 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Understanding Rare Spurious Correlations in Neural Networks
Feb 10, 2022

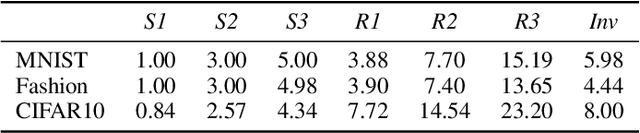
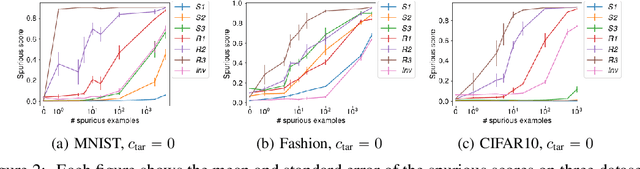
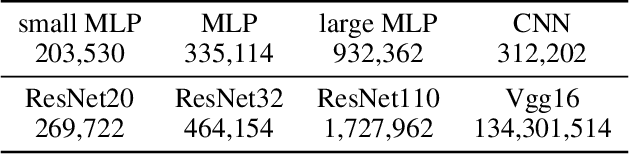
Neural networks are known to use spurious correlations for classification; for example, they commonly use background information to classify objects. But how many examples does it take for a network to pick up these correlations? This is the question that we empirically investigate in this work. We introduce spurious patterns correlated with a specific class to a few examples and find that it takes only a handful of such examples for the network to pick up on the spurious correlation. Through extensive experiments, we show that (1) spurious patterns with a larger $\ell_2$ norm are learnt to correlate with the specified class more easily; (2) network architectures that are more sensitive to the input are more susceptible to learning these rare spurious correlations; (3) standard data deletion methods, including incremental retraining and influence functions, are unable to forget these rare spurious correlations through deleting the examples that cause these spurious correlations to be learnt. Code available at https://github.com/yangarbiter/rare-spurious-correlation.
Learning Sinkhorn divergences for supervised change point detection
Feb 10, 2022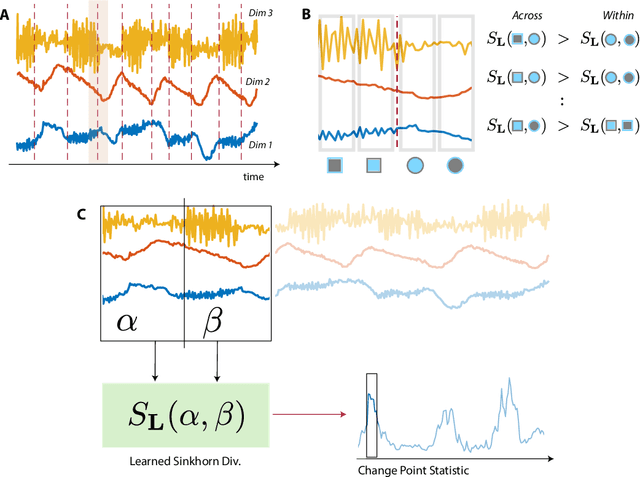
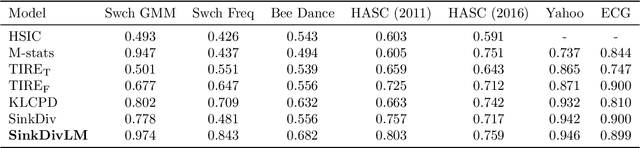
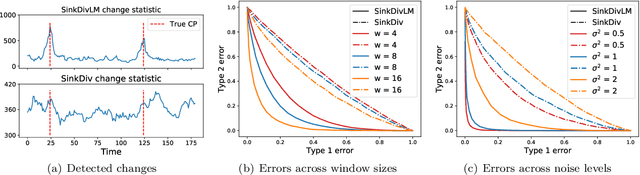
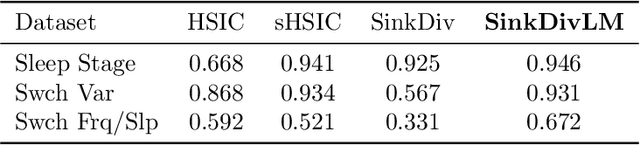
Many modern applications require detecting change points in complex sequential data. Most existing methods for change point detection are unsupervised and, as a consequence, lack any information regarding what kind of changes we want to detect or if some kinds of changes are safe to ignore. This often results in poor change detection performance. We present a novel change point detection framework that uses true change point instances as supervision for learning a ground metric such that Sinkhorn divergences can be then used in two-sample tests on sliding windows to detect change points in an online manner. Our method can be used to learn a sparse metric which can be useful for both feature selection and interpretation in high-dimensional change point detection settings. Experiments on simulated as well as real world sequences show that our proposed method can substantially improve change point detection performance over existing unsupervised change point detection methods using only few labeled change point instances.
Physics solutions for machine learning privacy leaks
Feb 24, 2022
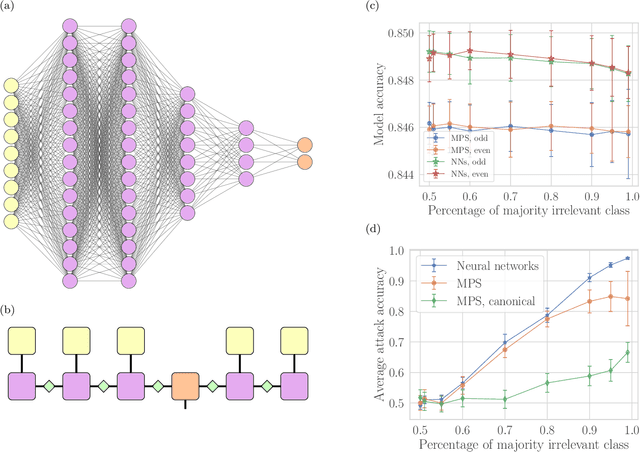
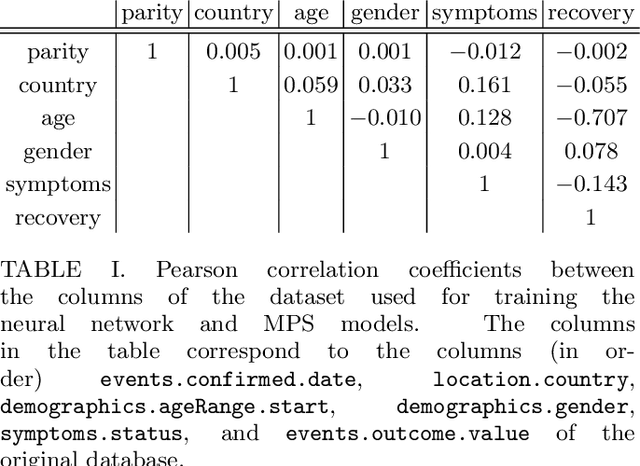
Machine learning systems are becoming more and more ubiquitous in increasingly complex areas, including cutting-edge scientific research. The opposite is also true: the interest in better understanding the inner workings of machine learning systems motivates their analysis under the lens of different scientific disciplines. Physics is particularly successful in this, due to its ability to describe complex dynamical systems. While explanations of phenomena in machine learning based on physics are increasingly present, examples of direct application of notions akin to physics in order to improve machine learning systems are more scarce. Here we provide one such application in the problem of developing algorithms that preserve the privacy of the manipulated data, which is especially important in tasks such as the processing of medical records. We develop well-defined conditions to guarantee robustness to specific types of privacy leaks, and rigorously prove that such conditions are satisfied by tensor-network architectures. These are inspired by the efficient representation of quantum many-body systems, and have shown to compete and even surpass traditional machine learning architectures in certain cases. Given the growing expertise in training tensor-network architectures, these results imply that one may not have to be forced to make a choice between accuracy in prediction and ensuring the privacy of the information processed.
Reliability Estimation of an Advanced Nuclear Fuel using Coupled Active Learning, Multifidelity Modeling, and Subset Simulation
Jan 06, 2022
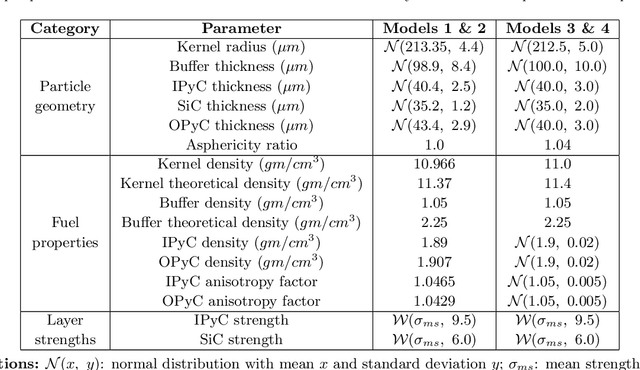
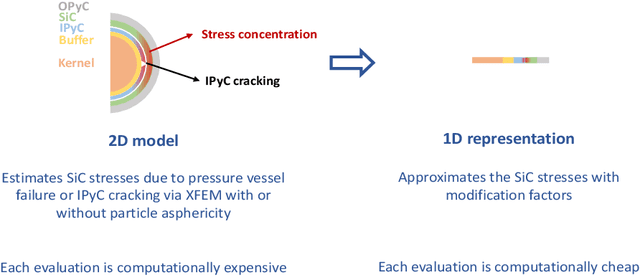

Tristructural isotropic (TRISO)-coated particle fuel is a robust nuclear fuel and determining its reliability is critical for the success of advanced nuclear technologies. However, TRISO failure probabilities are small and the associated computational models are expensive. We used coupled active learning, multifidelity modeling, and subset simulation to estimate the failure probabilities of TRISO fuels using several 1D and 2D models. With multifidelity modeling, we replaced expensive high-fidelity (HF) model evaluations with information fusion from two low-fidelity (LF) models. For the 1D TRISO models, we considered three multifidelity modeling strategies: only Kriging, Kriging LF prediction plus Kriging correction, and deep neural network (DNN) LF prediction plus Kriging correction. While the results across these multifidelity modeling strategies compared satisfactorily, strategies employing information fusion from two LF models consistently called the HF model least often. Next, for the 2D TRISO model, we considered two multifidelity modeling strategies: DNN LF prediction plus Kriging correction (data-driven) and 1D TRISO LF prediction plus Kriging correction (physics-based). The physics-based strategy, as expected, consistently required the fewest calls to the HF model. However, the data-driven strategy had a lower overall simulation time since the DNN predictions are instantaneous, and the 1D TRISO model requires a non-negligible simulation time.
data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
Feb 07, 2022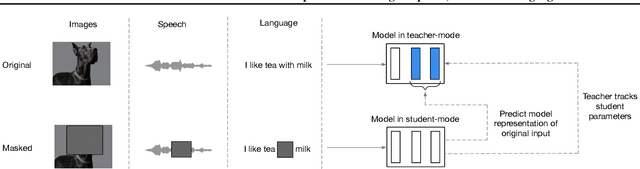
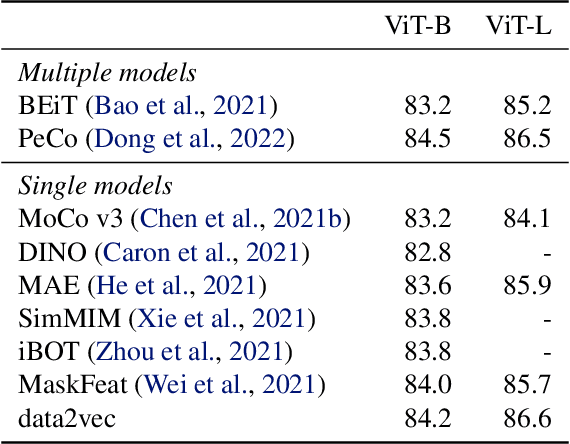
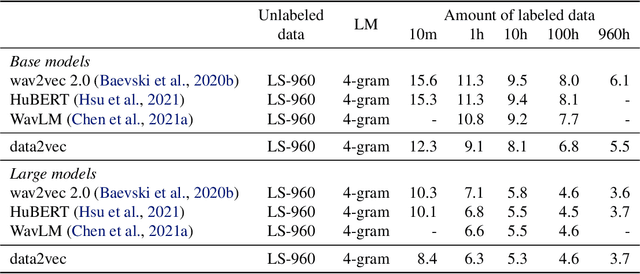
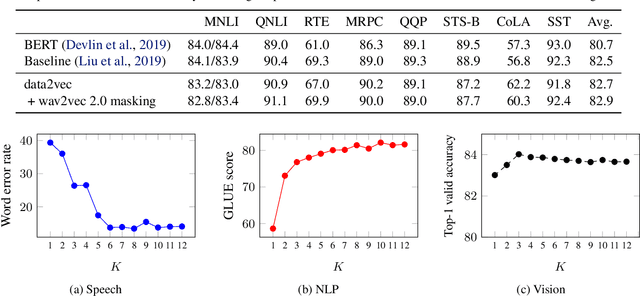
While the general idea of self-supervised learning is identical across modalities, the actual algorithms and objectives differ widely because they were developed with a single modality in mind. To get us closer to general self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech, NLP or computer vision. The core idea is to predict latent representations of the full input data based on a masked view of the input in a self-distillation setup using a standard Transformer architecture. Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which are local in nature, data2vec predicts contextualized latent representations that contain information from the entire input. Experiments on the major benchmarks of speech recognition, image classification, and natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
Learning Conditional Invariance through Cycle Consistency
Nov 25, 2021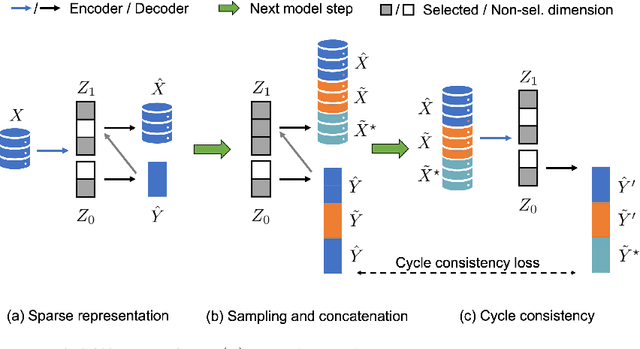
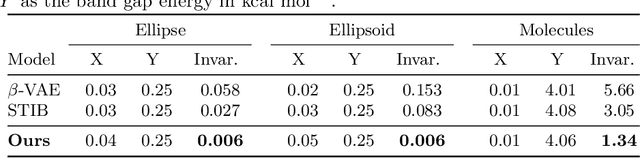
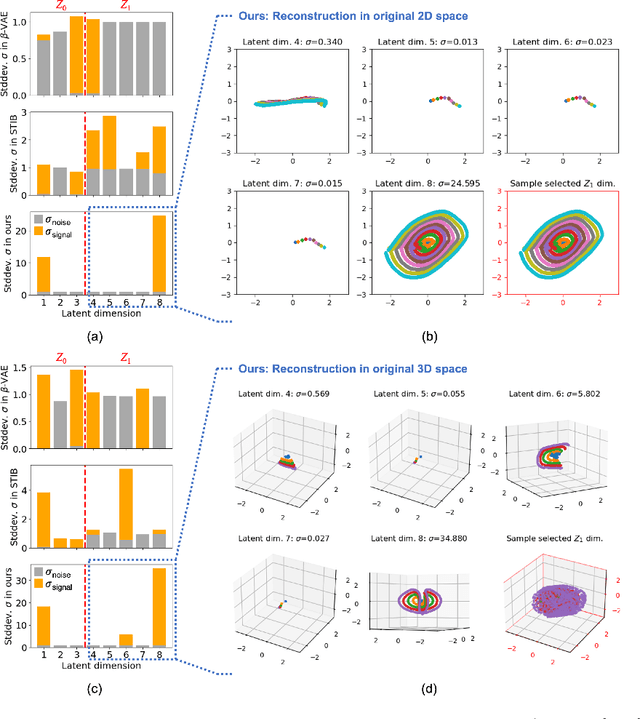
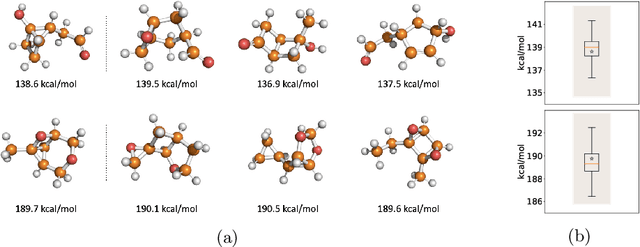
Identifying meaningful and independent factors of variation in a dataset is a challenging learning task frequently addressed by means of deep latent variable models. This task can be viewed as learning symmetry transformations preserving the value of a chosen property along latent dimensions. However, existing approaches exhibit severe drawbacks in enforcing the invariance property in the latent space. We address these shortcomings with a novel approach to cycle consistency. Our method involves two separate latent subspaces for the target property and the remaining input information, respectively. In order to enforce invariance as well as sparsity in the latent space, we incorporate semantic knowledge by using cycle consistency constraints relying on property side information. The proposed method is based on the deep information bottleneck and, in contrast to other approaches, allows using continuous target properties and provides inherent model selection capabilities. We demonstrate on synthetic and molecular data that our approach identifies more meaningful factors which lead to sparser and more interpretable models with improved invariance properties.
An Overview of Compressible and Learnable Image Transformation with Secret Key and Its Applications
Jan 26, 2022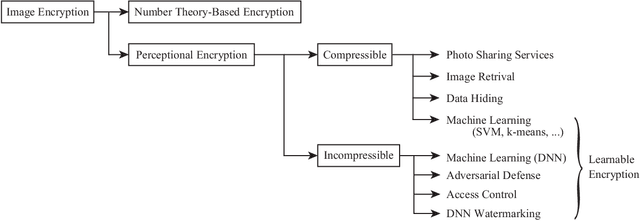

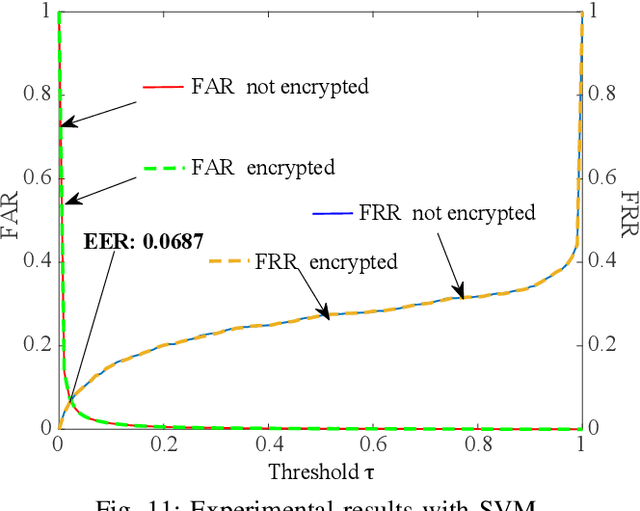

This article presents an overview of image transformation with a secret key and its applications. Image transformation with a secret key enables us not only to protect visual information on plain images but also to embed unique features controlled with a key into images. In addition, numerous encryption methods can generate encrypted images that are compressible and learnable for machine learning. Various applications of such transformation have been developed by using these properties. In this paper, we focus on a class of image transformation referred to as learnable image encryption, which is applicable to privacy-preserving machine learning and adversarially robust defense. Detailed descriptions of both transformation algorithms and performances are provided. Moreover, we discuss robustness against various attacks.
Adaptive Resonance Theory-based Topological Clustering with a Divisive Hierarchical Structure Capable of Continual Learning
Feb 02, 2022
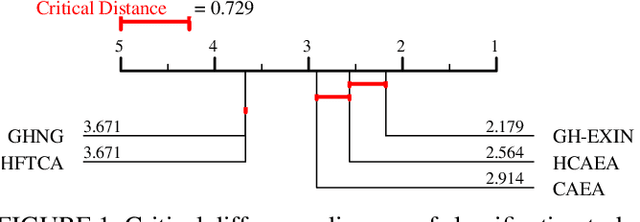
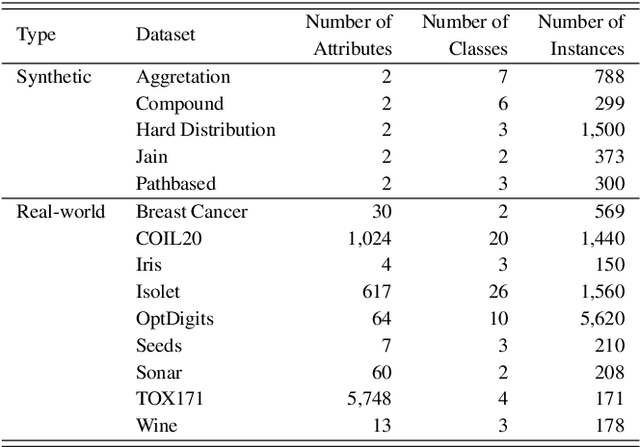
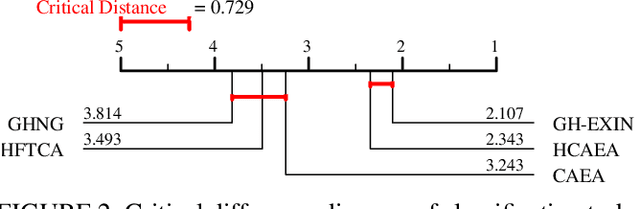
Adaptive Resonance Theory (ART) is considered as an effective approach for realizing continual learning thanks to its ability to handle the plasticity-stability dilemma. In general, however, the clustering performance of ART-based algorithms strongly depends on the specification of a similarity threshold, i.e., a vigilance parameter, which is data-dependent and specified by hand. This paper proposes an ART-based topological clustering algorithm with a mechanism that automatically estimates a similarity threshold from the distribution of data points. In addition, for improving information extraction performance, a divisive hierarchical clustering algorithm capable of continual learning is proposed by introducing a hierarchical structure to the proposed algorithm. Experimental results demonstrate that the proposed algorithm has high clustering performance comparable with recently-proposed state-of-the-art hierarchical clustering algorithms.
A Graph Convolutional Network with Signal Phasing Information for Arterial Traffic Prediction
Dec 25, 2020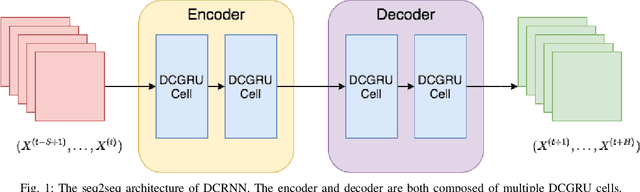
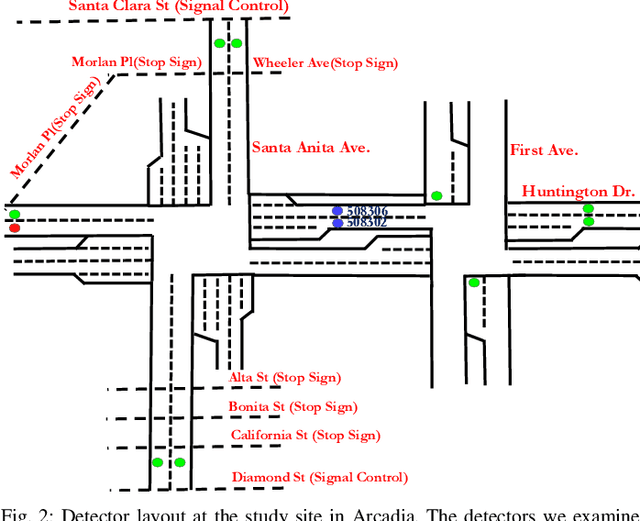
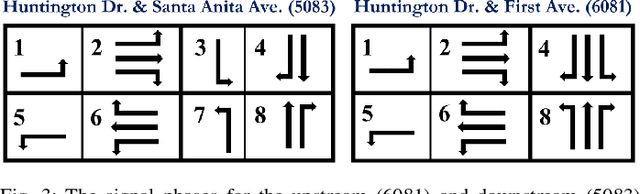
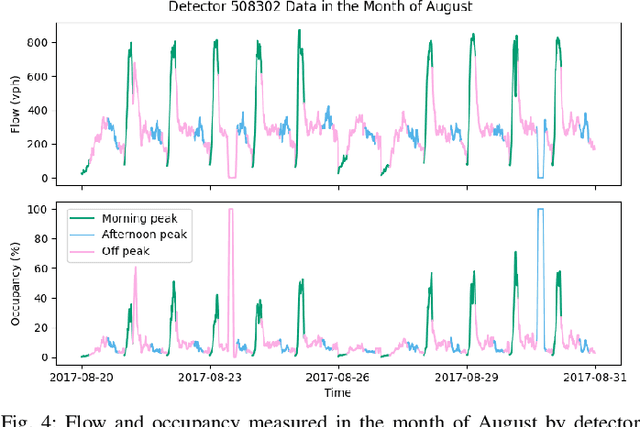
Accurate and reliable prediction of traffic measurements plays a crucial role in the development of modern intelligent transportation systems. Due to more complex road geometries and the presence of signal control, arterial traffic prediction is a level above freeway traffic prediction. Many existing studies on arterial traffic prediction only consider temporal measurements of flow and occupancy from loop sensors and neglect the rich spatial relationships between upstream and downstream detectors. As a result, they often suffer large prediction errors, especially for long horizons. We fill this gap by enhancing a deep learning approach, Diffusion Convolutional Recurrent Neural Network, with spatial information generated from signal timing plans at targeted intersections. Traffic at signalized intersections is modeled as a diffusion process with a transition matrix constructed from the phase splits of the signal phase timing plan. We apply this novel method to predict traffic flow from loop sensor measurements and signal timing plans at an arterial intersection in Arcadia, CA. We demonstrate that our proposed method yields superior forecasts; for a prediction horizon of 30 minutes, we cut the MAPE down to 16% for morning peaks, 10% for off peaks, and even 8% for afternoon peaks. In addition, we exemplify the robustness of our model through a number of experiments with various settings in detector coverage, detector type, and data quality.
Deep Generative model with Hierarchical Latent Factors for Time Series Anomaly Detection
Feb 15, 2022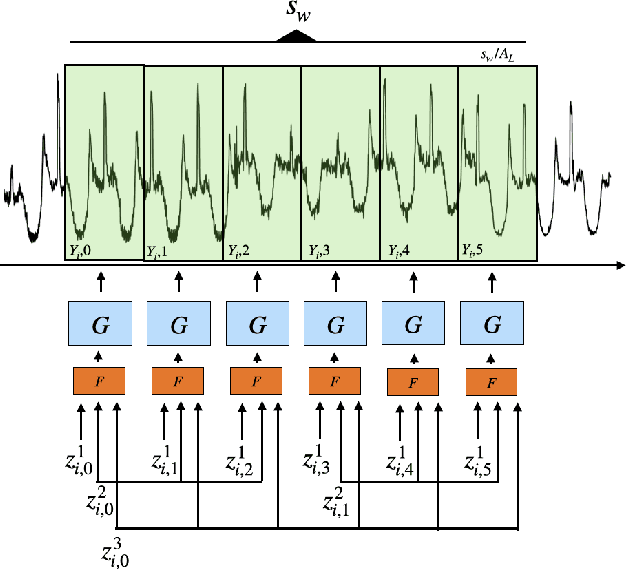
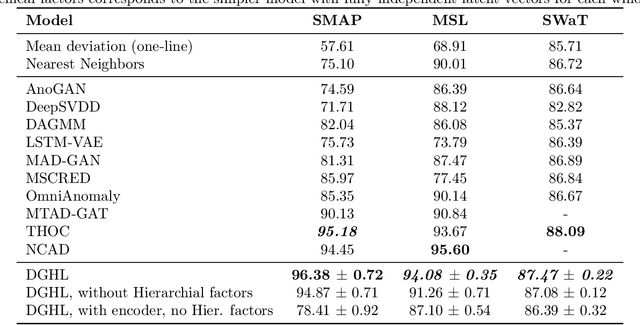
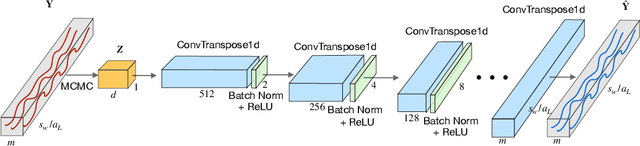
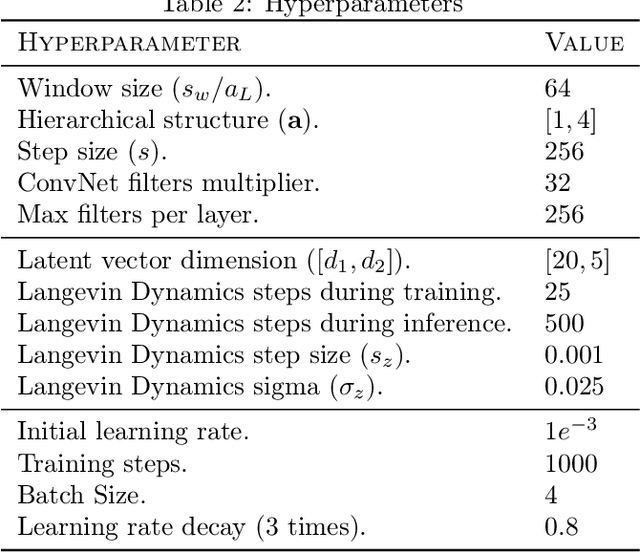
Multivariate time series anomaly detection has become an active area of research in recent years, with Deep Learning models outperforming previous approaches on benchmark datasets. Among reconstruction-based models, most previous work has focused on Variational Autoencoders and Generative Adversarial Networks. This work presents DGHL, a new family of generative models for time series anomaly detection, trained by maximizing the observed likelihood by posterior sampling and alternating back-propagation. A top-down Convolution Network maps a novel hierarchical latent space to time series windows, exploiting temporal dynamics to encode information efficiently. Despite relying on posterior sampling, it is computationally more efficient than current approaches, with up to 10x shorter training times than RNN based models. Our method outperformed current state-of-the-art models on four popular benchmark datasets. Finally, DGHL is robust to variable features between entities and accurate even with large proportions of missing values, settings with increasing relevance with the advent of IoT. We demonstrate the superior robustness of DGHL with novel occlusion experiments in this literature. Our code is available at https://github.com/cchallu/dghl.