 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hiding Information in Big Data based on Deep Learning
Dec 31, 2019
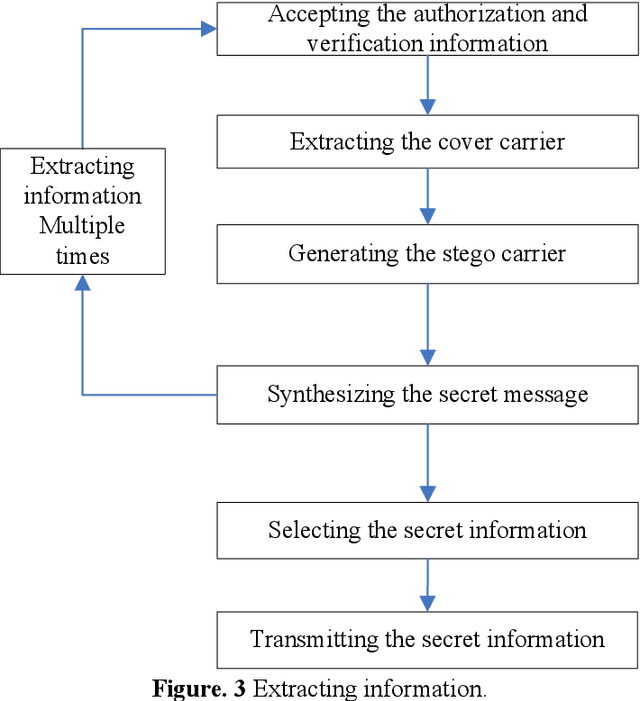
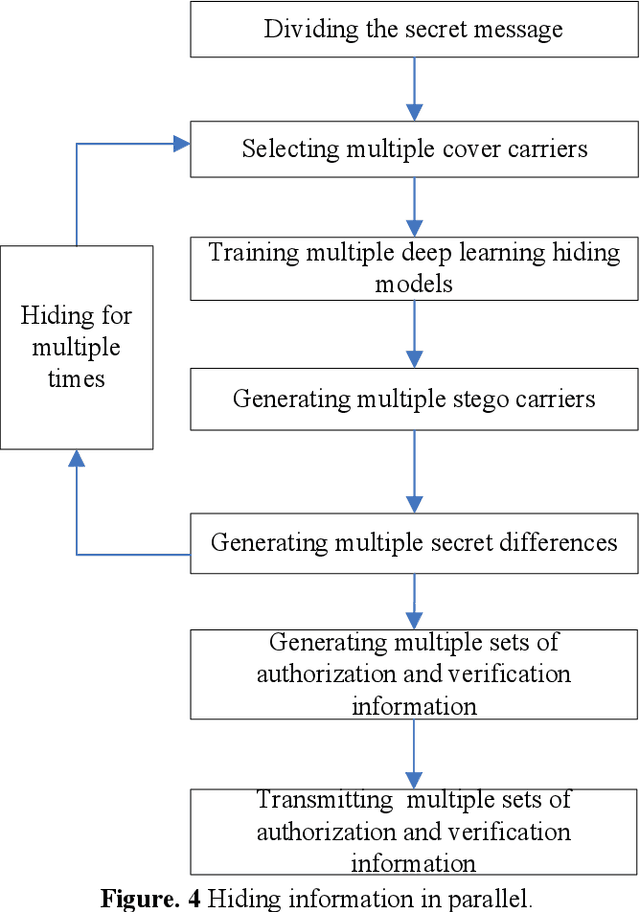
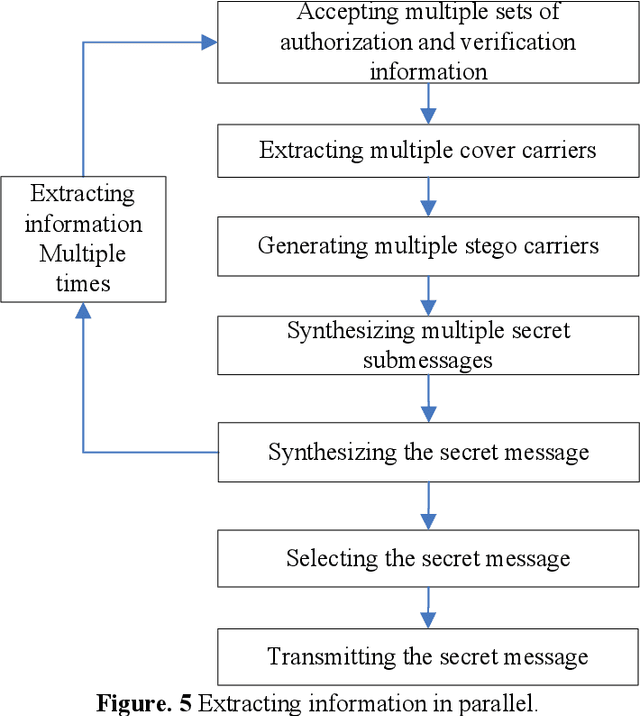
The current approach of information hiding based on deep learning model can not directly use the original data as carriers, which means the approach can not make use of the existing data in big data to hiding information. We proposed a novel method of information hiding in big data based on deep learning. Our method uses the existing data in big data as carriers and uses deep learning models to hide and extract secret messages in big data. The data amount of big data is unlimited and thus the data amount of secret messages hided in big data can also be unlimited. Before opponents want to extract secret messages from carriers, they need to find the carriers, however finding out the carriers from big data is just like finding out a box from the sea. Deep learning models are well known as deep black boxes in which the process from the input to the output is very complex, and thus the deep learning model for information hiding is almost impossible for opponents to reconstruct. The results also show that our method can hide secret messages safely, conveniently, quickly and with no limitation on the data amount.
Sparse Interventions in Language Models with Differentiable Masking
Dec 13, 2021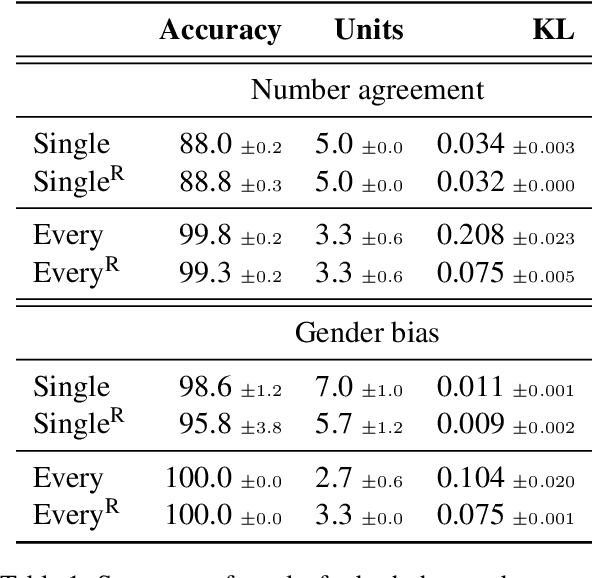
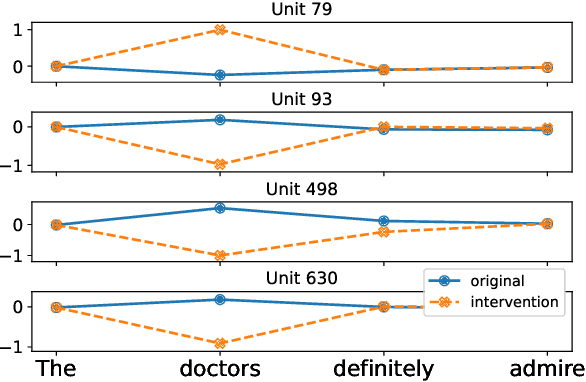
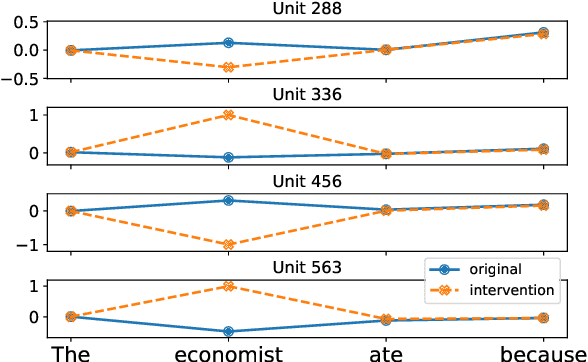
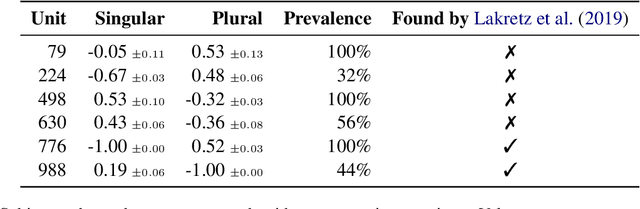
There has been a lot of interest in understanding what information is captured by hidden representations of language models (LMs). Typically, interpretation methods i) do not guarantee that the model actually uses the encoded information, and ii) do not discover small subsets of neurons responsible for a considered phenomenon. Inspired by causal mediation analysis, we propose a method that discovers within a neural LM a small subset of neurons responsible for a particular linguistic phenomenon, i.e., subsets causing a change in the corresponding token emission probabilities. We use a differentiable relaxation to approximately search through the combinatorial space. An $L_0$ regularization term ensures that the search converges to discrete and sparse solutions. We apply our method to analyze subject-verb number agreement and gender bias detection in LSTMs. We observe that it is fast and finds better solutions than the alternative (REINFORCE). Our experiments confirm that each of these phenomenons is mediated through a small subset of neurons that do not play any other discernible role.
SeMask: Semantically Masked Transformers for Semantic Segmentation
Dec 23, 2021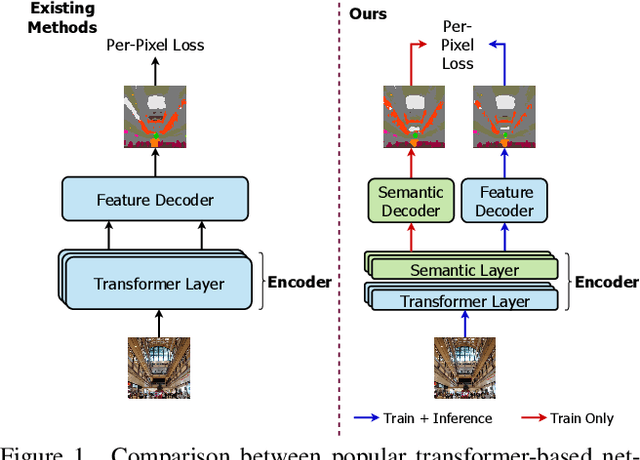
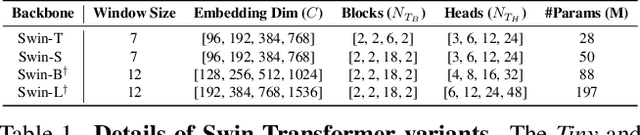
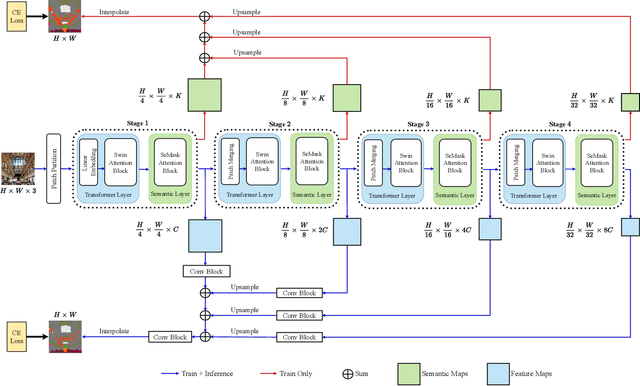
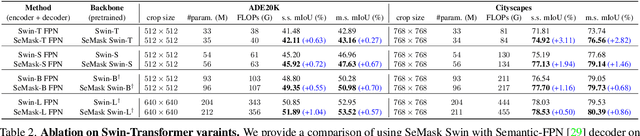
Finetuning a pretrained backbone in the encoder part of an image transformer network has been the traditional approach for the semantic segmentation task. However, such an approach leaves out the semantic context that an image provides during the encoding stage. This paper argues that incorporating semantic information of the image into pretrained hierarchical transformer-based backbones while finetuning improves the performance considerably. To achieve this, we propose SeMask, a simple and effective framework that incorporates semantic information into the encoder with the help of a semantic attention operation. In addition, we use a lightweight semantic decoder during training to provide supervision to the intermediate semantic prior maps at every stage. Our experiments demonstrate that incorporating semantic priors enhances the performance of the established hierarchical encoders with a slight increase in the number of FLOPs. We provide empirical proof by integrating SeMask into each variant of the Swin-Transformer as our encoder paired with different decoders. Our framework achieves a new state-of-the-art of 58.22% mIoU on the ADE20K dataset and improvements of over 3% in the mIoU metric on the Cityscapes dataset. The code and checkpoints are publicly available at https://github.com/Picsart-AI-Research/SeMask-Segmentation .
Adversarial Imitation Learning from Video using a State Observer
Feb 01, 2022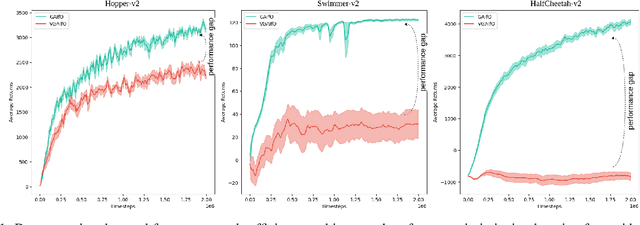
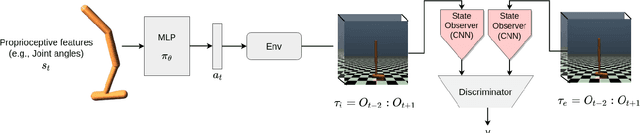
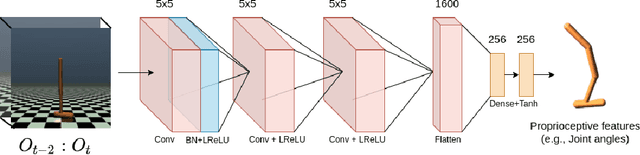
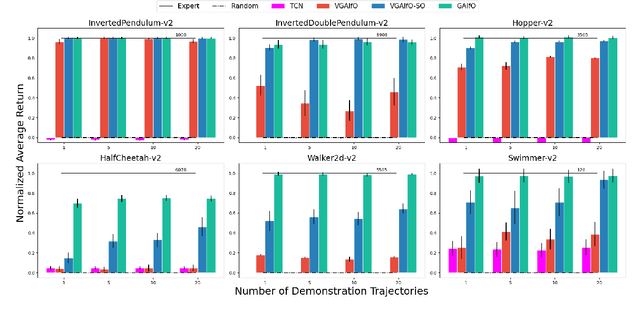
The imitation learning research community has recently made significant progress towards the goal of enabling artificial agents to imitate behaviors from video demonstrations alone. However, current state-of-the-art approaches developed for this problem exhibit high sample complexity due, in part, to the high-dimensional nature of video observations. Towards addressing this issue, we introduce here a new algorithm called Visual Generative Adversarial Imitation from Observation using a State Observer VGAIfO-SO. At its core, VGAIfO-SO seeks to address sample inefficiency using a novel, self-supervised state observer, which provides estimates of lower-dimensional proprioceptive state representations from high-dimensional images. We show experimentally in several continuous control environments that VGAIfO-SO is more sample efficient than other IfO algorithms at learning from video-only demonstrations and can sometimes even achieve performance close to the Generative Adversarial Imitation from Observation (GAIfO) algorithm that has privileged access to the demonstrator's proprioceptive state information.
The Effect of Model Size on Worst-Group Generalization
Dec 08, 2021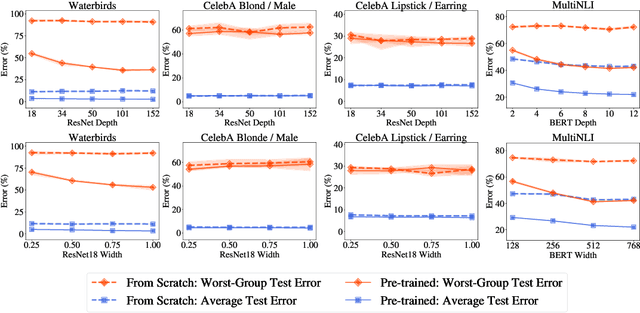
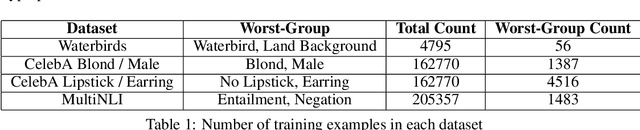
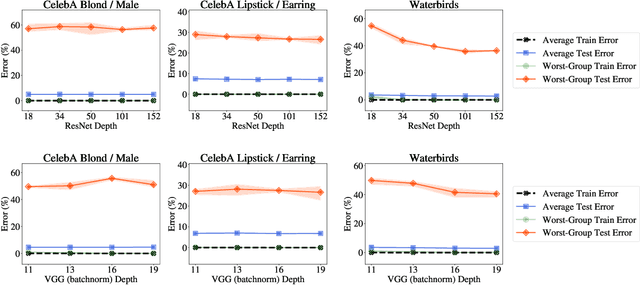
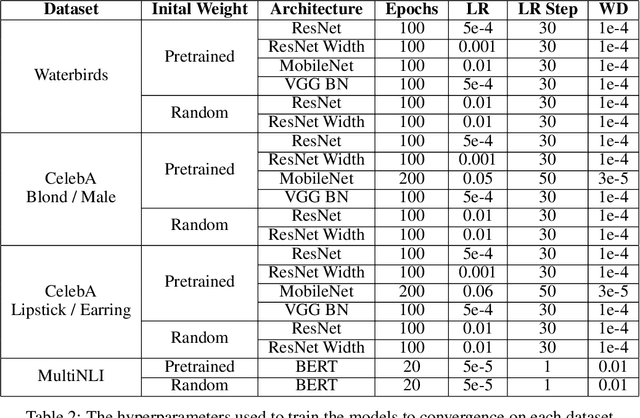
Overparameterization is shown to result in poor test accuracy on rare subgroups under a variety of settings where subgroup information is known. To gain a more complete picture, we consider the case where subgroup information is unknown. We investigate the effect of model size on worst-group generalization under empirical risk minimization (ERM) across a wide range of settings, varying: 1) architectures (ResNet, VGG, or BERT), 2) domains (vision or natural language processing), 3) model size (width or depth), and 4) initialization (with pre-trained or random weights). Our systematic evaluation reveals that increasing model size does not hurt, and may help, worst-group test performance under ERM across all setups. In particular, increasing pre-trained model size consistently improves performance on Waterbirds and MultiNLI. We advise practitioners to use larger pre-trained models when subgroup labels are unknown.
SECP-Net: SE-Connection Pyramid Network of Organ At Risk Segmentation for Nasopharyngeal Carcinoma
Dec 28, 2021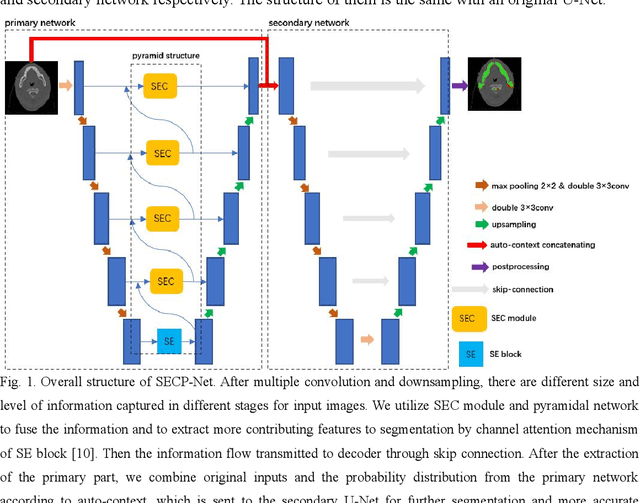
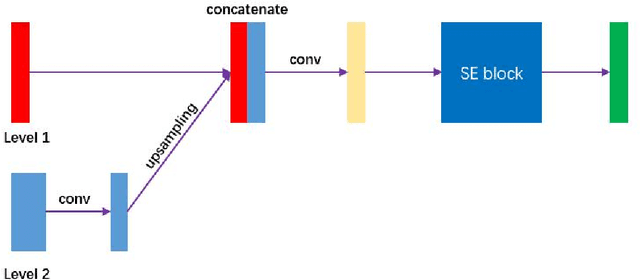
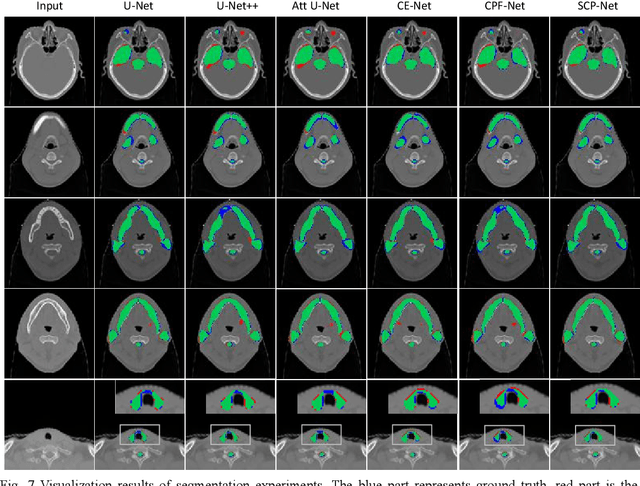
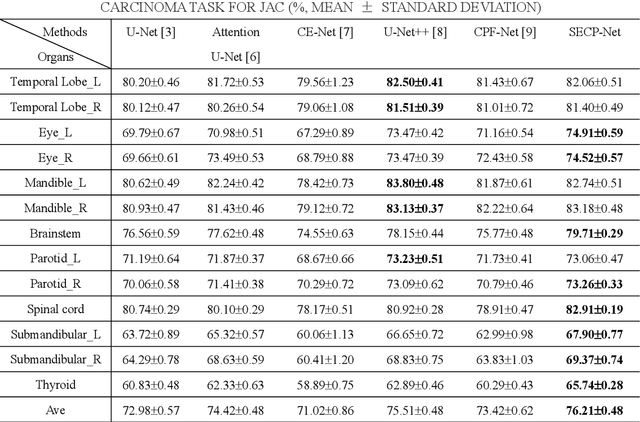
Nasopharyngeal carcinoma (NPC) is a kind of malignant tumor. Accurate and automatic segmentation of organs at risk (OAR) of computed tomography (CT) images is clinically significant. In recent years, deep learning models represented by U-Net have been widely applied in medical image segmentation tasks, which can help doctors with reduction of workload and get accurate results more quickly. In OAR segmentation of NPC, the sizes of OAR are variable, especially, some of them are small. Traditional deep neural networks underperform during segmentation due to the lack use of global and multi-size information. This paper proposes a new SE-Connection Pyramid Network (SECP-Net). SECP-Net extracts global and multi-size information flow with se connection (SEC) modules and a pyramid structure of network for improving the segmentation performance, especially that of small organs. SECP-Net also designs an auto-context cascaded network to further improve the segmentation performance. Comparative experiments are conducted between SECP-Net and other recently methods on a dataset with CT images of head and neck. Five-fold cross validation is used to evaluate the performance based on two metrics, i.e., Dice and Jaccard similarity. Experimental results show that SECP-Net can achieve SOTA performance in this challenging task.
GuidedMix-Net: Semi-supervised Semantic Segmentation by Using Labeled Images as Reference
Dec 28, 2021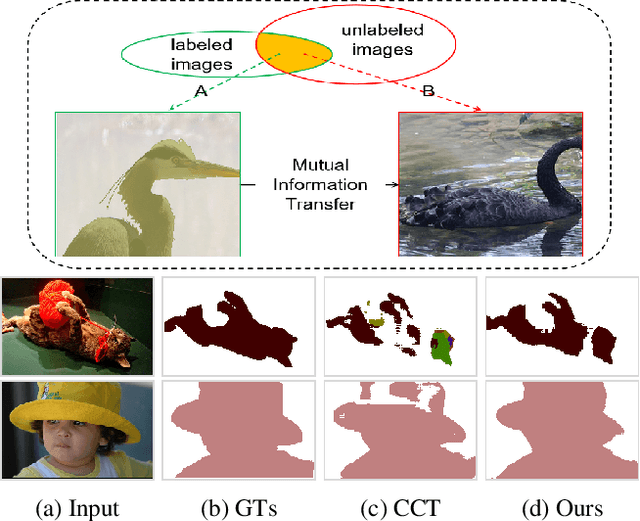
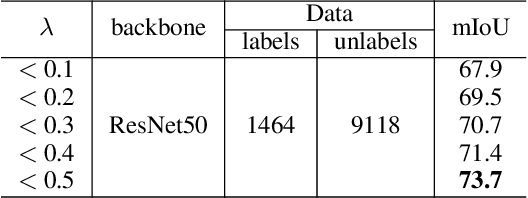
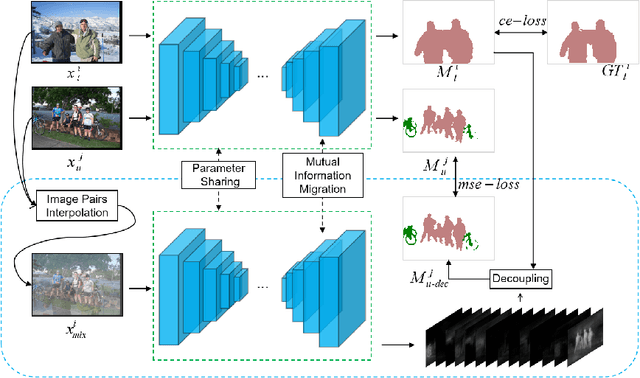
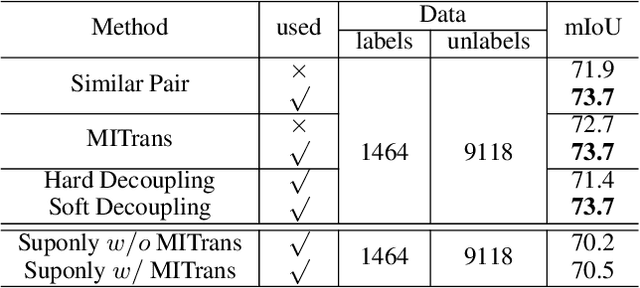
Semi-supervised learning is a challenging problem which aims to construct a model by learning from limited labeled examples. Numerous methods for this task focus on utilizing the predictions of unlabeled instances consistency alone to regularize networks. However, treating labeled and unlabeled data separately often leads to the discarding of mass prior knowledge learned from the labeled examples. %, and failure to mine the feature interaction between the labeled and unlabeled image pairs. In this paper, we propose a novel method for semi-supervised semantic segmentation named GuidedMix-Net, by leveraging labeled information to guide the learning of unlabeled instances. Specifically, GuidedMix-Net employs three operations: 1) interpolation of similar labeled-unlabeled image pairs; 2) transfer of mutual information; 3) generalization of pseudo masks. It enables segmentation models can learning the higher-quality pseudo masks of unlabeled data by transfer the knowledge from labeled samples to unlabeled data. Along with supervised learning for labeled data, the prediction of unlabeled data is jointly learned with the generated pseudo masks from the mixed data. Extensive experiments on PASCAL VOC 2012, and Cityscapes demonstrate the effectiveness of our GuidedMix-Net, which achieves competitive segmentation accuracy and significantly improves the mIoU by +7$\%$ compared to previous approaches.
Decentralized Task Offloading in Edge Computing: A Multi-User Multi-Armed Bandit Approach
Dec 28, 2021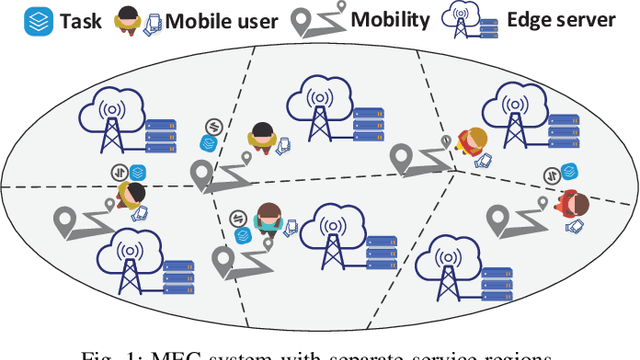
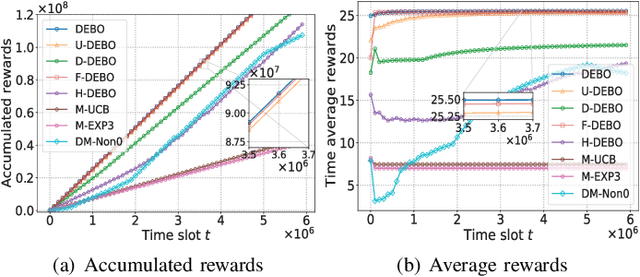
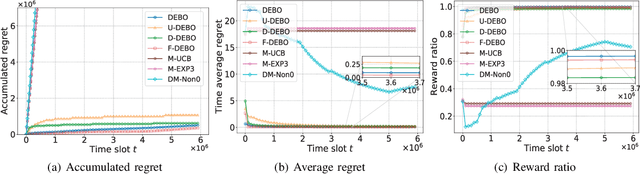
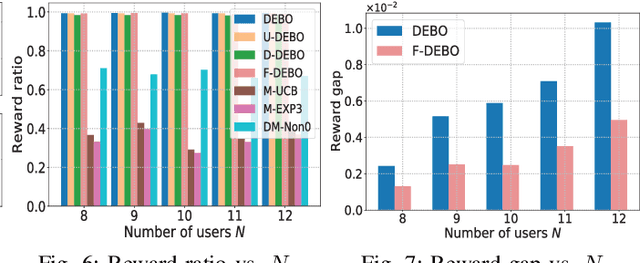
Mobile edge computing facilitates users to offload computation tasks to edge servers for meeting their stringent delay requirements. Previous works mainly explore task offloading when system-side information is given (e.g., server processing speed, cellular data rate), or centralized offloading under system uncertainty. But both generally fall short to handle task placement involving many coexisting users in a dynamic and uncertain environment. In this paper, we develop a multi-user offloading framework considering unknown yet stochastic system-side information to enable a decentralized user-initiated service placement. Specifically, we formulate the dynamic task placement as an online multi-user multi-armed bandit process, and propose a decentralized epoch based offloading (DEBO) to optimize user rewards which are subjected under network delay. We show that DEBO can deduce the optimal user-server assignment, thereby achieving a close-to-optimal service performance and tight O(log T) offloading regret. Moreover, we generalize DEBO to various common scenarios such as unknown reward gap, dynamic entering or leaving of clients, and fair reward distribution, while further exploring when users' offloaded tasks require heterogeneous computing resources. Particularly, we accomplish a sub-linear regret for each of these instances. Real measurements based evaluations corroborate the superiority of our offloading schemes over state-of-the-art approaches in optimizing delay-sensitive rewards.
Dynamic Bottleneck for Robust Self-Supervised Exploration
Oct 25, 2021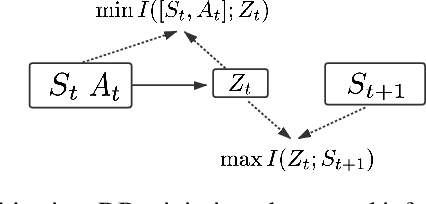
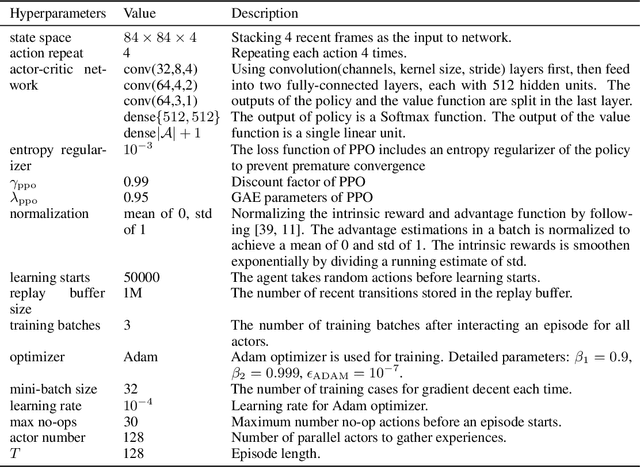

Exploration methods based on pseudo-count of transitions or curiosity of dynamics have achieved promising results in solving reinforcement learning with sparse rewards. However, such methods are usually sensitive to environmental dynamics-irrelevant information, e.g., white-noise. To handle such dynamics-irrelevant information, we propose a Dynamic Bottleneck (DB) model, which attains a dynamics-relevant representation based on the information-bottleneck principle. Based on the DB model, we further propose DB-bonus, which encourages the agent to explore state-action pairs with high information gain. We establish theoretical connections between the proposed DB-bonus, the upper confidence bound (UCB) for linear case, and the visiting count for tabular case. We evaluate the proposed method on Atari suits with dynamics-irrelevant noises. Our experiments show that exploration with DB bonus outperforms several state-of-the-art exploration methods in noisy environments.
Revisiting Over-Smoothness in Text to Speech
Feb 26, 2022


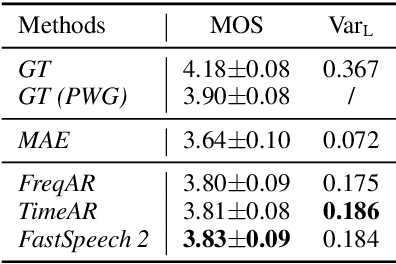
Non-autoregressive text to speech (NAR-TTS) models have attracted much attention from both academia and industry due to their fast generation speed. One limitation of NAR-TTS models is that they ignore the correlation in time and frequency domains while generating speech mel-spectrograms, and thus cause blurry and over-smoothed results. In this work, we revisit this over-smoothing problem from a novel perspective: the degree of over-smoothness is determined by the gap between the complexity of data distributions and the capability of modeling methods. Both simplifying data distributions and improving modeling methods can alleviate the problem. Accordingly, we first study methods reducing the complexity of data distributions. Then we conduct a comprehensive study on NAR-TTS models that use some advanced modeling methods. Based on these studies, we find that 1) methods that provide additional condition inputs reduce the complexity of data distributions to model, thus alleviating the over-smoothing problem and achieving better voice quality. 2) Among advanced modeling methods, Laplacian mixture loss performs well at modeling multimodal distributions and enjoys its simplicity, while GAN and Glow achieve the best voice quality while suffering from increased training or model complexity. 3) The two categories of methods can be combined to further alleviate the over-smoothness and improve the voice quality. 4) Our experiments on the multi-speaker dataset lead to similar conclusions as above and providing more variance information can reduce the difficulty of modeling the target data distribution and alleviate the requirements for model capacity.