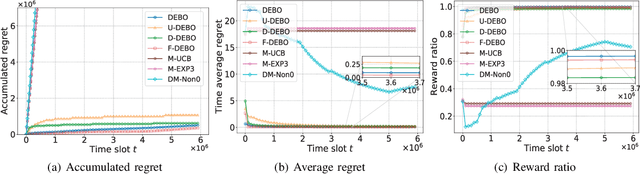
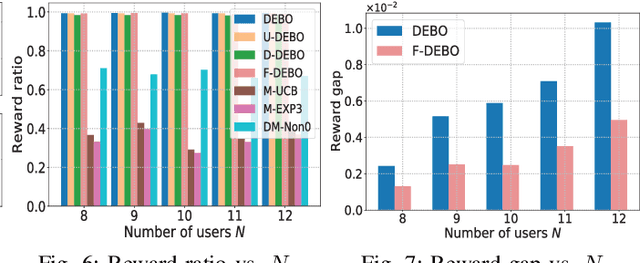
Mobile edge computing facilitates users to offload computation tasks to edge servers for meeting their stringent delay requirements. Previous works mainly explore task offloading when system-side information is given (e.g., server processing speed, cellular data rate), or centralized offloading under system uncertainty. But both generally fall short to handle task placement involving many coexisting users in a dynamic and uncertain environment. In this paper, we develop a multi-user offloading framework considering unknown yet stochastic system-side information to enable a decentralized user-initiated service placement. Specifically, we formulate the dynamic task placement as an online multi-user multi-armed bandit process, and propose a decentralized epoch based offloading (DEBO) to optimize user rewards which are subjected under network delay. We show that DEBO can deduce the optimal user-server assignment, thereby achieving a close-to-optimal service performance and tight O(log T) offloading regret. Moreover, we generalize DEBO to various common scenarios such as unknown reward gap, dynamic entering or leaving of clients, and fair reward distribution, while further exploring when users' offloaded tasks require heterogeneous computing resources. Particularly, we accomplish a sub-linear regret for each of these instances. Real measurements based evaluations corroborate the superiority of our offloading schemes over state-of-the-art approaches in optimizing delay-sensitive rewards.
Attentive Multi-View Deep Subspace Clustering Net
Dec 23, 2021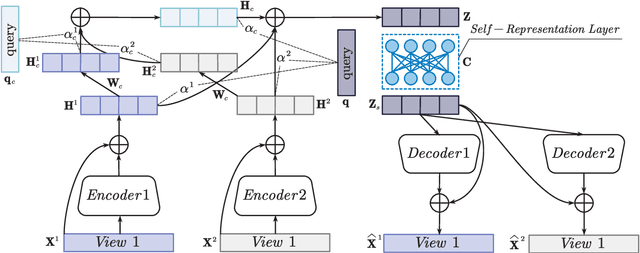
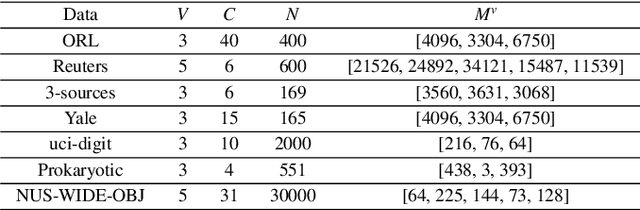

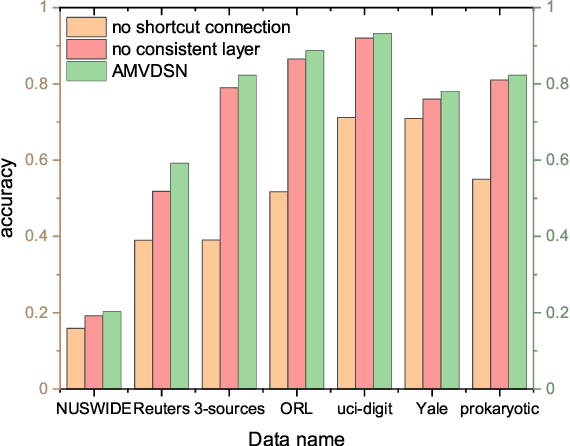
In this paper, we propose a novel Attentive Multi-View Deep Subspace Nets (AMVDSN), which deeply explores underlying consistent and view-specific information from multiple views and fuse them by considering each view's dynamic contribution obtained by attention mechanism. Unlike most multi-view subspace learning methods that they directly reconstruct data points on raw data or only consider consistency or complementarity when learning representation in deep or shallow space, our proposed method seeks to find a joint latent representation that explicitly considers both consensus and view-specific information among multiple views, and then performs subspace clustering on learned joint latent representation.Besides, different views contribute differently to representation learning, we therefore introduce attention mechanism to derive dynamic weight for each view, which performs much better than previous fusion methods in the field of multi-view subspace clustering. The proposed algorithm is intuitive and can be easily optimized just by using Stochastic Gradient Descent (SGD) because of the neural network framework, which also provides strong non-linear characterization capability compared with traditional subspace clustering approaches. The experimental results on seven real-world data sets have demonstrated the effectiveness of our proposed algorithm against some state-of-the-art subspace learning approaches.
Survey on English Entity Linking on Wikidata
Dec 03, 2021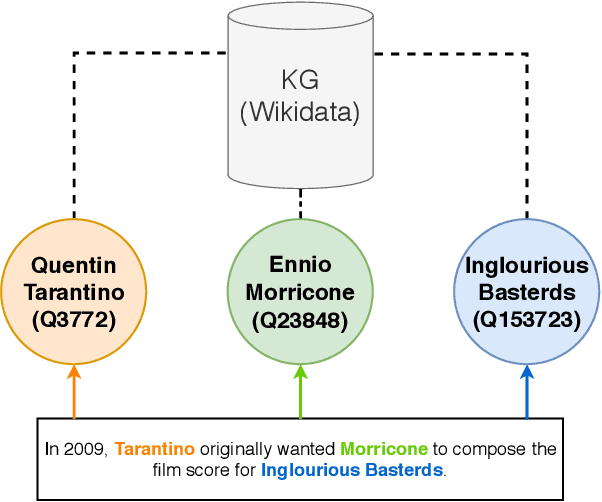

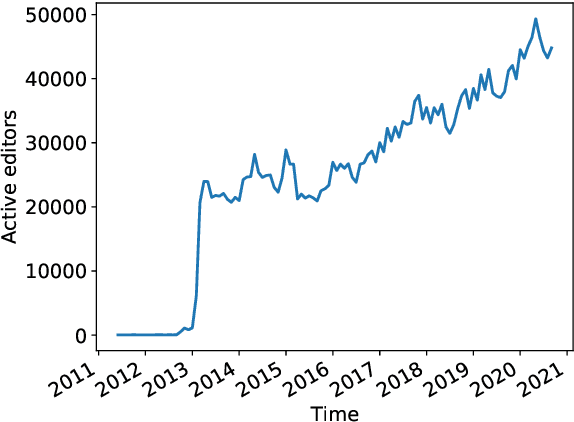
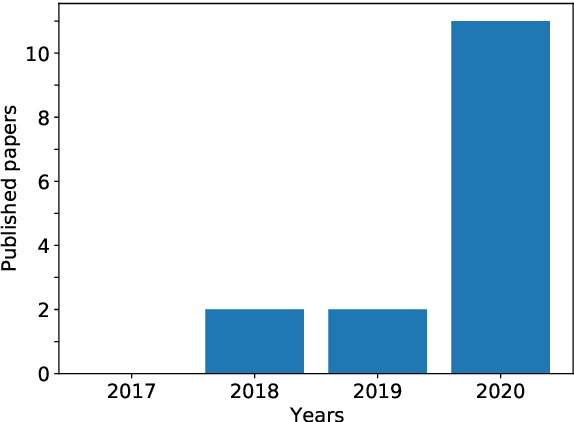
Wikidata is a frequently updated, community-driven, and multilingual knowledge graph. Hence, Wikidata is an attractive basis for Entity Linking, which is evident by the recent increase in published papers. This survey focuses on four subjects: (1) Which Wikidata Entity Linking datasets exist, how widely used are they and how are they constructed? (2) Do the characteristics of Wikidata matter for the design of Entity Linking datasets and if so, how? (3) How do current Entity Linking approaches exploit the specific characteristics of Wikidata? (4) Which Wikidata characteristics are unexploited by existing Entity Linking approaches? This survey reveals that current Wikidata-specific Entity Linking datasets do not differ in their annotation scheme from schemes for other knowledge graphs like DBpedia. Thus, the potential for multilingual and time-dependent datasets, naturally suited for Wikidata, is not lifted. Furthermore, we show that most Entity Linking approaches use Wikidata in the same way as any other knowledge graph missing the chance to leverage Wikidata-specific characteristics to increase quality. Almost all approaches employ specific properties like labels and sometimes descriptions but ignore characteristics such as the hyper-relational structure. Hence, there is still room for improvement, for example, by including hyper-relational graph embeddings or type information. Many approaches also include information from Wikipedia, which is easily combinable with Wikidata and provides valuable textual information, which Wikidata lacks.
Lawin Transformer: Improving Semantic Segmentation Transformer with Multi-Scale Representations via Large Window Attention
Jan 05, 2022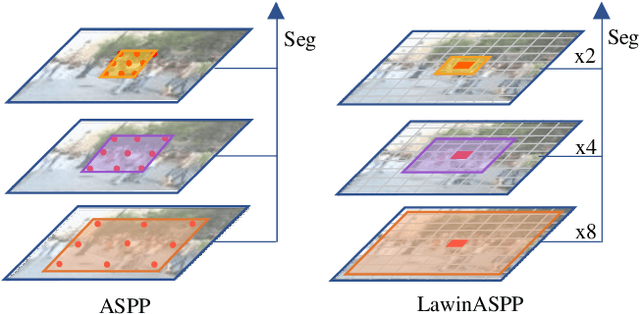
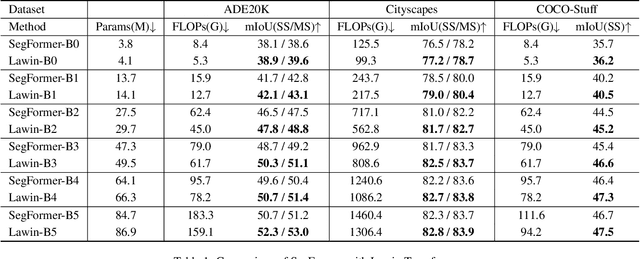
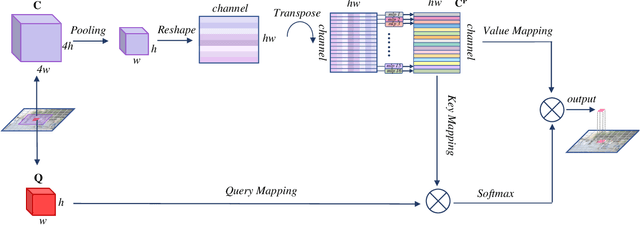
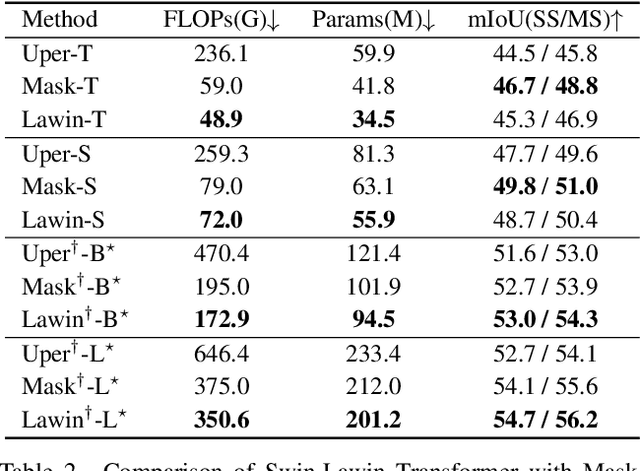
Multi-scale representations are crucial for semantic segmentation. The community has witnessed the flourish of semantic segmentation convolutional neural networks (CNN) exploiting multi-scale contextual information. Motivated by that the vision transformer (ViT) is powerful in image classification, some semantic segmentation ViTs are recently proposed, most of them attaining impressive results but at a cost of computational economy. In this paper, we succeed in introducing multi-scale representations into semantic segmentation ViT via window attention mechanism and further improves the performance and efficiency. To this end, we introduce large window attention which allows the local window to query a larger area of context window at only a little computation overhead. By regulating the ratio of the context area to the query area, we enable the large window attention to capture the contextual information at multiple scales. Moreover, the framework of spatial pyramid pooling is adopted to collaborate with the large window attention, which presents a novel decoder named large window attention spatial pyramid pooling (LawinASPP) for semantic segmentation ViT. Our resulting ViT, Lawin Transformer, is composed of an efficient hierachical vision transformer (HVT) as encoder and a LawinASPP as decoder. The empirical results demonstrate that Lawin Transformer offers an improved efficiency compared to the existing method. Lawin Transformer further sets new state-of-the-art performance on Cityscapes (84.4\% mIoU), ADE20K (56.2\% mIoU) and COCO-Stuff datasets. The code will be released at https://github.com/yan-hao-tian/lawin.
3D Fourier ghost imaging via semi-calibrated photometric stereo
Dec 28, 2021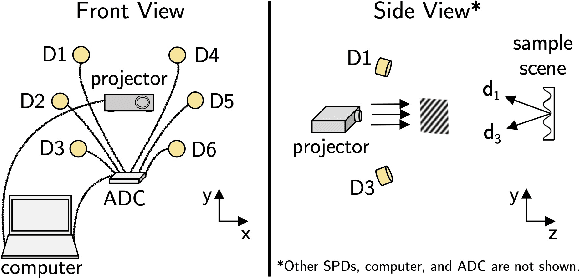
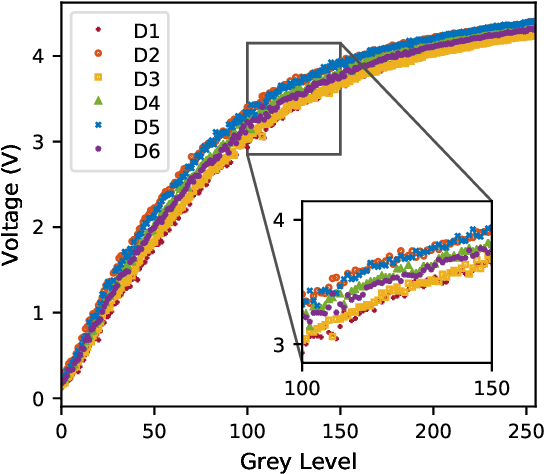


We achieved three-dimensional (3D) computational ghost imaging with multiple photoresistors serving as single-pixel detectors using semi-calibrated lighting approach. We performed imaging in the spatial frequency domain by having each photoresistor obtain the Fourier spectrum of the scene at a low spectral coverage ratio of 5%. To retrieve a depth map of a scene, we inverted, apodized, and applied semi-calibrated photometric stereo (SCPS) to the spectra. At least 93.5% accuracy was achieved for the 3D results of the apodized set of images applied with SCPS in comparison with the ground truth. Furthermore, intensity error map statistics obtained at least 97.0% accuracy for the estimated surface normals using our method. Our system does not need special calibration objects or any additional optical components to perform accurate 3D imaging, making it easily adaptable. Our method can be applied in current imaging systems where multiple detectors operating at any wavelength are used for two-dimensional (2D) imaging, such as imaging cosmological objects. Employing the idea of changing light patterns to illuminate a target scene and having stored information about these patterns, the data retrieved by one detector will give the 2D information while the multiple-detector system can be used to get a 3D profile.
* 10 pages, 8 figures, 2 visualizations
Joint Information Preservation for Heterogeneous Domain Adaptation
May 22, 2019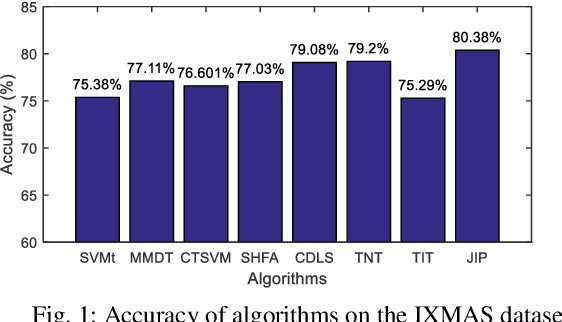
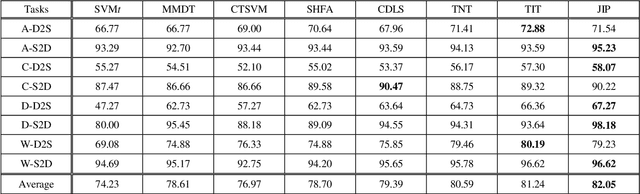
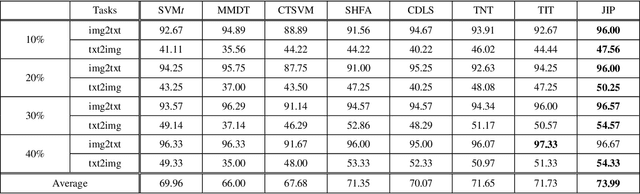
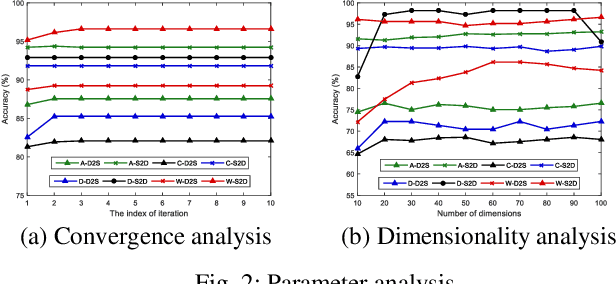
Domain adaptation aims to assist the modeling tasks of the target domain with knowledge of the source domain. The two domains often lie in different feature spaces due to diverse data collection methods, which leads to the more challenging task of heterogeneous domain adaptation (HDA). A core issue of HDA is how to preserve the information of the original data during adaptation. In this paper, we propose a joint information preservation method to deal with the problem. The method preserves the information of the original data from two aspects. On the one hand, although paired samples often exist between the two domains of the HDA, current algorithms do not utilize such information sufficiently. The proposed method preserves the paired information by maximizing the correlation of the paired samples in the shared subspace. On the other hand, the proposed method improves the strategy of preserving the structural information of the original data, where the local and global structural information are preserved simultaneously. Finally, the joint information preservation is integrated by distribution matching. Experimental results show the superiority of the proposed method over the state-of-the-art HDA algorithms.