 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Googling for Abortion: Search Engine Mediation of Abortion Accessibility in the United States
Feb 23, 2022
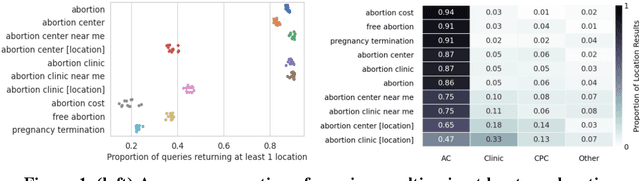
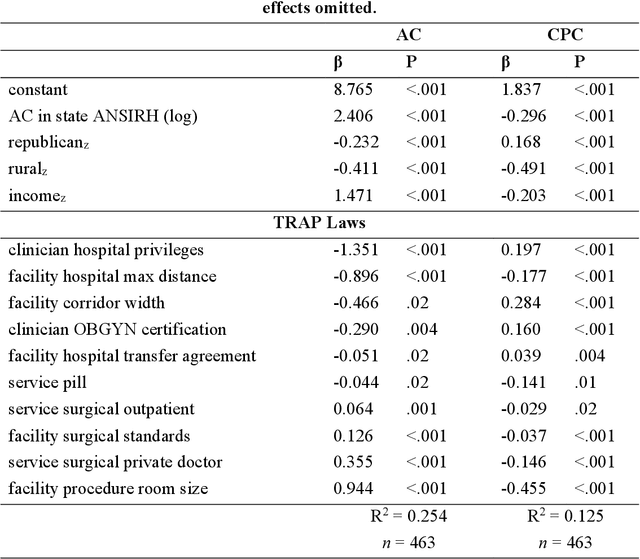
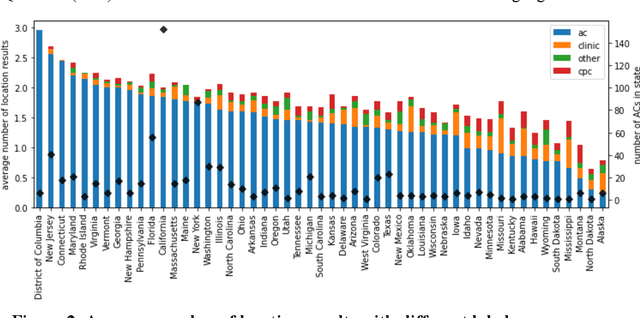
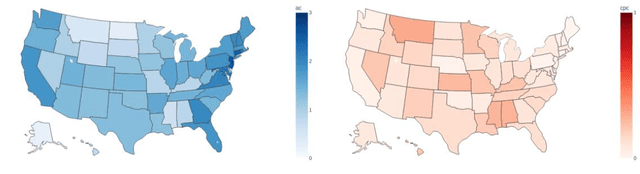
Among the myriad barriers to abortion access, crisis pregnancy centers (CPCs) pose an additional difficulty by targeting women with unexpected or "crisis" pregnancies in order to dissuade them from the procedure. Web search engines may prove to be another barrier, being in a powerful position to direct their users to health information, and above all, health services. In this study we ask, to what degree does Google Search provide quality responses to users searching for an abortion provider, specifically in terms of directing them to abortion clinics (ACs) or CPCs. To answer this question, we considered the scenario of a woman searching for abortion services online, and conducted 10 abortion-related queries from 467 locations across the United States once a week for 14 weeks. Overall, among Google's location results that feature businesses alongside a map, 79.4% were ACs, and 6.9% were CPCs. When an AC was returned, it was the closest known AC location 86.9% of the time. However, when a CPC appeared in a result set, it was the closest one to the search location 75.9% of the time. Examining correlates of AC results, we found that fewer AC results were returned for searches from poorer and rural areas, and those with TRAP laws governing AC facility and clinician requirements. We also observed that Google's performance on our queries significantly improved following a major algorithm update. These results have important implications concerning health access quality and equity, both for individual users and public health policy.
Pose Guided Image Generation from Misaligned Sources via Residual Flow Based Correction
Feb 02, 2022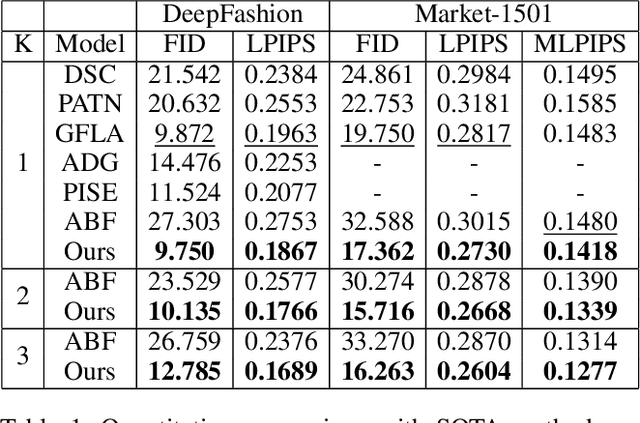
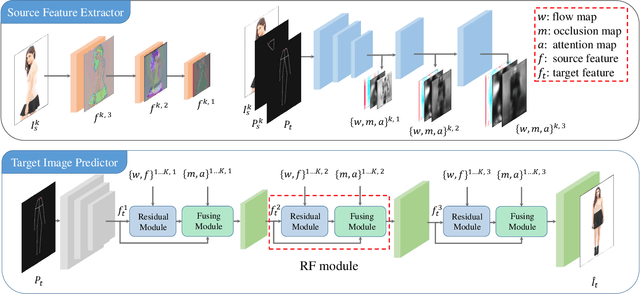
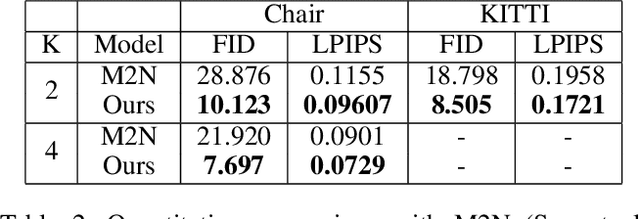
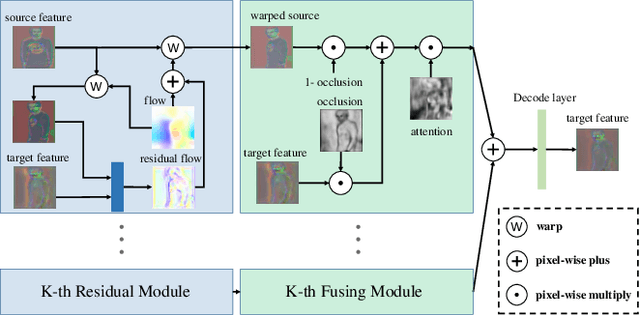
Generating new images with desired properties (e.g. new view/poses) from source images has been enthusiastically pursued recently, due to its wide range of potential applications. One way to ensure high-quality generation is to use multiple sources with complementary information such as different views of the same object. However, as source images are often misaligned due to the large disparities among the camera settings, strong assumptions have been made in the past with respect to the camera(s) or/and the object in interest, limiting the application of such techniques. Therefore, we propose a new general approach which models multiple types of variations among sources, such as view angles, poses, facial expressions, in a unified framework, so that it can be employed on datasets of vastly different nature. We verify our approach on a variety of data including humans bodies, faces, city scenes and 3D objects. Both the qualitative and quantitative results demonstrate the better performance of our method than the state of the art.
Privacy Amplification via Shuffling for Linear Contextual Bandits
Dec 11, 2021
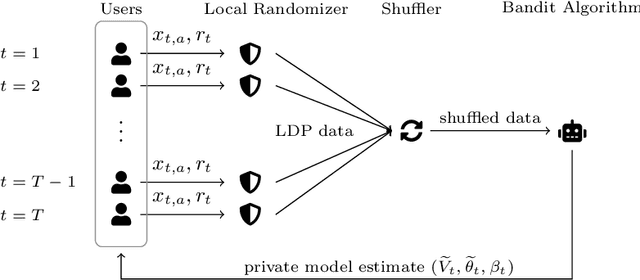
Contextual bandit algorithms are widely used in domains where it is desirable to provide a personalized service by leveraging contextual information, that may contain sensitive information that needs to be protected. Inspired by this scenario, we study the contextual linear bandit problem with differential privacy (DP) constraints. While the literature has focused on either centralized (joint DP) or local (local DP) privacy, we consider the shuffle model of privacy and we show that is possible to achieve a privacy/utility trade-off between JDP and LDP. By leveraging shuffling from privacy and batching from bandits, we present an algorithm with regret bound $\widetilde{\mathcal{O}}(T^{2/3}/\varepsilon^{1/3})$, while guaranteeing both central (joint) and local privacy. Our result shows that it is possible to obtain a trade-off between JDP and LDP by leveraging the shuffle model while preserving local privacy.
An Efficient Combinatorial Optimization Model Using Learning-to-Rank Distillation
Dec 24, 2021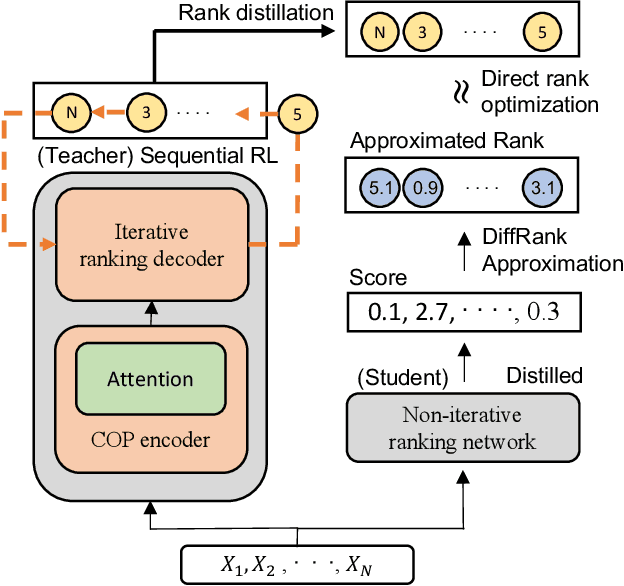
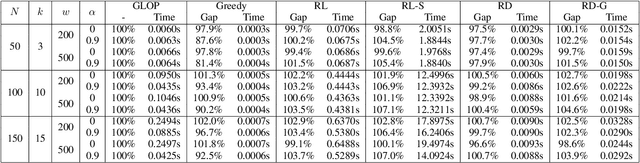
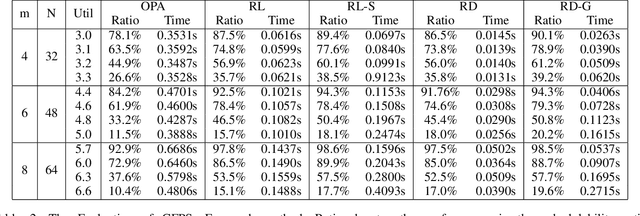
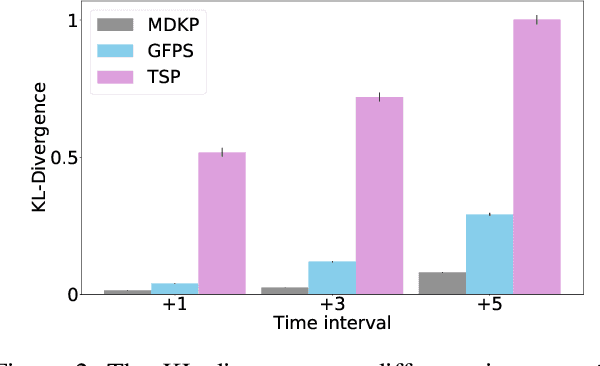
Recently, deep reinforcement learning (RL) has proven its feasibility in solving combinatorial optimization problems (COPs). The learning-to-rank techniques have been studied in the field of information retrieval. While several COPs can be formulated as the prioritization of input items, as is common in the information retrieval, it has not been fully explored how the learning-to-rank techniques can be incorporated into deep RL for COPs. In this paper, we present the learning-to-rank distillation-based COP framework, where a high-performance ranking policy obtained by RL for a COP can be distilled into a non-iterative, simple model, thereby achieving a low-latency COP solver. Specifically, we employ the approximated ranking distillation to render a score-based ranking model learnable via gradient descent. Furthermore, we use the efficient sequence sampling to improve the inference performance with a limited delay. With the framework, we demonstrate that a distilled model not only achieves comparable performance to its respective, high-performance RL, but also provides several times faster inferences. We evaluate the framework with several COPs such as priority-based task scheduling and multidimensional knapsack, demonstrating the benefits of the framework in terms of inference latency and performance.
Socially-Optimal Mechanism Design for Incentivized Online Learning
Dec 29, 2021
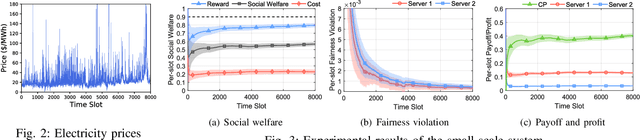
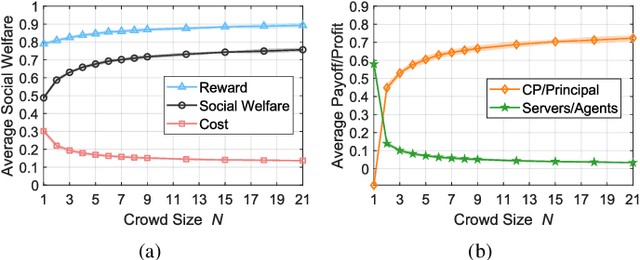

Multi-arm bandit (MAB) is a classic online learning framework that studies the sequential decision-making in an uncertain environment. The MAB framework, however, overlooks the scenario where the decision-maker cannot take actions (e.g., pulling arms) directly. It is a practically important scenario in many applications such as spectrum sharing, crowdsensing, and edge computing. In these applications, the decision-maker would incentivize other selfish agents to carry out desired actions (i.e., pulling arms on the decision-maker's behalf). This paper establishes the incentivized online learning (IOL) framework for this scenario. The key challenge to design the IOL framework lies in the tight coupling of the unknown environment learning and asymmetric information revelation. To address this, we construct a special Lagrangian function based on which we propose a socially-optimal mechanism for the IOL framework. Our mechanism satisfies various desirable properties such as agent fairness, incentive compatibility, and voluntary participation. It achieves the same asymptotic performance as the state-of-art benchmark that requires extra information. Our analysis also unveils the power of crowd in the IOL framework: a larger agent crowd enables our mechanism to approach more closely the theoretical upper bound of social performance. Numerical results demonstrate the advantages of our mechanism in large-scale edge computing.
Using Deep Learning to Bootstrap Abstractions for Hierarchical Robot Planning
Feb 11, 2022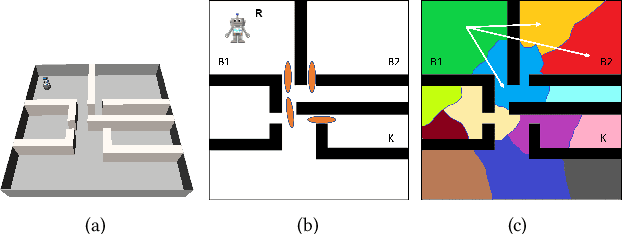
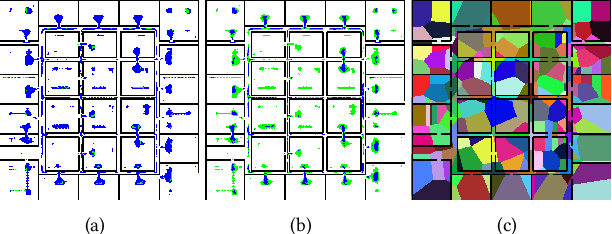
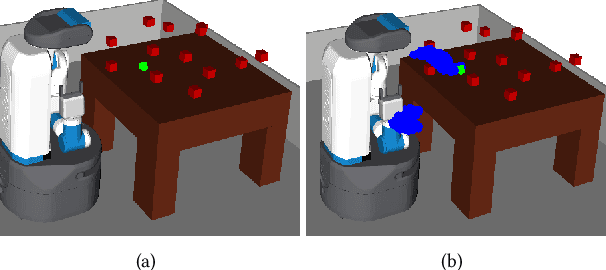
This paper addresses the problem of learning abstractions that boost robot planning performance while providing strong guarantees of reliability. Although state-of-the-art hierarchical robot planning algorithms allow robots to efficiently compute long-horizon motion plans for achieving user desired tasks, these methods typically rely upon environment-dependent state and action abstractions that need to be hand-designed by experts. We present a new approach for bootstrapping the entire hierarchical planning process. This allows us to compute abstract states and actions for new environments automatically using the critical regions predicted by a deep neural network with an auto-generated robot-specific architecture. We show that the learned abstractions can be used with a novel multi-source bi-directional hierarchical robot planning algorithm that is sound and probabilistically complete. An extensive empirical evaluation on twenty different settings using holonomic and non-holonomic robots shows that (a) our learned abstractions provide the information necessary for efficient multi-source hierarchical planning; and that (b) this approach of learning, abstractions, and planning outperforms state-of-the-art baselines by nearly a factor of ten in terms of planning time on test environments not seen during training.
A Newton-type algorithm for federated learning based on incremental Hessian eigenvector sharing
Feb 11, 2022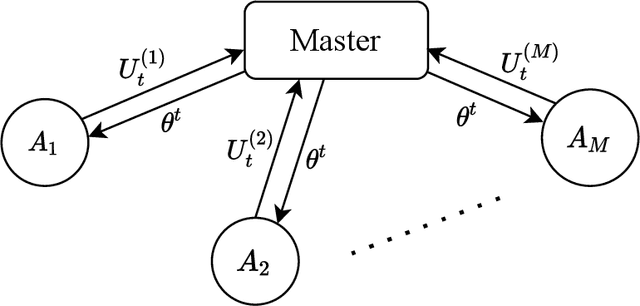
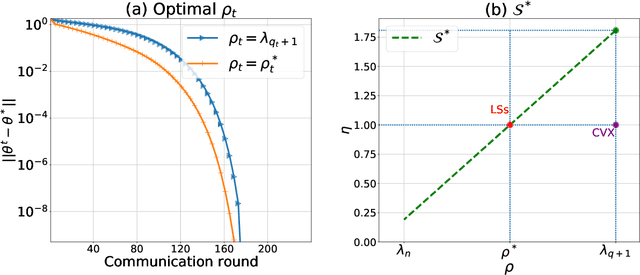
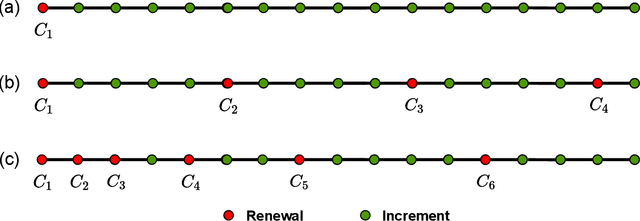
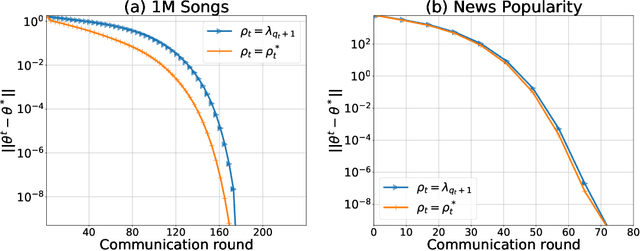
There is a growing interest in the decentralized optimization framework that goes under the name of Federated Learning (FL). In particular, much attention is being turned to FL scenarios where the network is strongly heterogeneous in terms of communication resources (e.g., bandwidth) and data distribution. In these cases, communication between local machines (agents) and the central server (Master) is a main consideration. In this work, we present an original communication-constrained Newton-type (NT) algorithm designed to accelerate FL in such heterogeneous scenarios. The algorithm is by design robust to non i.i.d. data distributions, handles heterogeneity of agents' communication resources (CRs), only requires sporadic Hessian computations, and achieves super-linear convergence. This is possible thanks to an incremental strategy, based on a singular value decomposition (SVD) of the local Hessian matrices, which exploits (possibly) outdated second-order information. The proposed solution is thoroughly validated on real datasets by assessing (i) the number of communication rounds required for convergence, (ii) the overall amount of data transmitted and (iii) the number of local Hessian computations required. For all these metrics, the proposed approach shows superior performance against state-of-the art techniques like GIANT and FedNL.
Multi-cell Non-coherent Over-the-Air Computation for Federated Edge Learning
Feb 11, 2022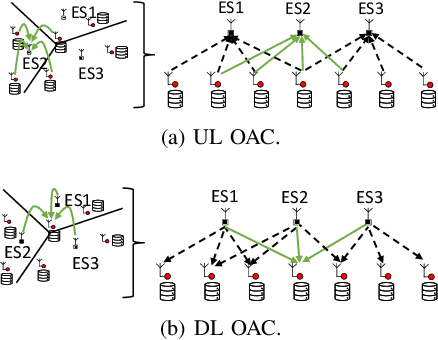
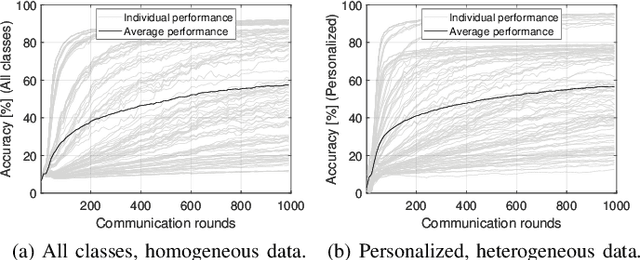
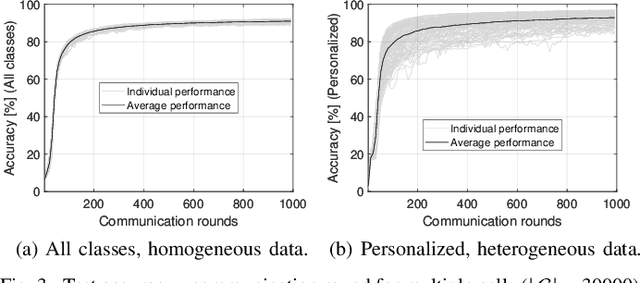
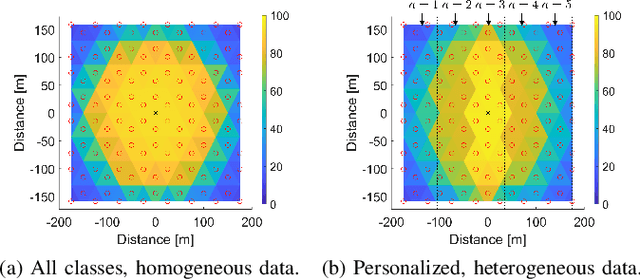
In this paper, we propose a framework where over-the-air computation (OAC) occurs in both uplink (UL) and downlink (DL), sequentially, in a multi-cell environment to address the latency and the scalability issues of federated edge learning (FEEL). To eliminate the channel state information (CSI) at the edge devices (EDs) and edge servers (ESs) and relax the time-synchronization requirement for the OAC, we use a non-coherent computation scheme, i.e., frequency-shift keying (FSK)-based majority vote (MV) (FSK-MV). With the proposed framework, multiple ESs function as the aggregation nodes in the UL and each ES determines the MVs independently. After the ESs broadcast the detected MVs, the EDs determine the sign of the gradient through another OAC in the DL. Hence, inter-cell interference is exploited for the OAC. In this study, we prove the convergence of the non-convex optimization problem for the FEEL with the proposed OAC framework. We also numerically evaluate the efficacy of the proposed method by comparing the test accuracy in both multi-cell and single-cell scenarios for both homogeneous and heterogeneous data distributions.
Constraining cosmological parameters from N-body simulations with Bayesian Neural Networks
Dec 22, 2021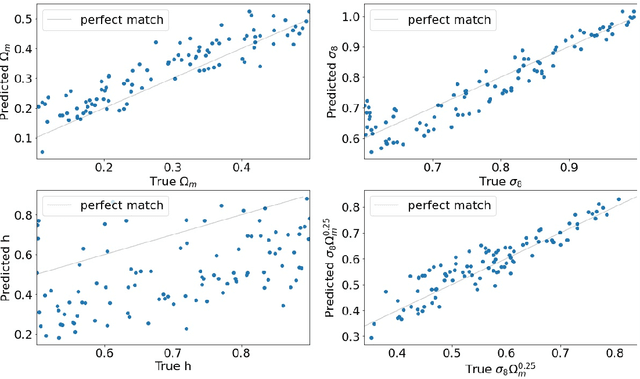
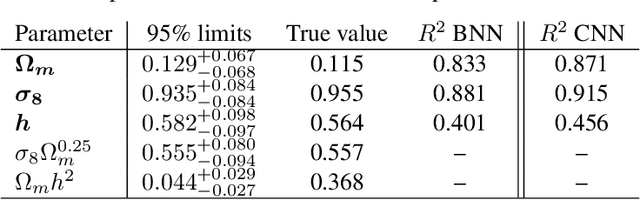
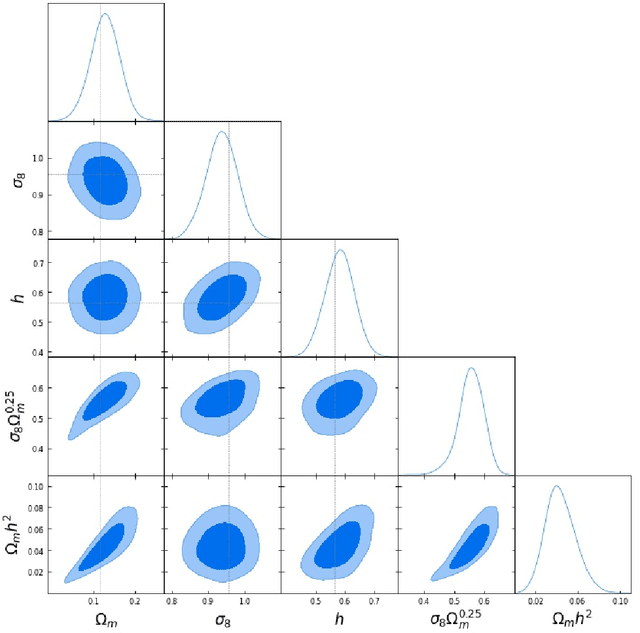
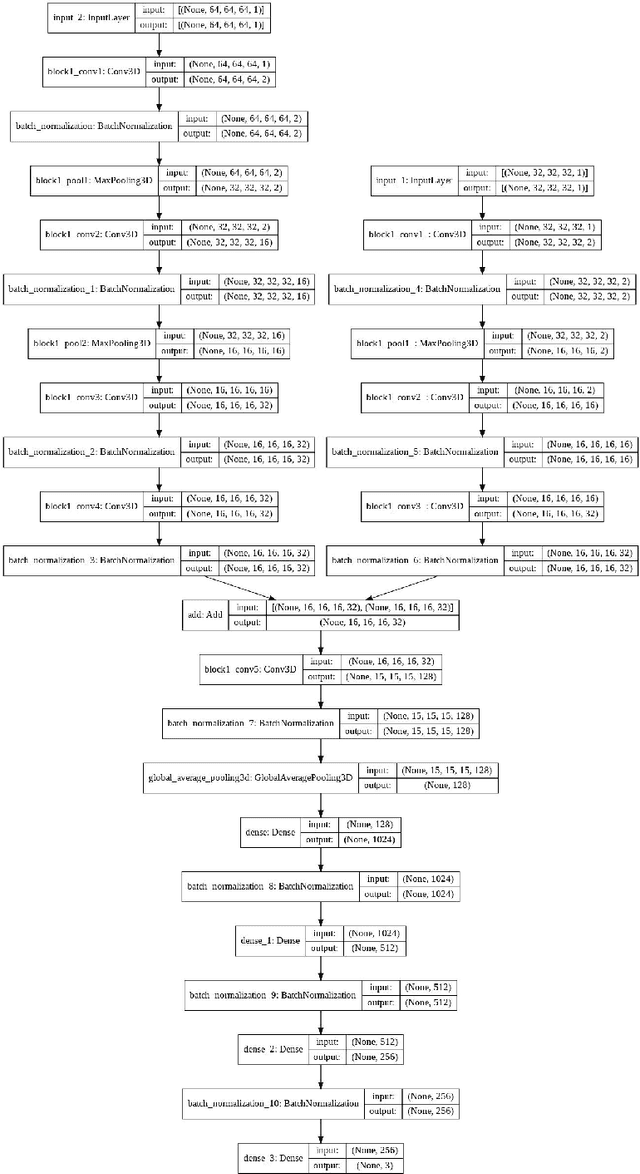
In this paper, we use The Quijote simulations in order to extract the cosmological parameters through Bayesian Neural Networks. This kind of model has a remarkable ability to estimate the associated uncertainty, which is one of the ultimate goals in the precision cosmology era. We demonstrate the advantages of BNNs for extracting more complex output distributions and non-Gaussianities information from the simulations.
Ranging-Based Localizability-Constrained Deployment of Mobile Robotic Networks
Feb 01, 2022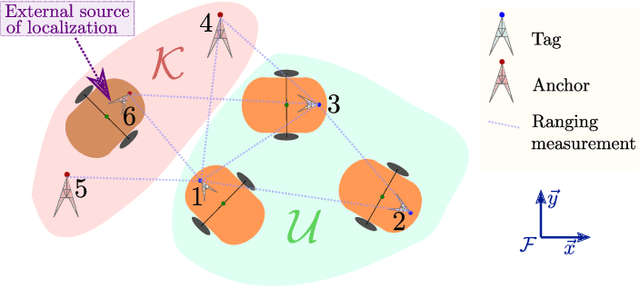
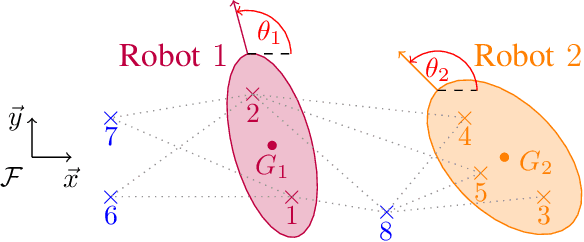
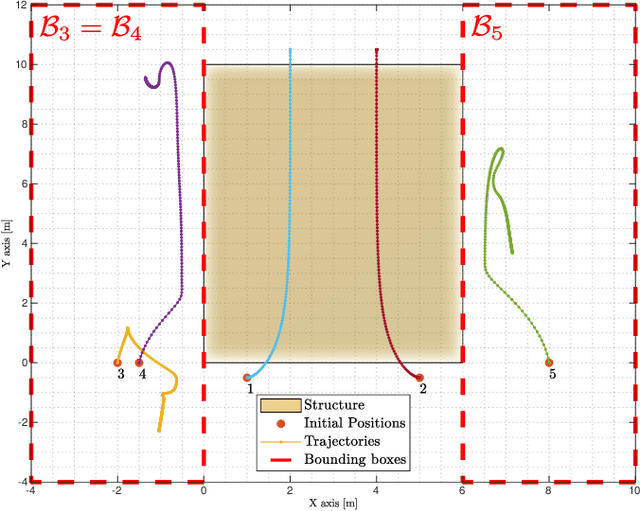
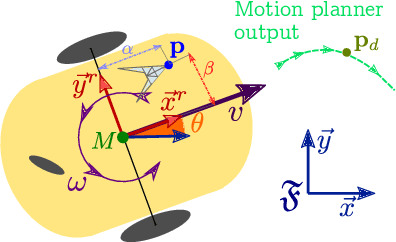
In cooperative localization schemes for robotic networks relying on noisy range measurements between agents, the achievable positioning accuracy strongly depends on the network geometry. This motivates the problem of planning robot trajectories in such multi-robot systems in a way that maintains high localization accuracy. We present potential-based planning methods, where localizability potentials are introduced to characterize the quality of the network geometry for cooperative position estimation. These potentials are based on Cram\'er Rao Lower Bounds (CRLB) and provide a theoretical lower bound on the error covariance achievable by any unbiased position estimator. In the process, we establish connections between CRLBs and the theory of graph rigidity, which has been previously used to plan the motion of robotic networks. We develop decentralized deployment algorithms appropriate for large networks, and we use equality-constrained CRLBs to extend the concept of localizability to scenarios where additional information about the relative positions of the ranging sensors is known. We illustrate the resulting robot deployment methodology through simulated examples.